

تتلقى ملف XML عبر البريد الإلكتروني المعتمد (PEC). تفتحه في المتصفح، وترى مجموعة هائلة من العلامات، وتعتقد أن المشكلة تكمن في «قراءته». في الواقع، هذا ليس سوى العائق الأول. أما المشكلة الحقيقية في الشركة فهي أخرى: معرفة ما إذا كانت تلك البيانات صحيحة ومتسقة وجاهزة لإدراجها في تقاريرك.
بالنسبة للعديد من الشركات الصغيرة والمتوسطة الإيطالية، لم يعد هذا الموضوع تقنيًا بالمعنى الضيق للكلمة. منذ أن أصبح إصدار الفواتير الإلكترونية إلزاميًا، أصبح لغة XML جزءًا لا يتجزأ من العمل اليومي في مجالات الإدارة والمراقبة الإدارية والتحليل. لا يكفي مجرد عرض المستند. عليك أن تتمكن من التمييز بين الملف القابل للقراءة والملف الموثوق. عليك أن تدرك متى يكفي إجراء فحص سريع ومتى يتطلب الأمر التحليل والتحقق من الصحة والتوحيد قبل تحميل البيانات في Excel أو في نظام ذكاء الأعمال (BI) أو في منصة تحليلية.
إذا كنت تبحث عن دليل عملي حول كيفية قراءة ملفات XML، فهذا هو الطريق الصحيح: ابدأ بالطرق البسيطة، وافهم أين تكمن نقاط الضعف فيها، ثم قم ببناء مسار يحول ملفات XML الخام إلى بيانات مفيدة للأعمال. وهنا يتم تقليل الأخطاء وتقصير الوقت بين «لدي الملف» و«لدي رؤية قابلة للاستخدام».
ينظم ملف XML البيانات في هيكل هرمي. يوجد عنصر رئيسي، وهناك أقسام متداخلة، ويصف كل كتلة معلومة ذات معنى محدد. وبالنسبة لمن يتولون إدارة العمليات الإدارية، فإن هذا التفصيل هو ما يميز بين البيانات القابلة للقراءة والبيانات القابلة للاستخدام فعليًّا.
ليس المقصود هنا «فتح» الملف. بل المقصود هو معرفة ما إذا كان بإمكان هذا الملف أن يندمج دون أخطاء في عمليات الرقابة والمحاسبة والتحليل.
لنأخذ فاتورة إلكترونية كمثال. يضم الملف نفسه بيانات المورد وبيانات العميل والقيم الخاضعة للضريبة وضريبة القيمة المضافة وبيانات البنود وشروط الدفع ومراجع الطلب، وغالبًا ما تتضمن أيضًا استثناءات تعقّد قراءتها. في لغة XML، لا تُدرج هذه المعلومات واحدة تلو الأخرى كما هو الحال في أي مستند عادي. بل تُوضع في مواقع محددة، ويوضح كل موقع ما يمثله.
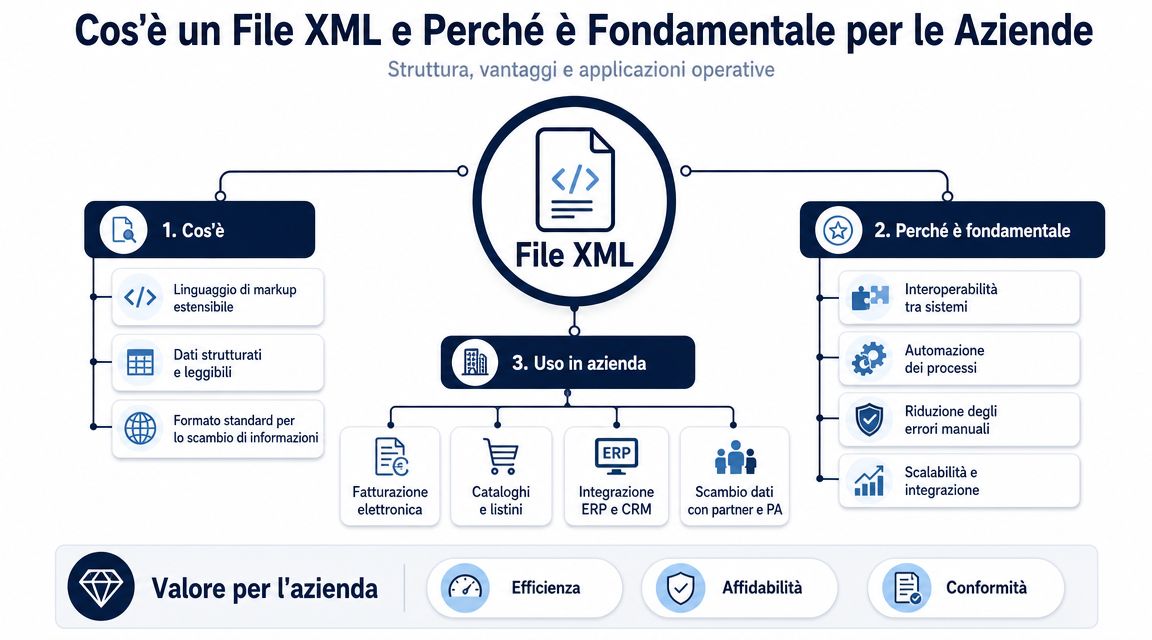
بالنسبة للمدير، فإن التمييز المفيد لا يكمن في الفرق بين «العلامات» و«السمات» بالمعنى النظري، بل بين «البيانات المعزولة» و«البيانات الموثوقة». فقراءة الرقم «1000,00» خارج سياقه لا تفيد كثيرًا، أما قراءته في الموضع الصحيح من الملف فتسمح بفهم ما إذا كان يمثل إجمالي المستند، أو القاعدة الضريبية، أو الضريبة، أو قيمة سطر واحد.
وهنا تكمن الميزة التشغيلية الأولى. فملف XML يحافظ على سياق البيانات.
قاعدة عملية: قراءة ملف XML جيدًا تعني التحقق من معنى القيمة، وليس القيمة فقط.
في إيطاليا، أصبح هذا الموضوع حقيقة واقعة مع انتشار الفواتير الإلكترونية. في تنسيق FatturaPA، أصبح لغة XML المعيار القياسي للوثائق الضريبية. ونتيجة لذلك، لم يعد قراءة هذه البيانات يقتصر على قسم تكنولوجيا المعلومات فحسب، بل أصبح يشمل الإدارة، ومراقبة الأداء، وقسم المشتريات، وأي شخص يحتاج إلى استخدام تلك البيانات لاتخاذ القرارات.
في الممارسة العملية، أرى دائمًا نفس المشكلة. الملف موجود، والبيانات موجودة، لكن الوقت اللازم لتحويلها إلى معلومات مفيدة يستغرق وقتًا طويلاً جدًّا. يقوم شخص ما بفتح ملف XML، والتحقق منه بصريًّا، ونسخ القيم إلى Excel، وتصحيح الحقول غير الموحدة، وإعادة تسمية الموردين المكتوبين بطرق مختلفة، ومحاولة إعادة بناء فئات الإنفاق التي لا يعرضها الملف في شكل جاهز للتحليل. والتكلفة ليست تشغيلية فحسب. إنه وقت ضائع في الحصول على الرؤى.
مع FatturaPA، يصبح الخطر أكثر وضوحًا. فقد يتسبب ملفان صحيحان من الناحية الشكلية في نفس مشاكل التحليل إذا استخدم أحدهما أوصافًا غير دقيقة للسطور، أو إذا كانت مراجع الطلبات غير مكتملة، أو إذا تم إدخال بيانات المورد بأشكال مختلفة. عندئذٍ لا تكمن المشكلة في قراءة ملفات XML، بل في منع أن تتحول البيانات الضريبية الصحيحة إلى بيانات إدارية غير موثوقة.
من الأخطاء الشائعة التعامل مع XML على أنه مرفق يجب عرضه. وفي الشركات، من الأفضل اعتباره مصدر بيانات منظم يجب التحقق منه قبل استخدامه في إعداد التقارير ولوحات المعلومات ونماذج الإنفاق. وإذا تمت إدارة هذه المرحلة بشكل خاطئ، فإن فريق الشؤون المالية يجد نفسه يناقش أرقامًا تبدو دقيقة ظاهريًّا، لكنها مبنية على تصنيفات غير متسقة.
الأسئلة الصحيحة، في البداية، هي التالية:
إنها عمليات تدقيق ملموسة للغاية. فهي تساعد على تجنب تكرار الموردين في التقارير، وسوء تفسير ضريبة القيمة المضافة، وعدم اكتمال بيانات مراكز التكلفة، وبطء عمليات التسوية في نهاية الشهر.
وهنا يتجلى الفارق بين القراءة التقنية والقيمة التجارية. يقوم محلل لغوي بقراءة الملف. وتنتج العملية المصممة جيدًا بيانات نظيفة وقابلة للمقارنة وجاهزة للتحليل. وقد تم إنشاء منصات مثل ELECTE لسد هذه الفجوة بالذات، من خلال تقليل العمل اليدوي الذي يفصل بين ملف XML المستلم والرؤى المفيدة لاتخاذ قرارات أفضل.
لإجراء عمليات تدقيق سريعة على ملف واحد، لا حاجة إلى محللات أو مكتبات برمجية. ما عليك هو تحديد ما إذا كنت تقوم بفحص بصري لعدد قليل من الحقول أم أنك تتعامل بالفعل مع بيانات ستُستخدم في المحاسبة أو إعداد التقارير أو الرقابة الإدارية. هذا الاختلاف مهم، لا سيما مع فواتير FatturePA. فالتدقيق الذي يتم على عجل اليوم قد يتحول غدًا إلى خطأ في مجموعة بيانات الموردين.

تعمل المتصفحات ومحررات النصوص وبرامج العرض المخصصة على حل مشكلة محددة: قراءة المحتوى بسرعة دون الحاجة إلى إعداد تدفق تقني. وبالنسبة لملف منفرد، غالبًا ما يكون ذلك كافيًا. يمكنك فتح ملف XML في Chrome أو Edge أو Firefox للاطلاع على هيكله، أو استخدام «المفكرة» أو «WordPad» أو «TextEdit» إذا كنت ترغب في فحص العلامات مباشرةً. وفي حالة الفواتير الإلكترونية، يتيح برنامج العرض المخصص قراءة العناوين وأسطر المستند والقيمة الخاضعة للضريبة وضريبة القيمة المضافة بشكل أوضح.
النقطة العملية هي التالية:
| أداة | مفيد لـ | العيب الرئيسي |
|---|---|---|
| المتصفح | فحص بصري سريع للهيكل | لا يتم التحقق من التناسق بين الحقول والأقسام |
| محرر نصوص | الفحص المباشر للعلامات | يصبح الأمر غير مريح عند التعامل مع الملفات الطويلة أو المتداخلة |
| إكسل | التدقيق الأولي في شكل جدول | يتعامل بشكل سيئ مع التسلسلات الهرمية والتكرارات |
| عارض مخصص | قراءة أوضح للفواتير والوثائق الضريبية | لا تقوم بإعداد البيانات للتحليل أو الأتمتة |
إذا كنت بحاجة إلى التحقق من تاريخ المستند أو رقم ضريبة القيمة المضافة أو إجمالي الفاتورة أو وجود مرفقات، فإن هذه الأدوات مناسبة لهذا الغرض.
أما إذا كان الهدف هو مقارنة الموردين، أو تصنيف النفقات، أو تزويد لوحة المعلومات بالبيانات، فإن الاكتفاء بعرض البيانات يؤدي إلى إبطاء العمل ويتيح مجالاً واسعاً للأخطاء اليدوية. وهذه هي الفجوة الكلاسيكية بين مجرد الاطلاع على ملف ما والوصول إلى بيانات موثوقة في الوقت المناسب.
إن فتح ملف XML لا يعني بالضرورة التحقق من صحة البيانات التي ستستخدمها في التقارير.
هناك نقطة عملية أخرى تتعلق بالحجم. يمكن التحقق من عشرة ملفات يدويًّا، أما مئات من فواتير FatturePA فلا. في هذه الحالة، من الأفضل التفكير مسبقًا في إنشاء سير عمل قابل للتكرار أو استخدام أدوات تقرأ المحتوى بطريقة منظمة، على سبيل المثال عبر واجهة برمجة التطبيقات (API) لاستيعاب المستندات الضريبية وإدارتها بطريقة متكاملة.
في إيطاليا، المشكلة المتكررة ليست فتح .xml، ولكن معرفة ما يجب فعله عندما يصل .xml.p7m عبر البريد الإلكتروني المعتمد (PEC). يجب التمييز بين ملفات XML البسيطة والملفات الموقعة رقمياً. الحالة الثانية تتطلب أدوات قادرة على قراءة التوقيع، واستخراج المحتوى، وعرض ملف XML الصحيح، كما يوضح هذا الدليل المخصص لـ XML و XML P7M في البريد الإلكتروني المعتمد (PEC).
هنا، الأخطاء تكلفنا الوقت:
بالنسبة لموظف إداري، فإن التسلسل الأكثر فائدة هو بسيط:
تؤدي هذه الأساليب دورها على أكمل وجه في عمليات المراقبة الأولية. لكنها لا تحل المشكلة التي تشكل عبئًا حقيقيًّا على الشركة: تحويل ملفات XML الضريبية، التي غالبًا ما تكون غير منتظمة أو غير موحدة، إلى بيانات نظيفة وقابلة للمقارنة دون إطالة الفترة الزمنية التي تفصل بين استلام المستند والحصول على المعلومات المفيدة.
عندما تبدأ الملفات في التراكم، يصبح العمل اليدوي غير قابل للاستمرار. عند هذه النقطة، لا يعد قراءة ملفات XML باستخدام التعليمات البرمجية خيارًا أنيقًا. إنها الخطوة الأولى لتجنب المهام المتكررة وأخطاء النسخ ومجموعات البيانات غير المتسقة.

يتبع النهج السليم لقراءة ملفات XML دائمًا نفس المنطق: التحليل، والتوحيد، والاستخراج الموجه. في دروس Java وAndroid، يمر المسار الصحيح عبر parse()، من خلال توحيد المحور باستخدام doc.getDocumentElement().normalize() ثم من خلال إعادة تأهيل الملاعب باستخدام getElementsByTagName، وهي طريقة أكثر استقرارًا من مجرد العرض في محرر النصوص، كما يوضح هذا الدليل الفني حول قراءة بيانات XML.
هذا التسلسل أكثر أهمية من اللغة التي تختارها. فإذا تخطيت عملية التطبيع، أو بحثت عن العقد بطريقة ساذجة للغاية، أو افترضت أن العلامة تظهر دائمًا مرة واحدة فقط، فسيعمل البرنامج النصي الخاص بك على بعض الملفات، لكنه سيفشل في الملفات المهمة بالذات.
بالنسبة للمشاريع التي يتعين عليها التفاعل مع أنظمة خارجية، قد يكون من المفيد إنشاء تدفق استخراج قابل للتكرار وموثق. إذا كنت تعمل على عمليات تكامل التطبيقات، فإن الوثائق الخاصة بواجهات برمجة التطبيقات (API) الخاصة بـ ELECTE مع ملف تعريف Postman تم التحقق منه تُعد أساسًا مفيدًا، لا سيما لفهم كيفية ربط مجموعة بيانات تم تنقيتها بالفعل بالعمليات اللاحقة.
فيما يلي بعض الأمثلة البسيطة. الهدف ليس تغطية كل الحالات، بل إظهار المنطق الأساسي: فتح الملف، والعثور على عقدة، وطباعة قيمة.
import xml.etree.ElementTree as ETtree = ET.parse("fattura.xml")root = tree.getroot()numero = root.find(".//Numero")if numero is not None:print(numero.text)غالبًا ما تكون لغة Python هي الخيار الأسرع للنماذج الأولية وعمليات التحويل وخطوط الإنتاج الخفيفة. وهي مثالية عندما تحتاج إلى قراءة العديد من ملفات XML واستخراج حقول قليلة وحفظها بتنسيق CSV أو JSON.
const xmlString = `<fattura><Numero>123</Numero></fattura>`;const parser = new DOMParser();const xmlDoc = parser.parseFromString(xmlString, "application/xml");const numero = xmlDoc.getElementsByTagName("Numero")[0];console.log(numero.textContent);يُعد هذا النهج مفيدًا للاختبارات السريعة على الصفحة أو الأدوات الداخلية الصغيرة. وهو مناسب للواجهات البسيطة، ولكنه أقل ملاءمة لعمليات العمل الداخلية المنظمة.
const fs = require("fs");const xml2js = require("xml2js");const xml = fs.readFileSync("fattura.xml", "utf8");xml2js.parseString(xml, (err, result) => {if (err) throw err;console.log(result.fattura.Numero[0]);});إذا كنت تعمل على جانب الخادم وترغب في إنشاء عمليات آلية، فإن Node.js تظل خيارًا عمليًّا. وتكمن ميزتها في سهولة دمج قراءة ملفات XML مع نظام الملفات وقوائم الانتظار والخدمات الداخلية.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse("fattura.xml");doc.getDocumentElement().normalize();NodeList lista = doc.getElementsByTagName("Numero");if (lista.getLength() > 0) {System.out.println(lista.item(0).getTextContent());}غالبًا ما تُستخدم لغة جافا في السياقات المؤسسية وإدارة الأعمال والبرمجيات الوسيطة. والهدف الأساسي هنا لا يقتصر على قراءة البيانات فحسب، بل القيام بذلك بطريقة يمكن التنبؤ بها وسهلة الصيانة.
library(XML)doc <- xmlParse("fattura.xml")numero <- xpathSApply(doc, "//Numero", xmlValue)print(numero)يكون استخدام لغة R منطقيًّا عندما يكون التحليل النحوي جزءًا من عمل تحليلي. فإذا كانت الخطوة التالية هي إجراء تحليل إحصائي أو تجهيز البيانات، فيمكنك الاحتفاظ بكل شيء في نفس البيئة.
إذا كان فريقك يفتح نفس الملفات كل أسبوع ويكرر نفس عمليات الفحص، فأنت بالفعل في مجال الأتمتة.
الفائدة الحقيقية لا تكمن في «قراءة ملفات XML باستخدام التعليمات البرمجية»، بل في إعفاء الأشخاص من العمل الروتيني وإنشاء مسار ينتج مجموعات بيانات متسقة.
تبدأ المشاكل الجدية عندما لا يكون الملف ملفًا واحدًا. ففي الغالب يمكن التعامل مع فاتورة FatturaPA واحدة بسهولة. لكن الصعوبة تظهر عندما يتعين عليك تجميع مستندات عدة أشهر، وموردين مختلفين، وحقول تم ملؤها بطرق غير موحدة، ومرفقات مدمجة.
في الشركات الصغيرة والمتوسطة الإيطالية، الحالة الأكثر شيوعًا ليست «الملف الضخم» المنفرد، بل «الدفعة». يمكن أن ينتج عن التصدير السنوي للفواتير المستلمة بنية تحتوي على أكثر من 380,000 عقدة موزعة على 4,200 فاتورة، تشمل العناوين، وبيانات التفاصيل، وبيانات الدفع، والمرفقات بتنسيق base64. في مثل هذه الحالات، لا تكمن المشكلة في فتح المستند، بل في تحويل ملفات XML غير المتجانسة إلى مجموعة بيانات متسقة.
وهنا يأتي دور خيار تقني له آثار على الجانب التجاري. في بيئة .NET، تشير مايكروسوفت إلى أن XmlDocument يقوم بتحميل المستند في الذاكرة وهو مفيد للقراءة والتعديل، بينما بالنسبة للملفات الكبيرة الحجم أو عمليات القراءة فقط، يُنصح باللجوء إلى أساليب أكثر كفاءة مثل محلل التدفق (parser streaming) أو XPathDocument، لتجنب الاستهلاك المفرط لذاكرة الوصول العشوائي (RAM)، كما هو موضح في وثائق مايكروسوفت حول قراءة XML باستخدام XmlDocument وXPathDocument.
بشكل عملي:
المفاضلة بسيطة. النموذج المخزّن في الذاكرة يتيح لك التطوير بسرعة أكبر. أما النموذج القائم على البث، فيُظهر أداءً أفضل في بيئة الإنتاج عندما يصبح عدد الملفات كبيرًا أو تزداد أحجامها.
تكتفي العديد من الفرق بالتحقق من صحة ملف XSD. وهذا أمر مفيد، لكنه لا يكفي. فقد يتوافق الملف مع المخطط، ومع ذلك ينتج بيانات غير صحيحة في المراحل اللاحقة.
أمثلة نموذجية من العمل الميداني:
| نوع الفحص | ما الذي يتم التحقق منه | لماذا نحتاج إليه |
|---|---|---|
| هيكلي | العلامات، التنسيق، التسلسل الهرمي | تجنب أخطاء التحليل النحوي |
| دلالي | التسقُّف المنطقي للبيانات | تجنب التحليلات الخاطئة |
| قيد التشغيل | وجود حقول مفيدة لإعداد التقارير | تجنب مجموعات البيانات غير القابلة للاستخدام |
الحالة الأكثر خداعًا هي التالية: «المبلغ الإجمالي للوثيقة» صالح من الناحية الشكلية ولكنه غير متسق مع مجموع الأسطر، ربما بسبب آليات التقريب المستخدمة في نظام إدارة المورد. أو رموز ضريبة القيمة المضافة المقبولة شكليًّا ولكنها غير متسقة مع طبيعة المعاملة.
قد يؤدي ملف صحيح من الناحية الشكلية إلى تشويه تقاريرك.
وهناك فخ آخر معروف في فواتير FatturaPA. تحتوي العلامة «DatiBeniServizi» على أوصاف حرة. فقد يظهر نفس التكلفة بعدة طرق مختلفة، بنصوص واضحة أو مختصرة أو غامضة. وإذا لم تقم بإجراء عملية توحيد، فإن أي تحليل حسب فئة الإنفاق يصبح غير موثوق.
ولهذا السبب، في العمليات الجادة، لا يمثل قراءة الملف سوى المستوى الأول. أما المستوى الثاني فهو دائمًا مجموعة من قواعد الاتساق والنظافة. فهناك يتم الحفاظ على جودة البيانات، وليس في أداة التحليل.
ملف XML الذي تمت قراءته بشكل صحيح لا يُعدّ بعد مجموعة بيانات مفيدة. إنه مجرد مستند منظم. ولإجراء التحليلات والمقارنات والتجميعات وإنشاء لوحات المعلومات، يتعين عليك في الغالب تحويله إلى تنسيق أسهل في المعالجة.
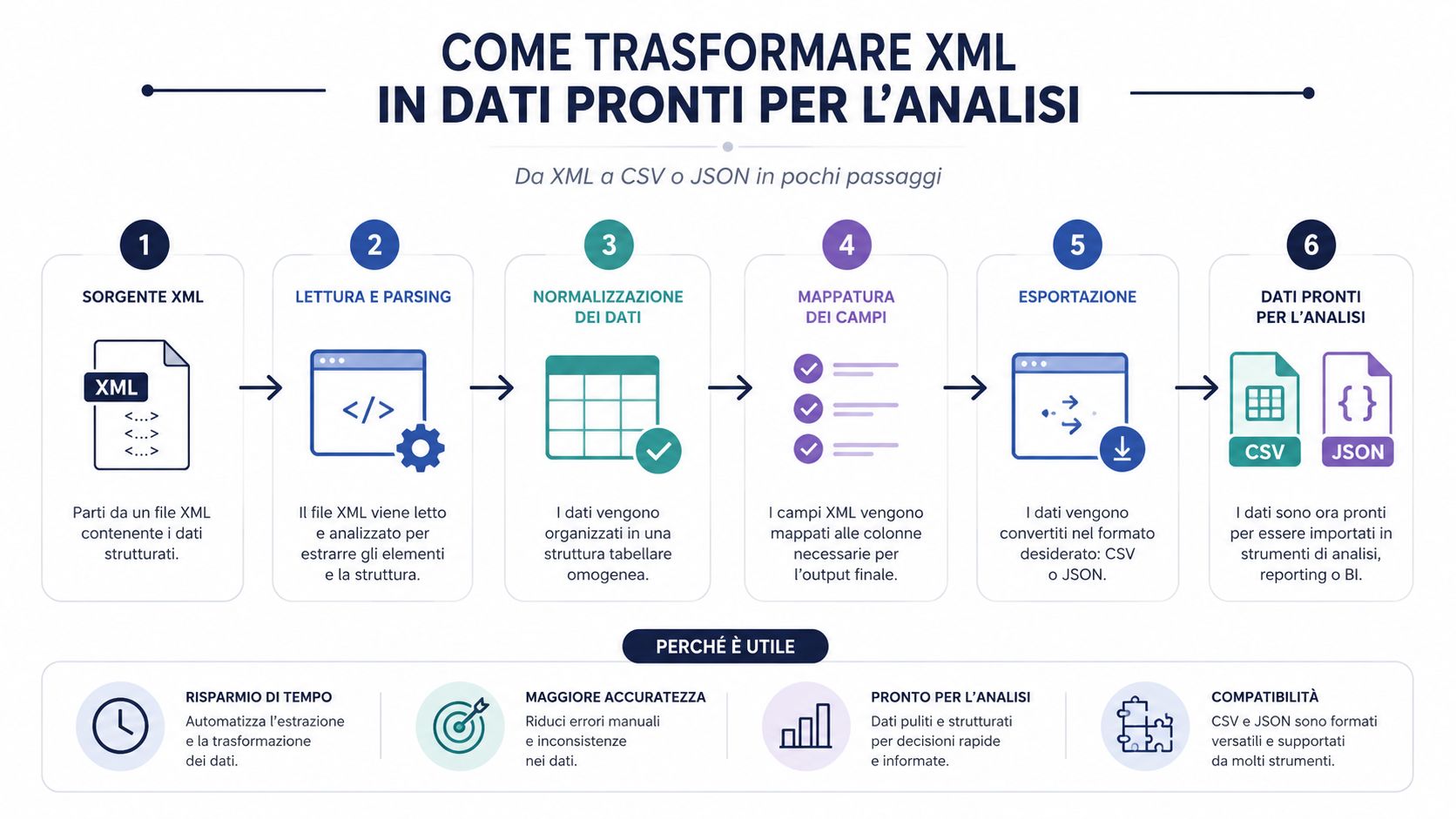
هذه هي النقطة التي يقلل الكثير من العمليات من أهميتها. فنقطة الاختناق نادراً ما تكمن في عملية التحليل النحوي بحد ذاتها. فالمكتبة الجيدة تقرأ ملفات XML بسرعة. أما الوقت فيُهدر في تفسير البنية، واستخراج الحقول المفيدة، وتنقية البيانات، وتوحيدها، وتحميلها إلى أداة تحليلية.
ولهذا السبب، فإن التحويل إلى CSV أو JSON ليس مجرد ميزة مريحة. بل هو خطوة تشغيلية أساسية. فإذا تخطيت هذه المرحلة وعملت مباشرةً على الملف الخام، فستنتهي في الغالب بإجراء عمليات تدقيق يدوية، وإنشاء أعمدة مرتجلة، واتباع منطق يصعب تكراره.
يُعد هذا الدليل مرجعًا مفيدًا لمن يعملون بشكل متكرر مع ملفات XML وجداول البيانات، حيث يشرح كيفية الانتقال من XML إلى Excel بطريقة أكثر تنظيماً.
يعتمد التنسيق المناسب على الطريقة التي ستستخدم بها البيانات لاحقًا.
يعمل CSV بشكل جيد عندما تريد سطراً واحداً لكل مستند، أو سطراً واحداً لكل تفصيل في الفاتورة، ثم استخدام Excel أو Power Query أو BI.
مثال بلغة بايثون:
استيراد xml.etree.ElementTree as ETimport csvtree = ET.parse("fattura.xml")root = tree.getroot()with open("fatture.csv", "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(["numero", "data"])numero = root.findtext(".//رقم")تاريخ = root.findtext(".//تاريخ")writer.writerow([رقم, تاريخ])الميزة هي البساطة. أما العيب فهو أنه عليك أن تقرر جيدًا كيفية تسوية التسلسل الهرمي. فإذا كانت الفاتورة تحتوي على عدة أسطر تفصيلية، فيجب اتخاذ قرار واضح بشأن مستوى التفصيل ومفتاح الربط.
يُعد JSON الخيار الأنسب عندما ترغب في الحفاظ على جزء من البنية الهرمية.
مثال على لغة جافا سكريبت:
const record = {numero: "123",data: "2024-01-15",righe: [{ descrizione: "Servizio", importo: "100.00" }]};console.log(JSON.stringify(record, null, 2));استخدمه عندما تكون الخطوة التالية هي واجهة برمجة تطبيقات (API) أو بحيرة بيانات أو تطبيق يعمل بشكل جيد مع الكائنات المتداخلة.
إليك قاعدة عملية مفيدة:
ملف XML هو الحاوية. أما CSV وJSON فهما التنسيقان اللذان يجعلان المحتوى قابلاً للمعالجة فعليًّا.
إذا كنت ترغب في تقليل «الوقت اللازم للحصول على الرؤى»، فهذا هو المجال الذي يجدر بك الاستثمار فيه بشكل منهجي. ليس في البحث عن أداة عرض أكثر سهولة، بل في تحديد عملية تحويل مستقرة وقابلة للتكرار.
بمجرد قراءة الملف والتحقق من صحته وتحويله، يتغير طابع العمل. لم تعد تعاني من مشكلة العلامات. بل أصبحت أخيرًا تفكر في التكاليف، والانحرافات، والموردين، وفئات الإنفاق، والاتجاهات التشغيلية.
في العمل الفعلي، لا تكمن القيمة في وقت التحليل. بل تكمن في الوقت الذي يفصل بين الملف الخام والمعلومات التي يمكنك اتخاذ قرار بناءً عليها. في حالة العمل اليدوي، يتعين على الشخص فتح المستند، وفهم هيكله، واستخراج الحقول، وتنقية القيم، وتوحيد النصوص، ثم إعداد التقارير. إنها عملية هشة.
من الأمثلة الكلاسيكية في نظام FatturaPA النص الحر في قسم «DatiBeniServizi». يمكن وصف الخدمة نفسها بعدة طرق مختلفة من قبل موردين مختلفين. وإذا قمت باستيراد تلك البيانات دون تخطيط متسق، فإن التحليل حسب فئة التكلفة سيؤدي إلى تجميعات غير مفيدة.
ولهذا السبب، قبل استخدام منصة التحليلات، يلزم وجود مرحلة تحضيرية، وذلك:
عندما يتم تنفيذ هذه المرحلة بشكل صحيح، تعمل أي منصة تحليلية بشكل أفضل. إذا كنت ترغب في التعمق في الجانب المتعلق باتخاذ القرار والجانب البصري لهذه الخطوة، فإن المورد الذي يتناول كيفية بناء القصص باستخدام البيانات مفيد لأنه يوضح كيف تتحول مجموعة البيانات المنظمة إلى سرد مفيد لصانعي القرار.
عند هذه النقطة، يتوقف ملف XML عن كونه مشكلة تقنية ليصبح مادة أولية لاستخلاص الرؤى. فمجموعة البيانات المُعدة جيدًا يمكن أن تُستخدم في تحليل النفقات، ومراقبة الاتجاهات، وكشف الانحرافات، وتقييم الحالات الاستثنائية.
لاختيار منصة مناسبة لهذه المرحلة الأخيرة، قد يساعدك مقارنة ما يقدمه برنامج تحليلات الأعمال الحديث مقارنةً بالعمليات اليدوية البحتة التي تعتمد على جداول البيانات والجداول المحورية.
المعيار الصحيح هنا ليس «هل يستطيع فتح ملف XML؟». فهذا هو الحد الأدنى. السؤال المهم هو آخر:
| سؤال | لماذا هذا مهم |
|---|---|
| تصل البيانات وهي منظمة بالفعل | تجنب استخلاص استنتاجات دقيقة من بيانات خاطئة |
| الفئات متسقة | هل تقارن فعلاً بين الموردين والفترات الزمنية؟ |
| تظهر الشذوذات على الفور | قلل الوقت الضائع في عمليات الفحص اليدوية |
| يمكن قراءة التقرير من قبل العاملين في مجالي الأعمال والمالية | تسريع عملية اتخاذ القرار |
لا يكمن الفرق بين العملية غير الناضجة والعملية الناضجة في القدرة على قراءة ملفات XML، بل في القدرة على تحويلها إلى قاعدة بيانات موثوقة، لا تجبر الفريق على إعادة القيام بنفس العمل في كل مرة.
إذا كنت بحاجة إلى قراءة ملفات XML بطريقة تفيد عملك، فضع هذه القائمة المرجعية في اعتبارك. فهي أكثر واقعية من أي تعريف تقني، وتساعدك على اختيار الطريقة الصحيحة دون إضاعة الوقت.
لا تستخدم دائمًا نفس النهج. تعد المتصفحات والمحررات وبرامج العرض خيارات جيدة لإجراء عمليات فحص سريعة. أما برامج تحليل البيانات والبرامج النصية فهي مفيدة عندما يتعين على الملف تغذية عمليات متكررة. إذا خلطت بين عرض البيانات ومعالجتها، فإنك تخاطر بإنشاء تقارير تستند إلى أسس هشة.
الملفات .xml.p7m تتطلب خطوة محددة لإدارة التوقيع. إذا كان المحتوى قادمًا من بريد إلكتروني معتمد (PEC)، فإن هذا الفحص ليس مجرد إجراء ثانوي. إنه جزء من القراءة الصحيحة للوثيقة.
لا يضمن الالتزام بنموذج معين وجود مجموعة بيانات سليمة. فالتناقضات المنطقية، مثل المجاميع غير المتوافقة أو التصنيفات الضريبية الغامضة، هي التي غالبًا ما تفسد التحليل. والتدقيق الدلالي هو ما يميز الملف «المقبول» عن البيانات الموثوقة.
لا يُعد CSV و JSON مجرد خطوة شكلية. بل هما النقطة التي يصبح عندها XML قابلاً للمعالجة بواسطة أدوات التحليلات وجداول البيانات ومسارات البيانات والتقارير. فكلما أسرعت في تحديد هذا التحويل، كلما قللت من العمل اليدوي والارتجال.
هدفك ليس قراءة ملفات XML. بل هو الحصول على رؤى مفيدة دون إثقال النظام ببيانات غير دقيقة. إذا لم ينتج عن التدفق مجموعة بيانات متسقة، فإن المشكلة لا تكمن في لوحة المعلومات النهائية. بل تكمن في مرحلة أبعد من ذلك بكثير.
عمليًّا، يمكنك استخدام قائمة المراجعة الموجزة هذه قبل البدء في أي مشروع جديد:
إذا كنت ترغب في تحويل البيانات المعدة مسبقًا إلى رؤى واضحة وقابلة للتنفيذ، فإن ELECTE تساعد الشركات الصغيرة والمتوسطة على الانتقال من مجموعة البيانات المنظمة إلى إعداد التقارير الذكية، من خلال نهج يسهل على الفرق غير التقنية استخدامه. إنها أسرع طريقة لتقليص الفجوة بين البيانات التشغيلية وعملية اتخاذ القرار.

.svg)
.svg)
.svg)
.webp)





