

بياناتك تروي قصة بالفعل. المشكلة هي أنها غالبًا ما تكون خافتة جدًّا.
تجمع الشركات الصغيرة والمتوسطة يومياً تعليقات العملاء والطلبات وتذاكر الدعم والتحركات المالية والرسائل الإلكترونية التجارية وملاحظات نظام إدارة علاقات العملاء. وتحتوي كل هذه البيانات على مؤشرات مفيدة. فبعضها يشير إلى عميل على وشك الانسحاب، وبعضها الآخر ينذر بمخاطر تشغيلية، بينما يوضح البعض الآخر المنتجات التي ستشهد نمواً أو تباطؤاً. لكن بدون منهجية واضحة، تظل هذه المؤشرات مجرد ضوضاء.
من بين الخوارزميات التي تساعد على إحلال النظام في هذا الفوضى، تحتل المصنفات البايزية الساذجة مكانة خاصة. فهي سهلة الفهم من الناحية المنطقية، وسريعة التدريب، وغالبًا ما تكون أكثر فعالية مما يوحي به اسمها «الساذجة». وهي ليست الخيار الأمثل لكل السيناريوهات، لكنها توفر في العديد من المشكلات التجارية الواقعية توازنًا نادرًا بين السرعة وقابلية التفسير والنتائج المفيدة.
إذا كنت تعمل في مجال الأعمال، فلا داعي لأن تصبح باحثًا لفهمها. ما تحتاج إليه هو معرفة ما تفعله هذه النماذج، ولماذا تنجح حتى عندما تبسط الواقع إلى حد كبير، وفي أي الحالات يمكن أن تساعدك على اتخاذ قرارات أفضل. وهنا بالذات يستحق الأمر التوقف قليلاً.
تبحث العديد من الشركات عن نماذج معقدة، في حين أن المشكلة تتطلب، في المقام الأول، نموذجًا موثوقًا وسهل الاستخدام. وهذا هو السبب نفسه الذي يجعل العملية الأكثر وضوحًا، وليس الأكثر أناقة من الناحية النظرية، هي التي تفوز غالبًا في مجالات مثل المالية أو تجارة التجزئة أو خدمة العملاء.
تنطلق المصنفات البايزية البسيطة من فكرة ملموسة للغاية. فإذا كانت لديك بعض الدلائل حول حالة جديدة، يمكنك تقدير الفئة التي تنتمي إليها بتحمل كبير. فإذا احتوت رسالة بريد إلكتروني على كلمات معينة، فقد تكون رسالة غير مرغوب فيها. وإذا اتسمت معاملة ما بأنماط معينة، فقد تستدعي المراجعة. وإذا استخدمت مراجعة ما مصطلحات معينة، فقد تشير إلى الرضا أو عدم الرضا.
تثير كلمة «بايزي» في الذهن صورًا عن معادلات معقدة. لكن جوهر هذه الطريقة هو في الواقع بديهي. فأنت تأخذ ما تعرفه بالفعل، وتضيف إليه أدلة جديدة، ثم تُحدِّث رأيك. إنها طريقة منظمة للتفكير في ظل حالة من عدم اليقين، وهو بالضبط ما يفعله المديرون يوميًا، إلا أن الخوارزمية تجعله عملية منهجية.
المثير للدهشة هو أن هذا النهج لا يزال يعمل بشكل جيد حتى في البيئات الحديثة، التي تتسم بوفرة البيانات وسرعة اتخاذ القرارات. ليس لأنه يصف العالم بشكل مثالي، بل لأنه يفصل الإشارة المفيدة عن الضوضاء بتكلفة حسابية منخفضة للغاية.
في المشكلات التجارية، السؤال الصحيح ليس «ما هو النموذج الأكثر دقة؟»، بل «أي نموذج يوفر لي قرارات موثوقة في أوقات تتناسب مع واقع العمل؟».
ولهذا السبب تظل المصنفات البايزية البسيطة مهمة. فهي تساعدك على التصنيف والتصفية والتقسيم وتحديد الأولويات. كما أنها تتيح لك إدخال عنصر الاحتمالية في عملية اتخاذ القرار دون تحويل كل مشروع إلى مشروع تقني معقد.
المبدأ الأساسي هو نظرية بايز. وبصورة مبسطة، فإنها تنص على ما يلي: تبدأ باحتمال أولي، ثم تقوم بتحديثه عند ورود معلومات جديدة.
في لغة البيانات، تُقرأ الصيغة على النحو التالي: P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y). وهذا يعني أن احتمال انتماء فئة ما، في ضوء مجموعة من الإشارات، يعتمد على عنصرين. الأول هو الاحتمال الأولي لتلك الفئة. والثاني هو مدى توافق كل إشارة مع تلك الفئة.
لنأخذ مثالاً من عالم الأعمال. عليك أن تحدد ما إذا كانت رسالة بريد إلكتروني ما هي بريد مزعج أم لا. لديك احتمال عام بأن تكون الرسالة الواردة بريدًا مزعجًا. ثم تلاحظ بعض الكلمات مثل «عرض»، «مجاني»، «انقر هنا». كل كلمة من هذه الكلمات تؤثر على الحكم النهائي.
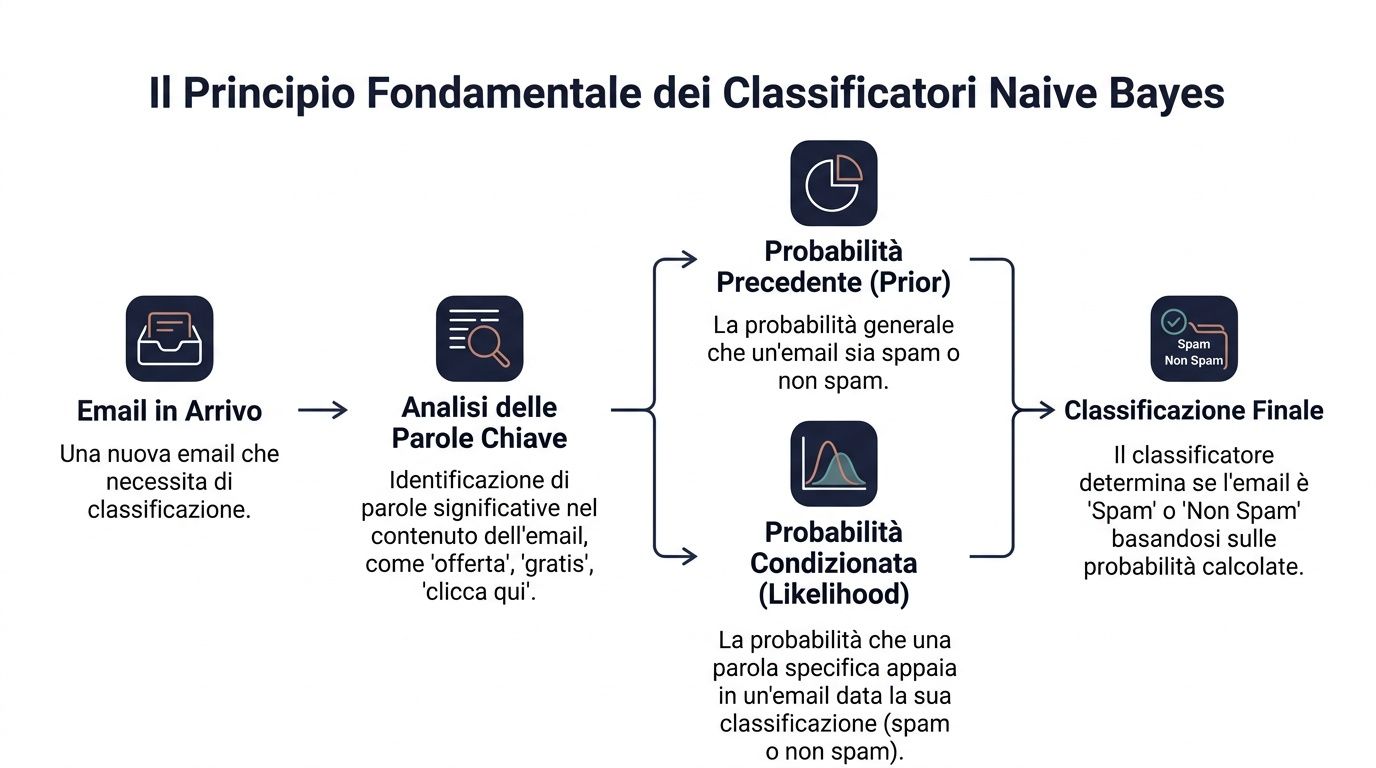
يقوم المدير بأمر مشابه كل يوم. فهو لا يتخذ قراراته من فراغ أبدًا. بل ينطلق من سياق أساسي ويضيف إليه مؤشرات. فالعميل الذي كان يشتري بانتظام دائمًا يتمتع بملف تعريفي أولي معين. أما إذا توقف عن فتح رسائل البريد الإلكتروني، وخفض قيمة طلباته، وفتح تذكرة دعم فنية حاسمة، فإن تقييمك له يتغير.
يشير مصطلح "نايف" إلى افتراض محدد. يعامل النموذج السمات كما لو كانت مستقلة عن بعضها البعض، نظراً لأن الفئة معروفة.
بشكل عملي، إذا كنت تقوم بتصنيف رسالة بريد إلكتروني، فاعتبر كل كلمة بمثابة دليل منفصل. لا تحاول تحديد جميع العلاقات المعقدة بين المصطلحات. فهذا تبسيط شديد. في الواقع، تظهر العديد من الكلمات معًا، كما أن العديد من السلوكيات المؤسسية مترابطة.
ومع ذلك، فإن هذا الاختيار بالذات هو ما يجعل النموذج خفيفًا للغاية. فهو لا يحتاج إلى تعلم شبكة معقدة من التبعيات. بل عليه تقدير احتمالات أبسط ودمجها بكفاءة.
قاعدة عملية: لا يحاول نموذج نايف بايز إعادة بناء العالم بأسره. بل يسعى إلى اتخاذ قرارات مفيدة بناءً على عدد قليل من الافتراضات وبسرعة كبيرة.
هنا غالبًا ما ينشأ سوء الفهم. فالكثيرون يقرؤون عبارة «افتراض ساذج» ويستنتجون منها «نموذج ضعيف». لكن الأمر ليس كذلك. فمن الممكن أن يبسط النموذج الأمور إلى حد كبير ويظل فعالاً إذا كان هذا التبسيط يركز على ما يهم في عملية اتخاذ القرار.
في عام 2004، أظهر تحليل نظري أسبابًا قوية تفسر فعالية مصنفات نايف بايز (Naive Bayes) على الرغم من افتراض الاستقلالية، كما أوضح أيضًا سبب قدرتها على الوصول إلى الخطأ اللانهائي بشكل أسرع من الانحدار اللوجستي. وفي نفس مجال التطبيقات، تحقق هذه المصنفات دقة تزيد عن 99٪ في تصفية الرسائل غير المرغوب فيها، كما يمكنها معالجة ملايين الوثائق، وفقًا لما ورد في المقالة المخصصة لمصنفات نايف بايز.
هذه النقطة مهمة بالنسبة للجمهور من الشركات. فقيمة الخوارزمية لا تكمن فقط في النتيجة النهائية، بل تكمن أيضًا في قدرتها على التعلم بسرعة، والتكيف مع مجموعات البيانات الضخمة، والحفاظ على قابليتها للتفسير.
عندما تكون النصوص أو الفئات أو العلامات أو الإشارات متفرقة، تعمل المصنفات البايزية البسيطة بشكل جيد للأسباب التالية:
لكن هناك نقطتان يجب أخذهما في الاعتبار.
ولهذا السبب، ينبغي النظر إلى نموذج Naive Bayes باعتباره أداة فعالة للغاية في مشكلات التصنيف السريعة، وليس كعصا سحرية شاملة. ومع ذلك، فهو في العديد من السياقات العملية أحد أكثر الطرق ذكاءً للبدء.
من الأخطاء الشائعة الحديث عن نموذج Naive Bayes وكأنه نموذج واحد متطابق في كل الحالات. في الواقع، هناك أنواع مختلفة منه، مصممة لتناسب أنواع مختلفة من البيانات.
يعتمد الاختيار الصحيح على شكل البيانات المتوفرة لديك. إذا اخترت المتغير الخاطئ، فقد ينتج النموذج توقعاتً مع ذلك، لكنه لن يعمل بالطريقة الأنسب لمشكلتك.
يُعد نموذج «Gaussian Naive Bayes» الخيار الأنسب عندما تكون السمات متصلة. فكر مثلاً في متوسط قيمة المعاملة، أو عمر العميل، أو متوسط الفترة الزمنية بين عمليتي شراء، أو الهامش الوحدوي، أو قيمة الفاتورة.
يفترض النموذج هنا أن القيم، داخل كل فئة، تتبع توزيعًا غاوسيًا. لا يجب أن تعتبر ذلك قيدًا نظريًا. يكفي أن تتذكر الفكرة العملية: بالنسبة لكل فئة، يقدّر النموذج مركزًا نموذجيًا وانحرافًا معياريًا.
هذا النهج مفيد عندما تريد تصنيف حالات مثل:
في اختبار أداء scikit-learn باستخدام مجموعة بيانات مشابهة لبيانات التجارة الإلكترونية الإيطالية، حقق نموذج Naive Bayes دقة بنسبة 95% باستخدام 1000 عينة، مع وقت تدريب أسرع بنسبة 15% مقارنة بالانحدار اللوجستي . المقارنة المشار إليها هي 0.01 ثانية مقابل 0.1 ثانية على وحدة المعالجة المركزية القياسية، بفضل التدريب في شكل مغلق، كما هو موضح في فصل جيك فاندربلاس حول التصنيف الساذج لبايز المتعمق.
بالنسبة للشركة، لا يهم الرقم العشري. المهم هو أن هذا الإصدار يمكن أن يحقق نتائج جيدة دون الحاجة إلى فترات تدريب طويلة ودون الحاجة إلى بنية تحتية معقدة.
إذا كنت تعمل مع النصوص أو التذاكر أو المراجعات أو التعليقات، فغالباً ما يكون نموذج «Multinomial Naive Bayes» هو الخيار الطبيعي. وفي هذه الحالة، تكون السمات عبارة عن أعداد أو تكرارات. وبشكل عملي، يراقب النموذج عدد المرات التي تظهر فيها الكلمات أو المصطلحات.
إنه السيناريو الكلاسيكي لـ:
السبب وراء نجاحها واضح جدًا. ففي النصوص المؤسسية، قد يكون نطاق المفردات واسعًا، لكن كل وثيقة لا تحتوي إلا على جزء صغير من الكلمات الممكنة. فالمعلومات موزعة بشكل متفرق. ويُجيد نموذج «Multinomial Naive Bayes» التعامل مع هذا النوع من البنية بالذات.
في دراسة شملت 100,000 تغريدة إيطالية مصنفة حسب المشاعر، حقق نموذج «Multinomial Naive Bayes» معدل F1 يبلغ 0.88 مع سرعة أعلى بـ 10 أضعاف مقارنةً بـ SVM، كما ورد في دليل GeeksforGeeks حول مصنفات Naive Bayes.
لتتذكر ذلك بسهولة، فكر في الأمر على النحو التالي: إذا كانت بياناتك تشبه وثيقة مليئة بكلمات معدودة، فإن الدالة المتعددة الحدود تكون في الغالب الخيار الأول الذي يجب اختباره.
إذا كانت شركتك بحاجة إلى قراءة كميات كبيرة من النصوص، فإن السؤال لا يقتصر على «ما مدى دقة النموذج؟»، بل يشمل أيضًا «كم عدد الطلبات التي يمكنه تصنيفها دون إبطاء عمل الفريق؟».
يعمل نموذج «برنولي نايف بايز» مع السمات الثنائية. فهو لا يأخذ في الاعتبار عدد مرات ظهور الإشارة، بل يكتفي بتحديد ما إذا كانت موجودة أم غائبة.
يُعد هذا النوع مفيدًا عندما يكون وجود السمة أكثر أهمية من تكرارها. وفيما يلي بعض الأمثلة من عالم الأعمال:
هذه طريقة منطقية مفيدة جدًا عندما تريد تحويل الظواهر المعقدة إلى مؤشرات "نعم/لا" يسهل رصدها. ففي تحليل المشاعر، على سبيل المثال، قد يكون ظهور كلمة سلبية أكثر أهمية من عدد مرات تكرارها.
إن توزيع برنولي ليس «أقل تطوراً» من التوزيع متعدد الحدود. إنه ببساطة أكثر ملاءمةً عندما تصف البيانات وجوداً أو غياباً. الفرق بسيط في الكلمات، لكنه كبير في النتائج.
| نسخة | نوع البيانات المثالي | مثال على حالة استخدام مؤسسية |
|---|---|---|
| غاوس نايف بايز | بيانات متواصلة | تصنيف المعاملات حسب المخاطر باستخدام المبالغ والتكرار والقيم المتوسطة |
| نموذج نايف بايز متعدد الحدود | النصوص، الحسابات، التكرارات | تحليل تعليقات العملاء وتذاكر الدعم حسب الرأي العام أو الفئة |
| برنولي نايف بايز | البيانات الثنائية، التواجد/الغياب | تقييم الإشارات بنعم/لا فيما يتعلق بالامتثال أو الدعم أو استخدام المنتج |
لاختيار الخيار الصحيح، اتبع قاعدة بسيطة:
تتعثر العديد من الفرق لأنها تبحث عن النموذج «الأفضل» على الإطلاق. والاختيار الصحيح، في الغالب، هو النموذج الأكثر توافقاً مع نوع البيانات.
الخبر السار هو أن تطبيق نموذج نايف بايز عمليًا لا يتطلب مشروعًا ضخمًا. فحتى النموذج الأولي البسيط يكفي لفهم كيفية عمل النموذج والبيانات التي يحتاجها.

يتم إنشاء المصنف في الغالب من خلال أربع خطوات.
تحضير البيانات
عليك جمع أمثلة تاريخية مصنفة مسبقًا. إذا كنت تقوم بتصنيف التعليقات، فستحتاج إلى نصوص تم تصنيفها مسبقًا على أنها إيجابية أو سلبية. وإذا كنت تقوم بتحليل المخاطر التشغيلية، فستحتاج إلى حالات سابقة ذات نتائج معروفة.
تدريب النموذج
يقوم النموذج بدراسة البيانات وتقدير الاحتمالات المفيدة. في المصنفات البايزية البسيطة، تكون هذه الخطوة سريعة لأن التدريب لا يتطلب عمليات تحسين معقدة بشكل خاص.
توقعات بشأن الحالات الجديدة
أدخل سجلات جديدة وسيقوم النموذج بتصنيفها. على سبيل المثال: "بريد مزعج"، "ليس بريدًا مزعجًا"، "عميل معرض للخطر"، "عميل مستقر".
تقييم "
": قارن التوقعات بالواقع على مجموعة اختبارات منفصلة. هنا لا تكتفي بمجرد التحقق من صحة عمل النموذج، بل تراقب أيضًا كيفية ارتكابه للأخطاء.
إذا كنت ترغب في التعمق في الصورة العامة للنهج التنبؤية، فإن هذه النظرة العامة على خوارزميات التعلم الآلي تساعد في وضع نموذج Naive Bayes ضمن مجموعة أوسع من الأساليب.
ولتوضيح هذه العملية بشكل عملي، إليك مثال بسيط باستخدام scikit-learn. لا داعي لقراءته كأنك مطور. يكفي أن تفهم سير العملية.
# نستورد الأدوات الأساسيةfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# نقوم بتحميل مجموعة بيانات نموذجيةX, y = load_iris(return_X_y=True)# نقسم البيانات إلى جزء للتدريب وجزء للاختبار X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# نقوم بإنشاء النموذج model = GaussianNB()# نقوم بتدريب النموذج على البيانات التاريخية model.fit(X_train, y_train)# نقوم بعمل تنبؤات على بيانات لم نرها من قبل y_pred = model.predict(X_test)# نقيس الدقة print(accuracy_score(y_test, y_pred))هذا المقتطف يقول أكثر بكثير مما يبدو عليه.
GaussianNB() اختر الخيار الخاص بالبيانات المستمرة.fit() هذه هي اللحظة التي يتعلم فيها النموذج.predict() يطبق ما تعلمه.accuracy_score() تحقق من عدد التصنيفات الصحيحة بشكل عام.بالنسبة للبيانات النصية، يظل المسار مشابهًا، لكن قبل استخدام النموذج، يجب تحويل النص إلى أرقام. وبشكل عملي، يتم تحويل الكلمات إلى سمات يمكن لمصنف استخدامها.
بعد إلقاء نظرة أولية على الكود، قد يكون من المفيد الاطلاع على شرح مرئي لهذه الآلية.
لا يهدف النموذج الأول إلى إثبات الكمال. بل يهدف إلى الإجابة على ثلاثة أسئلة عملية.
هنا تظهر قوة نموذج Naive Bayes. يمكنك الوصول بسرعة إلى أساس قوي. ومن هناك، يمكنك معرفة ما إذا كان من المنطقي تعقيد المشروع أم أن الحل البسيط يضيف قيمة بالفعل.
لا يُقيَّم نموذج التصنيف فقط بناءً على أنه «يبدو أنه يعمل». بل يُقيَّم بناءً على كيفية ارتكابه للأخطاء ومدى تأثير تلك الأخطاء على الأعمال.

تعدالدقة المقياس الأكثر بديهية. فهي تُبيّن عدد التوقعات الصحيحة مقارنةً بالإجمالي. وهي مفيدة، لكنها قد تكون خادعة إذا اعتمدنا عليها وحدها.
إذا كانت هناك بضع معاملات مشبوهة فقط من بين مائة معاملة، فإن النموذج الذي يصنف كل شيء تقريبًا على أنه طبيعي قد يبدو جيدًا من حيث الدقة، لكنه يظل ضعيفًا في المجالات التي تحتاج إليه حقًا.
لفهم ذلك، تخيل شبكة صيد.
في عالم الأعمال، هذا التمييز مهم للغاية.
النموذج الجيد ليس هو الذي يخطئ قليلاً بشكل عام، بل هو الذي يخطئ بطريقة أقل تكلفة على عمليتك.
لفهم كيفية تعلم الخوارزمية من البيانات التاريخية بشكل أفضل، ولماذا تؤثر جودة التدريب على النتيجة النهائية، يمكنك قراءة هذا المقال التفصيلي حول ماهية تدريب الخوارزمية.
طريقة نايف بايز بسيطة، لكنها لا تتسامح مع بعض الأخطاء العملية.
الخطأ الأول: تجاهل مشكلة التردد الصفري.
إذا لم تظهر كلمة أو قيمة ما مطلقًا في بيانات التدريب الخاصة بفئة معينة، فقد تنخفض الاحتمالية إلى الصفر وتؤثر سلبًا على الحساب. ولهذا السبب، غالبًا ما يُستخدم تسوية لابلاس، التي تضيف تصحيحًا بسيطًا إلى الأعداد.
الخطأ الثاني: استخدام متغيرات مرتبطة ارتباطًا وثيقًا.
إذا كانت عمودان يقدمان تقريبًا نفس المعلومات، فإن النموذج قد يبالغ في تقدير الإشارة. فهو لا «يدرك» أن هذين المؤشرين متطابقان تقريبًا.
الخطأ الثالث: الإفراط في الاعتماد على الاحتمالات الأولية.
غالبًا ما يقدم نموذج Naive Bayes تصنيفًا جيدًا، لكن احتمالاته قد تكون مفرطة في الثقة. بالنسبة للأعمال التجارية، يعني هذا أن التصنيف قد يكون مفيدًا، في حين يجب تفسير القيمة الدقيقة للاحتمال بحذر.
للحد من هذه المخاطر، يُنصح بما يلي:
تتجلى القيمة الحقيقية لمصنفات بايزية الساذجة عندما تتوقف عن اعتبارها مجرد تمرين رياضي وتبدأ في استخدامها كأداة لتحديد الأولويات. ففي عالم الأعمال، يعني التصنيف الجيد في الغالب اتخاذ قرارات أفضل.

تخيل فريقًا ماليًا يقوم بتحليل تدفقات المعاملات والأوصاف التشغيلية والإشارات التاريخية. فكل سطر ليس مجرد سجل؛ بل هو قرار محتمل: إما السماح بالمرور، أو التعمق في الأمر، أو حظره، أو إحالته إلى أحد المحللين.
باستخدام نموذج Naive Bayes، يمكنك الجمع بين مؤشرات مختلفة في تصنيف واحد. بعضها رقمي، وبعضها ثنائي، وبعضها نصي. يساعد النموذج في تحديد الحالات التي تشبه إلى حد كبير الأنماط التي سبق ملاحظتها، سواء كانت طبيعية أو شاذة.
الفائدة العملية مزدوجة:
إنه لا يحل محل التقدير البشري في السياقات الخاضعة للأنظمة. بل ينظمه. وفي العمليات التشغيلية ذات الحجم الكبير، يُحدث هذا فرقاً حقيقياً.
في مجال التسويق، غالبًا ما يعني التصنيف تصنيف كل عميل ضمن فئة معينة. العملاء المخلصون. العملاء الحساسون للأسعار. العملاء المعرضون لخطر الانسحاب. العملاء المستجيبون للعروض الترويجية. العملاء الخاملون.
هنا، يُعد نموذج نايف بايز مفيدًا لأنه قادر على دمج الإشارات المتنوعة بسرعة:
لا يحتاج فريق إدارة علاقات العملاء (CRM) إلى نظرية مثالية عن السلوك البشري. بل يحتاج إلى تصنيف جيد بما يكفي لاتخاذ إجراءات منطقية. على سبيل المثال، تغيير الرسالة أو وتيرة الاتصال أو نوع العرض.
عندما يساعد النموذج في اختيار الرسالة التالية للعميل المناسب، فإنه يكون قد بدأ بالفعل في تحقيق قيمة تشغيلية.
في قطاعي البيع بالتجزئة والتجارة الإلكترونية، يدعم التصنيف أنشطة تبدو مختلفة لكنها تشترك في نفس المنطق: تنظيم الفوضى.
يمكنك تصنيف المنتجات وفقًا لبيانات مبيعاتها. يمكنك قراءة التعليقات والتذاكر لفهم الفئات التي تسبب مشاكل. يمكنك تحديد أنماط الطلب التي تساعد الفريق على التخطيط للعروض الترويجية والمخزون بشكل أكثر دقة.
في هذا النوع من البيئات، غالبًا ما تكون البيانات كثيرة ومتنوعة وليست دائمًا دقيقة. ولهذا السبب، فإن وجود نموذج سريع وقابل للتوسع وسهل الفهم له قيمة كبيرة. ليس لأنه الأكثر جاذبية، بل لأنه يندمج في سير العمل دون إبطائه.
إذا كنت ترغب في معرفة كيف تتجسد مناهج التحليلات المطبقة على الأعمال في مشاريع ملموسة، يمكنك الاطلاع على هذه الدراسات الإفرادية.
من المفيد فهم نموذج نايف بايز. أما تطبيقه بشكل صحيح في سياق الأعمال، فهذه قصة أخرى.
المشكلة لا تكمن أبدًا في الخوارزمية وحدها. فالعمل الحقيقي يتمحور حول النموذج. عليك ربط مصادر البيانات المختلفة، وإدارة الحقول الناقصة، وإعداد النصوص، وتحديث العلامات، والتحقق من جودة المخرجات، وتفسير النتائج بطريقة مفهومة لصانعي القرار.
بالنسبة للشركات الصغيرة والمتوسطة، غالبًا ما يمثل هذا الانتقال نقطة حرجة. ليس بسبب عدم الاهتمام بالذكاء الاصطناعي، بل لأن وقت الفريق محدود والأولويات التشغيلية لا تنتظر.
من المنطقي هنا استخدام منصة تتولى التعامل مع التعقيدات التقنية. تتيح الحلول المدعومة بالذكاء الاصطناعي تحويل البيانات الأولية إلى رؤى واضحة دون الحاجة إلى أن تقوم الشركة بكتابة الأكواد البرمجية أو اختيار المكتبات البرمجية أو صيانة مسارات البيانات يدويًّا.
منصة مثل ELECTE وهي منصة لتحليل البيانات مدعومة بالذكاء الاصطناعي مخصصة للشركات الصغيرة والمتوسطة، تتيح استخدام أساليب مثل المصنفات البايزية البسيطة دون الحاجة إلى خبرات متخصصة في التعلم الآلي. ولا تكمن الميزة في السرعة فحسب، بل في تقليل العوائق بين البيانات واتخاذ القرار.
عندما تعمل الأتمتة بشكل جيد، لا يفكر الفريق بعد ذلك من منظور الصيغ. بل يفكر من منظور الأسئلة المفيدة:
وهذا هو السبب الذي يدفع المزيد والمزيد من الشركات إلى البحث عن أدوات تساعدها في تقييم موثوقية المحتوى الذي تولده الذكاء الاصطناعي والإشارات النصية المتداولة في العمليات الداخلية. وفي هذا السياق، قد يكون من المفيد أيضًا الرجوع إلى دليل حول أداة الكشف عن الذكاء الاصطناعي باللغة الإيطالية، خاصةً إذا كان فريقك يعمل على المستندات والمحتوى والتدقيق اللغوي.
الفرق، عملياً، بسيط. فبدلاً من التعامل مع خطوات تقنية مجزأة، تركز على النتيجة التي تحققها الشركة. وهنا تكمن أهمية الذكاء الاصطناعي، حيث يصبح قابلاً للتطبيق فعلياً، وليس مجرد أمر مثير للاهتمام.
تُعلّمنا مصنفات بايز الساذجة درساً مهماً. ففي مجال التحليلات، يمكن للبساطة المطبقة بشكل جيد أن تتفوق على التعقيد الذي يُدار بشكل سيئ.
بفضل أساسه الاحتمالي البديهي، وقدرته الجيدة على التوسع، وحالات الاستخدام الملموسة للغاية، يظل هذا النهج أداة موثوقة للشركات التي ترغب في تصنيف المعلومات، وقراءة الإشارات الخفية، والتصرف بثقة أكبر. ولا داعي لأن تكون متخصصًا في التعلم الآلي لفهم قيمته. بل ما عليك سوى ربط الرياضيات بالقرار التشغيلي.
عندما يتضح هذا الارتباط، تتوقف الذكاء الاصطناعي عن كونها مسألة تقنية وتصبح ميزة تنظيمية. وهنا تبدأ التنبؤات في إحداث تأثير.
إذا كنت ترغب في تحويل البيانات المتفرقة إلى رؤى واضحة، فجرب ELECTE. تساعد هذه المنصة الشركات الصغيرة والمتوسطة على ربط مصادر البيانات وأتمتة التحليلات والحصول على تقارير وتوقعات مفيدة لاتخاذ قرارات أسرع وأكثر استنارة.

.svg)
.svg)
.svg)






