

Du kennst diese Situation sicher: Du hast ein Verwaltungssystem, vielleicht ein CRM, ein paar Excel-Dateien, die per E-Mail hin- und hergeschickt werden, und dann sagt dir jemand, dass du dich für „seriöse Analysen“ zwischen Data Lake und Data Warehouse entscheiden musst. In diesem Moment dreht sich das Gespräch sofort um die Technologie, aber das eigentliche Problem ist ein anderes. Brauchst du wirklich eine neue Datenarchitektur, oder musst du einfach nur die Daten, die du bereits hast, lesbar und nutzbar machen?
Für ein KMU ist diese Unterscheidung wichtiger als die Terminologie. Die falsche Wahl führt nicht nur zu technischer Komplexität. Sie führt zu langwierigen Projekten, Abhängigkeit von Beratern, verspäteten Berichten und Investitionen, die sich nur schwer in bessere Entscheidungen umsetzen lassen. Die Entscheidung, nichts zu tun, lässt das Unternehmen jedoch auf Sicht navigieren.
Es geht nicht darum, die Fachsprache der Anbieter zu lernen. Es geht darum, zu verstehen, welche Lösung zu deinem Unternehmen, deinem Budget und den Kompetenzen passt, über die du tatsächlich verfügst. Hier findest du einen praktischen Leitfaden, um die Debatte „Data Lake vs. Data Warehouse“ aus der Perspektive derjenigen zu betrachten, die Kosten, Zugänglichkeit und operativen Ertrag unter einen Hut bringen müssen.
Der Druck, „etwas mit den Daten anzufangen“, ist heute sehr groß. Die Zahlen steigen, die Quellen vermehren sich, und die Führungskräfte verlangen schnellere Prognosen, Dashboards und Benachrichtigungen. Gleichzeitig tauchen Begriffe auf, die einen zu einer sofortigen architektonischen Entscheidung zu zwingen scheinen.
Für viele KMU liegt die Falle jedoch genau hier. Man redet ihnen ein, der erste Schritt bestehe darin, sich zwischen zwei Infrastrukturmodellen zu entscheiden, obwohl das eigentliche Problem oft viel konkreter ist: verstreute Daten, uneinheitliche Formate, manuelle Berichte und niemand, der Zeit hat, Ordnung zu schaffen.
Es gibt andere Fragen, die wichtiger sind. Hast du wirklich ein Problem mit der Architektur? Oder hast du ein Problem mit dem Zugriff auf die Daten? Wenn du die falsche Lösung wählst, riskierst du, ein technisches Projekt zu finanzieren, anstatt die Kontrolle über das Geschäft zu verbessern. Wenn du dich für nichts entscheidest, triffst du weiterhin Entscheidungen auf der Grundlage unvollständiger Informationen.
Wer ein KMU leitet, braucht keine Vorlesung an der Universität. Er braucht ein einfaches Kriterium, um zu verstehen, was nötig ist, was nicht und wo die wahren Kosten liegen.
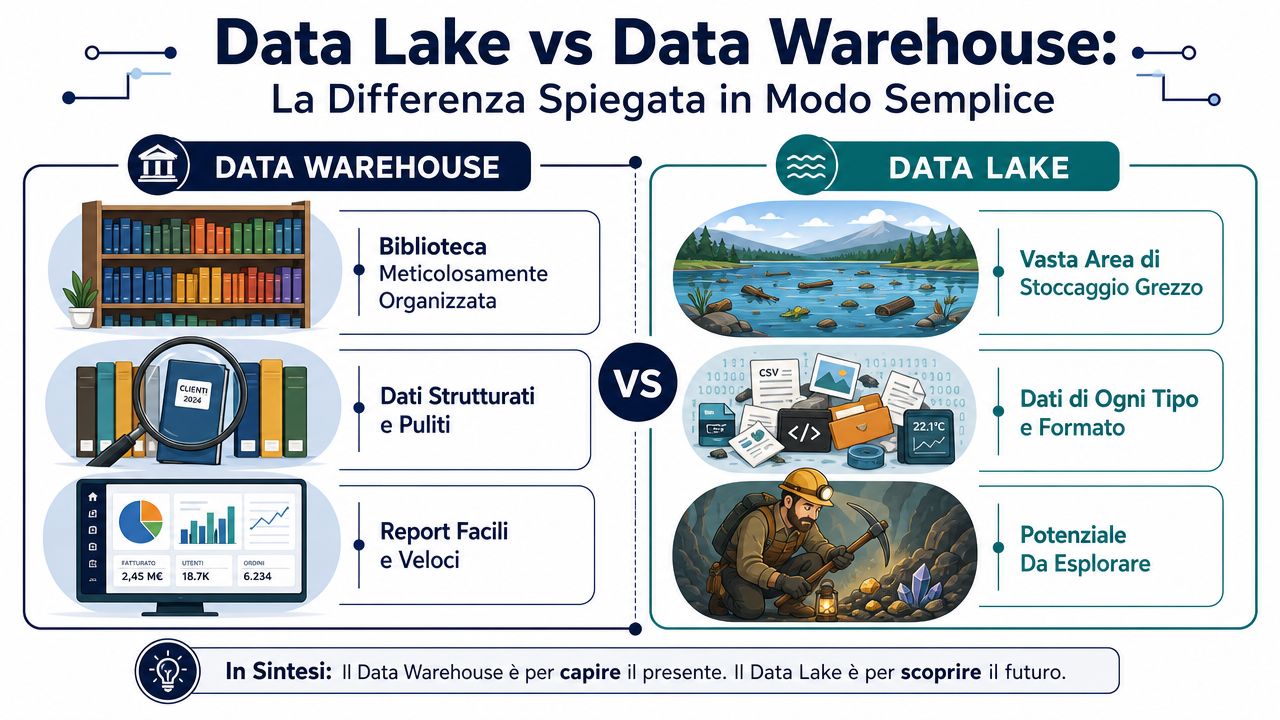
Am besten lässt sich der Unterschied anhand von zwei sehr anschaulichen Bildern verstehen.
Ein Data Warehouse gleicht einer gut organisierten Bibliothek. Jedes Buch wird bereits katalogisiert, klassifiziert und im richtigen Regal abgelegt. Wenn du nach einer Information suchst, findest du sie schnell, da die Ordnung bereits im Voraus festgelegt wurde. Ein Data Lake hingegen gleicht einem großen Lager, in dem Kisten aller Art ankommen. Man legt dort sortierte Dateien, Protokolle, PDFs, Bilder, Exporte aus dem Verwaltungssystem und Webdaten ab. Die Ordnung schafft man erst später, wenn man sie analysieren muss.
Hier kommt der einzige technische Aspekt ins Spiel, den es wirklich zu beachten gilt.
Diese Unterscheidung spiegelt auch ihren historischen Ursprung wider. Das Data Warehouse wurde für die Unternehmensanalyse bereits bereinigter und strukturierter Daten entwickelt, während der Data Lake später hinzukam, um Rohdaten in heterogenen Formaten zu speichern. Aus diesem Grund eignet sich das Warehouse besser für das Reporting und KPIs, während der Lake flexibler für die Datenexploration und das maschinelle Lernen ist, wie diese Analyse der Unterschiede zwischen Data Warehouse und Data Lake verdeutlicht.
Ein Data Warehouse eignet sich gut für bereits bekannte Abfragen. Ein Data Lake ist sinnvoll, wenn man weiß, dass die Daten wertvoll sein könnten, aber noch nicht weiß, in welcher Form.
Wenn du dich über Umsätze, Margen, Bestellungen, Lagerbestände, Verzögerungen, Vertriebsleistung und monatliche Vergleiche informieren möchtest, entspricht das Warehouse konzeptionell eher deinen Anforderungen. Es bietet dir eine zuverlässige Grundlage für Standardberichte, konsistente SQL-Abfragen und reproduzierbare Zahlen.
Wenn Sie hingegen mit sehr unterschiedlichen Daten arbeiten, wie beispielsweise Anwendungsprotokollen, PDF-Dateien, E-Mails, Texten, Bildern oder Maschinendaten, bietet der Data Lake mehr Flexibilität. IT-Teams können heterogene Datenquellen zentralisieren, während die für das Reporting zuständigen Mitarbeiter weiterhin strukturierte Umgebungen bevorzugen, um schnelle und konsistente Abfragen durchführen zu können. In diesen Zusammenhang fügt sich auch das umfassendere Thema der datengesteuerten Entscheidungen in Unternehmen ein, für die vor allem leicht zugängliche Daten und erst in zweiter Linie hochentwickelte Technologien erforderlich sind.
In der Debatte um Data Lake versus Data Warehouse verwechseln viele Flexibilität mit sofortigem Nutzen.
Ein Data Lake kann fast alles enthalten. Aber nur weil etwas gespeichert ist, heißt das noch lange nicht, dass es sofort analysierbar ist. Ein Data Warehouse ist bei der Dateneingabe weniger flexibel, aber nützlicher, wenn man schnelle und standardisierte Antworten benötigt. Für ein KMU ist dieser Unterschied wichtiger als die Theorie. Denn das Problem besteht nicht darin, mehr zu speichern, sondern bessere Entscheidungen zu treffen.
Zwei Unternehmen können mit denselben Ausgangsdaten zu sehr unterschiedlichen Ergebnissen kommen. Der Unterschied liegt oft nicht in der Menge der gesammelten Daten, sondern darin, wie sie diese organisieren, aufbereiten und den Entscheidungsträgern zugänglich machen.
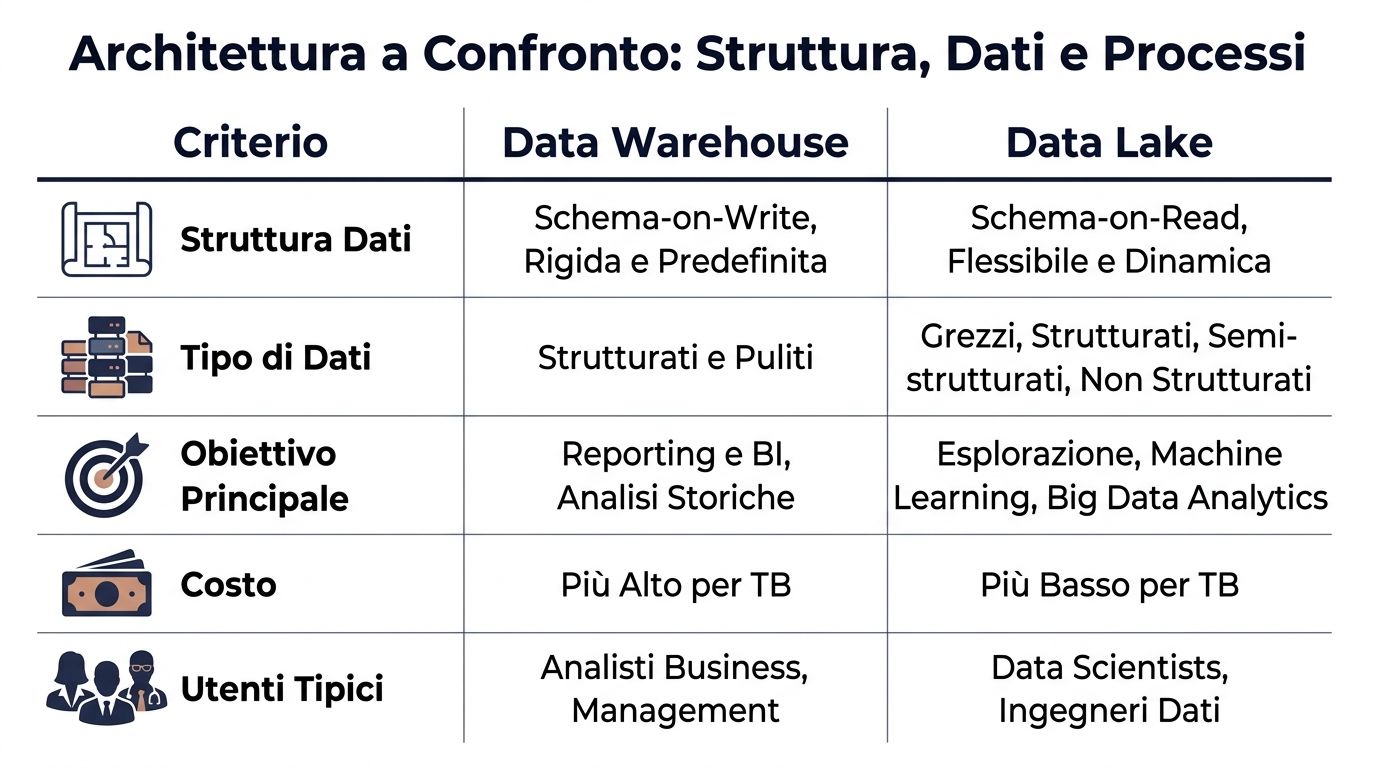
| Kriterium | Data Warehouse | Data Lake |
|---|---|---|
| Datenstruktur | Schema-on-write, vor dem Laden definiert | Schema-on-read, das zum Zeitpunkt der Analyse festgelegt wird |
| Datentyp | Vor allem übersichtlich und aufgeräumt | Strukturiert, halbstrukturiert und unstrukturiert |
| Typischer Prozess | ETL: Erst transformieren, dann laden | ELT: Erst laden, dann umwandeln |
| Typische Nutzer | Business Analyst, Finanzen, Management | Dateningenieur, Datenwissenschaftler, technische Teams |
| Erwartete Leistungen | Mehr Vorhersehbarkeit für BI und Berichterstattung | Mehr Variablen, abhängig von Abfrage und Vorbereitung |
Im Data Warehouse ist der klassische Ablauf ETL: Man extrahiert die Daten, transformiert sie und lädt sie anschließend hoch. Das erfordert zu Beginn zwar mehr Arbeit, verringert aber später den Reibungsverlust. Wer sich ein Dashboard ansieht, findet dort einheitliche Felder, feste Definitionen und KPIs, deren Bedeutung sich von Abteilung zu Abteilung nicht ändert.
Im Data Lake erfolgt der Datenfluss oft nach dem ELT-Prinzip: erst extrahieren, dann laden und erst danach transformieren, falls nötig. Dieser Ansatz bietet mehr technische Freiheit, verschiebt jedoch einen Teil der Arbeit auf später. Für ein kleines oder mittleres Unternehmen bedeutet dieses Aufschieben oft, dass sich Aufgaben anhäufen, die dann im ungünstigsten Moment auf das Team zurückfallen – nämlich dann, wenn eine schnelle Antwort erforderlich ist.
Faustregel: Wenn mehrere Personen denselben Bericht lesen und operative Entscheidungen treffen müssen, beugt die vor dem Hochladen festgelegte Struktur Fehlern, unnötigen Diskussionen und Zeitverlust vor.
Auf operativer Ebene ist ein Data Warehouse für wiederkehrende Abfragen, regelmäßige Berichte und täglich genutzte Dashboards ausgelegt. Ein Data Lake bewältigt große Datenmengen und unterschiedliche Formate gut, doch die Antwortzeiten und die Benutzerfreundlichkeit hängen stark davon ab, wie die Daten katalogisiert, aufbereitet und verwaltet wurden. Ein von CloudOptimo veröffentlichter technischer Vergleich fasst diesen Punkt gut zusammen: Das Warehouse setzt auf Vorhersehbarkeit, der Lake auf Flexibilität.
Für ein KMU ist das kein theoretisches Thema. Wenn der Vertriebsleiter morgens den Bericht öffnet, erwartet er konsistente Zahlen und schnelle Ergebnisse. Muss das technische Team hingegen Dateien, Protokolle oder unterschiedliche Dokumente analysieren, kann es eine gewisse Verzögerung in Kauf nehmen, um dafür umfassendere Daten zu erhalten.
Der praktische Unterschied ist nicht nur technischer Natur. Es kommt darauf an, wer die Daten nutzen kann, ohne jedes Mal um Hilfe bitten zu müssen.
Ein gut aufgesetztes Data Warehouse bringt die Daten näher an das Geschäft heran. Ein Data Lake allein bringt sie hingegen meist näher an das technische Team heran. Aus diesem Grund stellen viele KMU erst spät fest, dass die eigentliche Entscheidung nicht zwischen zwei Technologien liegt, sondern zwischen einem System, das Daten zugänglich macht, und einem, das sie lediglich speichert, ohne sie in bessere Entscheidungen umzusetzen.
Wer diese Optionen im Rahmen eines IT-Modernisierungsprojekts prüft, sollte nicht nur das Repository, sondern auch das Betriebsmodell berücksichtigen. Cloud-Lösungen für KMU helfen dabei, genau diesen Schritt zu verstehen: wo die Infrastruktur endet und wo Kosten, erforderliche Kompetenzen und tägliche Verantwortlichkeiten beginnen.
Der Data Lake wird oft als die kostengünstigste Lösung dargestellt, da er Rohdaten speichert und den anfänglichen Arbeitsaufwand reduziert. Das trifft jedoch nur teilweise zu. Fehlen ein Katalog, Zugriffsregeln, eine einheitliche Namensgebung und minimale Qualitätskontrollen, verwandeln sich die anfänglichen Einsparungen in Zeitverlust, der für die Suche nach Dateien, die Rekonstruktion von Definitionen und die Überprüfung der Datenzuverlässigkeit aufgewendet werden muss.
Aus diesem Grund geht es in vielen KMU nicht um den abstrakten Vergleich „Lake vs. Warehouse“. Die entscheidende Frage lautet vielmehr: Ist es wirklich notwendig, eine dieser umfassenden Architekturen aufzubauen, oder ist es sinnvoller, mit einer schlankeren Lösung zu beginnen, die schnelle Einblicke liefert, ohne gleich die gesamte Komplexität mit sich zu bringen?
Für ein KMU entsteht der kostspieligste Fehler oft durch eine falsch formulierte Frage: „Was ist günstiger: ein Data Lake oder ein Data Warehouse?“ Im Unternehmen kommt die Rechnung erst später. Sie kommt, wenn die Daten nicht miteinander kommunizieren, die Berichte bei jedem Wechsel des Betriebssystems zusammenbrechen und jede Anfrage über Berater oder Entwickler läuft, anstatt über das Team, das die Entscheidung treffen muss.

Die Speicherung selbst ist weniger wichtig, als es den Anschein hat. Viel wichtiger sind die Aufgaben, die dafür sorgen, dass die Daten zuverlässig und nutzbar sind: Modellierung, Integration, Berechtigungen, Qualitätssicherung, Überwachung, Fehlerbehebung und Benutzerunterstützung.
Ein Data Warehouse erfordert zu Beginn einiges an Arbeit. Man muss Kennzahlen definieren, Datenpipelines aufbauen, Datenquellen aufeinander abstimmen und alles in Ordnung halten, wenn sich ERP- oder CRM-Systeme oder Geschäftsregeln ändern. Im Gegenzug erhält das Management stabilere Zahlen, und das Berichtswesen wird in der Regel vorhersehbarer.
Ein Data Lake wird oft mit einem weniger ehrgeizigen Versprechen eingeführt. Man lädt Daten unterschiedlicher Art hoch und verschiebt einen Teil der strukturellen Entscheidungen auf später. Das Problem ist, dass diese Verschiebung die Arbeit nicht beseitigt. Sie verlagert sie lediglich auf einen späteren Zeitpunkt, wo sie sich in Form von Katalogisierung, Sicherheit, Rechenkosten, Duplikaten, inkonsistenten Versionen und ständigen Überprüfungen, welche Daten tatsächlich zuverlässig sind, bemerkbar macht.
Für ein KMU besteht die Gefahr, doppelt bezahlen zu müssen. Zunächst für die Datenerfassung. Dann dafür, die Daten endlich lesbar zu machen.
Die eigentliche Komplexität ist nicht technischer Natur. Sie ist operativer Natur.
Wenn jeder neue Bericht manuelle Eingriffe erfordert, wenn der Controller und der Vertriebsmitarbeiter unterschiedliche Definitionen derselben Kennzahl verwenden, wenn der Unternehmer tagelang auf eine verlässliche Zahl warten muss, zehrt das Datenprojekt bereits an der Marge. Auch wenn die Infrastruktur auf dem Papier modern erscheint.
Aus diesem Grund lohnt es sich, nicht nur die Architektur, sondern auch das Betriebsmodell zu prüfen. Cloud-Lösungen für KMU helfen dabei, genau diesen Unterschied zu erkennen: Was kaufen Sie tatsächlich, wie viel Wartungsaufwand bleibt intern und inwieweit sind Sie jeden Monat auf Fachwissen angewiesen?
Auf dem italienischen Markt erwarten Investoren im Bereich Analytics greifbare Ergebnisse: weniger manuelle Arbeit, schnellere Abschlüsse und eine bessere Kontrolle über Umsatz, Margen, Lagerbestände und Cashflow. Keine hochkomplexe Plattform, die nur wenigen vorbehalten ist.
Das verändert die Auswahlkriterien. Ein KMU sollte sich nicht fragen, welche Architektur abstrakt betrachtet am attraktivsten oder flexibelsten ist. Es sollte sich vielmehr fragen, wie lange es dauert, bis zuverlässige Dashboards zur Verfügung stehen, wie viele Mitarbeiter für deren Wartung benötigt werden und wie schnell das Projekt einen Mehrwert liefert.
Im Einzelhandel treten versteckte Kosten schnell zutage. Wenn Verkaufszahlen, Retouren, Werbeaktionen und Lagerbestände aus unterschiedlichen Systemen stammen, reicht schon eine falsche Definition von „Marge“ oder „Nettoumsatz“, um das Vertrauen in die Berichte zu untergraben. An diesem Punkt ist nicht die gewählte Datenbank das Problem. Das Problem ist vielmehr, dass der Geschäftsinhaber wieder auf Excel zurückgreift.
Im Finanzbereich wird der Preis eines Fehlers noch deutlicher. Berichterstattung, Abschlusserstellung, Controlling und Abweichungsanalyse erfordern konsistente und nachvollziehbare Daten. Wenn bei jeder Überprüfung Diskussionen über die Herkunft der Zahlen aufkommen, verliert das Projekt an Rentabilität, noch bevor es abgeschlossen ist.
Aus diesem Grund müssen viele KMU in der Praxis keinen Data Lake oder ein komplettes Data Warehouse von Grund auf neu aufbauen. Sie benötigen ein schlankeres, besser verwaltbares und entscheidungsorientiertes System.
Wenn es dir nicht gelingt, die Datenqualität, Zugriffsregeln und gemeinsamen Definitionen langfristig aufrechtzuerhalten, liegt das Problem nicht in der Wahl zwischen Data Lake und Data Warehouse. Das Problem ist vielmehr, dass du dir Komplexität auferlegt hast, bevor du einen Anwendungsfall hattest, der dies rechtfertigt.
Die richtige Frage lautet nicht, welche Architektur absolut gesehen die „beste“ ist. Die Frage ist vielmehr, welches Problem du morgen früh lösen musst.

Im Einzelhandel funktioniert das Lager gut, wenn man immer wieder dieselben operativen Fragen beantworten muss:
Das Gleiche gilt für den Finanzbereich. Wenn Sie strukturierte Daten konsolidieren, regelmäßige Berichte erstellen, Portfolios analysieren oder wirtschaftliche Entwicklungen anhand festgelegter Kriterien auswerten müssen, ist das Data Warehouse nach wie vor die naheliegende Wahl.
Ein Data Lake ist sinnvoll, wenn dein Unternehmen sehr unterschiedliche Daten sammelt und du nicht alles im Voraus definieren willst oder kannst.
Ein realistisches Beispiel ist das eines Energieunternehmens, das folgende Daten abgleicht:
In einem solchen Kontext zwingt dich ein klassisches Data Warehouse dazu, zunächst die Beziehungen zwischen Datenquellen zu definieren, die du vielleicht noch nicht gut kennst. Ein Data Lake ermöglicht es dir, alles zu zentralisieren und erst dann eine Struktur zu schaffen, wenn es für eine bestimmte Analyse erforderlich ist. Genau in solchen Szenarien schafft die Flexibilität des Data Lake einen echten Mehrwert.
Ein Data Lake ist keine „modernere“ Lösung. Er ist nur dann sinnvoll, wenn die Vielfalt der Daten den damit verbundenen Aufwand rechtfertigt.
Die meisten KMU befinden sich nicht in dieser Situation. Sie verfügen vor allem über Daten aus ERP-, CRM- und E-Commerce-Systemen, der Buchhaltung sowie aus CSV-Exporten und Excel-Dateien. In diesen Fällen besteht das Problem nicht darin, Videodateien, Anwendungsprotokolle oder Freitextdaten in großem Umfang zu verwalten. Das Problem besteht vielmehr darin, über saubere, konsistente und für Laien lesbare Zahlen zu verfügen.
Hier muss man eines klarstellen: Oftmals braucht man weder einen Data Lake noch ein herkömmliches Data Warehouse.
Vielmehr braucht es:
Das Lakehouse versucht, diese beiden Welten zu vereinen. Es verspricht die Flexibilität eines Lake und einige Eigenschaften eines Warehouse in ein und demselben Umfeld. Das ist ein interessanter Ansatz, insbesondere für Unternehmen mit gemischten Workloads aus den Bereichen BI, KI und Data Science.
Für ein KMU stellt sich jedoch nach wie vor dieselbe Frage: Hast du wirklich ein Problem, das all das erfordert? Wenn du lediglich einen besseren Überblick über Umsatz, Margen, Cashflow oder Prognosen gewinnen möchtest, könnte eine ausgefeilte Hybridlösung im Verhältnis zum erwarteten Nutzen immer noch unverhältnismäßig teuer sein.
Das Data Lakehouse wurde entwickelt, um die starre Trennung zwischen Lake und Warehouse zu überwinden. Die Idee ist einfach: Die Flexibilität eines großen, offenen Speichers beizubehalten, aber gleichzeitig für mehr Ordnung, Leistung und Analysefunktionen zu sorgen, die denen eines Warehouse näherkommen. Technologien wie Databricks und Delta Lake sind gute Beispiele für diese Entwicklung.
Theoretisch ist das sehr attraktiv. Man nutzt dieselbe Datenbank für BI, fortgeschrittene Analysen und maschinelles Lernen und vermeidet so, dass zu viele Informationen zwischen verschiedenen Systemen doppelt gespeichert werden. Für große Unternehmen oder erfahrene Datenteams ist dies eine logische Antwort auf ein Ökosystem, das im Laufe der Zeit immer komplexer geworden ist.
In akademischen Benchmarks wird die Data-Lakehouse-Architektur anhand von Kennzahlen wie Durchsatz, Latenz und Metadaten-Overhead bewertet. Dies zeigt, dass der Vergleich mit dem Data Warehouse nicht nur funktionaler, sondern auch leistungsbezogener Natur ist – insbesondere in Szenarien, in denen schon geringe Leistungsunterschiede erhebliche Auswirkungen haben, wie diese akademische Präsentation zu Lakehouse-Benchmarks verdeutlicht.
In der Unternehmenssprache ausgedrückt: Das Lakehouse löst Probleme von Organisationen, die bereits ein gewisses Maß an Größe, Komplexität und Spezialisierung aufweisen.
Wenn du weder einen Data Lake noch ein Data Warehouse wirklich gebraucht hast, brauchst du wohl kaum ein System, das beides vereint.
Für die meisten KMU lautet die wichtigste Frage nicht „Welche Architektur soll ich wählen?“, sondern „Wie erhalte ich zuverlässige Analysen, ohne dass das Datenprojekt zu einer ewigen Baustelle wird?“.
Dies ist der dritte Ansatz, der in vielen Vergleichen zwischen Data Lake und Data Warehouse zu kurz kommt. Man sollte keine neue proprietäre Infrastruktur aufbauen. Stattdessen sollte man eine Analyseebene über die bereits genutzten Systeme legen und so die technische Komplexität aus dem operativen Bereich des Unternehmens auslagern.

In der Praxis ist folgender Ansatz am sinnvollsten:
Ich habe schon oft erlebt, dass KMU monatelang in ein herkömmliches Lagerverwaltungssystem investiert haben, es dann aber kaum genutzt haben. Nicht, weil es schlecht aufgebaut war, sondern weil niemand im Unternehmen wusste, wie man es selbstständig abfragen konnte. Der Engpass lag nicht in der Datenbank, sondern in der Zugänglichkeit.
Dies ist ein Punkt, der oft unterschätzt wird. Eine elegante Architektur, die stets einen technischen Vermittler erfordert, mindert den praktischen Nutzen der Daten. Eine einfachere Lösung, die jedoch für das Management verständlich ist, führt oft schneller zu besseren Entscheidungen.
Aus diesem Grund profitieren viele Unternehmen mehr von einer gut konzipierten Business-Intelligence-Software für KMU als von einem überdimensionierten Infrastrukturprogramm. Ihr Ziel ist es nicht, ein Data Warehouse zu besitzen, sondern das Geschäft besser und früher zu verstehen.
Die richtige Infrastruktur ist die, die dein Team nutzen, warten und in Entscheidungen umsetzen kann. Nicht die, die auf einer technischen Folie beeindruckend wirkt.
Die Debatte „Data Lake vs. Data Warehouse“ ist zwar nützlich, geht für ein KMU jedoch oft von der falschen Frage aus. Bevor du dich für eine Architektur entscheidest, musst du klären, ob du tatsächlich ein Problem mit der Datenmenge und -vielfalt hast oder ob es sich um ein weitaus häufiger auftretendes Problem handelt: verstreute Daten, manuelle Berichte und schlechte Zugänglichkeit.
Das Data Warehouse bewährt sich, wenn zuverlässige Berichte, konsistente KPIs und vorhersehbare Leistung gefragt sind. Der Data Lake ist sinnvoll, wenn die Vielfalt der Quellen mehr Flexibilität und eine höhere Komplexität rechtfertigt. Das Lakehouse ist eine interessante Weiterentwicklung, aber selten der richtige erste Schritt für ein Unternehmen, das vor allem operative Kontrolle und ROI anstrebt.
Die klügste Entscheidung ist nicht unbedingt die fortschrittlichste Technologie. Es ist die Lösung, die dem tatsächlichen Problem, den vorhandenen Kompetenzen und der Geschwindigkeit, mit der Sie Daten in Entscheidungen umsetzen möchten, angemessen ist.
Wenn Sie Ihre Unternehmensdaten in Berichte, Prognosen und operative Erkenntnisse umwandeln möchten, ohne eine komplexe Infrastruktur aufbauen zu müssen, entdecken Sie ELECTE – eine KI-gestützte Datenanalyseplattform für KMU. Sie können mit den Daten beginnen, die Ihnen bereits vorliegen, den manuellen Aufwand reduzieren und Ihrem Team mit einem deutlich schlankeren Ansatz zugängliche Analysen zur Verfügung stellen.

.svg)
.svg)
.svg)






