

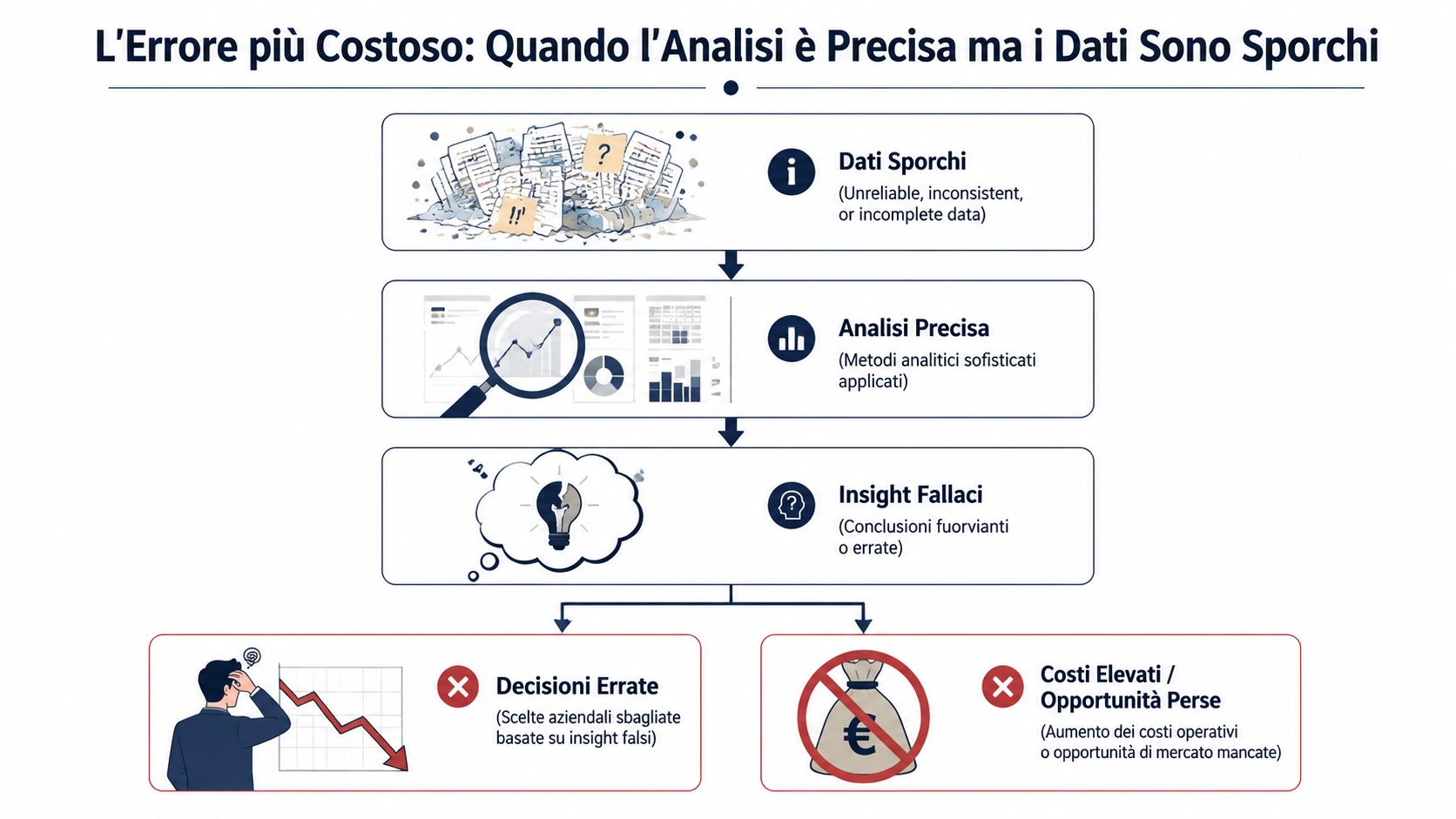
Sehen Sie sich den Umsatzbericht des Monats an. Die Umsätze scheinen gestiegen zu sein, die Marge scheint sich verbessert zu haben, und doch bleibt dieses unangenehme Gefühl, dass etwas nicht stimmt. Das ist keine Paranoia. Das ist operative Erfahrung. Wer in einem italienischen KMU arbeitet, weiß, dass die Daten zwischen dem Betriebssystem, Excel-Exporten und manuellen Änderungen mehrmals ihre Form ändern, bevor sie in einem Dashboard landen.
Der Punkt ist ganz einfach: Eine einwandfreie Analyse auf der Grundlage falscher Daten hilft dir nicht weiter. Sie führt dich in die Irre. Sie liefert dir eine präzise, elegante und beruhigende Antwort, die jedoch auf wackeligen Beinen steht. Und das ist viel gefährlicher als ein unvollständiger Bericht, denn sie verleitet dazu, Entscheidungen mit Sicherheit zu treffen, obwohl diese Sicherheit gar nicht gegeben ist.
Genau dafür sind Datenvalidierungstechniken da: Sie bringen Fehler ans Licht. Sie machen die Daten nicht „perfekt“. Sie machen Probleme sichtbar, die heute unbemerkt bleiben. Ob Sie nun in der Verwaltung, im Controlling, im Vertrieb oder im operativen Geschäft tätig sind – genau diese Arbeit unterscheidet eine verwertbare Zahl von einer reinen Ziffernfolge. Und in KMU ist dies wertvoller als viele „fortschrittliche“ Analytics-Initiativen, denn die Vorteile zeigen sich sofort, oft schon beim ersten Datenimport.
In KMU entstehen die Zahlen selten dort, wo sie gelesen werden. Sie wandern von einem Verwaltungssystem in eine exportierte Datei, dann in Excel und schließlich in eine „überarbeitete“ Version, die von jemandem erstellt wurde, der eigentlich nur zwei Spalten korrigieren sollte, am Ende aber die Hälfte der Tabelle neu geschrieben hat. Wenn der Abschlussbericht nicht überzeugt, liegt das Problem oft nicht an der Grafik. Es liegt an allem, was zuvor passiert ist.
Die Datenvalidierung ist das unattraktivste und zugleich wichtigste Thema des gesamten Analysezyklus. Kein Unternehmer möchte sich mit Formatprüfungen oder fehlenden Pflichtfeldern auseinandersetzen. Doch fast jede falsche Entscheidung, die auf der Grundlage scheinbar einwandfreier Dashboards getroffen wird, hat dort ihren Ursprung: bei einem geänderten Dezimaltrennzeichen, einem falsch interpretierten Datum, einem Duplikat im Stammdatenbestand oder einer Summe, die nicht stimmt, die aber niemand überprüft hat.
Wer gut mit Daten umgeht, entwickelt eine bestimmte Gewohnheit: Bevor er sich fragt, was die Zahlen aussagen, fragt er sich, ob diese Zahlen vertrauenswürdig sind. Die besten Techniken zur Datenvalidierung sind nicht unbedingt die ausgefeiltesten. Es sind diejenigen, die die häufigsten Fehler frühzeitig erkennen, ohne die tägliche Arbeit zu verlangsamen.
Wenn du den Daten nicht genug vertraust, um eine wichtige Entscheidung zu treffen, liegt das Problem nicht bei der Entscheidung selbst. Es liegt an der Überprüfung.
Der typische Fehler ist kein offensichtlich fehlerhafter Bericht. Es handelt sich um einen ordentlichen, scheinbar schlüssigen Bericht, der auf Daten basiert, die bereits an Zuverlässigkeit verloren haben. Wenn das passiert, liegt der Schaden nicht nur in der falschen Zahl. Er liegt darin, dass niemand sie in Frage stellt.
Die Vorgehensweise hat sich stark weiterentwickelt. Die Datenvalidierung hat sich von einer überwiegend manuellen Prüfung hin zu automatisierten und statistischen Überprüfungen gewandelt. In den Best Practices werden mindestens fünf grundlegende Prüfungen unterschieden, nämlich Datentypprüfung, Codeprüfung, Bereichsprüfung, Formatprüfung und Konsistenzprüfung, wie von Teradata in der Übersicht zur Datenvalidierung zusammengefasst. In Italien kommt dieser Entwicklung in regulierten Bereichen noch größere Bedeutung zu, wo bereits ein einziges fehlerhaftes Feld Berichte, Prognosemodelle oder die Einhaltung gesetzlicher Vorschriften beeinträchtigen kann.
Der erste Fehler besteht darin, sich mit dem Äußerlichen zu begnügen. Viele Unternehmen führen nur die einfachste Überprüfung durch, nämlich die syntaktische.
Eine korrekt angegebene Steuernummer kann die erste Hürde nehmen, an der zweiten jedoch scheitern. Der Rechnungsbetrag kann zwar numerisch und im richtigen Format vorliegen, aber wenn er nicht mit der Summe der Einzelposten übereinstimmt, hast du ein viel ernsthafteres Problem als nur das Format.
Faustregel: Eine Prüfung, die nur eine Spalte auswertet, deckt banale Fehler auf. Eine Prüfung, die mehrere Felder miteinander in Beziehung setzt, deckt Fehler auf, die Entscheidungen beeinflussen.
Eine sinnvolle Validierung findet nicht erst am Ende der Arbeit statt. Sie erfolgt schon vorher. Wenn Sie auf den Abschlussbericht warten, wurde der Fehler bereits umgewandelt, aggregiert, in andere Dateien kopiert und in Besprechungen diskutiert. Zu diesem Zeitpunkt kostet seine Korrektur Aufmerksamkeit, Zeit und Glaubwürdigkeit.
Dies gilt umso mehr, wenn Sie anfangen, anspruchsvollere Methoden wie die Anomalieerkennung oder den Umgang mit statistischen Ausreißern einzusetzen. Das sind nützliche Werkzeuge, aber sie ersetzen nicht die grundlegenden Prüfungen. Wenn eine als Text importierte Spalte Preise enthält, brauchen Sie kein komplexes Modell. Sie benötigen einen einfachen Filter, der den Fehler bereits bei der Eingabe abfängt.
Eine gute Analyse beginnt nicht mit den schönsten Dashboards. Sie beginnt mit Daten, die eine Reihe sinnvoller Tests durchlaufen haben, sobald sie in den Datenfluss gelangen.
Im Tagesgeschäft von KMU entsteht der größte Teil des Mehrwerts durch einfache Kontrollen. Nicht durch ausgefeilte akademische Techniken. Nicht durch komplexe Prozesse, die niemand aufrechterhalten wird. Sondern durch klare, wiederholbare Regeln, die genau dort ansetzen, wo die Daten tatsächlich ins Unternehmen gelangen.

Im italienischen Kontext steht dieser Ansatz im Einklang mit dem Konzept des ISTAT, das die Datenqualität anhand von Dimensionen wie Genauigkeit, Konsistenz und Vollständigkeit definiert und die VIMO-Prüfung (Valid, Invalid, Missing, Outlier) zur Ermittlung gültiger, fehlender und anomaler Werte einsetzt. Der Ansatz sieht eine Validierung bei der Dateneingabe, während der Datenverarbeitung und vor der endgültigen Nutzung der Daten vor, wie in den ISTAT-Unterlagen zur Datenqualität und -validierung erläutert.
Der typische Ablauf ist immer derselbe. Die Daten entstehen im Verwaltungssystem. Sie werden exportiert. Sie landen in Excel. Jemand korrigiert eine Überschrift, zieht eine Formel, kopiert eine Spalte, ändert das Datumsformat, „um es in Ordnung zu bringen“. Von da an beginnen die versteckten Fehler.
Hier sind die Kontrollen, die man am besten sofort vor Ort durchführen sollte:
Wenn Sie mit manuellen Exporten arbeiten, können Sie mit einer sehr konkreten Tabelle beginnen:
| Kontrolle | Ein typischer Fehler in KMU | Eine Frage, die du dir stellen solltest |
|---|---|---|
| Typ | Preis als Text einlesen | Kann diese Spalte berechnet werden? |
| Format | Gemischte Datumsangaben in verschiedenen Formaten | Interpretiert das System sie immer auf dieselbe Weise? |
| Bereich | Beträge außerhalb der Skala | Ist dieser Wert für den Kunden oder das Produkt plausibel? |
| Einzigartigkeit | Kunde wurde mehrfach eingegeben | Zähle ich verschiedene Personen oder unterschiedlich geschriebene Namen? |
| Vollständigkeit | Leere Pflichtfelder | Kann ich diesen Datensatz in Berichten und Auswertungen verwenden? |
| Kohärenz | Summen, die nicht stimmen | Bestätigen sich die Spalten gegenseitig? |
Für diejenigen, die in Branchen tätig sind, in denen die Qualität von Dokumenten und Abläufen bereits eine große operative Rolle spielt, lohnt es sich, auch strukturiertere Verfahren zur Qualifizierung und Kontrolle in Betracht zu ziehen. Eine hilfreiche Lektüre ist der Leitfaden zur Qualifizierung in regulierten Branchen, da er deutlich macht, dass es bei der Validierung nicht nur um „Ordnung“ geht, sondern um die Kontrolle des Prozesses.
Duplikate verdienen eine gesonderte Erwähnung. Sie sind ein chronisches Problem in den Stammdaten vieler KMU und verfälschen fast alles: aktive Kunden, Kaufhäufigkeit, Geschäftsvolumen, Beziehungshistorie. Wenn Sie von einem konkreten Fall ausgehen möchten, finden Sie einen praktischen Ansatz in ELECTE: Kompletter Leitfaden zu Duplikaten in Excel.
Ausgefeilte Kontrollmaßnahmen sind erst dann sinnvoll, wenn die Grundlagen geschaffen sind. Sonst ist das so, als würde man ein Radar auf ein Auto ohne Bremsen montieren.
Montagmorgen, Vertriebsbesprechung. Der Inhaber schaut sich den Umsatzbericht an, der Verwaltungsleiter eine andere Datei, der Controller eine dritte. Die Zahlen sollten übereinstimmen. Das tun sie aber nicht.
Das ist ein ganz normaler Anblick in italienischen KMU. Ein veraltetes Verwaltungssystem exportiert CSV-Dateien mit festgelegten Feldern. Das CRM verwendet andere Bezeichnungen. Der E-Commerce hat seine eigene Logik. Dann kommt Excel ins Spiel, und dort passt dann jemand die Kopfzeilen an, kopiert Spalten, korrigiert Datumsangaben und versucht, vor der Besprechung alles unter einen Hut zu bringen.
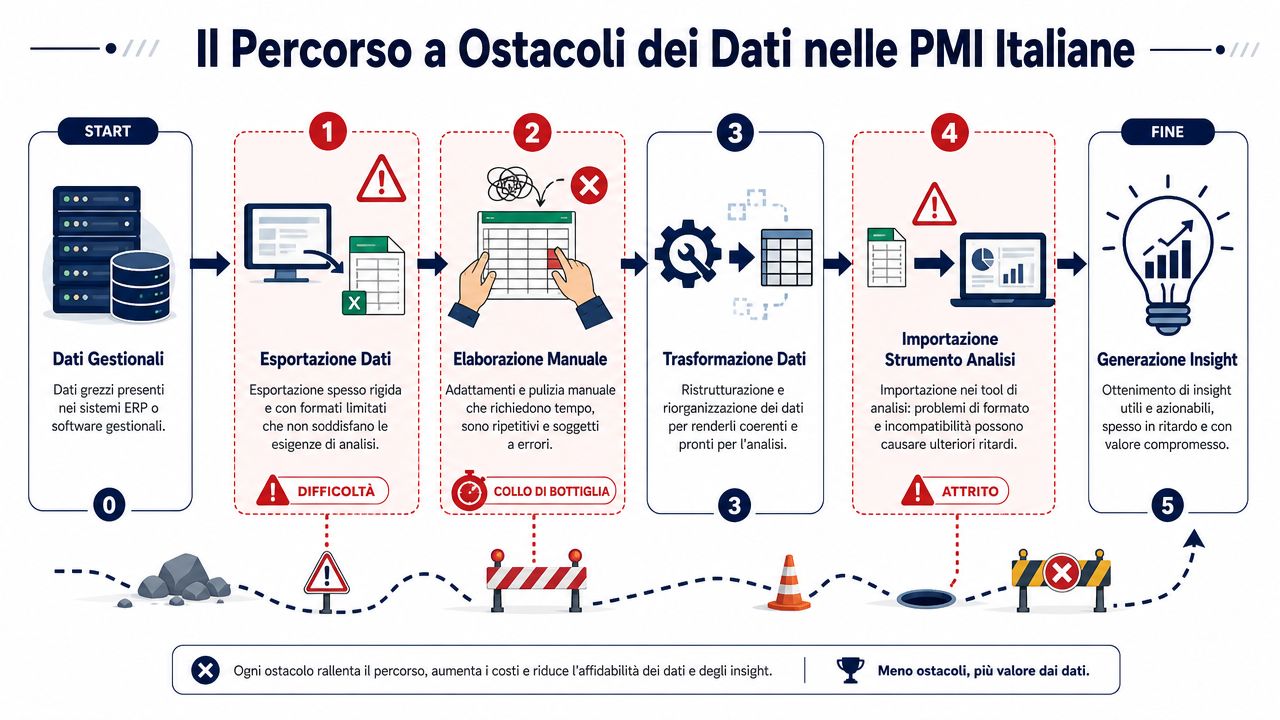
Das Problem ist nicht die Technologie an sich. Das Problem ist die Summe kleiner manueller Schritte bei Daten, die aus Systemen stammen, die zu unterschiedlichen Zeitpunkten entwickelt wurden und oft keine gemeinsamen Regeln aufweisen. Wer mit der Verknüpfung verschiedener Datenquellen arbeitet, erkennt das sofort: Jede Quelle bringt ihre eigenen Konventionen, wiederkehrende Fehler und Felder mit, die „wie es gerade passt“ ausgefüllt werden.
Selbst die kostspieligsten Fehler halten den Prozess nicht auf. Sie werden in die Datei geschrieben und bleiben dort.
Das passiert jeden Tag in ganz konkreten Situationen:
Hier begehen viele Unternehmen denselben Fehler. Sie suchen nach ausgeklügelten Lösungen, bevor sie die einfachen, aber gewinnbringenden Kontrollmaßnahmen sichergestellt haben: korrekte Datentypen, konsistente Schlüssel, geschützte Codes und Datumsangaben, die von allen Systemen einheitlich gelesen werden können.
In KMU sind die Daten selten von vornherein einheitlich und stabil. Sie wandern zwischen Verwaltung, Vertrieb, Logistik, externen Beratern und lokalen Dateien mit Namen wie „report_finale_def_vero.xlsx“ hin und her. Jeder korrigiert das, was er für seine Arbeit benötigt. Kaum jemand dokumentiert die Änderungen.
Aus diesem Grund kommen akademische Prüfungen oder allzu ehrgeizige Projekte zur Anomalieerkennung oft zu früh. Zunächst ist Disziplin bei den Grundlagen gefragt. Eine automatische Prüfung, die ungültige CAPs, abgeschnittene Kundencodes, doppelte Zeilen oder Daten außerhalb des Zeitraums meldet, vermeidet mehr Fehler als viele „fortgeschrittene“ Initiativen, die zu früh auf den Weg gebracht werden.
Ich sage das ganz offen, denn das ist der Punkt, den ich am häufigsten beobachte: Ein KMU verliert das Vertrauen in die Daten nicht, weil es an künstlicher Intelligenz mangelt. Es verliert es, weil sich der Umsatz von einer Excel-Datei zur nächsten ändert und niemand sagen kann, welche Version die richtige ist.
Die Datei, die „immer funktioniert hat“, ist oft die Datei, die niemand mehr überprüft.
Wenn Daten durch mehrere Hände und Systeme wandern, muss die Validierung nicht elegant sein. Sie muss wiederholbar, mühsam und möglichst nah am Dateneingang erfolgen. Genau dort liegt der größte Teil des Nutzens, noch bevor man überhaupt von Vorhersagemodellen oder ansprechenderen Dashboards spricht.
So beginnt der Montagmorgen oft. Der Verwaltungsleiter öffnet zwei Exportdateien desselben Monats – eine aus dem Verwaltungssystem und eine aus der Vertriebsdatei –, und die Summen stimmen nicht überein. Niemand hat Zeit, die Überprüfungen manuell zu wiederholen. An diesem Punkt ist das Problem nicht der Bericht. Das Problem ist, dass das Vertrauen in die Zahlen bereits erschüttert ist.
ELECTE greift ein, bevor die unbereinigten Daten in die Analyse gelangen. Für ein italienisches KMU ist das der entscheidende Punkt. Man braucht keine komplizierte Software, die ausgefeilte Prüfungen verspricht, wenn sie dann banale Importfehler, falsch interpretierte Spalten oder Codes, deren Format sich von einem System zum anderen ändert, durchlässt.
Praktisch gesehen überprüft die Plattform die Daten bereits bei ihrem Eingang. Nicht erst nach dem Bericht. Nicht erst nach der Besprechung, in der jemand fragt, warum sich der Rand von einer Dateiversion zur nächsten geändert hat.
Die automatischen Prüfungen decken die Probleme ab, die in KMU mehr Schaden anrichten als erwartet: inkonsistente Datentypen, fehlende Felder, Datumsangaben außerhalb des zulässigen Zeitraums, Duplikate, Werte außerhalb des zulässigen Bereichs sowie Schlüssel, die nicht mit den richtigen Tabellen verknüpft sind. Es handelt sich um wenig glamouröse Prüfungen, doch gerade sie verhindern die meisten operativen Fehler in Umgebungen, in denen Excel-Exporte, veraltete ERP-Systeme und per E-Mail versendete Dateien an der Tagesordnung sind.
Dann gibt es noch die kontextbezogene Ebene. Beim Onboarding werden Regeln festgelegt, die mit dem tatsächlichen Unternehmensprozess im Einklang stehen, nicht mit einem theoretischen Modell. Ein Unternehmen im Einzelhandel hat andere Anforderungen als eine Agentur, die Touristenbetreuung anbietet, oder ein Hersteller mit gestaffelten Preislisten und Rabatten. Gleiches gilt für spezifische Dokumentenfälle, wie das Auslesen strukturierter Daten aus Dokumenten und Check-ins – ein Thema, das auch für diejenigen relevant ist, die mit MRZ für Beherbergungsbetriebe arbeiten.
Der praktische Vorteil liegt auf der Hand: Das Team muss sich nicht jedes Mal überlegen, welche Kontrollen durchgeführt werden sollen. Diese sind bereits einheitlich und wiederholbar festgelegt.
Ein typisches Beispiel: Ein Update des Betriebsmanagementsystems ändert das Format einiger Preisfelder nur in einem Teil des Exportdatensatzes. Auf den ersten Blick scheint die Datei korrekt zu sein. Bei genauerer Analyse stellen sich jedoch heraus, dass diese Werte den Umsatz, die Margen und die Vergleiche mit den Vormonaten verfälschen. ELECTE meldet die Anomalie sofort, isoliert die betroffenen Zeilen und ermöglicht es, diese zu korrigieren, bevor sie in Dashboards und Führungsberichten landen.
Einer der nützlichsten Aspekte für diejenigen, die Entscheidungen treffen müssen und sich nicht mit Data Science beschäftigen, ist das Ausnahmemanagement. Problematische Datensätze verschwinden nicht. Sie bleiben sichtbar, werden separat aufgeführt und mit einer Begründung versehen.
Wer sich mit den Daten auskennt, versteht sofort:
Diese Transparenz verhindert eine der schlimmsten Gewohnheiten, die ich in KMU beobachte: den Datensatz spurlos zu bereinigen und erst Wochen später festzustellen, dass die Zahlen nicht mehr stimmen.
Gerade aus diesem Grund ist die Funktion zur Verknüpfung verschiedener Datenquellen so wertvoll. Es reicht nicht aus, CRM, ERP, E-Commerce und manuell erstellte Dateien miteinander zu verknüpfen. Wenn die Daten ohne klare Kontrollen zusammenfließen, bleibt das Chaos bestehen – nur auf einem übersichtlicheren Bildschirm.
ELECTE verspricht keine perfekten Daten. Es reduziert die häufigsten Fehler, macht sie sichtbar und verhindert, dass sie als korrekte Daten in die Berichte gelangen. Für ein KMU macht genau das oft den Unterschied zwischen der Diskussion über Zahlen und der Diskussion mit Zahlen aus.
Die Validierung sollte nicht als ein vom Geschäft getrenntes technisches Projekt betrachtet werden. Sie sollte als operative Disziplin behandelt werden. Wer ein Budget erstellt, eine Preisliste genehmigt, Margen überprüft oder Einkäufe plant, nutzt bereits Daten, die entweder gut oder schlecht validiert sind. Eine dritte Option gibt es nicht.
Es gibt nur wenige nützliche Regeln, aber sie müssen konsequent angewendet werden:
Gilt beim Eingang, nicht im weiteren Verlauf
Wenn die Prüfung erst am Ende erfolgt, hat der Fehler bereits Formeln, Aggregationen und Berichte beeinträchtigt.
Beschränke dich nicht auf das Format „
“. Ein Datensatz kann zwar korrekt geschrieben sein, aber dennoch falsch sein. Du musst die Plausibilität und Konsistenz zwischen den Feldern überprüfen, nicht nur die Einhaltung eines Schemas.
Automatisieren Sie sich wiederholende Prüfungen
Kein Verwaltungs- oder Vertriebsteam hat die Zeit, jeden Export manuell zu überprüfen. Grundlegende Prüfungen müssen systematisch erfolgen.
Vermeiden Sie zu strenge Regeln
Es gibt einen echten Kompromiss zwischen Strenge und Produktivität. Zu strenge Regeln können dazu führen, dass nicht-technische Teams Analysetools weniger nutzen, wie Acceldata in seinen Überlegungen zum Trade-off bei der Datenvalidierung hervorhebt. Der richtige Mittelweg ist der, der Fehler minimiert, ohne das Geschäft zu verlangsamen.
Behandle Ausnahmen als Signale, nicht als Ärgernisse
Ein anomaler Datensatz sagt fast immer etwas über den Prozess aus, der ihn hervorgebracht hat. Ihn zu ignorieren bedeutet, auf Verbesserungen im Vorfeld zu verzichten.
Ein anschauliches Beispiel findet sich in Bereichen, in denen das Format kein Detail, sondern eine Voraussetzung für den Betrieb ist. In Beherbergungsbetrieben beispielsweise verdeutlicht das Thema der automatischen Dokumentenerkennung, wie wichtig es ist, dass die Daten nicht nur vorhanden sind, sondern auch einem interpretierbaren Standard entsprechen. Wer einen konkreten Anhaltspunkt sucht, kann diesen ausführlichen Artikel über MRZ für Beherbergungsbetriebe lesen.
Die richtige Einstellung lautet: Vertraue den Daten erst, nachdem du sie auf Herz und Nieren geprüft hast. Wenn du dich heute auf Dateien verlässt, die niemand systematisch überprüft, betreibst du keine Analyse. Du hoffst nur.
Die meisten Probleme in Berichten entstehen nicht erst im letzten Diagramm. Sie entstehen schon viel früher, nämlich dann, wenn unvollständige, inkonsistente oder aus dem Zusammenhang gerissene Daten ohne ernsthafte Filterung in die Systeme gelangen. Deshalb sind Datenvalidierungstechniken wichtiger, als es auf den ersten Blick scheint. Sie sind der Punkt, an dem man aufhört, sich von den Daten leiten zu lassen, und anfängt, sie zu steuern.
Für ein KMU liegt der Gewinn nicht darin, nach Perfektion zu streben. Er liegt vielmehr darin, ein ausreichendes Maß an Vertrauen aufzubauen, um Entscheidungen mit klarem Kopf treffen zu können. Prüfungen hinsichtlich Typ, Format, Bereich, Eindeutigkeit, Vollständigkeit und Kreuzkonsistenz lösen einen Großteil der tatsächlichen Probleme. Die Automatisierung macht diese Prüfungen nachhaltig.
Wenn du keinen strukturierten Validierungsprozess hast, vertraust du nicht auf die Daten. Du vertraust auf das Glück.
Wenn Sie unübersichtliche Exporte, anfällige Excel-Dateien und heterogene Datenquellen in zuverlässige Analysen umwandeln möchten, erfahren Sie hier, wie ELECTE – eine KI-gestützte Datenanalyseplattform für KMU – Prüfungen, Anomalien und Erkenntnisse automatisiert, ohne Ihr Team zusätzlich zu belasten.

.svg)
.svg)
.svg)





