

Sie stehen bereits vor dem Problem, das High Performance Computing löst, auch wenn Sie es vielleicht nicht so nennen. Eine Prognose benötigt zu viel Zeit für die Berechnung. Ein Bericht liegt erst vor, wenn sich die Rahmenbedingungen bereits geändert haben. Ein vielversprechendes Modell zur Nachfrage, zum Risiko oder zur Preisgestaltung kommt nicht zum Einsatz – nicht weil Daten fehlen, sondern weil die Rechenzeit es für das Unternehmen kaum noch nutzbar macht.
Für viele KMU besteht die Herausforderung nicht mehr darin, Informationen zu sammeln. Die Herausforderung besteht vielmehr darin, diese Informationen rechtzeitig in Entscheidungen umzusetzen. An dieser Stelle istHigh Performance Computing kein reines Labor-Thema mehr, sondern wird zu einer Frage des Managements: Wie viele Simulationen kann man durchführen, wie schnell lässt sich eine Prognose aktualisieren, wie viele Alternativen kann man vergleichen, bevor der Markt einen zur Entscheidung zwingt?
In Italien hat das Thema zudem nationale strategische Bedeutung. Der Supercomputer „Leonardo“ des CINECA, der 2022 im Rahmen von EuroHPC in Bologna eingeweiht wurde, wurde zum Zeitpunkt seiner Inbetriebnahme als eines der leistungsstärksten Systeme der Welt vorgestellt, was verdeutlicht, dass HPC mittlerweile nicht mehr nur für die Wissenschaft, sondern auch für die Industrie und die angewandte Forschung von Bedeutung ist (Hintergrundinformationen zum HPC-Markt und zu Leonardo).
Montagmorgen. Der Vertriebsleiter verlangt bis zum Nachmittag eine neue Prognose, die Lieferkette möchte die Lagerbestände überprüfen, bevor sie die Bestellungen bestätigt, und das Finanzteam erwartet für die Besprechung am nächsten Tag ein konservatives und ein aggressives Szenario. Die Daten liegen vor. Das Problem ist die Zeit, die benötigt wird, um sie gründlich auszuwerten.
Genau dafür istHigh Performance Computing da: um viele komplexe Berechnungen gleichzeitig durchzuführen und so nützliche Antworten zu erhalten, wenn sie noch gebraucht werden. Für ein KMU geht es nicht darum, einen Supercomputer zu besitzen. Es geht darum, zu verhindern, dass langsame Analysen Entscheidungen verzögern, die sich direkt auf Margen, Service und Lagerbestände auswirken.
Ein herkömmliches System erledigt die Arbeit auf linearere Weise. HPC verteilt die Arbeitslast auf mehrere koordinierte Ressourcen, so wie es ein gut organisiertes Team angesichts einer knappen Frist tun würde. Das Ergebnis ist nicht nur Geschwindigkeit. Es ist die Möglichkeit, mehr Hypothesen zu testen, Prognosen häufiger zu aktualisieren und Entscheidungen mit geringerer Ungenauigkeit zu treffen.
Bei ELECTE sehen wir dies in ganz konkreten Zusammenhängen. Eine schneller neu berechnete Prognose trägt dazu bei, Lieferengpässe und Überbestände zu reduzieren. Eine schnellere Optimierungsengine ermöglicht es, verschiedene Szenarien zu vergleichen, bevor Budgets, Lagerbestände oder operative Kapazitäten zugewiesen werden. In der Praxis wird die Berechnung so zu einem Steuerungsinstrument und nicht mehr zu einer Angelegenheit der IT-Abteilung.
HPC kommt dann zum Einsatz, wenn eine verspätete Analyse mehr kostet als deren parallele Ausführung.
Ein häufiges Missverständnis unter Führungskräften ist es, HPC ausschließlich mit riesigen Datenmengen in Verbindung zu bringen. Bei unternehmerischen Entscheidungen stößt man oft schon früher an Grenzen, nämlich wenn die Komplexität der zu lösenden Aufgabe zunimmt.
Das passiert beispielsweise, wenn ein Datensatz, der an sich noch überschaubar ist, für Berechnungen herangezogen werden muss, die weitaus rechenintensiver sind als das einfache Berichtswesen. Hier sind einige typische Fälle:
Die richtige Frage lautet hier nicht: „Wie viele Daten habe ich?“, sondern: „Was kostet es, Entscheidungen auf der Grundlage eines vereinfachten Modells zu treffen oder auf der Grundlage von Ergebnissen, die zu spät eintreffen?“
Aus technischer Sicht bündelt HPC zahlreiche Rechenressourcen, um Rechenaufgaben zu bewältigen, die ein einzelner Rechner langsamer oder unter größeren Einschränkungen bewältigen würde. Aus Sicht eines KMU lässt sich dies einfacher erklären: frühere Prognosen, häufigere Simulationen, besser abgestimmte Lagerbestandspläne und kürzere Wartezeiten zwischen einer geschäftlichen Anfrage und einer verlässlichen Antwort.
Und genau hier unterscheidet sich die Perspektive von den eher akademischen Inhalten zu diesem Thema. Für ein kleines oder mittelständisches Unternehmen bedeutet HPC nicht, in die Welt der Forschungszentren einzusteigen. Es bedeutet vielmehr, skalierbare Rechenkapazität zu nutzen, um komplexe geschäftliche Probleme zu lösen, ohne ein Ingenieurteam oder eine schwer zu verwaltende Infrastruktur von Grund auf neu aufbauen zu müssen. Es ist genau diese Herangehensweise, die Plattformen wie ELECTE auch außerhalb großer Unternehmen praktikabel machen.
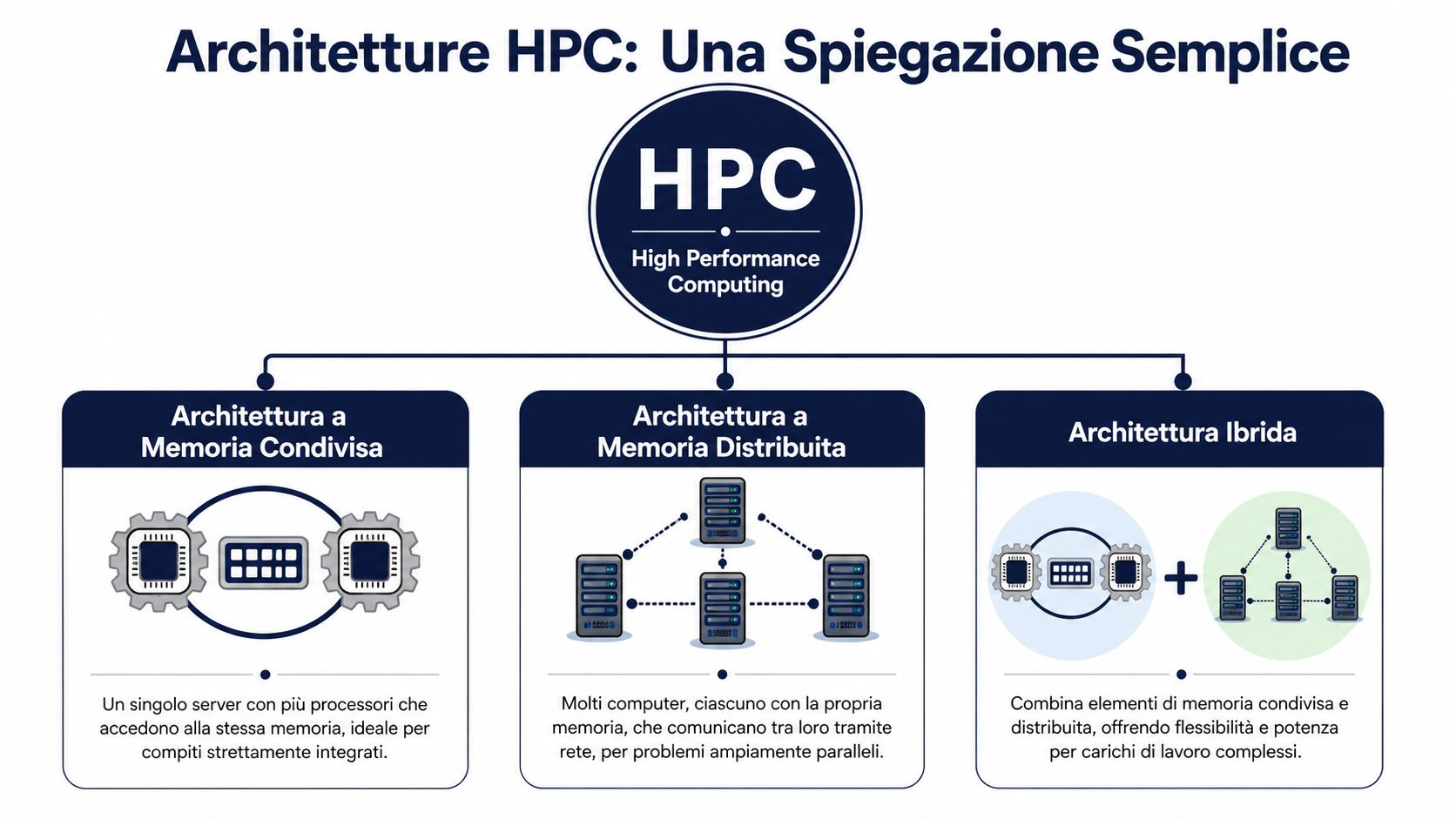
HPC funktioniert dank mehrerer Komponenten, die zusammenwirken. Die drei Begriffe, auf die es wirklich ankommt, sind Cluster, GPU und Cloud.
Ein Cluster vereint mehrere Rechner, sogenannte Knoten, um eine Aufgabe parallel auszuführen. In der Praxis wird eine Aufgabe, die für einen einzelnen Server zu aufwendig ist, in kleinere Teile aufgeteilt und mehreren untereinander koordinierten Knoten zugewiesen. Für einen Manager ist dies kein technisches, sondern ein operatives Anliegen: weniger Wartezeit zwischen der Anforderung einer Analyse und einer Entscheidung über Lagerbestände, Preisgestaltung oder Prognosen.
In ELECTE erweist sich dieses Prinzip beispielsweise dann als nützlich, wenn ein Unternehmen Prognosen für zahlreiche Kombinationen aus Produkt, Verkaufsstelle und Zeitraum neu berechnen muss. Bleibt die Arbeit auf einem einzigen Rechner, verlängert sich die Bearbeitungszeit, und das Team neigt dazu, weniger Simulationen durchzuführen. Wird die Last hingegen verteilt, ist es realistisch, mehrere Szenarien im selben Entscheidungszyklus zu vergleichen.
GPUs dienen einer anderen Art der Beschleunigung. Sie sind besonders effektiv, wenn dieselbe Art von Berechnung sehr oft wiederholt werden muss, wie dies beim maschinellen Lernen, bei bestimmten Optimierungen und in Teilen der fortgeschrittenen Analyse der Fall ist. Der geschäftliche Nutzen ist greifbar: Modelle lassen sich schneller trainieren oder testen, Prognosen können früher aktualisiert werden und die Zeitspanne zwischen einer Hypothese und ihrer Überprüfung wird verkürzt.
Die HPC-Cloud sorgt für mehr Flexibilität bei der Rechenkapazität. Anstatt Ressourcen zu kaufen, die auf die jährliche Spitzenauslastung ausgelegt sind, kann das Unternehmen diese genau dann aktivieren, wenn sie tatsächlich benötigt werden. Für ein KMU ist dies oft der Unterschied zwischen dem Verzicht auf eine komplexe Analyse und deren Durchführung zum richtigen Zeitpunkt, ohne eine schwer zu wartende Infrastruktur im eigenen Haus aufbauen zu müssen. Wenn Sie sich ein klareres Bild davon machen möchten, wie sich diese Bereitstellungsmodelle zueinander verhalten, kann dieser ausführliche Artikel über IaaS, PaaS und SaaS in der Cloud hilfreich sein.
In der Unternehmenspraxis lässt sich die beste Lösung selten mit einer einzigen Architektur erreichen. Viel wichtiger ist es, die Ressourcen gut zu kombinieren.
Eine On-Premise-Umgebung bietet direkte Kontrolle, Vorhersehbarkeit und in manchen Fällen eine besser beherrschbare Latenz. Die Cloud ergänzt dies durch Kapazitäten nach Bedarf. GPUs beschleunigen Workloads, die sich für massive Parallelisierung eignen. Cluster verteilen die Arbeit auf mehrere Knoten. Eine hybride Architektur entsteht genau aus dieser Kombination, die je nach Art der Analyse, Häufigkeit von Spitzenauslastungen und Governance-Vorgaben zusammengestellt wird.
Für ein KMU ist das richtige Kriterium ganz einfach: Wenn Sie über stabile, wiederkehrende und reaktionszeitkritische Prozesse verfügen, kann eine On-Premise-Lösung sinnvoll sein. Wenn hingegen die Auslastung zu bestimmten Zeiten steigt – beispielsweise bei Periodenabschlüssen, Neuprognosen oder außerordentlichen Simulationen –, ermöglicht die Cloud eine Kapazitätserweiterung, ohne dass das Budget das ganze Jahr über gebunden ist.
Es gibt außerdem einen Punkt, der oft für Verwirrung sorgt. Skalieren bedeutet nicht nur, Kerne oder Server hinzuzufügen. Bei einer realen Arbeitslast spielen auch Netzwerk, Arbeitsspeicher und Speicher eine Rolle, da die Knoten Daten schnell und geordnet austauschen müssen. Die technischen Erläuterungen zu HPC-Rechenzentren veranschaulichen dieses Prinzip sehr gut, insbesondere im Zusammenhang zwischen Knoten, Vernetzung und Speicher (weiterführende Informationen zu Knoten, Vernetzung und Speicher in HPC-Rechenzentren).
In die Sprache der Unternehmensführung übersetzt bedeutet dies: Die richtige Architektur ist diejenige, die Engpässe reduziert, die das Geschäft verlangsamen. Ein Supercomputer aus dem Labor ist nicht erforderlich. Was benötigt wird, ist eine skalierbare Konfiguration, die häufigere Analysen, zeitnahere Prognosen und operative Entscheidungen auf der Grundlage besserer Daten ermöglicht. Genau hier machen Plattformen wie ELECTE HPC auch für Unternehmen greifbar, die nicht über ein internes Team aus spezialisierten Ingenieuren verfügen.
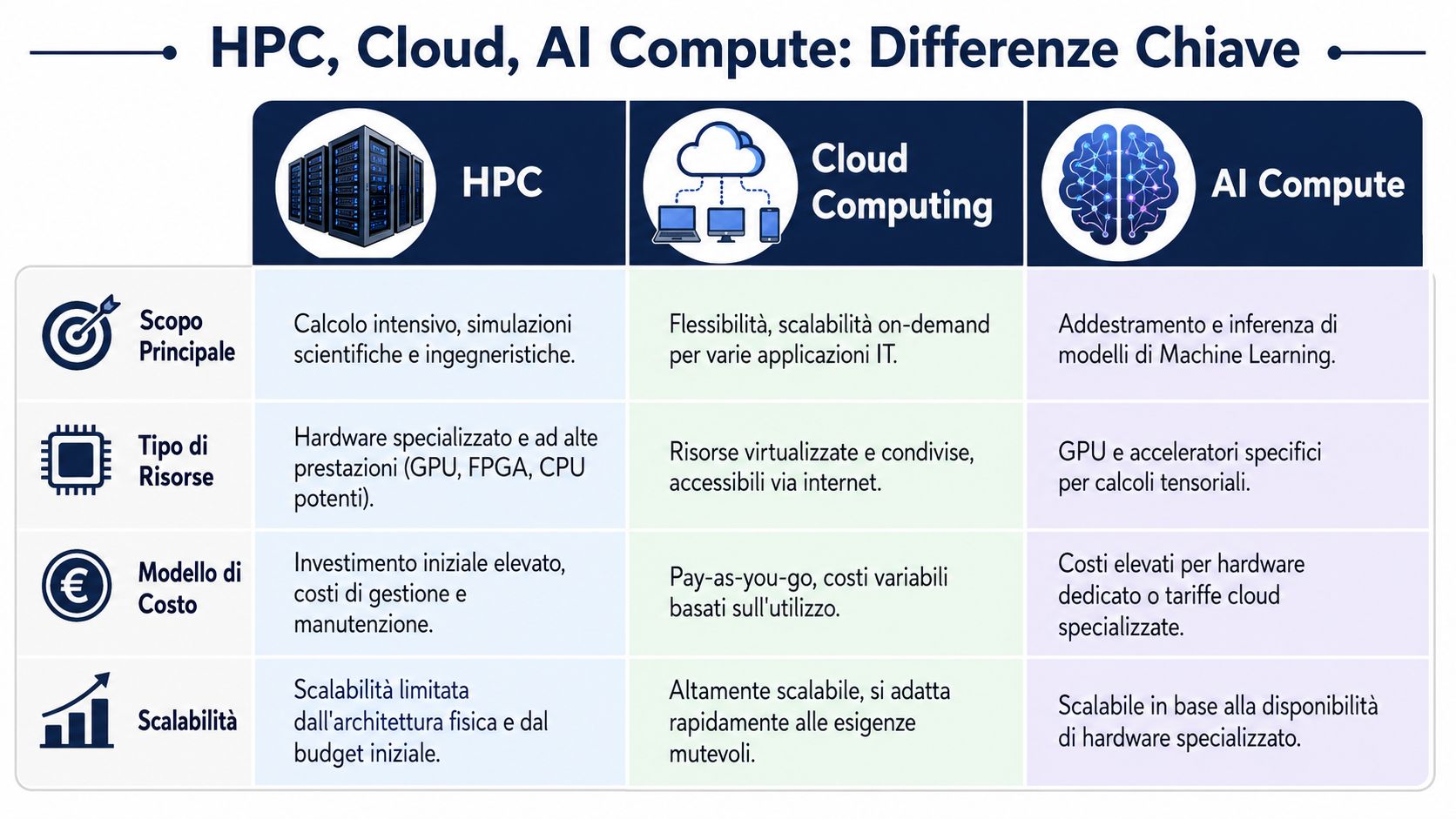
Diese drei Begriffe werden oft verwechselt, bezeichnen jedoch verschiedene Ebenen derselben Realität.
Ein einfacher Satz hilft dabei, sie voneinander zu unterscheiden. HPC ist der Motor. Die Cloud ist die Art des Zugriffs. AI-Compute ist die Art der Berechnung, die Sie durchführen.
| Aussehen | HPC | Cloud Computing | KI-Rechenleistung |
|---|---|---|---|
| Eine Frage, die beantwortet wird | Wie kann ich rechenintensive Berechnungen beschleunigen? | Wo bekomme ich flexible Ressourcen? | Welche Art von Berechnung führe ich gerade durch? |
| Typische Verwendung | Simulationen, komplexe Prognosen, Optimierung | Elastische Umgebungen, schnelle Bereitstellung, Burst-Kapazität | Training und Inferenz von ML-Modellen |
| Managementvorteil | Verkürzt die Durchführungszeit | Vermeiden Sie starre Investitionen aufgrund von nicht dauerhaften Spitzen | Erschließen Sie Anwendungsfälle für KI |
| Beziehungen zu anderen | Es kann vor Ort oder in der Cloud betrieben werden | Es kann HPC- und KI-Workloads aufnehmen | Er nutzt häufig HPC-Infrastrukturen |
Wenn Sie umfassendere digitale Dienste in Betracht ziehen, kann es für Sie auch hilfreich sein, den Unterschied zwischen Infrastruktur- und Anwendungsmodellen wie IaaS, PaaS und SaaS in Cloud-Architekturen zu klären.
„Cloud“ bedeutet nicht automatisch „HPC“. Und „KI“ bedeutet nicht automatisch eine gut durchdachte Architektur.
Ein HPC-Cluster in der Cloud ist also möglich. Eine KI-Last auf einer HPC-Infrastruktur ist üblich. Eine allgemeine Cloud-Umgebung ist hingegen nicht unbedingt für Aufgaben geeignet, bei denen intensive Parallelisierung, Scheduler, Beschleuniger und konstanter Durchsatz erforderlich sind.

Eine der anschaulichsten Möglichkeiten, den Wert von HPC zu verstehen, besteht darin, zu beobachten, was passiert, wenn die Verarbeitungszeiten für das Unternehmen nicht mehr akzeptabel sind.
In einem von ELECTE betreuten Einzelhandelsprojekt musste ein Kunde mit 42 Filialen die wöchentlichen Nachfrageprognosen für 8.600 SKUs neu berechnen, wobei Saisonabhängigkeit, Werbeaktionen, Kalendereffekte und Kannibalisierungseffekte zwischen den Produkten zu berücksichtigen waren. Der bisherige Prozess, der auf sequenziellen Python-Skripten auf einem einzelnen Server basierte, benötigte für einen vollständigen Zyklus etwa 50 Stunden. Nach der Migration auf eine verteilte Architektur mit Parallelisierung nach Produktclustern sank die Dauer auf 4 Stunden.
Der wichtigste Vorteil lag nicht allein in der Geschwindigkeit. Er war organisatorischer Natur. Das Team konnte das Modell viel häufiger neu berechnen, anstatt mit bereits veralteten Prognosen zu arbeiten, wenn diese bei den Category-Managern eintrafen.
Das hat ganz konkrete Auswirkungen auf Entscheidungen:
Im Energiesektor hat ELECTE einen Fall bearbeitet, bei dem der Engpass nicht im klassischen Sinne bei „Big Data“ lag. Der Datensatz umfasste 14 Millionen stündliche Verbrauchsdaten über einen Zeitraum von 36 Monaten, die mit Wetter-, Tarif- und Erzeugungskapazitätsvariablen abgeglichen wurden. Das Prognosemodell erforderte die gleichzeitige Optimierung von über 200 Kombinationen von Hyperparametern über fünf Algorithmen hinweg.
Auf einem einzelnen Rechner mit 32 GB RAM kam der Prozess nach 18 Stunden zum Stillstand, ohne die Rastersuche abzuschließen. Durch die Verteilung der Last auf einen Cluster mit insgesamt 128 vCPUs und 512 GB RAM wurde die gesamte Pipeline in weniger als 3 Stunden abgeschlossen.
Hier wird der Punkt deutlich: Der Wert von HPC ergibt sich nicht nur aus dem Datenvolumen. Er ergibt sich aus der kombinatorischen Komplexität des Problems.
Für Führungskräfte von KMU sind diese Beispiele aussagekräftiger als eine technische Definition. Sie zeigen, dass HPC das Geschäft verbessert, indem es die Zeit zwischen Anfrage und Entscheidung verkürzt.
Ein weiterer Aspekt ist die Reife des Marktes. In Italien gaben im Jahr 2024 nur 5,7 % der Unternehmen mit mindestens 10 Mitarbeitern an, KI zu nutzen, gegenüber einem EU-Durchschnitt von 13,5 % (Daten zur KI-Einführung in italienischen Unternehmen). Diese Lücke ist ein Problem, aber auch eine Chance für diejenigen, die Analytik und KI schneller in die Produktion einführen.
Um zu verstehen, warum das Datenvolumen allein nicht ausreicht, um diese Szenarien zu erklären, ist es hilfreich, klar zwischen den Fällen zu unterscheiden, in denen eine verteilte Analyse tatsächlich erforderlich ist, und den normalen BI-Workloads. Eine gute Grundlage dafür bietet dieser Artikel über Big-Data-Analytik und analytische Komplexität.

Das eigentliche Hindernis für den Einsatz von HPC in KMU besteht nicht darin, zu verstehen, dass man es braucht. Es geht vielmehr darum, es so zu handhaben, dass nicht jedes Analyseprojekt zu einem Infrastrukturprojekt wird.
Hier kommt der Ansatz von ELECTE ins Spiel. Die Plattform trennt die Benutzererfahrung von der technischen Komplexität. Der Nutzer des Systems sieht Daten, Modelle, Berichte und Erkenntnisse. Er muss nicht entscheiden, wo ein Job eingeplant werden soll, wie ein Dataframe verteilt werden soll oder welcher Knoten über genügend freien Speicherplatz verfügt.
Dies verändert die Wirtschaftlichkeit von HPC. Nicht, weil das Rechnen plötzlich kostenlos wird, sondern weil die Betriebskosten aufgrund der Komplexität sinken. In der Praxis erhält der Manager die benötigte Rechenleistung, wann immer er sie benötigt, ohne eine eigene Entwicklungsabteilung aufbauen zu müssen.
Hinter den Kulissen nutzt ELECTE einen Stack, der so konzipiert ist, dass er skaliert werden kann, ohne dass die Logik neu geschrieben werden muss, wenn Datenvolumen oder Komplexität zunehmen:
Für die Prognose laufen die proprietären Modelle von ELECTE auf einer Orchestrierungsebene, die je nach Größe der Eingabedaten und Komplexität der Pipeline automatisch entscheidet, ob die Berechnung lokal durchgeführt oder die Last auf den Cluster verteilt wird.
Praktischer Hinweis: Die beste Entscheidung ist es, sich nicht auf ein einziges Framework festzulegen. Vielmehr sollte eine austauschbare Architektur aufgebaut werden, damit sich die Plattform weiterentwickeln kann, ohne dass der geschäftliche Nutzen neu programmiert werden muss.
Dieser Ansatz hat für ein KMU ganz konkrete Auswirkungen. Das Team kauft keine abstrakte „Leistung“, sondern analytische Kontinuität. Wenn der Anwendungsfall wächst, wächst auch die Infrastruktur. Wenn die Auslastung zurückgeht, bleibt kein überdimensionierter Rechner zurück, der Budget und Aufmerksamkeit beansprucht.

Die richtige Frage lautet nicht: „Wie viel kostet HPC?“. Die richtige Frage lautet: „Welche Konfiguration benötige ich tatsächlich für meine realen Workloads?“.
Aus den Erfahrungen von ELECTE lässt sich eine sehr praktische Regel ableiten: Die Dimensionierung sollte nicht auf den dauerhaften Spitzenbedarf ausgerichtet sein. Die meisten KMU haben zeitweise auftretende Lastspitzen. Prognosen, Quartalsabschlüsse, Ad-hoc-Neuberechnungen und Simulationen erfordern nicht jeden Tag den gleichen Aufwand.
Für einen typischen Kunden mit einem Datensatz zwischen 5 und 50 Millionen Datensätzen können die Infrastrukturkosten zwischen 400 und 1.200 Euro pro Monat liegen, wobei ein Basiscluster den Großteil des Bedarfs abdeckt und zusätzliche Kapazitäten bei Bedarf für Spitzenauslastungen bereitgestellt werden. Der häufigste Fehler ist das Gegenteil: Man kauft Kapazitäten „auf Nummer sicher“ und hat dann fast das ganze Jahr über einen Großteil der Infrastruktur ungenutzt.
Eine hilfreiche Checkliste für die Entscheidung:
Sicherheit darf kein nachträglicher Zusatz sein. Im Jahr 2024 verzeichnete die Nationale Agentur für Cybersicherheit einen Anstieg der Cybervorfälle um 40 % und der bestätigten Vorfälle um 45 % im Vergleich zu 2023 (ACN-Daten, wie in der angegebenen Quelle aufgeführt). Das reicht aus, um eines klarzustellen: Eine Hochleistungs-Rechenplattform muss bereits vom ersten Entwurf an sicher sein.
In geregelten oder empfindlichen Umgebungen sollten zumindest folgende Aspekte überprüft werden:
| Bereich | Führungsfrage |
|---|---|
| Segmentierung | Sind die kritischen Workloads vom Rest der Infrastruktur getrennt? |
| Datenaufbewahrungsort | Weißt du, wo sich die Daten befinden und wo sie verarbeitet werden? |
| Audit | Kannst du nachvollziehen, wer was wann getan hat? |
| Skalierbarkeit | Bleiben bei der Erhöhung der Belastung die gleichen Steuerungen erhalten? |
Integration ist genauso wichtig wie Sicherheit. Bleibt HPC isoliert, wird es letztendlich kaum genutzt. Wird es hingegen in den Datenfluss des Unternehmens eingebunden, wird es zu einem kontinuierlichen Hebel. Um zu verstehen, wie sich fortschrittliche Analysen mit bestehenden Systemen verknüpfen lassen, kann es hilfreich sein, die Optionen für die Daten- und Anwendungsintegration in ELECTE zu prüfen.
High Performance Computing ist für KMU längst kein fernes Konzept mehr. Es ist eine konkrete Lösung für ein sehr häufiges Problem: Man hat Daten, man hat Modelle, man hat wichtige Fragen, aber man hat nicht genug Zeit, um daraus nützliche Entscheidungen zu treffen.
Der entscheidende Punkt, den man sich merken sollte, ist ganz einfach: HPC wird dann wertvoll, wenn die analytische Komplexität zunimmt. Es geht nicht darum, dem Traum vom Supercomputer hinterherzujagen. Vielmehr muss man verstehen, wo parallele Berechnungen den Zyklus zwischen Erkenntnis und Handeln verkürzen können.
Wenn du über deine nächsten Schritte nachdenkst, gehe folgendermaßen vor:
Wenn Prognosen, Optimierung und KI schneller werden, ändert sich auch die Arbeitsweise des Unternehmens. Entscheidungen warten nicht mehr auf Berichte. Die Berichte passen sich zunehmend dem Tempo des Geschäfts an.
Wenn Sie komplexe Daten in klare Erkenntnisse umwandeln möchten, ohne sich um die zugrunde liegende Infrastruktur kümmern zu müssen, entdecken Sie ELECTE, die KI-gestützte Datenanalyseplattform für KMU. Erfahren Sie, wie Sie Berichterstellung, Prognosen und fortgeschrittene Analysen automatisieren können – mit einer Benutzererfahrung, die speziell auf Geschäftsteams zugeschnitten ist und nicht nur auf technische Spezialisten.

.svg)
.svg)
.svg)






