

Du erhältst eine XML-Datei per PEC. Du öffnest sie im Browser, siehst eine Flut von Tags und denkst, das Problem bestehe darin, sie zu „lesen“. Tatsächlich ist das jedoch nur die erste Hürde. Das eigentliche Problem im Unternehmen ist ein anderes: herauszufinden, ob diese Daten korrekt, konsistent und bereit für die Übernahme in deine Berichte sind.
Für viele italienische KMU ist dieses Thema nicht mehr nur im engeren Sinne technischer Natur. Seit die elektronische Rechnungsstellung verpflichtend geworden ist, hat XML Einzug in den Arbeitsalltag der Verwaltung, des Controllings und der Analyse gehalten. Es reicht nicht aus, das Dokument nur anzuzeigen. Man muss zwischen einer lesbaren und einer zuverlässigen Datei unterscheiden können. Man muss erkennen, wann eine schnelle Überprüfung ausreicht und wann Parsing, Validierung und Normalisierung erforderlich sind, bevor die Daten in Excel, in das BI-System oder in eine Analyseplattform geladen werden.
Wenn Sie nach einer praktischen Anleitung zum Lesen von XML-Dateien suchen, ist dies der richtige Weg: Beginnen Sie mit einfachen Methoden, finden Sie heraus, wo es hakt, und bauen Sie dann einen Workflow auf, der rohes XML in geschäftlich nutzbare Daten umwandelt. Auf diese Weise lassen sich Fehler reduzieren und die Zeit zwischen „Ich habe die Datei“ und „Ich habe eine verwertbare Erkenntnis“ verkürzen.
Eine XML-Datei organisiert Daten in einer hierarchischen Struktur. Es gibt ein Hauptelement, verschachtelte Abschnitte, und jeder Block beschreibt eine Information mit einer bestimmten Bedeutung. Für diejenigen, die Verwaltungsprozesse abwickeln, macht dieses Detail den Unterschied zwischen lesbaren und wirklich verwertbaren Daten aus.
Es geht nicht darum, die Datei zu „öffnen“. Es geht darum, herauszufinden, ob diese Datei fehlerfrei in die Kontroll-, Buchhaltungs- und Analyseprozesse integriert werden kann.
Nehmen wir einmal eine elektronische Rechnung als Beispiel. In ein und derselben Datei sind Daten des Lieferanten, Daten des Kunden, Steuerbeträge, Mehrwertsteuer, Artikelzeilen, Zahlungsbedingungen, Bestellnummern und oft auch Ausnahmen enthalten, die das Lesen erschweren. Im XML-Format sind diese Informationen nicht wie in einem gewöhnlichen Dokument untereinander angeordnet. Sie befinden sich an genau festgelegten Positionen, und diese Position erklärt, was sie darstellen.
Für einen Manager ist nicht die Unterscheidung zwischen Tags und Attributen im theoretischen Sinne von Bedeutung, sondern die zwischen isolierten Daten und verlässlichen Daten. Die Angabe „1000,00“ aus dem Zusammenhang gerissen zu lesen, nützt wenig. Liest man sie an der richtigen Stelle in der Datei, lässt sich erkennen, ob es sich um den Gesamtbetrag des Dokuments, die Steuerbemessungsgrundlage, die Steuer oder den Wert einer einzelnen Zeile handelt.
Hier ergibt sich der erste operative Vorteil. XML bewahrt den Kontext der Daten.
Faustregel: Eine XML-Datei richtig zu lesen bedeutet, die Bedeutung des Werts zu überprüfen, nicht nur den Wert selbst.
In Italien hat dieses Thema mit der Verbreitung der elektronischen Rechnungsstellung konkrete Formen angenommen. Im FatturaPA-Format ist XML zum Standard für Steuerunterlagen geworden. Folglich betrifft dessen Auswertung nicht mehr nur die IT-Abteilung. Sie betrifft auch die Verwaltung, das Controlling, den Einkauf und alle, die diese Daten für ihre Entscheidungen nutzen müssen.
In der Praxis sehe ich immer wieder dasselbe Problem. Die Datei ist vorhanden, die Daten sind da, aber die Zeit, die benötigt wird, um sie in nützliche Informationen umzuwandeln, ist viel zu lang. Jemand öffnet die XML-Datei, überprüft sie visuell, kopiert Werte in Excel, korrigiert uneinheitliche Felder, benennt unterschiedlich geschriebene Lieferanten um und versucht, Ausgabenkategorien zu rekonstruieren, die in der Datei nicht in einer für die Analyse geeigneten Form dargestellt sind. Die Kosten sind nicht nur operativer Natur. Es ist verlorene Zeit bis zur Erkenntnisgewinnung.
Bei FatturaPA ist dieses Risiko noch deutlicher. Zwei formal korrekte Dateien können dieselben Analyseprobleme verursachen, wenn in den Zeilenbeschreibungen Unstimmigkeiten vorliegen, die Auftragsreferenzen unvollständig sind oder die Lieferantenstammdaten mit unterschiedlichen Varianten eingegeben werden. In diesem Fall besteht das Problem nicht darin, XML zu lesen. Das Problem besteht vielmehr darin, zu verhindern, dass gültige Steuerdaten zu unzuverlässigen Verwaltungsdaten werden.
Ein häufiger Fehler besteht darin, XML als Anhang zu behandeln, der angezeigt werden soll. Im Unternehmen ist es sinnvoller, XML als strukturierte Datenquelle zu betrachten, die zunächst überprüft werden muss, bevor sie in Berichte, Dashboards und Ausgabenmodelle einfließt. Wird dieser Schritt nicht ordnungsgemäß durchgeführt, diskutiert das Finanzteam am Ende Zahlen, die zwar auf den ersten Blick präzise erscheinen, aber auf inkonsistenten Klassifizierungen beruhen.
Die richtigen Fragen zu Beginn lauten wie folgt:
Das sind sehr konkrete Überprüfungen. Sie dienen dazu, doppelte Lieferanten in den Berichten, falsch interpretierte Mehrwertsteuer, unvollständig ausgefüllte Kostenstellen und langwierige Abstimmungen am Monatsende zu vermeiden.
Hier zeigt sich die Kluft zwischen technischer Auswertung und geschäftlichem Nutzen. Ein Parser liest die Datei ein. Ein gut konzipierter Prozess liefert saubere, vergleichbare und analysefertige Daten. Plattformen wie ELECTE wurden entwickelt, um genau diese Lücke zu schließen und den manuellen Aufwand zu reduzieren, der zwischen dem empfangenen XML und den für bessere Entscheidungen nützlichen Erkenntnissen steht.
Für schnelle Überprüfungen einer einzelnen Datei braucht man keine Parser oder Bibliotheken. Man muss sich darüber im Klaren sein, ob man eine visuelle Überprüfung einiger weniger Felder durchführt oder ob man bereits Daten bearbeitet, die später in der Buchhaltung, im Berichtswesen oder im Controlling landen. Dieser Unterschied ist entscheidend, insbesondere bei FatturePA. Eine heute hastig durchgeführte Überprüfung kann morgen zu einer fehlerhaften Zeile im Lieferantendatensatz führen.

Browser, Texteditoren und spezielle Viewer lösen ein ganz konkretes Problem: den Inhalt schnell zu lesen, ohne einen technischen Workflow einrichten zu müssen. Für eine einzelne Datei reicht das oft aus. Sie können eine XML-Datei in Chrome, Edge oder Firefox öffnen, um die Struktur zu betrachten, oder Notepad, WordPad oder TextEdit verwenden, wenn Sie die Tags direkt untersuchen möchten. Bei elektronischen Rechnungen sorgt ein spezieller Viewer dafür, dass Kopfzeilen, Belegzeilen, Steuerbetrag und Mehrwertsteuer besser lesbar sind.
Der entscheidende Punkt ist folgender:
| Instrument | Nützlich für | Hauptnachteil |
|---|---|---|
| Browser | Schnelle Sichtprüfung der Konstruktion | Es wird keine Konsistenz zwischen Feldern und Abschnitten überprüft |
| Texteditor | Direkte Überprüfung der Tags | Bei langen oder verschachtelten Dateien wird es unübersichtlich |
| Excel | Vorabprüfung in Tabellenform | Es geht schlecht mit Hierarchien und Wiederholungen um |
| Spezieller Viewer | Bessere Lesbarkeit von Rechnungen und Steuerbelegen | Die Daten werden nicht für Analysen oder Automatisierungen aufbereitet |
Wenn Sie das Dokumentdatum, die Umsatzsteuer-Identifikationsnummer, den Rechnungsbetrag oder das Vorhandensein von Anhängen überprüfen müssen, sind diese Tools dafür geeignet.
Wenn es hingegen darum geht, Anbieter zu vergleichen, Ausgaben zu klassifizieren oder ein Dashboard zu füllen, verlangsamt die reine Anzeige der Daten die Arbeit und lässt zu viel Raum für manuelle Fehler. Das ist die klassische Lücke zwischen dem Betrachten einer Datei und dem Erhalten einer zuverlässigen Angabe in angemessener Zeit.
Das Öffnen einer XML-Datei bedeutet nicht, dass die Daten, die Sie in den Berichten verwenden werden, validiert werden.
Ein weiterer praktischer Aspekt betrifft den Umfang. Zehn Zeilen lassen sich noch von Hand prüfen. Hunderte von FatturePA hingegen nicht. In diesem Fall lohnt es sich bereits, über einen wiederholbaren Arbeitsablauf oder über Tools nachzudenken, die den Inhalt strukturiert auswerten, beispielsweise über eine API zur integrierten Erfassung und Verwaltung von Steuerdokumenten.
In Italien besteht das immer wiederkehrende Problem nicht darin, ein .xml, aber zu wissen, was man tun soll, wenn ein .xml.p7m per PEC. Man muss zwischen einfachen XML-Dateien und digital signierten Dateien unterscheiden. Im zweiten Fall sind Tools erforderlich, die die Signatur lesen, den Inhalt extrahieren und das korrekte XML anzeigen können, wie erklärt Dieser Leitfaden befasst sich mit XML und XML P7M im Zusammenhang mit der PEC.
Hier kosten Fehler Zeit:
Für einen Verwaltungsmitarbeiter ist die nützlichste Reihenfolge ganz einfach:
Diese Methoden erfüllen ihren Zweck bei der Erstprüfung. Sie lösen jedoch nicht das eigentliche Problem im Unternehmen: die Umwandlung von oft unregelmäßigen oder uneinheitlichen Steuer-XML-Dateien in saubere und vergleichbare Daten, ohne dabei die Zeitspanne zwischen dem Eingang des Dokuments und der Verfügbarkeit der nutzbaren Informationen zu verlängern.
Wenn sich die Dateien häufen, ist die manuelle Bearbeitung nicht mehr tragbar. An diesem Punkt ist das Einlesen von XML-Dateien per Programmierung keine elegante Lösung mehr. Dies ist der erste Schritt, um sich wiederholende Aufgaben, Kopierfehler und inkonsistente Datensätze zu vermeiden.

Ein solider Ansatz zum Lesen von XML folgt immer derselben Logik: Parsen, Normalisierung, gezielte Extraktion. In den Java- und Android-Tutorials verläuft der korrekte Ablauf wie folgt: parse(), durch die Normalisierung der Baumstruktur mit doc.getDocumentElement().normalize() und dann durch die Wiederherstellung der Felder mit getElementsByTagName, eine stabilere Methode als die einfache Anzeige in einem Texteditor, wie folgt gezeigt wird Diese technische Anleitung zum Auslesen von XML-Daten.
Diese Abfolge ist wichtiger als die von dir gewählte Programmiersprache. Wenn du die Normalisierung überspringst, wenn du zu naiv nach Knoten suchst oder wenn du davon ausgehst, dass ein Tag immer nur einmal vorkommt, wird dein Skript bei einigen Dateien funktionieren, bei den wirklich wichtigen jedoch fehlschlagen.
Bei Projekten, die später mit externen Systemen kommunizieren müssen, kann es sinnvoll sein, einen reproduzierbaren und dokumentierten Extraktionsablauf zu erstellen. Wenn Sie an Anwendungsintegrationen arbeiten, bietet die Dokumentation zu den ELECTE-APIs mit verifiziertem Postman-Profil eine nützliche Grundlage, insbesondere um zu verstehen, wie ein bereits bereinigter Datensatz mit nachfolgenden Prozessen verknüpft werden kann.
Im Folgenden findest du einige einfache Beispiele. Das Ziel ist nicht, jeden Fall abzudecken, sondern dir die grundlegende Logik zu verdeutlichen: eine Datei öffnen, einen Knoten finden, einen Wert ausgeben.
import xml.etree.ElementTree as ETtree = ET.parse("fattura.xml")root = tree.getroot()numero = root.find(".//Numero")if numero is not None:print(numero.text)Python ist oft die schnellste Wahl für Prototypen, Transformationen und schlanke Pipelines. Es eignet sich hervorragend, wenn Sie viele XML-Dateien einlesen, einige Felder extrahieren und diese als CSV- oder JSON-Dateien speichern müssen.
const xmlString = `<fattura><Numero>123</Numero></fattura>`;const parser = new DOMParser();const xmlDoc = parser.parseFromString(xmlString, "application/xml");const numero = xmlDoc.getElementsByTagName("Numero")[0];console.log(numero.textContent);Dieser Ansatz eignet sich für schnelle Tests auf der Seite oder kleine interne Tools. Er ist gut für schlanke Benutzeroberflächen geeignet, weniger jedoch für strukturierte Backoffice-Abläufe.
const fs = require("fs");const xml2js = require("xml2js");const xml = fs.readFileSync("fattura.xml", "utf8");xml2js.parseString(xml, (err, result) => {if (err) throw err;console.log(result.fattura.Numero[0]);});Wenn Sie serverseitig arbeiten und Automatisierungen erstellen möchten, ist Node.js nach wie vor eine praktische Wahl. Der Vorteil besteht darin, dass sich das Auslesen von XML-Dateien problemlos in Dateisysteme, Verarbeitungswarteschlangen und interne Dienste integrieren lässt.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse("fattura.xml");doc.getDocumentElement().normalize();NodeList lista = doc.getElementsByTagName("Numero");if (lista.getLength() > 0) {System.out.println(lista.item(0).getTextContent());}Java kommt häufig in Unternehmens-, Verwaltungs- und Middleware-Kontexten zum Einsatz. Dabei geht es nicht nur darum, die Daten zu lesen, sondern dies auf vorhersehbare und wartbare Weise zu tun.
library(XML)doc <- xmlParse("fattura.xml")numero <- xpathSApply(doc, "//Numero", xmlValue)print(numero)R ist sinnvoll, wenn das Parsing Teil einer analytischen Arbeit ist. Wenn dein nächster Schritt eine statistische Analyse oder eine Datenaufbereitung ist, kannst du alles in derselben Umgebung behalten.
Wenn dein Team jede Woche dieselben Dateien öffnet und dieselben Überprüfungen durchführt, befindest du dich bereits im Bereich der Automatisierung.
Der eigentliche Gewinn besteht nicht darin, „XML mit Code zu lesen“. Es geht darum, den Menschen eine mechanische Arbeit abzunehmen und einen Workflow aufzubauen, der konsistente Datensätze liefert.
Die ernsthaften Probleme beginnen, wenn es sich nicht mehr um eine einzige Datei handelt. Eine einzelne FatturaPA lässt sich fast immer bewältigen. Schwierigkeiten treten auf, wenn man Dokumente aus mehreren Monaten, von verschiedenen Lieferanten, mit uneinheitlich ausgefüllten Feldern und eingebetteten Anhängen zusammenführen muss.
In italienischen KMU ist nicht die einzelne „Mega-Datei“ der häufigste Fall, sondern der Datensatz. Ein jährlicher Export von Eingangsrechnungen kann eine Struktur mit über 380.000 Knoten aus 4.200 Rechnungen erzeugen, bestehend aus Kopfzeilen, Detailzeilen, Zahlungsdaten und Base64-Anhängen. In solchen Szenarien besteht das Problem nicht darin, das Dokument zu öffnen, sondern heterogene XML-Daten in einen konsistenten Datensatz umzuwandeln.
Hier kommt eine technische Entscheidung ins Spiel, die sich auf das Geschäft auswirkt. In der .NET-Umgebung weist Microsoft darauf hin, dass XmlDocument das Dokument in den Arbeitsspeicher lädt und sich zum Lesen und Bearbeiten eignet, während es bei großen Dateien oder rein lesbaren Operationen ratsam ist, auf effizientere Ansätze wie Streaming-Parser oder XPathDocument zurückzugreifen, um einen übermäßigen RAM-Verbrauch zu vermeiden, wie in der Microsoft-Dokumentation zum Lesen von XML mit XmlDocument und XPathDocument angegeben.
In der Praxis:
Der Kompromiss ist einfach. Mit dem In-Memory-Modell lässt sich die Entwicklung beschleunigen. Das Streaming-Modell bewährt sich in der Produktion besser, wenn die Dateien zahlreich oder groß werden.
Viele Teams beschränken sich auf die XSD-Validierung. Das ist zwar nützlich, reicht aber nicht aus. Eine Datei kann dem Schema entsprechen und dennoch im weiteren Verlauf fehlerhafte Daten liefern.
Typische Beispiele aus der operativen Arbeit:
| Art der Kontrolle | Was wird überprüft? | Wozu dient es? |
|---|---|---|
| Strukturell | Tags, Format, Hierarchie | Vermeide Parsing-Fehler |
| Semantisch | Logische Konsistenz der Daten | Vermeide falsche Analysen |
| In Betrieb | Vorhandensein von Feldern, die für das Berichtswesen nützlich sind | Vermeide unbrauchbare Datensätze |
Der heimtückischste Fall ist folgender: Der „ImportoTotaleDocumento“ ist formal gültig, stimmt aber nicht mit der Summe der Zeilen überein, was möglicherweise auf Rundungsregeln im Buchhaltungssystem des Lieferanten zurückzuführen ist. Oder es handelt sich um formal zulässige Umsatzsteuernummern, die jedoch nicht mit der Art des Geschäftsvorfalls übereinstimmen.
Eine formal korrekte Datei kann dennoch Ihr Berichtswesen verfälschen.
Es gibt noch eine weitere bekannte Falle in den FatturaPA-Rechnungen. Das Tag „DatiBeniServizi“ enthält freie Beschreibungen. Dieselben Kosten können auf viele verschiedene Arten dargestellt werden – mit klaren, abgekürzten oder kryptischen Texten. Wenn Sie keinen Normalisierungsprozess einführen, wird jede Analyse nach Ausgabenkategorien unzuverlässig.
Aus diesem Grund ist das Einlesen der Datei bei seriösen Datenströmen nur die erste Stufe. Die zweite Stufe besteht immer aus einer Reihe von Regeln zur Konsistenz und Sauberkeit. Dort wird die Datenqualität gesichert, nicht im Parser.
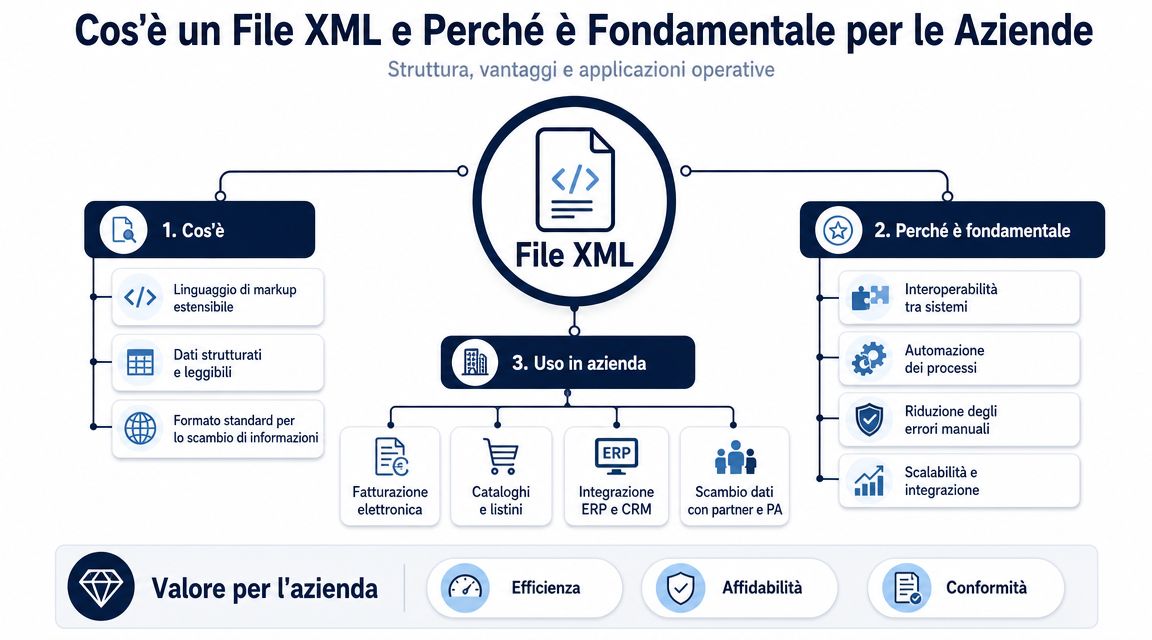
Eine korrekt eingelesene XML-Datei ist noch kein brauchbarer Datensatz. Es handelt sich um ein strukturiertes Dokument. Um Analysen, Vergleiche, Gruppierungen und Dashboards zu erstellen, muss man sie fast immer in ein Format übertragen, das sich leichter verarbeiten lässt.
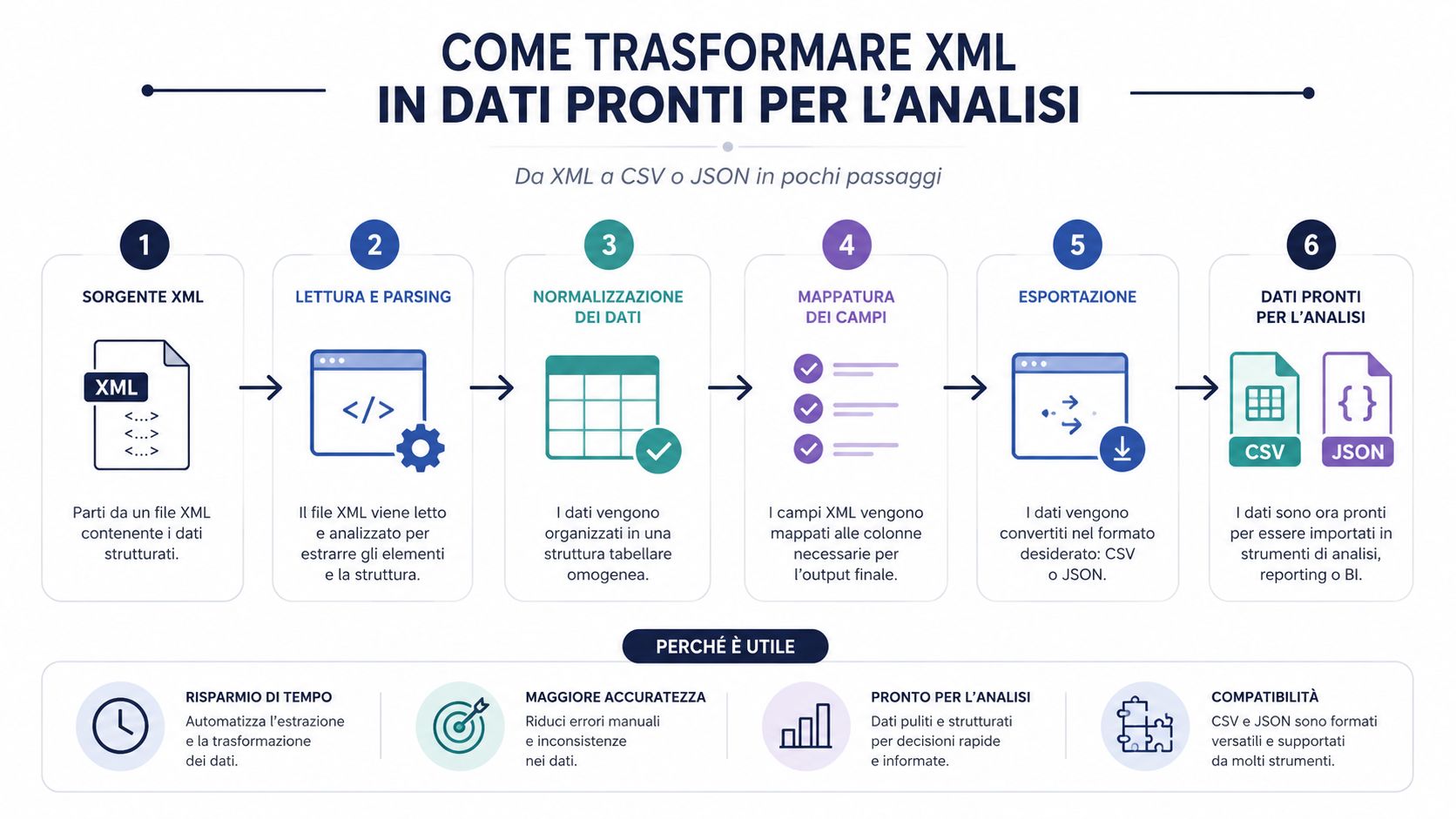
Das ist der Punkt, den viele Prozesse unterschätzen. Der Engpass liegt selten im reinen Parsing. Eine ordentliche Bibliothek liest XML in kürzester Zeit ein. Die Zeit geht vielmehr bei der Interpretation der Struktur, der Extraktion der relevanten Felder, der Bereinigung, der Normalisierung und dem Laden in ein Analysetool verloren.
Aus diesem Grund ist die Konvertierung in CSV oder JSON kein bloßer Komfort. Es handelt sich um einen zentralen Arbeitsschritt. Wenn du diesen Schritt überspringst und direkt mit der Rohdatei arbeitest, landest du fast immer bei manuellen Überprüfungen, improvisierten Spalten und Logiken, die sich nur schwer reproduzieren lassen.
Eine nützliche Hilfe für alle, die häufig mit XML und Tabellenkalkulationen arbeiten, ist diese Anleitung, wie man XML auf übersichtlichere Weise in Excel überträgt.
Das richtige Format hängt davon ab, wie du die Daten später verwenden wirst.
CSV eignet sich gut, wenn Sie eine Zeile pro Dokument oder eine Zeile pro Rechnungsposition wünschen und anschließend Excel, Power Query oder BI verwenden möchten.
Python-Beispiel:
import xml.etree.ElementTree as ETimport csvtree = ET.parse("Rechnung.xml")root = tree.getroot()with open("Rechnungen.csv", "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(["Nummer", "Datum"])Nummer = root.findtext(".//Numero")data = root.findtext(".//Data")writer.writerow([numero, data])Der Vorteil liegt in der Einfachheit. Die Einschränkung besteht darin, dass man sorgfältig entscheiden muss, wie die Hierarchie abgeflacht werden soll. Wenn eine Rechnung mehrere Detailzeilen enthält, muss man sich klar über die Granularität und den Verknüpfungsschlüssel entscheiden.
JSON eignet sich am besten, wenn du einen Teil der hierarchischen Struktur beibehalten möchtest.
JavaScript-Beispiel:
const record = {numero: "123",data: "2024-01-15",righe: [{ descrizione: "Servizio", importo: "100.00" }]};console.log(JSON.stringify(record, null, 2));Verwende dies, wenn dein nächster Schritt eine API, ein Data Lake oder eine Anwendung ist, die gut mit verschachtelten Objekten funktioniert.
Hier ist eine hilfreiche Faustregel:
Die XML-Datei ist der Container. CSV und JSON sind die Formate, die den Inhalt tatsächlich verarbeitbar machen.
Wenn du die Zeit bis zur Erkenntnis verkürzen möchtest, lohnt es sich, hier methodisch vorzugehen. Nicht darin, einen benutzerfreundlicheren Visualisierer zu finden, sondern darin, eine stabile und wiederholbare Transformation zu definieren.
Sobald die Datei gelesen, validiert und aufbereitet wurde, ändert sich der Charakter der Arbeit. Man kämpft nicht mehr mit den Tags. Endlich kann man sich mit Kosten, Abweichungen, Lieferanten, Ausgabenkategorien und operativen Trends befassen.
In der Praxis liegt der Wert nicht in der Zeit, die für das Parsen benötigt wird. Er liegt in der Zeit, die zwischen der Rohdatei und einer Information liegt, auf deren Grundlage man eine Entscheidung treffen kann. Bei einem manuellen Arbeitsablauf muss eine Person das Dokument öffnen, die Struktur verstehen, die Felder extrahieren, die Werte bereinigen, Texte normalisieren und anschließend Berichte erstellen. Das ist ein anfälliger Prozess.
Ein klassisches Beispiel in FatturaPA ist der Freitext in „DatiBeniServizi“. Dieselbe Dienstleistung kann von verschiedenen Anbietern auf viele unterschiedliche Weisen beschrieben werden. Wenn Sie diese Daten ohne einheitliche Zuordnung importieren, führt die Analyse nach Kostenkategorien zu unnötigen Aggregationen.
Aus diesem Grund ist vor der Analytics-Plattform eine Datenaufbereitungsschicht erforderlich:
Wenn diese Phase gut durchgeführt wird, funktioniert jede Analyseplattform besser. Wenn Sie sich näher mit den entscheidungsrelevanten und visuellen Aspekten dieses Schritts befassen möchten, ist die Anleitung zum Erstellen von Geschichten mit Daten hilfreich, da sie zeigt, wie aus einem bereinigten Datensatz eine für Entscheidungsträger nützliche Erzählung wird.
An diesem Punkt ist die XML-Datei kein technisches Problem mehr, sondern wird zum Ausgangsmaterial für Erkenntnisse. Ein gut aufbereiteter Datensatz kann als Grundlage für Ausgabenanalysen, Trendbeobachtungen, die Aufdeckung von Abweichungen und die Auswertung von Ausnahmen dienen.
Um eine geeignete Plattform für diese letzte Etappe auszuwählen, kann es hilfreich sein, die Funktionen einer modernen Business-Analytics-Software mit rein manuellen, auf Tabellen und Pivot-Tabellen basierenden Arbeitsabläufen zu vergleichen.
Das entscheidende Kriterium ist hier nicht: „Kann es XML öffnen?“. Das ist das Mindeste. Die relevante Frage lautet anders:
| Frage | Warum es wichtig ist |
|---|---|
| Die Daten sind bereits bereinigt | Vermeiden Sie präzise Erkenntnisse auf der Grundlage falscher Daten |
| Die Kategorien sind konsistent | Vergleichen Sie wirklich Anbieter und Zeiträume? |
| Die Unregelmäßigkeiten fallen sofort auf | Reduzieren Sie den Zeitaufwand für manuelle Kontrollen |
| Der Bericht ist für die Bereiche Wirtschaft und Finanzen verständlich. | Beschleunigen Sie die Entscheidungsfindung |
Der Unterschied zwischen einem unausgereiften und einem ausgereiften Prozess liegt nicht in der Fähigkeit, XML-Dateien zu lesen. Er liegt vielmehr in der Fähigkeit, diese in eine zuverlässige Datenbank umzuwandeln, die das Team nicht dazu zwingt, jedes Mal dieselbe Arbeit erneut zu erledigen.
Wenn Sie XML-Dateien auf eine für Ihr Unternehmen sinnvolle Weise auswerten möchten, sollten Sie diese Checkliste beachten. Sie ist konkreter als jede technische Definition und hilft Ihnen dabei, die richtige Methode auszuwählen, ohne Zeit zu verlieren.
Verwenden Sie nicht immer denselben Ansatz. Browser, Editoren und Anzeigeprogramme eignen sich gut für schnelle Überprüfungen. Parser und Skripte sind erforderlich, wenn die Datei wiederholte Prozesse versorgen soll. Wenn Sie die Anzeige mit der Datenverarbeitung verwechseln, besteht die Gefahr, dass Sie Berichte auf einer unsicheren Grundlage erstellen.
Die Dateien .xml.p7m erfordern einen speziellen Schritt bei der Signaturverwaltung. Wenn der Inhalt von einer PEC-Adresse stammt, ist diese Überprüfung nicht nebensächlich. Sie ist Teil der korrekten Auslegung des Dokuments.
Ein eingehaltenes Schema garantiert noch keinen fehlerfreien Datensatz. Logische Unstimmigkeiten, wie nicht übereinstimmende Summen oder mehrdeutige Steuerklassifizierungen, sind es, die die Analyse am häufigsten zunichte machen. Die semantische Prüfung ist das, was eine „akzeptable“ Datei von zuverlässigen Daten unterscheidet.
CSV und JSON sind keine rein kosmetische Maßnahme. Sie sind der Punkt, an dem XML für Analysetools, Tabellenkalkulationen, Pipelines und Berichte verwertbar wird. Je früher Sie diese Transformation definieren, desto eher reduzieren Sie manuellen Aufwand und Improvisation.
Dein Ziel ist es nicht, XML-Dateien zu lesen. Du möchtest nützliche Erkenntnisse gewinnen, ohne das System mit unbereinigten Daten zu überfrachten. Wenn der Datenfluss keinen konsistenten Datensatz liefert, liegt das Problem nicht im endgültigen Dashboard. Es liegt viel weiter oben in der Kette.
In der Praxis kannst du diese Mini-Checkliste vor jedem neuen Projekt nutzen:
Wenn Sie bereits aufbereitete Daten in klare und umsetzbare Erkenntnisse umwandeln möchten, unterstützt ELECTE KMU dabei, den Weg vom bereinigten Datensatz zum intelligenten Reporting zu beschreiten – mit einem Ansatz, der auch für nicht-technische Teams leicht verständlich ist. Dies ist der schnellste Weg, um die Lücke zwischen Betriebsdaten und Entscheidungsfindung zu schließen.

.svg)
.svg)
.svg)
.webp)





