

Deine Daten erzählen bereits eine Geschichte. Das Problem ist nur, dass sie oft zu leise sprechen.
Jeden Tag sammeln KMU Kundenfeedback, Bestellungen, Support-Tickets, Finanztransaktionen, geschäftliche E-Mails und CRM-Notizen. All diese Daten enthalten nützliche Hinweise. Einige deuten darauf hin, dass ein Kunde kurz davor steht, abzuwandern. Andere lassen ein operatives Risiko erkennen. Wieder andere zeigen, welche Produkte an Fahrt gewinnen oder an Schwung verlieren. Ohne eine klare Methode bleiben diese Hinweise jedoch nur Rauschen.
Unter den Algorithmen, die dabei helfen, Ordnung in dieses Chaos zu bringen, nehmen naive Bayes-Klassifikatoren einen besonderen Platz ein. Sie sind logisch leicht zu verstehen, schnell zu trainieren und oft effektiver, als der Name „naiv“ vermuten lässt. Sie sind zwar nicht für jedes Szenario die richtige Wahl, bieten aber bei vielen realen Geschäftsproblemen eine seltene Balance zwischen Geschwindigkeit, Interpretierbarkeit und nützlichen Ergebnissen.
Wenn du im Geschäftsleben tätig bist, musst du kein Wissenschaftler werden, um sie zu verstehen. Du musst wissen, wie sie funktionieren, warum sie auch dann gut funktionieren, wenn sie die Realität stark vereinfachen, und in welchen Fällen sie dir helfen können, bessere Entscheidungen zu treffen. Genau hier lohnt es sich, einen Moment innezuhalten.
Viele Unternehmen suchen nach ausgefeilten Modellen, obwohl das Problem in erster Linie ein zuverlässiges und benutzerfreundliches Modell erfordert. Aus demselben Grund setzt sich in der Finanzbranche, im Einzelhandel oder im Kundenservice oft der klarste Prozess durch, nicht der theoretisch eleganteste.
Naive-Bayes-Klassifikatoren basieren auf einer ganz konkreten Idee: Wenn man einige Hinweise zu einem neuen Fall hat, kann man mit hoher Wahrscheinlichkeit einschätzen, zu welcher Kategorie er gehört. Wenn eine E-Mail bestimmte Wörter enthält, könnte es sich um Spam handeln. Wenn eine Transaktion bestimmte Muster aufweist, könnte sie eine Überprüfung erfordern. Wenn eine Bewertung bestimmte Begriffe verwendet, könnte dies auf Zufriedenheit oder Unzufriedenheit hindeuten.
Das Wort „bayesianisch“ lässt an komplexe Formeln denken. Tatsächlich ist der Kern der Methode intuitiv. Man nimmt das, was man bereits weiß, fügt neue Erkenntnisse hinzu und aktualisiert seine Einschätzung. Es ist eine strukturierte Art, unter Unsicherheit zu argumentieren – genau das, was Manager jeden Tag tun, nur dass es durch einen Algorithmus systematisiert wird.
Erstaunlich ist, dass dieser Ansatz auch in modernen Umgebungen mit großen Datenmengen und schnellen Entscheidungen weiterhin gut funktioniert. Nicht, weil er die Welt perfekt beschreibt, sondern weil er das nützliche Signal mit sehr geringem Rechenaufwand vom Rauschen trennt.
Bei geschäftlichen Problemen lautet die richtige Frage nicht: „Welches ist das ausgefeilteste Modell?“, sondern: „Welches Modell liefert mir zuverlässige Entscheidungen in einem Zeitrahmen, der mit der Praxis vereinbar ist?“
Aus diesem Grund sind naive Bayes-Klassifikatoren nach wie vor wichtig. Sie helfen dir beim Klassifizieren, Filtern, Segmentieren und Priorisieren. Und sie ermöglichen es dir, Wahrscheinlichkeitsberechnungen in den Entscheidungsprozess einzubeziehen, ohne jedes Projekt in eine technische Baustelle zu verwandeln.
Das Grundprinzip ist der Satz von Bayes. Vereinfacht ausgedrückt besagt er Folgendes: Man geht von einer Ausgangswahrscheinlichkeit aus und aktualisiert diese, sobald neue Informationen vorliegen.
In der Sprache der Daten lautet die Formel wie folgt: P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y). Das bedeutet, dass die Wahrscheinlichkeit einer Klasse bei einer gegebenen Menge von Signalen von zwei Faktoren abhängt. Der erste ist die Ausgangswahrscheinlichkeit der Klasse. Der zweite ist, inwieweit jedes einzelne Signal mit dieser Klasse vereinbar ist.
Übertragen auf ein Beispiel aus der Wirtschaft: Du musst herausfinden, ob eine E-Mail Spam ist oder nicht. Du hast eine allgemeine Wahrscheinlichkeit, dass eine eingehende E-Mail Spam ist. Dann achtest du auf bestimmte Wörter wie „Angebot“, „kostenlos“ oder „hier klicken“. Jedes dieser Wörter beeinflusst die endgültige Beurteilung.
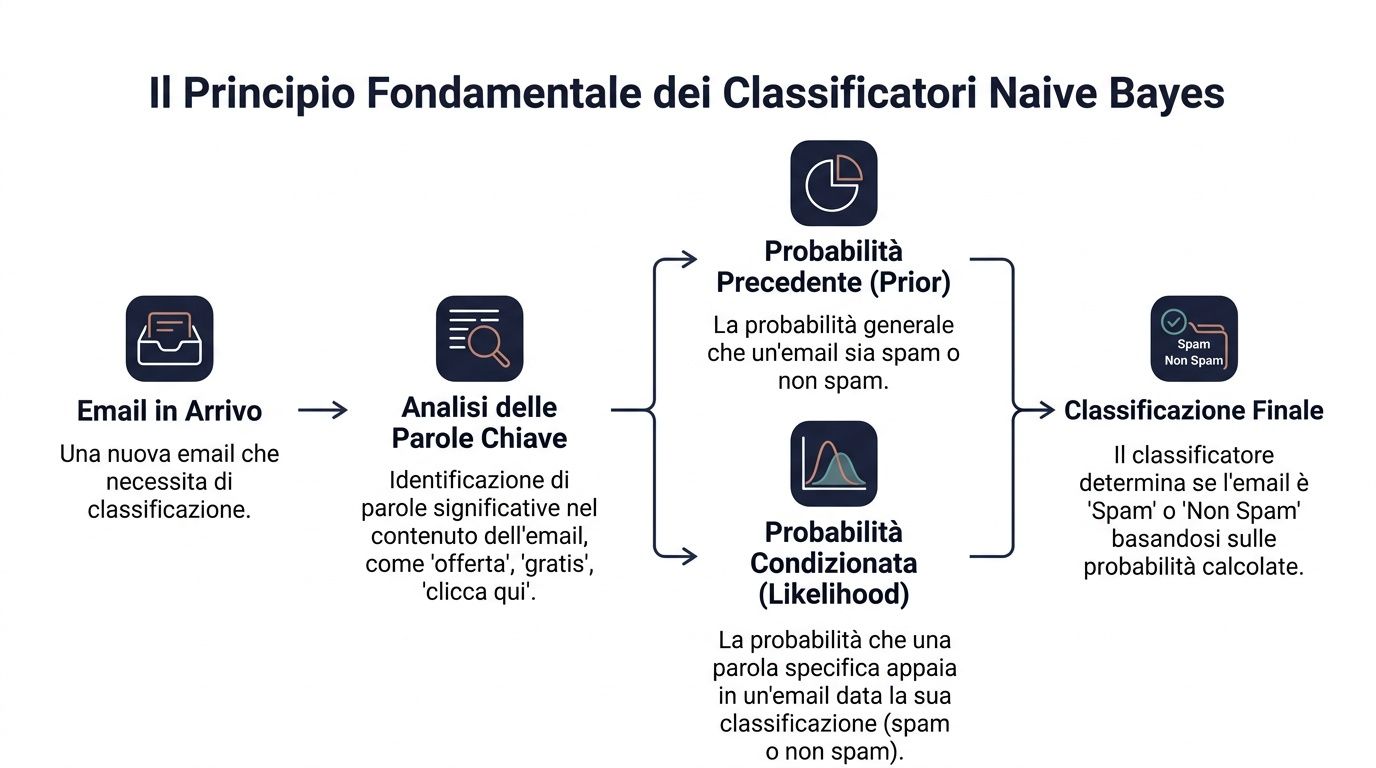
Ein Manager tut jeden Tag etwas Ähnliches. Er trifft Entscheidungen nie aus dem Nichts. Er geht von einem Grundkontext aus und fügt Hinweise hinzu. Ein Kunde, der bisher regelmäßig gekauft hat, weist ein bestimmtes Ausgangsprofil auf. Wenn er dann aufhört, E-Mails zu öffnen, den Wert seiner Bestellungen reduziert und ein kritisches Ticket eröffnet, ändert sich deine Einschätzung.
Der Begriff „naiv“ bezeichnet eine bestimmte Annahme. Das Modell behandelt die Merkmale so, als seien sie voneinander unabhängig, da die Klasse bekannt ist.
In der Praxis solltest du bei der Klassifizierung einer E-Mail jedes Wort als separaten Hinweis betrachten. Versuche nicht, alle komplexen Beziehungen zwischen den Begriffen abzubilden. Das ist eine starke Vereinfachung. In der Realität treten viele Wörter gemeinsam auf, und viele geschäftliche Verhaltensweisen hängen miteinander zusammen.
Doch gerade diese Entscheidung macht das Modell so leicht. Es muss kein kompliziertes Netz von Abhängigkeiten lernen. Es muss einfachere Wahrscheinlichkeiten abschätzen und diese effizient kombinieren.
Faustregel: Naive Bayes non cerca di ricostruire l’intero mondo. Cerca di prendere decisioni utili con poche assunzioni e molta velocità.
Hier entsteht oft ein Missverständnis. Viele lesen „naive Annahme“ und schließen daraus, es handele sich um ein „schwaches Modell“. Das ist nicht der Fall. Ein Modell kann stark vereinfacht werden und dennoch aussagekräftig bleiben, wenn die Vereinfachung das erfasst, was für die Entscheidungsfindung wichtig ist.
Im Jahr 2004 lieferte eine theoretische Analyse stichhaltige Gründe für die Wirksamkeit von Naive-Bayes-Klassifikatoren trotz der Annahme der Unabhängigkeit und erklärte zudem, warum diese den asymptotischen Fehler schneller erreichen können als die logistische Regression. Im gleichen Anwendungsbereich erzielen sie bei der Spam-Filterung eine Genauigkeit von über 99 % und lassen sich auf Millionen von Dokumenten skalieren, wie im Eintrag zu den Naive-Bayes-Klassifikatoren beschrieben.
Dieser Punkt ist für ein Unternehmenspublikum wichtig. Der Wert eines Algorithmus liegt nicht nur in der Endpunktzahl. Er liegt auch in seiner Fähigkeit, sich schnell zu trainieren, sich an umfangreiche Datensätze anzupassen und interpretierbar zu bleiben.
Wenn Texte, Kategorien, Tags oder Signale verstreut sind, funktionieren naive Bayes-Klassifikatoren gut, weil:
Es gibt jedoch zwei Punkte, die man beachten sollte.
Aus diesem Grund sollte Naive Bayes als sehr effektives Werkzeug für schnelle Klassifizierungsprobleme betrachtet werden und nicht als universeller Zauberstab. In vielen praktischen Anwendungsfällen ist es jedoch eine der klügsten Möglichkeiten, um den Einstieg zu finden.
Ein häufiger Irrtum ist es, von Naive-Bayes-Modellen so zu sprechen, als handele es sich um ein einziges, in jeder Situation identisches Modell. Tatsächlich gibt es verschiedene Varianten, die für unterschiedliche Datentypen konzipiert sind.
Die richtige Wahl hängt davon ab, in welcher Form dir die Daten vorliegen. Wenn du die falsche Variante wählst, kann das Modell zwar trotzdem eine Vorhersage erstellen, aber es wendet nicht die für dein Problem am besten geeignete Methode an.
Gaussian Naive Bayes eignet sich am besten, wenn die Merkmale kontinuierlich sind. Denk dabei an den durchschnittlichen Transaktionsbetrag, das Kundenalter, die durchschnittliche Zeit zwischen zwei Käufen, die Stückmarge oder den Rechnungswert.
Das Modell geht hier davon aus, dass die Werte innerhalb jeder Klasse einer Gaußschen Verteilung folgen. Du solltest das nicht als rein theoretische Vorgabe betrachten. Behalte einfach den praktischen Gedanken im Hinterkopf: Für jede Klasse schätzt das Modell einen typischen Mittelwert und eine Streuung.
Dieser Ansatz ist nützlich, wenn du Fälle wie die folgenden klassifizieren möchtest:
In einem scikit-learn-Benchmark mit einem Datensatz, der italienischen E-Commerce-Daten ähnelt, erreichte ein Naive-Bayes-Modell bei 1000 Beispielen eine Genauigkeit von 95 % und benötigte dabei 15% weniger Trainingszeit als die logistische Regression . Der angegebene Vergleich lautet 0,01 s gegenüber 0,1 s auf einer Standard-CPU, dank des Closed-Loop-Trainings, wie im Kapitel von Jake VanderPlas über „In Depth Naive Bayes Classification“ gezeigt.
Für ein Unternehmen geht es nicht um die Dezimalstelle. Der Punkt ist, dass diese Variante ohne lange Trainingszeiten und ohne aufwendige Infrastruktur gute Ergebnisse liefern kann.
Wenn du mit Texten, Tickets, Bewertungen oder Kommentaren arbeitest, ist Multinomial Naive Bayes oft die naheliegende Wahl. Hier dienen Zählungen oder Häufigkeiten als Merkmale. Im Grunde genommen zählt das Modell, wie oft Wörter oder Begriffe vorkommen.
Es ist das klassische Szenario von:
Der Grund, warum es gut funktioniert, ist ganz konkret. In Geschäftstexten kann der Wortschatz zwar umfangreich sein, doch jedes Dokument enthält nur einen kleinen Teil der möglichen Wörter. Die Daten sind verstreut. Multinomial Naive Bayes kommt gerade mit dieser Art von Struktur gut zurecht.
In einer Studie mit 100.000 italienischen Tweets, die nach ihrer Stimmung gekennzeichnet waren, erzielte der Multinomial Naive Bayes-Algorithmus einen F1-Score von 0,88 und war dabei zehnmal schneller als SVM, wie im Leitfaden von GeeksforGeeks zu Naive-Bayes-Klassifikatoren berichtet wird.
Um sich das leicht zu merken, stell dir Folgendes vor: Wenn deine Daten wie ein Dokument voller gezählter Wörter aussehen, ist die Multinomialverteilung fast immer die erste Option, die du prüfen solltest.
Wenn Ihr Unternehmen große Textmengen auswerten muss, lautet die Frage nicht nur: „Wie genau ist das Modell?“, sondern auch: „Wie viele Anfragen kann es klassifizieren, ohne das Team auszubremsen?“
Bernoulli Naive Bayes arbeitet mit binären Merkmalen. Es zählt nicht, wie oft ein Signal auftritt. Es zählt nur, ob es vorhanden ist oder nicht.
Diese Variante ist nützlich, wenn das Vorhandensein eines Attributs wichtiger ist als dessen Häufigkeit. Einige Beispiele aus der Praxis:
Das ist ein sehr nützlicher Ansatz, wenn man komplexe Phänomene in einfach zu überwachende Ja/Nein-Indikatoren umwandeln möchte. Bei der Stimmungsanalyse kann es beispielsweise wichtiger sein, dass ein negatives Wort vorkommt, als wie oft es wiederholt wird.
Bernoulli ist nicht „weniger ausgereift“ als die Multinomialverteilung. Es eignet sich einfach besser, wenn die Daten das Vorhandensein oder Fehlen beschreiben. Der Unterschied ist in der Theorie gering, in der Praxis jedoch erheblich.
| Variante | Idealer Datentyp | Beispiel für einen Anwendungsfall im Unternehmensbereich |
|---|---|---|
| Gaußscher Naive-Bayes-Algorithmus | Kontinuierliche Daten | Transaktionen anhand von Beträgen, Häufigkeit und Durchschnittswerten nach Risiko einstufen |
| Multinomial-Naive-Bayes-Modell | Texte, Berechnungen, Häufigkeiten | Kundenbewertungen und Tickets nach Stimmung oder Kategorie analysieren |
| Bernoulli-Naive-Bayes-Modell | Binäre Daten, Anwesenheit/Abwesenheit | Auswertung von Ja/Nein-Signalen in den Bereichen Compliance, Support oder Produktnutzung |
Um die richtige Wahl zu treffen, halte dich an eine einfache Regel:
Viele Teams kommen nicht weiter, weil sie nach dem absolut „besten“ Modell suchen. Die richtige Wahl ist fast immer das Modell, das am besten zur Art der Daten passt.
Die gute Nachricht ist, dass die praktische Umsetzung von Naive Bayes kein Mammutprojekt erfordert. Schon ein übersichtlicher Prototyp reicht aus, um zu verstehen, wie das Modell funktioniert und welche Daten es benötigt.

Ein Klassifikator entsteht fast immer in vier Schritten.
Datenaufbereitung
Du musst bereits klassifizierte historische Beispiele sammeln. Wenn du Bewertungen klassifizierst, benötigst du Texte, die bereits als positiv oder negativ gekennzeichnet sind. Wenn du das operationelle Risiko analysierst, benötigst du Fälle aus der Vergangenheit mit bekanntem Ausgang.
Modelltraining
Das Modell analysiert die Daten und schätzt die relevanten Wahrscheinlichkeiten. Bei naiven Bayes-Klassifikatoren erfolgt dieser Schritt schnell, da das Training keine besonders aufwendigen Optimierungen erfordert.
Prognose zu neuen Fällen
Fügen Sie neue Datensätze hinzu, und das Modell ordnet ihnen eine Klasse zu. Zum Beispiel „Spam“, „kein Spam“, „Risikokunde“, „stabiler Kunde“.
-Bewertung: Vergleichen Sie die Vorhersagen mit der Realität anhand eines separaten Testdatensatzes. Dabei prüfen Sie nicht nur, ob das Modell funktioniert, sondern auch, wie es Fehler macht.
Wenn du dir einen umfassenderen Überblick über prädiktive Ansätze verschaffen möchtest, hilft dir dieser Überblick über Algorithmen des maschinellen Lernens dabei, Naive Bayes in den größeren Kontext einer ganzen Familie von Methoden einzuordnen.
Um den Prozess zu veranschaulichen, hier ein einfaches Beispiel mit scikit-learn. Als Entwickler musst du es nicht im Detail lesen. Es reicht, wenn du den Ablauf verstehst.
# Importieren wir die wichtigsten Werkzeugefrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# Laden wir einen BeispieldatensatzX, y = load_iris(return_X_y=True)# Teilen wir die Daten in einen Trainings- und einen Testteil aufX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Erstellen wir das Modellmodel = GaussianNB()# Trainieren wir das Modell mit den historischen Datenmodel.fit(X_train, y_train)# Machen wir Vorhersagen für bisher unbekannte Dateny_pred = model.predict(X_test)# Messen wir die Genauigkeitprint(accuracy_score(y_test, y_pred))Dieser Ausschnitt sagt viel mehr aus, als es auf den ersten Blick scheint.
GaussianNB() Wählen Sie die Variante für kontinuierliche Daten.fit() Das ist der Moment, in dem das Modell lernt.predict() wendet das Gelernte an.accuracy_score() Überprüfe, wie viele Einstufungen insgesamt korrekt sind.Bei Textdaten verläuft der Ablauf ähnlich, doch vor der Modellierung musst du den Text in Zahlen umwandeln. Konkret bedeutet das, dass du die Wörter in Merkmale umwandelst, die von einem Klassifikator verarbeitet werden können.
Nach einem ersten Blick auf den Code kann es hilfreich sein, sich eine visuelle Darstellung des Mechanismus anzusehen.
Das erste Modell dient nicht dazu, Perfektion zu beweisen. Es dient dazu, drei praktische Fragen zu beantworten.
Hier zeigt sich die Stärke von Naive Bayes. Man gelangt schnell zu einer soliden Ausgangsbasis. Von dort aus lässt sich erkennen, ob es sinnvoll ist, das Projekt zu verkomplizieren, oder ob eine einfache Lösung bereits einen Mehrwert schafft.
Ein Klassifizierungsmodell wird nicht allein danach beurteilt, ob es „zu funktionieren scheint“. Es wird danach beurteilt, wie es Fehler macht und wie stark sich diese Fehler auf das Geschäft auswirken.

Die Genauigkeit ist die intuitivste Kennzahl. Sie gibt an, wie viele der Prognosen von der Gesamtzahl korrekt sind. Sie ist nützlich, kann aber für sich genommen irreführend sein.
Wenn von hundert Transaktionen nur wenige tatsächlich verdächtig sind, kann ein Modell, das fast alles als normal einstuft, zwar eine gute Genauigkeit aufweisen, aber genau dort versagen, wo es wirklich darauf ankommt.
Um das zu verstehen, stell dir ein Fischernetz vor.
Im Geschäftsleben spielt diese Unterscheidung eine große Rolle.
Ein gutes Modell ist nicht das, das generell nur wenige Fehler macht. Es ist das, das Fehler auf die für deinen Prozess kostengünstigste Weise macht.
Um besser zu verstehen, wie ein Algorithmus aus historischen Daten lernt und warum die Qualität des Trainings das Endergebnis beeinflusst, kannst du diesen ausführlichen Artikel darüber lesen, worin das Training eines Algorithmus besteht.
Naive Bayes ist einfach, verzeiht aber bestimmte praktische Fehler nicht.
Erster Fehler: Das Problem der Nullhäufigkeit ignorieren.
Wenn ein Wort oder ein Wert in den Trainingsdaten für eine bestimmte Klasse nie vorkommt, kann die Wahrscheinlichkeit auf null sinken und die Berechnung beeinträchtigen. Aus diesem Grund wird häufig das Laplace-Smoothing verwendet, das den Zählwerten eine kleine Korrektur hinzufügt.
Zweiter Fehler: Verwendung stark korrelierter Merkmale.
Wenn zwei Spalten fast dieselben Informationen enthalten, besteht die Gefahr, dass das Modell das Signal überschätzt. Es „versteht“ nicht, dass die beiden Merkmale fast identisch sind.
Dritter Fehler: Zu großes Vertrauen in die rohen Wahrscheinlichkeiten.
Naive Bayes liefert oft gute Klassifizierungsergebnisse, doch seine Wahrscheinlichkeitswerte können zu sicher sein. Für Unternehmen bedeutet dies, dass das Ranking zwar nützlich sein kann, der genaue Wert der Wahrscheinlichkeit jedoch mit Vorsicht interpretiert werden sollte.
Um diese Risiken zu verringern, empfiehlt es sich:
Der wahre Wert der naiven Bayes-Klassifikatoren zeigt sich erst dann, wenn man aufhört, sie als reine mathematische Übung zu betrachten, und beginnt, sie als Entscheidungshilfe zu nutzen. In der Unternehmenswelt bedeutet eine gute Klassifizierung fast immer, bessere Entscheidungen zu treffen.

Stellen Sie sich ein Finanzteam vor, das Transaktionsströme, Geschäftsbeschreibungen und historische Signale analysiert. Jede Zeile ist nicht nur ein Datensatz. Sie ist eine potenzielle Entscheidung: durchlassen, genauer prüfen, blockieren oder an einen Analysten weiterleiten.
Mit Naive Bayes kannst du verschiedene Indikatoren in einer einzigen Klassifizierung kombinieren. Einige sind numerisch, andere binär, wieder andere textbasiert. Das Modell hilft dabei zu erkennen, welche Fälle bereits beobachteten Mustern – ob normal oder anomal – am ehesten ähneln.
Der praktische Nutzen ist zweierlei:
Es ersetzt nicht das menschliche Urteilsvermögen in regulierten Kontexten. Es strukturiert es. Und bei operativen Prozessen mit hohem Durchsatz macht das einen echten Unterschied.
Im Marketing bedeutet Segmentierung oft, jeden Kunden einer bestimmten Gruppe zuzuordnen. Treue Kunden. Preisbewusste Kunden. Kunden mit Abwanderungsrisiko. Kunden, die auf Werbeaktionen reagieren. Inaktive Kunden.
Hier ist Naive Bayes nützlich, da es heterogene Signale schnell kombinieren kann:
Ein CRM-Team braucht keine perfekte Theorie des menschlichen Verhaltens. Es braucht eine Segmentierung, die gut genug ist, um sinnvolle Maßnahmen zu ergreifen. Zum Beispiel die Anpassung der Botschaft, der Kontaktfrequenz oder der Art des Angebots.
Wenn ein Modell dabei hilft, die nächste Nachricht für den richtigen Kunden auszuwählen, schafft es bereits einen operativen Mehrwert.
Im Einzelhandel und im E-Commerce unterstützt die Klassifizierung Tätigkeiten, die zwar unterschiedlich erscheinen, aber derselben Logik folgen: Ordnung ins Chaos zu bringen.
Du kannst Produkte anhand ihres Verkaufsprofils klassifizieren. Du kannst Bewertungen und Supportanfragen lesen, um herauszufinden, in welchen Kategorien es zu Reibungsverlusten kommt. Du kannst Nachfragemuster erkennen, die dem Team helfen, Werbeaktionen und Lagerbestände besser zu planen.
In einem solchen Umfeld sind die Daten oft zahlreich, heterogen und nicht immer fehlerfrei. Aus diesem Grund ist ein schnelles, skalierbares und übersichtliches Modell von großem Wert. Nicht, weil es besonders glamourös ist, sondern weil es sich nahtlos in den Arbeitsablauf einfügt, ohne diesen zu verlangsamen.
Wenn du sehen möchtest, wie sich Analysemethoden für Unternehmen in konkreten Projekten umsetzen lassen, kannst du dir diese Fallstudien ansehen.
Naive-Bayes-Modelle zu verstehen, ist nützlich. Sie in einem Unternehmenskontext gut umzusetzen, ist eine ganz andere Sache.
Das Problem liegt fast nie nur im Algorithmus. Die eigentliche Arbeit dreht sich um das Modell. Man muss verschiedene Datenquellen verknüpfen, fehlende Felder bearbeiten, Texte aufbereiten, Bezeichnungen aktualisieren, die Qualität der Ergebnisse überprüfen und die Ergebnisse so aufbereiten, dass sie für die Entscheidungsträger verständlich sind.
Für ein KMU ist dieser Schritt oft der entscheidende Punkt. Nicht, weil das Interesse an KI fehlt, sondern weil die Zeit des Teams begrenzt ist und operative Prioritäten keinen Aufschub dulden.
Hier ist es sinnvoll, eine Plattform zu nutzen, die die technische Komplexität übernimmt. Eine KI-gestützte Lösung ermöglicht es, Rohdaten in aussagekräftige Erkenntnisse umzuwandeln, ohne dass die Fachabteilungen Code schreiben, Bibliotheken auswählen oder manuelle Pipelines verwalten müssen.
Eine Plattform wie ELECTE, eine KI-gestützte Datenanalyseplattform für KMU, macht Methoden wie naive Bayes-Klassifikatoren zugänglich, ohne dass spezielle Kenntnisse im Bereich des maschinellen Lernens erforderlich sind. Der Vorteil liegt nicht nur in der Geschwindigkeit. Es ist die Verringerung der Reibungsverluste zwischen Daten und Entscheidung.
Wenn die Automatisierung gut funktioniert, denkt das Team nicht mehr in Formeln. Es denkt in Form von nützlichen Fragen:
Das ist auch der Grund, warum immer mehr Unternehmen nach Tools suchen, die dabei helfen, die Zuverlässigkeit von KI-generierten Inhalten und der in internen Prozessen zirkulierenden Textsignale zu beurteilen. In diesem Zusammenhang kann es hilfreich sein, einen Leitfaden zu einem italienischen KI-Detektor zu Rate zu ziehen, insbesondere wenn Ihr Team mit Dokumenten, Inhalten und sprachlichen Überprüfungen arbeitet.
Der Unterschied ist im Grunde ganz einfach. Anstatt sich mit einzelnen technischen Schritten zu beschäftigen, richtet man den Fokus auf das Unternehmensergebnis. Und genau hier wird KI wirklich einsetzbar und ist nicht mehr nur interessant.
Naive-Bayes-Klassifikatoren vermitteln eine wichtige Lektion. In der Analytik kann gut eingesetzte Einfachheit schlecht gehandhabte Komplexität übertrumpfen.
Mit einer intuitiven probabilistischen Grundlage, guter Skalierbarkeit und sehr konkreten Anwendungsfällen bleibt dieser Ansatz ein zuverlässiges Instrument für Unternehmen, die Informationen klassifizieren, verborgene Signale erkennen und sicherer handeln wollen. Man muss kein Spezialist für maschinelles Lernen sein, um ihren Wert zu verstehen. Es geht darum, Mathematik mit operativen Entscheidungen zu verknüpfen.
Sobald dieser Zusammenhang klar ist, ist KI kein rein technisches Thema mehr, sondern wird zu einem organisatorischen Vorteil. Genau dann beginnt die Prognose, Wirkung zu zeigen.
Wenn du aus verstreuten Daten klare Erkenntnisse gewinnen möchtest, probier ELECTE. Die Plattform hilft KMU dabei, Datenquellen zu verknüpfen, die Analyse zu automatisieren und nützliche Berichte und Prognosen zu erhalten, um schnellere und fundiertere Entscheidungen zu treffen.

.svg)
.svg)
.svg)






