

You’ve probably found yourself in this situation before: you have an ERP system, maybe a CRM, a few Excel files being passed around via email, and then someone tells you that to “do serious analytics,” you have to choose between a data lake and a data warehouse. At that point, the conversation immediately shifts to technology, but the real issue is something else entirely. Do you really need a new data architecture, or do you simply need to make the data you already have readable and useful?
For an SME, this distinction matters more than just the terminology. Making the wrong choice doesn’t just create technical complexity. It leads to lengthy projects, reliance on consultants, late reports, and investments that struggle to translate into better decisions. Doing nothing, however, leaves the company flying by the seat of its pants.
The point isn’t to learn vendor jargon. The point is to figure out which solution is the right fit for your business, your budget, and the skills you actually have in-house. Here’s a practical guide to understanding the data lake vs. data warehouse debate from the perspective of someone who needs to balance costs, accessibility, and operational return.
The pressure to “do something with the data” is very real today. The volume of data is growing, data sources are multiplying, and managers are demanding faster forecasts, dashboards, and alerts. Meanwhile, new terms are popping up that seem to force you into making an immediate architectural decision.
For many SMEs, however, this is precisely where the trap lies. They convince you that the first step is to choose between two infrastructure models, when often the real issue is much more practical: scattered data, inconsistent formats, manual reporting, and no one who has the time to bring order to it all.
There are other questions you should be asking. Do you really have an architectural problem? Or is it a data accessibility issue? If you choose the wrong solution, you risk funding a technical project instead of improving your control over the business. If you don’t choose anything, you’ll keep making decisions based on incomplete information.
Someone running an SME doesn’t need a college lecture. They need a simple guideline to figure out what’s necessary, what isn’t, and where the real costs lie.
The most useful distinction can be understood with the help of two very practical examples.
A data warehouse is like a well-organized library. Every book arrives already cataloged, classified, and placed on the correct shelf. When you look for information, you find it quickly because the order has been established in advance. A data lake, on the other hand, is like a large warehouse where boxes of all kinds arrive. You put in organized files, logs, PDFs, images, exports from the management system, and web data. You apply the order later, when you need to analyze them.
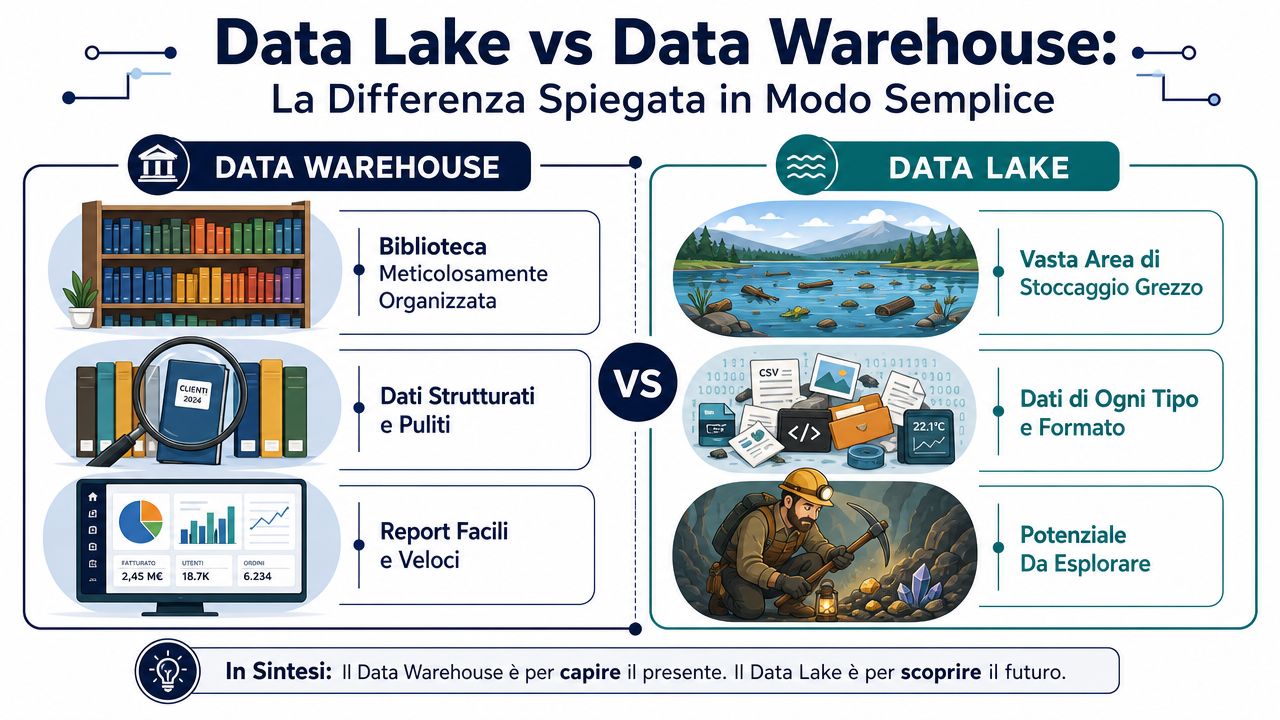
This is the only technical detail that’s really worth mentioning.
This distinction also reflects their historical origins. The data warehouse was originally designed for business analytics on data that had already been cleaned and structured, while the data lake came later to store raw data in heterogeneous formats. For this reason, the warehouse is better suited for reporting and KPIs, while the lake is more flexible for exploration and machine learning, as explained in this analysis of the differences between data warehouses and data lakes.
A data warehouse performs well with known queries. A data lake is useful when you know the data might contain value, but you don’t yet know in what form.
If your goal is to track sales, profit margins, orders, inventory, delays, sales performance, and monthly comparisons, the warehouse is conceptually better suited to your needs. It provides a reliable foundation for standard reports, consistent SQL queries, and repeatable results.
If, on the other hand, you work with highly diverse data types—such as application logs, PDFs, emails, text files, images, or machine data streams—the data lake offers greater flexibility. IT teams can centralize heterogeneous data sources, while those responsible for reporting continue to prefer structured environments for fast and consistent queries. This approach also ties into the broader concept of data-driven business decisions, which require accessible data even more than sophisticated technologies.
In the data lake vs. data warehouse debate, many people confuse flexibility with immediate utility.
A data lake can store almost anything. But storing data doesn’t mean it’s immediately ready for analysis. A data warehouse is less flexible when it comes to data ingestion, but more useful when you need quick, standardized answers. For an SME, this difference matters more than just in theory. Because the issue isn’t about storing more data. It’s about making better decisions.
Two companies can start with the same data and end up with very different results. The difference often lies not in the amount of data collected, but in how they organize it, prepare it, and make it accessible to decision-makers.
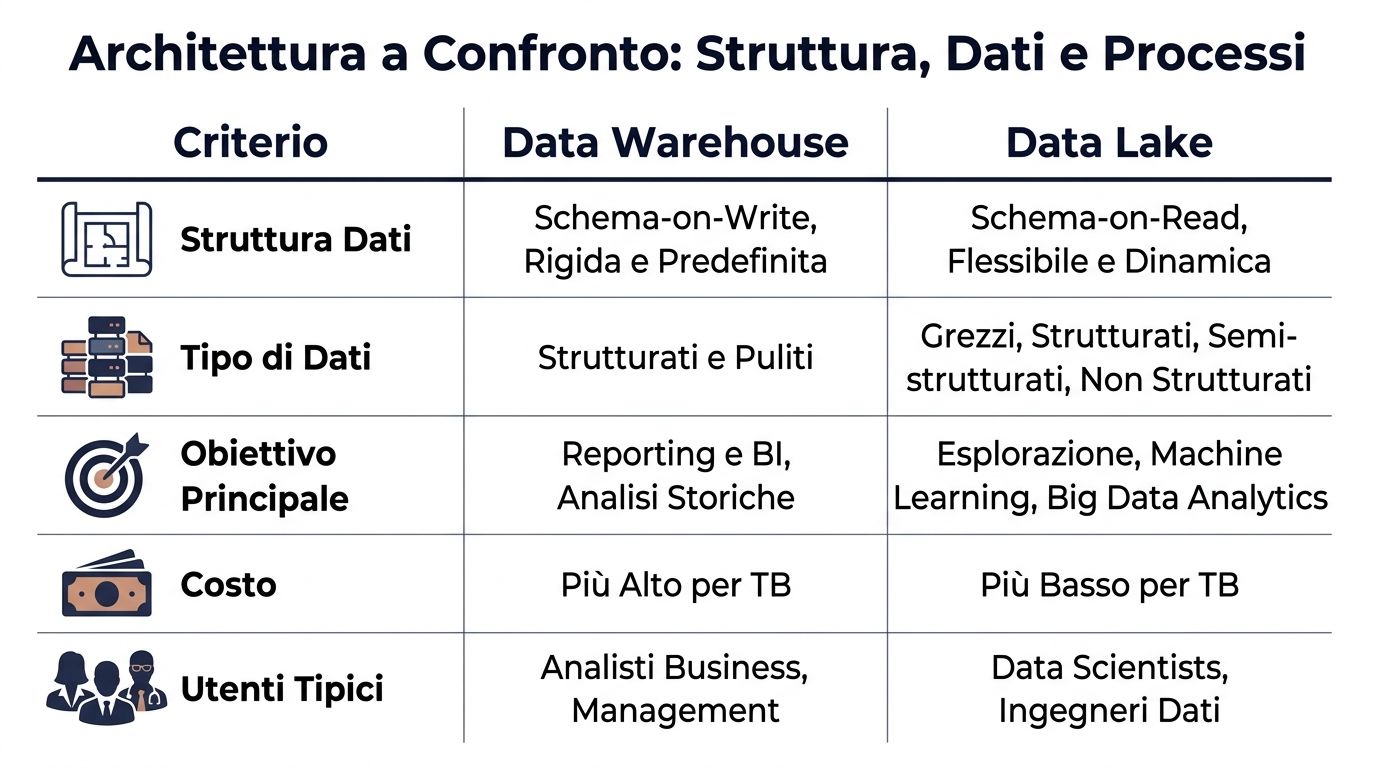
| Criterion | Data Warehouse | Data Lake |
|---|---|---|
| Data structure | Schema-on-write, defined before loading | Schema-on-read, defined at the time of analysis |
| Data type | Above all, well-organized and tidy | Structured, semi-structured, and unstructured |
| Typical process | ETL: Process first, then load | ELT: Load first, transform later |
| Typical users | Business analyst, finance, management | Data engineers, data scientists, technical teams |
| Expected performance | More predictable for BI and reporting | More variables; they depend on the query and the preparation |
In a data warehouse, the standard process is ETL: extract the data, transform it, and then load it. It requires more work upfront, but reduces friction down the line. Anyone looking at a dashboard will find consistent fields, stable definitions, and KPIs whose meaning doesn’t vary from one department to another.
In a data lake, the workflow is often ELT: extract, load, and transform only later, if necessary. This approach offers greater technical flexibility, but it defers part of the work. For a small or medium-sized business, deferring work often means letting tasks pile up, which then falls on the team at the worst possible moment—namely, when a quick response is needed.
Rule of thumb: If multiple people need to review the same document and make operational decisions, establishing a clear structure before uploading it helps reduce errors, unnecessary discussions, and wasted time.
From an operational standpoint, a data warehouse is designed for repetitive queries, frequent reports, and dashboards used on a daily basis. A data lake handles large volumes and diverse formats well, but response times and ease of use depend heavily on how the data has been cataloged, prepared, and governed. A technical comparison published by CloudOptimo sums this up well: the warehouse focuses on predictability, while the lake focuses on flexibility.
For an SME, this is no mere academic exercise. When the sales manager opens the morning report, they want consistent numbers and quick results. If, on the other hand, the technical team needs to analyze files, logs, or diverse documents, they may be willing to accept some latency in exchange for a broader range of data.
The practical difference isn't just technical. It's about who can use the data without having to ask for help every time.
A well-designed data warehouse brings data closer to the business. A data lake, on its own, more often brings it closer to the technical team. That’s why many SMEs discover an uncomfortable truth too late: the real choice isn’t between two technologies, but between a system that makes data accessible and one that simply stores it without turning it into better decisions.
Anyone evaluating these options as part of an IT modernization project should also consider the operational model, not just the repository. Cloud solutions for SMBs help clarify this very point: where the infrastructure ends and where costs, required skills, and day-to-day responsibilities begin.
Data lakes are often touted as the most cost-effective option because they store raw data and reduce the initial workload. This is only partly true. Without a catalog, access rules, consistent naming conventions, and basic quality controls, the initial savings turn into wasted time spent searching for files, reconstructing definitions, and verifying which data is reliable.
For this reason, in many SMEs, the right comparison isn’t “data lake versus data warehouse” in the abstract. The useful question is a different one: is it really necessary to build one of these comprehensive architectures, or is it better to start with a lighter-weight solution that delivers quick insights without immediately taking on all the complexity?
For an SME, the most costly mistake often stems from a poorly framed question: “Is a data lake or a data warehouse cheaper?” In a company, the real cost becomes apparent later. It becomes clear when data systems aren’t interoperable, reports break every time the ERP system is updated, and every request goes through consultants or developers instead of the team that needs to make the decision.

Storage is less of a burden than it seems. What really takes up the most effort are the tasks that make data reliable and usable: modeling, integrations, permissions, quality assurance, monitoring, error correction, and user support.
A data warehouse requires some initial effort. You need to define metrics, build pipelines, align data sources, and keep everything organized when ERP systems, CRMs, or business rules change. In return, management gets more consistent data, and reporting tends to become more predictable.
A data lake often starts out with a more modest promise. You load in different types of data and defer some of the structural decisions. The problem is that deferring these decisions doesn’t eliminate the work. It just pushes it further down the line, where it manifests itself in the form of cataloging, security, computational costs, data duplication, inconsistent versions, and constant verification of which data is truly reliable.
The risk for an SME is having to pay twice: first to collect the data, and then to finally make it readable.
The real complexity isn't technical. It's operational.
If every new report requires manual intervention, if the controller and the sales representative use different definitions for the same metric, or if the business owner has to wait days to get a reliable figure, the data project is already eating into profits—even if the infrastructure looks modern on paper.
That’s why it’s important to evaluate the management model as well, not just the architecture. Cloud solutions for SMBs help clarify this distinction: what you’re actually buying, how much maintenance remains in-house, and how much you rely on specialized expertise each month.
In the Italian market, investors in analytics are looking for tangible results: a reduction in manual work, faster deal closings, and better control over sales, margins, inventory, and cash flow. They don’t want a sophisticated platform that remains in the hands of only a few.
This changes the criteria for making a choice. An SME shouldn’t ask itself which architecture is more appealing or more flexible in theory. It should ask itself how long it takes to develop reliable dashboards, how many people are needed to maintain them, and how quickly the project delivers value.
In retail, hidden costs quickly come to light. If sales, returns, promotions, and inventory data come from different systems, all it takes is a single misinterpretation of “margin” or “net sales” to undermine confidence in the reports. At that point, the problem isn’t the database you chose. It’s that the owner goes back to making decisions in Excel.
In finance, the cost of error is even more apparent. Reporting, reconciliation, management control, and variance analysis all require consistent and traceable data. If every review sparks debates about where a figure came from, the project loses its ROI before it’s even finished.
For this reason, in practice, many SMEs do not need to build a data lake or a full-fledged data warehouse from scratch. They need a system that is more lightweight, manageable, and decision-oriented.
If you can’t maintain data quality, access rules, and shared definitions over time, the problem isn’t whether to choose a data lake or a data warehouse. The problem is that you’ve bought into complexity before having a use case that justifies it.
The right question isn’t which architecture is “best” overall. The question is: what problem do you need to solve tomorrow morning?

In retail, the warehouse runs smoothly when you consistently have to answer the same operational questions:
The same applies to the finance sector. Whether you need to consolidate structured data, generate periodic reports, analyze portfolios, or track economic trends using consistent criteria, a data warehouse remains the natural choice.
A data lake makes sense when your company collects a wide variety of data and you either don't want to or can't define everything in advance.
A realistic example is that of an energy company that combines:
In this kind of situation, a traditional warehouse forces you to first map out relationships between data sources that you may not yet fully understand. A data lake allows you to centralize everything and apply structure only when needed for a specific analysis. This is the kind of scenario where the flexibility of a data lake truly adds value.
A data lake isn’t just a “more modern” option. It only makes sense when the variety of data justifies the complexity you’re bringing into your organization.
Most SMEs don’t operate in that kind of environment. They primarily deal with data from ERP, CRM, e-commerce, accounting systems, CSV exports, and Excel. In these cases, the challenge isn’t managing video files, application logs, or unstructured text on a large scale. The challenge is ensuring that the data is clean, consistent, and understandable to non-technical users.
Let’s be clear about this: often, you don’t need either a data lake or a traditional data warehouse.
What is needed instead is:
The lakehouse aims to bridge the two worlds. It promises the flexibility of a lake and some of the features of a warehouse within the same environment. It’s an interesting approach, especially for companies with mixed workloads spanning BI, AI, and data science.
For an SME, however, the question remains the same: do you really have a problem that warrants all of this? If your goal is simply to gain a better understanding of sales, margins, cash flow, or forecasts, a sophisticated hybrid solution may still be out of proportion to the expected value.
The data lakehouse was created to overcome the rigid separation between data lakes and data warehouses. The idea is simple: retain the flexibility of a large, open storage system while adding structure, performance, and analytical capabilities more akin to those of a data warehouse. Technologies such as Databricks and Delta Lake are prime examples of this approach.
In theory, it’s very appealing. You use the same database for BI, advanced analytics, and machine learning, avoiding the duplication of too much data across different systems. For large organizations or mature data teams, it’s a logical solution to an ecosystem that has grown increasingly complex over time.
In academic benchmarks, the data lakehouse architecture is evaluated using metrics such as throughput, latency, and metadata overhead. This demonstrates that the comparison with the data warehouse is not only functional but also performance-based, particularly in scenarios where even small differences in performance have a significant impact, as highlighted in this academic presentation on lakehouse benchmarks.
In business terms: The Lakehouse addresses challenges faced by organizations that have already reached a certain level of scale, complexity, and specialization.
If you didn't really need either a data lake or a data warehouse, you probably don't need a system that combines both.
For most SMEs, the most useful question isn’t “Which architecture should I choose?”, but “How can I obtain reliable analytics without turning the data project into a never-ending construction site?”.
This is the third key point that’s often overlooked in many data lake vs. data warehouse comparisons. Don’t build a new proprietary infrastructure. Instead, add a layer of analytics on top of the systems you already use, shifting the technical complexity outside the company’s operational scope.

In practice, the best approach is this:
I’ve seen more than one small or medium-sized business invest months in a traditional warehouse system and then hardly use it at all. Not because it was poorly built. It was because no one in the company knew how to query it on their own. The bottleneck wasn’t the database. It was accessibility.
This is a point that is often overlooked. An elegant architecture that always requires a technical intermediary reduces the practical value of the data. A simpler solution—one that management can understand—often leads to better decisions more quickly.
That’s why many companies get more value from well-designed business intelligence software for SMEs than from an oversized infrastructure solution. Their goal isn’t to own a data warehouse; it’s to understand their business better and sooner.
The right infrastructure is the one your team can actually use, maintain, and turn into decisions. Not the one that looks impressive on a technical slide.
The data lake vs. data warehouse debate is useful, but for an SME, it often starts with the wrong question. Before choosing an architecture, you need to figure out whether you really have a problem with data scale and variety, or a much more common issue: scattered data, manual reporting, and poor accessibility.
The data warehouse remains the best choice when reliable reporting, consistent KPIs, and predictable performance are required. The data lake makes sense when the variety of sources justifies greater flexibility and complexity. The lakehouse is an interesting evolution, but it is rarely the right first step for an organization that prioritizes operational control and ROI above all else.
The smartest choice isn't necessarily the most advanced technology. It's the one that's tailored to the actual problem, the skills you have on hand, and how quickly you want to turn data into decisions.
If you want to turn your business data into reports, forecasts, and actionable insights without building a complex infrastructure, check out ELECTE, an AI-powered data analytics platform for SMEs. You can start with the data you already have, reduce manual work, and make analytics accessible to your team with a much more streamlined approach.

.svg)
.svg)
.svg)






