

Your data is already telling a story. The problem is that it often speaks too softly.
Every day, an SME collects customer feedback, orders, support tickets, financial transactions, sales emails, and CRM notes. All of this data contains useful insights. Some indicate that a customer is on the verge of churning. Others signal an operational risk. Still others reveal which products are about to gain or lose momentum. Without a clear method, however, those insights remain just noise.
Among the algorithms that help bring order to this chaos, Naive Bayesian classifiers hold a special place. They are logically straightforward, quick to train, and often more effective than the term “naive” might suggest. They aren’t the right choice for every scenario, but for many real-world business problems, they offer a rare balance of speed, interpretability, and useful results.
If you work in the business world, you don’t need to become a researcher to understand them. You need to know what they do, why they work well even when they greatly simplify reality, and in which cases they can help you make better decisions. This is exactly where it’s worth taking a closer look.
Many companies look for sophisticated models when the problem actually calls for, first and foremost, a reliable and user-friendly model. This is the same reason why, in finance, retail, or customer service, the clearest approach often wins out over the most theoretically elegant one.
Naive Bayesian classifiers are based on a very practical idea. If you have some clues about a new case, you can estimate which category it most likely belongs to. If an email contains certain words, it might be spam. If a transaction exhibits certain patterns, it might require review. If a review uses certain terms, it might indicate satisfaction or dissatisfaction.
The word “Bayesian” brings to mind complex formulas. In reality, the core of the method is intuitive. You take what you already know, add new evidence, and update your judgment. It’s a structured way of reasoning under uncertainty—exactly what managers do every day, only systematized by an algorithm.
What is surprising is that this approach continues to work well even in modern environments, with vast amounts of data and rapid decision-making. Not because it perfectly describes the world, but because it separates the useful signal from the noise at a very low computational cost.
When it comes to business problems, the right question isn’t “Which model is the most sophisticated?” It’s “Which model provides reliable decisions in a timeframe that works for real-world operations?”
That’s why Naive Bayesian classifiers remain important. They help you classify, filter, segment, and prioritize. And they allow you to incorporate probability into the decision-making process without turning every project into a technical nightmare.
The basic principle is Bayes' theorem. Put simply, it works like this: you start with an initial probability, then update it as new information becomes available.
In statistical terms, the formula is written as follows: P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y). This means that the probability of a class given a set of observations depends on two factors. The first is the prior probability of the class. The second is how well each observation fits that class.
Let’s look at a business example. You need to determine whether an email is spam or not. You have a general probability that an incoming email is spam. Then you look for certain words like “offer,” “free,” or “click here.” Each of these words affects the final judgment.
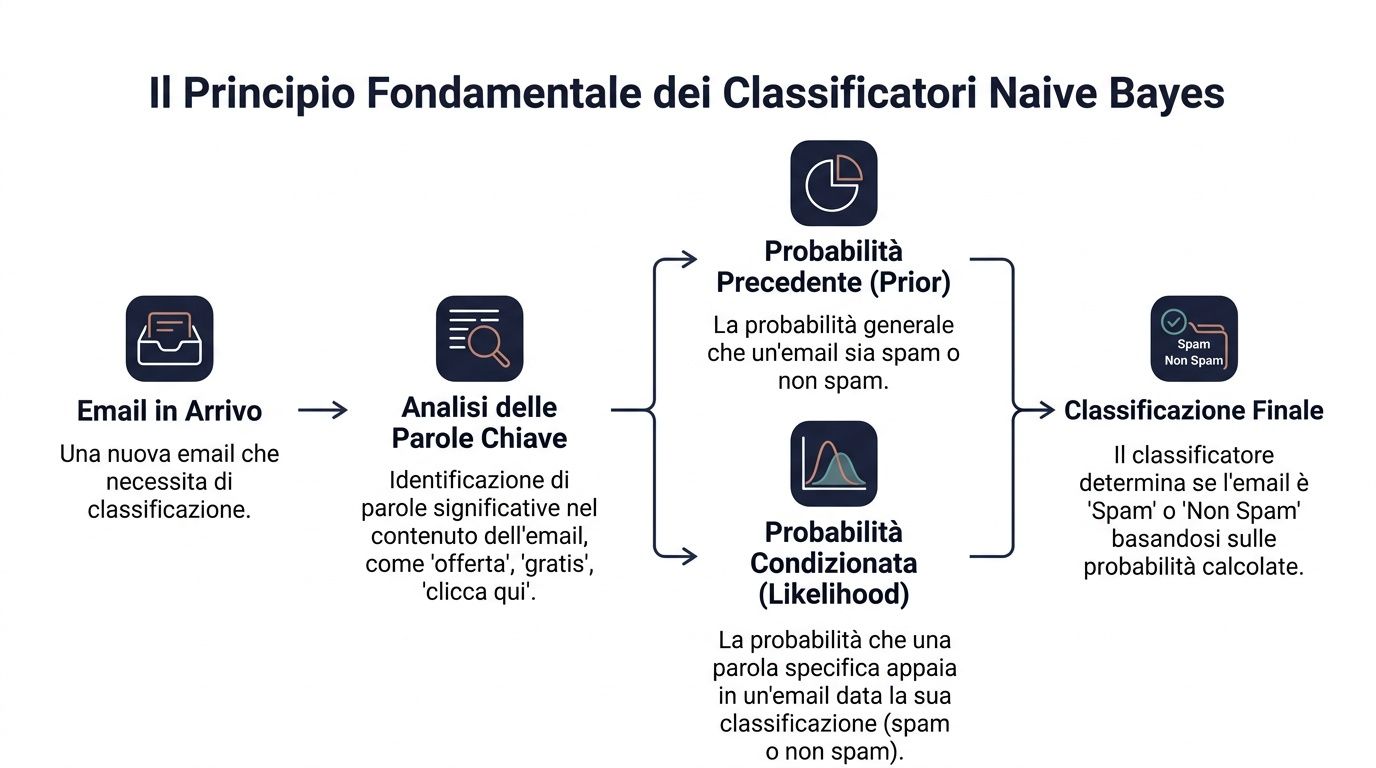
Managers do something similar every day. They never make decisions in a vacuum. They start with a baseline context and add clues. A customer who has always made regular purchases has a certain initial profile. If they then stop opening emails, reduce the value of their orders, and open a critical support ticket, your assessment changes.
The term "naive" refers to a specific assumption. The model treats the features as if they were independent of one another, since the class is known.
In practice, when you’re classifying an email, treat each word as a separate clue. Don’t try to model all the complex relationships between terms. This is a significant simplification. In reality, many words appear together, and many business behaviors are interrelated.
Yet it is precisely this choice that makes the model so lightweight. It does not have to learn a complex network of dependencies. It must estimate simpler probabilities and combine them efficiently.
Rule of thumb: Naive Bayes non cerca di ricostruire l’intero mondo. Cerca di prendere decisioni utili con poche assunzioni e molta velocità.
This is where misunderstandings often arise. Many people read “naive assumption” and conclude “weak model.” That is not the case. A model can be highly simplified and still be competitive if the simplification captures what matters for the decision-making task.
In 2004, a theoretical analysis provided solid grounds for the effectiveness of Naive Bayes classifiers despite the assumption of independence, and also explained why they can reach their asymptotic error rate more quickly than logistic regression. In the same line of applications, in spam filtering they achieve accuracies exceeding 99% and scale to millions of documents, as described in the entry on Naive Bayes classifiers.
This point is important for a business audience. The value of an algorithm lies not only in the final score. It also lies in its ability to train quickly, adapt to large datasets, and remain interpretable.
When you have scattered text, categories, tags, or signals, Naive Bayesian classifiers work well because:
However, there are two points to keep in mind.
For this reason, Naive Bayes should be viewed as a highly effective tool for fast classification problems, not as a universal magic wand. In many practical contexts, however, it is one of the smartest ways to get started.
A common mistake is to talk about Naive Bayes as if it were a single, identical model in every situation. In reality, there are different variants designed for different types of data.
The right choice depends on the format of the data you have. If you choose the wrong variant, the model can still produce a prediction, but it won’t be using the approach best suited to your problem.
Gaussian Naive Bayes is the most suitable variant when the features are continuous. Think of the average transaction amount, customer age, average time between purchases, unit margin, or receipt value.
Here, the model assumes that, within each class, the values follow a Gaussian distribution. You shouldn’t think of this as an academic constraint. Just keep the practical idea in mind: for each class, the model estimates a typical center and a dispersion.
This approach is useful when you want to classify cases such as:
In a scikit-learn benchmark using a dataset similar to Italian e-commerce data, a Naive Bayes model achieved 95% accuracy with 1,000 samples, with a training time 15% faster than logistic regression . The comparison shown is 0.01s vs. 0.1s on a standard CPU, thanks to closed-form training, as demonstrated in Jake VanderPlas’s chapter on “In Depth Naive Bayes Classification.”
For a company, the point isn’t the decimal point. The point is that this variant can deliver good results without lengthy training periods or a heavy infrastructure.
If you work with text, tickets, reviews, or comments, Multinomial Naive Bayes is often the natural choice. In this case, the features are counts or frequencies. Essentially, the model looks at how many times words or terms appear.
It's the classic scenario of:
The reason it works well is quite straightforward. While the vocabulary in business texts can be extensive, each document contains only a small fraction of the possible words. The data is sparse. Multinomial Naive Bayes handles this type of structure particularly well.
In a study of 100,000 Italian tweets labeled by sentiment, the Multinomial Naive Bayes classifier achieved an F1 score of 0.88 with a 10-fold speedup compared to SVM, as reported in the GeeksforGeeks guide on Naive Bayes classifiers.
To remember this easily, think of it this way: if your data looks like a document full of counted words, the multinomial model is almost always the first option to try.
If your company needs to process large volumes of text, the question isn’t just “How accurate is the model?” It’s also “How many requests can it handle without slowing down the team?”
Bernoulli Naive Bayes works with binary features. It doesn't count how many times a signal appears. It counts whether it is present or absent.
This approach is useful when the presence of an attribute is more important than its frequency. Some business examples:
This approach is very useful when you want to break down complex phenomena into simple yes/no indicators that are easy to track. In sentiment analysis, for example, the mere presence of a negative word may be more significant than how often it is repeated.
Bernoulli is not “less sophisticated” than the multinomial distribution. It is simply more suitable when the data describes presence or absence. The difference is subtle in theory, but significant in practice.
| Variant | Ideal Data Type | Example of a Business Use Case |
|---|---|---|
| Gaussian Naive Bayes | Continuous data | Classify transactions by risk using amounts, frequency, and average values |
| Multinomial Naive Bayes | Texts, counts, frequencies | Analyze customer reviews and tickets by sentiment or category |
| Bernoulli Naive Bayes | Binary data, presence/absence | Evaluate yes/no signals related to compliance, support, or product usage |
To make the right choice, follow this simple rule:
Many teams get stuck because they’re looking for the “best” model of all. Almost always, the right choice is the model that best fits the type of data.
The good news is that putting Naive Bayes into practice doesn’t require a massive project. Even a simple prototype is enough to understand how the model works and what data it needs.

A classifier is almost always created in four steps.
Data Preparation
You need to collect pre-labeled historical examples. If you’re classifying reviews, you need texts that have already been labeled as positive or negative. If you’re analyzing operational risk, you need past cases with known outcomes.
Model Training
The model examines the data and estimates the relevant probabilities. In naive Bayesian classifiers, this step is quick because training does not require particularly intensive optimization.
New Case Prediction
Enter new records, and the model will assign a class. For example, “spam,” “not spam,” “at-risk customer,” “stable customer.”
Evaluation
Compare the predictions with the actual data on a separate test set. Here, you don’t just check whether the model works. You look at how it makes mistakes.
If you want to gain a deeper understanding of the broader landscape of predictive approaches, this overview of machine learning algorithms helps place Naive Bayes within a wider family of methods.
To illustrate the process, here’s a simple example using scikit-learn. You don’t need to read it as a developer; just understand the workflow.
# Import the main toolsfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# Load a sample datasetX, y = load_iris(return_X_y=True)# Let’s split the data into training and test setsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Create the modelmodel = GaussianNB()# Train the model on the training datamodel.fit(X_train, y_train)# Make predictions on the test datay_pred = model.predict(X_test)# Measure the accuracyprint(accuracy_score(y_test, y_pred))This passage says much more than it seems.
GaussianNB() Select the option for continuous data.fit() This is when the model learns.predict() put what he has learned into practice.accuracy_score() Check how many classifications are correct overall.For text data, the process is similar, but before applying the model, you need to convert the text into numbers. In practice, you convert the words into features that a classifier can use.
After taking a quick look at the code, it might be helpful to see a visual explanation of how it works.
The first model is not meant to demonstrate perfection. It is meant to answer three practical questions.
This is where the power of Naive Bayes really shines. You can quickly establish a solid baseline. From there, you can determine whether it makes sense to complicate the project or if a simple solution is already delivering value.
A classification model isn’t judged solely on the fact that it “seems to work.” It’s judged by how often it makes mistakes and how much those mistakes impact the business.

Accuracy is the most intuitive metric. It tells you how many predictions are correct out of the total. It’s useful, but on its own it can be misleading.
If only a few out of a hundred transactions are actually suspicious, a model that classifies almost everything as normal may appear to have good accuracy but still perform poorly where it really matters.
To understand this, think of a fishing net.
In business, this distinction matters a great deal.
A good model isn't one that generally makes few mistakes. It's one that makes mistakes in the way that is least costly to your process.
To better understand how an algorithm learns from historical data and why the quality of training affects the final result, you can read this in-depth article on what algorithm training entails.
Naive Bayes is simple, but it doesn't forgive certain practical mistakes.
First mistake: ignoring the zero-count problem.
If a word or value never appears in the training data for a given class, the probability can drop to zero and compromise the calculation. This is why Laplace smoothing is often used, as it adds a small correction to the counts.
Second mistake: using highly correlated features.
If two columns convey nearly the same information, the model risks overestimating the signal. It doesn’t “understand” that the two features are nearly duplicates.
Mistake #3: Relying too heavily on raw probabilities.
Naive Bayes often performs well in ranking, but its probabilities can be overly confident. For businesses, this means that while the ranking may be useful, the exact probability values should be interpreted with caution.
To reduce these risks, it is advisable to:
The true value of Naive Bayesian classifiers becomes apparent when you stop viewing them as a mathematical exercise and start using them as a decision-making tool. In business, effective classification almost always leads to better decision-making.

Imagine a finance team analyzing transaction flows, operational descriptions, and historical data. Every line isn’t just a record. It’s a potential decision: let it pass, investigate further, block it, or forward it to an analyst.
With Naive Bayes, you can combine different features into a single classification. Some are numerical, others binary, and others textual. The model helps determine which cases most closely resemble patterns previously observed as normal or anomalous.
The practical benefit is twofold:
It does not replace human judgment in regulated contexts. It organizes it. And in high-volume operational processes, this makes a real difference.
In marketing, segmentation often involves assigning each customer to a specific group: loyal customers, price-sensitive customers, at-risk customers, promotion-responsive customers, and dormant customers.
Here, Naive Bayes is useful because it can quickly combine diverse signals:
A CRM team doesn’t need a perfect theory of human behavior. It needs segmentation that’s good enough to trigger sensible actions—such as changing the message, the frequency of contact, or the type of offer.
When a model helps select the next message for the right customer, it is already creating operational value.
In retail and e-commerce, classification supports activities that may seem different but share the same underlying principle: bringing order to chaos.
You can categorize products based on their sales performance. You can review customer feedback and support tickets to identify which categories are causing issues. You can recognize demand patterns that help the team plan promotions and inventory more effectively.
In this type of environment, data is often voluminous, diverse, and not always perfect. That’s why a fast, scalable, and readable model is so valuable. Not because it’s the most glamorous option, but because it integrates seamlessly into the workflow without slowing it down.
If you want to see how analytics approaches applied to business take shape in real-world projects, take a look at these case studies.
Understanding Naive Bayes is useful. Implementing it effectively in a business context is another story.
The problem is almost never just the algorithm. The real work lies in the model. You have to connect different data sources, handle missing fields, prepare text, update labels, check the quality of the output, and present the results in a way that decision-makers can understand.
For an SME, this step is often the sticking point. Not because there’s a lack of interest in AI, but because the team’s time is limited and operational priorities can’t wait.
This is where it makes sense to use a platform that handles the technical complexity. An AI-powered solution allows you to transform raw data into actionable insights without requiring the business team to write code, choose libraries, or maintain manual pipelines.
A platform like ELECTE, an AI-powered data analytics platform for SMEs, makes methods such as naive Bayesian classifiers accessible without requiring specialized expertise in machine learning. The benefit isn’t just speed. It’s the reduction of friction between data and decision-making.
When automation works well, the team no longer thinks in terms of formulas. Instead, it thinks in terms of useful questions:
This is also why more and more companies are looking for tools to help assess the reliability of AI-generated content and the textual cues that appear in internal processes. In this context, it may also be helpful to consult a guide to an Italian AI detector, especially if your team works with documents, content, and language verification.
In practice, the difference is simple. Instead of dealing with fragmented technical steps, you shift your focus to the business outcome. And that’s where AI becomes truly actionable—not just interesting.
Naive Bayesian classifiers teach us an important lesson. In analytics, simplicity applied effectively can outperform complexity that is poorly managed.
With an intuitive probabilistic foundation, good scalability, and very concrete use cases, this approach remains a reliable tool for companies that want to classify information, identify hidden signals, and act with greater confidence. You don’t need to be a machine learning specialist to understand its value. You just need to connect the math to operational decision-making.
Once this connection is clear, AI ceases to be a technical issue and becomes an organizational advantage. That’s when forecasting begins to make a real difference.
If you want to turn scattered data into clear insights, try ELECTE. The platform helps SMEs connect data sources, automate analysis, and generate reports and forecasts that enable faster, more informed decisions.

.svg)
.svg)
.svg)






