

Seguramente te has encontrado en esta situación: tienes un sistema de gestión, quizá un CRM, algunos archivos de Excel que circulan por correo electrónico, y de repente alguien te dice que para «hacer análisis serios» tienes que elegir entre un lago de datos y un almacén de datos. En ese momento, la conversación se centra inmediatamente en la tecnología, pero el verdadero problema es otro. ¿De verdad necesitas una nueva arquitectura de datos, o simplemente necesitas que los datos que ya tienes sean legibles y útiles?
Para una pyme, esta distinción es más importante que la terminología. Una elección errónea no solo genera complejidad técnica. Provoca proyectos prolongados, dependencia de los consultores, informes que llegan tarde e inversiones que tardan en traducirse en mejores decisiones. Sin embargo, la decisión de no hacer nada deja a la empresa a la deriva.
La cuestión no es aprender la jerga de los proveedores. La cuestión es entender qué solución se adapta mejor a tu negocio, a tu presupuesto y a las competencias con las que realmente cuentas en tu empresa. Aquí encontrarás una guía práctica para analizar el debate entre «data lake» y «data warehouse» desde la perspectiva de quien debe equilibrar los costes, la accesibilidad y el rendimiento operativo.
Hoy en día, la presión para «hacer algo con los datos» es real. Las cifras aumentan, las fuentes se multiplican y los directivos exigen previsiones, paneles de control y alertas más rápidas. Mientras tanto, surgen términos que parecen obligarte a tomar una decisión arquitectónica inmediata.
Para muchas pymes, sin embargo, ahí radica precisamente el problema. Te convencen de que el primer paso es elegir entre dos modelos de infraestructura, cuando a menudo el verdadero problema es mucho más concreto: datos dispersos, formatos incoherentes, informes manuales y nadie que tenga tiempo para poner orden.
Hay otras preguntas que son más útiles. ¿De verdad tienes un problema de arquitectura? ¿O se trata de un problema de acceso a los datos? Si eliges la solución equivocada, corres el riesgo de financiar un proyecto técnico en lugar de mejorar el control sobre el negocio. Si no eliges nada, seguirás tomando decisiones con información parcial.
Quien dirige una pyme no necesita una clase universitaria. Necesita un criterio sencillo para entender qué es lo que hace falta, qué no, y dónde se esconde el verdadero coste.
La diferencia más útil se entiende con dos ejemplos muy prácticos.
Un almacén de datos se parece a una biblioteca bien organizada. Cada libro llega ya catalogado, clasificado y colocado en la estantería correcta. Cuando buscas una información, la encuentras rápidamente porque el orden ya se ha establecido de antemano. Un lago de datos, en cambio, se parece a un gran almacén al que llegan cajas de todo tipo. En él se guardan archivos ordenados, registros, PDF, imágenes, exportaciones del sistema de gestión y datos web. El orden se aplica después, cuando hay que analizarlos.
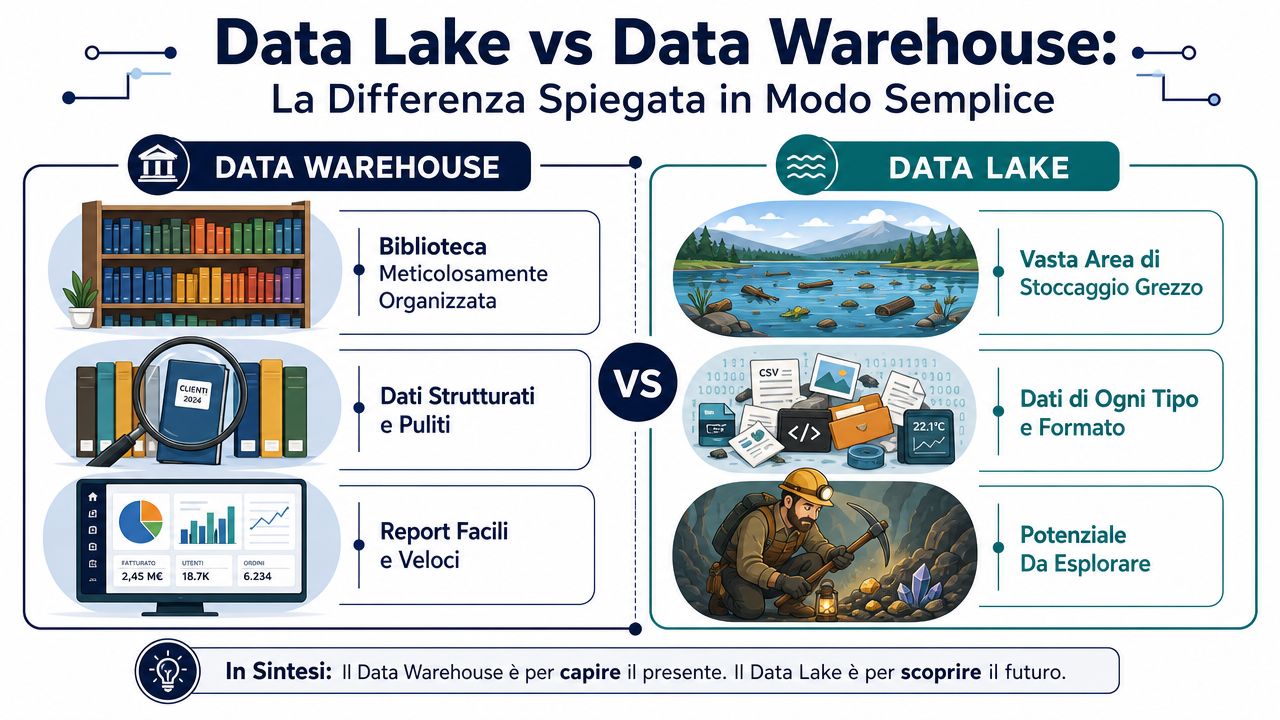
Aquí es donde entra en juego el único detalle técnico que realmente vale la pena mencionar.
Esta distinción resume también su origen histórico. El almacén de datos (data warehouse) se creó para el análisis empresarial de datos ya depurados y estructurados, mientras que el lago de datos (data lake) surgió posteriormente para almacenar datos sin procesar en formatos heterogéneos. Por eso, el almacén de datos es más adecuado para la elaboración de informes y los KPI, mientras que el lago de datos es más flexible para la exploración y el aprendizaje automático, tal y como explica este análisis sobre las diferencias entre el almacén de datos y el lago de datos.
Un almacén de datos funciona bien para consultas ya conocidas. Un lago de datos resulta útil cuando sabes que los datos pueden contener información valiosa, pero aún no sabes en qué forma.
Si tu objetivo es conocer las ventas, los márgenes, los pedidos, las existencias, los retrasos, el rendimiento comercial y las comparativas mensuales, el almacén de datos se ajusta mejor a tus necesidades. Te ofrece una base fiable para generar informes estándar, consultas SQL coherentes y cifras fiables.
Si, por el contrario, trabajas con datos muy diversos entre sí, como registros de aplicaciones, archivos PDF, correos electrónicos, textos, imágenes o flujos de datos de máquinas, el lago de datos ofrece mayor libertad. Los equipos de TI pueden centralizar fuentes heterogéneas, mientras que los responsables de la elaboración de informes siguen prefiriendo entornos estructurados para realizar consultas rápidas y coherentes. En esta lógica se inscribe también el tema más amplio de las decisiones empresariales basadas en datos, que requieren datos accesibles incluso antes que tecnologías sofisticadas.
En el debate entre «data lake» y «data warehouse», muchos confunden la flexibilidad con la utilidad inmediata.
Un lago de datos puede contener casi cualquier cosa. Pero contener no significa que se pueda analizar de inmediato. Un almacén de datos es menos flexible en cuanto a la entrada de datos, pero más útil cuando se buscan respuestas rápidas y estandarizadas. Para una pyme, esta diferencia tiene más peso que la teoría. Porque el problema no es almacenar más. Es tomar mejores decisiones.
Dos empresas pueden partir de los mismos datos y obtener resultados muy diferentes. La diferencia, a menudo, no radica en la cantidad de datos recopilados, sino en cómo los organizan, los preparan y los ponen a disposición de quienes deben tomar las decisiones.
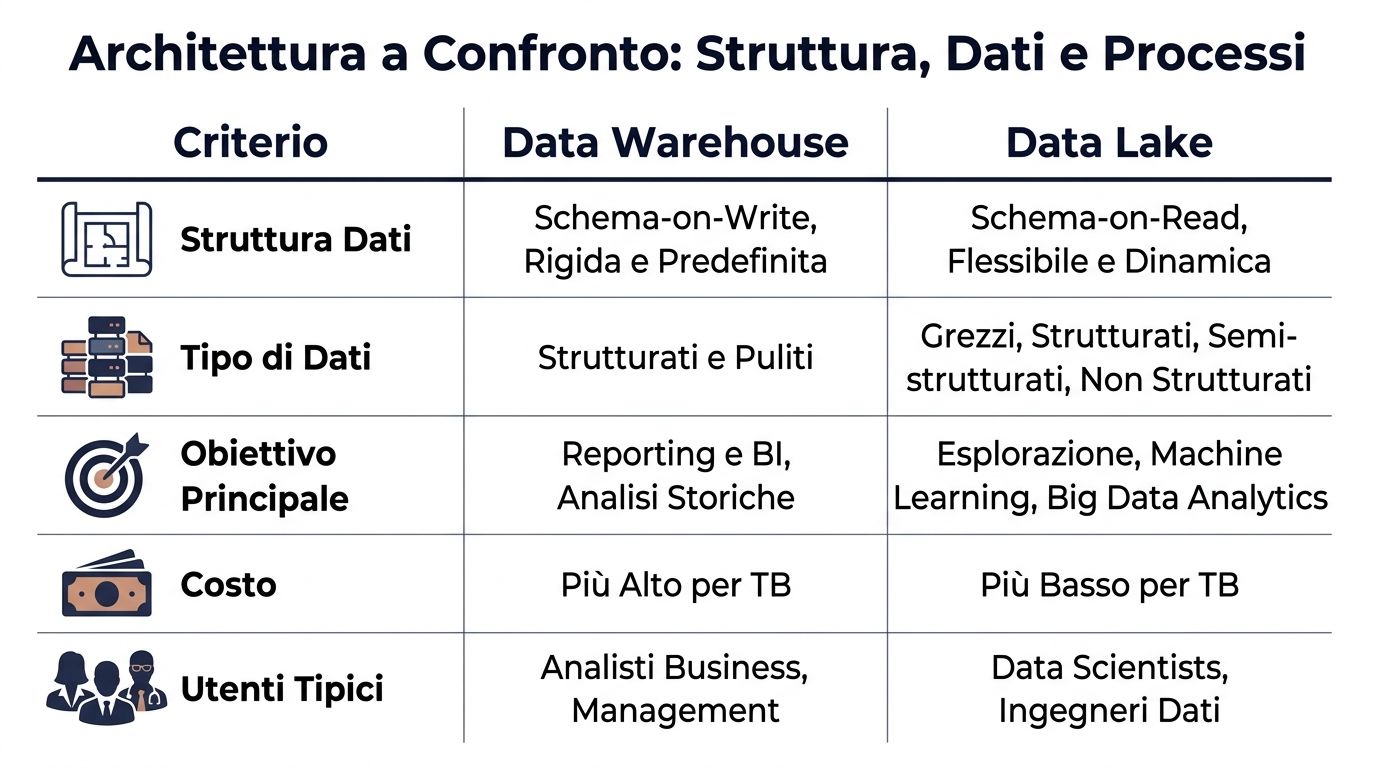
| Criterio | Almacén de datos | Lago de datos |
|---|---|---|
| Estructura de datos | Esquema en tiempo de escritura, definido antes de la carga | Esquema en lectura, definido en el momento del análisis |
| Tipo de datos | Sobre todo, ordenados y limpios | Estructurados, semiestructurados y no estructurados |
| Proceso típico | ETL: primero transformar y luego cargar | ELT: primero las cargas y luego las transformaciones |
| Usuarios típicos | Analista de negocios, finanzas, gestión | Ingenieros de datos, científicos de datos, equipos técnicos |
| Rendimiento esperado | Más predecibles para la inteligencia empresarial y la elaboración de informes | Son más variables, ya que dependen de la consulta y de la preparación |
En el almacén de datos, el flujo clásico es el ETL: se extraen los datos, se transforman y, a continuación, se cargan. Requiere más trabajo al principio, pero reduce las fricciones más adelante. Quien consulta un panel de control encuentra campos coherentes, definiciones estables y KPI cuyo significado no varía de un departamento a otro.
En el lago de datos, el flujo suele ser ELT: se extrae, se carga y se transforma solo después, si es necesario. Este enfoque ofrece mayor libertad técnica, pero pospone parte del trabajo. Para una pequeña o mediana empresa, posponerlo a menudo significa acumular tareas que luego recaen sobre el equipo en el peor momento, es decir, cuando se necesita una respuesta rápida.
Regla práctica: si varias personas deben leer el mismo informe y tomar decisiones operativas, la estructura definida antes de la carga reduce los errores, las discusiones innecesarias y la pérdida de tiempo.
Desde el punto de vista operativo, un almacén de datos está diseñado para consultas repetitivas, informes frecuentes y paneles de control de uso diario. Un lago de datos gestiona bien grandes volúmenes y formatos diversos, pero los tiempos de respuesta y la facilidad de uso dependen en gran medida de cómo se hayan catalogado, preparado y gestionado los datos. Una comparación técnica publicada por CloudOptimo resume bien este punto: el almacén de datos apuesta por la previsibilidad, mientras que el lago de datos lo hace por la flexibilidad.
Para una pyme, la cuestión no es meramente teórica. Si el responsable de ventas abre el informe matutino, quiere cifras coherentes y resultados rápidos. En cambio, si el equipo técnico tiene que analizar archivos, registros o documentos de diversa índole, puede aceptar una mayor latencia a cambio de una recopilación de datos más amplia.
La diferencia práctica no es solo técnica. Lo que cambia es quién es capaz de utilizar los datos sin tener que pedir ayuda cada vez.
Un almacén de datos bien diseñado acerca los datos al negocio. Un lago de datos, por sí solo, suele acercarlos más al equipo técnico. Por eso, muchas pymes se dan cuenta tarde de un aspecto incómodo: la verdadera disyuntiva no está entre dos tecnologías, sino entre un sistema que hace que los datos sean accesibles y otro que los almacena sin convertirlos en mejores decisiones.
Quien evalúe estas opciones en el marco de un proyecto de modernización de TI debería tener en cuenta también el modelo operativo, y no solo el repositorio. Las soluciones en la nube para pymes ayudan precisamente a comprender este aspecto: dónde termina la infraestructura y dónde empiezan los costes, las competencias necesarias y las responsabilidades diarias.
El lago de datos suele presentarse como la opción más económica, ya que almacena datos sin procesar y reduce el trabajo inicial. Esto solo es cierto en parte. Si no se cuenta con un catálogo, normas de acceso, una nomenclatura coherente y controles mínimos de calidad, el ahorro inicial se convierte en tiempo perdido buscando archivos, reconstruyendo definiciones y verificando qué datos son fiables.
Por eso, en muchas pymes, la comparación adecuada no es «lago frente a almacén» en abstracto. La pregunta relevante es otra: ¿realmente es necesario construir una de estas arquitecturas completas, o conviene empezar por una solución más ligera que proporcione información útil rápidamente sin tener que asumir de inmediato toda la complejidad?
Para una pyme, el error más costoso suele surgir de una pregunta mal planteada: «¿Es más barato un lago de datos o un almacén de datos?». En la empresa, la verdadera factura llega después. Llega cuando los datos no se comunican entre sí, los informes se estropean con cada cambio en el sistema de gestión y cada solicitud pasa por consultores o desarrolladores en lugar de por el equipo que debe tomar la decisión.

El almacenamiento tiene menos importancia de lo que parece. Lo que realmente importa son las actividades que garantizan la fiabilidad y la utilidad de los datos: modelización, integraciones, permisos, calidad, supervisión, corrección de errores y asistencia al usuario.
Un almacén de datos requiere trabajo al principio. Hay que definir métricas, crear flujos de datos, armonizar las fuentes y mantener todo en orden cuando cambian los sistemas ERP, CRM o las reglas de negocio. A cambio, la dirección dispone de cifras más estables y la elaboración de informes tiende a ser más predecible.
Un lago de datos suele presentarse con una promesa más modesta. Se cargan datos de distintos tipos y se posponen algunas de las decisiones estructurales. El problema es que posponerlas no elimina el trabajo. Simplemente lo desplaza a una fase posterior, donde se manifiesta en forma de catalogación, seguridad, costes de cálculo, duplicaciones, versiones incoherentes y continuas verificaciones sobre qué datos son realmente fiables.
El riesgo para una pyme es tener que pagar dos veces: primero, por recopilar los datos; y luego, por hacerlos finalmente legibles.
La verdadera complejidad no es técnica. Es operativa.
Si cada nuevo informe requiere intervenciones manuales, si el responsable de control de gestión y el comercial utilizan definiciones diferentes de la misma métrica, si el empresario tiene que esperar días para obtener una cifra fiable, el proyecto de datos ya está mermando el margen. Aunque, sobre el papel, la infraestructura parezca moderna.
Por eso conviene evaluar también el modelo de gestión, y no solo la arquitectura. Las soluciones en la nube para pymes ayudan precisamente a entender esta diferencia: qué es lo que realmente estás comprando, qué parte del mantenimiento se queda en la empresa y en qué medida dependes de conocimientos especializados cada mes.
En el mercado italiano, quienes invierten en analítica buscan resultados tangibles: menos trabajo manual, cierres más rápidos y un mayor control sobre las ventas, los márgenes, las existencias y el flujo de caja. No una plataforma sofisticada que quede en manos de unos pocos.
Esto cambia los criterios de elección. Una pyme no debería preguntarse qué arquitectura es más atractiva o más flexible en teoría. Debería preguntarse cuánto tiempo se necesita para conseguir paneles de control fiables, cuántas personas se necesitan para mantenerlos y con qué rapidez el proyecto genera valor.
En el sector minorista, los costes ocultos no tardan en salir a la luz. Si las ventas, las devoluciones, las promociones y las existencias proceden de sistemas diferentes, basta con una definición errónea de «margen» o «ventas netas» para que se pierda la confianza en los informes. En ese momento, el problema no es la base de datos elegida, sino que el propietario vuelve a tomar las decisiones en Excel.
En el ámbito financiero, el coste de los errores es aún más evidente. La elaboración de informes, el cierre de cuentas, el control de gestión y el análisis de desviaciones requieren datos coherentes y trazables. Si cada revisión da lugar a debates sobre el origen de las cifras, el proyecto pierde rentabilidad incluso antes de llegar a su fin.
Por eso, en la práctica, muchas pymes no necesitan crear desde cero un lago de datos o un almacén de datos completo. Necesitan un sistema más ligero, manejable y orientado a la toma de decisiones.
Si no consigues mantener la calidad de los datos, las reglas de acceso y las definiciones compartidas a lo largo del tiempo, el problema no es la elección entre un lago de datos y un almacén de datos. El problema es haber adquirido complejidad antes de tener un caso de uso que la justifique.
La pregunta correcta no es qué arquitectura es «mejor» en términos absolutos. La pregunta es qué problema tienes que resolver mañana por la mañana.

En el sector minorista, el almacén funciona bien cuando hay que responder siempre a las mismas cuestiones operativas:
Lo mismo ocurre en el ámbito financiero. Si necesitas consolidar datos estructurados, elaborar informes periódicos, analizar carteras o interpretar la evolución económica con criterios fijos, el almacén de datos sigue siendo la opción más lógica.
El «lake» tiene sentido cuando tu empresa recopila datos muy diversos y no quieres o no puedes definirlo todo de antemano.
Un ejemplo realista es el de una empresa energética que combina:
En un contexto como este, un almacén de datos clásico te obliga a diseñar primero las relaciones entre fuentes que quizá aún no conozcas bien. Un lago de datos permite centralizarlo todo y estructurarlo solo cuando es necesario para un análisis específico. Este es el tipo de situación en la que la flexibilidad del lago de datos realmente aporta valor.
El data lake no es una opción «más moderna». Solo tiene sentido cuando la variedad de los datos justifica la complejidad que ello conlleva.
La mayoría de las pymes no se encuentran en esa situación. Disponen principalmente de datos procedentes de sistemas ERP, CRM, comercio electrónico, contabilidad, exportaciones CSV y Excel. En estos casos, el problema no es gestionar archivos de vídeo, registros de aplicaciones o texto sin formato a gran escala. El problema es disponer de datos limpios, coherentes y comprensibles para personas sin conocimientos técnicos.
Hay que dejarlo claro: a menudo no hace falta ni un lago de datos ni un almacén de datos tradicional.
Lo que hace falta es más bien:
Lakehouse intenta combinar ambos mundos. Promete la flexibilidad de Lake y algunas de las cualidades de Warehouse en un mismo entorno. Es una dirección interesante, sobre todo para empresas con cargas de trabajo mixtas que incluyen BI, IA y ciencia de datos.
Para una pyme, sin embargo, la pregunta sigue siendo la misma: ¿realmente tienes un problema que justifique todo esto? Si lo que necesitas es analizar mejor las ventas, los márgenes, el flujo de caja o las previsiones, una solución híbrida sofisticada puede seguir siendo desproporcionada en relación con el valor esperado.
El «data lakehouse» surge para superar la rígida separación entre el lago de datos y el almacén de datos. La idea es sencilla: mantener la flexibilidad de un almacenamiento amplio y abierto, pero añadir orden, rendimiento y capacidades analíticas más cercanas a las de un almacén de datos. Tecnologías como Databricks y Delta Lake representan bien esta tendencia.
En teoría, resulta muy atractivo. Se utiliza la misma base de datos para la inteligencia empresarial, el análisis avanzado y el aprendizaje automático, lo que evita duplicar demasiada información entre distintos sistemas. Para las grandes organizaciones o los equipos de datos con experiencia, es una respuesta lógica a un ecosistema que se ha ido complicando con el tiempo.
En las pruebas de rendimiento académicas, la arquitectura de data lakehouse se evalúa mediante métricas como el rendimiento, la latencia y la sobrecarga de metadatos. Esto demuestra que la comparación con el data warehouse no es solo funcional, sino también en términos de rendimiento, en escenarios en los que pequeñas diferencias de rendimiento tienen un impacto significativo, tal y como se pone de manifiesto en esta presentación académica sobre las pruebas de rendimiento de lakehouse.
Traducido al lenguaje empresarial: el «lakehouse» resuelve los problemas de las organizaciones que ya cuentan con un cierto nivel de escala, complejidad y especialización.
Si realmente no necesitabas ni un lago de datos ni un almacén de datos, es poco probable que necesites un sistema que combine ambos.
Para la mayoría de las pymes, la pregunta más útil no es «¿qué arquitectura elijo?», sino «¿cómo consigo análisis fiables sin convertir el proyecto de datos en una obra en constante construcción?».
Esta es la tercera vía que suele pasarse por alto en muchas comparaciones entre data lakes y data warehouses. No se trata de construir una nueva infraestructura propietaria, sino de añadir una capa de análisis sobre los sistemas que ya utilizas, trasladando la complejidad técnica fuera del ámbito operativo de la empresa.

En la práctica, el enfoque más sensato es el siguiente:
He visto a más de una pyme invertir meses en un almacén de datos tradicional y luego apenas utilizarlo. No porque estuviera mal diseñado, sino porque nadie en la empresa sabía cómo consultar sus datos por su cuenta. El cuello de botella no era la base de datos, sino la accesibilidad.
Este es un aspecto que a menudo se subestima. Una arquitectura sofisticada que siempre requiere un intermediario técnico reduce el valor práctico de los datos. Una solución más sencilla, pero comprensible para la dirección, suele dar lugar a mejores decisiones con mayor rapidez.
Por eso, muchas empresas obtienen más valor de un software de inteligencia empresarial para pymes bien diseñado que de un programa de infraestructura sobredimensionado. Lo que buscan no es tener un almacén de datos, sino comprender mejor y antes el negocio.
La infraestructura adecuada es aquella que tu equipo es capaz de utilizar, mantener y convertir en decisiones. No la que causa impresión en una diapositiva técnica.
El debate entre «data lake» y «data warehouse» es útil, pero para una pyme suele partir de una pregunta equivocada. Antes de elegir una arquitectura, debes averiguar si realmente tienes un problema de escala y variedad de datos, o si se trata de un problema mucho más común: datos dispersos, informes manuales y escasa accesibilidad.
El data warehouse sigue siendo la mejor opción cuando se necesitan informes fiables, KPI coherentes y un rendimiento predecible. El data lake tiene sentido cuando la variedad de fuentes justifica una mayor flexibilidad y complejidad. El lakehouse es una evolución interesante, pero rara vez es el primer paso adecuado para una empresa que busca, ante todo, control operativo y retorno de la inversión.
La elección más inteligente no es la tecnología más avanzada. Es aquella que se adapta al problema real, a las competencias disponibles y a la rapidez con la que quieres convertir los datos en decisiones.
Si quieres convertir los datos de tu empresa en informes, previsiones y conocimientos operativos sin tener que crear una infraestructura compleja, descubre ELECTE, una plataforma de análisis de datos basada en IA para pymes. Puedes partir de los datos que ya tienes, reducir el trabajo manual y poner el análisis al alcance de tu equipo con un enfoque mucho más ágil.

.svg)
.svg)
.svg)






