

Echa un vistazo al informe de ventas del mes. Los ingresos parecen haber aumentado, el margen parece haber mejorado, y, sin embargo, hay esa molesta sensación de que algo no cuadra. No es paranoia. Es experiencia operativa. Quien trabaja en una pyme italiana sabe que, entre el sistema de gestión, las exportaciones a Excel y las modificaciones manuales, los datos cambian de forma varias veces antes de llegar a un panel de control.
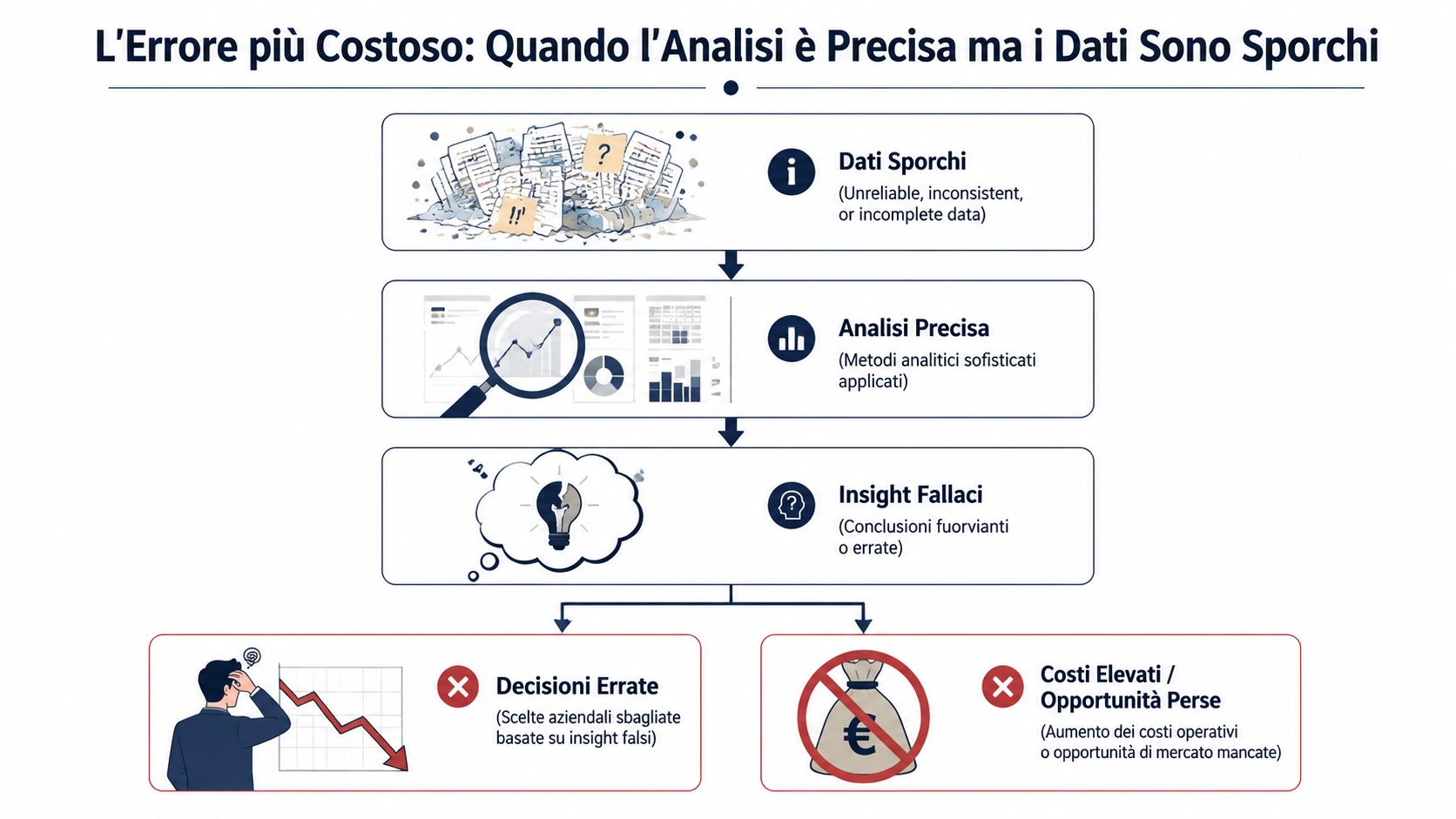
La cuestión es sencilla: un análisis impecable basado en datos erróneos no te sirve de nada. Te engaña. Te da una respuesta precisa, elegante y tranquilizadora, pero construida sobre bases frágiles. Y es mucho más peligroso que un informe incompleto, porque te empuja a tomar decisiones con seguridad cuando en realidad no la hay.
Las técnicas de validación de datos sirven precisamente para eso: sacar a la luz los errores. No hacen que los datos sean «perfectos». Hacen visibles los problemas que hoy pasan desapercibidos. Si te encargas de la administración, el control de gestión, las ventas o las operaciones, este es el trabajo que distingue una cifra útil de una cifra meramente decorativa. Y en las pymes vale más que muchas iniciativas «avanzadas» de análisis de datos, porque los beneficios se notan de inmediato, a menudo ya desde la primera importación.
En las pymes, los datos rara vez se generan allí donde se consultan. Pasan de un programa de gestión a un archivo exportado, luego a Excel y, a continuación, a una versión «arreglada» por alguien que solo tenía que corregir dos columnas y acabó reescribiendo la mitad de la hoja. Cuando el informe final no convence, el problema no suele ser el gráfico. Es todo lo que ha ocurrido antes.
La validación de datos es el tema menos atractivo y más importante de todo el ciclo analítico. Ningún empresario quiere hablar de controles de formato o de campos obligatorios que faltan. Sin embargo, casi todas las decisiones erróneas que se toman a partir de paneles de control aparentemente limpios tienen su origen ahí: en un separador decimal cambiado, en una fecha mal interpretada, en un duplicado en el registro maestro, en un total que no cuadra pero que nadie ha comprobado.
Quien trabaja bien con los datos desarrolla un hábito concreto: antes de preguntarse qué dicen las cifras, se pregunta si esas cifras son fiables. Las mejores técnicas de validación de datos no son las más sofisticadas, sino aquellas que detectan a tiempo los errores más comunes, sin ralentizar el trabajo diario.
Si no confías lo suficiente en los datos como para tomar una decisión importante, el problema no es la decisión. Es la validación.
El error típico no es un informe que esté claramente erróneo. Es un informe ordenado, aparentemente coherente, elaborado a partir de datos que ya han perdido su fiabilidad. Cuando esto ocurre, el daño no radica solo en la cifra errónea, sino en el hecho de que nadie la cuestiona.
Esta disciplina ha evolucionado mucho. La validación de datos ha pasado de ser un control principalmente manual a consistir en verificaciones automatizadas y estadísticas. Las mejores prácticas distinguen al menos cinco controles básicos: comprobación de tipo de datos, comprobación de código, comprobación de rango, comprobación de formato y comprobación de coherencia, tal y como resume Teradata en su visión general sobre la validación de datos. En Italia, esta evolución cobra aún más importancia en los entornos regulados, donde incluso un solo campo erróneo puede alterar los informes, los modelos de previsión o el cumplimiento normativo.
El primer error es quedarse en lo superficial. Muchas empresas se limitan a realizar la comprobación más sencilla: la sintáctica.
Un número de identificación fiscal bien escrito puede superar la primera barrera y fallar en la segunda. El importe total de una factura puede ser numérico y tener el formato correcto, pero si no coincide con la suma de las líneas, tienes un problema mucho más grave que el simple formato.
Regla práctica: una comprobación que solo analiza una columna detecta errores triviales. Una comprobación que relaciona varios campos detecta los errores que influyen en las decisiones.
La validación útil no llega al final del trabajo. Llega antes. Si esperas al informe final, el error ya se habrá transformado, agregado, copiado a otros archivos y debatido en una reunión. En ese momento, corregirlo cuesta atención, tiempo y credibilidad.
Esto es aún más cierto cuando empiezas a utilizar métodos más sofisticados, como la detección de anomalías o la gestión de valores atípicos estadísticos. Son herramientas útiles, pero no sustituyen a los controles básicos. Si una columna importada como texto contiene precios, no necesitas un modelo complejo. Lo que necesitas es un filtro básico que detecte el error en la entrada.
Un buen análisis no parte de los paneles más bonitos. Parte de datos que han superado una serie de pruebas sensatas en el momento en que entran en el flujo.
En el día a día de las pymes, la mayor parte del valor proviene de controles sencillos. No de las técnicas académicas más sofisticadas. Ni de procesos complejos que nadie va a mantener. Sino de reglas claras, repetibles y cercanas al punto en el que los datos entran realmente en la empresa.

En el contexto italiano, este enfoque está en consonancia con el enfoque del ISTAT, que define la calidad de los datos a través de dimensiones como la exactitud, la coherencia y la exhaustividad, y utiliza el control VIMO (Valid, Invalid, Missing, Outlier) para medir los valores válidos, faltantes y atípicos. Este enfoque prevé la validación en la fase de entrada, durante la transformación y antes del uso final de los datos, tal y como se explica en el material del ISTAT sobre la calidad y la validación de los datos.
El proceso habitual es siempre el mismo. El dato se genera en el sistema de gestión. Se exporta. Se pasa a Excel. Alguien corrige un encabezado, arrastra una fórmula, copia una columna, cambia el formato de la fecha «para arreglarlo». A partir de ahí empiezan los errores ocultos.
Estas son las comprobaciones que conviene realizar de inmediato:
Si trabajas con exportaciones manuales, puedes empezar con una plantilla muy concreta:
| Control | Error típico en las pymes | Una pregunta que debes hacerte |
|---|---|---|
| Tipo | Precio de la cama como texto | ¿Se puede calcular esta columna? |
| Formato | Fechas mixtas entre distintos formatos | ¿El sistema siempre la interpreta de la misma manera? |
| Gama | Importes fuera de escala | ¿Es este valor razonable para un cliente o un producto? |
| Singularidad | Cliente introducido varias veces | ¿Estoy contando personas diferentes o nombres escritos de forma diferente? |
| Exhaustividad | Campos clave vacíos | ¿Puedo utilizar este registro en informes y decisiones? |
| Coherencia | Cifras totales que no cuadran | ¿Se confirman unas a otras las columnas? |
Para quienes trabajan en sectores en los que la calidad documental y procedimental ya tiene un gran peso operativo, merece la pena analizar también prácticas más estructuradas de cualificación y control. Una lectura útil es la Guía para la cualificación en sectores regulados, ya que ilustra claramente que la disciplina de la validación no es solo una cuestión de «limpieza», sino de control del proceso.
Los duplicados merecen una mención aparte. Son un problema crónico en las bases de datos de muchas pymes y distorsionan casi todo: clientes activos, frecuencia de compra, exposición comercial e historial de relaciones. Si quieres partir de un caso concreto, encontrarás un enfoque práctico en ELECTE: guía completa sobre duplicados en Excel.
Los controles sofisticados solo sirven de algo una vez que se han sentado las bases. De lo contrario, es como instalar un radar en un coche sin frenos.
Lunes por la mañana, reunión comercial. El propietario revisa el informe de ventas, el responsable administrativo revisa otro archivo y el controlador tiene un tercero. Las cifras deberían coincidir. Pero no coinciden.
Es una situación habitual en las pymes italianas. Un antiguo sistema de gestión exporta archivos CSV con campos fijos. El CRM utiliza etiquetas diferentes. El comercio electrónico tiene su propia lógica. Entonces entra en escena Excel, que se convierte en el lugar donde alguien ajusta los encabezados, copia columnas, corrige fechas e intenta que todo cuadre antes de la reunión.
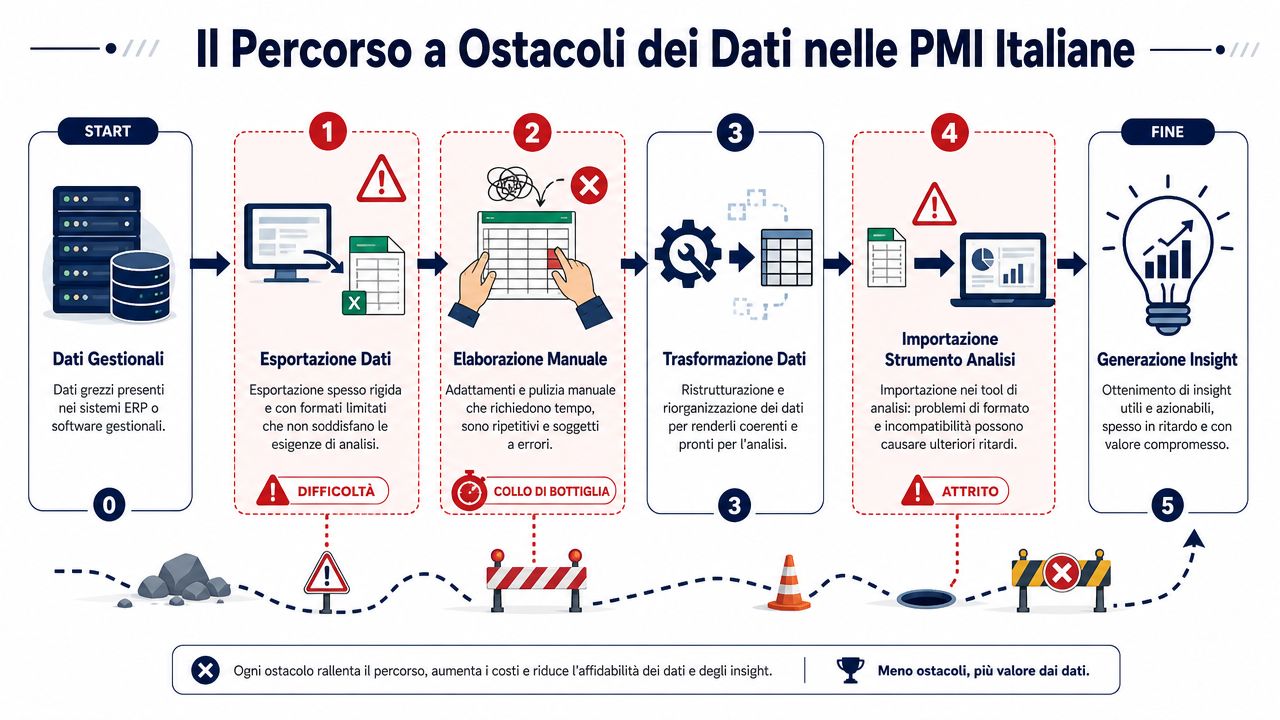
El problema no es la tecnología en sí misma. El problema es la suma de pequeños pasos manuales sobre datos que proceden de sistemas creados en momentos diferentes, a menudo sin una norma común. Quien trabaja conectando diferentes fuentes de datos lo ve enseguida: cada fuente trae consigo sus propias convenciones, errores recurrentes y campos rellenados «como viene a ser».
Los errores más costosos no detienen el proceso. Se registran en el archivo y permanecen allí.
Ocurre todos los días en situaciones muy concretas:
En este sentido, muchas empresas cometen el mismo error. Buscan soluciones sofisticadas antes de haber garantizado la seguridad de los controles más básicos, pero que resultan muy rentables: tipos de datos correctos, claves coherentes, códigos protegidos y fechas que todos los sistemas puedan leer de la misma forma.
En las pymes, los datos rara vez se generan de forma clara y estable. Pasan por administración, ventas, logística, consultores externos y archivos locales con nombres como «report_finale_def_vero.xlsx». Cada persona corrige lo que necesita para trabajar. Casi nadie documenta los cambios.
Por eso, los controles académicos o los proyectos de detección de anomalías demasiado ambiciosos suelen llegar fuera de lugar. Primero hay que centrarse en lo básico. Un control automático que señale códigos CAP no válidos, códigos de cliente truncados, líneas duplicadas o fechas fuera de período evita más errores que muchas iniciativas «avanzadas» puestas en marcha demasiado pronto.
Lo digo sin rodeos porque es el problema que veo con más frecuencia: una pyme no pierde la confianza en los datos por falta de inteligencia artificial. La pierde porque la propia cifra de negocios varía de un archivo de Excel a otro, y nadie sabe decir cuál es la versión correcta.
El archivo que «siempre ha funcionado» suele ser aquel que ya nadie revisa.
Cuando los datos pasan por varias manos y varios sistemas, la validación no tiene por qué ser elegante. Debe ser repetible, tediosa y realizarse lo más cerca posible del punto de entrada de los datos. Es ahí donde se obtiene gran parte del valor, incluso antes de hablar de modelos predictivos o de paneles de control más atractivos.
Los lunes por la mañana suelen empezar así. El responsable administrativo abre dos archivos de exportación del mismo mes, uno del sistema de gestión y otro del archivo comercial, y las cifras no cuadran. Nadie tiene tiempo para volver a hacer los controles a mano. En ese momento, el problema no es el informe. Es que la confianza en las cifras ya se ha perdido.
ELECTE interviene antes de que los datos sin procesar se incorporen a los análisis. Para una pyme italiana, ese es el aspecto que realmente importa. No sirve de nada una herramienta complicada que prometa controles sofisticados si luego deja pasar errores triviales de importación, columnas mal interpretadas o códigos cuyo formato cambia de un sistema a otro.
En la práctica, la plataforma comprueba los datos a medida que llegan. No después del informe. No después de la reunión en la que alguien pregunta por qué ha cambiado el margen de una versión del archivo a otra.
Los controles automáticos abordan los problemas que, en las pymes, causan más daños de lo previsto: tipos de datos incoherentes, campos que faltan, fechas fuera de rango, duplicados, valores fuera de rango y claves que no se vinculan a las tablas correctas. Son comprobaciones poco glamurosas, pero son las que evitan más errores operativos en entornos repletos de exportaciones de Excel, sistemas ERP obsoletos y archivos enviados por correo electrónico.
Luego está el nivel contextual. En la incorporación de nuevos empleados se establecen normas coherentes con el proceso empresarial real, no con un modelo teórico. Una empresa del sector de la distribución tiene necesidades diferentes a las de una agencia que gestiona visitas turísticas o a las de un fabricante con listas de precios y descuentos por niveles. Lo mismo ocurre con casos documentales específicos, como la lectura de datos estructurados a partir de documentos y registros de entrada, un tema relevante también para quienes trabajan con MRZ en establecimientos hoteleros.
La ventaja práctica es sencilla: el equipo no tiene que pensar cada vez qué controles debe realizar. Los encuentra ya aplicados de forma coherente y repetible.
Un ejemplo típico. Una actualización del sistema de gestión cambia el formato de algunos campos de precio solo en una parte del archivo de exportación. A simple vista, el archivo parece correcto. Sin embargo, al analizarlo, esos valores alteran la facturación, los márgenes y las comparaciones con los meses anteriores. ELECTE señala inmediatamente la anomalía, aísla las líneas afectadas y permite corregirlas antes de que aparezcan en los paneles de control y los informes directivos.
Uno de los aspectos más útiles, para quienes deben tomar decisiones y no se dedican a la ciencia de datos, es la gestión de excepciones. Los registros problemáticos no desaparecen. Siguen siendo visibles, están separados y se indica el motivo.
Quien utiliza los datos lo entiende enseguida:
Esta transparencia evita uno de los peores hábitos que veo en las pymes: limpiar el conjunto de datos sin dejar rastro y descubrir semanas después que las cifras ya no cuadran.
La función de conectar diferentes fuentes de datos cobra importancia precisamente por este motivo. No basta con conectar el CRM, el ERP, el comercio electrónico y los archivos manuales. Si los datos se integran sin controles claros, el caos sigue siendo el mismo, solo que en una pantalla más ordenada.
ELECTE no promete datos perfectos. Reduce los errores más frecuentes, los hace visibles y evita que aparezcan en los informes como si fueran correctos. Para una pyme, a menudo esto es lo que marca la diferencia entre hablar de cifras y debatir sobre ellas.
La validación no debe considerarse un proyecto técnico independiente del negocio. Debe abordarse como una disciplina operativa. Quien elabora un presupuesto, aprueba una lista de precios, revisa los márgenes o planifica las compras ya está utilizando datos bien validados o mal validados. No existe una tercera opción.
Las reglas útiles son pocas, pero hay que aplicarlas con constancia:
Válido al inicio, pero no al final
. Si la comprobación llega hasta el final, el error ya habrá afectado a fórmulas, agregaciones e informes.
No te limites al formato
. Un dato puede estar bien escrito y, aun así, ser incorrecto. Debes comprobar la plausibilidad y la coherencia entre los campos, no solo que se respete un esquema.
Automatiza las comprobaciones repetitivas
Ningún equipo administrativo o comercial tiene tiempo para volver a comprobar manualmente cada exportación. Las comprobaciones básicas deben convertirse en un proceso sistemático.
Evita las normas demasiado estrictas
Existe un equilibrio real entre el rigor y la productividad. Las normas demasiado estrictas pueden reducir la adopción de herramientas analíticas por parte de los equipos no técnicos, tal y como destaca Acceldata en su reflexión sobre la relación entre rigor y productividad en la validación de datos. El umbral adecuado es aquel que minimiza los errores sin ralentizar la actividad empresarial.
Considera las excepciones como señales, no como molestias
Un registro anómalo casi siempre revela algo sobre el proceso que lo ha generado. Ignorarlo significa renunciar a mejorar desde el principio.
Un ejemplo útil nos lo ofrecen aquellos ámbitos en los que el formato no es un simple detalle, sino una condición imprescindible para el funcionamiento. En los establecimientos hoteleros, por ejemplo, la cuestión de la lectura automática de documentos ilustra claramente que los datos no solo deben estar presentes, sino que también deben ser coherentes con un estándar interpretable. Quien desee una referencia concreta puede leer este artículo de fondo sobre MRZ para establecimientos hoteleros.
La mentalidad correcta es esta: confía en los datos solo después de haberlos puesto a prueba. Si hoy te basas en archivos que nadie comprueba de forma sistemática, no estás haciendo un análisis. Solo estás esperando que salga bien.
La mayoría de los problemas en los informes no surgen en el último gráfico. Surgen mucho antes, cuando datos incompletos, incoherentes o fuera de contexto se introducen en los sistemas sin un filtro riguroso. Por eso, las técnicas de validación de datos son más importantes de lo que parece. Son el punto en el que dejas de ser víctima de los datos y empiezas a controlarlos.
Para una pyme, el beneficio no reside en perseguir la perfección, sino en generar un nivel de confianza suficiente para tomar decisiones con claridad. Los controles de tipo, formato, rango, unicidad, integridad y coherencia cruzada resuelven gran parte de los problemas reales. La automatización hace que estos controles sean viables.
Si no cuentas con un proceso de validación estructurado, no estás confiando en los datos. Estás confiando en la suerte.
Si quieres convertir exportaciones confusas, archivos de Excel inestables y fuentes de datos heterogéneas en análisis fiables, descubre cómo ELECTE, una plataforma de análisis de datos basada en IA para pymes, automatiza los controles, la detección de anomalías y la obtención de información sin añadir complejidad a tu equipo.

.svg)
.svg)
.svg)






