

Recibes un archivo XML a través del correo electrónico certificado (PEC). Lo abres en el navegador, ves un sinfín de etiquetas y piensas que el problema es «leerlo». En realidad, ese es solo el primer obstáculo. El verdadero problema en la empresa es otro: averiguar si esos datos son correctos, coherentes y están listos para incluirlos en tus informes.
Para muchas pymes italianas, este tema ya no es estrictamente técnico. Desde que la facturación electrónica pasó a ser obligatoria, el XML se ha incorporado al trabajo diario de administración, control de gestión y análisis. No basta con visualizar el documento. Hay que saber distinguir entre un archivo legible y uno fiable. Hay que saber cuándo basta con una comprobación rápida y cuándo es necesario realizar un análisis sintáctico, una validación y una normalización antes de cargar los datos en Excel, en el sistema de BI o en una plataforma de análisis.
Si estás buscando una guía práctica sobre cómo leer archivos XML, este es el camino correcto: empezar por los métodos sencillos, entender dónde fallan y, a continuación, crear un flujo que transforme el XML sin procesar en datos útiles para el negocio. Así es como se reducen los errores y se acorta el tiempo que transcurre entre «tengo el archivo» y «tengo una información útil».
Un archivo XML organiza los datos en una estructura jerárquica. Hay un elemento principal, hay secciones anidadas y cada bloque describe una información con un significado concreto. Para quienes gestionan procesos administrativos, este detalle marca la diferencia entre un dato legible y un dato realmente utilizable.
La cuestión no es «abrir» el archivo. La cuestión es averiguar si ese archivo puede integrarse sin errores en los procesos de control, contabilidad y análisis.
Tomemos como ejemplo una factura electrónica. En un mismo archivo conviven los datos del proveedor, los del cliente, las bases imponibles, el IVA, las líneas de artículos, las condiciones de pago, las referencias del pedido y, a menudo, también excepciones que complican su lectura. En XML, esta información no se presenta una debajo de otra como en cualquier hoja de cálculo. Se sitúa en posiciones concretas, y esa posición explica qué representan.
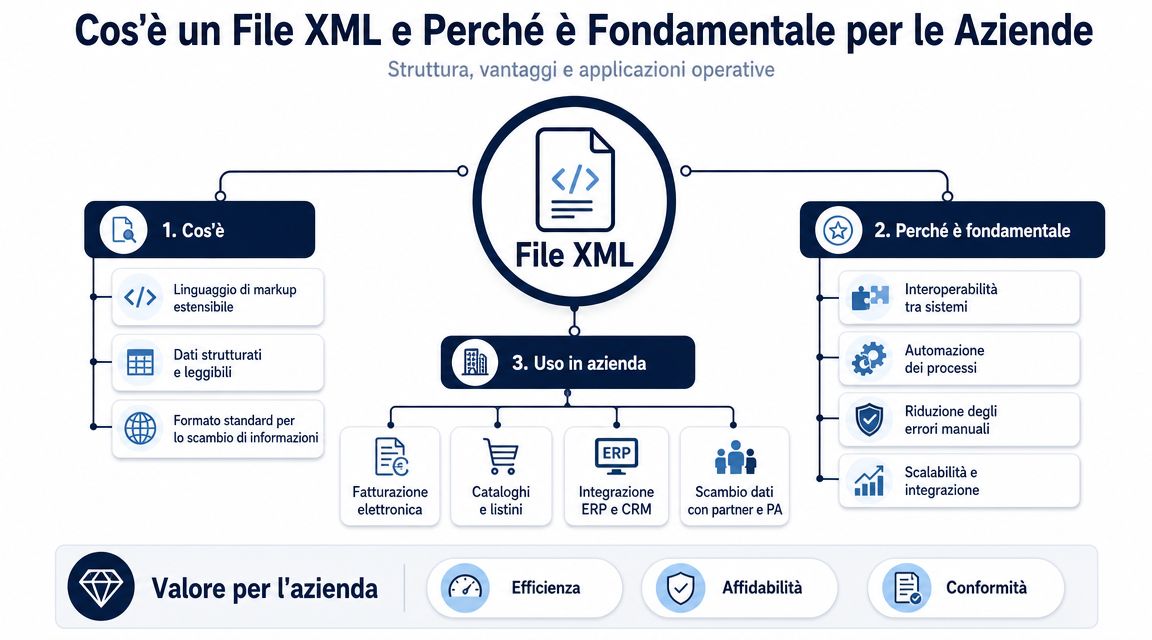
Para un directivo, la distinción útil no es entre etiquetas y atributos en sentido teórico, sino entre un dato aislado y un dato fiable. Leer «1000,00» fuera de contexto no sirve de mucho. Leerlo en el lugar correcto del archivo permite entender si se trata del total del documento, la base imponible, el impuesto o el valor de una sola línea.
Aquí surge la primera ventaja operativa. El XML conserva el contexto de los datos.
Regla práctica: leer bien un archivo XML significa comprobar el significado del valor, no solo el valor en sí.
En Italia, esta cuestión ha cobrado relevancia con la implantación de la facturación electrónica. En el formato FatturaPA, el XML se ha convertido en el estándar para la documentación fiscal. En consecuencia, su interpretación ya no es competencia exclusiva del departamento de TI. Afecta a la administración, al control de gestión, al departamento de compras y a cualquier persona que deba utilizar esos datos para tomar decisiones.
En la práctica, siempre veo el mismo problema. El archivo existe, los datos están ahí, pero el tiempo que se tarda en convertirlos en información útil se alarga demasiado. Una persona abre el XML, lo revisa a simple vista, copia los valores en Excel, corrige los campos que no están uniformes, renombra a los proveedores cuyos nombres están escritos de formas diferentes e intenta reconstruir categorías de gasto que el archivo no presenta en un formato listo para el análisis. El coste no es solo operativo. Es tiempo perdido para obtener información útil.
Con FatturaPA, el riesgo es aún más evidente. Dos archivos formalmente correctos pueden plantear los mismos problemas de análisis si uno de ellos utiliza descripciones de línea muy imprecisas, si las referencias de pedido están incompletas o si los datos maestros del proveedor se introducen con variantes diferentes. En ese caso, el problema no es leer el XML. El problema es evitar que los datos fiscales válidos se conviertan en datos de gestión poco fiables.
Un error habitual es tratar el XML como un archivo adjunto que hay que visualizar. En la empresa, resulta más eficaz considerarlo como una fuente de datos estructurada que hay que verificar antes de que alimente informes, cuadros de mando y modelos de gasto. Si esta fase se gestiona mal, el equipo de finanzas se ve obligado a debatir cifras aparentemente precisas, pero basadas en clasificaciones incoherentes.
Las preguntas adecuadas, al principio, son estas:
Se trata de comprobaciones muy concretas. Sirven para evitar que aparezcan proveedores por duplicado en los informes, errores en la interpretación del IVA, centros de coste con datos incompletos y conciliaciones lentas a final de mes.
Es aquí donde se aprecia la diferencia entre la lectura técnica y el valor empresarial. Un analizador sintáctico lee el archivo. Un proceso bien diseñado genera datos limpios, comparables y listos para su análisis. Plataformas como ELECTE se han creado precisamente para salvar esta brecha, reduciendo el trabajo manual que separa el XML recibido de la información útil para tomar mejores decisiones.
Para realizar comprobaciones rápidas de un solo archivo, no se necesitan analizadores sintácticos ni bibliotecas. Hay que tener en cuenta si se trata de una comprobación visual de unos pocos campos o si ya se están manipulando datos que acabarán en contabilidad, en la elaboración de informes o en el control de gestión. La diferencia es importante, sobre todo con las facturas FatturePA. Una comprobación realizada de forma apresurada hoy puede convertirse mañana en una línea errónea en el conjunto de datos de proveedores.

Los navegadores, los editores de texto y los visores específicos resuelven un problema concreto: leer rápidamente el contenido sin tener que configurar un flujo técnico. Para un archivo aislado, a menudo es suficiente. Puedes abrir un archivo XML en Chrome, Edge o Firefox para ver la estructura, o utilizar el Bloc de notas, WordPad o TextEdit si quieres examinar directamente las etiquetas. En el caso de las facturas electrónicas, un visor específico facilita la lectura de los encabezados, las líneas del documento, la base imponible y el IVA.
La cuestión fundamental es la siguiente:
| Instrumento | Útil para | Limitación principal |
|---|---|---|
| Navegador | Inspección visual rápida de la estructura | No comprueba la coherencia entre los campos y las secciones |
| Editor de texto | Inspección directa de las etiquetas | Resulta incómodo con archivos largos o anidados |
| Excel | Comprobación preliminar en formato de tabla | No gestiona bien las jerarquías y las repeticiones |
| Visor específico | Una lectura más clara de las facturas y los documentos fiscales | No prepara los datos para su análisis o automatización |
Si necesitas comprobar la fecha del documento, el número de IVA, el importe total de la factura o si hay archivos adjuntos, estas herramientas son adecuadas.
Sin embargo, si el objetivo es comparar proveedores, clasificar gastos o alimentar un panel de control, la mera visualización ralentiza el trabajo y deja demasiado margen para los errores manuales. Es la clásica diferencia entre ver un archivo y obtener un dato fiable a tiempo.
Abrir un archivo XML no equivale a validar los datos que vas a utilizar en los informes.
Otro aspecto práctico tiene que ver con el volumen. Diez archivos se pueden revisar incluso a mano. Pero cientos de facturas FatturePA, no. En ese caso, ya conviene plantearse un flujo repetible o herramientas que lean el contenido de forma estructurada, por ejemplo, mediante una API para capturar y gestionar documentos fiscales de forma integrada.
En Italia, el problema habitual no es abrir un .xml, pero saber qué hacer cuando llega un .xml.p7m a través de PEC. Hay que distinguir entre archivos XML simples y archivos firmados digitalmente. En el segundo caso se necesitan herramientas capaces de leer la firma, extraer el contenido y mostrar el XML correcto, tal y como explica esta guía dedicada al XML y al XML P7M en el correo electrónico certificado (PEC).
Aquí los errores cuestan tiempo:
Para un empleado administrativo, la secuencia más útil es sencilla:
Estos métodos funcionan bien en los controles de primer nivel. Sin embargo, no resuelven el verdadero problema de la empresa: transformar los archivos XML fiscales, a menudo irregulares o poco uniformes, en datos limpios y comparables sin alargar el tiempo que transcurre entre la recepción del documento y la obtención de la información útil.
Cuando los archivos empiezan a acumularse, el trabajo manual deja de ser viable. En ese momento, leer archivos XML mediante código ya no es una opción adecuada. Es el primer paso para evitar tareas repetitivas, errores de copia y conjuntos de datos incoherentes.

Un enfoque sólido para la lectura de XML sigue siempre la misma lógica: análisis sintáctico, normalización y extracción selectiva. En los tutoriales de Java y Android, el flujo correcto pasa por parse(), a partir de la normalización del árbol con doc.getDocumentElement().normalize() y, además, de la recuperación de los campos con getElementsByTagName, un método más estable que la simple visualización en un editor de texto, como se muestra en este tutorial técnico sobre cómo leer datos XML.
Esta secuencia es más importante que el lenguaje que elijas. Si te saltas la normalización, si buscas nodos de forma demasiado ingenua o si das por sentado que una etiqueta siempre aparece una sola vez, tu script funcionará en algunos archivos y fallará precisamente en los que realmente importan.
En el caso de proyectos que deban interactuar posteriormente con sistemas externos, puede resultar útil crear un flujo de extracción replicable y documentado. Si trabajas en integraciones de aplicaciones, una base útil es la documentación sobre las API de ELECTE con perfil de Postman verificado, sobre todo para comprender cómo conectar un conjunto de datos ya depurado a los procesos posteriores.
A continuación encontrarás algunos ejemplos sencillos. El objetivo no es abarcar todos los casos, sino mostrarte la lógica básica: abrir el archivo, buscar un nodo e imprimir un valor.
import xml.etree.ElementTree as ETtree = ET.parse("factura.xml")root = tree.getroot()número = root.find(".//Número")if número is not None:print(número.text)Python suele ser la opción más rápida para prototipos, transformaciones y procesos ligeros. Es ideal cuando hay que leer muchos archivos XML, extraer unos pocos campos y guardarlos en formato CSV o JSON.
const xmlString = `<fattura><Numero>123</Numero></fattura>`;const parser = new DOMParser();const xmlDoc = parser.parseFromString(xmlString, "application/xml");const numero = xmlDoc.getElementsByTagName("Numero")[0];console.log(numero.textContent);Este enfoque resulta útil para pruebas rápidas en la propia página o para pequeñas herramientas internas. Es adecuado para interfaces sencillas, pero no tanto para flujos estructurados de back-office.
const fs = require("fs");const xml2js = require("xml2js");const xml = fs.readFileSync("fattura.xml", "utf8");xml2js.parseString(xml, (err, result) => {if (err) throw err;console.log(result.fattura.Numero[0]);});Si trabajas en el lado del servidor y quieres crear automatizaciones, Node.js sigue siendo una opción práctica. La ventaja es que permite integrar fácilmente la lectura de XML con el sistema de archivos, las colas de procesamiento y los servicios internos.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse("fattura.xml");doc.getDocumentElement().normalize();NodeList lista = doc.getElementsByTagName("Numero");if (lista.getLength() > 0) {System.out.println(lista.item(0).getTextContent());}Java suele utilizarse en entornos empresariales, de gestión y de middleware. En este caso, lo fundamental no es solo leer los datos, sino hacerlo de forma predecible y fácil de mantener.
library(XML)doc <- xmlParse("fattura.xml")numero <- xpathSApply(doc, "//Numero", xmlValue)print(numero)R tiene sentido cuando el análisis sintáctico forma parte de un trabajo analítico. Si tu siguiente paso es un análisis estadístico o una preparación de datos, puedes mantenerlo todo en el mismo entorno.
Si tu equipo abre los mismos archivos cada semana y repite las mismas comprobaciones, ya estás en el ámbito de la automatización.
El beneficio real no es «leer XML con código». Es liberar a las personas de una tarea mecánica y crear un flujo que genere conjuntos de datos consistentes.
Los problemas graves empiezan cuando ya no se trata de un solo archivo. Una sola FatturaPA suele ser fácil de gestionar. La dificultad surge cuando hay que agrupar documentos de varios meses, de distintos proveedores, con campos rellenados de forma desigual y con archivos adjuntos incorporados.
En las pymes italianas, el caso más habitual no es el «megarchivo» aislado, sino el lote. Una exportación anual de facturas recibidas puede generar una estructura con más de 380 000 nodos en 4 200 facturas, entre encabezados, líneas de detalle, datos de pago y archivos adjuntos en base64. En estos casos, el problema no es abrir el documento, sino transformar XML heterogéneos en un conjunto de datos coherente.
Aquí entra en juego una decisión técnica que tiene repercusiones en el negocio. En el entorno .NET, Microsoft indica que XmlDocument carga el documento en memoria y resulta útil para la lectura y la modificación, mientras que, para archivos de gran tamaño u operaciones de solo lectura, conviene optar por enfoques más eficientes, como los analizadores de flujo continuo o XPathDocument, para evitar un consumo excesivo de RAM, tal y como se especifica en la documentación de Microsoft sobre la lectura de XML con XmlDocument y XPathDocument.
En resumen:
La disyuntiva es sencilla. El modelo en memoria te permite desarrollar más rápido. El modelo en streaming funciona mejor en producción cuando los archivos son muchos o muy pesados.
Muchos equipos se limitan a la validación XSD. Es útil, pero no basta. Un archivo puede cumplir con el esquema y, aun así, generar datos erróneos en las fases posteriores.
Ejemplos típicos del trabajo operativo:
| Tipo de control | ¿Qué comprueba? | ¿Para qué sirve? |
|---|---|---|
| Estructural | Etiquetas, formato, jerarquía | Evita los errores de análisis sintáctico |
| Semántico | Coherencia lógica de los datos | Evita los análisis erróneos |
| En funcionamiento | Existencia de campos útiles para la elaboración de informes | Evita los conjuntos de datos que no se pueden utilizar |
El caso más engañoso es el siguiente: el «Importe total del documento» es formalmente válido, pero no concuerda con la suma de las líneas, quizá debido a la lógica de redondeo del sistema de gestión del proveedor. O bien, los códigos de IVA son formalmente válidos, pero no se ajustan a la naturaleza de la operación.
Un archivo que, en teoría, sea correcto puede, no obstante, afectar negativamente a tus informes.
Además, hay otra trampa conocida en las facturas FatturaPA. La etiqueta «DatiBeniServizi» contiene descripciones libres. Un mismo coste puede aparecer de muchas formas diferentes, con textos claros, abreviados o crípticos. Si no se introduce un paso de normalización, cualquier análisis por categoría de gasto se vuelve poco fiable.
Por eso, en los flujos serios, la lectura del archivo es solo el nivel uno. El nivel dos es siempre un conjunto de reglas de coherencia y limpieza. Es ahí donde se protege la calidad de los datos, no en el analizador sintáctico.
Un archivo XML bien estructurado aún no es un conjunto de datos útil. Es un documento estructurado. Para realizar análisis, comparaciones, agrupaciones y paneles de control, casi siempre hay que convertirlo a un formato más fácil de manejar.
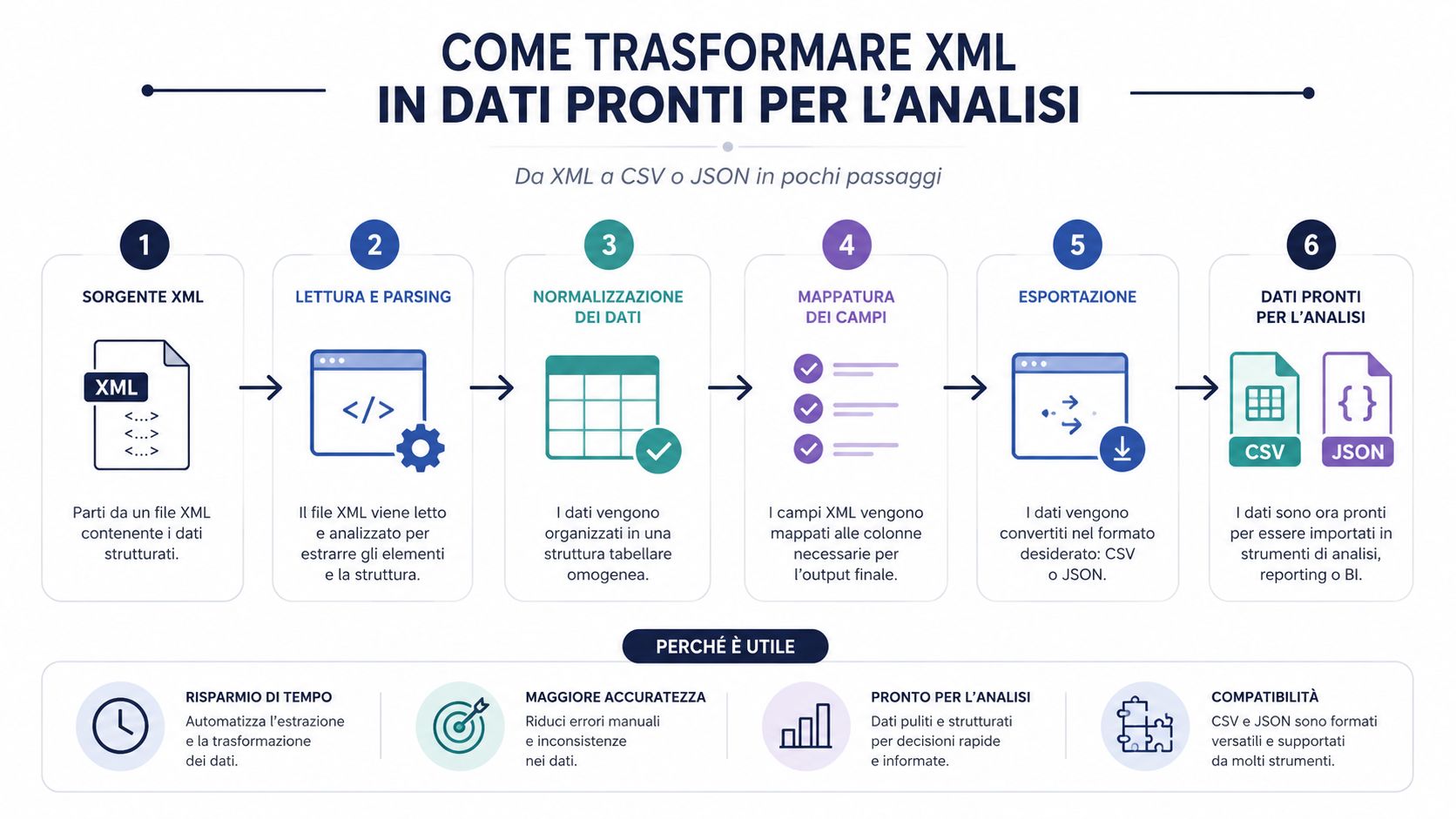
Este es el aspecto que muchos procesos subestiman. El cuello de botella rara vez es el análisis sintáctico en sí. Una biblioteca decente lee un archivo XML rápidamente. El tiempo se pierde en la interpretación de la estructura, la extracción de los campos útiles, la limpieza, la normalización y la carga en una herramienta analítica.
Por eso, la conversión a CSV o JSON no es una simple comodidad. Es un paso operativo fundamental. Si te saltas esta fase y trabajas directamente con el archivo sin procesar, casi siempre acabas teniendo que realizar comprobaciones manuales, crear columnas improvisadas y aplicar lógicas difíciles de replicar.
Una guía útil para quienes trabajan a menudo con XML y hojas de cálculo es esta guía sobre cómo pasar de XML a Excel de una forma más ordenada.
El formato adecuado depende del uso que le vayas a dar a los datos posteriormente.
El CSV funciona bien cuando quieres una línea por documento, o una línea por detalle de factura, y luego utilizar Excel, Power Query o BI.
Ejemplo en Python:
import xml.etree.ElementTree as ETimport csvtree = ET.parse("factura.xml")root = tree.getroot()with open("facturas.csv", "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(["número", "fecha"])número = root.findtext(".//Número")data = root.findtext(".//Fecha")writer.writerow([número, fecha])La ventaja es la sencillez. La limitación es que hay que decidir bien cómo simplificar la jerarquía. Si una factura tiene varias líneas de detalle, hay que tomar una decisión clara sobre la granularidad y la clave de enlace.
El JSON es más adecuado cuando quieres conservar parte de la estructura jerárquica.
Ejemplo de JavaScript:
const record = {numero: "123",data: "2024-01-15",righe: [{ descrizione: "Servizio", importo: "100.00" }]};console.log(JSON.stringify(record, null, 2));Úsalo cuando tu siguiente paso sea una API, un lago de datos o una aplicación que funcione bien con objetos anidados.
He aquí una regla práctica que resulta útil:
El archivo XML es el contenedor. Los formatos CSV y JSON son los que permiten trabajar realmente con el contenido.
Si quieres reducir el tiempo necesario para obtener información útil, es aquí donde conviene invertir esfuerzo. No en buscar un visualizador más cómodo, sino en definir una transformación estable y repetible.
Una vez que el archivo se ha leído, validado y transformado, el trabajo cambia de naturaleza. Ya no estás lidiando con las etiquetas. Por fin te estás centrando en los costes, las anomalías, los proveedores, las categorías de gasto y las tendencias operativas.
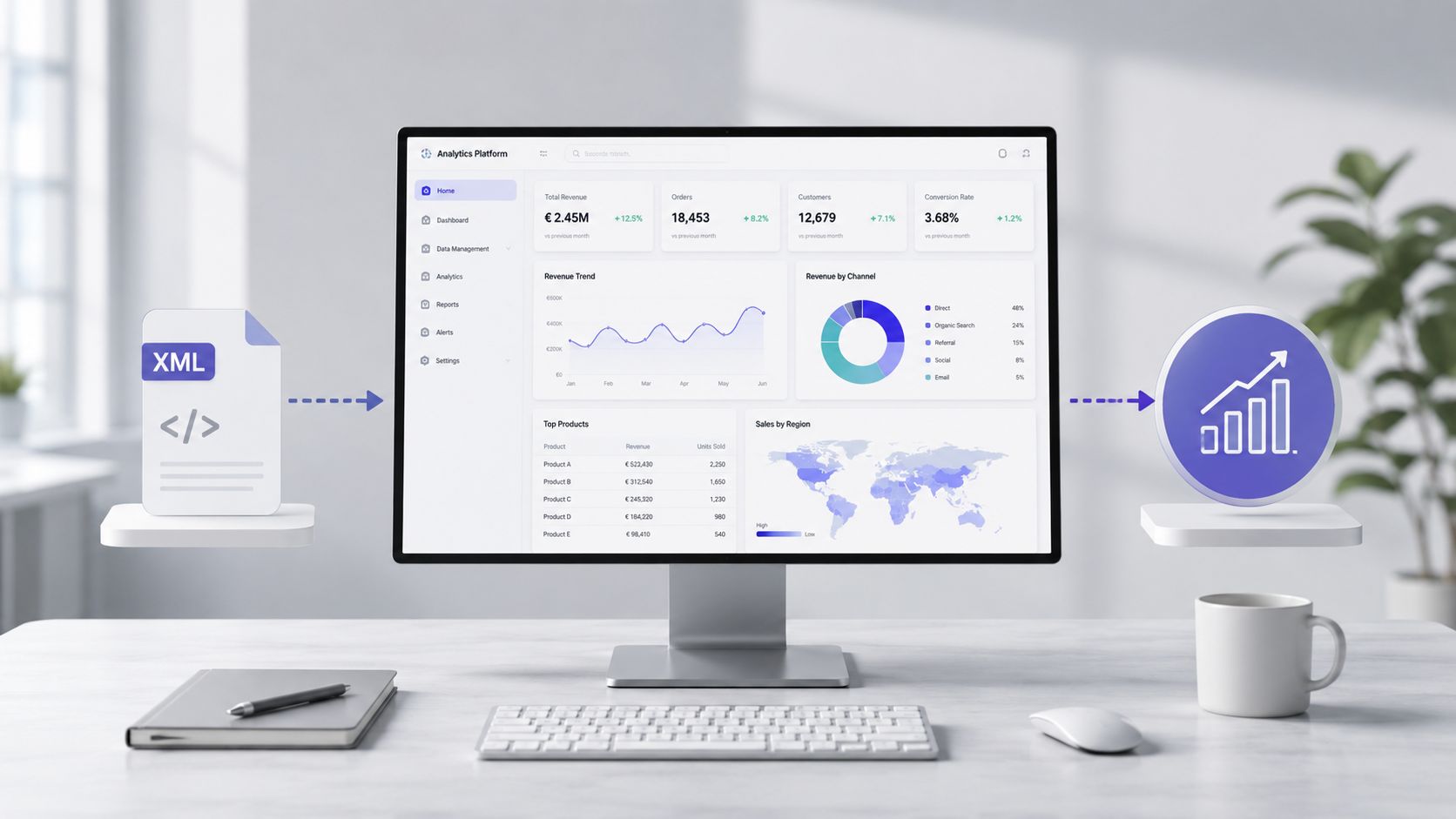
En la práctica, el valor no reside en el tiempo que lleva el análisis sintáctico. Reside en el tiempo que transcurre desde el archivo sin procesar hasta obtener información sobre la que puedas tomar una decisión. Con un flujo manual, una persona tiene que abrir el documento, comprender su estructura, extraer los campos, limpiar los valores, normalizar los textos y, a continuación, elaborar informes. Es un proceso frágil.
Un ejemplo clásico en FatturaPA es el texto libre de DatiBeniServizi. Un mismo servicio puede describirse de muchas formas diferentes según el proveedor. Si se importan esos datos sin una asignación coherente, el análisis por categoría de coste genera agregaciones innecesarias.
Por eso, antes de la plataforma de análisis, se necesita una capa de preparación de datos:
Cuando esta fase se lleva a cabo correctamente, cualquier plataforma de análisis funciona mejor. Si quieres profundizar en el aspecto decisional y visual de este paso, el recurso sobre cómo crear historias con datos resulta útil, ya que muestra cómo un conjunto de datos limpio se convierte en una narración útil para los responsables de la toma de decisiones.
Llegados a este punto, el archivo XML deja de ser un problema técnico y se convierte en materia prima para obtener información útil. Un conjunto de datos bien preparado puede servir de base para analizar gastos, realizar un seguimiento de las tendencias, detectar desviaciones e interpretar las excepciones.
Para elegir una plataforma adecuada para esta «última milla», puede resultarte útil comparar lo que ofrece un software moderno de análisis empresarial con los procesos puramente manuales basados en hojas de cálculo y tablas dinámicas.
En este caso, el criterio adecuado no es «¿sabe abrir archivos XML?». Eso es lo mínimo. La pregunta relevante es otra:
| Pregunta | Por qué es importante |
|---|---|
| Los datos ya vienen limpios | Evita obtener conclusiones precisas a partir de datos erróneos |
| Las categorías son coherentes | ¿De verdad comparas proveedores y plazos? |
| Las anomalías se detectan de inmediato | Reduce el tiempo perdido en comprobaciones manuales |
| El informe es comprensible para los departamentos de negocios y finanzas | Acelera la toma de decisiones |
La diferencia entre un proceso inmaduro y uno maduro no radica en la capacidad de leer archivos XML. Radica en la capacidad de transformarlos en una base de datos fiable, que no obligue al equipo a repetir el mismo trabajo una y otra vez.
Si tienes que leer archivos XML de forma que resulte útil para tu negocio, ten en cuenta esta lista de comprobación. Es más práctica que cualquier definición técnica y te ayuda a elegir el método adecuado sin perder tiempo.
No utilices siempre el mismo enfoque. Los navegadores, editores y visualizadores están bien para comprobaciones rápidas. Los analizadores sintácticos y los scripts son necesarios cuando el archivo debe alimentar procesos repetitivos. Si confundes la visualización con el tratamiento de datos, corres el riesgo de crear informes sobre bases poco sólidas.
Los archivos .xml.p7m requieren un paso específico en la gestión de la firma. Si el contenido procede de un correo electrónico certificado (PEC), este control no es accesorio. Forma parte de la lectura correcta del documento.
El hecho de que se respete un esquema no garantiza que el conjunto de datos sea válido. Las incoherencias lógicas, como totales que no cuadran o clasificaciones fiscales ambiguas, son las que con mayor frecuencia echan por tierra el análisis. El control semántico es lo que distingue un archivo «aceptable» de unos datos fiables.
CSV y JSON no son un simple cambio superficial. Son el punto en el que el XML se vuelve procesable por herramientas de análisis, hojas de cálculo, flujos de trabajo e informes. Cuanto antes definas esta transformación, antes reducirás el trabajo manual y la improvisación.
Tu objetivo no es leer archivos XML. Es obtener información útil sin saturar el sistema con datos de mala calidad. Si el flujo no genera un conjunto de datos coherente, el problema no está en el panel de control final. Está mucho más arriba en el proceso.
En la práctica, puedes utilizar esta minilista de comprobación antes de cada nuevo proyecto:
Si quieres convertir datos ya preparados en información clara y útil, ELECTE ayuda a las pymes a pasar de un conjunto de datos limpio a la elaboración de informes inteligentes, con un enfoque accesible incluso para equipos sin conocimientos técnicos. Es la forma más rápida de acortar la distancia entre los datos operativos y la toma de decisiones.

.svg)
.svg)
.svg)
.webp)





