

Tus datos ya están contando una historia. El problema es que, a menudo, hablan demasiado bajo.
Cada día, una pyme acumula comentarios de clientes, pedidos, tickets de asistencia, movimientos financieros, correos electrónicos comerciales y notas de CRM. Todo este material contiene señales útiles. Algunas indican que un cliente está a punto de abandonar la empresa. Otras anticipan un riesgo operativo. Otras, además, muestran qué productos están a punto de crecer o de perder impulso. Sin embargo, sin un método claro, esas señales no son más que ruido.
Entre los algoritmos que ayudan a poner orden en este caos, los clasificadores bayesianos ingenuos ocupan un lugar especial. Su lógica es fácil de entender, se entrenan rápidamente y, a menudo, son más eficaces de lo que su nombre «ingenuo» podría sugerir. No son la opción adecuada para todos los casos, pero en muchos problemas empresariales reales ofrecen un equilibrio poco común entre velocidad, interpretabilidad y resultados útiles.
Si trabajas en el ámbito empresarial, no hace falta que te conviertas en investigador para entenderlos. Lo que necesitas es saber qué hacen, por qué funcionan bien incluso cuando simplifican mucho la realidad, y en qué casos pueden ayudarte a tomar mejores decisiones. Es precisamente aquí donde vale la pena detenerse.
Muchas empresas buscan modelos sofisticados cuando lo que el problema requiere, ante todo, es un modelo fiable y fácil de usar. Es por eso que, en el ámbito financiero, en el comercio minorista o en la atención al cliente, suele imponerse el proceso más claro, y no el más elegante desde el punto de vista teórico.
Los clasificadores bayesianos ingenuos parten de una idea muy concreta. Si se conocen algunas pistas sobre un caso nuevo, se puede estimar con bastante probabilidad a qué categoría pertenece. Si un correo electrónico contiene determinadas palabras, podría tratarse de spam. Si una transacción presenta ciertos patrones, podría requerir una comprobación. Si una reseña utiliza ciertos términos, podría indicar satisfacción o insatisfacción.
La palabra «bayesiano» evoca fórmulas complejas. En realidad, la esencia del método es intuitiva. Se parte de lo que ya se sabe, se añaden nuevas pruebas y se actualiza el juicio. Es una forma ordenada de razonar en condiciones de incertidumbre, exactamente lo que hacen los directivos cada día, solo que sistematizado mediante un algoritmo.
Lo sorprendente es que este enfoque sigue funcionando bien incluso en entornos modernos, con gran cantidad de datos y decisiones rápidas. No porque describa el mundo a la perfección, sino porque separa la información útil del ruido con un coste computacional muy reducido.
En los problemas empresariales, la pregunta adecuada no es «¿cuál es el modelo más sofisticado?», sino «¿qué modelo me permite tomar decisiones fiables en plazos compatibles con el trabajo real?».
Por eso los clasificadores bayesianos naíf siguen siendo importantes. Te ayudan a clasificar, filtrar, segmentar y establecer prioridades. Y te permiten incorporar la probabilidad en el proceso de toma de decisiones sin convertir cada proyecto en una obra de ingeniería.
El principio básico es el teorema de Bayes. En pocas palabras, dice lo siguiente: se parte de una probabilidad inicial y luego se actualiza cuando se obtiene nueva información.
En el lenguaje de los datos, la fórmula se lee así: P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y). Esto significa que la probabilidad de una clase, dada una serie de señales, depende de dos elementos. El primero es la probabilidad inicial de la clase. El segundo es el grado de compatibilidad de cada señal con esa clase.
Traducido a un ejemplo empresarial. Tienes que determinar si un correo electrónico es spam o no. Tienes una probabilidad general de que un correo entrante sea spam. A continuación, fijaste en algunas palabras como «oferta», «gratis» o «haz clic aquí». Cada una de estas palabras modifica la valoración final.
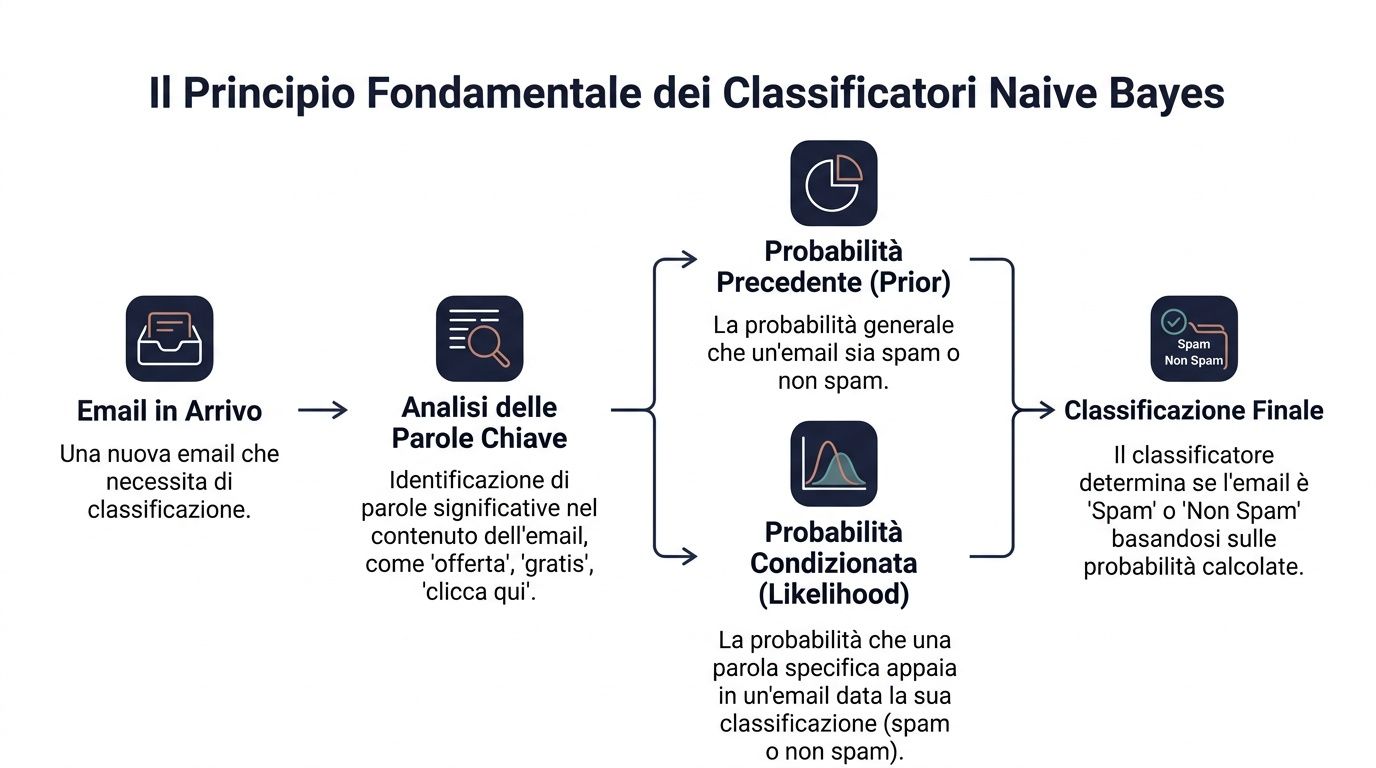
Un directivo hace algo parecido todos los días. Nunca toma decisiones sin tener en cuenta el contexto. Parte de un contexto básico y va añadiendo indicios. Un cliente que siempre ha comprado con regularidad tiene un perfil inicial determinado. Si luego deja de abrir los correos electrónicos, reduce el valor de los pedidos y abre un ticket crítico, tu valoración cambia.
El término «naïve» hace referencia a una suposición concreta. El modelo trata las características como si fueran independientes entre sí, dado que se conoce la clase.
En la práctica, si estás clasificando un correo electrónico, considera cada palabra como una pista independiente. No intentes modelar todas las relaciones complejas entre los términos. Se trata de una simplificación considerable. En realidad, muchas palabras aparecen juntas y muchos comportamientos empresariales están relacionados entre sí.
Sin embargo, es precisamente esta elección la que hace que el modelo sea muy ligero. No tiene que aprender una intrincada red de dependencias. Debe estimar probabilidades más sencillas y combinarlas de manera eficiente.
Regla práctica: el algoritmo Naive Bayes no pretende reconstruir el mundo entero. Su objetivo es tomar decisiones útiles partiendo de pocas suposiciones y con gran rapidez.
Aquí es donde suele surgir el malentendido. Muchos leen «supuesto ingenuo» y concluyen que se trata de un «modelo débil». No es así. Un modelo puede simplificar mucho y seguir siendo competitivo si la simplificación capta lo que realmente importa para la toma de decisiones.
En 2004, un análisis teórico puso de manifiesto razones sólidas que justificaban la eficacia de los clasificadores Naive Bayes a pesar de la hipótesis de independencia, explicando además por qué pueden alcanzar el error asintótico más rápidamente que la regresión logística. En la misma línea de aplicaciones, en el filtrado de spam alcanzan una precisión superior al 99 % y se adaptan a millones de documentos, tal y como se indica en la entrada dedicada a los clasificadores Naive Bayes.
Este punto es importante para un público empresarial. El valor de un algoritmo no reside únicamente en la puntuación final. También radica en su capacidad para entrenarse rápidamente, adaptarse a conjuntos de datos de gran tamaño y seguir siendo interpretable.
Cuando se tienen textos, categorías, etiquetas o señales dispersas, los clasificadores bayesianos ingenuos funcionan bien porque:
Sin embargo, hay dos cosas que hay que tener en cuenta.
Por eso, el algoritmo Naive Bayes debe considerarse una herramienta muy eficaz para problemas de clasificación rápidos, y no una varita mágica universal. Sin embargo, en muchos contextos prácticos, es una de las mejores formas de empezar.
Un error habitual es hablar del modelo Naive Bayes como si fuera un único modelo idéntico en todas las situaciones. En realidad, existen diferentes variantes, diseñadas para distintos tipos de datos.
La elección correcta depende del formato de los datos de los que dispones. Si eliges una variante incorrecta, el modelo podrá generar una predicción, pero no estará razonando de la forma más adecuada para tu problema.
El modelo Gaussian Naive Bayes es la variante más adecuada cuando las características son continuas. Piensa, por ejemplo, en el importe medio de una transacción, la edad del cliente, el tiempo medio entre dos compras, el margen unitario o el valor del ticket de caja.
En este caso, el modelo parte de la base de que, dentro de cada clase, los valores siguen una distribución gaussiana. No debes verlo como una restricción teórica. Basta con que recuerdes la idea práctica: para cada clase, el modelo estima un valor medio y una dispersión.
Este enfoque resulta útil cuando se desea clasificar casos como:
En una prueba de rendimiento de scikit-learn con un conjunto de datos similar a los del comercio electrónico italiano, un modelo Naive Bayes alcanzó una precisión del 95 % con 1000 muestras, con un tiempo de entrenamiento un 15 % mejor que el de la regresión logística . La comparación indicada es de 0,01 s frente a 0,1 s en una CPU estándar, gracias al entrenamiento en forma cerrada, tal y como se muestra en el capítulo de Jake VanderPlas sobre «In Depth Naive Bayes Classification».
Para una empresa, la cuestión no es el decimal. La cuestión es que esta variante puede ofrecer buenos resultados sin necesidad de largos periodos de formación ni de una infraestructura compleja.
Si trabajas con textos, tickets, reseñas o comentarios, el modelo Multinomial Naive Bayes suele ser la opción más lógica. En este caso, las características son recuentos o frecuencias. En la práctica, el modelo analiza cuántas veces aparecen las palabras o los términos.
Es el típico caso de:
La razón por la que funciona bien es muy concreta. En los textos empresariales, el vocabulario puede ser amplio, pero cada documento contiene solo una pequeña parte de las palabras posibles. Los datos están dispersos. El modelo Multinomial Naive Bayes gestiona bien precisamente este tipo de estructura.
En un estudio realizado con 100 000 tuits italianos etiquetados según su tono, el modelo multinomial Naive Bayes obtuvo un F1-score de 0,88 y una velocidad 10 veces superior a la de las máquinas de vectores de soporte (SVM), tal y como se recoge en la guía de GeeksforGeeks sobre los clasificadores Naive Bayes.
Para recordarlo fácilmente, piénsalo así: si tus datos se parecen a un documento repleto de palabras contadas, la distribución multinomial es casi siempre la primera opción que hay que probar.
Si tu empresa tiene que leer grandes volúmenes de texto, la pregunta no es solo «¿qué grado de precisión tiene el modelo?». También es «¿cuántas solicitudes es capaz de clasificar sin ralentizar el trabajo del equipo?».
Bernoulli Naive Bayes trabaja con características binarias. No tiene en cuenta cuántas veces aparece una señal, sino si está presente o ausente.
Esta variante resulta útil cuando la presencia de un atributo tiene más importancia que su frecuencia. Algunos ejemplos empresariales:
Es una lógica muy útil cuando se quiere convertir fenómenos complejos en indicadores de «sí» o «no» fáciles de supervisar. En el análisis del sentimiento, por ejemplo, puede ser más importante el hecho de que aparezca una palabra negativa que el número de veces que se repita.
Bernoulli no es «menos avanzado» que la distribución multinomial. Simplemente resulta más adecuado cuando los datos describen presencia o ausencia. La diferencia es pequeña en teoría, pero grande en la práctica.
| Variante | Tipo de datos ideal | Ejemplo de caso de uso empresarial |
|---|---|---|
| Gaussiano-Naive Bayes | Datos continuos | Clasificar las transacciones por riesgo utilizando importes, frecuencia y valores medios |
| Naive Bayes multinomial | Textos, recuentos, frecuencias | Analizar las opiniones y los tickets de los clientes por tono o categoría |
| Bernoulli y Naive Bayes | Datos binarios, presencia/ausencia | Evaluar señales de «sí» o «no» en materia de cumplimiento, asistencia o uso del producto |
Para elegir bien, sigue una regla sencilla:
Muchos equipos se quedan estancados porque buscan el «mejor» modelo en absoluto. La elección correcta, casi siempre, es el modelo que mejor se adapta al tipo de datos.
La buena noticia es que poner en práctica el algoritmo Naive Bayes no requiere un proyecto de gran envergadura. Incluso un prototipo sencillo ya permite comprender cómo funciona el modelo y qué datos necesita.

Un clasificador se crea casi siempre siguiendo cuatro pasos.
Preparación de datos
Debes recopilar ejemplos históricos ya etiquetados. Si estás clasificando reseñas, necesitas textos que ya estén marcados como positivos o negativos. Si estás analizando el riesgo operativo, necesitas casos pasados cuyo resultado se conozca.
Entrenamiento del modelo bayesiano ingenuo (
) El modelo analiza los datos y calcula las probabilidades pertinentes. En los clasificadores bayesianos ingenuos, este paso es rápido porque el entrenamiento no requiere optimizaciones especialmente complejas.
Predicción de nuevos casos
Introduce nuevos registros y el modelo les asignará una clase. Por ejemplo: «spam», «no spam», «cliente de riesgo», «cliente estable».
Evaluación de «
»: compara las predicciones con la realidad en un conjunto de datos de prueba independiente. Aquí no solo se comprueba si el modelo funciona, sino también cómo se equivoca.
Si quieres profundizar en el panorama general de los enfoques predictivos, esta visión general de los algoritmos de aprendizaje automático te ayudará a situar el algoritmo Naive Bayes dentro de una familia más amplia de métodos.
Para que el proceso resulte más claro, aquí tienes un ejemplo sencillo con scikit-learn. No hace falta que lo leas como desarrollador; basta con que entiendas el flujo.
# Importamos las herramientas principalesfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# Cargamos un conjunto de datos de ejemploX, y = load_iris(return_X_y=True)# Dividimos los datos en una parte para entrenamiento y otra para prueba X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Creamos el modelo model = GaussianNB()# Entrenamos el modelo con los datos históricos model.fit(X_train, y_train)# Realizamos predicciones sobre datos nunca vistos y_pred = model.predict(X_test)# Medimos la precisión print(accuracy_score(y_test, y_pred))Este fragmento dice mucho más de lo que parece.
GaussianNB() elige la opción para datos continuos.fit() Es el momento en el que el modelo aprende.predict() pone en práctica lo que ha aprendido.accuracy_score() Comprueba cuántas clasificaciones son correctas en total.En el caso de los datos de texto, el proceso es similar, pero antes de aplicar el modelo hay que convertir el texto en números. En la práctica, se trata de convertir las palabras en características que pueda utilizar un clasificador.
Tras echar un primer vistazo al código, puede resultar útil ver una explicación visual del mecanismo.
El primer modelo no sirve para demostrar la perfección. Sirve para responder a tres preguntas prácticas.
Aquí se aprecia la ventaja de Naive Bayes. Permite llegar rápidamente a una base sólida. A partir de ahí, puedes determinar si tiene sentido complicar el proyecto o si una solución sencilla ya está aportando valor.
Un modelo de clasificación no se evalúa solo por el hecho de que «parece funcionar». Se evalúa por cómo se equivoca y por el impacto que esos errores tienen en el negocio.

La precisión es el indicador más intuitivo. Indica cuántas predicciones son correctas del total. Es útil, pero por sí sola puede llevar a conclusiones erróneas.
Si de cada cien transacciones solo unas pocas son realmente sospechosas, un modelo que clasifica casi todo como normal puede parecer preciso, pero resultar deficiente justo donde más se necesita.
Para entenderlo, piensa en una red de pesca.
En el mundo de los negocios, esta distinción es muy importante.
Un buen modelo no es aquel que, en general, se equivoca poco. Es aquel que se equivoca de la forma menos costosa para tu proceso.
Para comprender mejor cómo un algoritmo aprende a partir de los datos históricos y por qué la calidad del entrenamiento influye en el resultado final, puedes leer este artículo detallado sobre en qué consiste el entrenamiento de un algoritmo.
El algoritmo Naive Bayes es sencillo, pero no perdona ciertos errores prácticos.
Primer error: ignorar el problema de la frecuencia cero.
Si una palabra o un valor nunca aparece en los datos de entrenamiento para una clase determinada, la probabilidad puede reducirse a cero y comprometer el cálculo. Por eso se suele utilizar el suavizado de Laplace, que añade un pequeño ajuste a los recuentos.
Segundo error: utilizar variables muy correlacionadas.
Si dos columnas aportan prácticamente la misma información, el modelo corre el riesgo de sobreestimar la señal. No «entiende» que las dos variables son prácticamente idénticas.
Tercer error: confiar demasiado en las probabilidades brutas.
El algoritmo Naive Bayes suele clasificar bien, pero sus probabilidades pueden ser demasiado categóricas. Para las empresas, esto significa que la clasificación puede ser útil, mientras que el valor exacto de la probabilidad debe interpretarse con cautela.
Para reducir estos riesgos, conviene:
El verdadero valor de los clasificadores bayesianos ingenuos se pone de manifiesto cuando dejas de considerarlos un ejercicio matemático y empiezas a utilizarlos como motor de priorización. En el ámbito empresarial, clasificar bien casi siempre significa tomar mejores decisiones.

Imagina un equipo financiero que analiza flujos de transacciones, descripciones operativas y datos históricos. Cada línea no es solo un registro. Es una decisión potencial: dejarla pasar, investigarla más a fondo, bloquearla o remitirla a un analista.
Con Naive Bayes puedes combinar diferentes indicadores en una única clasificación. Algunos son numéricos, otros binarios y otros textuales. El modelo ayuda a determinar qué casos se asemejan más a los patrones ya observados como normales o anómalos.
La ventaja práctica es doble:
No sustituye al criterio humano en los contextos regulados. Lo organiza. Y en los procesos operativos de gran volumen, esto marca una diferencia real.
En marketing, clasificar suele significar asignar a cada cliente a un grupo operativo: clientes fieles, sensibles al precio, en riesgo de abandono, receptivos a las promociones o inactivos.
En este caso, el algoritmo Naive Bayes resulta útil porque es capaz de combinar señales heterogéneas con rapidez:
Un equipo de CRM no necesita una teoría perfecta sobre el comportamiento humano. Necesita una segmentación lo suficientemente buena como para poner en marcha medidas sensatas. Por ejemplo, cambiar el mensaje, la frecuencia de contacto o el tipo de oferta.
Cuando un modelo ayuda a elegir el siguiente mensaje para el cliente adecuado, ya está generando valor operativo.
En el comercio minorista y el comercio electrónico, la clasificación sirve de apoyo a actividades que, aunque parecen diferentes, comparten la misma lógica: poner orden en el caos.
Puedes clasificar los productos según su perfil de ventas. Puedes leer reseñas y tickets para identificar qué categorías generan problemas. Puedes detectar patrones de demanda que ayuden al equipo a planificar las promociones y el stock con mayor claridad.
En este tipo de entornos, los datos suelen ser numerosos, heterogéneos y no siempre perfectos. Por eso, un modelo rápido, escalable y legible tiene un gran valor. No porque sea el más llamativo, sino porque se integra en el flujo de trabajo sin ralentizarlo.
Si quieres ver cómo los enfoques analíticos aplicados a los negocios se plasman en proyectos concretos, puedes echar un vistazo a estos casos prácticos.
Entender el modelo Naive Bayes es útil. Implementarlo correctamente en un contexto empresarial es otra historia.
El problema casi nunca se reduce solo al algoritmo. El verdadero trabajo gira en torno al modelo. Hay que conectar diferentes fuentes de datos, gestionar los campos que faltan, preparar los textos, actualizar las etiquetas, controlar la calidad de los resultados y presentar los resultados de forma que resulten comprensibles para los responsables de la toma de decisiones.
Para una pyme, este paso suele ser el punto crítico. No porque falte interés por la IA, sino porque el tiempo del equipo es limitado y las prioridades operativas no pueden esperar.
En este caso, lo más sensato es utilizar una plataforma que se encargue de la complejidad técnica. Una solución basada en inteligencia artificial permite transformar datos sin procesar en información útil sin que la empresa tenga que escribir código, elegir bibliotecas o gestionar flujos de trabajo manuales.
Una plataforma como ELECTE, una plataforma de análisis de datos basada en inteligencia artificial para pymes, pone al alcance de todos métodos como los clasificadores bayesianos ingenuos sin necesidad de contar con conocimientos especializados en aprendizaje automático. La ventaja no es solo la rapidez. Es la reducción de la fricción entre los datos y la toma de decisiones.
Cuando la automatización funciona bien, el equipo ya no piensa en términos de fórmulas. Piensa en términos de preguntas útiles:
Esta es también la razón por la que cada vez más empresas buscan herramientas que les ayuden a evaluar la fiabilidad de los contenidos generados por la IA y de las señales textuales que circulan en los procesos internos. En este contexto, puede resultar útil consultar también una guía sobre un detector de IA en español, sobre todo si tu equipo trabaja con documentos, contenidos y revisiones lingüísticas.
En la práctica, la diferencia es sencilla. En lugar de gestionar pasos técnicos fragmentados, te centras en el resultado empresarial. Y ahí es donde la IA se vuelve realmente viable, no solo interesante.
Los clasificadores bayesianos ingenuos nos enseñan una lección importante. En el ámbito del análisis de datos, la simplicidad bien aplicada puede superar a la complejidad mal gestionada.
Con una base probabilística intuitiva, una buena escalabilidad y casos de uso muy concretos, este enfoque sigue siendo una herramienta fiable para las empresas que desean clasificar información, detectar señales ocultas y actuar con mayor seguridad. No hace falta ser especialista en aprendizaje automático para comprender su valor. Lo que se necesita es vincular las matemáticas con la toma de decisiones operativas.
Cuando esta relación queda clara, la IA deja de ser una cuestión técnica y se convierte en una ventaja organizativa. Es ahí donde la predicción empieza a tener un impacto.
Si quieres convertir datos dispersos en información clara, prueba ELECTE. La plataforma ayuda a las pymes a conectar fuentes de datos, automatizar el análisis y obtener informes y previsiones útiles para tomar decisiones más rápidas y fundamentadas.

.svg)
.svg)
.svg)






