

Tu te retrouves souvent dans cette situation : tu disposes d'un logiciel de gestion, peut-être d'un CRM, de quelques fichiers Excel qui circulent par e-mail, et voilà que quelqu'un te dit que pour « faire de l'analyse sérieuse », tu dois choisir entre un lac de données et un entrepôt de données. À ce stade, la conversation dérive immédiatement vers la technologie, mais le vrai problème est tout autre. As-tu vraiment besoin d'une nouvelle architecture de données, ou s'agit-il simplement de rendre lisibles et exploitables les données dont tu disposes déjà ?
Pour une PME, cette distinction va bien au-delà d'une simple question de terminologie. Un mauvais choix n'entraîne pas seulement des complexités techniques. Il se traduit par des projets interminables, une dépendance vis-à-vis des consultants, des rapports qui arrivent en retard et des investissements qui peinent à déboucher sur de meilleures décisions. Ne rien faire, en revanche, revient à laisser l'entreprise avancer à l'aveuglette.
L'important n'est pas d'apprendre le jargon des fournisseurs. L'important est de déterminer quelle solution est la mieux adaptée à votre entreprise, à votre budget et aux compétences dont vous disposez réellement en interne. Vous trouverez ici un guide pratique pour aborder le débat « data lake » contre « data warehouse » avec le regard de celui qui doit trouver le juste équilibre entre coûts, accessibilité et retour sur investissement.
La pression pour « faire quelque chose avec les données » est aujourd’hui bien réelle. Les chiffres augmentent, les sources se multiplient, les dirigeants réclament des prévisions, des tableaux de bord et des alertes plus rapides. Pendant ce temps, on nous présente des termes qui semblent nous obliger à prendre une décision architecturale immédiate.
Pour de nombreuses PME, cependant, c'est là que réside le piège. On vous fait croire que la première étape consiste à choisir entre deux modèles d'infrastructure, alors que souvent, le véritable problème est bien plus concret : des données dispersées, des formats incohérents, des rapports établis manuellement et personne qui ait le temps de remettre de l'ordre.
Il y a d'autres questions à se poser. As-tu vraiment un problème d'architecture ? Ou bien as-tu un problème d'accès aux données ? Si tu choisis la mauvaise solution, tu risques de financer un projet technique au lieu d'améliorer le contrôle sur l'activité. Si tu ne fais aucun choix, tu continues à prendre des décisions sur la base d'informations partielles.
Le dirigeant d'une PME n'a pas besoin d'un cours magistral. Il a besoin d'un critère simple pour comprendre ce qui est utile, ce qui ne l'est pas, et où se cache le véritable coût.
C'est à l'aide de deux exemples très concrets que l'on comprend le mieux cette différence.
Un entrepôt de données ressemble à une bibliothèque bien organisée. Chaque livre y est déjà catalogué, classé et rangé sur la bonne étagère. Lorsque vous recherchez une information, vous la trouvez rapidement car l'ordre a été défini au préalable. Un lac de données, en revanche, ressemble à un immense entrepôt où arrivent des cartons de toutes sortes. On y place des fichiers classés, des journaux, des PDF, des images, des exportations issues du système de gestion, des données web. On s'occupe de l'ordre après, au moment de les analyser.
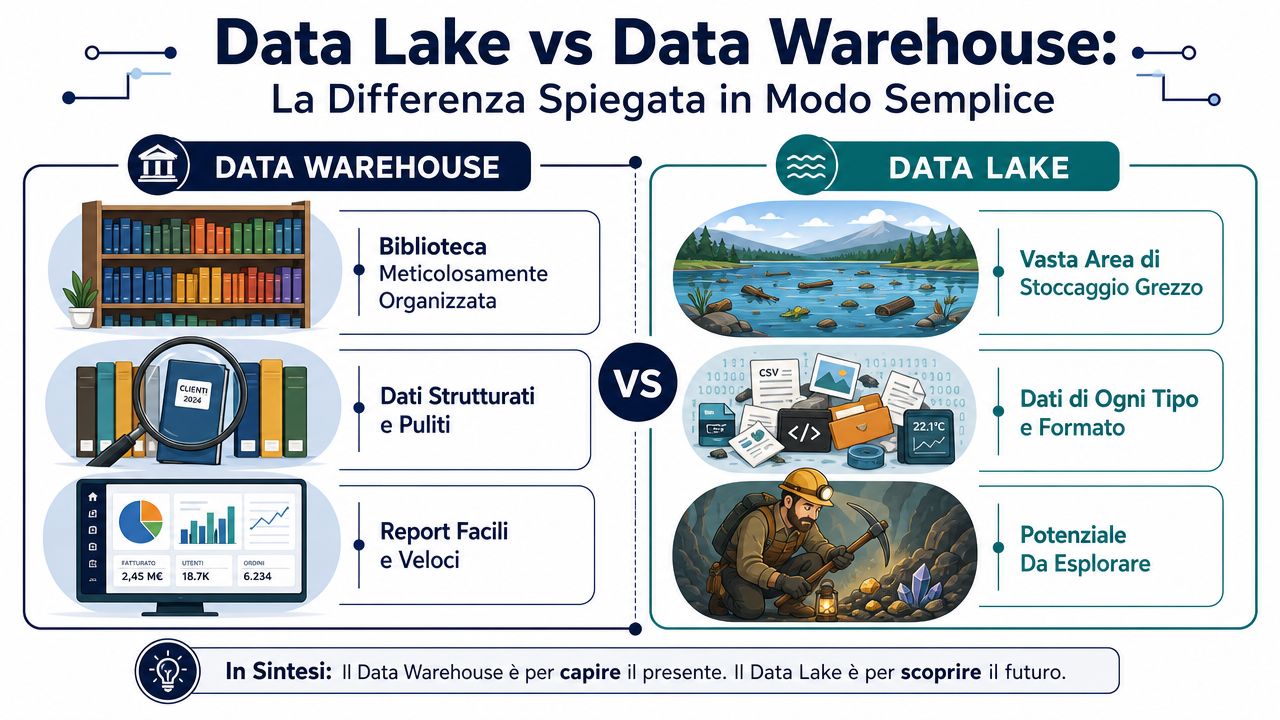
C'est là qu'intervient le seul détail technique qui mérite vraiment d'être mentionné.
Cette distinction reflète également leur origine historique. Le data warehouse a été conçu pour l'analyse d'entreprise sur des données déjà nettoyées et structurées, tandis que le data lake est apparu plus tard pour stocker des données brutes dans des formats hétérogènes. C'est pourquoi le warehouse est plus adapté au reporting et aux indicateurs clés de performance (KPI), tandis que le lake offre davantage de flexibilité pour l'exploration et l'apprentissage automatique, comme l'explique cette analyse sur les différences entre le data warehouse et le data lake.
Un entrepôt de données est efficace pour répondre à des questions déjà connues. Un lac de données est utile lorsque vous savez que les données pourraient contenir des informations précieuses, mais que vous ne savez pas encore sous quelle forme.
Si votre objectif est de connaître les chiffres d'affaires, les marges, les commandes, les stocks, les retards, les performances commerciales et les comparaisons mensuelles, l'entrepôt de données est, d'un point de vue conceptuel, plus adapté à vos besoins. Il vous offre une base fiable pour des rapports standard, des requêtes SQL cohérentes et des chiffres reproductibles.
Si, en revanche, vous travaillez avec des données très hétérogènes, telles que des journaux d'application, des PDF, des e-mails, des textes, des images ou des flux de données brutes, le lac de données offre davantage de liberté. Les équipes informatiques peuvent centraliser des sources hétérogènes, tandis que les responsables du reporting continuent de privilégier des environnements structurés pour des requêtes rapides et cohérentes. C'est dans cette logique que s'inscrit également la question plus large des décisions basées sur les données pour les entreprises, qui nécessitent avant tout des données accessibles, bien plus que des technologies sophistiquées.
Dans le débat opposant les lacs de données aux entrepôts de données, beaucoup confondent flexibilité et utilité immédiate.
Un lac de données peut contenir presque tout. Mais le simple fait de contenir des données ne signifie pas qu'elles soient immédiatement exploitables. Un entrepôt de données est moins flexible en termes d'entrée, mais plus utile lorsque l'on souhaite obtenir des réponses rapides et standardisées. Pour une PME, cette différence a plus d'importance que la théorie. Car le problème n'est pas de stocker davantage. Il s'agit de prendre de meilleures décisions.
Deux entreprises peuvent disposer des mêmes données de départ et obtenir des résultats très différents. La différence ne réside souvent pas dans la quantité de données collectées, mais dans la manière dont elles sont organisées, préparées et mises à la disposition des décideurs.
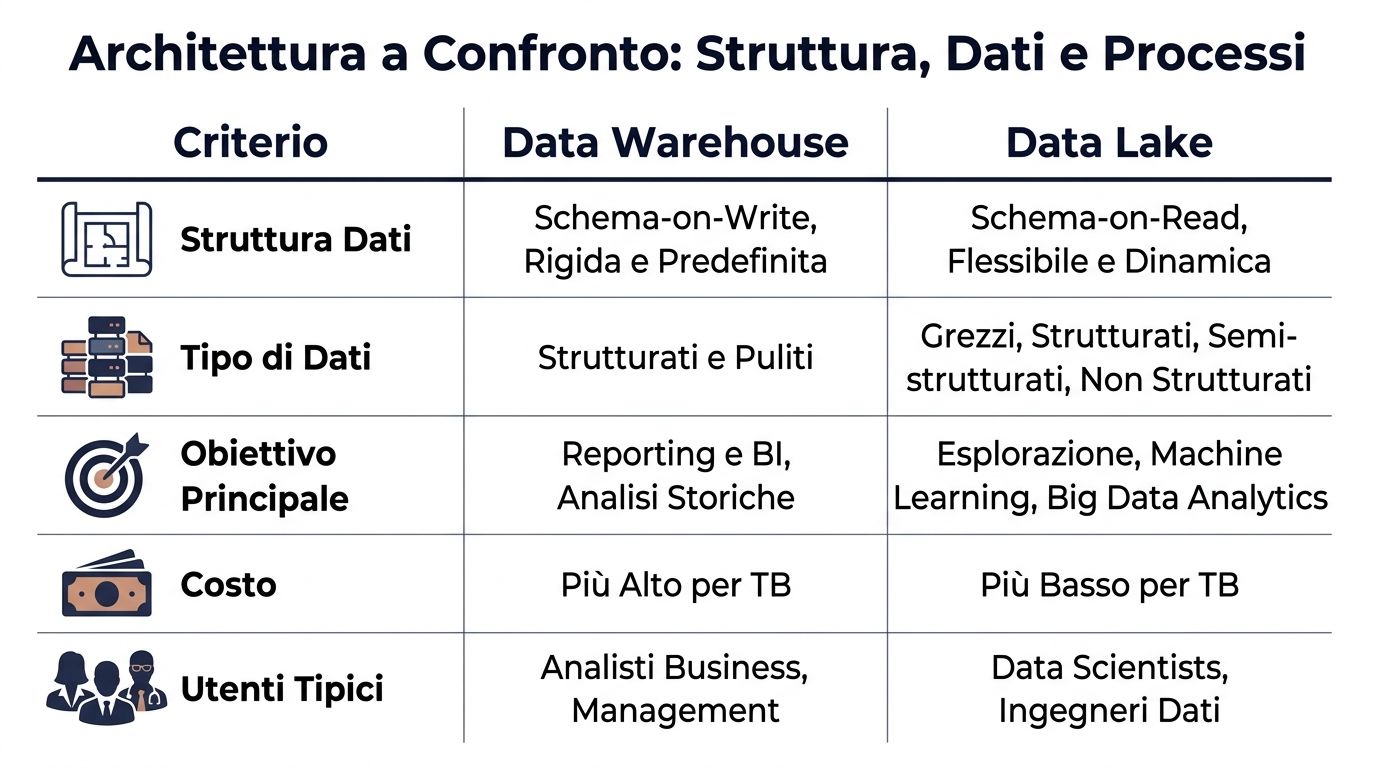
| Critère | Entrepôt de données | Lac de données |
|---|---|---|
| Structure de données | Schéma à l'écriture, défini avant le chargement | Schéma à la lecture, défini au moment de l'analyse |
| Type de données | Surtout bien organisés et soignés | Structurés, semi-structurés et non structurés |
| Processus type | ETL : transformez d'abord, chargez ensuite | ELT : charge d'abord, transformation ensuite |
| Utilisateurs types | Analyste commercial, finance, gestion | Ingénieur de données, data scientist, équipes techniques |
| Performances attendues | Plus prévisibles pour la BI et le reporting | Elles sont plus variables et dépendent des requêtes et de la préparation |
Dans un entrepôt de données, le processus classique est l'ETL : on extrait les données, on les transforme, puis on les charge. Cela demande plus de travail au départ, mais réduit les frictions par la suite. L'utilisateur qui consulte un tableau de bord y trouve des champs cohérents, des définitions stables et des indicateurs clés de performance (KPI) dont la signification ne varie pas d'un service à l'autre.
Dans un lac de données, le flux suit souvent une approche ELT : on extrait, on charge, puis on transforme seulement après, si nécessaire. Cette approche offre davantage de liberté technique, mais repousse une partie du travail. Pour une petite ou moyenne entreprise, repousser ce travail revient souvent à accumuler des tâches qui finissent par retomber sur l'équipe au pire moment, c'est-à-dire lorsqu'une réponse rapide est nécessaire.
Règle pratique : si plusieurs personnes doivent lire le même document et prendre des décisions opérationnelles, la structure définie avant la publication permet de réduire les erreurs, les discussions inutiles et les pertes de temps.
Sur le plan opérationnel, un entrepôt de données est conçu pour des requêtes répétitives, des rapports fréquents et des tableaux de bord utilisés quotidiennement. Un lac de données gère bien les grands volumes et les différents formats, mais les temps de réponse et la facilité d'utilisation dépendent fortement de la manière dont les données ont été cataloguées, préparées et gérées. Une comparaison technique publiée par CloudOptimo résume bien ce point : l'entrepôt mise sur la prévisibilité, le lac sur la flexibilité.
Pour une PME, la question n'est pas purement théorique. Lorsque le responsable des ventes consulte son rapport matinal, il attend des chiffres cohérents et des résultats rapides. En revanche, si l'équipe technique doit analyser des fichiers, des journaux ou des documents hétérogènes, elle peut accepter un temps de latence plus long en échange d'un ensemble de données plus complet.
La différence pratique n'est pas seulement d'ordre technique. Ce qui change, c'est qui est capable d'utiliser les données sans avoir à demander de l'aide à chaque fois.
Un entrepôt de données bien conçu met les données à la disposition des équipes opérationnelles. Un lac de données, à lui seul, les met le plus souvent à la disposition de l'équipe technique. C'est pourquoi de nombreuses PME se rendent compte tardivement d'un problème : le véritable choix ne se pose pas entre deux technologies, mais entre un système qui rend les données accessibles et un autre qui les stocke sans les transformer en décisions plus éclairées.
Quiconque évalue ces options dans le cadre d'un projet de modernisation informatique devrait également tenir compte du modèle opérationnel, et pas seulement du référentiel. Les solutions cloud destinées aux PME aident justement à comprendre cette transition : où s'arrête l'infrastructure et où commencent les coûts, les compétences requises et les responsabilités quotidiennes.
Le lac de données est souvent présenté comme la solution la plus économique, car il stocke des données brutes et réduit la charge de travail initiale. Ce n'est vrai qu'en partie. En l'absence de catalogue, de règles d'accès, d'une nomenclature cohérente et de contrôles de qualité minimaux, les économies initiales se transforment en perte de temps consacrée à la recherche de fichiers, à la reconstitution de définitions et à la vérification de la fiabilité des données.
C'est pourquoi, dans de nombreuses PME, la question n'est pas de savoir, de manière abstraite, s'il faut choisir un « lac de données » ou un « entrepôt de données ». La question pertinente est tout autre : faut-il vraiment mettre en place l'une de ces architectures complètes, ou vaut-il mieux commencer par une solution plus légère qui permette d'obtenir rapidement des informations utiles sans se charger d'emblée de toute cette complexité ?
Pour une PME, l'erreur la plus coûteuse découle souvent d'une question mal posée : « Qu'est-ce qui coûte moins cher : un lac de données ou un entrepôt de données ? ». En entreprise, la véritable facture arrive plus tard. Elle arrive lorsque les données ne communiquent pas entre elles, que les rapports tombent en panne à chaque changement de logiciel de gestion et que chaque demande passe par des consultants ou des développeurs plutôt que par l'équipe qui doit prendre la décision.

Le stockage pèse moins lourd qu'il n'y paraît. Ce sont les activités qui garantissent la fiabilité et l'exploitabilité des données qui pèsent le plus lourd : modélisation, intégrations, autorisations, qualité, surveillance, correction des erreurs, assistance aux utilisateurs.
La mise en place d'un entrepôt de données demande du travail au départ. Il faut définir des indicateurs, créer des pipelines, harmoniser les sources et veiller à ce que tout reste en ordre lorsque les systèmes ERP, CRM ou les règles métier changent. En contrepartie, la direction dispose de chiffres plus stables et le reporting tend à devenir plus prévisible.
Un lac de données se présente souvent avec une promesse plus modeste. Il permet de charger des données de différents types et de reporter une partie des décisions structurelles. Le problème, c'est que ce report n'élimine pas le travail. Il le repousse simplement plus loin, où il se présente sous la forme de catalogage, de sécurité, de coûts de calcul, de doublons, de versions incohérentes et de vérifications constantes pour déterminer quelles données sont réellement fiables.
Le risque, pour une PME, est de payer deux fois. D'abord pour collecter les données. Ensuite pour les rendre enfin lisibles.
La véritable complexité n'est pas d'ordre technique. Elle est d'ordre opérationnel.
Si chaque nouveau rapport nécessite des interventions manuelles, si le contrôleur de gestion et le commercial utilisent des définitions différentes pour un même indicateur, si l'entrepreneur doit attendre plusieurs jours avant d'obtenir un chiffre fiable, le projet de gestion des données est déjà en train de grignoter la marge. Même si, sur le papier, l'infrastructure semble moderne.
C'est pourquoi il convient également d'évaluer le modèle de gestion, et pas seulement l'architecture. Les solutions cloud destinées aux PME permettent justement de cerner cette différence : ce que vous achetez réellement, la part de maintenance qui reste en interne et votre degré de dépendance vis-à-vis d'expertises spécialisées chaque mois.
Sur le marché italien, ceux qui investissent dans l'analyse de données recherchent des résultats concrets. Une réduction du travail manuel. Des cycles de décision plus rapides. Un meilleur contrôle des ventes, des marges, des stocks et de la trésorerie. Pas une plateforme sophistiquée réservée à quelques privilégiés.
Cela modifie les critères de choix. Une PME ne devrait pas se demander quelle architecture est la plus séduisante ou la plus flexible en théorie. Elle devrait plutôt se demander combien de temps il faut pour obtenir des tableaux de bord fiables, combien de personnes sont nécessaires pour les maintenir et à quelle vitesse le projet génère de la valeur.
Dans le commerce de détail, les coûts cachés apparaissent rapidement. Si les ventes, les retours, les promotions et les stocks proviennent de systèmes différents, il suffit d’une définition erronée de la « marge » ou du « chiffre d’affaires net » pour que l’on cesse de se fier aux rapports. À ce stade, le problème ne réside pas dans la base de données choisie. C’est simplement que le propriétaire recommence à prendre ses décisions sur Excel.
Dans le domaine financier, le coût de l'erreur est encore plus flagrant. Le reporting, la clôture des comptes, le contrôle de gestion et l'analyse des écarts exigent des données cohérentes et traçables. Si chaque révision donne lieu à des discussions sur l'origine d'un chiffre, le projet perd en rentabilité avant même d'être achevé.
C'est pourquoi, dans la pratique, de nombreuses PME n'ont pas besoin de créer de toutes pièces un lac de données ou un entrepôt de données complet. Elles ont besoin d'un système plus léger, plus facile à gérer et axé sur la prise de décision.
Si vous ne parvenez pas à garantir la qualité des données, le respect des règles d'accès et la cohérence des définitions au fil du temps, le problème ne réside pas dans le choix entre un lac de données et un entrepôt de données. Le problème, c'est d'avoir opté pour la complexité avant même d'avoir un cas d'utilisation qui la justifie.
La bonne question n'est pas de savoir quelle architecture est « la meilleure » en soi. La question est de savoir quel problème vous devrez résoudre demain matin.

Dans le secteur de la vente au détail, l'entrepôt fonctionne bien lorsqu'il faut toujours répondre aux mêmes questions opérationnelles :
Il en va de même dans le domaine financier. Si vous devez consolider des données structurées, établir des rapports périodiques, analyser des portefeuilles ou interpréter les tendances économiques selon des critères fixes, l'entrepôt de données reste un choix naturel.
Le lac de données prend tout son sens lorsque votre entreprise collecte des données très variées et que vous ne souhaitez pas ou ne pouvez pas tout définir à l'avance.
Un cas concret est celui d'une entreprise du secteur de l'énergie qui croise :
Dans un tel contexte, un entrepôt de données classique vous oblige à définir au préalable les relations entre des sources que vous ne connaissez peut-être pas encore bien. Un lac de données permet de tout centraliser et de ne structurer les données que lorsque cela s'avère nécessaire pour une analyse spécifique. C'est dans ce type de scénario que la flexibilité du lac de données apporte une réelle valeur ajoutée.
Le lac de données n'est pas un choix « plus moderne ». Ce n'est un choix judicieux que lorsque la diversité des données justifie la complexité que cela implique.
La plupart des PME ne se trouvent pas dans ce cas de figure. Elles disposent principalement de données issues de systèmes ERP, CRM, de commerce électronique, de comptabilité, ainsi que d'exportations CSV et Excel. Dans ces cas-là, le problème n'est pas de gérer des fichiers vidéo, des journaux d'application ou du texte brut à grande échelle. Le problème est d'avoir des données propres, cohérentes et compréhensibles par des personnes non initiées à la technique.
Il faut ici être clair : souvent, on n'a besoin ni d'un lac de données ni d'un entrepôt de données traditionnel.
Il faut plutôt :
Le « lakehouse » tente de concilier ces deux mondes. Il promet la flexibilité du lac de données et certaines qualités de l'entrepôt de données au sein d'un même environnement. C'est une orientation intéressante, en particulier pour les entreprises dont les charges de travail combinent la BI, l'IA et la science des données.
Pour une PME, cependant, la question reste la même : avez-vous vraiment un problème qui justifie tout cela ? Si votre besoin est simplement de mieux analyser vos ventes, vos marges, votre trésorerie ou vos prévisions, une solution hybride sophistiquée peut s'avérer disproportionnée par rapport à la valeur attendue.
Le « data lakehouse » a été conçu pour dépasser la séparation rigide entre le lac de données et l'entrepôt de données. L'idée est simple : conserver la flexibilité d'un stockage vaste et ouvert, tout en y ajoutant de l'ordre, des performances et des capacités analytiques plus proches de celles d'un entrepôt de données. Des technologies telles que Databricks et Delta Lake illustrent bien cette orientation.
En théorie, c'est très séduisant. On utilise la même base de données pour la BI, l'analyse avancée et l'apprentissage automatique, ce qui évite de multiplier les doublons entre différents systèmes. Pour les grandes entreprises ou les équipes de données expérimentées, c'est une réponse logique à un écosystème qui s'est complexifié au fil du temps.
Dans les tests de performance universitaires, l'architecture « data lakehouse » est évaluée à l'aide d'indicateurs tels que le débit, la latence et la surcharge liée aux métadonnées. Cela montre que la comparaison avec le data warehouse ne porte pas seulement sur les fonctionnalités, mais aussi sur les performances, dans des scénarios où de légères différences de performances ont un impact significatif, comme le souligne cette présentation universitaire sur les tests de performance « lakehouse ».
Traduction en français des affaires : le « lakehouse » apporte des solutions aux organisations qui ont déjà atteint un certain niveau d'échelle, de complexité et de spécialisation.
Si tu n'avais vraiment besoin ni d'un lac de données ni d'un entrepôt de données, tu n'as probablement pas besoin d'un système qui combine les deux.
Pour la plupart des PME, la question la plus pertinente n’est pas « quelle architecture choisir ? », mais « comment obtenir des analyses fiables sans transformer le projet de données en chantier permanent ? ».
C'est la troisième approche qui fait souvent défaut dans les comparaisons entre lac de données et entrepôt de données. Il ne s'agit pas de mettre en place une nouvelle infrastructure propriétaire, mais plutôt d'ajouter une couche d'analyse au-dessus des systèmes que vous utilisez déjà, en transférant la complexité technique hors du périmètre opérationnel de l'entreprise.

En pratique, la meilleure approche est la suivante :
J'ai vu plus d'une PME passer des mois à mettre en place un entrepôt de données traditionnel pour ensuite très peu l'utiliser. Non pas parce qu'il était mal conçu, mais parce que personne dans l'entreprise ne savait l'interroger de manière autonome. Le goulot d'étranglement n'était pas la base de données, mais son accessibilité.
C'est là un aspect souvent sous-estimé. Une architecture sophistiquée qui nécessite systématiquement l'intervention d'un intermédiaire technique réduit la valeur pratique des données. Une solution plus simple, mais compréhensible par la direction, permet souvent de prendre de meilleures décisions plus rapidement.
C'est pourquoi de nombreuses entreprises tirent davantage de valeur d'un logiciel de veille économique bien conçu pour les PME que d'un programme d'infrastructure surdimensionné. Leur objectif n'est pas de posséder un entrepôt de données, mais de mieux comprendre leur activité, et ce plus rapidement.
Une bonne infrastructure, c'est celle que votre équipe est capable d'utiliser, de maintenir et de mettre à profit pour prendre des décisions. Pas celle qui fait bonne impression sur une diapositive technique.
Le débat entre « data lake » et « data warehouse » est utile, mais pour une PME, il part souvent d'une mauvaise question. Avant de choisir une architecture, vous devez déterminer si vous êtes réellement confronté à un problème d'échelle et de diversité des données, ou à un problème bien plus courant : des données dispersées, des rapports manuels et un accès limité.
Le data warehouse reste la solution idéale lorsqu'il s'agit de disposer de rapports fiables, d'indicateurs clés de performance cohérents et de performances prévisibles. Le data lake prend tout son sens lorsque la diversité des sources justifie une plus grande flexibilité et une complexité accrue. Le lakehouse est une évolution intéressante, mais il s'agit rarement de la première étape appropriée pour une entreprise qui recherche avant tout le contrôle opérationnel et le retour sur investissement.
Le choix le plus judicieux n'est pas forcément la technologie la plus avancée. C'est celui qui est adapté au problème réel, aux compétences disponibles et à la rapidité avec laquelle vous souhaitez transformer les données en décisions.
Si vous souhaitez transformer les données de votre entreprise en rapports, prévisions et informations opérationnelles sans avoir à mettre en place une infrastructure complexe, découvrez ELECTE, une plateforme d'analyse de données basée sur l'IA destinée aux PME. Vous pouvez partir des données dont vous disposez déjà, réduire le travail manuel et mettre l'analyse de données à la portée de votre équipe grâce à une approche beaucoup plus simple.

.svg)
.svg)
.svg)






