

Les équipes financières des PME le savent bien : chaque fois qu'on essaie d'importer un PDF dans Excel, c'est la guerre contre la mise en forme. Le copier-coller classique se transforme presque toujours en catastrophe : des données éparpillées, des cellules fusionnées au hasard et des tableaux bien ordonnés qui se transforment en un chaos illisible. La frustration est bien réelle, mais ce n'est pas de votre faute. Le problème réside dans la nature même du format PDF, conçu pour l'impression et le partage, et non pour servir de source de données à analyser.
Ce processus manuel, qui repose sur des relevés bancaires, des factures de fournisseurs et des documents administratifs, est un véritable gouffre en termes de productivité. En plus d'être fastidieux, il est une source quasi certaine d'erreurs de saisie. Heureusement, en 2026, vous disposez de méthodes bien plus intelligentes pour relever ce défi. Dans ce guide, nous vous présenterons étape par étape les stratégies les plus efficaces, depuis celles intégrées à Excel jusqu'aux solutions basées sur l'IA qui éliminent complètement le travail manuel, vous permettant de passer de l'extraction à l'analyse en quelques minutes.
Le problème tient à une distinction fondamentale : les fichiers PDF ont été conçus pour préserver la mise en page d'un document sur n'importe quel appareil, et non pour conserver la structure logique des données qu'ils contiennent. Comprendre la différence entre les différents types de PDF est la première étape pour choisir le bon outil et éviter des heures de travail inutiles.
Cette image illustre parfaitement la frustration de quiconque doit jongler entre un PDF complexe et une feuille de calcul désordonnée.

C'est précisément à ce moment-là qu'un processus manuel devient un frein à la productivité, ce qui démontre la nécessité d'une méthode plus efficace pour importer un fichier PDF dans Excel.
Tu ne le savais peut-être pas, mais l'outil le plus simple pour importer un fichier PDF dans Excel est déjà intégré au logiciel que tu utilises tous les jours. Il s'appelle Power Query et c'est une fonctionnalité puissante de « récupération et transformation des données » que Microsoft a intégrée à Excel.

C'est la solution idéale pour l'importation ponctuelle de fichiers PDF simples et bien structurés, comme une liste de prix ou une liste de contacts. Son principal avantage ? Elle est gratuite et ne nécessite aucune installation supplémentaire.
Les données seront importées dans une nouvelle feuille de calcul, déjà mises en forme sous forme de tableau Excel, prêtes à être utilisées.
Power Query est formidable, mais il a ses limites. Il fonctionne mieux avec des tableaux simples contenus dans une seule page. Ses performances chutent face à des scénarios plus complexes :
Si vous travaillez souvent avec l'analyse de données, vous pourriez être intéressé par les intégrations avec Power BI, qui utilise la même technologie. De même, il est essentiel de savoir gérer d'autres formats ; notre guide sur la gestion des fichiers CSV dans Excel peut vous fournir des conseils utiles.
Si votre entreprise dispose déjà d'une licence Adobe Acrobat Pro, sa fonctionnalité d'exportation est l'une des solutions les plus fiables. Elle surpasse souvent Power Query lorsqu'il s'agit de conserver la mise en forme de tableaux complexes et de mise en page non conventionnelle.
La procédure est simple : ouvrez le fichier PDF, allez dans « Tous les outils », sélectionnez « Exporter vers PDF », choisissez le format « Feuille de calcul » et enregistrez votre nouveau fichier Excel.
Le résultat est presque toujours net et soigné. Il y a toutefois deux inconvénients principaux :
Des outils comme iLovePDF, Smallpdf ou l'outil open source Tabula sont incroyablement pratiques : il suffit de glisser-déposer le fichier, de cliquer sur un bouton et de télécharger le résultat. Ils constituent une bonne option pour les conversions ponctuelles de données non sensibles.
Cependant, cette commodité cache un risque énorme : la sécurité des données.
Télécharger un document sur un serveur tiers revient, en réalité, à en perdre le contrôle. Si ce PDF contient des relevés bancaires, des données clients, des listes de prix confidentielles ou toute autre information stratégique, vous exposez votre entreprise à des violations potentielles de la vie privée et à de sérieux risques de non-conformité au RGPD.
Pour les PME opérant en Europe, ce n'est pas une mince affaire. Utiliser un convertisseur en ligne pour analyser un rapport public de l'Istat est acceptable. Le faire avec les données financières de votre entreprise est une démarche risquée que vous devez évaluer avec soin.
Si votre équipe doit traiter des dizaines de relevés bancaires, de factures ou de rapports qui arrivent chaque mois dans le même format, l'extraction manuelle est plus qu'une simple corvée : c'est un goulot d'étranglement opérationnel.
Pour les PME qui traitent des volumes importants de documents standardisés, l'automatisation via des scripts Python n'est pas un luxe, mais un investissement ciblé sur l'efficacité. Certes, cela nécessite des compétences techniques, mais le retour sur investissement est considérable en termes de gain de temps et de réduction des erreurs.

Python domine ce domaine grâce à des bibliothèques gratuites et extrêmement puissantes telles que pdfplumber et Camelot, spécialement conçues pour reconnaître et reconstituer la structure des tableaux contenus dans les fichiers PDF.
pdfplumber: Extrêmement polyvalent, il est idéal pour extraire des tableaux, du texte et des métadonnées, en analysant la position de chaque caractère.Camelot: Spécialisé dans l'extraction de tableaux, il propose des algorithmes avancés pour gérer les tableaux avec ou sans lignes de séparation visibles.Exemple concret : imaginez que vous receviez 50 factures d'un fournisseur à la fin du mois. Au lieu de mobiliser une ressource pendant des heures, un script Python peut les analyser, en extraire les totaux et les dates, puis générer un fichier Excel prêt à être analysé. Le tout en moins d'une minute et sans aucun risque d'erreur humaine.
Une fois extraites et structurées, ces données peuvent être transmises à des plateformes d'analyse. Pour en savoir plus sur la manière d'intégrer ces données dans des flux plus larges, découvrez comment fonctionnent les API ELECTE pour automatiser l'envoi de données vers notre plateforme.
Lorsque les méthodes traditionnelles échouent, l'intelligence artificielle entre en jeu. Les plateformes basées sur l'IA, telles ELECTE changer la donne, en particulier pour les documents numérisés ou présentant une mise en page complexe.
Nous ne parlons pas ici de l'ancien OCR, qui se contentait de « lire » le texte. Les solutions modernes associent l'OCR à des modèles linguistiques avancés (LLM) pour comprendre la structure, le contexte et les relations entre les données.
Imaginez un rapport financier comportant des tableaux qui s'étendent sur plusieurs pages. Une plateforme basée sur l'IA est capable de :
Cela change tout. Au lieu d'extraire des données brutes, la plateforme d'IA « digère » le PDF et le restitue sous la forme d'un ensemble de données nettoyé et prêt à être analysé. Si vous souhaitez en savoir plus, nous en avons parlé dans notre article sur les meilleures solutions d'intelligence artificielle pour les entreprises.
La véritable valeur de l'IA ne réside pas dans l'extraction de données, mais dans celle d'informations prêtes à l'emploi. Vous n'obtenez pas un simple fichier Excel, mais des données que votre équipe peut utiliser immédiatement pour prendre des décisions stratégiques, sans perdre de temps à les nettoyer.
Il est intéressant de savoir que Milan domine les importations italiennes. Mais le fait de pouvoir importer automatiquement un rapport complet sur les provinces importatrices permet à votre équipe d'aller bien plus loin : comparer les tendances, optimiser les stocks et réduire les coûts.
Avec autant de possibilités, comment choisir celle qui vous convient le mieux ? La réponse dépend de quatre facteurs clés qui déterminent l'efficacité, la sécurité et le coût de votre opération.
Cet arbre de décision vous aide à visualiser le raisonnement qui sous-tend votre choix.
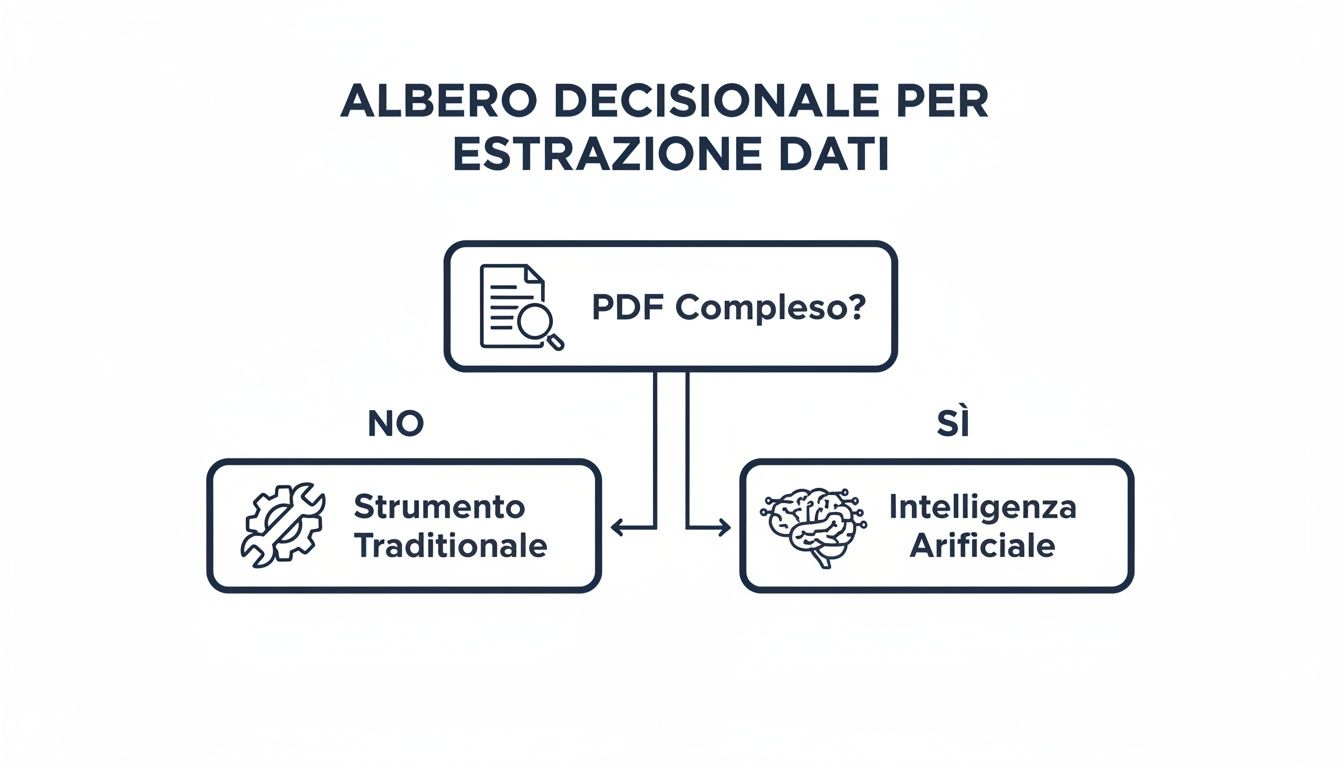
Le principe est simple : pour les fichiers PDF simples et les opérations ponctuelles, les outils traditionnels tels que Power Query sont parfaits. Pour les volumes importants, les documents complexes et les flux de travail récurrents, une plateforme basée sur l'IA comme ELECTE une tâche fastidieuse en un processus automatisé qui génère de la valeur.
L'importation d'un fichier PDF dans Excel ne doit plus être une tâche manuelle et fastidieuse. Vous disposez aujourd'hui d'une multitude d'outils, allant des solutions gratuites et intégrées comme Power Query aux solutions d'automatisation avancées et aux plateformes basées sur l'IA.
Le choix dépend de vos besoins spécifiques : pour des opérations ponctuelles sur des fichiers simples, Power Query est imbattable. Pour gérer des volumes récurrents de documents complexes et sensibles, l'automatisation et l'intelligence artificielle ne sont plus un luxe, mais une nécessité stratégique. En éliminant l'extraction manuelle, vous gagnez non seulement du temps et réduisez les erreurs, mais vous libérez également vos ressources les plus précieuses pour qu'elles puissent se concentrer sur ce qui compte vraiment : analyser les données afin de prendre des décisions commerciales plus intelligentes et plus rapides. C'est ainsi que vous transformez un simple document en source d'avantage concurrentiel.
Prêt à dire adieu pour de bon au copier-coller ? Découvrez comment ELECTE accélérer vos décisions en transformant vos PDF les plus complexes en informations exploitables.

.svg)
.svg)
.svg)



.webp)

.webp)
.webp)