

Vous recevez un fichier XML par courrier électronique certifié (PEC). Vous l'ouvrez dans votre navigateur, vous voyez une multitude de balises et vous pensez que le problème réside dans sa « lecture ». En réalité, ce n'est que le premier obstacle. Le véritable problème au sein de l'entreprise est tout autre : déterminer si ces données sont correctes, cohérentes et prêtes à être intégrées dans vos rapports.
Pour de nombreuses PME italiennes, cette question n'est plus purement technique. Depuis que la facturation électronique est devenue obligatoire, le format XML fait désormais partie intégrante du travail quotidien dans les domaines de l'administration, du contrôle de gestion et de l'analyse. Il ne suffit pas de visualiser le document. Il faut savoir faire la distinction entre un fichier lisible et un fichier fiable. Il faut comprendre quand un contrôle rapide suffit et quand il est nécessaire de procéder à l'analyse syntaxique, à la validation et à la normalisation avant d'importer les données dans Excel, dans un outil de BI ou sur une plateforme d'analyse.
Si vous cherchez un guide pratique pour lire des fichiers XML, voici la bonne approche : commencez par les méthodes simples, identifiez où elles présentent des failles, puis mettez en place un flux qui transforme le XML brut en données exploitables pour l'entreprise. C'est ainsi que l'on réduit les erreurs et que l'on raccourcit le délai entre « j'ai le fichier » et « j'ai une information exploitable ».
Un fichier XML organise les données selon une structure hiérarchique. Il comporte un élément principal, des sections imbriquées, et chaque bloc décrit une information ayant une signification précise. Pour ceux qui gèrent des processus administratifs, ce détail fait la différence entre une donnée lisible et une donnée réellement exploitable.
L'important n'est pas d'« ouvrir » le fichier. L'important est de déterminer si ce fichier peut être intégré sans erreur dans les processus de contrôle, de comptabilité et d'analyse.
Prenons l'exemple d'une facture électronique. Un même fichier contient à la fois les données du fournisseur, celles du client, les montants imposables, la TVA, les lignes d'articles, les conditions de paiement, les références de commande et souvent aussi des exceptions qui compliquent la lecture. En XML, ces informations ne sont pas présentées les unes sous les autres comme dans un document classique. Elles sont placées à des emplacements précis, et cet emplacement explique ce qu'elles représentent.
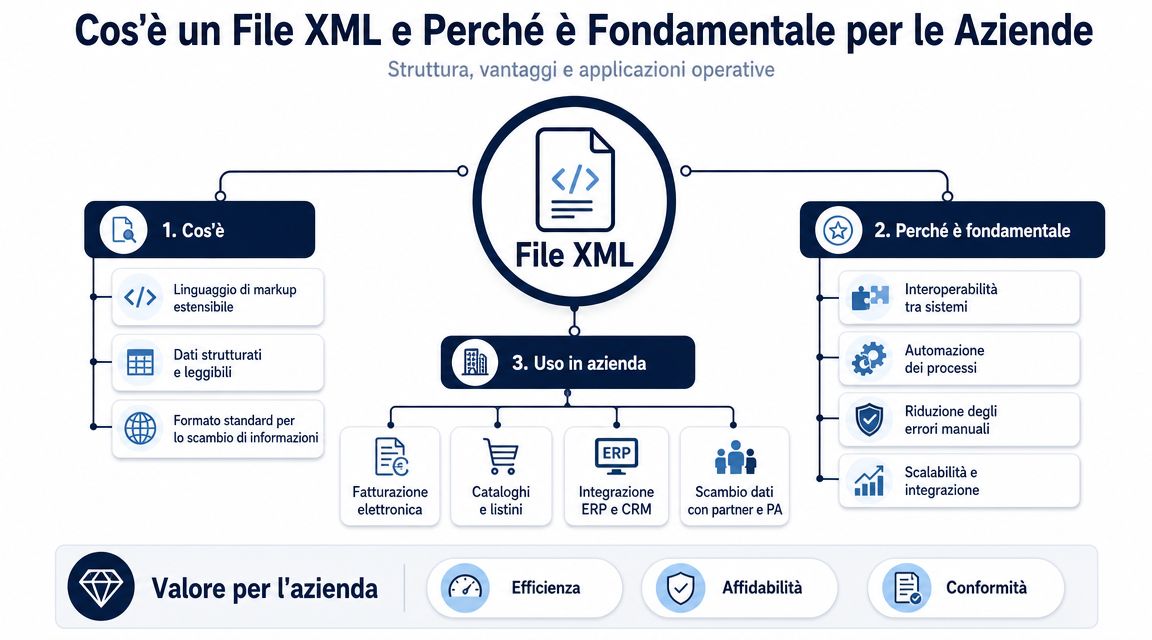
Pour un responsable, la distinction utile ne se situe pas entre les balises et les attributs au sens théorique. Elle se situe entre une donnée isolée et une donnée fiable. Lire « 1 000,00 » hors contexte ne sert pas à grand-chose. Le lire à l'endroit approprié du fichier permet de comprendre s'il s'agit du total du document, de la base imposable, de l'impôt ou de la valeur d'une ligne spécifique.
C'est là qu'apparaît le premier avantage opérationnel. Le format XML préserve le contexte des données.
Règle pratique : bien lire un fichier XML, c'est vérifier la signification de la valeur, et pas seulement la valeur elle-même.
En Italie, cette question s'est concrétisée avec la généralisation de la facturation électronique. Dans le format FatturaPA, le langage XML est devenu la norme pour la documentation fiscale. Par conséquent, son interprétation ne relève plus uniquement du domaine informatique. Elle concerne désormais l'administration, le contrôle de gestion, les achats et toute personne amenée à utiliser ces données pour prendre des décisions.
Dans la pratique, je constate toujours le même problème. Le fichier existe, les données sont là, mais le temps nécessaire pour les transformer en informations utiles est beaucoup trop long. Une personne ouvre le fichier XML, le vérifie à l’œil nu, copie les valeurs dans Excel, corrige les champs non uniformes, renomme les fournisseurs dont les noms sont écrits de différentes manières et tente de reconstituer des catégories de dépenses que le fichier ne présente pas sous une forme prête à être analysée. Le coût n’est pas seulement opérationnel. C’est du temps perdu avant d’obtenir des informations exploitables.
Avec FatturaPA, le risque est encore plus flagrant. Deux fichiers formellement corrects peuvent poser les mêmes problèmes d'analyse si l'un d'eux contient des descriptions de ligne très imprécises, si les références de commande sont incomplètes ou si les données de base du fournisseur présentent des variations. À ce stade, le problème n'est pas de lire le XML. Le problème est d'éviter que des données fiscales valides ne deviennent des données de gestion peu fiables.
Une erreur courante consiste à considérer le XML comme une pièce jointe à afficher. En entreprise, il vaut mieux le considérer comme une source de données structurée qu’il faut vérifier avant qu’elle n’alimente les rapports, les tableaux de bord et les modèles de dépenses. Si cette étape est mal gérée, l’équipe financière se retrouve à discuter de chiffres apparemment précis, mais fondés sur des classifications incohérentes.
Au départ, les bonnes questions sont les suivantes :
Il s'agit de contrôles très concrets. Ils permettent d'éviter les doublons de fournisseurs dans les rapports, les erreurs d'interprétation de la TVA, les centres de coûts renseignés de manière incomplète et les rapprochements laborieux en fin de mois.
C'est là que l'on constate l'écart entre la lecture technique et la valeur métier. Un analyseur syntaxique lit le fichier. Un processus bien conçu produit des données propres, comparables et prêtes à être analysées. Des plateformes telles qu'ELECTE ont été créées précisément pour combler cet écart, en réduisant le travail manuel qui sépare le fichier XML reçu des informations utiles permettant de prendre de meilleures décisions.
Pour effectuer des vérifications rapides sur un seul fichier, pas besoin de parseurs ni de bibliothèques. Il faut déterminer si vous procédez à une vérification visuelle de quelques champs ou si vous manipulez déjà des données qui seront utilisées pour la comptabilité, le reporting ou le contrôle de gestion. Cette distinction est importante, surtout avec les factures FatturePA. Une vérification effectuée à la va-vite aujourd’hui peut se traduire demain par une ligne erronée dans le jeu de données des fournisseurs.

Les navigateurs, les éditeurs de texte et les visionneuses dédiées répondent à un besoin précis : lire rapidement le contenu sans mettre en place un flux technique. Pour un fichier isolé, cela suffit souvent. Vous pouvez ouvrir un fichier XML dans Chrome, Edge ou Firefox pour en voir la structure, ou utiliser le Bloc-notes, WordPad ou TextEdit si vous souhaitez inspecter directement les balises. Dans le cas des factures électroniques, un visualiseur dédié rend plus lisibles les en-têtes, les lignes du document, le montant imposable et la TVA.
Le point essentiel est le suivant :
| Outil | Utile pour | Principale limite |
|---|---|---|
| Navigateur | Contrôle visuel rapide de la structure | Ne vérifie pas la cohérence entre les champs et les sections |
| Éditeur de texte | Inspection directe des étiquettes | Cela devient peu pratique avec des fichiers longs ou imbriqués |
| Excel | Contrôle préliminaire sous forme de tableau | Il gère mal les hiérarchies et les répétitions |
| Visionneuse dédiée | Une lecture plus claire des factures et des documents fiscaux | Il ne prépare pas les données en vue d'analyses ou d'automatisations |
Si vous devez vérifier la date du document, le numéro de TVA, le montant total de la facture ou la présence de pièces jointes, ces outils sont adaptés.
En revanche, si l'objectif est de comparer des fournisseurs, de classer des dépenses ou d'alimenter un tableau de bord, la simple consultation ralentit le travail et laisse trop de place aux erreurs manuelles. C'est l'écart classique entre le fait de consulter un fichier et celui d'obtenir une donnée fiable en temps utile.
Ouvrir un fichier XML ne revient pas à valider les données que vous utiliserez dans vos rapports.
Un autre aspect pratique concerne le volume. On peut encore vérifier dix fichiers à la main. Mais pas des centaines de factures FatturePA. Dans ce cas, il vaut mieux d’emblée envisager un processus reproductible ou des outils capables de lire le contenu de manière structurée, par exemple via une API permettant de collecter et de gérer les documents fiscaux de manière intégrée.
En Italie, le problème récurrent n'est pas d'ouvrir un .xml, mais savoir quoi faire quand arrive un .xml.p7m par PEC. Il faut distinguer les fichiers XML simples des fichiers signés numériquement. Dans ce dernier cas, il faut disposer d'outils capables de lire la signature, d'extraire le contenu et d'afficher le fichier XML correct, comme l'explique ce guide consacré au XML et au XML P7M dans la PEC.
Ici, les erreurs font perdre du temps :
Pour un employé administratif, la séquence la plus utile est simple :
Ces méthodes sont efficaces pour les contrôles de premier niveau. Elles ne résolvent toutefois pas le véritable problème auquel l'entreprise est confrontée : transformer les fichiers XML fiscaux, souvent irréguliers ou peu uniformes, en données propres et comparables, sans allonger le délai entre la réception du document et l'obtention d'informations exploitables.
Lorsque les fichiers commencent à s'accumuler, le travail manuel devient ingérable. À ce stade, lire des fichiers XML à l'aide de code n'est pas une solution élégante. C'est la première étape pour éviter les tâches répétitives, les erreurs de copie et les ensembles de données incohérents.

Une approche rigoureuse de la lecture du XML suit toujours la même logique : analyse syntaxique, normalisation, extraction ciblée. Dans les tutoriels Java et Android, le flux correct passe par parse(), à partir de la normalisation de l'arbre avec doc.getDocumentElement().normalize() et ensuite par la réhabilitation des terrains avec getElementsByTagName, une méthode plus fiable que le simple affichage dans un éditeur de texte, comme le montre ce tutoriel technique sur la lecture des données XML.
Cet enchaînement est plus important que le langage que tu choisis. Si tu ne procèdes pas à la normalisation, si tu recherches les nœuds de manière trop naïve, ou si tu pars du principe qu’une balise n’apparaît qu’une seule fois, ton script fonctionnera sur certains fichiers et échouera justement sur ceux qui comptent.
Pour les projets qui doivent ensuite interagir avec des systèmes externes, il peut être utile de mettre en place un flux d'extraction reproductible et documenté. Si vous travaillez sur des intégrations d'applications, la documentation sur les API d'ELECTE, accompagnée d'un profil Postman vérifié, constitue une base utile, notamment pour comprendre comment relier un ensemble de données déjà nettoyé à des processus ultérieurs.
Tu trouveras ci-dessous quelques exemples simples. L'objectif n'est pas de couvrir tous les cas de figure, mais de te montrer la logique de base : ouvrir le fichier, trouver un nœud, afficher une valeur.
import xml.etree.ElementTree as ETtree = ET.parse("fattura.xml")root = tree.getroot()numero = root.find(".//Numero")if numero is not None:print(numero.text)Python est souvent le choix le plus rapide pour les prototypes, les transformations et les pipelines légers. C'est un excellent choix lorsque vous devez lire de nombreux fichiers XML, extraire quelques champs et les enregistrer au format CSV ou JSON.
const xmlString = `<fattura><Numero>123</Numero></fattura>`;const parser = new DOMParser();const xmlDoc = parser.parseFromString(xmlString, "application/xml");const numero = xmlDoc.getElementsByTagName("Numero")[0];console.log(numero.textContent);Cette approche est utile pour les tests rapides en ligne ou les petits outils internes. Elle convient bien aux interfaces légères, mais moins aux flux structurés de back-office.
const fs = require("fs");const xml2js = require("xml2js");const xml = fs.readFileSync("fattura.xml", "utf8");xml2js.parseString(xml, (err, result) => {if (err) throw err;console.log(result.fattura.Numero[0]);});Si vous travaillez côté serveur et que vous souhaitez mettre en place des automatisations, Node.js reste un choix pratique. L'avantage réside dans la possibilité d'intégrer facilement la lecture de fichiers XML au système de fichiers, aux files d'attente de traitement et aux services internes.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse("fattura.xml");doc.getDocumentElement().normalize();NodeList lista = doc.getElementsByTagName("Numero");if (lista.getLength() > 0) {System.out.println(lista.item(0).getTextContent());}Java est souvent utilisé dans les environnements d'entreprise, les systèmes de gestion et les middlewares. Dans ce contexte, l'essentiel n'est pas seulement de lire les données, mais de le faire de manière prévisible et facile à maintenir.
library(XML)doc <- xmlParse("fattura.xml")numero <- xpathSApply(doc, "//Numero", xmlValue)print(numero)R est utile lorsque l'analyse syntaxique s'inscrit dans le cadre d'un travail analytique. Si votre prochaine étape consiste en une analyse statistique ou en une préparation des données, vous pouvez tout garder dans le même environnement.
Si votre équipe ouvre les mêmes fichiers chaque semaine et effectue les mêmes vérifications, vous êtes déjà dans le domaine de l'automatisation.
Le véritable intérêt ne réside pas dans le fait de « lire du XML à l'aide d'un code ». Il s'agit plutôt de décharger les personnes d'une tâche mécanique et de mettre en place un processus permettant de générer des ensembles de données cohérents.
Les vrais problèmes commencent lorsque les fichiers ne sont plus au nombre d'un seul. Une facture FatturaPA isolée est presque toujours facile à gérer. La difficulté apparaît lorsqu'il faut regrouper plusieurs mois de documents, différents fournisseurs, des champs remplis de manière hétérogène et des pièces jointes intégrées.
Dans les PME italiennes, le cas le plus courant n’est pas celui d’un « méga-fichier » isolé, mais celui d’un lot. Une exportation annuelle de factures fournisseurs peut générer une structure comportant plus de 380 000 nœuds répartis sur 4 200 factures, comprenant les en-têtes, les lignes de détail, les données de paiement et les pièces jointes au format base64. Dans ces cas-là, le problème ne réside pas dans l'ouverture du document, mais dans la transformation de fichiers XML hétérogènes en un ensemble de données cohérent.
C'est là qu'intervient un choix technique ayant des répercussions sur l'activité. Dans l'environnement .NET, Microsoft indique que XmlDocument charge le document en mémoire et s'avère utile pour la lecture et la modification, tandis que pour les fichiers volumineux ou les opérations en lecture seule, il est préférable de s'orienter vers des approches plus efficaces telles que les analyseurs en continu (parser streaming) ou XPathDocument, afin d'éviter une consommation excessive de RAM, comme le précise la documentation Microsoft sur la lecture XML avec XmlDocument et XPathDocument.
En pratique :
Le compromis est simple. Le modèle en mémoire vous permet de développer plus rapidement. Le modèle en streaming est plus performant en production lorsque les fichiers sont nombreux ou volumineux.
De nombreuses équipes se contentent de la validation XSD. C'est utile, mais cela ne suffit pas. Un fichier peut respecter le schéma tout en générant des données erronées en aval.
Exemples typiques tirés de la pratique :
| Type de contrôle | Ce qu'il vérifie | Pourquoi est-ce nécessaire ? |
|---|---|---|
| Structurel | Balises, format, hiérarchie | Évitez les erreurs d'analyse syntaxique |
| Sémantique | Cohérence logique des données | Évitez les analyses erronées |
| En service | Présence de champs utiles pour le reporting | Évitez les ensembles de données inutilisables |
Le cas le plus insidieux est le suivant : un « Montant total du document » formellement valide mais qui ne correspond pas à la somme des lignes, peut-être en raison des règles d'arrondi du logiciel de gestion du fournisseur. Ou encore, des codes TVA formellement admissibles mais qui ne correspondent pas à la nature de l'opération.
Un fichier formellement correct peut néanmoins fausser vos rapports.
Il existe par ailleurs un autre piège bien connu dans les factures FatturaPA. La balise « DatiBeniServizi » contient des descriptions libres. Un même coût peut apparaître sous de nombreuses formes différentes, avec des textes clairs, abrégés ou cryptiques. Si vous ne procédez pas à une normalisation, toute analyse par catégorie de dépenses devient peu fiable.
C'est pourquoi, dans les flux sérieux, la lecture du fichier ne constitue que le premier niveau. Le deuxième niveau consiste toujours en un ensemble de règles de cohérence et de nettoyage. C'est là que l'on garantit la qualité des données, et non dans le parseur.
Un fichier XML correctement lu ne constitue pas encore un ensemble de données exploitable. Il s'agit d'un document structuré. Pour effectuer des analyses, des comparaisons, des regroupements et créer des tableaux de bord, il faut presque toujours le convertir dans un format plus facile à traiter.
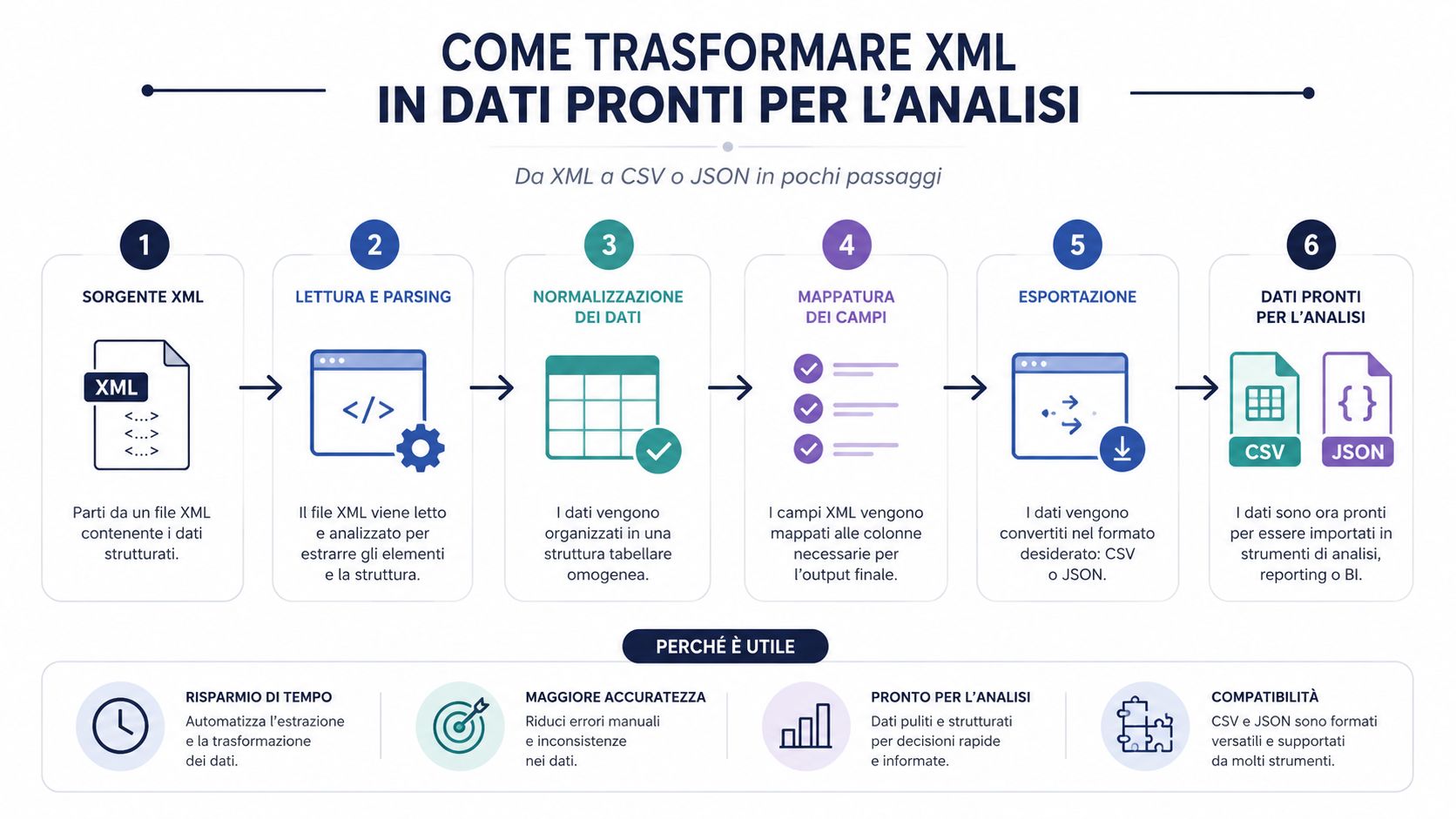
C'est là un aspect que de nombreux processus sous-estiment. Le goulot d'étranglement réside rarement dans le parsing proprement dit. Une bibliothèque de qualité lit un fichier XML en un temps record. Le temps est plutôt consacré à l'interprétation de la structure, à l'extraction des champs utiles, au nettoyage, à la normalisation et au chargement dans un outil d'analyse.
C'est pourquoi la conversion au format CSV ou JSON n'est pas simplement une question de commodité. Il s'agit d'une étape opérationnelle essentielle. Si vous sautez cette étape et travaillez directement sur le fichier brut, vous vous retrouvez presque toujours avec des vérifications manuelles, des colonnes improvisées et des logiques difficiles à reproduire.
Ce guide, qui explique comment passer du format XML à Excel de manière plus structurée, constitue une ressource utile pour ceux qui travaillent souvent avec des fichiers XML et des feuilles de calcul.
Le format approprié dépend de l'usage que vous ferez ensuite de ces données.
Le format CSV est particulièrement adapté lorsque vous souhaitez une ligne par document ou une ligne par ligne de détail de facture, puis utiliser Excel, Power Query ou un outil de BI.
Exemple en Python :
import xml.etree.ElementTree as ETimport csvtree = ET.parse("facture.xml")root = tree.getroot()with open("factures.csv", "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(["numéro", "date"])numéro = root.findtext(".//Numero")data = root.findtext(".//Data")writer.writerow([numero, data])L'avantage, c'est la simplicité. L'inconvénient, c'est qu'il faut bien réfléchir à la manière d'aplatir la hiérarchie. Si une facture comporte plusieurs lignes de détail, il faut faire un choix clair concernant la granularité et la clé de liaison.
Le format JSON est plus adapté lorsque vous souhaitez conserver une partie de la structure hiérarchique.
Exemple JavaScript :
const record = {numero: "123",data: "2024-01-15",righe: [{ descrizione: "Servizio", importo: "100.00" }]};console.log(JSON.stringify(record, null, 2));Utilisez-le lorsque votre prochaine étape est une API, un lac de données ou une application qui gère bien les objets imbriqués.
Voici une règle pratique qui peut vous aider :
Le fichier XML sert de conteneur. Les formats CSV et JSON permettent de traiter efficacement le contenu.
Si vous souhaitez réduire le délai d'analyse, c'est là qu'il convient d'investir de manière méthodique. Non pas en cherchant un outil de visualisation plus pratique, mais en définissant une transformation stable et reproductible.
Une fois que le fichier a été lu, validé et transformé, la nature du travail change. Vous n'êtes plus aux prises avec les balises. Vous vous concentrez enfin sur les coûts, les anomalies, les fournisseurs, les catégories de dépenses et les tendances opérationnelles.
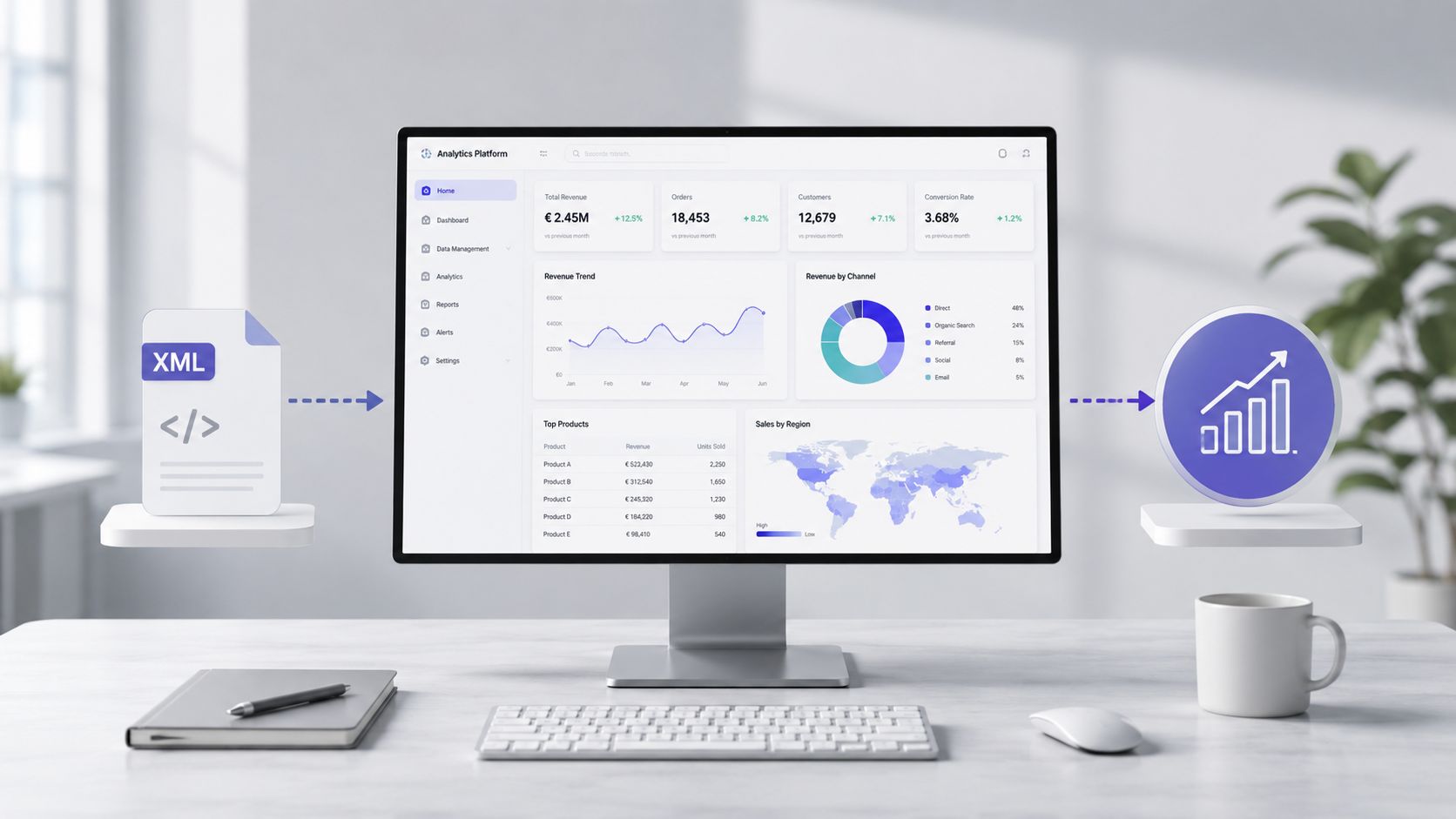
Dans la pratique, la valeur ne réside pas dans le temps de parsing. Elle réside dans le temps qui sépare le fichier brut d'une information sur laquelle vous pouvez prendre une décision. Avec un flux manuel, une personne doit ouvrir le document, en comprendre la structure, extraire les champs, nettoyer les valeurs, normaliser les textes, puis créer des rapports. C'est un processus fragile.
Un exemple classique dans FatturaPA est le champ de texte libre de la section « DatiBeniServizi ». Un même service peut être décrit de nombreuses façons différentes selon les prestataires. Si vous importez ces données sans mise en correspondance cohérente, l'analyse par catégorie de coûts génère des agrégations inutiles.
C'est pourquoi, avant la plateforme d'analyse, il faut une couche de préparation, étant donné que :
Lorsque cette étape est bien menée, n’importe quelle plateforme d’analyse fonctionne mieux. Si vous souhaitez approfondir l’aspect décisionnel et visuel de cette étape, la ressource consacrée à la création de récits à partir des données est utile, car elle montre comment un ensemble de données propre peut devenir un récit pertinent pour les décideurs.
À ce stade, le fichier XML cesse d'être un problème technique pour devenir une source d'informations. Un ensemble de données bien préparé peut alimenter des analyses de dépenses, le suivi des tendances, la mise en évidence des écarts et l'identification des exceptions.
Pour choisir une plateforme adaptée à cette « dernière étape », il peut être utile de comparer ce qu'offre un logiciel moderne d'analyse de données d'entreprise par rapport à des processus purement manuels reposant sur des feuilles de calcul et des tableaux croisés dynamiques.
Ici, la bonne question n'est pas « sait-il ouvrir un fichier XML ? ». C'est le minimum. La question pertinente est une autre :
| Question | Pourquoi c'est important |
|---|---|
| Les données sont déjà propres à leur arrivée | Évitez les analyses précises basées sur des données erronées |
| Les catégories sont cohérentes | Vous comparez-vous vraiment les fournisseurs et les périodes ? |
| Les anomalies apparaissent immédiatement | Réduisez le temps perdu en vérifications manuelles |
| Le rapport est compréhensible pour les services commerciaux et financiers | Accélérer la prise de décision |
La différence entre un processus immature et un processus abouti ne réside pas dans la capacité à lire des fichiers XML. Elle réside dans la capacité à les transformer en une base de données fiable, qui n'oblige pas l'équipe à refaire le même travail à chaque fois.
Si vous devez lire des fichiers XML à des fins professionnelles, gardez cette liste de contrôle à l'esprit. Elle est plus concrète que n'importe quelle définition technique et vous aide à choisir la bonne méthode sans perdre de temps.
N'utilisez pas toujours la même approche. Les navigateurs, les éditeurs et les visualiseurs conviennent pour des vérifications rapides. Les analyseurs syntaxiques et les scripts sont utiles lorsque le fichier doit alimenter des processus répétitifs. Si vous confondez visualisation et traitement des données, vous risquez de créer des rapports reposant sur des bases fragiles.
Les fichiers .xml.p7m nécessitent une étape spécifique de gestion de la signature. Si le contenu provient d'une adresse PEC, ce contrôle n'est pas accessoire. Il fait partie intégrante de la lecture correcte du document.
Le fait de respecter un schéma ne garantit pas la qualité d'un ensemble de données. Ce sont les incohérences logiques, telles que des totaux non alignés ou des classifications fiscales ambiguës, qui compromettent le plus souvent l'analyse. C'est le contrôle sémantique qui fait la différence entre un fichier « acceptable » et des données fiables.
Les formats CSV et JSON ne sont pas une simple question d'apparence. C'est grâce à eux que le XML devient exploitable par les outils d'analyse, les tableurs, les pipelines et les rapports. Plus tôt vous définissez cette transformation, plus tôt vous réduisez le travail manuel et l'improvisation.
Votre objectif n'est pas de lire des fichiers XML. Il s'agit d'obtenir des informations utiles sans encombrer le système avec des données erronées. Si le flux ne produit pas un ensemble de données cohérent, le problème ne se situe pas au niveau du tableau de bord final. Il se situe bien en amont.
Concrètement, tu peux utiliser cette mini-liste de contrôle avant chaque nouveau projet :
Si vous souhaitez transformer des données déjà préparées en informations claires et exploitables, ELECTE aide les PME à passer d'un ensemble de données nettoyé à un reporting intelligent, grâce à une approche accessible même aux équipes non techniques. C'est le moyen le plus rapide de réduire l'écart entre les données opérationnelles et la prise de décision.

.svg)
.svg)
.svg)
.webp)





