

Tes données racontent déjà une histoire. Le problème, c'est qu'elles parlent souvent trop doucement.
Chaque jour, une PME recueille des retours clients, des commandes, des tickets d'assistance, des mouvements financiers, des e-mails commerciaux et des notes CRM. Toutes ces données contiennent des indices utiles. Certains indiquent qu'un client est sur le point de partir. D'autres signalent un risque opérationnel. D'autres encore montrent quels produits sont sur le point de connaître une accélération ou un ralentissement. Sans méthode claire, cependant, ces indices ne sont que du bruit.
Parmi les algorithmes qui aident à mettre de l'ordre dans ce chaos, les classificateurs bayésiens naïfs occupent une place particulière. Leur logique est simple à comprendre, ils sont rapides à entraîner et souvent plus efficaces que ne le laisse supposer leur nom « naïf ». Ils ne constituent pas le choix idéal dans tous les cas de figure, mais pour de nombreux problèmes concrets rencontrés en entreprise, ils offrent un équilibre rare entre rapidité, interprétabilité et résultats utiles.
Si vous travaillez dans le monde des affaires, vous n’avez pas besoin de devenir chercheur pour les comprendre. Vous devez savoir ce qu’ils font, pourquoi ils fonctionnent bien même lorsqu’ils simplifient considérablement la réalité, et dans quels cas ils peuvent vous aider à prendre de meilleures décisions. C’est précisément là qu’il vaut la peine de s’arrêter.
De nombreuses entreprises recherchent des modèles sophistiqués alors que le problème nécessite avant tout un modèle fiable et facile à utiliser. C'est pour cette même raison que, dans la finance, le commerce de détail ou le service client, c'est souvent le processus le plus clair qui l'emporte, et non le plus élégant d'un point de vue théorique.
Les classificateurs bayésiens naïfs partent d'un principe très concret. Si l'on dispose de quelques indices sur un nouveau cas, on peut estimer avec une bonne probabilité à quelle catégorie il appartient. Si un e-mail contient certains mots, il pourrait s'agir d'un spam. Si une transaction présente certaines caractéristiques, elle pourrait nécessiter une vérification. Si un avis utilise certains termes, cela pourrait indiquer une satisfaction ou une insatisfaction.
Le mot « bayésien » évoque des formules complexes. En réalité, le principe de cette méthode est intuitif. On part de ce que l’on sait déjà, on y ajoute de nouvelles informations et on actualise son jugement. C’est une manière structurée de raisonner en situation d’incertitude, exactement ce que font les managers au quotidien, mais systématisé par un algorithme.
Ce qui est surprenant, c'est que cette approche continue de bien fonctionner même dans les environnements modernes, caractérisés par une abondance de données et des prises de décision rapides. Non pas parce qu'elle décrit parfaitement le monde, mais parce qu'elle permet de distinguer le signal utile du bruit avec un coût de calcul très faible.
Dans le domaine des affaires, la bonne question n'est pas « quel est le modèle le plus sophistiqué ? », mais « quel modèle me permet de prendre des décisions fiables dans des délais compatibles avec la réalité du terrain ? ».
C'est pourquoi les classificateurs bayésiens naïfs restent importants. Ils vous aident à classer, filtrer, segmenter et hiérarchiser. Et ils vous permettent d'intégrer la probabilité dans le processus décisionnel sans transformer chaque projet en chantier technique.
Le principe de base est le théorème de Bayes. En termes simples, cela signifie qu'on part d'une probabilité initiale, puis qu'on la met à jour lorsque de nouvelles informations sont disponibles.
En langage statistique, la formule s'écrit ainsi : P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y). Cela signifie que la probabilité d'une classe, compte tenu d'un ensemble de signaux, dépend de deux éléments. Le premier est la probabilité initiale de la classe. Le second est le degré de compatibilité de chaque signal avec cette classe.
Transposons cela à un exemple concret. Vous devez déterminer si un e-mail est du spam ou non. Vous disposez d'une probabilité générale indiquant qu'un e-mail entrant est du spam. Vous examinez ensuite certains mots tels que « offre », « gratuit », « cliquez ici ». Chacun de ces mots modifie votre jugement final.
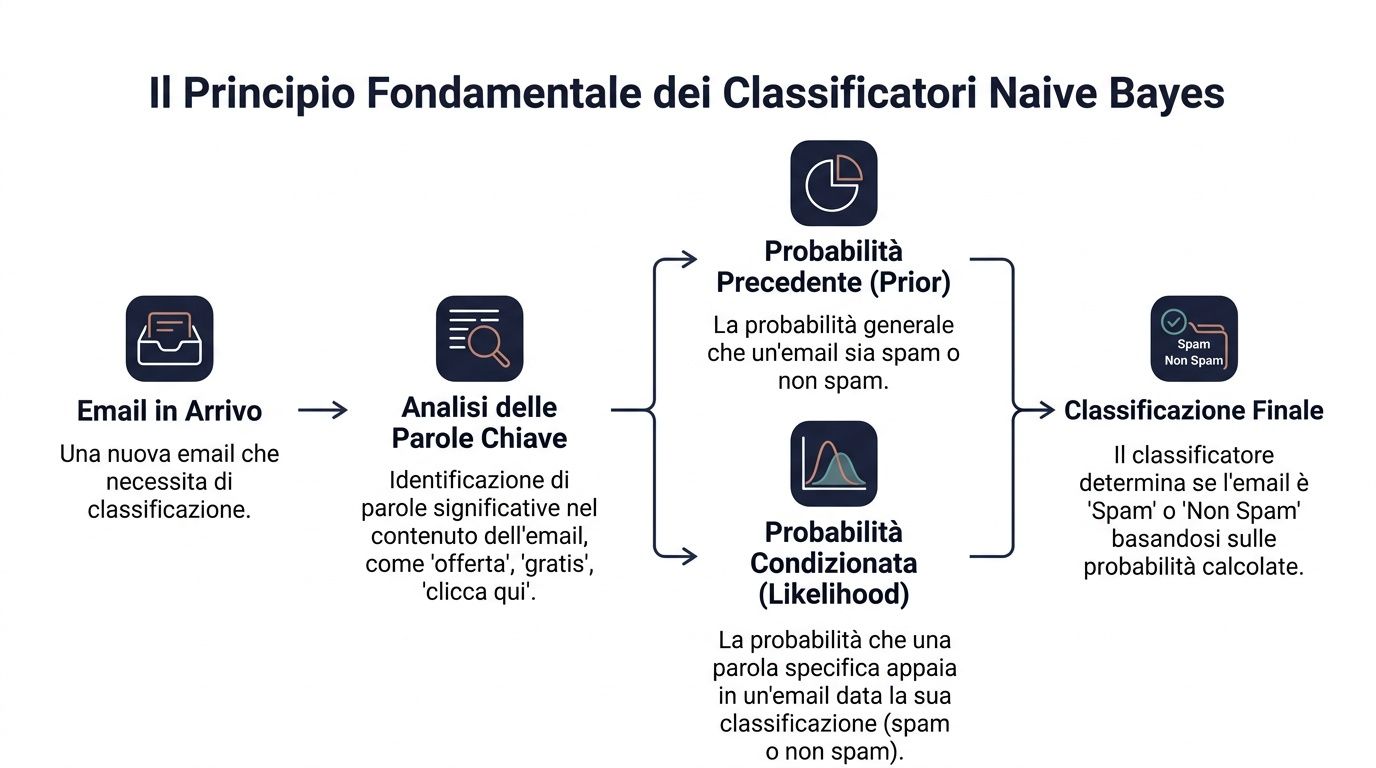
Un responsable fait ce genre de chose tous les jours. Il ne prend jamais de décision en vide. Il part d'un contexte de base et y ajoute des indices. Un client qui a toujours acheté régulièrement présente un certain profil de départ. S'il cesse ensuite d'ouvrir ses e-mails, réduit la valeur de ses commandes et ouvre un ticket critique, votre évaluation change.
Le terme « naïf » désigne une hypothèse précise. Le modèle traite les caractéristiques comme si elles étaient indépendantes les unes des autres, étant donné que la classe est connue.
Concrètement, lorsque vous classez un e-mail, considérez chaque mot comme un indice distinct. N'essayez pas de modéliser toutes les relations complexes entre les termes. Il s'agit là d'une simplification radicale. En réalité, de nombreux mots apparaissent ensemble et de nombreux comportements d'entreprise sont interdépendants.
Et pourtant, c'est précisément ce choix qui rend ce modèle très léger. Il n'a pas besoin d'apprendre un réseau complexe de dépendances. Il doit estimer des probabilités plus simples et les combiner efficacement.
Règle pratique : l'algorithme Naive Bayes ne cherche pas à modéliser le monde dans son ensemble. Il cherche à prendre des décisions utiles en se basant sur un minimum d'hypothèses et en agissant très rapidement.
C'est souvent là que naît le malentendu. Beaucoup lisent « hypothèse naïve » et en concluent qu'il s'agit d'un « modèle faible ». Ce n'est pas le cas. Un modèle peut simplifier considérablement les choses tout en restant performant si cette simplification met en évidence ce qui compte pour la prise de décision.
En 2004, une analyse théorique a mis en évidence des raisons solides justifiant l'efficacité des classificateurs naïfs de Bayes malgré l'hypothèse d'indépendance, expliquant également pourquoi ils peuvent atteindre l'erreur asymptotique plus rapidement que la régression logistique. Dans le même domaine d'application, en matière de filtrage des spams, ils atteignent des taux de précision supérieurs à 99 % et s'adaptent à des millions de documents, comme indiqué dans l'article consacré aux classificateurs naïfs de Bayes.
Ce point est important pour un public professionnel. La valeur d'un algorithme ne réside pas uniquement dans le score final. Elle réside également dans sa capacité à s'entraîner rapidement, à s'adapter à de vastes ensembles de données et à rester interprétable.
Lorsque vous avez des textes, des catégories, des balises ou des signaux dispersés, les classificateurs bayésiens naïfs fonctionnent bien car :
Il y a toutefois deux points à garder à l'esprit.
C'est pourquoi l'algorithme Naive Bayes doit être considéré comme un outil très efficace pour les problèmes de classification rapides, et non comme une solution miracle universelle. Dans de nombreux contextes pratiques, cependant, c'est l'une des meilleures façons de commencer.
Une erreur courante consiste à parler du modèle Naive Bayes comme s'il s'agissait d'un modèle unique et identique dans toutes les situations. En réalité, il existe différentes variantes, conçues pour différents types de données.
Le choix approprié dépend de la forme des données dont vous disposez. Si vous choisissez la mauvaise variante, le modèle peut tout de même produire une prévision, mais il ne raisonne pas de la manière la plus adaptée à votre problème.
Le modèle Gaussian Naive Bayes est la variante la plus adaptée lorsque les caractéristiques sont continues. Pense par exemple au montant moyen d'une transaction, à l'âge du client, au délai moyen entre deux achats, à la marge unitaire ou au montant du ticket de caisse.
Ici, le modèle part du principe que, dans chaque classe, les valeurs suivent une distribution gaussienne. Il ne faut pas voir cela comme une contrainte théorique. Il suffit de retenir l'idée pratique : pour chaque classe, le modèle estime un centre typique et un écart-type.
Cette approche est utile lorsque vous souhaitez classer des cas tels que :
Lors d'un test de performance scikit-learn réalisé sur un ensemble de données similaire à des données de commerce électronique italiennes, un modèle Naive Bayes a atteint une précision de 95 % avec 1 000 échantillons, avec un temps d'apprentissage inférieur de 15 % à celui de la régression logistique . La comparaison indiquée est de 0,01 s contre 0,1 s sur un processeur standard, grâce à l'apprentissage en mode fermé, comme le montre le chapitre de Jake VanderPlas intitulé « In Depth Naive Bayes Classification ».
Pour une entreprise, l'important n'est pas la décimale. L'important, c'est que cette variante peut donner de bons résultats sans nécessiter de longues périodes d'apprentissage ni d'infrastructure lourde.
Si vous travaillez avec des textes, des tickets, des avis ou des commentaires, le modèle Multinomial Naive Bayes est souvent le choix qui s'impose. Dans ce cas, les caractéristiques sont des comptages ou des fréquences. Concrètement, le modèle examine le nombre de fois où des mots ou des termes apparaissent.
C'est le scénario classique de :
La raison pour laquelle cela fonctionne bien est très concrète. Dans les textes d'entreprise, le vocabulaire peut être vaste, mais chaque document ne contient qu'une petite partie des mots possibles. Les données sont dispersées. Le modèle Naive Bayes multinomial gère très bien ce type de structure.
Dans une étude portant sur 100 000 tweets italiens classés selon leur sentiment, le modèle multinomial Naive Bayes a obtenu un score F1 de 0,88, avec une vitesse 10 fois supérieure à celle du SVM, comme l'indique le guide de GeeksforGeeks sur les classificateurs Naive Bayes.
Pour t'en souvenir facilement, pense-y ainsi : si tes données ressemblent à un document rempli de mots comptés, la distribution multinomiale est presque toujours la première option à tester.
Si votre entreprise doit traiter de grands volumes de texte, la question n'est pas seulement « quel est le niveau de précision du modèle ? ». Il s'agit également de savoir « combien de requêtes il est capable de classer sans ralentir le travail de l'équipe ? ».
Bernoulli Naive Bayes fonctionne avec des caractéristiques binaires. Il ne tient pas compte du nombre de fois où un signal apparaît. Il prend uniquement en compte sa présence ou son absence.
Cette variante est utile lorsque la présence d'un attribut a plus d'importance que sa fréquence. Voici quelques exemples tirés du monde de l'entreprise :
C'est une approche très utile lorsque l'on souhaite transformer des phénomènes complexes en indicateurs binaires (oui/non) faciles à suivre. En analyse de sentiment, par exemple, le fait qu'un mot négatif apparaisse peut avoir plus d'importance que le nombre de fois où il est répété.
La loi de Bernoulli n'est pas « moins sophistiquée » que la loi multinomiale. Elle est simplement plus adaptée lorsque les données décrivent une présence ou une absence. La différence est minime en théorie, mais considérable dans les résultats.
| Variante | Type de données idéal | Exemple de cas d'utilisation en entreprise |
|---|---|---|
| Gaussien naïf bayésien | Données en continu | Classer les transactions par niveau de risque en fonction des montants, de la fréquence et des valeurs moyennes |
| Naïf bayésien multinomial | Textes, calculs, fréquences | Analyser les avis et les tickets clients par sentiment ou par catégorie |
| Bernoulli et Naive Bayes | Données binaires, présence/absence | Évaluer les signaux « oui/non » concernant la conformité, l'assistance ou l'utilisation du produit |
Pour faire le bon choix, suis cette règle simple :
De nombreuses équipes se retrouvent dans une impasse parce qu'elles cherchent le « meilleur » modèle qui soit. Le bon choix est presque toujours celui qui correspond le mieux au type de données.
La bonne nouvelle, c'est que la mise en pratique de l'algorithme Naive Bayes ne nécessite pas un projet titanesque. Même un prototype lisible permet déjà de comprendre comment le modèle fonctionne et de quelles données il a besoin.

La création d'un classificateur se déroule presque toujours en quatre étapes.
Préparation des données
Vous devez collecter des exemples historiques déjà étiquetés. Si vous classez des avis, vous avez besoin de textes déjà marqués comme positifs ou négatifs. Si vous analysez le risque opérationnel, vous avez besoin de cas passés dont l'issue est connue.
Entraînement du modèle
Le modèle analyse les données et estime les probabilités pertinentes. Dans les classificateurs bayésiens naïfs, cette étape est rapide car l'entraînement ne nécessite pas d'optimisations particulièrement lourdes.
Prévision des nouveaux cas
Saisissez de nouvelles entrées et le modèle leur attribuera une catégorie. Par exemple : « spam », « non-spam », « client à risque », « client stable ».
Évaluation d'
: comparez les prévisions avec la réalité sur un ensemble de données distinct. Ici, vous ne vous contentez pas de vérifier si le modèle fonctionne. Vous examinez comment il se trompe.
Si vous souhaitez approfondir vos connaissances sur les approches prédictives en général, cet aperçu des algorithmes d'apprentissage automatique vous aidera à replacer l'algorithme Naive Bayes dans le contexte d'une famille plus large de méthodes.
Pour illustrer concrètement ce processus, voici un exemple très simple avec scikit-learn. Pas besoin de le lire en tant que développeur. Il suffit de comprendre le déroulement.
# Importons les principaux outilsfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# Chargons un ensemble de données d'exempleX, y = load_iris(return_X_y=True)# Nous divisons les données en un ensemble d'entraînement et un ensemble de testX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Créons le modèlelmodel = GaussianNB()# Entraînons le modèle sur les données historiquesmodel.fit(X_train, y_train)# Faisons des prédictions sur des données jamais vuesy_pred = model.predict(X_test)# Mesurons la précisionprint(accuracy_score(y_test, y_pred))Ce passage en dit bien plus long qu'il n'y paraît.
GaussianNB() choisissez l'option pour les données continues.fit() C'est le moment où le modèle apprend.predict() met en pratique ce qu'il a appris.accuracy_score() vérifie combien de classifications sont correctes au total.Pour les données textuelles, le processus reste similaire, mais avant d'appliquer le modèle, tu dois convertir le texte en chiffres. Concrètement, tu transformes les mots en caractéristiques exploitables par un classificateur.
Après un premier coup d'œil au code, il peut être utile de consulter une illustration du mécanisme.
Le premier modèle ne vise pas à démontrer la perfection. Il sert à répondre à trois questions pratiques.
C'est là que réside la force de l'algorithme Naive Bayes. Il permet d'obtenir rapidement une base de référence solide. À partir de là, on peut déterminer s'il est judicieux de complexifier le projet ou si une solution simple apporte déjà de la valeur.
On ne juge pas un modèle de classification uniquement sur le fait qu'il « semble fonctionner ». On le juge en fonction de ses erreurs et de l'impact de ces erreurs sur l'activité.

La précision est l'indicateur le plus intuitif. Elle indique le nombre de prévisions correctes par rapport au total. Elle est utile, mais à elle seule, elle peut être trompeuse.
Si, sur cent transactions, seules quelques-unes sont réellement suspectes, un modèle qui classe presque tout comme normal peut sembler performant en termes de précision, mais s'avérer insuffisant là où cela compte vraiment.
Pour mieux comprendre, imagine un filet de pêche.
Dans le monde des affaires, cette distinction a beaucoup d'importance.
Un bon modèle n'est pas celui qui fait le moins d'erreurs en général. C'est celui qui commet des erreurs de la manière la moins coûteuse pour votre processus.
Pour mieux comprendre comment un algorithme apprend à partir des données historiques et pourquoi la qualité de l'entraînement influe sur le résultat final, vous pouvez lire cet article détaillé sur ce en quoi consiste l'entraînement d'un algorithme.
L'algorithme Naive Bayes est simple, mais il ne pardonne pas certaines erreurs pratiques.
Première erreur : ignorer le problème de la fréquence nulle.
Si un mot ou une valeur n'apparaît jamais dans les données d'entraînement pour une certaine classe, la probabilité peut chuter à zéro et fausser le calcul. C'est pourquoi on utilise souvent le lissage de Laplace, qui ajoute un petit correctif aux comptages.
Deuxième erreur : utiliser des variables fortement corrélées.
Si deux colonnes fournissent pratiquement la même information, le modèle risque de surestimer le signal. Il ne « comprend » pas que ces deux indices sont pratiquement identiques.
Troisième erreur : se fier trop aux probabilités brutes.
L'algorithme Naive Bayes classe souvent correctement les éléments, mais ses probabilités peuvent être trop catégoriques. Pour les entreprises, cela signifie que le classement peut être utile, tandis que la valeur précise de la probabilité doit être interprétée avec prudence.
Pour réduire ces risques, il est conseillé de :
La véritable valeur des classificateurs bayésiens naïfs apparaît lorsque l'on cesse de les considérer comme un simple exercice mathématique et que l'on commence à les utiliser comme outil d'établissement des priorités. En entreprise, bien classer signifie presque toujours mieux décider.

Imaginez une équipe financière qui analyse les flux de transactions, les descriptions opérationnelles et les données historiques. Chaque ligne n'est pas seulement un enregistrement. C'est une décision potentielle : laisser passer, approfondir, bloquer, transmettre à un analyste.
Avec Naive Bayes, vous pouvez combiner différents indicateurs au sein d'une même classification. Certains sont numériques, d'autres binaires, d'autres encore textuels. Le modèle aide à déterminer quels cas ressemblent le plus à des schémas déjà observés, qu'ils soient normaux ou anormaux.
L'avantage pratique est double :
Cela ne remplace pas le jugement humain dans les contextes réglementés. Cela permet de l'organiser. Et dans les processus opérationnels à haut volume, cela fait une réelle différence.
En marketing, classer signifie souvent attribuer chaque client à un groupe opérationnel. Les fidèles. Les sensibles au prix. Les clients à risque de désabonnement. Les réactifs aux promotions. Les clients inactifs.
Dans ce cas, l'algorithme Naive Bayes est utile car il permet de combiner rapidement des signaux hétérogènes :
Une équipe CRM n'a pas besoin d'une théorie parfaite du comportement humain. Elle a besoin d'une segmentation suffisamment précise pour déclencher des actions pertinentes. Par exemple, modifier le message, la fréquence des contacts ou le type d'offre.
Lorsqu'un modèle aide à choisir le message suivant destiné au bon client, il crée déjà de la valeur opérationnelle.
Dans le commerce de détail et le commerce électronique, la classification facilite des activités qui semblent différentes mais qui reposent sur la même logique : mettre de l'ordre dans le chaos.
Vous pouvez classer les produits en fonction de leur profil de vente. Vous pouvez consulter les avis et les tickets pour identifier les catégories qui posent problème. Vous pouvez repérer des tendances de la demande qui aident l'équipe à planifier les promotions et les stocks avec plus de clarté.
Dans ce type d'environnement, les données sont souvent nombreuses, hétérogènes et pas toujours parfaites. C'est pourquoi un modèle rapide, évolutif et lisible revêt une grande importance. Non pas parce qu'il est le plus séduisant, mais parce qu'il s'intègre au flux de travail sans le ralentir.
Si vous souhaitez découvrir comment les approches analytiques appliquées au monde des affaires se concrétisent dans des projets concrets, vous pouvez consulter ces études de cas.
Il est utile de comprendre le modèle Naive Bayes. Mais le mettre en œuvre correctement dans un contexte professionnel, c'est une autre histoire.
Le problème ne réside presque jamais uniquement dans l'algorithme. Le véritable travail porte sur le modèle. Il faut relier différentes sources de données, gérer les champs manquants, préparer les textes, mettre à jour les étiquettes, contrôler la qualité des résultats et présenter ces derniers de manière compréhensible pour les décideurs.
Pour une PME, cette étape est souvent le point critique. Non pas parce que l'IA ne suscite pas d'intérêt, mais parce que le temps dont dispose l'équipe est limité et que les priorités opérationnelles ne peuvent attendre.
Dans ce contexte, il est judicieux d'utiliser une plateforme qui prend en charge la complexité technique. Une solution basée sur l'IA permet de transformer des données brutes en informations exploitables sans que les équipes métier aient à écrire de code, à choisir des bibliothèques ou à gérer manuellement des pipelines.
Une plateforme telle ELECTE, une plateforme d'analyse de données alimentée par l'IA destinée aux PME, rend accessibles des méthodes telles que les classificateurs bayésiens naïfs sans nécessiter de compétences spécialisées en apprentissage automatique. L'avantage ne réside pas seulement dans la rapidité. Il s'agit de la réduction des frictions entre les données et la prise de décision.
Lorsque l'automatisation fonctionne bien, l'équipe ne raisonne plus en termes de formules. Elle raisonne en termes de questions pertinentes :
C'est aussi la raison pour laquelle de plus en plus d'entreprises recherchent des outils permettant d'évaluer la fiabilité des contenus générés par l'IA et des signaux textuels qui circulent dans leurs processus internes. Dans ce contexte, il peut être utile de consulter également un guide sur un détecteur d'IA italien, surtout si votre équipe travaille sur des documents, des contenus et des vérifications linguistiques.
En pratique, la différence est simple. Au lieu de gérer des étapes techniques fragmentées, vous vous concentrez sur les résultats de l'entreprise. Et c'est là que l'IA devient vraiment exploitable, et pas seulement intéressante.
Les classificateurs bayésiens naïfs nous enseignent une leçon importante. En analyse de données, la simplicité bien appliquée peut l'emporter sur la complexité mal gérée.
Grâce à une base probabiliste intuitive, à une bonne évolutivité et à des cas d'utilisation très concrets, cette approche reste un outil fiable pour les entreprises qui souhaitent classer des informations, déceler des signaux cachés et agir avec plus d'assurance. Il n'est pas nécessaire d'être un spécialiste du machine learning pour en comprendre la valeur. Il suffit de faire le lien entre les mathématiques et la prise de décision opérationnelle.
Une fois ce lien bien compris, l'IA cesse d'être une question technique pour devenir un atout organisationnel. C'est là que la prévision commence à produire des résultats concrets.
Si tu souhaites transformer des données éparses en informations claires, essaie ELECTE. Cette plateforme aide les PME à connecter leurs sources de données, à automatiser l'analyse et à obtenir des rapports et des prévisions utiles pour prendre des décisions plus rapides et mieux informées.

.svg)
.svg)
.svg)






