

צוותי הכספים בחברות קטנות ובינוניות יודעים זאת היטב: בכל פעם שמנסים לייבא קובץ PDF ל-Excel, מתחיל מאבק עם העיצוב. פעולת ההעתקה וההדבקה הקלאסית הופכת כמעט תמיד לאסון: נתונים מפוזרים, תאים שמאורגנים באקראי וטבלאות מסודרות שהופכות לכאוס בלתי קריא. התסכול הוא אמיתי, אך האשמה אינה מוטלת עליך. הבעיה טמונה באופי של פורמט ה-PDF עצמו, שנועד להדפסה ולשיתוף, ולא לשמש כמקור נתונים לניתוח.
תהליך עבודה ידני זה, המורכב מדוחות בנקאיים, חשבוניות ספקים ומסמכים של גופים ממשלתיים, מהווה מכשול אמיתי לפריון. מלבד היותו משעמם, הוא מהווה מקור כמעט ודאי לטעויות בהזנת נתונים. למרבה המזל, בשנת 2026 עומדים לרשותך שיטות חכמות בהרבה להתמודדות עם אתגר זה. במדריך זה, נציג לך צעד אחר צעד את האסטרטגיות היעילות ביותר, החל מאלה המשולבות ב-Excel ועד לפתרונות מבוססי בינה מלאכותית (AI) המבטלים לחלוטין את העבודה הידנית, ומאפשרים לך לעבור מחילוץ נתונים לניתוח תוך דקות ספורות.
הבעיה נובעת מהבחנה מהותית: קבצי PDF נוצרו כדי לשמר את המראה של מסמך בכל מכשיר, ולא כדי לשמור על המבנה הלוגי של הנתונים שבתוכו. הבנת ההבדל בין סוגי קבצי ה-PDF היא הצעד הראשון בבחירת הכלי הנכון ובמניעת שעות של עבודה מיותרת.
תמונה זו משקפת בצורה מושלמת את התסכול של כל מי שנאלץ להתמודד עם התאמת נתונים בין קובץ PDF מורכב לבין גיליון אלקטרוני מבולגן.

זהו הרגע המדויק שבו תהליך ידני הופך למכשול בפני הפריון, ומדגים את הצורך בשיטה יעילה יותר לייבוא קובץ PDF ל-Excel.
אולי לא ידעת, אבל הכלי הפשוט ביותר לייבוא קובץ PDF ל-Excel כבר מובנה בתוכנה שבה אתה משתמש מדי יום. הוא נקרא Power Query, וזו פונקציונליות חזקה של "שליפת נתונים והמרתם" שמיקרוסופט שילבה ב-Excel.

זהו הפתרון האידיאלי לייבוא מזדמן של קבצי PDF פשוטים ומאורגנים היטב, כגון מחירון או רשימת אנשי קשר. היתרון הגדול ביותר שלו? הוא חינמי ואינו מצריך התקנות נוספות.
הנתונים יוכנסו לגליון עבודה חדש, מעוצבים כבר כטבלה ב-Excel, ומוכנים לשימוש.
Power Query הוא כלי נהדר, אך יש לו מגבלות. הוא פועל במיטבו עם טבלאות פשוטות המופיעות בעמוד אחד. הביצועים שלו יורדים משמעותית כאשר מדובר בתרחישים מורכבים יותר:
אם אתה עוסק לעתים קרובות בניתוח נתונים, ייתכן שתתעניין בבחינת שילובים עם Power BI, המשתמש באותה הטכנולוגיה. כמו כן, היכולת לטפל בפורמטים אחרים היא חיונית; המדריך שלנו לטיפול בקבצי CSV ב-Excel עשוי לספק לך רעיונות מועילים.
אם לחברה שלך כבר יש רישיון ל-Adobe Acrobat Pro, פונקציית הייצוא של התוכנה היא אחד הפתרונות האמינים ביותר. לעתים קרובות היא עולה על Power Query בשמירה על העיצוב של טבלאות מורכבות ובעלות פריסה לא שגרתית.
התהליך פשוט: פתח את קובץ ה-PDF, עבור ל "כל הכלים", בחר "ייצא ל-PDF", הגדר את הפורמט ל"גיליון אלקטרוני" ושמור את קובץ ה-Excel החדש שלך.
התוצאה היא כמעט תמיד נקייה ומסודרת. עם זאת, ישנם שני חסרונות עיקריים:
כלים כמו iLovePDF, Smallpdf או התוכנה הקוד הפתוח Tabula הם נוחים להפליא: גוררים את הקובץ, לוחצים על כפתור ומורידים את התוצאה. הם מהווים אופציה טובה להמרות מזדמנות של נתונים שאינם רגישים.
עם זאת, הנוחות הזו מסתירה סיכון עצום: אבטחת המידע.
העלאת מסמך לשרת של צד שלישי פירושה, למעשה, לאבד את השליטה עליו. אם קובץ ה-PDF הזה מכיל דוחות בנק, נתוני לקוחות, מחירונים סודיים או כל מידע אסטרטגי אחר, אתה חושף את החברה שלך להפרות פוטנציאליות של פרטיות ולסיכונים חמורים בתחום הציות לתקנות ה-GDPR.
עבור חברות קטנות ובינוניות הפועלות באירופה, זו אינה עניין של מה בכך. השימוש בממיר מקוון לניתוח דוח ציבורי של Istat הוא דבר מקובל. אך לעשות זאת עם הנתונים הפיננסיים של החברה שלך הוא צעד מסוכן שיש לשקול בזהירות.
אם הצוות שלכם נדרש לטפל בעשרות דוחות חשבון, חשבוניות או דוחות שמגיעים מדי חודש באותו פורמט, הטיפול הידני בהם הוא יותר מסתם מטרד: זהו צוואר בקבוק תפעולי.
עבור חברות קטנות ובינוניות המעבדות כמויות גדולות של מסמכים סטנדרטיים, אוטומציה באמצעות סקריפטים ב-Python אינה מותרות, אלא השקעה ממוקדת ביעילות. אמנם הדבר דורש כישורים טכניים, אך התשואה על ההשקעה היא עצומה מבחינת החיסכון בזמן והפחתת הטעויות.

Python שולטת בתחום זה בזכות ספריות חינמיות ועוצמתיות ביותר כמו pdfplumber ו קמלוט, שפותחו במיוחד כדי לזהות ולשחזר את מבנה הטבלאות הכלולות בקבצי PDF.
pdfplumber: הוא רב-תכליתי ביותר, ומצטיין בחילוץ טבלאות, טקסט ומטא-נתונים, תוך ניתוח המיקום של כל תו ותו.קמלוט: מתמחה בחילוץ טבלאי, ומציע אלגוריתמים מתקדמים לניהול טבלאות עם ובלי קווי הפרדה גלויים.תרחיש מעשי: דמיין שאתה מקבל 50 חשבוניות מספק בסוף החודש. במקום להקדיש לכך שעות עבודה, סקריפט ב-Python יכול לסרוק אותן, לחלץ את הסכומים הכוללים והתאריכים, וליצור קובץ Excel מוכן לניתוח. כל זאת בפחות מדקה, תוך ביטול מוחלט של הסיכון לטעויות אנוש.
לאחר שחולצו ואורגנו, ניתן לשלוח נתונים אלה לפלטפורמות ניתוח נתונים. כדי ללמוד כיצד לשלב נתונים אלה בזרימות נתונים רחבות יותר, גלה כיצד פועלות ממשקי ה-API של ELECTE כדי להפוך את שליחת הנתונים לפלטפורמה שלנו לאוטומטית.
כאשר השיטות המסורתיות נכשלות, הבינה המלאכותית נכנסת לתמונה. פלטפורמות המונעות על ידי בינה מלאכותית, כמו ELECTE את כללי המשחק, במיוחד בכל הנוגע למסמכים סרוקים או בעלי פריסה מורכבת.
אנחנו לא מדברים על ה-OCR הישן, שהסתפק ב"קריאת" הטקסט. הפתרונות המודרניים משלבים בין OCR למודלים לשוניים מתקדמים (LLM) כדי להבין את המבנה, ההקשר והקשרים בין הנתונים.
דמיין דוח פיננסי הכולל טבלאות המשתרעות על פני מספר עמודים. פלטפורמה המונעת על ידי בינה מלאכותית מסוגלת:
זה משנה את הכל. במקום לחלץ נתונים גולמיים, פלטפורמת ה-AI "מעכלת" את קובץ ה-PDF ומחזירה אותו כמאגר נתונים מסודר ומוכן לניתוח. אם ברצונך לקבל מידע נוסף, התייחסנו לנושא במאמר שלנו על מערכות הבינה המלאכותית הטובות ביותר לעסקים.
הערך האמיתי של הבינה המלאכותית אינו בהפקת נתונים, אלא בהפקת מידע מוכן לשימוש. אתה לא מקבל סתם קובץ אקסל, אלא נתונים שהצוות שלך יכול להשתמש בהם מיד לצורך קבלת החלטות אסטרטגיות, מבלי לבזבז זמן על ניקוי הנתונים.
מעניין לדעת שמילאנו מובילה את היבוא האיטלקי. אך היכולת לייבא באופן אוטומטי דוח מקיף על מחוזות היבוא מאפשרת לצוות שלך לעשות הרבה יותר: להשוות מגמות, לייעל את המלאי ולהפחית עלויות.
עם כל כך הרבה אפשרויות, איך תבחר את האפשרות המתאימה לך? התשובה תלויה בארבעה גורמים מרכזיים הקובעים את היעילות, הבטיחות והעלות של הניתוח שלך.
עץ ההחלטות הזה עוזר לך להמחיש את התהליך ההגיוני שבבסיס הבחירה שלך.
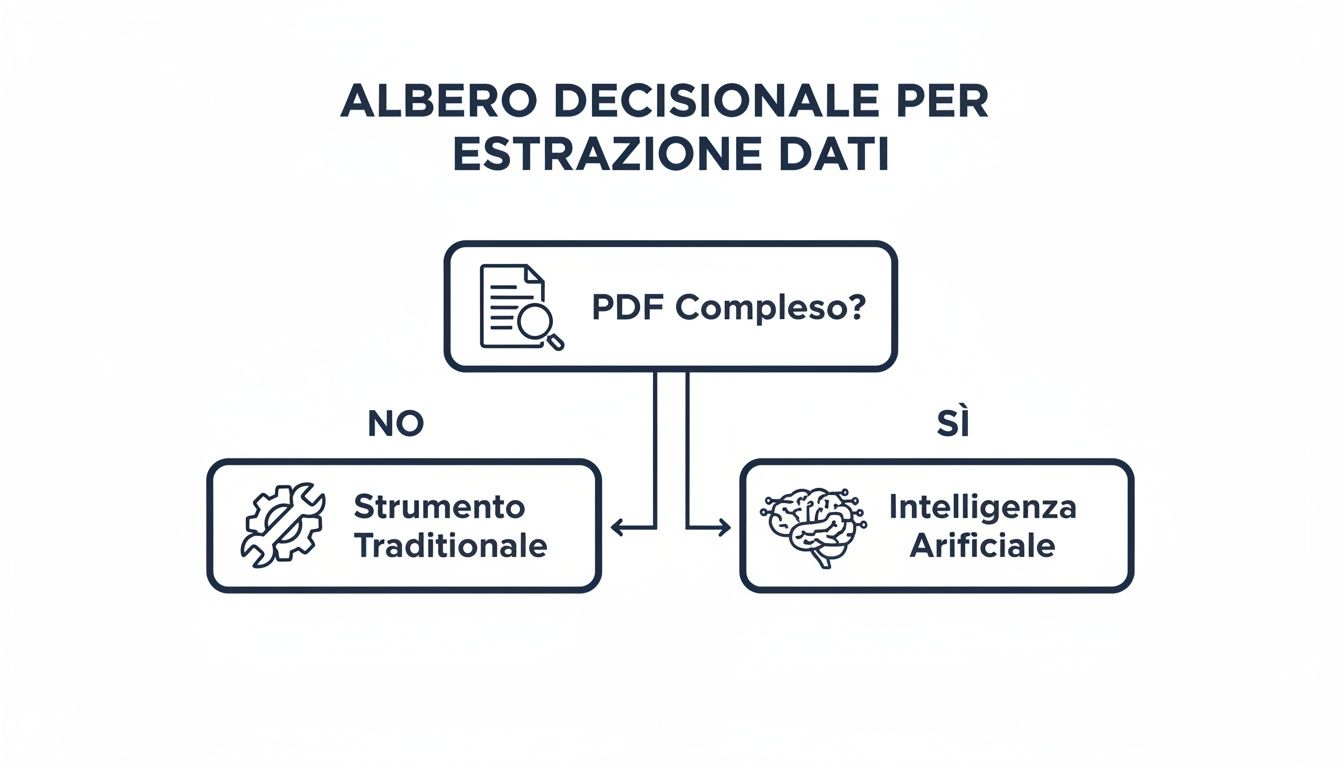
העיקרון פשוט: עבור קבצי PDF פשוטים ופעולות מזדמנות, כלים מסורתיים כמו Power Query הם הפתרון המושלם. עבור כמויות גדולות, מסמכים מורכבים ותהליכי עבודה חוזרים, פלטפורמה מבוססת בינה מלאכותית כמו ELECTE משימה משעממת לתהליך אוטומטי המייצר ערך.
ייבוא קובץ PDF ל-Excel כבר לא חייב להיות תהליך ידני ומתסכל. כיום עומד לרשותך מגוון רחב של כלים, החל מכלי חינמיים ומובנים כמו Power Query ועד לפתרונות אוטומציה מתקדמים ופלטפורמות המונעות על ידי בינה מלאכותית.
הבחירה תלויה בצרכים הספציפיים שלך: עבור פעולות מזדמנות על קבצים פשוטים, Power Query היא הבחירה הטובה ביותר. לניהול כמויות חוזרות ונשנות של מסמכים מורכבים ורגישים, אוטומציה ובינה מלאכותית אינן עוד מותרות, אלא צורך אסטרטגי. על ידי ביטול החילוץ הידני, לא רק שאתה חוסך זמן ומצמצם טעויות, אלא גם משחרר את המשאבים היקרים ביותר שלך כדי להתמקד במה שבאמת חשוב: ניתוח נתונים כדי להנחות החלטות עסקיות חכמות ומהירות יותר. כך אתה הופך מסמך פשוט למקור של יתרון תחרותי.
מוכן להיפרד לתמיד מההעתקה וההדבקה? גלה כיצד ELECTE להאיץ את קבלת ההחלטות שלך על ידי הפיכת קבצי ה-PDF המורכבים ביותר שלך לתובנות שניתן לפעול על פיהן.

.svg)
.svg)
.svg)






