

אתה מקבל קובץ XML באמצעות דואר אלקטרוני מאובטח (PEC). אתה פותח אותו בדפדפן, רואה קיר של תגיות וחושב שהבעיה היא "לקרוא" אותו. למעשה, זהו רק המכשול הראשון. הבעיה האמיתית בארגון היא אחרת: להבין אם הנתונים האלה נכונים, עקביים ומוכנים להכללה בדוחות שלך.
עבור חברות קטנות ובינוניות איטלקיות רבות, נושא זה כבר אינו טכני במובן הצר של המילה. מאז שהחשבוניות האלקטרוניות הפכו לחובה, שפת ה-XML הפכה לחלק בלתי נפרד מהעבודה היומיומית בתחומי הניהול, הבקרה הניהולית והניתוח. לא די בצפייה במסמך. עליך לדעת להבחין בין קובץ קריא לקובץ אמין. עליך להבין מתי די בבדיקה מהירה ומתי נדרשים ניתוח, אימות ונורמליזציה לפני העלאת הנתונים ל-Excel, ל-BI או לפלטפורמת ניתוח נתונים.
אם אתם מחפשים מדריך מעשי לקריאת קבצי XML, זו הדרך הנכונה: להתחיל בשיטות הפשוטות, להבין היכן הן נכשלות, ואז לבנות זרימה שתהפוך XML גולמי לנתונים שימושיים לעסק. כך ניתן לצמצם את השגיאות ולקצר את הזמן שבין "יש לי את הקובץ" ל"יש לי תובנה שמישה".
קובץ XML מארגן את הנתונים במבנה היררכי. יש בו אלמנט ראשי, יש בו קטעים מקוננים, וכל בלוק מתאר מידע בעל משמעות מדויקת. עבור מי שמנהל תהליכים מנהליים, פרט זה הוא ההבדל בין נתונים קריאים לנתונים שניתן באמת להשתמש בהם.
העניין אינו "לפתוח" את הקובץ. העניין הוא להבין אם הקובץ הזה יכול להשתלב ללא שגיאות בתהליכי הבקרה, החשבונאות והניתוח.
ניקח לדוגמה חשבונית אלקטרונית. באותו הקובץ מופיעים יחד נתוני הספק, נתוני הלקוח, סכומים חייבים במס, מע"מ, שורות פריטים, תנאי תשלום, הפניות להזמנה ולעתים קרובות גם חריגים שמסבכים את הקריאה. ב-XML, מידע זה אינו מוצג זה מתחת לזה כמו בכל גיליון רגיל. הוא ממוקם במיקומים מדויקים, והמיקום הזה מסביר מה הוא מייצג.
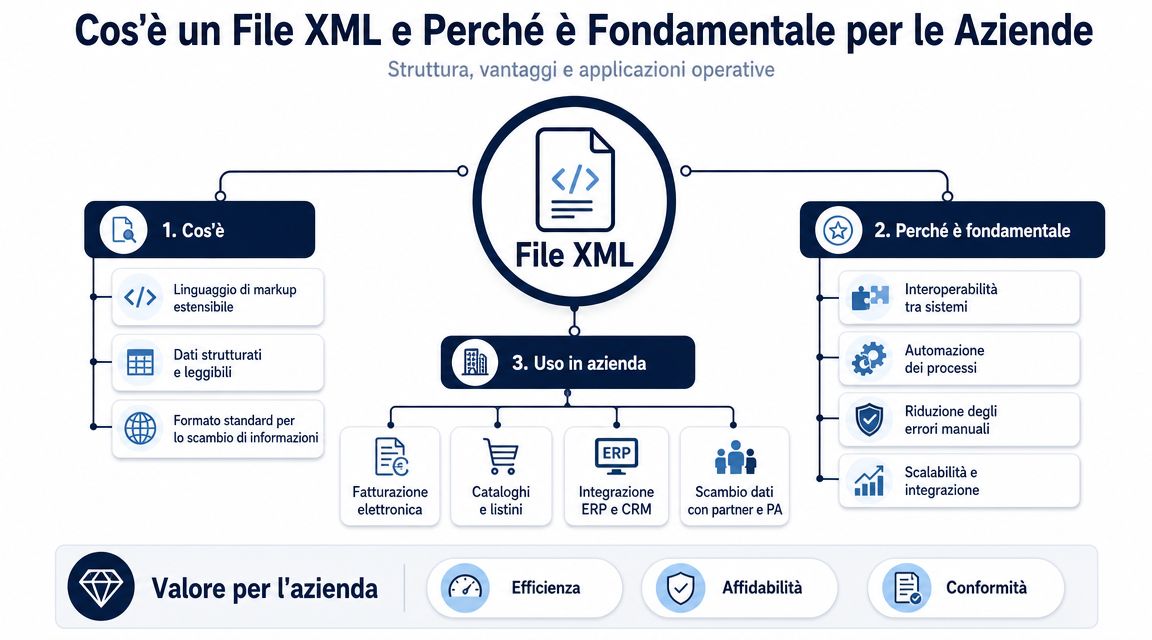
עבור מנהל, ההבחנה החשובה אינה בין תגים לתכונות במובן התיאורטי. היא בין נתון מבודד לנתון אמין. לקרוא את "1000,00" מחוץ להקשר לא מועיל הרבה. קריאתו במקום הנכון בקובץ מאפשרת להבין אם מדובר בסך המסמך, בבסיס המס, במס עצמו או בערך של שורה בודדת.
כאן טמון היתרון התפעולי הראשון. ה-XML שומר על ההקשר של הנתונים.
כלל מעשי: קריאה נכונה של קובץ XML פירושה לבדוק את המשמעות של הערך, ולא רק את הערך עצמו.
באיטליה נושא זה הפך למציאות עם התפשטות החשבוניות האלקטרוניות. בפורמט FatturaPA, שפת ה-XML הפכה לסטנדרט עבור מסמכים פיסקליים. כתוצאה מכך, קריאתן אינה נוגעת עוד רק לתחום ה-IT. היא מערבת את מחלקות הניהול, בקרת הניהול, הרכש וכל מי שנדרש להשתמש בנתונים אלה לצורך קבלת החלטות.
בפועל, אני נתקל תמיד באותה הבעיה. הקובץ קיים, הנתונים שם, אך הזמן הנדרש להפיכתם למידע שימושי מתארך יתר על המידה. אדם פותח את קובץ ה-XML, בודק אותו בעין, מעתיק ערכים ל-Excel, מתקן שדות שאינם אחידים, משנה שמות של ספקים שנכתבו בצורות שונות ומנסה לשחזר קטגוריות הוצאה שהקובץ אינו מציג בצורה מוכנה לניתוח. העלות אינה רק תפעולית. זהו זמן אבוד עד להפקת תובנות.
בשימוש ב-FatturaPA הסיכון בולט עוד יותר. שני קבצים שנראים תקינים מבחינה פורמלית עלולים ליצור את אותן בעיות ניתוח אם באחד מהם נעשה שימוש בתיאורי שורות לא מדויקים, אם פרטי ההזמנה אינם שלמים או אם פרטי הספק מוזנים בגרסאות שונות. בשלב זה, הבעיה אינה בקריאת ה-XML. הבעיה היא למנוע ממידע פיסקלי תקין להפוך לנתונים ניהוליים שאינם אמינים.
טעות נפוצה היא להתייחס ל-XML כאל קובץ מצורף שיש להציג. בארגון, עדיף להתייחס אליו כאל מקור נתונים מובנה שיש לבדוק לפני שהוא משמש כבסיס לדוחות, לוחות מחוונים ומודלים של הוצאות. אם שלב זה מנוהל בצורה לא נכונה, צוות הכספים מוצא את עצמו דן במספרים שנראים מדויקים, אך מבוססים על סיווגים לא עקביים.
השאלות הנכונות, בהתחלה, הן אלה:
מדובר בבדיקות מעשיות מאוד. הן נועדו למנוע כפילויות של ספקים בדוחות, פרשנות שגויה של מע"מ, מילוי חלקי של מרכזי עלות ותהליכי התאמה איטיים בסוף החודש.
כאן ניכר הפער בין קריאה טכנית לערך עסקי. מנתח תחבירי קורא את הקובץ. תהליך שתוכנן כהלכה מניב נתונים נקיים, הניתנים להשוואה ומוכנים לניתוח. פלטפורמות כמו ELECTE נוצרו כדי לגשר על פער זה, על ידי צמצום העבודה הידנית המפרידה בין ה-XML שהתקבל לבין התובנות השימושיות לקבלת החלטות טובות יותר.
לבדיקות מהירות של קובץ בודד, אין צורך במנתחי קוד או בספריות. צריך להבין אם אתה מבצע בדיקה ויזואלית של מספר שדות בודדים, או שאתה כבר נוגע בנתונים שייכנסו לחשבונאות, לדיווחים או לבקרה ניהולית. ההבדל הזה חשוב, במיוחד כשמדובר בחשבוניות FatturePA. בדיקה שנעשית היום בחופזה עלולה להפוך מחר לשורה שגויה במאגר הנתונים של הספקים.

דפדפנים, עורכי טקסט ותוכנות צפייה ייעודיות פותרות בעיה ספציפית: קריאה מהירה של התוכן ללא צורך בהגדרת תהליך טכני. עבור קובץ בודד, זה לרוב מספיק. ניתן לפתוח קובץ XML ב-Chrome, ב-Edge או ב-Firefox כדי לראות את המבנה, או להשתמש ב-Notepad, ב-WordPad או ב-TextEdit אם ברצונך לבחון את התגים ישירות. במקרה של חשבוניות אלקטרוניות, תוכנת צפייה ייעודית מקלה על קריאת הכותרות, שורות המסמך, הסכום החייב במס ומע"מ.
הנקודה המעשית היא זו:
| כלי | שימושי ל- | מגבלה עיקרית |
|---|---|---|
| דפדפן | בדיקה ויזואלית מהירה של המבנה | אינו בודק את העקביות בין השדות והקטעים |
| עורך טקסט | בדיקה ישירה של התגים | זה הופך להיות מסורבל בקבצים ארוכים או מקוננים |
| Excel | בדיקה מקדימה בטבלה | מתמודד בצורה לא טובה עם היררכיות וחזרות |
| תצוגה ייעודית | קריאה ברורה יותר של חשבוניות ומסמכים פיסקליים | היא אינה מכינה את הנתונים לצורך ניתוח או אוטומציה |
אם עליך לבדוק את תאריך המסמך, מספר המע"מ, סכום החשבונית או קיומם של קבצים מצורפים, כלים אלה מתאימים למטרה זו.
לעומת זאת, אם המטרה היא להשוות בין ספקים, לסווג הוצאות או להזין נתונים ללוח מחוונים, הצגת הנתונים בלבד מאטה את העבודה ומותירה מרחב רב מדי לטעויות ידניות. זהו הפער הקלאסי בין הצגת קובץ לבין השגת נתון אמין בזמן סביר.
פתיחת קובץ XML אינה זהה לאימות הנתונים שתשתמש בהם בדוחות.
נקודה מעשית נוספת נוגעת להיקף. עשר שורות אפשר לבדוק גם ידנית. מאות חשבוניות FatturePA – לא. במקרה כזה, כבר כדאי לשקול תהליך חוזר או כלים שיקראו את התוכן בצורה מובנית, למשל באמצעות ממשק API לאיסוף ולניהול מסמכים פיסקליים באופן משולב.
באיטליה, הבעיה החוזרת ונשנית אינה פתיחת .xml, אך להבין מה לעשות כאשר מגיע .xml.p7m באמצעות PEC. יש להבחין בין קבצי XML פשוטים לקבצים חתומים דיגיטלית. במקרה השני נדרשים כלים המסוגלים לקרוא את החתימה, לחלץ את התוכן ולהציג את ה-XML הנכון, כפי שמסביר מדריך זה מוקדש ל-XML ול-XML P7M במערכת הדואר האלקטרוני המאושר (PEC).
כאן טעויות עולות בזמן:
עבור עובד אדמיניסטרטיבי, הרצף השימושי ביותר הוא פשוט:
שיטות אלה מבצעות היטב את תפקידן בבדיקות ברמה הראשונה. הן אינן פותרות את הבעיה האמיתית המעיקה על החברה: הפיכת קבצי XML של מסים, שלעתים קרובות אינם תקינים או אינם אחידים, לנתונים נקיים וניתנים להשוואה, מבלי להאריך את הזמן שבין קבלת המסמך לקבלת המידע השימושי.
כאשר הקבצים מתחילים להצטבר, העבודה הידנית כבר אינה בת-קיימא. בשלב זה, קריאת קבצי XML באמצעות קוד אינה פתרון אלגנטי. זהו הצעד הראשון למניעת פעולות חוזרות, טעויות בהעתקה ומאגרי נתונים לא עקביים.

גישה איתנה לקריאת XML תמיד פועלת לפי אותה לוגיקה: ניתוח תחבירי, נורמליזציה, חילוץ ממוקד. במדריכים ל-Java ול-Android, התהליך הנכון עובר דרך parse(), מהנורמליזציה של העץ באמצעות doc.getDocumentElement().normalize() ואז משיקום השדות באמצעות getElementsByTagName, שיטה יציבה יותר מאשר הצגה פשוטה בעורך טקסט, כפי שמוצג המדריך הטכני הזה על קריאת נתוני XML.
הסדר הזה חשוב יותר מהשפה שתבחר. אם תדלג על הנורמליזציה, אם תחפש צמתים בצורה תמימה מדי, או אם תניח שתג מופיע תמיד פעם אחת בלבד, הסקריפט שלך יעבוד על חלק מהקבצים, אך ייכשל דווקא באלה החשובים באמת.
בפרויקטים שצריכים לתקשר עם מערכות חיצוניות, ייתכן שיהיה מועיל לבנות תהליך חילוץ שניתן לשכפל אותו ומתועד. אם אתה עובד על שילוב יישומים, בסיס מועיל הוא התיעוד על ה-API של ELECTE עם פרופיל Postman מאומת, במיוחד כדי להבין כיצד לחבר מערך נתונים שכבר נוקה לתהליכים הבאים.
להלן דוגמאות פשוטות. המטרה אינה לכסות כל מקרה, אלא להמחיש לך את ההיגיון הבסיסי: פתיחת הקובץ, איתור צומת, הדפסת ערך.
import xml.etree.ElementTree as ETtree = ET.parse("fattura.xml")root = tree.getroot()numero = root.find(".//Numero")if numero is not None:print(numero.text)Python היא לרוב הבחירה המהירה ביותר ליצירת אב טיפוס, עיבוד נתונים וצינורות עיבוד קלים. היא מצוינת כאשר צריך לקרוא קבצי XML רבים, לחלץ שדות בודדים ולשמור אותם בפורמט CSV או JSON.
const xmlString = `<fattura><Numero>123</Numero></fattura>`;const parser = new DOMParser();const xmlDoc = parser.parseFromString(xmlString, "application/xml");const numero = xmlDoc.getElementsByTagName("Numero")[0];console.log(numero.textContent);גישה זו שימושית לבדיקות מהירות בדף או לכלי עבודה פנימיים קטנים. היא מתאימה לממשקים פשוטים, אך פחות מתאימה לתהליכים מובנים של מערך תפעולי.
const fs = require("fs");const xml2js = require("xml2js");const xml = fs.readFileSync("fattura.xml", "utf8");xml2js.parseString(xml, (err, result) => {if (err) throw err;console.log(result.fattura.Numero[0]);});אם אתה עובד בצד השרת ורוצה לבנות אוטומציות, Node.js נותרה בחירה מעשית. היתרון הוא היכולת לשלב בקלות את קריאת ה-XML עם מערכת הקבצים, תורי עיבוד ושירותים פנימיים.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse("fattura.xml");doc.getDocumentElement().normalize();NodeList lista = doc.getElementsByTagName("Numero");if (lista.getLength() > 0) {System.out.println(lista.item(0).getTextContent());}Java נפוצה לעתים קרובות בהקשרים ארגוניים, במערכות ניהול ובתוכנות ביניים. כאן, הנקודה המרכזית אינה רק קריאת הנתונים, אלא ביצוע פעולה זו באופן צפוי וניתן לתחזוקה.
library(XML)doc <- xmlParse("fattura.xml")numero <- xpathSApply(doc, "//Numero", xmlValue)print(numero)R מתאים כאשר ניתוח התחבירי הוא חלק מעבודה אנליטית. אם השלב הבא שלך הוא ניתוח סטטיסטי או הכנת נתונים, תוכל לבצע את הכל באותה סביבה.
אם הצוות שלך פותח את אותם קבצים מדי שבוע ומבצע את אותן בדיקות שוב ושוב, אתה כבר נמצא בתחום האוטומציה.
הרווח האמיתי אינו "קריאת XML באמצעות קוד". הוא לשחרר את האנשים מעבודה מכנית ולבנות תהליך המייצר מערכי נתונים עקביים.
הבעיות הרציניות מתחילות כאשר הקובץ כבר אינו קובץ בודד. כמעט תמיד ניתן לטפל בחשבונית FatturaPA אחת. הקושי מתעורר כאשר יש לאחד מסמכים של חודשים רבים, ספקים שונים, שדות שמולאו באופן לא אחיד וקבצים מצורפים.
בחברות קטנות ובינוניות (SME) באיטליה, המקרה הנפוץ ביותר אינו "קובץ ענק" בודד, אלא אצווה. ייצוא שנתי של חשבוניות ספקים עשוי ליצור מבנה המכיל למעלה מ-380,000 צמתים ב-4,200 חשבוניות, הכוללים כותרות, שורות פירוט, נתוני תשלום וקבצים מצורפים ב-base64. בתרחישים אלה, הבעיה אינה פתיחת המסמך, אלא הפיכת קבצי XML הטרוגניים למאגר נתונים עקבי.
כאן נכנסת לתמונה בחירה טכנית שיש לה השלכות עסקיות. בסביבת .NET, מיקרוסופט מציינת כי XmlDocument טוען את המסמך לזיכרון והוא שימושי לקריאה ולשינוי, בעוד שבמקרה של קבצים גדולים או פעולות לקריאה בלבד, מומלץ לפנות לגישות יעילות יותר כגון מפרש זרם (streaming parser) או XPathDocument, כדי למנוע צריכת RAM מוגזמת, כפי שמפורט בתיעוד של מיקרוסופט בנושא קריאת XML באמצעות XmlDocument ו-XPathDocument.
בפועל:
הפשרה פשוטה. המודל בזיכרון מאפשר פיתוח מהיר יותר. המודל הזורם מתפקד טוב יותר בסביבת ייצור כאשר מספר הקבצים גדל או כשהם כבדים.
צוותים רבים מסתפקים באימות XSD. זה מועיל, אך לא מספיק. קובץ יכול לעמוד בדרישות הסכימה ובכל זאת לייצר נתונים פגומים בשלבים הבאים.
דוגמאות אופייניות מהעבודה השוטפת:
| סוג הבדיקה | מה הוא בודק | למה זה נחוץ |
|---|---|---|
| מבני | תגיות, פורמט, היררכיה | הימנעו משגיאות ניתוח תחבירי |
| סמנטי | עקביות לוגית של הנתונים | הימנעי מניתוחים שגויים |
| פעיל | נוכחות שדות שימושיים לדיווח | הימנעו ממאגרי נתונים שאינם שמישים |
המקרה הערמומי ביותר הוא זה: "סכום כולל המסמך" תקין מבחינה פורמלית אך אינו עולה בקנה אחד עם סכום השורות, אולי בשל כללי עיגול במערכת הניהול של הספק. או קודי מע"מ המותרים מבחינה פורמלית אך אינם עולים בקנה אחד עם אופי העסקה.
קובץ שנראה תקין מבחינה פורמלית עלול בכל זאת לפגוע בדיוק הדיווחים שלך.
ישנה עוד מלכודת ידועה ב-FatturaPA. התג DatiBeniServizi מכיל תיאורים חופשיים. אותה עלות עשויה להופיע בדרכים רבות ושונות, עם טקסטים ברורים, מקוצרים או סתומים. אם לא תבצע שלב של נורמליזציה, כל ניתוח לפי קטגוריית הוצאות יהפוך לבלתי אמין.
לכן, בזרימות נתונים רציניות, קריאת הקובץ היא רק השלב הראשון. השלב השני הוא תמיד מערך של כללי עקביות וניקיון. שם נשמרת איכות הנתונים, ולא במנתח התחבירי.
קובץ XML שקראתם היטב עדיין אינו מהווה מערך נתונים שימושי. זהו מסמך מובנה. כדי לבצע ניתוחים, השוואות, קיבוץ נתונים ולוחות מחוונים, כמעט תמיד עליכם להמיר אותו לפורמט שקל יותר לעבד.
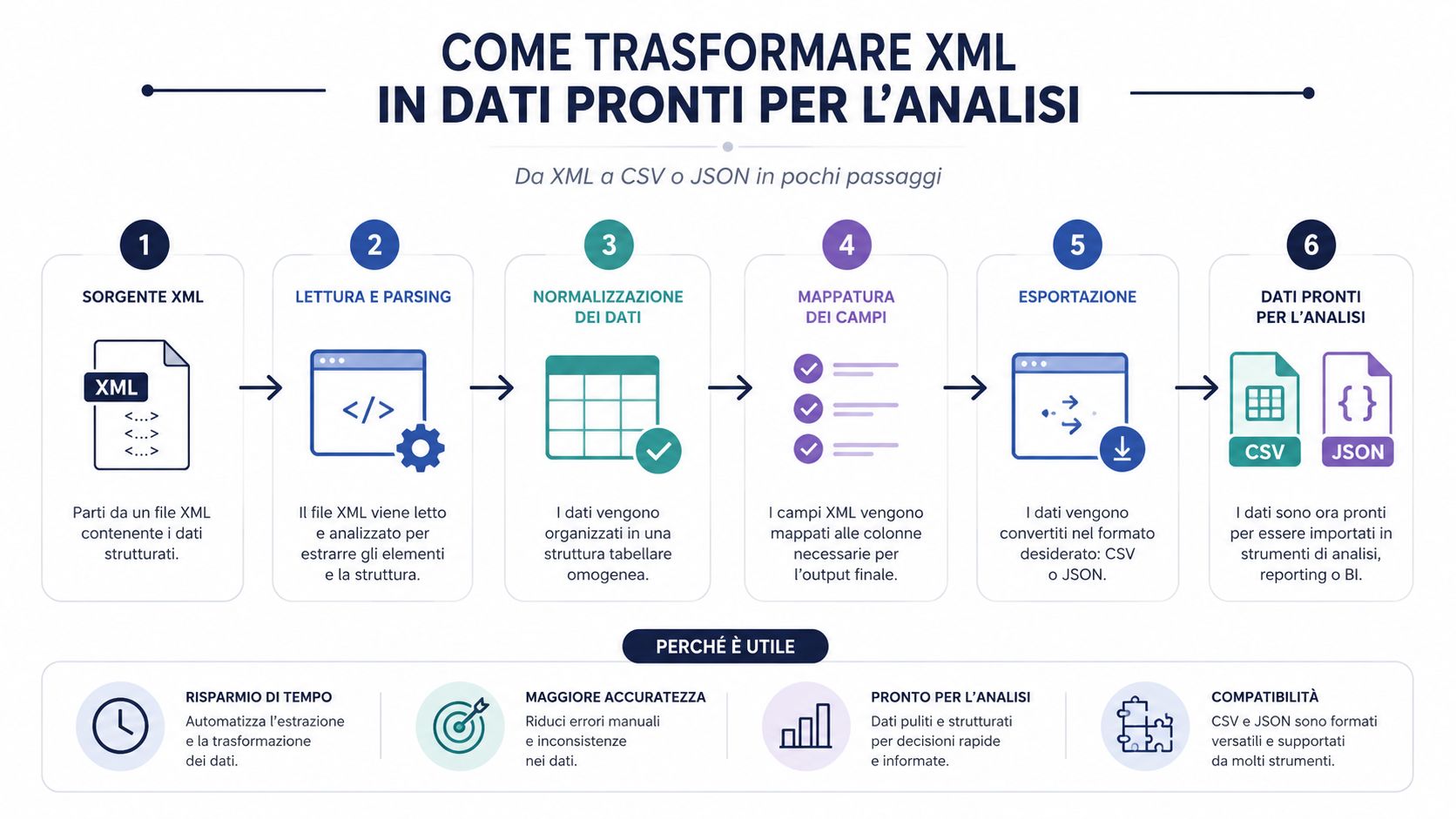
זהו הנקודה שרבים מהתהליכים נוטים לזלזל בה. צוואר הבקבוק הוא לעיתים רחוקות רק פעולת ה-parsing עצמה. ספרייה טובה קוראת קובץ XML במהירות. הזמן מתבזבז על פענוח המבנה, חילוץ השדות הרלוונטיים, ניקוי הנתונים, נורמליזציה והעלאתם לכלי ניתוח.
לכן, ההמרה לקובץ CSV או JSON אינה רק עניין של נוחות. זהו שלב תפעולי מרכזי. אם מדלגים על שלב זה ועובדים ישירות על הקובץ הגולמי, כמעט תמיד נאלצים לבצע בדיקות ידניות, ליצור עמודות מאולתרות ולהשתמש בלוגיקה שקשה לשחזר.
מדריך זה, המסביר כיצד לעבור מ-XML ל-Excel בצורה מסודרת יותר, מהווה מקור מידע שימושי למי שעובד לעתים קרובות עם קבצי XML וגיליונות אלקטרוניים.
הפורמט המתאים תלוי באופן שבו תשתמש בנתונים בהמשך.
CSV מתאים במיוחד כאשר אתה רוצה שורה אחת לכל מסמך, או שורה אחת לכל פרט בחשבונית, ולאחר מכן להשתמש ב-Excel, ב-Power Query או ב-BI.
דוגמה ב-Python:
import xml.etree.ElementTree as ETimport csvtree = ET.parse("fattura.xml")root = tree.getroot()with open("fatture.csv", "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(["numero", "data"])numero = root.findtext(".//Numero")data = root.findtext(".//Data")writer.writerow([numero, data])היתרון הוא הפשטות. המגבלה היא שעליך להחליט היטב כיצד לשטח את ההיררכיה. אם לחשבונית יש מספר שורות פירוט, יש לקבל החלטה ברורה לגבי רמת הפירוט ומפתח הקישור.
JSON מתאים יותר כאשר ברצונך לשמור על חלק מהמבנה ההיררכי.
דוגמה ב-JavaScript:
const record = {numero: "123",data: "2024-01-15",righe: [{ descrizione: "Servizio", importo: "100.00" }]};console.log(JSON.stringify(record, null, 2));השתמש בזה כאשר השלב הבא שלך הוא ממשק API, מאגר נתונים או יישום שמתאים לעבודה עם אובייקטים מקוננים.
הנה כלל מעשי שיעזור לכם:
קובץ ה-XML הוא המכל. CSV ו-JSON הם הפורמטים שהופכים את התוכן לניתן לעיבוד בפועל.
אם ברצונך לקצר את זמן ההגעה לתובנות, זהו המקום שבו כדאי להשקיע מאמץ. לא בחיפוש אחר כלי הצגה נוח יותר, אלא בהגדרת תהליך עיבוד יציב וניתן לשחזור.
ברגע שהקובץ נקרא, אומת והומר, אופי העבודה משתנה. אתה כבר לא מתמודד עם התגים. סוף סוף אתה מתמקד בעלויות, בחריגות, בספקים, בקטגוריות הוצאות ובמגמות תפעוליות.
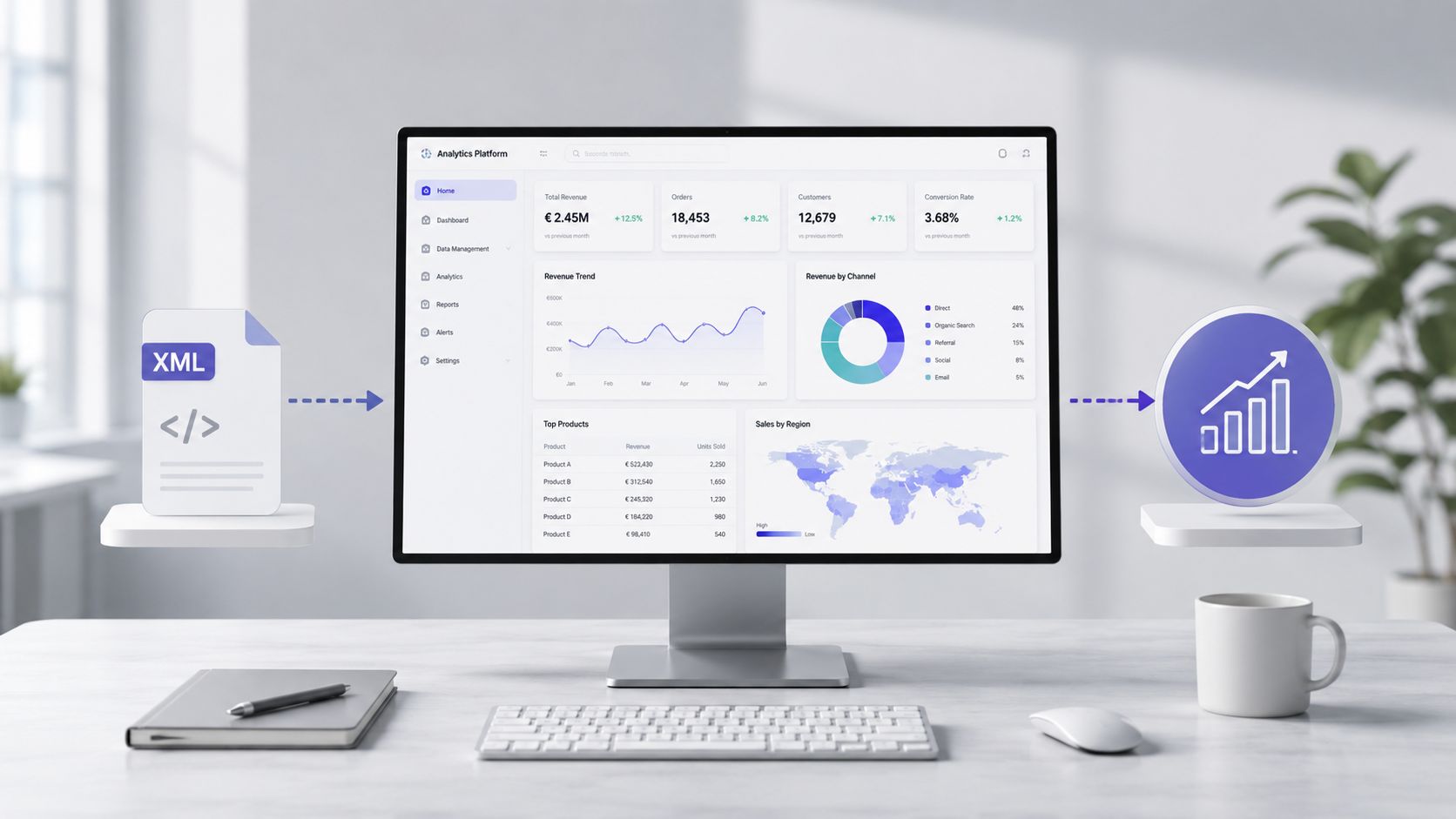
בעבודה בפועל, הערך אינו טמון בזמן הניתוח. הוא טמון בזמן שחלף בין הקובץ הגולמי למידע שעליו ניתן לקבל החלטה. בתהליך ידני, על האדם לפתוח את המסמך, להבין את המבנה שלו, לחלץ את השדות, לנקות את הערכים, לנרמל את הטקסטים ורק אז לבנות דוחות. זהו תהליך רגיש.
דוגמה קלאסית ב-FatturaPA היא הטקסט החופשי ב-DatiBeniServizi. אותו שירות יכול להיות מתואר בדרכים רבות ושונות על ידי ספקים שונים. אם מייבאים נתונים אלה ללא מיפוי עקבי, הניתוח לפי קטגוריית עלויות יניב צבירות מיותרות.
לכן, לפני הפלטפורמה האנליטית, יש צורך בשכבת הכנה, שכן:
כאשר שלב זה מבוצע כהלכה, כל פלטפורמת ניתוח נתונים פועלת טוב יותר. אם ברצונך להעמיק בהיבטים הקשורים לקבלת החלטות ולהצגה הוויזואלית של שלב זה, המדריך בנושא בניית סיפורים באמצעות נתונים עשוי להועיל לך, שכן הוא מדגים כיצד מערך נתונים מסודר הופך לנרטיב שימושי עבור מקבלי ההחלטות.
בשלב זה, קובץ ה-XML מפסיק להיות בעיה טכנית והופך לחומר גלם להפקת תובנות. מאגר נתונים שהוכן כהלכה יכול לשמש כבסיס לניתוח הוצאות, מעקב אחר מגמות, זיהוי סטיות וניתוח חריגות.
כדי לבחור פלטפורמה המתאימה ל"מייל האחרון" הזה, ייתכן שתמצא תועלת בהשוואת מה שמציעה תוכנת ניתוח עסקי מודרנית לעומת תהליכים ידניים גרידא המבוססים על גיליונות אלקטרוניים וטבלאות פיבוט.
הקריטריון הנכון כאן אינו "האם הוא יודע לפתוח קבצי XML?". זה המינימום. השאלה הרלוונטית היא אחרת:
| שאלה | למה זה חשוב |
|---|---|
| הנתונים נכנסים כבר לאחר ניקוי | הימנע מתובנות מדויקות המבוססות על נתונים שגויים |
| הקטגוריות עקביות | האם אתה באמת משווה בין ספקים ובין תקופות? |
| החריגות מתגלות מיד | צמצם את הזמן המבוזבז על בדיקות ידניות |
| הדו"ח מובן לאנשי עסקים ולמומחים בתחום הפיננסי | מאיץ את תהליך קבלת ההחלטות |
ההבדל בין תהליך לא מפותח לתהליך מפותח אינו טמון ביכולת לקרוא קבצי XML. הוא טמון ביכולת להפוך אותם למסד נתונים אמין, שלא יאלץ את הצוות לבצע את אותה העבודה מחדש בכל פעם.
אם אתה צריך לקרוא קבצי XML באופן שימושי לעסק, זכור את רשימת הבדיקה הזו. היא מעשית יותר מכל הגדרה טכנית ותעזור לך לבחור את השיטה הנכונה מבלי לבזבז זמן.
אל תשתמש תמיד באותה שיטה. דפדפנים, עורכים ותוכנות הצגה מתאימים לבדיקות מהירות. מפרסים וסקריפטים נדרשים כאשר הקובץ אמור להזין תהליכים חוזרים. אם תבלבל בין הצגת הנתונים לעיבודם, אתה עלול לבנות דוחות על בסיס רעוע.
הקבצים .xml.p7m מחייבים שלב ספציפי בניהול החתימה. אם התוכן מגיע מ-PEC, בדיקה זו אינה משנית. היא מהווה חלק מקריאה נכונה של המסמך.
עמידה בתבנית אינה מבטיחה מאגר נתונים תקין. חוסר עקביות לוגי, כגון סכומים שאינם תואמים או סיווגים פיסקליים מעורפלים, הוא הגורם השכיח ביותר לפגיעה בניתוח. הבדיקה הסמנטית היא זו שמבדילה בין קובץ "מקובל" לנתונים אמינים.
CSV ו-JSON אינם רק שינוי קוסמטי. הם מה שהופך את ה-XML למתאים לעיבוד על ידי כלי ניתוח, גיליונות אלקטרוניים, צינורות נתונים ודוחות. ככל שתגדיר את ההמרה הזו מוקדם יותר, כך תצמצם את העבודה הידנית ואת הצורך באלתורים.
המטרה שלך אינה לקרוא קבצי XML. המטרה היא להפיק תובנות מועילות מבלי לזהם את המערכת בנתונים לא נקיים. אם הזרם אינו מייצר מערך נתונים עקבי, הבעיה אינה נמצאת בלוח המחוונים הסופי. היא נמצאת הרבה יותר במעלה הזרם.
בפועל, תוכל להשתמש ברשימת הבדיקה הקצרה הזו לפני כל פרויקט חדש:
אם ברצונך להפוך נתונים מוכנים לתובנות ברורות וניתנות ליישום, ELECTE מסייעת לחברות קטנות ובינוניות לעבור ממאגר נתונים מסודר לדיווח חכם, באמצעות גישה הנגישה גם לצוותים שאינם טכניים. זוהי הדרך המהירה ביותר לצמצם את הפער בין נתונים תפעוליים לתהליך קבלת ההחלטות.

.svg)
.svg)
.svg)
.webp)





