

הנתונים שלך כבר מספרים סיפור. הבעיה היא שלעתים קרובות הם מדברים בשקט מדי.
מדי יום צוברת חברה קטנה ובינונית משוב מלקוחות, הזמנות, כרטיסי תמיכה, תנועות פיננסיות, מיילים עסקיים והערות CRM. כל החומר הזה מכיל סימנים מועילים. חלקם מצביעים על לקוח שעומד לעזוב. אחרים מבשרים על סיכון תפעולי. ואחרים מראים אילו מוצרים עומדים לצבור תאוצה או להאט. אך ללא שיטה ברורה, הסימנים הללו נותרים רק רעש.
בין האלגוריתמים המסייעים להביא סדר לתוך הכאוס הזה, למסווגים הבייסיאניים התמימים יש מקום מיוחד. הם קלים להבנה מבחינה לוגית, מהירים לאימון ולעתים קרובות יעילים יותר ממה שהשם "תמים" מרמז. הם אינם הבחירה הנכונה לכל תרחיש, אך בבעיות עסקיות רבות וממשיות הם מציעים איזון נדיר בין מהירות, פרשנות ותוצאות שימושיות.
אם אתה עובד בתחום העסקי, אין צורך שתהפוך לחוקר כדי להבין אותם. אתה צריך לדעת מה הם עושים, מדוע הם פועלים היטב גם כשהם מפשטים מאוד את המציאות, ובאילו מקרים הם יכולים לעזור לך לקבל החלטות טובות יותר. בדיוק בנקודה זו כדאי לעצור ולחשוב.
חברות רבות מחפשות מודלים מתוחכמים, בעוד שהבעיה דורשת, בראש ובראשונה, מודל אמין וקל לשימוש. זו אותה הסיבה שבגללה בתחום הפיננסי, הקמעונאות או שירות הלקוחות, לרוב זוכה התהליך הברור יותר, ולא זה שנחשב אלגנטי יותר מבחינה תיאורטית.
מסווגים בייסיאניים נאיביים מבוססים על רעיון מאוד קונקרטי. אם יש לך כמה רמזים לגבי מקרה חדש, תוכל להעריך לאיזו קטגוריה הוא שייך בסבירות גבוהה. אם דוא"ל מכיל מילים מסוימות, ייתכן שמדובר בספאם. אם לעסקה יש דפוסים מסוימים, ייתכן שיש לבדוק אותה. אם ביקורת משתמשת במונחים מסוימים, הדבר עשוי להצביע על שביעות רצון או על חוסר שביעות רצון.
המילה "בייסיאני" מעלה אסוציאציות של נוסחאות מורכבות. אך למעשה, הליבה של השיטה היא אינטואיטיבית. לוקחים את מה שכבר ידוע, מוסיפים ראיות חדשות ומעדכנים את ההערכה. זוהי דרך מסודרת להסיק מסקנות במצב של אי-ודאות, בדיוק מה שמנהלים עושים מדי יום, רק שהפעם התהליך נעשה באופן שיטתי באמצעות אלגוריתם.
מה שמפתיע הוא שגישה זו ממשיכה לתפקד היטב גם בסביבות מודרניות, שבהן יש כמויות אדירות של נתונים והחלטות מהירות. לא משום שהיא מתארת את העולם בצורה מושלמת, אלא משום שהיא מפרידה בין האות המועיל לרעש בעלות חישובית נמוכה מאוד.
בבעיות עסקיות, השאלה הנכונה אינה "מהו המודל המתוחכם ביותר?", אלא "איזה מודל מספק לי החלטות אמינות בזמן המתאים לעבודה בפועל?".
לכן, מסווגים בייסיאניים נאיביים נותרים חשובים. הם עוזרים לך לסווג, לסנן, לפלח ולקבוע סדרי עדיפויות. והם מאפשרים לך לשלב את ההסתברות בתהליך קבלת ההחלטות מבלי להפוך כל פרויקט לאתר בנייה טכני.
העיקרון הבסיסי הוא משפט בייס. בפשטות, הוא אומר כך: מתחילים מהסתברות ראשונית, ואז מעדכנים אותה עם קבלת מידע חדש.
בשפת הנתונים, הנוסחה נכתבת כך: P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y). משמעות הדבר היא שההסתברות לקיומה של קטגוריה נתונה, בהתחשב במערך של סימנים, תלויה בשני גורמים. הגורם הראשון הוא ההסתברות הראשונית לקיומה של הקטגוריה. הגורם השני הוא מידת ההתאמה של כל סימן לאותה קטגוריה.
הנה דוגמה מתחום העסקים. עליך להבין אם דוא"ל מסוים הוא דואר זבל או לא. יש לך הערכה כללית לגבי הסיכוי שדוא"ל נכנס הוא דואר זבל. לאחר מכן, אתה בוחן מילים מסוימות כמו "מבצע", "בחינם" או "לחץ כאן". כל אחת מהמילים הללו משפיעה על ההחלטה הסופית.
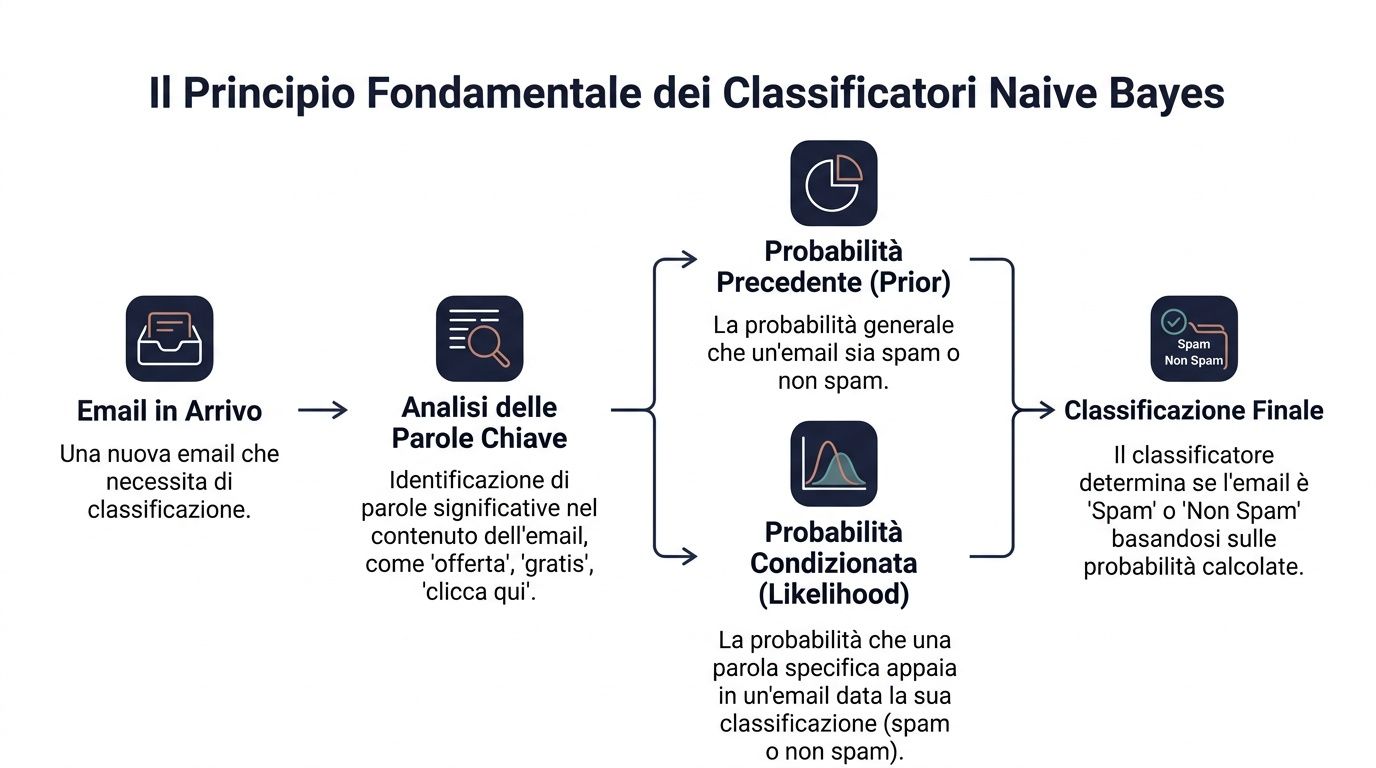
מנהל עושה דבר דומה מדי יום. הוא לעולם לא מקבל החלטות בחלל ריק. הוא יוצא מנקודת מוצא בסיסית ומוסיף רמזים. ללקוח שרכש באופן קבוע יש פרופיל התחלתי מסוים. אם הוא מפסיק לפתוח את המיילים, מקטין את שווי ההזמנות ופותח פנייה קריטית, הערכתך לגביו משתנה.
המונח "נאיבי" מתייחס להנחה ספציפית. המודל מתייחס לתכונות כאילו הן בלתי תלויות זו בזו, מאחר שהקטגוריה ידועה.
בפועל, כשאתה מסווג דוא"ל, התייחס לכל מילה כאל רמז נפרד. אל תנסה למדל את כל הקשרים המורכבים בין המונחים. זוהי הפשטה משמעותית. במציאות, מילים רבות מופיעות יחד, וקיימים קשרים בין התנהגויות עסקיות רבות.
ואולם, דווקא בחירה זו היא שהופכת את המודל לקל מאוד. הוא אינו נדרש ללמוד רשת מורכבת של תלות. הוא נדרש להעריך הסתברויות פשוטות יותר ולשלב ביניהן ביעילות.
כלל אצבע: אלגוריתם Naive Bayes אינו מנסה לשחזר את העולם כולו. הוא מנסה לקבל החלטות מועילות על סמך הנחות מועטות ובמהירות רבה.
כאן נוצרת לעתים קרובות אי-הבנה. רבים קוראים את המונח "הנחה נאיבית" ומסיקים שמדובר ב"מודל חלש". זה לא המצב. מודל יכול לפשט מאוד את הדברים ולהישאר תחרותי, אם הפישוט קולט את מה שחשוב לתהליך קבלת ההחלטות.
בשנת 2004, ניתוח תיאורטי הצביע על סיבות מוצקות ליעילותם של מסווגים מסוג Naive Bayes, למרות ההנחה בדבר עצמאות, והסביר גם מדוע הם יכולים להגיע לשגיאה אסימפטוטית מהר יותר מאשר רגרסיה לוגית. באותו תחום יישומים, בסינון דואר זבל הם מגיעים לדיוק של מעל 99% ומסוגלים לטפל במיליוני מסמכים, כפי שמפורט בערך המוקדש למסווגים מסוג Naive Bayes.
נקודה זו חשובה לקהל העסקי. הערך של אלגוריתם אינו טמון רק בציון הסופי. הוא טמון גם ביכולתו ללמוד במהירות, להסתגל למאגרי נתונים נרחבים ולהישאר מובן.
כאשר יש לך טקסטים, קטגוריות, תגיות או סימנים מפוזרים, מסווגים בייסיאניים נאיביים פועלים היטב מכיוון ש:
יש, עם זאת, שני דברים שכדאי לזכור.
מסיבה זו יש לראות ב-Naive Bayes כלי יעיל מאוד בבעיות סיווג מהירות, ולא כפתרון קסם אוניברסלי. עם זאת, בהקשרים מעשיים רבים, זוהי אחת הדרכים החכמות ביותר להתחיל.
טעות נפוצה היא לדבר על Naive Bayes כאילו מדובר במודל אחד זהה בכל מצב. בפועל, קיימות גרסאות שונות, שנועדו לסוגי נתונים שונים.
הבחירה הנכונה תלויה במבנה הנתונים שברשותך. אם תבחר בגרסה הלא נכונה, המודל עדיין יוכל לייצר תחזית, אך הוא לא יפעל באופן המתאים ביותר לבעיה שלך.
מודל Gaussian Naive Bayes הוא המתאים ביותר כאשר המאפיינים הם רציפים. דוגמאות לכך הן סכום ממוצע של עסקה, גיל הלקוח, הזמן הממוצע בין שתי רכישות, רווח ליחידה או סכום הקבלה.
המודל מניח כאן כי בתוך כל קטגוריה, הערכים מצייתים להתפלגות גאוסיאנית. אין צורך להתייחס לכך כאל אילוץ תיאורטי. די אם תזכור את הרעיון המעשי: עבור כל קטגוריה, המודל מעריך מרכז טיפוסי ופיזור.
גישה זו מועילה כאשר ברצונך לסווג מקרים כגון:
בבדיקת ביצועים של scikit-learn עם מאגר נתונים הדומה לנתוני מסחר אלקטרוני איטלקיים, מודל Naive Bayes הגיע לדיוק של 95% עם 1,000 דוגמאות, תוך זמן אימון שהיה מהיר ב-15% מזה של רגרסיה לוגית . ההשוואה המוצגת היא 0.01 שניות לעומת 0.1 שניות על מעבד סטנדרטי, הודות לאימון בסגנון סגור, כפי שמוצג בפרק של ג'ייק ונדרפלאס על In Depth Naive Bayes Classification.
עבור חברה, העניין אינו בספרה אחרי הנקודה העשרונית. העניין הוא שגרסה זו יכולה להניב תוצאות טובות ללא צורך בהכשרה ממושכת וללא תשתית כבדה.
אם אתה עובד עם טקסטים, כרטיסי תמיכה, ביקורות או תגובות, מודל Multinomial Naive Bayes הוא לרוב הבחירה הטבעית. במקרה זה, המאפיינים הם ספירות או תדירות. למעשה, המודל בוחן כמה פעמים מילים או מונחים מופיעים.
זהו התרחיש הקלאסי של:
הסיבה לכך שזה עובד היטב היא מאוד קונקרטית. בטקסטים עסקיים אוצר המילים עשוי להיות רחב, אך כל מסמך מכיל רק חלק קטן מהמילים האפשריות. הנתונים מפוזרים. מודל Multinomial Naive Bayes מתמודד היטב דווקא עם מבנה מסוג זה.
במחקר שנערך על 100,000 ציוצים איטלקיים שסווגו לפי סנטימנט, מודל Multinomial Naive Bayes השיג ציון F1 של 0.88 עם מהירות גבוהה פי 10 בהשוואה ל-SVM, כפי שדווח במדריך של GeeksforGeeks על מסווגים מסוג Naive Bayes.
כדי לזכור זאת בקלות, חשבו כך: אם הנתונים שלכם דומים למסמך מלא במילים שנספרו, המודל הרב-נומינלי הוא כמעט תמיד האפשרות הראשונה שכדאי לבדוק.
אם החברה שלך צריכה לקרוא כמויות גדולות של טקסט, השאלה היא לא רק "עד כמה המודל מדויק?". היא גם "כמה בקשות הוא מצליח לסווג מבלי להאט את קצב העבודה של הצוות?".
מודל ברנולי-נייטיב בייס עובד עם מאפיינים בינאריים. הוא אינו מתייחס למספר הפעמים שהסימן מופיע, אלא רק לנוכחותו או להיעדרותו.
גרסה זו שימושית כאשר חשיבותו של תכונה מסוימת עולה על תדירות הופעתה. כמה דוגמאות מהעולם העסקי:
זוהי גישה שימושית מאוד כאשר רוצים להפוך תופעות מורכבות למדדים של "כן" או "לא" שקל לעקוב אחריהם. בניתוח סנטימנט, למשל, ייתכן שהעובדה שמילה שלילית מופיעה תהיה משמעותית יותר מאשר מספר הפעמים שהיא חוזרת על עצמה.
ברנולי אינו "פחות מתקדם" מהמודל המולטינומי. הוא פשוט מתאים יותר כאשר הנתונים מתארים נוכחות או היעדרות. ההבדל קטן במילים, אך גדול בתוצאות.
| גרסה | סוג הנתונים האידיאלי | דוגמה לשימוש עסקי |
|---|---|---|
| גאוס-נייבי בייס | נתונים רציפים | לסווג עסקאות לפי רמת סיכון באמצעות סכומים, תדירות וערכים ממוצעים |
| מודל Naive Bayes רב-נומינלי | טקסטים, חישובים, תדירות | לנתח ביקורות וכרטיסי שירות של לקוחות לפי סנטימנט או קטגוריה |
| ברנולי-נייבי בייס | נתונים בינאריים, נוכחות/היעדרות | הערכת סימנים של "כן" או "לא" בתחומי תאימות, תמיכה או שימוש במוצר |
כדי לבחור נכון, השתמש בכלל פשוט:
צוותים רבים נתקעים כי הם מחפשים את "המודל הטוב ביותר" המוחלט. הבחירה הנכונה, כמעט תמיד, היא המודל המתאים ביותר לסוג הנתונים.
החדשות הטובות הן שיישום Naive Bayes בפועל אינו מצריך פרויקט ענק. אפילו אב טיפוס ברור ומובן מאפשר כבר להבין כיצד המודל פועל ואילו נתונים הוא זקוק להם.

מערכת סיווג נוצרת כמעט תמיד בארבעה שלבים.
הכנת הנתונים
עליך לאסוף דוגמאות היסטוריות שכבר סומנו. אם אתה מסווג ביקורות, אתה זקוק לטקסטים שכבר סומנו כחיוביים או שליליים. אם אתה מנתח סיכונים תפעוליים, אתה זקוק למקרים מהעבר שתוצאותיהם ידועות.
אימון המודל ה-
המודל בוחן את הנתונים ומעריך את ההסתברויות הרלוונטיות. במסווגים ה-Naive Bayesian שלב זה מתבצע במהירות, מכיוון שהאימון אינו מצריך אופטימיזציות מורכבות במיוחד.
חיזוי מקרים חדשים
הזן רשומות חדשות והמודל יקצה להן קטגוריה. לדוגמה: "דואר זבל", "לא דואר זבל", "לקוח בסיכון", "לקוח יציב".
הערכת מודל "
": השוואת התחזיות למציאות על מערך בדיקה נפרד. כאן לא בודקים רק אם המודל פועל. בודקים כיצד הוא טועה.
אם ברצונך להעמיק את הידע הכללי שלך בנושא גישות חיזוי, סקירה זו על אלגוריתמי למידת מכונה תסייע לך למקם את Naive Bayes בתוך משפחה רחבה יותר של שיטות.
כדי להמחיש את התהליך, הנה דוגמה פשוטה עם scikit-learn. אין צורך לקרוא אותה כמו מפתח. מספיק להבין את זרימת העבודה.
# ייבוא הכלים העיקרייםfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# טעינת מערך נתונים לדוגמהX, y = load_iris(return_X_y=True)# נחלק את הנתונים לחלק לאימון וחלק לבדיקה X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# ניצור את המודל model = GaussianNB()# נלמד את המודל על הנתונים ההיסטוריים model.fit(X_train, y_train)# נבצע תחזיות על נתונים שלא ראינו מעולם y_pred = model.predict(X_test)# נמדוד את הדיוק print(accuracy_score(y_test, y_pred))קטע זה אומר הרבה יותר ממה שנראה לעין.
GaussianNB() בחר באפשרות המתאימה לנתונים רציפים.fit() זה הרגע שבו המודל לומד.predict() מיישם את מה שלמד.accuracy_score() בדוק כמה סיווגים נכונים בסך הכול.במקרה של נתונים טקסטואליים, התהליך דומה, אך לפני השימוש במודל עליך להמיר את הטקסט למספרים. למעשה, אתה ממיר את המילים לתכונות שניתן להשתמש בהן בממיין.
לאחר התבוננות ראשונית בקוד, ייתכן שיהיה מועיל לראות הסבר חזותי של המנגנון.
המודל הראשון אינו נועד להוכיח שלמות. הוא נועד לענות על שלוש שאלות מעשיות.
כאן ניתן לראות את עוצמתו של אלגוריתם Naive Bayes. ניתן להגיע במהירות לנקודת ייחוס איתנה. משם ניתן להבין אם יש טעם לסבך את הפרויקט, או שמא פתרון פשוט כבר מייצר ערך.
מודל סיווג לא נמדד רק על סמך העובדה שהוא "נראה כאילו הוא עובד". הוא נמדד לפי האופן שבו הוא טועה, ובמידת ההשפעה של טעויות אלה על העסק.

הדיוק הוא המדד האינטואיטיבי ביותר. הוא מציין כמה תחזיות נכונות מתוך הסך הכולל. הוא שימושי, אך כשלעצמו עלול להטעות.
אם מתוך מאה עסקאות רק מעטות הן באמת חשודות, מודל שמסווג כמעט הכל כרגיל עשוי להיראות טוב מבחינת הדיוק, אך להישאר לקוי דווקא במקום שבו הוא באמת נחוץ.
כדי להבין זאת, דמיין רשת דיג.
בעולם העסקים יש חשיבות רבה להבחנה זו.
מודל טוב אינו זה שטועה מעט באופן כללי. זהו המודל שטועה באופן הפחות יקר לתהליך שלך.
כדי להבין טוב יותר כיצד אלגוריתם לומד מנתונים היסטוריים ומדוע איכות האימון משפיעה על התוצאה הסופית, תוכל לקרוא את המאמר המפורט הזה על מהות אימון האלגוריתם.
מודל Naive Bayes הוא פשוט, אך אינו סלחני כלפי טעויות מעשיות מסוימות.
הטעות הראשונה: התעלמות מבעיית התדירות האפסית.
אם מילה או ערך מסוימים אינם מופיעים כלל בנתוני האימון עבור קטגוריה מסוימת, ההסתברות עלולה לצנוח לאפס ולפגוע בחישוב. לכן נעשה לעתים קרובות שימוש בשיטת ה-Laplace Smoothing, המוסיפה תיקון קטן לספירות.
הטעות השנייה: שימוש במאפיינים הקשורים זה לזה באופן הדוק.
אם שתי עמודות מספקות כמעט את אותה המידע, קיים סיכון שהמודל יעריך יתר על המידה את האות. הוא אינו "מבין" ששני הרמזים כמעט זהים.
טעות שלישית: הסתמכות יתר על הסתברויות גולמיות.
אלגוריתם Naive Bayes מסווג לעתים קרובות בצורה טובה, אך ההסתברויות שהוא מספק עלולות להיות ודאיות מדי. מבחינה עסקית, משמעות הדבר היא שהדירוג עשוי להיות שימושי, אך יש לפרש את הערך המדויק של ההסתברות בזהירות.
כדי לצמצם סיכונים אלה, מומלץ:
הערך האמיתי של מסווגים בייסיאניים נאיביים מתגלה כאשר מפסיקים להתייחס אליהם כאל תרגיל מתמטי ומתחילים להשתמש בהם כמנוע לקביעת סדרי עדיפויות. בארגון, סיווג נכון פירושו כמעט תמיד קבלת החלטות נבונה יותר.

דמיינו צוות פיננסי שמנתח תזרימי עסקאות, תיאורים תפעוליים וסימנים היסטוריים. כל שורה היא לא רק רשומה. היא החלטה פוטנציאלית: לאשר, לבדוק לעומק, לחסום או להעביר לאנליסט.
באמצעות Naive Bayes ניתן לשלב אינדיקטורים שונים בסיווג אחד. חלקם מספריים, חלקם בינאריים וחלקם טקסטואליים. המודל מסייע להבין אילו מקרים דומים ביותר לדפוסים שנצפו בעבר כנורמליים או חריגים.
היתרון המעשי הוא כפול:
הוא אינו מחליף את שיקול הדעת האנושי בהקשרים מוסדרים. הוא מארגן אותו. ובתהליכים תפעוליים בהיקף נרחב, הדבר עושה הבדל של ממש.
בשיווק, סיווג פירושו לעתים קרובות שיוך כל לקוח לקבוצת יעד. לקוחות נאמנים. רגישים למחיר. בסיכון לנטישה. מגיבים למבצעים. לקוחות רדומים.
במקרה זה, אלגוריתם Naive Bayes מועיל מכיוון שהוא מצליח לשלב סימנים מגוונים במהירות:
צוות CRM אינו זקוק לתיאוריה מושלמת של התנהגות אנושית. הוא זקוק לפילוח טוב מספיק כדי להניע פעולות הגיוניות. למשל, לשנות את המסר, את תדירות יצירת הקשר או את סוג ההצעה.
כאשר מודל מסייע בבחירת המסר הבא עבור הלקוח הנכון, הוא כבר מייצר ערך תפעולי.
בתחום הקמעונאות והמסחר האלקטרוני, הסיווג תומך בפעילויות שנראות שונות אך מבוססות על אותה לוגיקה: סדר בתוך הכאוס.
ניתן לסווג מוצרים על פי פרופיל המכירות שלהם. ניתן לקרוא ביקורות ודיווחים כדי להבין אילו קטגוריות גורמות לבעיות. ניתן לזהות דפוסי ביקוש שיעזרו לצוות לתכנן מבצעים ומלאי בצורה מושכלת יותר.
בסוג כזה של סביבה, הנתונים לרוב רבים, מגוונים ולא תמיד מושלמים. לכן, למודל מהיר, ניתן להרחבה וקריא יש ערך רב. לא כי הוא הכי נוצץ, אלא כי הוא משתלב בתהליך העבודה מבלי להאט אותו.
אם ברצונך לראות כיצד גישות אנליטיות המיועדות לעולם העסקי מתממשות בפרויקטים קונקרטיים, תוכל לעיין במקרי המבחן הבאים.
הבנת מודל Naive Bayes היא דבר מועיל. יישום נכון שלו בסביבה ארגונית הוא כבר סיפור אחר.
הבעיה כמעט אף פעם אינה רק האלגוריתם. העבודה האמיתית מתמקדת במודל. עליך לחבר מקורות נתונים שונים, לטפל בשדות חסרים, להכין טקסטים, לעדכן תוויות, לבדוק את איכות התפוקות, ולפרש את התוצאות באופן שיהיה מובן למקבלי ההחלטות.
עבור חברה קטנה ובינונית, שלב זה הוא לרוב נקודת המבחן. לא משום שאין עניין ב-AI, אלא משום שזמנו של הצוות מוגבל והעדיפויות התפעוליות אינן סובלות דיחוי.
במקרה זה, כדאי להשתמש בפלטפורמה שמטפלת במורכבות הטכנית. פתרון מבוסס בינה מלאכותית מאפשר להפוך נתונים גולמיים לתובנות ברורות, מבלי לדרוש מהעסק לכתוב קוד, לבחור ספריות או לתחזק צינורות עיבוד ידניים.
פלטפורמה כמו ELECTE, פלטפורמת ניתוח נתונים מבוססת בינה מלאכותית המיועדת לעסקים קטנים ובינוניים, מאפשרת גישה לשיטות כגון מסווגים בייסיאניים נאיביים, מבלי לדרוש ידע מומחה בתחום למידת מכונה. היתרון אינו רק במהירות. הוא טמון בצמצום החיכוך שבין הנתונים להחלטה.
כאשר האוטומציה פועלת כראוי, הצוות כבר לא חושב במונחים של נוסחאות. הוא חושב במונחים של שאלות מועילות:
זו גם הסיבה לכך שיותר ויותר חברות מחפשות כלים שיסייעו להן להעריך את אמינות התכנים שנוצרו על ידי בינה מלאכותית ואת הרמזים הטקסטואליים המופיעים בתהליכים הפנימיים. בהקשר זה, ייתכן שיהיה מועיל להיעזר במדריך בנושא גלאי בינה מלאכותית באיטלקית, במיוחד אם הצוות שלכם עוסק במסמכים, בתכנים ובבדיקות לשוניות.
ההבדל, למעשה, הוא פשוט. במקום להתעסק בפרטים טכניים מקוטעים, אתה ממקד את תשומת הלב בתוצאות העסקיות. וזהו הרגע שבו הבינה המלאכותית הופכת לממש ישימה, ולא רק למעניינת.
מסווגים בייסיאניים נאיביים ממחישים לקח חשוב. בתחום הניתוח, פשטות המיושמת כהלכה עשויה להתעלות על מורכבות המנוהלת בצורה לקויה.
בזכות בסיס הסתברותי אינטואיטיבי, יכולת הרחבה טובה ושימושים מעשיים מאוד, גישה זו נותרת כלי אמין עבור חברות המעוניינות לסווג מידע, לזהות סימנים נסתרים ולפעול בביטחון רב יותר. אין צורך להיות מומחים בלמידת מכונה כדי להבין את ערכן. יש צורך לקשר בין המתמטיקה להחלטות התפעוליות.
כאשר הקשר הזה מתבהר, הבינה המלאכותית מפסיקה להיות נושא טכני והופכת ליתרון ארגוני. זה הרגע שבו התחזיות מתחילות להשפיע.
אם ברצונך להפוך נתונים מפוזרים לתובנות ברורות, נסה ELECTE. הפלטפורמה מסייעת לעסקים קטנים ובינוניים לחבר בין מקורות נתונים, להפוך את הניתוח לאוטומטי ולקבל דוחות ותחזיות שימושיים לקבלת החלטות מהירות ומבוססות יותר.

.svg)
.svg)
.svg)






