

Data Anda sebenarnya sudah menceritakan sebuah kisah. Masalahnya, seringkali kisahnya terlalu pelan.
Setiap hari, sebuah UMKM mengumpulkan umpan balik pelanggan, pesanan, tiket layanan pelanggan, transaksi keuangan, email komersial, dan catatan CRM. Semua data ini mengandung sinyal-sinyal yang berguna. Beberapa di antaranya menandakan adanya pelanggan yang hampir berhenti berlangganan. Yang lain mengindikasikan adanya risiko operasional. Ada pula yang menunjukkan produk mana yang akan mengalami pertumbuhan pesat atau justru melambat. Namun, tanpa metode yang jelas, sinyal-sinyal tersebut hanya akan menjadi kebisingan belaka.
Di antara berbagai algoritma yang membantu menata kekacauan ini, klasifikasi Naive Bayesian memegang peranan khusus. Logikanya mudah dipahami, proses pelatihannya cepat, dan seringkali lebih efektif daripada yang disiratkan oleh sebutan “naive”. Meskipun tidak selalu menjadi pilihan yang tepat untuk setiap situasi, dalam banyak masalah bisnis nyata, algoritma ini menawarkan keseimbangan yang langka antara kecepatan, keterbacaan, dan hasil yang bermanfaat.
Jika Anda bekerja di bidang bisnis, Anda tidak perlu menjadi peneliti untuk memahaminya. Yang perlu Anda ketahui adalah apa yang mereka lakukan, mengapa mereka bisa berfungsi dengan baik meskipun menyederhanakan realitas secara drastis, dan dalam situasi apa saja mereka dapat membantu Anda mengambil keputusan yang lebih baik. Inilah tepatnya yang patut kita perhatikan.
Banyak perusahaan mencari model yang rumit, padahal masalah yang dihadapi sebenarnya membutuhkan, di atas segalanya, model yang andal dan mudah digunakan. Inilah alasan mengapa dalam bidang keuangan, ritel, atau layanan pelanggan, proses yang paling jelas sering kali lebih unggul daripada yang secara teoritis lebih canggih.
Klasifikasi Naive Bayesian didasarkan pada gagasan yang sangat konkret. Jika Anda memiliki beberapa petunjuk mengenai suatu kasus baru, Anda dapat memperkirakan kategori mana yang paling mungkin menjadi tempatnya. Jika sebuah email mengandung kata-kata tertentu, kemungkinan besar itu adalah spam. Jika suatu transaksi menunjukkan pola tertentu, mungkin perlu diperiksa. Jika sebuah ulasan menggunakan istilah-istilah tertentu, hal itu mungkin menandakan kepuasan atau ketidakpuasan.
Kata “Bayesian” sering dikaitkan dengan rumus-rumus yang rumit. Padahal, inti dari metode ini sebenarnya intuitif. Ambil apa yang sudah Anda ketahui, tambahkan bukti-bukti baru, lalu perbarui penilaian Anda. Ini adalah cara yang terstruktur untuk berpikir dalam kondisi ketidakpastian, persis seperti yang dilakukan para manajer setiap hari, hanya saja kini disistematisasikan melalui sebuah algoritma.
Yang mengejutkan adalah bahwa pendekatan ini tetap berfungsi dengan baik bahkan di lingkungan modern yang dipenuhi data dan pengambilan keputusan yang cepat. Bukan karena pendekatan ini menggambarkan dunia dengan sempurna, melainkan karena mampu memisahkan sinyal yang berguna dari gangguan dengan biaya komputasi yang sangat rendah.
Dalam masalah bisnis, pertanyaan yang tepat bukanlah “model mana yang paling canggih?”. Melainkan “model mana yang dapat memberikan keputusan yang dapat diandalkan dalam waktu yang sesuai dengan kondisi kerja nyata?”.
Oleh karena itu, klasifikasi Naive Bayesian tetap penting. Klasifikasi ini membantu Anda mengklasifikasikan, menyaring, menyegmentasikan, dan memprioritaskan. Selain itu, klasifikasi ini memungkinkan Anda memasukkan unsur probabilitas ke dalam proses pengambilan keputusan tanpa mengubah setiap proyek menjadi proyek teknis yang rumit.
Prinsip dasarnya adalah Teorema Bayes. Secara sederhana, teorema ini menyatakan: mulailah dengan probabilitas awal, lalu perbarui probabilitas tersebut ketika informasi baru tersedia.
Dalam terminologi data, rumus tersebut berbunyi sebagai berikut: P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y). Artinya, probabilitas suatu kelas berdasarkan sekumpulan sinyal bergantung pada dua faktor. Yang pertama adalah probabilitas awal kelas tersebut. Yang kedua adalah sejauh mana setiap sinyal sesuai dengan kelas tersebut.
Diterjemahkan ke dalam contoh bisnis. Anda harus menentukan apakah sebuah email merupakan spam atau bukan. Anda memiliki perkiraan umum bahwa email yang masuk tersebut adalah spam. Kemudian, Anda memeriksa beberapa kata seperti “penawaran”, “gratis”, “klik di sini”. Masing-masing kata tersebut memengaruhi penilaian akhir.
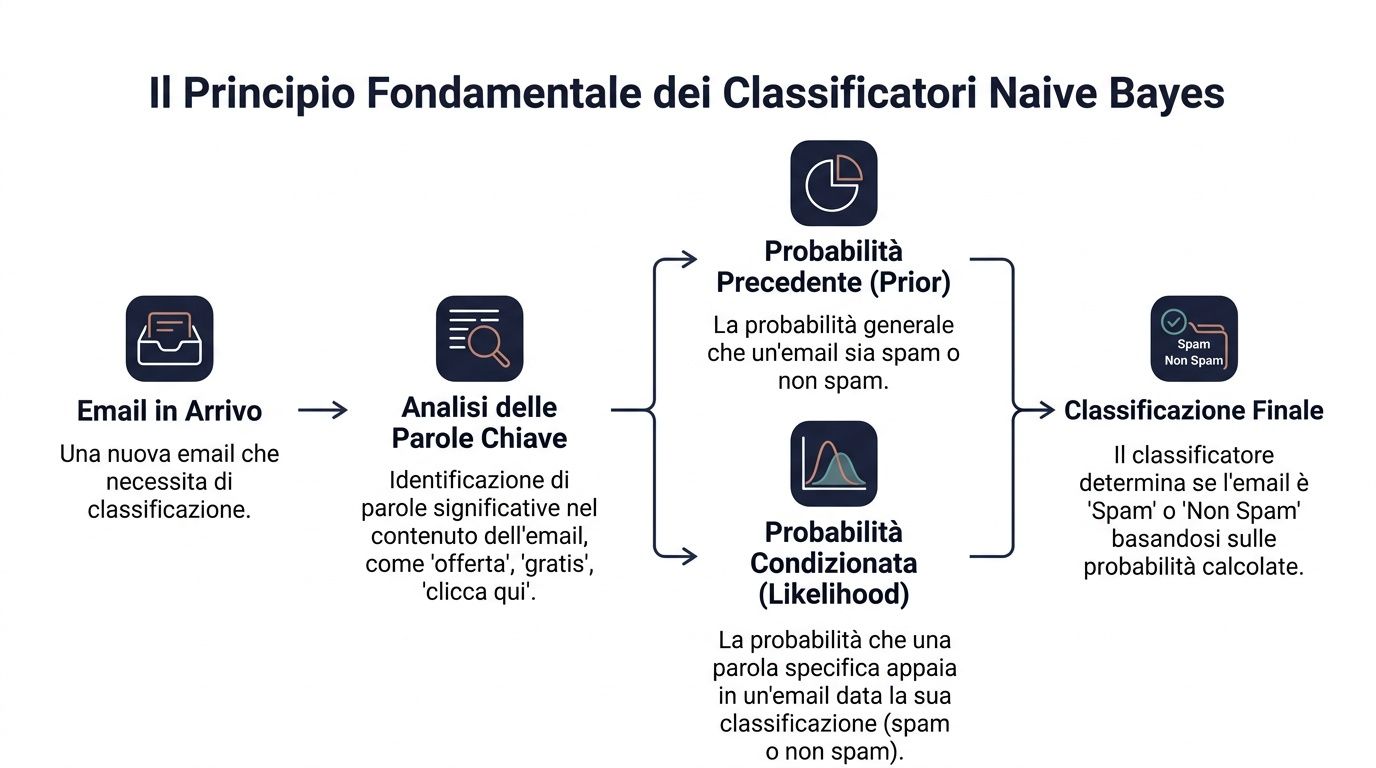
Seorang manajer melakukan hal serupa setiap hari. Ia tidak pernah mengambil keputusan tanpa dasar. Ia memulai dari konteks dasar dan menambahkan petunjuk-petunjuk. Seorang pelanggan yang selalu berbelanja secara teratur memiliki profil awal tertentu. Jika kemudian ia berhenti membuka email, mengurangi nilai pesanan, dan mengajukan tiket keluhan yang kritis, penilaian Anda pun berubah.
Istilah " naive" mengacu pada asumsi tertentu. Model ini memperlakukan fitur-fitur seolah-olah saling independen, karena kelasnya sudah diketahui.
Pada dasarnya, saat Anda mengklasifikasikan sebuah email, anggaplah setiap kata sebagai petunjuk tersendiri. Jangan mencoba memodelkan semua hubungan kompleks antaristilah. Ini adalah penyederhanaan yang sangat besar. Pada kenyataannya, banyak kata yang muncul bersamaan dan banyak perilaku bisnis yang saling terkait.
Namun, justru pilihan inilah yang membuat model tersebut sangat ringan. Model ini tidak perlu mempelajari jaringan ketergantungan yang rumit. Model ini hanya perlu memperkirakan probabilitas yang lebih sederhana dan menggabungkannya secara efisien.
Aturan praktis: Naive Bayes tidak berusaha merekonstruksi seluruh dunia. Model ini berusaha mengambil keputusan yang berguna dengan sedikit asumsi dan kecepatan yang tinggi.
Di sinilah sering kali muncul kesalahpahaman. Banyak orang membaca “asumsi naif” dan menyimpulkan bahwa itu adalah “model yang lemah”. Sebenarnya tidak demikian. Sebuah model dapat sangat menyederhanakan dan tetap kompetitif jika penyederhanaan tersebut menangkap hal-hal yang penting bagi proses pengambilan keputusan.
Pada tahun 2004, sebuah analisis teoretis menunjukkan alasan yang kuat mengenai keefektifan klasifikasi Naive Bayes meskipun didasarkan pada asumsi independensi, sekaligus menjelaskan mengapa klasifikasi ini dapat mencapai kesalahan asimtotik lebih cepat daripada regresi logistik. Dalam bidang aplikasi yang sama, yaitu penyaringan spam, klasifikasi ini mencapai akurasi lebih dari 99% dan dapat diterapkan pada jutaan dokumen, sebagaimana dijelaskan dalam entri yang membahas klasifikasi Naive Bayes.
Hal ini penting bagi audiens korporat. Nilai dari sebuah algoritma tidak hanya terletak pada skor akhir. Nilai tersebut juga terletak pada kemampuannya untuk dilatih dengan cepat, beradaptasi dengan kumpulan data yang besar, dan tetap dapat diinterpretasikan.
Ketika Anda memiliki teks, kategori, label, atau sinyal yang tersebar, klasifikasi Naive Bayesian bekerja dengan baik karena:
Namun, ada dua hal yang perlu diingat.
Oleh karena itu, Naive Bayes harus dipandang sebagai alat yang sangat efektif untuk masalah klasifikasi yang cepat, bukan sebagai solusi ajaib yang serba bisa. Namun, dalam banyak konteks praktis, ini merupakan salah satu cara paling cerdas untuk memulai.
Kesalahan umum yang sering terjadi adalah membicarakan Naive Bayes seolah-olah itu adalah satu model yang sama persis dalam setiap situasi. Pada kenyataannya, terdapat berbagai varian yang dirancang untuk jenis data yang berbeda-beda.
Pilihan yang tepat bergantung pada bentuk data yang Anda miliki. Jika Anda memilih varian yang salah, model tersebut tetap dapat menghasilkan prediksi, tetapi tidak memproses data dengan cara yang paling sesuai untuk masalah Anda.
Gaussian Naive Bayes adalah varian yang paling cocok jika fitur-fiturnya bersifat kontinu. Contohnya antara lain nilai rata-rata transaksi, usia pelanggan, waktu rata-rata antara dua pembelian, margin per unit, atau nilai struk.
Di sini, model ini mengasumsikan bahwa, di dalam setiap kelas, nilai-nilai tersebut mengikuti distribusi Gaussian. Jangan menganggapnya sebagai batasan akademis. Cukup ingat prinsip praktisnya: untuk setiap kelas, model ini memperkirakan nilai tengah dan simpangan baku.
Pendekatan ini berguna ketika Anda ingin mengklasifikasikan kasus-kasus seperti:
Pada benchmark scikit-learn dengan dataset yang mirip dengan data e-commerce Italia, model Naive Bayes mencapai akurasi 95% dengan 1.000 sampel, dengan waktu pelatihan yang 15% lebih cepat dibandingkan regresi logistik . Perbandingan yang ditunjukkan adalah 0,01 detik vs 0,1 detik pada CPU standar, berkat pelatihan tertutup, seperti yang ditunjukkan dalam bab karya Jake VanderPlas berjudul In Depth Naive Bayes Classification.
Bagi sebuah perusahaan, intinya bukanlah angka desimal. Intinya adalah bahwa varian ini dapat memberikan hasil yang baik tanpa memerlukan waktu pelatihan yang lama dan tanpa infrastruktur yang rumit.
Jika Anda bekerja dengan teks, tiket, ulasan, atau komentar, Multinomial Naive Bayes sering kali menjadi pilihan yang paling tepat. Di sini, fitur-fiturnya berupa jumlah atau frekuensi. Pada dasarnya, model ini melihat seberapa sering kata atau istilah tertentu muncul.
Ini adalah skenario klasik dari:
Alasan mengapa metode ini bekerja dengan baik sangatlah konkret. Dalam teks-teks bisnis, kosakata yang digunakan bisa sangat luas, tetapi setiap dokumen hanya mengandung sebagian kecil dari kata-kata yang mungkin ada. Data tersebut tersebar. Multinomial Naive Bayes mampu menangani struktur seperti ini dengan baik.
Dalam sebuah studi terhadap 100.000 cuitan berbahasa Italia yang diberi label berdasarkan sentimen, Multinomial Naive Bayes berhasil meraih skor F1 sebesar 0,88 dengan kecepatan 10 kali lipat dibandingkan SVM, sebagaimana dilaporkan dalam panduan GeeksforGeeks mengenai klasifikasi Naive Bayes.
Agar mudah diingat, pikirkanlah begini: jika data Anda mirip dengan dokumen yang penuh dengan kata-kata yang dihitung, model multinomial hampir selalu menjadi pilihan pertama yang harus dicoba.
Jika perusahaan Anda harus mengolah teks dalam jumlah besar, pertanyaannya bukan hanya “seberapa akurat model tersebut?”. Pertanyaannya juga “berapa banyak permintaan yang dapat diklasifikasikan tanpa memperlambat kerja tim?”.
Bernoulli Naive Bayes bekerja dengan fitur biner. Model ini tidak menghitung berapa kali suatu sinyal muncul. Model ini hanya menghitung apakah sinyal tersebut ada atau tidak.
Varian ini berguna ketika keberadaan suatu atribut lebih penting daripada frekuensinya. Beberapa contoh dalam konteks bisnis:
Ini adalah pendekatan yang sangat berguna ketika Anda ingin mengubah fenomena yang kompleks menjadi indikator ya/tidak yang mudah dipantau. Dalam analisis sentimen, misalnya, kehadiran sebuah kata negatif bisa jadi lebih penting daripada seberapa sering kata tersebut diulang.
Bernoulli tidak “lebih sederhana” daripada distribusi multinomial. Distribusi ini hanya lebih cocok digunakan ketika data menggambarkan adanya atau tidak adanya suatu peristiwa. Perbedaannya mungkin tampak kecil secara teoritis, tetapi sangat signifikan dalam hasilnya.
| Varian | Jenis Data yang Ideal | Conto Kasus Penggunaan di Perusahaan |
|---|---|---|
| Gaussian Naive Bayes | Data berkelanjutan | Mengelompokkan transaksi berdasarkan risiko dengan menggunakan jumlah, frekuensi, dan nilai rata-rata |
| Naive Bayes Multinomial | Teks, perhitungan, frekuensi | Menganalisis ulasan dan tiket pelanggan berdasarkan sentimen atau kategori |
| Bernoulli Naive Bayes | Data biner, ada/tidak ada | Mengevaluasi sinyal ya/tidak terkait kepatuhan, dukungan, atau penggunaan produk |
Untuk memilih dengan tepat, gunakan aturan sederhana ini:
Banyak tim terhambat karena mereka mencari model yang “paling baik” secara mutlak. Pilihan yang tepat, hampir selalu, adalah model yang paling sesuai dengan jenis datanya.
Kabar baiknya adalah, menerapkan Naive Bayes dalam praktiknya tidak memerlukan proyek yang rumit. Bahkan prototipe yang mudah dipahami saja sudah cukup untuk memahami cara kerja model tersebut dan data apa saja yang dibutuhkannya.

Sebuah klasifikasi hampir selalu dibuat melalui empat langkah.
Persiapan data
Anda perlu mengumpulkan contoh data historis yang sudah diberi label. Jika Anda mengklasifikasikan ulasan, Anda memerlukan teks yang sudah ditandai sebagai positif atau negatif. Jika Anda menganalisis risiko operasional, Anda memerlukan kasus-kasus di masa lalu dengan hasil yang sudah diketahui.
Pelatihan model
Model ini menganalisis data dan memperkirakan probabilitas yang relevan. Pada klasifikasi Naive Bayesian, proses ini berlangsung cepat karena pelatihan tidak memerlukan optimisasi yang terlalu rumit.
Prediksi kasus baru
Masukkan data baru dan model akan mengklasifikasikannya. Misalnya “spam”, “bukan spam”, “pelanggan berisiko”, “pelanggan stabil”.
Penilaian
Bandingkan prediksi dengan kenyataan pada kumpulan data uji terpisah. Di sini, Anda tidak hanya melihat apakah model tersebut berfungsi. Anda juga melihat bagaimana model tersebut membuat kesalahan.
Jika Anda ingin memahami gambaran umum mengenai pendekatan prediktif, ikhtisar tentang algoritma pembelajaran mesin ini akan membantu Anda memahami posisi Naive Bayes dalam kelompok metode yang lebih luas.
Untuk memperjelas prosesnya, berikut ini contoh sederhana menggunakan scikit-learn. Anda tidak perlu membacanya sebagai seorang pengembang. Cukup pahami alurnya saja.
# Impor alat-alat utamafrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# Muat dataset contohX, y = load_iris(return_X_y=True)# Membagi data menjadi bagian untuk pelatihan dan bagian untuk pengujianX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Membuat modelmodel = GaussianNB()# Melatih model pada data historismodel.fit(X_train, y_train)# Melakukan prediksi pada data yang belum pernah dilihatsebelumnyay_pred = model.predict(X_test)# Mengukur akurasiprint(accuracy_score(y_test, y_pred))Potongan ini mengandung makna yang jauh lebih dalam daripada yang terlihat.
GaussianNB() pilih opsi untuk data kontinu.fit() Ini adalah saat ketika model tersebut belajar.predict() menerapkan apa yang telah dipelajarinya.accuracy_score() Periksa berapa banyak klasifikasi yang benar secara keseluruhan.Untuk data teks, alur kerjanya tetap sama, tetapi sebelum memproses model, Anda harus mengubah teks menjadi angka. Pada dasarnya, Anda mengubah kata-kata menjadi fitur yang dapat digunakan oleh klasifikasi.
Setelah melihat sekilas kode tersebut, mungkin akan bermanfaat untuk melihat penjelasan visual mengenai mekanismenya.
Model pertama tidak dimaksudkan untuk membuktikan kesempurnaan. Model ini dimaksudkan untuk menjawab tiga pertanyaan praktis.
Di sini terlihat keunggulan Naive Bayes. Anda dapat dengan cepat mencapai titik acuan yang kokoh. Dari situ, Anda dapat menilai apakah perlu memperumit proyek atau apakah solusi sederhana sudah memberikan nilai tambah.
Sebuah model klasifikasi tidak dinilai hanya berdasarkan fakta bahwa model tersebut “tampaknya berfungsi”. Model tersebut dinilai berdasarkan bagaimana model tersebut melakukan kesalahan dan seberapa besar dampak kesalahan tersebut terhadap bisnis.

Akurasi adalah metrik yang paling mudah dipahami. Metrik ini menunjukkan berapa banyak prediksi yang benar dari total prediksi. Metrik ini berguna, tetapi jika dilihat sendiri saja, bisa menyesatkan.
Jika dari seratus transaksi hanya sedikit yang benar-benar mencurigakan, model yang mengklasifikasikan hampir semua transaksi sebagai normal mungkin tampak memiliki akurasi yang baik, namun tetap kurang memadai di bidang yang sebenarnya paling dibutuhkan.
Untuk memahaminya, bayangkan sebuah jaring ikan.
Dalam dunia bisnis, perbedaan ini sangat penting.
Model yang baik bukanlah model yang secara umum jarang membuat kesalahan. Melainkan model yang membuat kesalahan dengan dampak paling kecil terhadap proses Anda.
Untuk lebih memahami bagaimana sebuah algoritma belajar dari data historis dan mengapa kualitas pelatihan memengaruhi hasil akhir, Anda dapat membaca artikel mendalam ini tentang apa saja yang termasuk dalam proses pelatihan algoritma.
Naive Bayes memang sederhana, tetapi tidak akan memaafkan beberapa kesalahan praktis.
Kesalahan pertama: mengabaikan masalah frekuensi nol.
Jika sebuah kata atau nilai tidak pernah muncul dalam data pelatihan untuk suatu kelas tertentu, probabilitasnya bisa turun drastis hingga nol dan mengganggu perhitungan. Oleh karena itu, sering digunakan metode Laplace smoothing, yang menambahkan koreksi kecil pada hitungan.
Kesalahan kedua: menggunakan fitur yang sangat saling terkait.
Jika dua kolom menyajikan informasi yang hampir sama, model berisiko melebih-lebihkan sinyal tersebut. Model tidak “memahami” bahwa kedua petunjuk tersebut hampir sama.
Kesalahan ketiga: terlalu mengandalkan probabilitas mentah.
Naive Bayes sering kali memberikan peringkat yang akurat, tetapi probabilitas yang dihasilkannya bisa jadi terlalu pasti. Bagi dunia bisnis, hal ini berarti peringkat tersebut memang berguna, namun nilai probabilitas yang tepat harus ditafsirkan dengan hati-hati.
Untuk mengurangi risiko-risiko tersebut, sebaiknya:
Nilai sesungguhnya dari klasifikasi Naive Bayesian akan terlihat ketika Anda berhenti memandangnya sebagai sekadar latihan matematika dan mulai menggunakannya sebagai alat untuk menentukan prioritas. Di dunia bisnis, melakukan klasifikasi dengan baik hampir selalu berarti mengambil keputusan yang lebih baik.

Bayangkan sebuah tim keuangan yang menganalisis aliran transaksi, deskripsi operasional, dan data historis. Setiap baris bukan sekadar catatan. Itu adalah keputusan potensial: membiarkan lewat, menyelidiki lebih lanjut, memblokir, atau meneruskan ke analis.
Dengan Naive Bayes, Anda dapat menggabungkan berbagai indikator dalam satu klasifikasi. Beberapa di antaranya bersifat numerik, beberapa biner, dan beberapa lagi berupa teks. Model ini membantu mengidentifikasi kasus-kasus mana yang paling mirip dengan pola yang telah diamati sebelumnya, baik yang normal maupun yang anomali.
Manfaat praktisnya ada dua:
Hal ini tidak menggantikan penilaian manusia dalam konteks yang diatur. Hal ini justru mengorganisirnya. Dan dalam proses operasional berskala besar, hal ini benar-benar membuat perbedaan.
Dalam pemasaran, pengelompokan sering kali berarti memasukkan setiap pelanggan ke dalam kelompok operasional tertentu. Pelanggan setia. Pelanggan yang sensitif terhadap harga. Pelanggan yang berisiko berhenti berlangganan. Pelanggan yang responsif terhadap promosi. Pelanggan yang tidak aktif.
Di sini, Naive Bayes berguna karena mampu menggabungkan sinyal-sinyal yang beragam dengan cepat:
Tim CRM tidak memerlukan teori yang sempurna tentang perilaku manusia. Yang dibutuhkan adalah segmentasi yang cukup baik untuk memicu tindakan yang tepat. Misalnya, mengubah pesan, frekuensi kontak, atau jenis penawaran.
Ketika sebuah model membantu memilih pesan berikutnya untuk pelanggan yang tepat, model tersebut sudah menciptakan nilai operasional.
Dalam sektor ritel dan e-commerce, klasifikasi mendukung kegiatan yang tampak berbeda namun memiliki logika yang sama: menata kekacauan.
Anda dapat mengelompokkan produk berdasarkan profil penjualannya. Anda dapat membaca ulasan dan tiket layanan pelanggan untuk mengetahui kategori mana yang menimbulkan kendala. Anda dapat mengidentifikasi pola permintaan yang membantu tim merencanakan promosi dan persediaan dengan lebih terarah.
Dalam lingkungan seperti ini, data seringkali sangat banyak, beragam, dan tidak selalu sempurna. Oleh karena itu, model yang cepat, dapat diskalakan, dan mudah dipahami memiliki nilai yang sangat besar. Bukan karena model tersebut paling menarik, melainkan karena model tersebut dapat diintegrasikan ke dalam alur kerja tanpa menghambatnya.
Jika Anda ingin melihat bagaimana pendekatan analitik yang diterapkan dalam bisnis diwujudkan dalam proyek-proyek nyata, Anda dapat melihat studi kasus berikut ini.
Memahami Naive Bayes memang bermanfaat. Namun, menerapkannya dengan baik dalam konteks bisnis adalah hal yang berbeda.
Masalahnya hampir tidak pernah hanya terletak pada algoritma. Pekerjaan yang sesungguhnya justru terletak pada modelnya. Anda harus menghubungkan berbagai sumber data, menangani kolom yang kosong, menyiapkan teks, memperbarui label, memeriksa kualitas hasil, serta menyajikan hasil tersebut dengan cara yang mudah dipahami oleh para pengambil keputusan.
Bagi sebuah UMKM, tahap ini sering kali menjadi titik kritis. Bukan karena kurangnya minat terhadap AI, melainkan karena waktu tim terbatas dan prioritas operasional tidak bisa ditunda.
Di sini, masuk akal untuk menggunakan platform yang menangani kerumitan teknis. Solusi berbasis AI memungkinkan Anda mengubah data mentah menjadi wawasan yang mudah dipahami tanpa mengharuskan tim bisnis untuk menulis kode, memilih pustaka, atau mengelola alur kerja secara manual.
Platform seperti ELECTE, sebuah platform analitik data berbasis kecerdasan buatan (AI) untuk UMKM, memudahkan penggunaan metode seperti klasifikasi Naive Bayesian tanpa memerlukan keahlian khusus dalam machine learning. Keuntungannya bukan hanya soal kecepatan. Melainkan juga pengurangan hambatan antara data dan pengambilan keputusan.
Ketika otomatisasi berjalan dengan baik, tim tidak lagi berpikir dalam kerangka rumus. Mereka berpikir dalam kerangka pertanyaan yang bermanfaat:
Inilah juga alasan mengapa semakin banyak perusahaan yang mencari alat bantu untuk menilai keandalan konten yang dihasilkan oleh AI serta sinyal-sinyal tekstual yang beredar dalam proses internal. Dalam konteks ini, akan sangat berguna untuk membaca panduan mengenai pendeteksi AI berbahasa Italia, terutama jika tim Anda bekerja dengan dokumen, konten, dan verifikasi linguistik.
Perbedaannya, pada dasarnya, cukup sederhana. Alih-alih menangani langkah-langkah teknis yang terpisah-pisah, Anda memusatkan perhatian pada hasil bisnis. Dan di sinilah AI benar-benar menjadi sesuatu yang dapat diterapkan, bukan sekadar menarik.
Klasifikasi Naive Bayesian mengajarkan sebuah pelajaran penting. Dalam analisis data, kesederhanaan yang diterapkan dengan baik dapat mengungguli kompleksitas yang tidak dikelola dengan baik.
Dengan landasan probabilitas yang intuitif, skalabilitas yang baik, dan kasus penggunaan yang sangat konkret, pendekatan ini tetap menjadi alat yang andal bagi perusahaan yang ingin mengklasifikasikan informasi, membaca sinyal tersembunyi, dan bertindak dengan lebih percaya diri. Tidak perlu menjadi ahli machine learning untuk memahami nilainya. Yang diperlukan hanyalah mengaitkan matematika dengan pengambilan keputusan operasional.
Ketika hubungan ini menjadi jelas, AI tidak lagi sekadar masalah teknis, melainkan menjadi keunggulan organisasi. Di situlah prediksi mulai memberikan dampak.
Jika Anda ingin mengubah data yang tersebar menjadi wawasan yang jelas, cobalah ELECTE. Platform ini membantu UMKM menghubungkan sumber data, mengotomatiskan analisis, dan menghasilkan laporan serta prediksi yang berguna untuk pengambilan keputusan yang lebih cepat dan terinformasi.

.svg)
.svg)
.svg)






