

こんな状況に直面したことはあるでしょう。業務管理システムやCRM、メールでやり取りされるExcelファイルなどがある中で、誰かが「本格的な分析を行う」ためにはデータレイクとデータウェアハウスのどちらかを選ばなければならないと言うのです。すると、会話はすぐに技術的な話題に移ってしまいますが、本当の問題はそこではありません。本当に新しいデータアーキテクチャが必要なのでしょうか、それとも、すでに持っているデータを読みやすく、活用しやすい形にするだけでよいのでしょうか?
中小企業にとって、この区別は単なる用語の問題以上の意味を持ちます。誤った選択は、技術的な複雑さを招くだけではありません。プロジェクトの長期化、コンサルタントへの依存、報告書の遅延、そして投資がより良い意思決定につながらないといった問題を引き起こします。しかし、何もしないという選択は、企業をその場しのぎの状態に追い込んでしまいます。
重要なのは、ベンダーの専門用語を覚えることではありません。重要なのは、自社のビジネス規模、予算、そして社内に実際に存在するスキルに見合ったソリューションを見極めることです。ここでは、コスト、アクセス性、そして業務上のリターンをバランスよく考慮しなければならない立場から、「データレイク対データウェアハウス」の議論を読み解くための実践的なガイドをご紹介します。
今日、「データを活用せよ」というプレッシャーは現実のものとなっています。データ量は増え続け、情報源は多様化し、経営陣からはより迅速な予測、ダッシュボード、アラートが求められています。その一方で、アーキテクチャに関する即断を迫られるような用語が次々と持ち出されています。
しかし、多くの中小企業にとって、まさにここに落とし穴がある。最初のステップは2つのインフラモデルから選ぶことだと説得されるが、実際のところ、真の問題はもっと現実的なところにある。データが散在し、フォーマットが統一されておらず、レポート作成は手作業で、それを整理する時間のある人が誰もいないのだ。
重要なのは別の問いです。本当にアーキテクチャに問題があるのでしょうか?それとも、データへのアクセス性に問題があるのでしょうか?間違った解決策を選んでしまうと、ビジネスへの統制を強化する代わりに、技術的なプロジェクトに資金を投じてしまうリスクがあります。何も選ばなければ、不完全な情報に基づいて意思決定をし続けることになります。
中小企業を経営する人は、大学のような講義を必要としているわけではありません。必要なものと不要なもの、そして真のコストがどこに潜んでいるのかを理解するための、シンプルな基準を必要としているのです。
この違いは、2つの実用的な図を見ればよく理解できます。
データウェアハウスは、整然と整理された図書館のようなものです。どの本も、すでに目録が作成され、分類され、適切な書架に並べられています。情報を探す際、あらかじめ順序が決まっているため、すぐに見つけることができます。一方、データレイクは、あらゆる種類の箱が運び込まれる巨大な倉庫のようなものです。 そこには、整理されたファイル、ログ、PDF、画像、管理システムからのエクスポートデータ、ウェブデータなどが投入されます。整理は、それらを分析する必要が生じた後に施すものです。
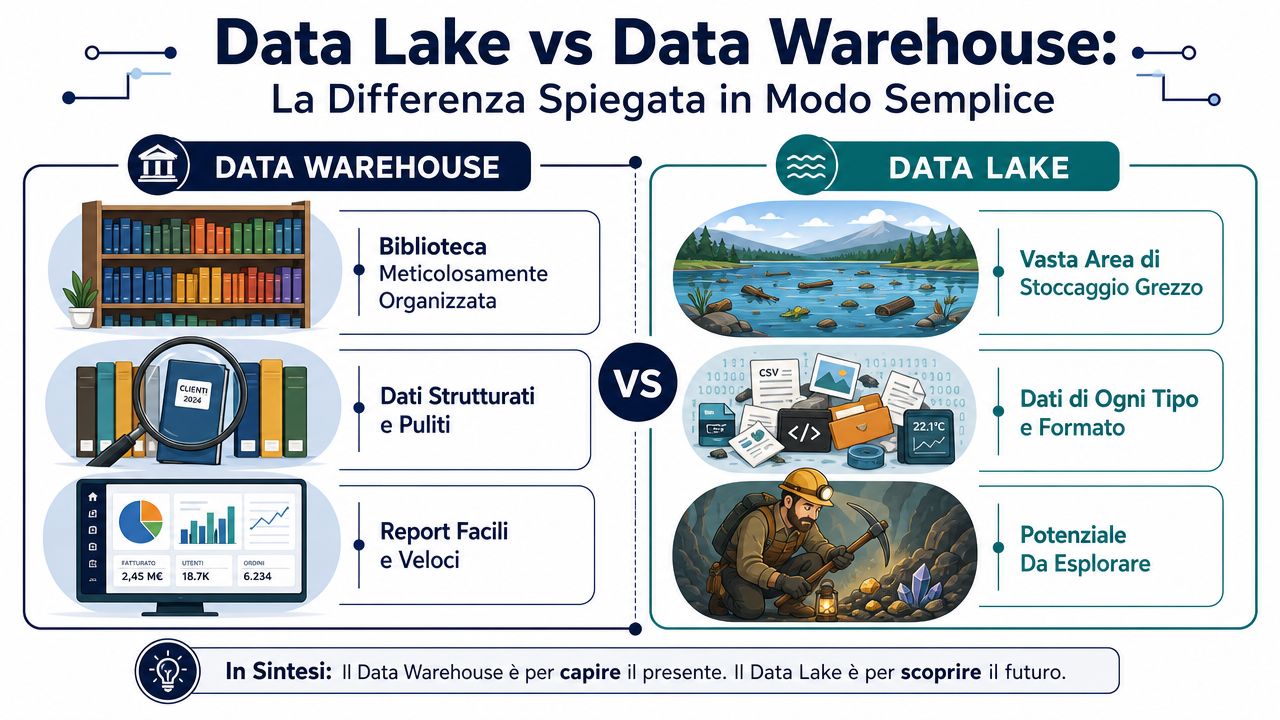
ここで、唯一覚えておく価値のある技術的なポイントが登場します。
この区別は、両者の歴史的背景も要約しています。データウェアハウスは、すでにクレンジングされ構造化されたデータを用いたビジネス分析のために誕生したのに対し、データレイクは、多様な形式の生データを保存するためにその後登場しました。そのため、データウェアハウスはレポーティングやKPIに適しているのに対し、データレイクは探索や機械学習においてより柔軟性が高いと言えます。これは、データウェアハウスとデータレイクの違いに関するこの分析でも説明されています。
データウェアハウスは、既知のクエリに対して高いパフォーマンスを発揮します。データレイクは、データに価値がある可能性はあるものの、それがどのような形であるかはまだ分からない場合に役立ちます。
売上、利益率、受注、在庫、遅延、営業実績、月次比較などを把握したいのであれば、倉庫(Warehouse)の方がそのニーズに概念的に近いと言えます。これにより、標準的なレポート、一貫性のあるSQLクエリ、再現性のある数値を得るための信頼できる基盤が得られます。
一方、アプリケーションのログ、PDF、メール、テキスト、画像、機械データなど、非常に多様なデータを扱う場合、データレイクの方が柔軟性が高いと言えます。ITチームは異種混在のデータソースを一元管理できる一方で、レポート作成担当者は、高速かつ一貫性のあるクエリ実行のために、依然として構造化された環境を好む傾向にあります。こうした文脈には、ビジネスにおける「データ駆動型の意思決定」というより広範なテーマも含まれます。これには、高度な技術よりもまず、データへのアクセス可能性が求められます。
データレイク対データウェアハウスの議論において、多くの人が柔軟性と 即効性を混同している。
データレイクには、ほぼあらゆるデータを格納できます。しかし、格納したからといって、すぐに分析できるわけではありません。データウェアハウスはデータの取り込みにおいて柔軟性に欠けますが、迅速かつ標準化された回答が必要な場合にはより有用です。中小企業にとって、この違いは単なる理論以上の重みを持っています。なぜなら、問題は「より多くのデータを保存すること」ではなく、「より適切な意思決定を行うこと」だからです。
同じ出発点となるデータを持っていても、企業によって得られる結果は大きく異なることがあります。その違いは、多くの場合、収集したデータの量にあるのではなく、データをどのように整理し、加工し、意思決定者に利用しやすい形にするかにあるのです。
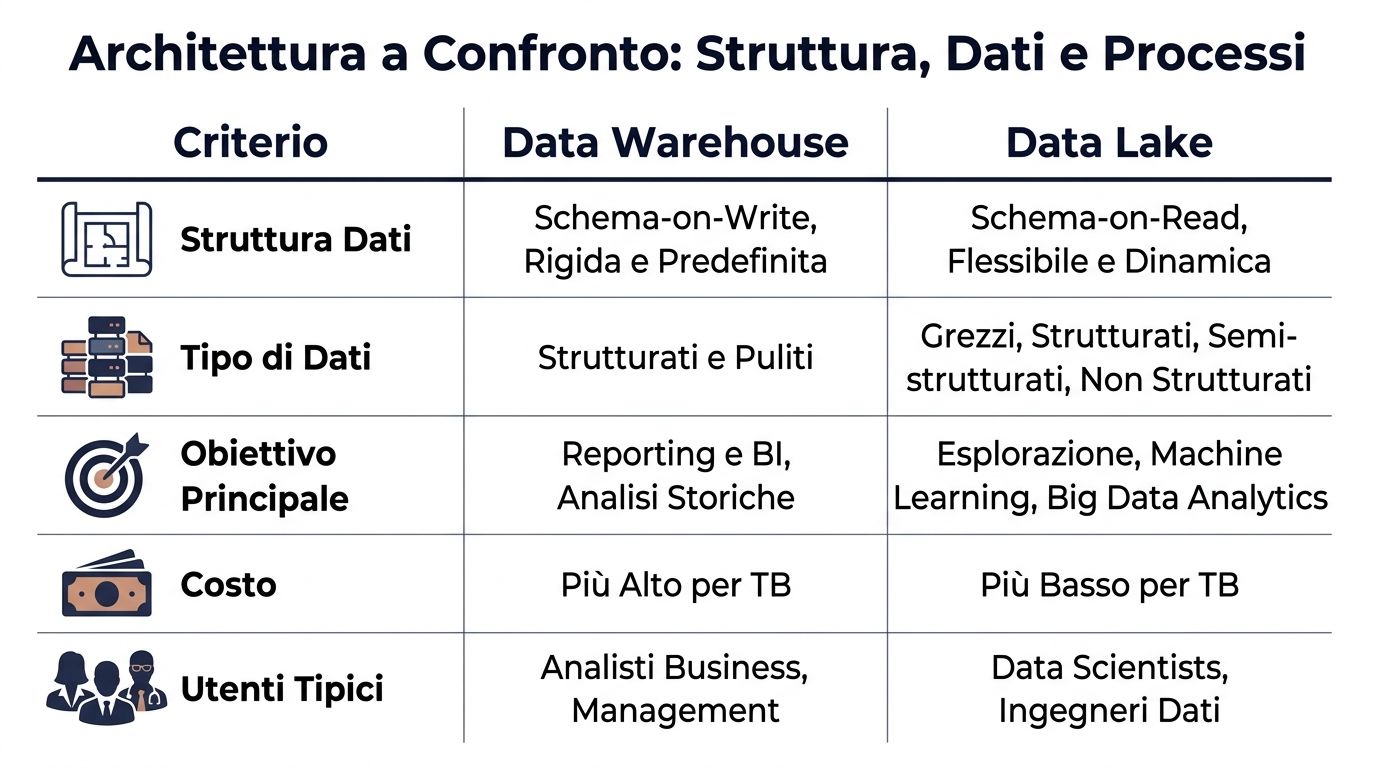
| 基準 | データウェアハウス | データレイク |
|---|---|---|
| データ構造 | ロード前に定義されるSchema-on-write | 分析時に定義される「Schema-on-read」 |
| データ型 | 何よりも整然としていて清潔 | 構造化、半構造化、非構造化 |
| 典型的なプロセス | ETL:まず変換し、その後読み込む | ELT、まず負荷を接続し、その後変圧器を接続する |
| 代表的なユーザー | ビジネスアナリスト、財務、経営 | データエンジニア、データサイエンティスト、技術チーム |
| 期待される性能 | BIおよびレポート作成において、より予測可能に | より多くの変数があり、クエリや準備内容によって異なります |
データウェアハウスにおける一般的なワークフローはETL(抽出、変換、ロード)です。初期段階では手間がかかりますが、その後は運用上の摩擦を軽減できます。ダッシュボードを確認するユーザーは、一貫性のあるフィールド、安定した定義、そして部署ごとに意味が変わらないKPIを確認することができます。
データレイクでは、データフローは多くの場合ELT(抽出、ロード、必要に応じて変換)の形式をとります。このアプローチは技術的な自由度を高めますが、作業の一部を後回しにすることになります。中小企業にとって、作業を後回しにすることは、タスクが積み重なることを意味し、その結果、迅速な対応が求められる最悪のタイミングでチームに負担がのしかかることになります。
経験則として、複数の人が同じ資料を読み、実務上の判断を下す必要がある場合、事前に整理された構成があれば、ミスや不必要な議論、時間の浪費を減らすことができます。
運用面において、データウェアハウスは反復的なクエリ、頻繁なレポート作成、そして日常的に使用されるダッシュボードを想定して設計されています。一方、データレイクは大量のデータや多様な形式のデータをうまく処理できますが、応答速度や使いやすさは、データの分類、前処理、ガバナンスの方法に大きく左右されます。CloudOptimoが発表した技術的な比較では、この点がよく要約されています。すなわち、ウェアハウスは「予測可能性」を重視し、レイクは「柔軟性」を重視するということです。
中小企業にとって、これは単なる理論上の問題ではありません。営業責任者が朝のレポートを開く際、求めているのは一貫性のある数値と迅速な処理です。一方、技術チームがファイルやログ、あるいは多種多様な文書を分析する必要がある場合、より広範なデータ収集と引き換えに、多少の処理遅延は許容できるでしょう。
実用上の違いは、単に技術的なものだけではありません。毎回助けを借りずにデータを活用できる人が変わってくるのです。
適切に構築されたデータウェアハウスは、データをビジネスに近づけます。一方、データレイクだけでは、多くの場合、データを技術チームに近づけるだけにとどまります。そのため、多くの中小企業は後になって、ある不都合な事実に気づくことになります。真の分岐点は、2つの技術の選択にあるのではなく、データをアクセス可能な形にするシステムと、データを保存するだけで、それをより良い意思決定につなげないシステムとの違いにあるのです。
IT近代化プロジェクトにおいてこれらの選択肢を検討する際は、リポジトリだけでなく、運用モデルについても考慮すべきです。中小企業向けのクラウドソリューションは、まさにこの点――インフラの境界がどこにあり、そこからコスト、必要なスキル、日々の責任がどこから始まるのか――を理解するのに役立ちます。
データレイクは、生データを保存し、初期の作業負担を軽減できるため、最もコスト効率の良い選択肢としてよく紹介されます。しかし、これは一部しか真実ではありません。カタログやアクセスルール、一貫性のある命名規則、最低限の品質管理が欠けている場合、初期のコスト削減は、ファイルの検索、定義の再構築、データの信頼性確認に費やす時間の浪費へと変わってしまいます。
そのため、多くの中小企業において、適切な比較対象は抽象的な「レイク対ウェアハウス」という構図ではありません。重要な問いは別のところにあります。果たして、こうした包括的なアーキテクチャを構築する必要があるのか、それとも、最初から複雑さを抱え込まずに、迅速なインサイトを得られる軽量なレベルから始める方が得策なのか、ということです。
中小企業にとって、最もコストのかかるミスは、往々にして「データレイクとデータウェアハウス、どちらが安上がりか?」という、根本的に間違った問いかけから生じます。企業において、真の代償は後になってからやってきます。それは、データ間の連携が取れなくなり、管理システムの変更のたびにレポートが機能しなくなり、あらゆるリクエストが意思決定を行うべきチームではなく、コンサルタントや開発者の手を経るようになった時に訪れるのです。

ストレージ自体は見た目ほど重くはありません。むしろ、データを信頼性が高く実用的なものにするための作業――モデリング、統合、権限管理、品質管理、監視、エラー修正、ユーザーサポート――の方が、より多くの労力を要します。
データウェアハウスを構築するには、初期段階での作業が必要です。指標を定義し、パイプラインを構築し、データソースを整合させ、ERPやCRM、あるいはビジネスルールが変更された際にも、すべてを適切に管理し続ける必要があります。その見返りとして、経営陣はより安定した数値を確認できるようになり、レポート作成もより予測可能になります。
データレイクは、往々にして「負担の少ない」という謳い文句で導入されることが多い。さまざまな種類のデータを投入し、構造的な決定の一部は後回しにされる。問題は、先送りしたからといって作業がなくなるわけではないということだ。作業は先送りされるだけで、後になってカタログ化、セキュリティ、計算コスト、データの重複、バージョンの不整合、そしてどのデータが本当に信頼できるのかという絶え間ない検証という形で現れることになる。
中小企業にとってのリスクは、二重にコストがかかることだ。まずはデータを収集するために、そしてようやくそのデータを読み取り可能な状態にするために。
真の複雑さは技術的なものではなく、実務的なものです。
新しいレポートを作成するたびに手作業が必要だったり、経理担当者と営業担当者が同じ指標について異なる定義を使っていたり、経営者が信頼できる数値を得るのに何日も待たなければならなかったりする場合、データプロジェクトはすでに利益率を圧迫していることになる。たとえインフラが、紙の上では最新式に見えたとしても。
そのため、アーキテクチャだけでなく、運用モデルについても検討することが重要です。中小企業向けのクラウドソリューションは、まさにこの違いを明確に理解するのに役立ちます。つまり、実際に何を購入しているのか、社内で対応すべき保守作業はどの程度残っているのか、そして毎月どの程度専門的なノウハウに依存しているのか、といった点です。
イタリア市場において、アナリティクスに投資する人々は、目に見える成果を求めています。手作業の削減。迅速な意思決定。売上、利益率、在庫、キャッシュフローに対する管理の強化。ごく一部の限られた人だけが扱うような、高度で複雑なプラットフォームではありません。
これにより、選択基準が変わってきます。中小企業は、どのアーキテクチャが抽象的に見てより魅力的か、あるいはより柔軟かといった点を問うべきではありません。信頼性の高いダッシュボードを構築するのにどれだけの時間がかかるか、その維持管理に何人の人員が必要か、そしてプロジェクトがどれほど早く価値を生み出すかを問うべきです。
小売業界では、隠れたコストはすぐに表面化します。売上、返品、プロモーション、在庫といったデータが異なるシステムから集約されている場合、「マージン」や「純売上高」の定義が少しでも間違っていれば、レポートへの信頼が失われてしまいます。そうなると、問題は選択したデータベースそのものではありません。経営者が再びExcelで判断を下すようになってしまうのです。
金融業界において、ミスがもたらす代償はさらに明白です。報告、決算、管理会計、および差異分析には、一貫性があり追跡可能なデータが不可欠です。もし監査のたびに数値の出典について議論が生じるようなら、プロジェクトは完了する前からROIを失うことになります。
そのため、実際には多くの中小企業にとって、データレイクやデータウェアハウスをゼロから構築する必要はありません。彼らに必要なのは、より軽量で管理しやすく、意思決定に重点を置いたシステムなのです。
データの品質、アクセスルール、および定義を長期的に維持できない場合、問題は「データレイク」と「データウェアハウス」のどちらを選ぶかということではありません。問題は、それを正当化するユースケースが確立される前に、複雑さを抱え込んでしまったことにあるのです。
重要なのは、どのアーキテクチャが絶対的に「優れている」かということではありません。重要なのは、明日の朝、あなたが解決しなければならない問題が何であるかということです。

小売業界において、倉庫業務が円滑に進むのは、常に同じ業務上の課題に対応する必要がある場合です:
金融分野においても同様です。構造化されたデータの統合、定期的なレポート作成、ポートフォリオの分析、あるいは一定の基準に基づいた経済動向の把握を行う必要がある場合、データウェアハウスは依然として自然な選択肢となります。
このアプローチは、企業が多種多様なデータを収集しており、すべてを事前に定義したくない、あるいは定義できない場合に有効です。
現実的な例として、あるエネルギー企業が以下のデータを照合する場合が挙げられる:
このような状況下では、従来のデータウェアハウスでは、まだ十分に把握していない可能性のあるデータソース間の関係を、あらかじめ設計せざるを得ません。一方、データレイクでは、すべてを一元管理し、特定の分析が必要になった時点で初めて構造化することができます。こうしたシナリオにおいてこそ、データレイクの柔軟性が真の価値を生み出すのです。
データレイクは、単に「より現代的な」選択肢というわけではありません。データの多様性が、導入に伴う複雑さを正当化できる場合にのみ、合理的な選択となるのです。
ほとんどの中小企業は、そのような状況にはありません。主にERP、CRM、EC、会計システムからのデータや、CSVおよびExcel形式のエクスポートデータを利用しています。こうしたケースでは、問題となるのは、動画ファイルやアプリケーションのログ、自由形式のテキストを大規模に管理することではありません。問題は、技術的な知識のない人でも理解できる、正確で一貫性のあるデータを手にすることです。
ここで明確に言っておくべきことがあります。多くの場合、データレイクも従来のデータウェアハウスも必要ないのです。
むしろ必要なのは:
レイクハウスは、この2つの世界を融合させようとしています。レイクの柔軟性と、ウェアハウスの特長の一部を、同じ環境の中で実現することを約束しています。これは、特にBI、AI、データサイエンスといった多様なワークロードを抱える企業にとって、興味深い方向性と言えます。
しかし、中小企業にとっては、依然として同じ疑問が残ります。本当にこれほどの規模の対策が必要な問題を抱えているのでしょうか?もし、売上、利益率、キャッシュフロー、あるいは予測をより的確に把握したいというニーズがあるだけなら、高度なハイブリッドソリューションは、期待される価値に比べて依然として過剰な投資となる可能性があります。
データレイクハウスは、レイクとウェアハウス間の厳格な分離を解消するために生まれました。その考え方はシンプルです。広範でオープンなストレージの柔軟性を維持しつつ、ウェアハウスに近い秩序、パフォーマンス、分析機能を付加するというものです。DatabricksやDelta Lakeといったテクノロジーは、この方向性をよく体現しています。
理論的には非常に魅力的です。BI、高度な分析、機械学習に同じデータベースを使用することで、異なるシステム間で情報を重複させることを最小限に抑えられます。大規模な組織や、データ活用が成熟したチームにとって、これは時間の経過とともに複雑化してきたエコシステムに対する理にかなった解決策と言えます。
学術的なベンチマークでは、データレイクハウスアーキテクチャは、スループット、レイテンシ、メタデータのオーバーヘッドといった指標で評価されています。これは、データウェアハウスとの比較が機能面だけでなくパフォーマンス面でも行われていることを示しており、パフォーマンスのわずかな差が大きな影響を及ぼすシナリオにおいて、このレイクハウスに関する学術的なベンチマークのプレゼンテーションが指摘している通りです。
ビジネス用語で言えば、Lakehouseは、すでに一定の規模、複雑さ、専門性を備えた組織が抱える課題を解決します。
データレイクもデータウェアハウスも本当に必要なかったのなら、その両方を組み合わせたシステムが必要になることはまずないでしょう。
多くの中小企業にとって、最も有益な問いは「どのアーキテクチャを選ぶべきか?」ではなく、「データプロジェクトを終わりのない作業にさせずに、いかにして信頼性の高い分析結果を得るか?」である。
これは、データレイクとデータウェアハウスの比較において、多くの議論で取り上げられていない3つ目のアプローチです。独自の新しいインフラを構築するのではなく、すでに使用しているシステムの上に分析レイヤーを構築し、技術的な複雑さを企業の業務範囲の外に委ねるのです。

実際には、最も健全なアプローチは次の通りです:
多くの中小企業が、従来のデータウェアハウスに数ヶ月を費やしたにもかかわらず、ほとんど活用していないのを目にしてきました。それはシステム自体の構築が不十分だったからではありません。社内に、そのデータを独自に分析できる人材がいなかったからです。ボトルネックはデータベースそのものではなく、アクセスしやすさの問題だったのです。
この点は、しばしば過小評価されがちです。常に技術的な仲介者を必要とする洗練されたアーキテクチャは、データの実用的な価値を低下させてしまいます。よりシンプルでありながら、経営陣にも理解しやすいソリューションの方が、多くの場合、より迅速に、より良い意思決定につながります。
そのため、多くの企業は、過剰な機能を備えたインフラストラクチャ・ソフトウェアよりも、適切に設計された中小企業向けビジネスインテリジェンス(BI)ソフトウェアから、より大きな価値を引き出しています。彼らが求めているのは、データウェアハウスを所有することではありません。ビジネスをより深く、より早く理解することです。
適切なインフラとは、チームが実際に活用し、維持管理し、意思決定に活かすことができるものです。技術的なスライドで印象づけるようなものではないのです。
「データレイク対データウェアハウス」という議論は有益ですが、中小企業の場合、その議論は往々にして間違った問いから始まってしまいます。アーキテクチャを選択する前に、本当にデータの規模や多様性に関する問題があるのか、それとも、データが散在していたり、レポート作成が手作業だったり、データへのアクセスが困難だったりするという、はるかに一般的な問題なのかを見極める必要があります。
信頼性の高いレポート、一貫性のあるKPI、予測可能なパフォーマンスが求められる場面では、データウェアハウスが依然として有力な選択肢です。データソースの多様性により、より高い柔軟性と複雑さが求められる場合には、データレイクが適しています。レイクハウスは興味深い進化形ですが、何よりも業務上の管理とROIを重視する企業にとって、最初の選択肢として適していることは稀です。
最も賢明な選択とは、最先端の技術を選ぶことではありません。それは、実際の問題、利用可能なスキル、そしてデータを意思決定へと変換したいスピードに見合った選択なのです。
複雑なインフラを構築することなく、企業のデータをレポート、予測、実務的な知見に変換したいとお考えなら、中小企業向けAI搭載データ分析プラットフォーム「ELECTE」をご検討ください。既存のデータを活用し、手作業を削減することで、より効率的なアプローチでチーム全体が分析を活用できるようになります。

.svg)
.svg)
.svg)






