

今月の売上レポートを見てください。売上高は増加し、利益率も改善したように見えますが、それでもどこか腑に落ちないという不快な感覚が拭えません。これは単なる思い込みではありません。実務経験からくる感覚なのです。イタリアの中小企業で働く人なら誰でも知っていることですが、管理システムやExcelへのエクスポート、手作業による修正などを経て、データはダッシュボードに届くまでに何度も形を変えてしまうのです。
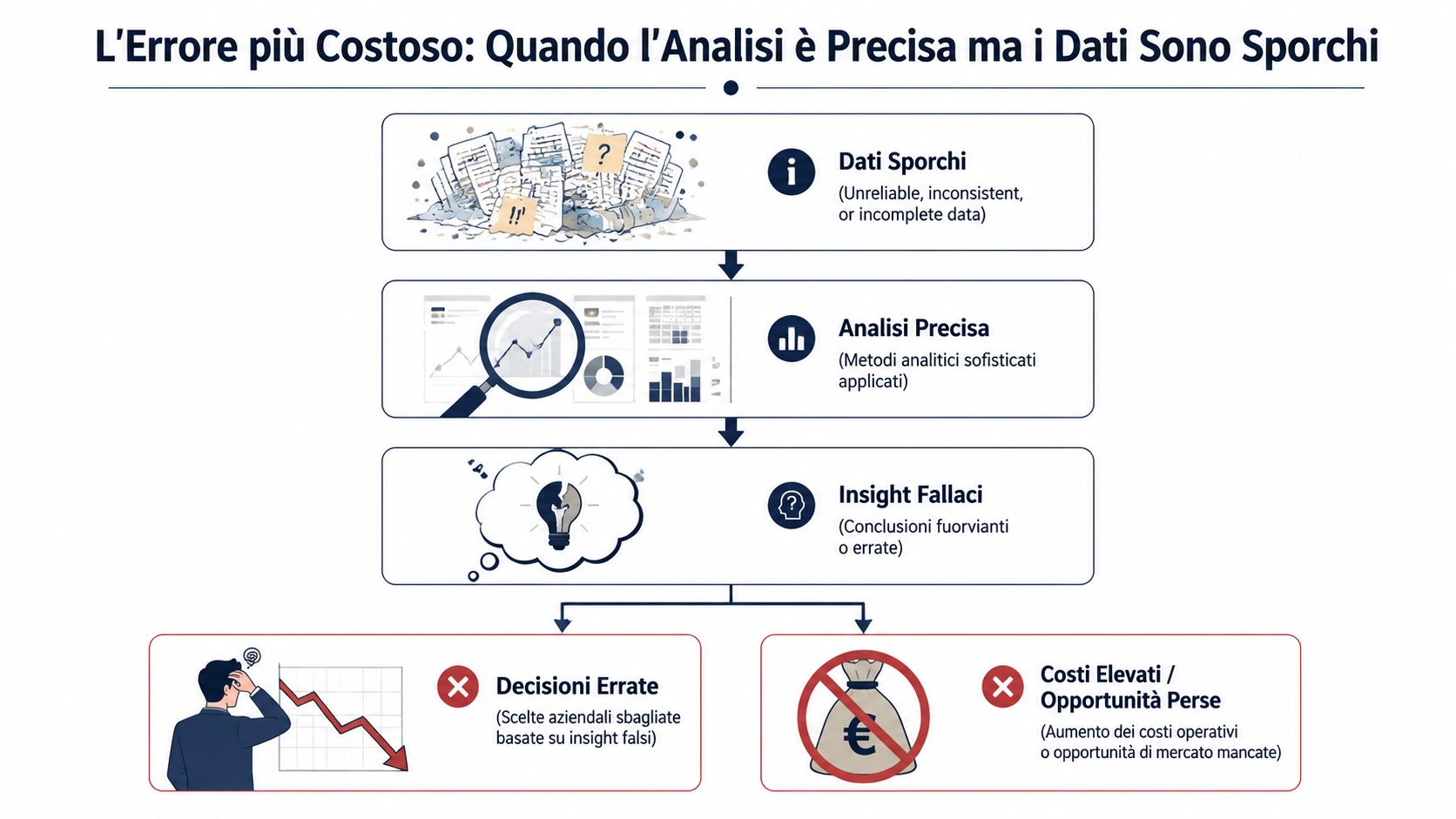
要点は単純だ。誤ったデータに基づく完璧な分析は、何の役にも立たない。それは人を惑わす。正確で、洗練され、安心感を与える答えを提示するが、その根拠は脆弱なものに過ぎない。そして、それは不完全なレポートよりもはるかに危険だ。なぜなら、確信がないにもかかわらず、自信を持って決断を下すよう促してしまうからだ。
データ検証の手法は、まさにこの目的のためにあるのです。つまり、エラーを「黙らせない」ことです。データそのものを「完璧」にするわけではありません。現在見過ごされている問題を可視化するのです。経理、管理会計、営業、あるいはオペレーションを担当している方にとって、この作業こそが、実用的な数値と単なる飾り物の数値を分ける鍵となります。そして中小企業においては、多くの「先進的な」アナリティクス施策よりも価値があります。なぜなら、その効果は即座に現れ、多くの場合、最初のデータ取り込みの段階からすでに実感できるからです。
中小企業では、数値が「読み取られる場所」で直接生成されることはめったにありません。管理システムからエクスポートされたファイルへ、さらにExcelへ、そして「整理」されたバージョンへと移り変わります。その「整理」とは、本来は2つの列を修正するだけだったはずの担当者が、結局はシートの半分を書き直してしまったようなものです。最終的なレポートが納得のいくものでない場合、問題は往々にしてグラフそのものにあるわけではありません。問題は、その前に起きた一連の過程にあるのです。
データの検証は、分析サイクル全体の中で最も魅力に欠けるが、最も重要なテーマである。フォーマットチェックや必須項目の未入力について議論したいと思う経営者はいないだろう。しかし、一見問題のないダッシュボードに基づいて下された誤った判断のほとんどは、こうした点に起因している。小数点区切り記号の変更、日付の誤解釈、マスターデータの重複、合計が合わないのに誰も確認しなかったことなどである。
データを適切に扱う人は、ある明確な習慣を身につけています。それは、数字が何を示しているかを考える前に、その数字が信頼に値するかどうかをまず問うことです。優れたデータ検証手法とは、最も洗練されたものとは限りません。日々の業務の足を引っ張ることなく、よくあるエラーを早期に発見できる手法こそが、優れたものなのです。
重要な決断を下すほどデータを信頼できないのであれば、問題は決断そのものではなく、データの検証にある。
典型的な誤りは、明らかに欠陥のあるレポートではありません。それは、一見すると整然として一貫性があるように見え、すでに信頼性を失ったデータに基づいて作成されたレポートなのです。このような事態が発生した場合、被害は単に数値が間違っていることだけにとどまりません。問題は、誰もその数値に疑問を抱かないという点にあるのです。
この分野は大きく進化しました。データ検証は、主に手動で行われていたものから、自動化および統計的な検証へと移行しました。 ベストプラクティスでは、少なくとも5つの基本的なチェック、すなわちデータ型チェック、コードチェック、範囲チェック、フォーマットチェック、整合性チェックが挙げられており、これはTeradataのデータ検証に関する概要でもまとめられています。イタリアでは、規制対象の分野においてこの成熟度がさらに重要視されており、たった1つのフィールドに誤りがあるだけでも、レポートや予測モデル、あるいはコンプライアンス要件に影響を及ぼす可能性があります。
最初の過ちは、表面的なチェックにとどまってしまうことです。多くの企業は、最も単純な構文チェックしか行っていません。
正しく記載された納税者番号は、最初の関門は突破できても、2つ目の関門で失敗することがある。請求書の合計金額が数値で正しい形式であっても、各行の合計と一致していなければ、単なる形式の問題よりもはるかに深刻な問題が生じる。
経験則:1つの列のみをチェックする検証では、些細なエラーしか見つかりません。複数のフィールドを関連付けてチェックする検証では、判断に影響を与えるようなエラーが見つかります。
実用的な検証は、作業の最後に行われるものではありません。それより前に行われるものです。最終レポートを待っていると、そのエラーはすでに変換され、集計され、他のファイルにコピーされ、会議で議論されてしまっているでしょう。その段階になってから修正しようとすると、注意力、時間、そして信頼性を犠牲にすることになります。
これは、異常検知や統計的な外れ値の処理といった、より高度な手法を使い始める場合にはなおさらです。これらは有用なツールですが、基本的なチェックに代わるものではありません。テキストとしてインポートされた列に価格が含まれている場合、複雑なモデルは必要ありません。入力段階でエラーを遮断する、基本的なフィルタがあれば十分です。
優れた分析は、見た目が美しいダッシュボードから始まるわけではありません。データがフローに入る時点で、一連の妥当なテストを通過したデータから始まるのです。
中小企業の日常業務において、価値の大部分はシンプルな管理手法から生まれます。それは、洗練された学術的な手法からではありません。誰も維持できないような複雑なプロセスからでもありません。データが実際に社内に取り込まれる現場に近い場所で、明確かつ再現性のあるルールから生まれるのです。

イタリアの文脈において、このアプローチはISTATの方針と一致している。ISTATは、データの質を「正確性」「一貫性」「完全性」といった側面を通じて定義し、VIMO(Valid、Invalid、Missing、Outlier)チェックを用いて、有効な値、欠損値、異常値を測定している。 このアプローチでは、ISTATのデータ品質および検証に関する資料で説明されているように、データの取り込み時、変換時、および最終利用前の各段階で検証が行われる。
典型的な流れはいつも同じです。データは管理システムで生成され、エクスポートされてExcelに取り込まれます。誰かがヘッダーを修正したり、数式をドラッグしたり、列をコピーしたり、「整える」ために日付の書式を変更したりします。そこから、目に見えないエラーが発生し始めるのです。
今すぐ実施すべき点検項目は以下の通りです:
手動でのエクスポートを行っている場合は、次のような具体的なテンプレートから始めることができます:
| 確認 | 中小企業によく見られるミス | 自分に問いかけてみるべき質問 |
|---|---|---|
| 種類 | 「ベッド」をテキストとして扱う | この列は計算できますか? |
| フォーマット | 異なる形式の日付が混在している | システムは常に同じように解釈するのでしょうか? |
| 範囲 | スケール外の金額 | この数値は、顧客や製品ごとに妥当なものですか? |
| 唯一無二 | 同じ顧客が複数回登録された | 別の人数を数えているのか、それとも書き方が違う名前を数えているのか? |
| 網羅性 | 空欄の主要フィールド | このレコードをレポートや意思決定に活用できますか? |
| 一貫性 | 辻が合わない合計額 | それらの列は互いに一致しているのでしょうか? |
文書や手続きの品質がすでに業務上大きな比重を占めている分野で働く人にとっては、より体系的な適格性評価や管理の手法についても比較検討してみる価値がある。その点で参考になるのが『規制対象分野における適格性評価ガイド』であり、このガイドは、バリデーションの枠組みが単なる「整理整頓」ではなく、プロセスそのものの管理であることを明確に示している。
重複データについては、特に触れておく価値があります。これは多くの中小企業の顧客データベースにおいて慢性的な問題となっており、アクティブな顧客数、購入頻度、販売実績、取引履歴など、ほぼすべてのデータを歪めてしまいます。具体的な事例から始めたい場合は、『ELECTE:Excelの重複データ完全ガイド』に実践的なアプローチが紹介されています。
高度な監視システムは、基礎が整って初めて役に立つ。そうでなければ、ブレーキのない車にレーダーを取り付けるようなものだ。
月曜日の朝、営業会議。社長は売上レポートを見ており、管理責任者は別のファイルを見ており、経理担当者はさらに別のファイルを見ている。数字は一致するはずなのに、一致していない。
これはイタリアの中小企業ではよくある光景だ。古い業務管理システムは、固定されたフィールドを持つCSVファイルをエクスポートする。CRMは異なるラベルを使用している。ECサイトには独自のロジックがある。そこでExcelが登場し、誰かがヘッダーを調整し、列をコピーし、日付を修正し、会議の前にすべてを整合させようと試みる。
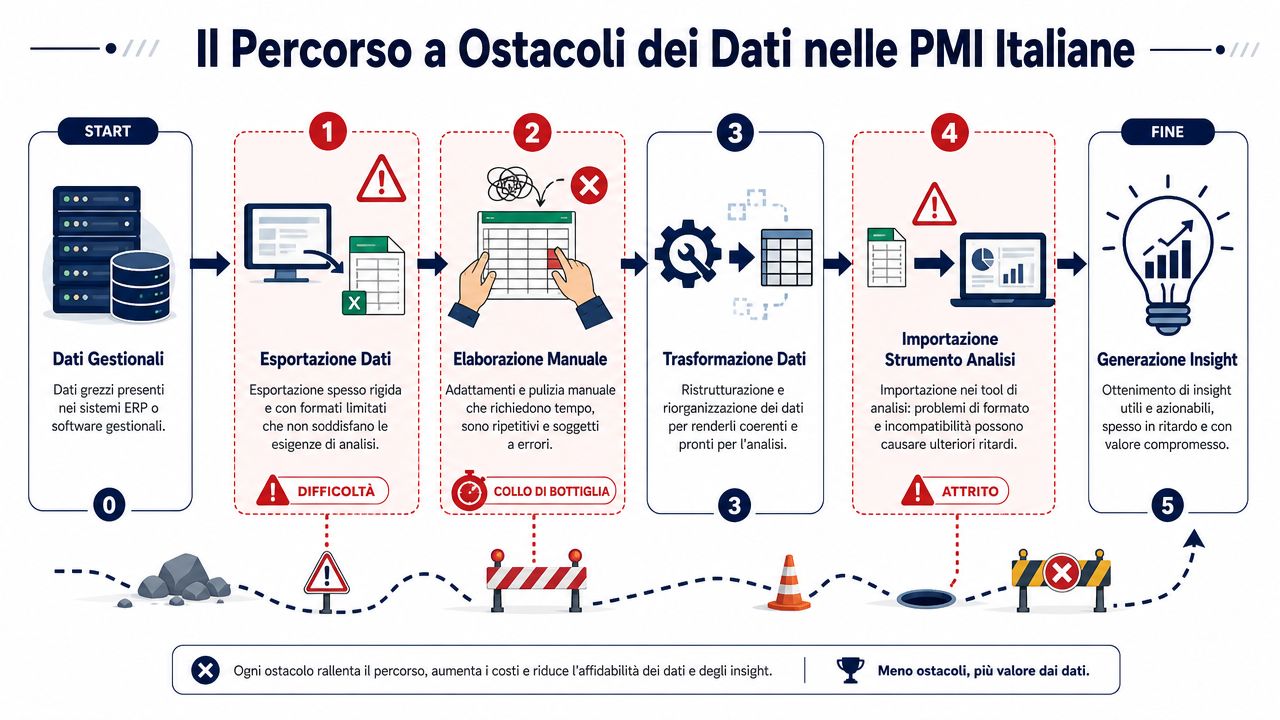
問題は技術そのものではありません。問題は、異なる時期に構築されたシステムから送られてくるデータに対して、共通のルールがないまま行われる、細かな手作業の積み重ねにあります。さまざまなデータソースを連携させる業務に携わる人なら、すぐに気づくでしょう。どのデータソースにも固有の慣習や繰り返し発生するエラーがあり、フィールドの入力も「その場しのぎ」で行われているのです。
最もコストのかかるエラーであっても、処理は停止しません。それらはファイルに書き込まれ、そのまま残ります。
これは、ごく身近な場面で毎日起こっていることです:
この点で、多くの企業が同じ過ちを犯しています。ありふれてはいるものの収益性の高い対策――正しいデータ型、一貫性のあるキー、保護されたコード、すべてのシステムで同じように読み取れる日付――を確実に整える前に、複雑な解決策を模索してしまうのです。
中小企業では、データが最初から整然として安定していることはめったにありません。データは、経理、営業、物流、外部コンサルタントの間をやり取りされ、「report_finale_def_vero.xlsx」といった名前のローカルファイルとして保存されます。各担当者は、自分の業務に必要な部分を修正します。その変更内容を記録する人はほとんどいません。
そのため、学術的な検証や、あまりにも野心的な異常検知プロジェクトは、しばしば時期尚早となってしまう。まずは基礎をしっかりと固めることが必要だ。無効なCAP、切り捨てられた顧客コード、重複行、期間外の date などを指摘する自動チェックは、時期尚早に立ち上げられた多くの「先進的」な取り組みよりも、より多くのエラーを防ぐことができる。
率直に言いますが、これは私が最も頻繁に目にする問題だからです。中小企業がデータへの信頼を失うのは、人工知能が不足しているからではありません。Excelファイルごとに売上高の数値が異なり、どのバージョンが正しいのか誰も分からないからなのです。
「これまでずっと問題なく動いていた」ファイルは、往々にして誰もチェックしなくなっているファイルである。
データが複数の担当者やシステムを経由する場合、検証は「洗練された」ものである必要はありません。再現可能で、手間がかかり、データの入力段階に近いものでなければなりません。予測モデルや見栄えの良いダッシュボードの話をする前に、そこでこそ価値の大部分が得られるのです。
月曜日の朝は、たいていこんな風に始まります。管理担当者が同じ月のエクスポートファイルを2つ開きます。1つは管理システムから、もう1つは営業ファイルからですが、合計が合いません。手作業で再確認する時間など誰にもありません。その時点で、問題はレポートそのものではありません。数字に対する信頼がすでに失われてしまっているのです。
ELECTEは、不正確なデータが分析プロセスに入る前に介入します。イタリアの中小企業にとって、これこそが本当に重要なポイントです。洗練されたチェック機能を謳う複雑なシステムであっても、単純なインポートエラーや列の読み取りミス、システム間でフォーマットが異なるコードを見逃してしまうようでは、何の役にも立ちません。
実際には、このプラットフォームはデータが到着する時点でそれをチェックします。レポート作成後ではありません。あるファイルのバージョンから別のバージョンへと移行した際に、なぜ利益率が変化したのかと誰かが問うような会議の後でもありません。
自動チェックは、中小企業において予想以上に大きな損害をもたらす問題に対応しています。具体的には、データ形式の不整合、入力漏れ、期間外の date、重複、範囲外の値、適切なテーブルに紐づいていないキーなどです。これらは華やかな作業ではありませんが、Excelのエクスポートや旧式のERP、メールでやり取りされるファイルが氾濫する環境において、運用上のミスを最も多く防ぐ役割を果たしています。
次に、文脈的なレベルがあります。オンボーディングでは、理論上のモデルではなく、実際の業務プロセスに沿ったルールを設定します。流通業の企業と、観光客の受け入れを管理する事務所、あるいは段階的な価格表や割引体系を持つ製造業者では、ニーズが異なります。これは、文書からの構造化データの読み取りやチェックインといった特定の文書処理のケースにも当てはまり、宿泊施設向けにMRZを扱う担当者にとっても重要なテーマです。
実用的なメリットは単純明快です。チームは毎回、どのようなチェックを行うべきかを考え直す必要がありません。すでに一貫性があり、再現性のある形で適用されているからです。
典型的な例を挙げよう。管理システムのアップデートにより、エクスポートデータの一部において、一部の価格フィールドの形式が変更された。一見、ファイルは正常に見える。しかし、分析してみると、それらの値が売上高、利益率、および前月との比較に影響を及ぼしていることが判明した。ELECTEは直ちにこの異常を検知し、影響を受けた行を特定することで、ダッシュボードや経営報告書に反映される前に修正を行うことを可能にする。
意思決定を行う必要があり、データサイエンスを行うわけではない人にとって、最も有用なポイントの一つは例外処理です。問題のあるレコードは消えることはありません。それらは目に見える状態で、他のデータとは区別され、その理由も明記されたまま残ります。
このデータを見れば、すぐにわかるでしょう:
この透明性のおかげで、私が中小企業で目にする最悪の習慣の一つ――痕跡を残さずにデータセットを整理してしまい、数週間後に数字が合わなくなっていることに気づく――を防ぐことができます。
さまざまなデータソースを連携させる機能は、まさにこの理由から価値があるのです。CRM、ERP、ECサイト、手動で管理されているファイルを連携させるだけでは不十分です。明確な管理基準なしにデータが流れ込めば、画面上は整然としていても、混乱は依然として残ったままです。
ELECTEは、完璧なデータを保証するものではありません。最も頻繁に発生するエラーを減らし、それらを可視化することで、誤ったデータが正しいデータであるかのようにレポートに反映されるのを防ぎます。中小企業にとって、これこそが「数字について議論する」ことと「数字そのものを議論する」ことの違いを生むことが多いのです。
バリデーションは、ビジネスとは切り離された技術的なプロジェクトとして扱うべきではありません。それは業務上の規律として扱うべきものです。予算を策定したり、価格表を承認したり、利益率を見直したり、仕入れ計画を立てたりする人は、すでに適切にバリデーションされたデータ、あるいは不適切にバリデーションされたデータを利用しています。その中間という選択肢は存在しません。
役立つルールは少ないですが、それを一貫して実践することが大切です:
入力時には有効だが、下流では無効
検証が最後まで行われた場合、エラーはすでに数式、集計、レポートに悪影響を及ぼしている。
という形式だけにこだわらないでください。データは、書き方が正しくても内容が間違っている場合があります。スキーマに準拠しているかどうかだけでなく、各フィールド間の妥当性や一貫性も確認する必要があります。
反復的なチェックを自動化
管理部門や営業部門のチームには、エクスポートデータを一つひとつ手作業で再確認する時間などありません。基本的な確認作業は、体系的なものにする必要があります。
過度に厳格なルールは避ける
厳格さと生産性の間には、現実的なトレードオフが存在します。Acceldataがデータ検証のトレードオフに関する考察で指摘しているように、過度に厳格なルールは、技術系ではないチームによる分析ツールの導入を妨げる可能性があります。適切な基準とは、ビジネスの進行を遅らせることなく、エラーを最小限に抑えるものです。
例外を「厄介なもの」ではなく「シグナル」として捉える
異常な記録は、ほとんどの場合、それを生み出したプロセスについて何かを物語っている。それを無視することは、上流工程の改善を諦めることに等しい。
有用な例としては、フォーマットが単なる細部ではなく、機能の前提条件となる分野が挙げられます。例えば宿泊施設では、書類の自動読み取りという課題が、データが存在するだけでなく、解釈可能な標準に準拠している必要があることを如実に示しています。具体的な事例をお求めの方は、宿泊施設向けのMRZに関するこの詳細記事をご覧ください。
正しい考え方はこうだ。データを検証してからでなければ、それを信用してはならない。もし今日、誰も体系的にチェックしていないファイルに頼っているなら、それは分析ではない。単なる「期待」に過ぎない。
レポートにおける問題のほとんどは、最後のグラフで生じるわけではありません。それよりはるかに前の段階、つまり不完全なデータや一貫性のないデータ、あるいは文脈から外れたデータが、適切なフィルタリングを経ずにシステムに取り込まれる時点で生じているのです。だからこそ、データ検証の手法は見た目以上に重要です。そこが、データに振り回されるのをやめ、データを制御し始める分岐点なのです。
中小企業にとって、利益は「完璧」を追求することにあるわけではありません。重要なのは、冷静に意思決定を行えるだけの十分な信頼関係を築くことです。タイプ、フォーマット、範囲、一意性、完全性、および相互整合性に関するチェックを行うことで、実際の問題の大部分は解決されます。自動化により、こうしたチェックを持続可能なものにすることができます。
体系的な検証プロセスがなければ、データを信頼しているとは言えません。運を頼りにしているに過ぎないのです。
混乱したエクスポートデータ、不安定なExcelファイル、多様なデータソースを信頼性の高い分析に変えたいなら、中小企業向けAI搭載データ分析プラットフォーム「ELECTE」が、チームの負担を増やすことなく、チェック、異常検知、インサイトの抽出をどのように自動化するのか、ぜひご覧ください。

.svg)
.svg)
.svg)






