

中小企業の財務チームならよくご存知でしょう。PDFをExcelに取り込もうとするたびに、書式設定との戦いが始まります。よくある「コピー&ペースト」は、ほとんどの場合、大惨事へとつながります。データが散らばり、セルがランダムに結合され、整然とした表が読めないほどの混乱状態に陥ってしまうのです。その苛立ちは本物ですが、それはあなたのせいではありません。 問題は、PDFというフォーマットそのものの性質にあります。PDFは印刷や共有のために設計されており、分析用のデータソースとして設計されたものではないのです。
銀行からの報告書、仕入先からの請求書、政府機関からの書類などで構成されるこの手作業のワークフローは、生産性を著しく低下させる要因となっています。 退屈なだけでなく、データ入力ミスが発生する可能性も極めて高い。幸いなことに、2026年現在では、この課題を克服するためのよりスマートな方法が利用可能だ。本ガイドでは、Excelに組み込まれた機能から、手作業を完全に排除し、データ抽出から分析までを数分で完了させるAI搭載ソリューションに至るまで、最も効果的な戦略をステップバイステップで解説する。
この問題は、ある根本的な違いに起因しています。PDFは、あらゆるデバイスで文書の見た目を維持するために作成されたものであり、内部のデータの論理構造を維持するためのものではありません。PDFの種類ごとの違いを理解することは、適切なツールを選び、無駄な作業時間を避けるための第一歩となります。
この画像は、複雑なPDFと整理されていないスプレッドシートの間で、どうにかやりくりしなければならない人々のもどかしさを完璧に捉えています。

まさにこの瞬間、手作業のプロセスが生産性の妨げとなり、PDFをExcelに取り込むためのより効率的な方法が必要であることが明らかになります。
ご存じないかもしれませんが、PDFをExcelに取り込む最も手軽なツールは、皆さんが毎日使っているソフトウェアにすでに組み込まれています。その名は「Power Query」で、MicrosoftがExcelに搭載した「データの取得と変換」という強力な機能です。

価格表や連絡先リストなど、シンプルで構成の整ったPDFをたまにインポートする場合に最適なソリューションです。最大のメリットは?無料で、追加のインストールも不要な点です。
データは新しいワークシートに挿入され、すでにExcelの表形式にフォーマットされており、すぐに使用できるようになっています。
Power Queryは素晴らしいツールですが、限界もあります。1ページに収まるようなシンプルなテーブルであれば最高のパフォーマンスを発揮します。しかし、より複雑な状況になると、そのパフォーマンスは著しく低下します:
データ分析を頻繁に行う場合は、同じ技術を採用しているPower BIとの連携について調べてみると良いでしょう。同様に、他のファイル形式を扱う能力も不可欠です。ExcelでのCSVファイルの扱い方に関する当社のガイドが、役立つヒントとなるはずです。
貴社で既にAdobe Acrobat Proのライセンスをお持ちであれば、そのエクスポート機能は最も信頼性の高い解決策の一つです。複雑な表や型破りなレイアウトの書式を保持する点では、多くの場合、Power Queryを上回ります。
手順は簡単です。PDFを開き、「すべてのツール」から「PDFをエクスポート」を選択し、形式を「スプレッドシート」に設定して、新しいExcelファイルを保存してください。
結果はたいていすっきりとして整然としています。しかし、主に2つの欠点があります:
iLovePDF、Smallpdf、あるいはオープンソースのTabulaといったツールは、非常に便利です。ファイルをドラッグ&ドロップし、ボタンをクリックするだけで、変換結果がダウンロードできます。機密性のないデータをたまに変換する場合には、これらのツールが適しています。
しかし、この利便性には、データセキュリティという大きなリスクが潜んでいる。
サードパーティのサーバーに文書をアップロードすることは、事実上、その文書に対する管理権を失うことを意味します。そのPDFに取引明細、顧客データ、機密の価格表、あるいはその他の戦略的情報が含まれている場合、貴社はプライバシー侵害のリスクにさらされ、GDPRへの準拠において重大なリスクを負うことになります。
欧州で事業を展開する中小企業にとって、これは決して軽視できない問題です。公開されているIstatの報告書を分析するためにオンライン変換ツールを利用することは許容されますが、自社の財務データに対して同じことを行うのは危険な行為であり、慎重に検討する必要があります。
チームが毎月同じ形式で届く数十件の明細書、請求書、またはレポートを処理しなければならない場合、手作業でのデータ抽出は単なる手間以上の問題であり、業務上のボトルネックとなります。
標準化された大量の文書を処理する中小企業にとって、Pythonスクリプトによる自動化は単なる贅沢ではなく、効率化に向けた的確な投資です。確かに技術的なスキルは必要ですが、時間の節約やミスの削減という点で、その投資対効果は極めて大きいと言えます。

Pythonは、次のような無料かつ非常に強力なライブラリのおかげで、この分野で圧倒的な存在感を示しています。 pdfplumber そして キャメロット、PDF内に埋め込まれた表の構造を認識・再構築するために特別に設計されたものです。
pdfplumber: 非常に汎用性が高く、各文字の位置を分析することで、表やテキスト、メタデータを抽出するのに最適です。キャメロット: 表の抽出に特化しており、境界線が表示されている場合と表示されていない場合の両方の表を処理するための高度なアルゴリズムを提供します。実用的なシナリオ:月末にサプライヤーから50件の請求書が届いたと想像してみてください。何時間もリソースを割く代わりに、Pythonスクリプトを使って請求書をスキャンし、合計金額や日付を抽出し、分析用のExcelファイルを生成することができます。これらすべてを1分未満で完了でき、人的ミスのリスクもゼロに抑えられます。
データを抽出・整理した後、それらを分析プラットフォームに送信することができます。これらのデータをより広範なデータフローに統合する方法について詳しく知りたい場合は、 ELECTEがどのように機能し、当社プラットフォームへのデータ送信を自動化するかをご確認ください。
従来の方法が通用しなくなった時、人工知能の出番となる。ELECTE 、特にスキャンされた文書やレイアウトが複雑な文書において、業界の常識ELECTE 。
単にテキストを「読み取る」だけだった従来のOCRの話ではありません。最新のソリューションでは、OCRと高度な言語モデル(LLM)を組み合わせることで、データの構造や文脈、相互関係を理解できるようになっています。
数ページにわたる表を含む財務レポートを想像してみてください。AIを活用したプラットフォームなら、次のようなことが可能です:
これで状況が一変します。生データを抽出する代わりに、AIプラットフォームがPDFを「解析」し、分析可能なクリーンなデータセットとして出力します。詳細については、企業向けのおすすめAIに関する記事でも取り上げています。
AIの真の価値は、データを抽出することではなく、すぐに活用できる情報を抽出することにあります。単なるExcelファイルが得られるのではなく、チームがデータの前処理に時間を費やすことなく、すぐに戦略的な意思決定に活用できるデータが得られるのです。
ミラノがイタリアの輸入を牽引しているという事実は興味深いものです。しかし、輸入元となる各県に関する詳細なレポートを自動的に取り込むことができれば、チームはさらに多くのことを実現できます。例えば、傾向の比較、在庫の最適化、コスト削減などが可能です。
選択肢がこれほど多い中で、自分に最適なものはどう選べばよいのでしょうか?その答えは、手術の効率、安全性、そして費用を左右する4つの重要な要素にかかっています。
この意思決定ツリーは、選択に至る論理的な流れを把握するのに役立ちます。
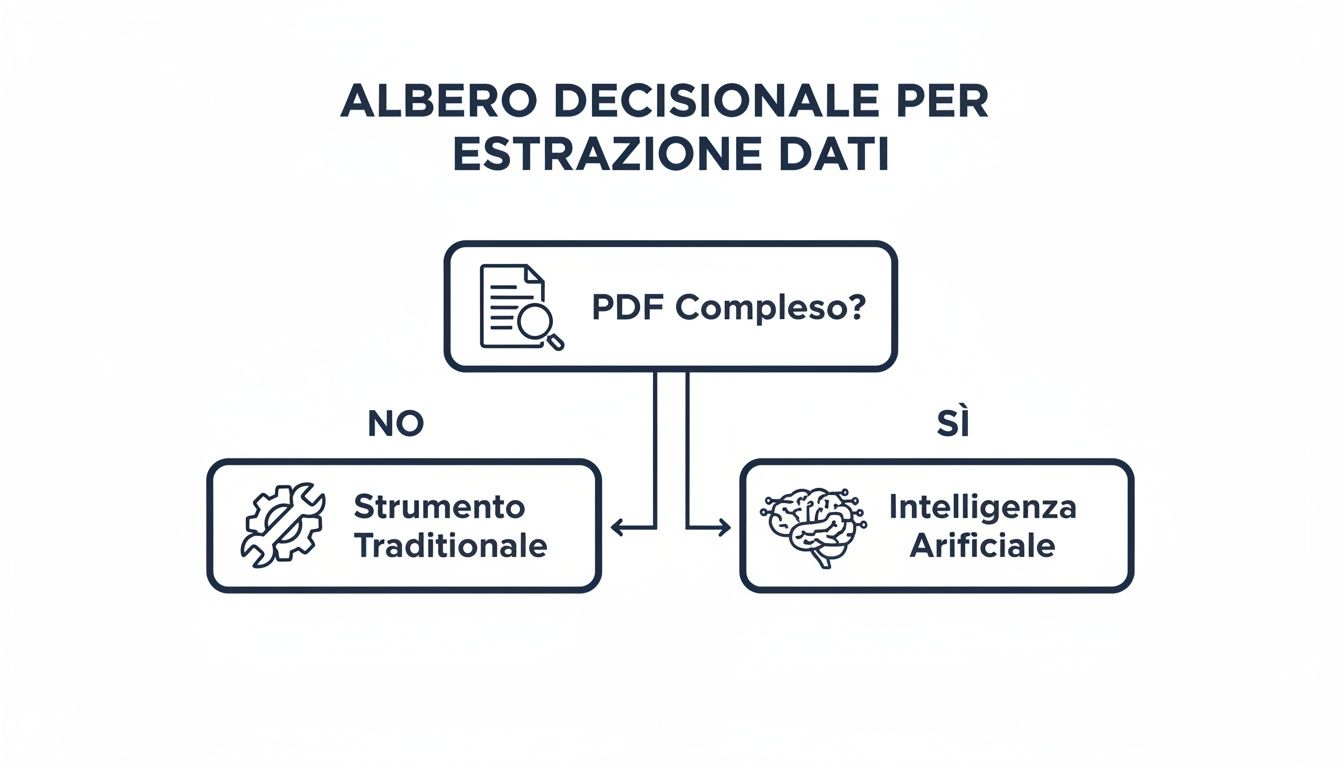
仕組みはシンプルです。単純なPDFや偶発的な作業であれば、Power Queryのような従来のツールで十分です。しかし、大量のデータや複雑なドキュメント、繰り返し行われるワークフローの場合、ELECTE を活用すれば、単調な作業を価値を生み出す自動化されたプロセスへとELECTE 。
PDFをExcelに取り込む作業は、もはや手作業で煩わしいものになる必要はありません。現在では、Power Queryのような無料の組み込みツールから、高度な自動化ソリューションやAI搭載プラットフォームに至るまで、豊富なツールが利用可能です。
どちらを選ぶかは、具体的なニーズ次第です。単純なファイルに対する偶発的な操作であれば、Power Queryに勝るものはありません。一方、複雑で機密性の高い文書を定期的に処理する場合、自動化と人工知能はもはや「ぜいたく品」ではなく、戦略的な「必須要件」となっています。 手作業によるデータ抽出を排除することで、時間を節約しエラーを減らすだけでなく、最も貴重なリソースを解放し、真に重要なこと、つまりデータを分析して、より賢明かつ迅速なビジネス上の意思決定を行うことに集中できるようになります。こうして、単なる文書を競争優位性の源泉へと変えることができるのです。
コピペに永遠に別れを告げる準備はできていますか? ELECTE 意思決定をいかに加速ELECTE をご覧ください 複雑なPDFを実用的なインサイトに変換し、意思決定を加速させる方法をご覧ください。

.svg)
.svg)
.svg)



.webp)

.webp)
.webp)