

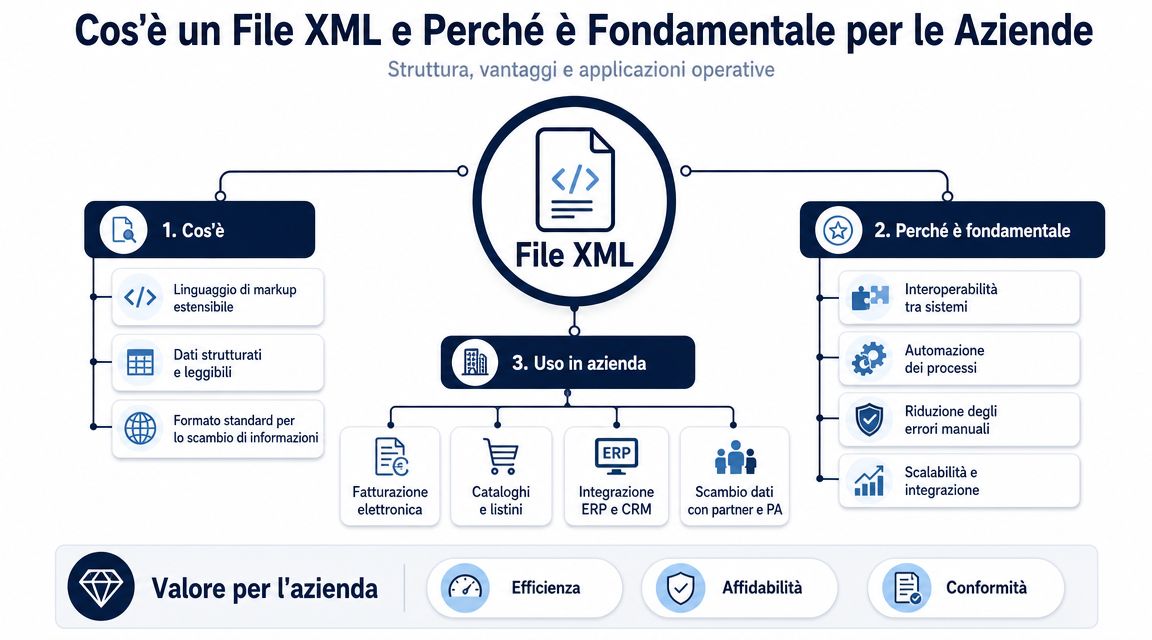
PEC経由でXMLファイルが届きます。ブラウザで開くと、タグの壁が目に飛び込んできて、「これを読み解くこと」が問題だと思いがちです。しかし実際には、それは最初のハードルに過ぎません。企業における真の問題は別のところにあります。それは、そのデータが正確で一貫性があり、レポートに組み込む準備ができているかどうかを見極めることです。
多くのイタリアの中小企業にとって、このテーマはもはや厳密な意味での技術的な問題ではありません。電子請求書の発行が義務化されて以来、XMLは管理業務、経営管理、分析といった日々の業務に浸透しています。 単に文書を表示するだけでは不十分です。読み取り可能なファイルと信頼できるファイルを区別できる必要があります。データをExcel、BI、あるいは分析プラットフォームに取り込む前に、簡単なチェックで済む場合と、パーシング、検証、正規化が必要な場合を見極める必要があります。
XMLファイルの読み方に関する実践的なガイドをお探しなら、この方法が最適です。まずは簡単な手法から始め、どこで問題が発生するかを把握し、その後、生のXMLをビジネスに役立つデータに変換するフローを構築します。そうすることでエラーを減らし、「ファイルを入手した」から「活用できるインサイトを得た」までの時間を短縮できるのです。
XMLファイルは、データを階層構造で整理します。親要素があり、その下にネストされたセクションがあり、各ブロックは明確な意味を持つ情報を記述しています。管理業務に携わる者にとって、この細部こそが、単に読み取れるデータと、実際に活用できるデータとの違いを決定づけるのです。
重要なのは、そのファイルを「開く」ことではありません。重要なのは、そのファイルが、管理、会計、分析の各プロセスにエラーなく組み込めるかどうかを見極めることです。
電子請求書を例に挙げてみましょう。同じファイルの中に、仕入先情報、顧客情報、課税対象額、付加価値税、品目明細、支払条件、注文番号、そして多くの場合、読み取りを複雑にする例外事項などが混在しています。XMLでは、これらの情報は一般的な文書のように単に縦に並べられているわけではありません。それぞれが特定の位置に配置されており、その位置によって何が表されているかが明確になります。
マネージャーにとって、有用な区別は、理論的な意味での「タグ」と「属性」の区別ではありません。それは、「孤立したデータ」と「信頼できるデータ」の区別です。文脈を無視して「1000,00」とだけ見ても、ほとんど意味がありません。ファイル内の適切な箇所でそれを確認することで、それが書類の合計額なのか、課税対象額なのか、税額なのか、あるいは個々の行の金額なのかを判断することができるのです。
ここに、最初の運用上の利点があります。XMLはデータの文脈を保持します。
経験則:XMLファイルをしっかりと読むとは、単に値そのものではなく、その値が意味する内容を確認することを指します。
イタリアでは、電子請求書の普及に伴い、この課題が現実のものとなりました。「FatturaPA」フォーマットにおいて、XMLは税務書類の標準規格となりました。その結果、その解析はもはやIT部門だけの問題ではなくなりました。管理部門、経営管理、購買部門、そして意思決定のためにそのデータを利用する必要があるすべての関係者が関与することになります。
実務では、いつも同じ問題に直面します。ファイルは存在し、データもあるのですが、それを有用な情報に変換するのに時間がかかりすぎます。担当者がXMLファイルを開き、目視で確認し、値をExcelにコピーし、不統一な項目を修正し、表記が異なる仕入先名を統一し、ファイルには分析可能な形で記載されていない経費のカテゴリーを再構築しようと試みます。そのコストは、単に業務上のものだけではありません。 それは「インサイトを得るまでの時間」の損失なのです。
FatturaPAの場合、このリスクはさらに顕著になります。形式的には正しい2つのファイルであっても、行の説明が非常に不正確であったり、注文番号が不完全であったり、サプライヤーのマスターデータに異なるバリエーションが含まれていたりすると、分析上同じ問題が生じる可能性があります。その場合、問題はXMLを読み取ることではありません。問題は、有効な税務データが信頼性の低い管理データになってしまうことを防ぐことです。
よくある間違いは、XMLを単に表示するための添付ファイルとして扱うことです。企業においては、XMLを、レポートやダッシュボード、経費モデルに反映させる前に検証すべき構造化されたデータソースとして捉える方が効果的です。この段階の処理が不適切だと、財務チームは、一見正確に見えるものの、一貫性のない分類に基づいて作成された数値について議論することになってしまいます。
まず最初に問うべき適切な質問は、次の通りです:
これらは非常に具体的なチェック項目です。レポート内のサプライヤーの重複、付加価値税の誤った解釈、コストセンターの情報不足、そして月末の照合作業の遅延を防ぐために役立ちます。
ここには、技術的な読み取りとビジネス上の価値との間に隔たりが見て取れます。パーサーがファイルを読み込みます。適切に設計されたプロセスにより、クリーンで比較可能、かつ分析にすぐ使えるデータが生成されます。ELECTEのようなプラットフォームは、まさにこの隔たりを埋めるために誕生したものであり、受け取ったXMLから、より良い意思決定に役立つインサイトを引き出すまでの手作業を削減します。
単一のファイルを素早くチェックする場合、パーサーやライブラリは必要ありません。重要なのは、単に数個のフィールドを目視で確認しているだけなのか、それとも会計、レポート作成、あるいは経営管理に活用されるデータにすでに触れているのかを見極めることです。この違いは、特にFatturePAにおいては重要です。今日、手抜きで行ったチェックが、明日にはサプライヤーのデータセットに誤った行として反映されてしまう可能性があるからです。

ブラウザ、テキストエディタ、専用のビューアは、技術的な処理を設定することなくコンテンツを素早く閲覧するという具体的な課題を解決します。単体のファイルであれば、多くの場合これで十分です。 Chrome、Edge、FirefoxでXMLファイルを開いて構造を確認したり、タグを直接確認したい場合はメモ帳、ワードパッド、TextEditを使用したりできます。電子請求書の場合、専用のビューアを使用することで、ヘッダー、明細行、課税対象額、消費税などがより読みやすくなります。
要点は以下の通りです:
| ツール | 次のような場合に役立ちます | 主な制限 |
|---|---|---|
| ブラウザ | 構造の簡易目視検査 | フィールドとセクション間の一貫性を確認しない |
| テキストエディタ | タグの直接検査 | ファイルが長かったり、ネストされていたりすると扱いにくくなる |
| エクセル | 表形式による予備チェック | 階層構造や繰り返し処理の扱いが不適切 |
| 専用ビューア | 請求書や税務書類をより明確に読み取る | 分析や自動化のためのデータ準備を行わない |
書類の日付、VAT番号、請求書の合計金額、または添付ファイルの有無を確認する必要がある場合は、これらのツールが適しています。
一方、サプライヤーの比較、経費の分類、あるいはダッシュボードへのデータ反映が目的である場合、単にデータを表示するだけでは作業が遅くなり、手作業によるミスが生じやすくなります。これは、ファイルを閲覧することと、適切なタイミングで信頼できるデータにたどり着くこととの間にある、典型的なギャップです。
XMLを開くことは、レポートで使用するデータの妥当性を検証することとは異なります。
もう1つの実用的なポイントは、処理量に関するものです。10件程度なら手作業でも確認できますが、数百件ものFatturePAとなると話は別です。その場合は、繰り返し可能なワークフローや、構造化された方法で内容を読み取るツール――例えば、APIを活用して税務書類を統合的に取得・管理する仕組み――を検討した方が賢明です。
イタリアでは、繰り返し起こる問題は、何かを開くことではなく、 .xml、しかし、それが来た時にどうすべきかを理解することは .xml.p7m PEC経由。単純なXMLファイルとデジタル署名付きのファイルは区別する必要があります。後者の場合、署名を読み取り、内容を抽出し、正しいXMLを表示できるツールが必要となります。これは、 PECにおけるXMLおよびXML P7Mに関するこのガイド.
ここでは、ミスは時間のロスにつながります:
事務担当者にとって、最も役立つ手順は単純明快です:
これらの手法は、一次チェックにおいては十分に機能します。しかし、企業にとって真に重くのしかかっている問題、すなわち、しばしば不規則であったり統一性に欠けたりする税務用XMLを、受領から有用な情報を得られるまでの時間を延ばすことなく、クリーンで比較可能なデータに変換するという課題を解決するものではありません。
ファイルが溜まり始めると、手作業では対応しきれなくなります。その段階になると、コードを使ってXMLファイルを読み込むのは賢明な選択とは言えません。これは、反復作業やコピーミス、データセットの不整合を防ぐための第一歩です。

XMLを読み込むための堅実なアプローチは、常に同じ論理に従います。すなわち、パーシング、正規化、そして目的を絞った抽出です。JavaやAndroidのチュートリアルでは、正しい処理の流れは以下の通りです。 parse()、シャフトの標準化により doc.getDocumentElement().normalize() そして、フィールドの復元を通じて getElementsByTagName、テキストエディタでの単純な表示よりも安定した方法であり、以下に示すように XMLデータの読み取りに関するこの技術チュートリアル.
この処理の流れは、どの言語を選ぶかよりも重要です。正規化を省略したり、ノードの検索方法を単純化しすぎたり、タグが常に1回しか出現しないと仮定したりすると、スクリプトは一部のファイルでは正常に動作するものの、肝心なファイルでは失敗してしまいます。
外部システムと連携する必要があるプロジェクトでは、再現可能で文書化されたデータ抽出フローを構築しておくと役立つ場合があります。アプリケーションの統合に取り組む場合、特に、すでにクレンジング済みのデータセットを後続のプロセスにどのように連携させるかを理解する上で、検証済みのPostmanプロファイルを含むELECTEのAPIドキュメントが有用な参考資料となります。
以下に、ごく簡単な例を示します。目的はあらゆるケースを網羅することではなく、基本的なロジック――ファイルを開き、ノードを見つけ、値を出力する――を示すことです。
import xml.etree.ElementTree as ETtree = ET.parse("fattura.xml")root = tree.getroot()numero = root.find(".//Numero")if numero is not None:print(numero.text)Pythonは、プロトタイプ作成やデータ変換、軽量なパイプラインにおいて、多くの場合最も高速な選択肢となります。多数のXMLファイルを読み込み、少数のフィールドを抽出してCSVやJSON形式で保存する必要がある場合に最適です。
const xmlString = `<fattura><Numero>123</Numero></fattura>`;const parser = new DOMParser();const xmlDoc = parser.parseFromString(xmlString, "application/xml");const numero = xmlDoc.getElementsByTagName("Numero")[0];console.log(numero.textContent);このアプローチは、ページ上での簡易テストや小規模な社内ツールには有用です。シンプルなインターフェースには適していますが、構造化されたバックオフィスの業務フローにはあまり適していません。
const fs = require("fs");const xml2js = require("xml2js");const xml = fs.readFileSync("fattura.xml", "utf8");xml2js.parseString(xml, (err, result) => {if (err) throw err;console.log(result.fattura.Numero[0]);});サーバーサイドの開発を行い、自動化を構築したい場合、Node.jsは依然として実用的な選択肢です。その利点は、XMLの読み取りをファイルシステム、処理キュー、内部サービスと容易に統合できる点にあります。
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse("fattura.xml");doc.getDocumentElement().normalize();NodeList lista = doc.getElementsByTagName("Numero");if (lista.getLength() > 0) {System.out.println(lista.item(0).getTextContent());}Javaは、エンタープライズ環境や業務管理システム、ミドルウェアの分野でよく利用されています。ここで重要なのは、単にデータを読み取るだけでなく、予測可能かつ保守しやすい方法でそれを行うことです。
library(XML)doc <- xmlParse("fattura.xml")numero <- xpathSApply(doc, "//Numero", xmlValue)print(numero)Rは、パーシングが分析作業の一部である場合に有用です。次のステップが統計分析やデータ前処理であるなら、すべてを同じ環境で処理することができます。
もしあなたのチームが毎週同じファイルを開き、同じチェックを繰り返しているのであれば、それはすでに自動化の領域に入っています。
真のメリットは「コードを使ってXMLを読み込むこと」ではありません。人々の手間のかかる作業を軽減し、一貫性のあるデータセットを生成するワークフローを構築することにあります。
ファイルが1つではなくなると、深刻な問題が生じ始めます。単一のFatturaPAであれば、ほとんどの場合、処理可能です。しかし、数ヶ月分の書類、複数の仕入先、記入方法が統一されていない項目、埋め込まれた添付ファイルなどを統合しなければならない場合、困難が生じます。
イタリアの中小企業において、最も一般的なケースは単体の「メガファイル」ではなく、バッチ処理である。 年間で輸出される仕入請求書は、ヘッダー、明細行、支払データ、base64形式の添付ファイルを含め、4,200件の請求書に対して 38万を超えるノードを持つ構造を生成する可能性があります。このようなシナリオにおいて、問題はドキュメントを開くことではありません。異種混在するXMLを一貫性のあるデータセットに変換することにあります。
ここで、ビジネスに及ぼす影響のある技術的な選択が関わってきます。.NET環境において、Microsoftは、XmlDocumentがドキュメントをメモリに読み込み、読み取りや変更に有用である一方、大容量のファイルや読み取り専用操作の場合は、RAMの過剰な消費を避けるために、ストリーミングパーサーやXPathDocumentといったより効率的なアプローチを採用すべきであると指摘しています。これは、XmlDocumentおよびXPathDocumentを用いたXMLの読み取りに関するMicrosoftのドキュメントにも明記されています。
具体的には:
トレードオフは単純です。メモリ内モデルなら開発が速く進みます。ファイルの数が増えたり、容量が大きくなったりした場合、ストリーミングモデルの方が本番環境での安定性が高くなります。
多くのチームはXSDによる検証だけで終わってしまいます。それは有用ですが、それだけでは不十分です。ファイルがスキーマに準拠していても、下流で不正なデータが生成される可能性があります。
実務における代表的な例:
| 制御の種類 | 何を検証するのか | なぜ必要なのか |
|---|---|---|
| 構造的 | タグ、形式、階層 | 構文解析の誤りを防ぐ |
| セマンティック | データの論理的一貫性 | 誤った分析を避ける |
| 稼働中 | レポート作成に役立つフィールドの有無 | 使用できないデータセットを避ける |
最も見抜けにくいケースは次のようなものです。書類の「合計金額」が形式的には有効であるものの、各行の合計と一致しない場合です。これは、例えばサプライヤーの管理システムにおける四捨五入のルールが原因である可能性があります。あるいは、形式的には認められているVATコードであっても、取引の性質と整合していない場合もあります。
形式的には正しいファイルであっても、レポートの正確性を損なう可能性があります。
さらに、FatturaPAにはもう1つ、よく知られた落とし穴があります。「DatiBeniServizi」タグには自由記述が含まれています。同じ費用でも、明確な表現、略語、あるいは難解な表現など、さまざまな形で記載される可能性があります。正規化のプロセスを導入しなければ、支出カテゴリごとの分析は信頼性を欠くものになってしまいます。
そのため、本格的なデータフローにおいて、ファイルの読み取りはあくまで第1段階に過ぎません。第2段階は常に、整合性とクリーンさを確保するためのルールセットです。データの品質を守るのはその段階であり、パーサーではありません。
正しく読み込まれたXMLファイルは、それだけでは有用なデータセットとは言えません。それは構造化された文書に過ぎません。分析、比較、グループ化、ダッシュボード作成を行うには、ほとんどの場合、処理しやすい形式に変換する必要があります。
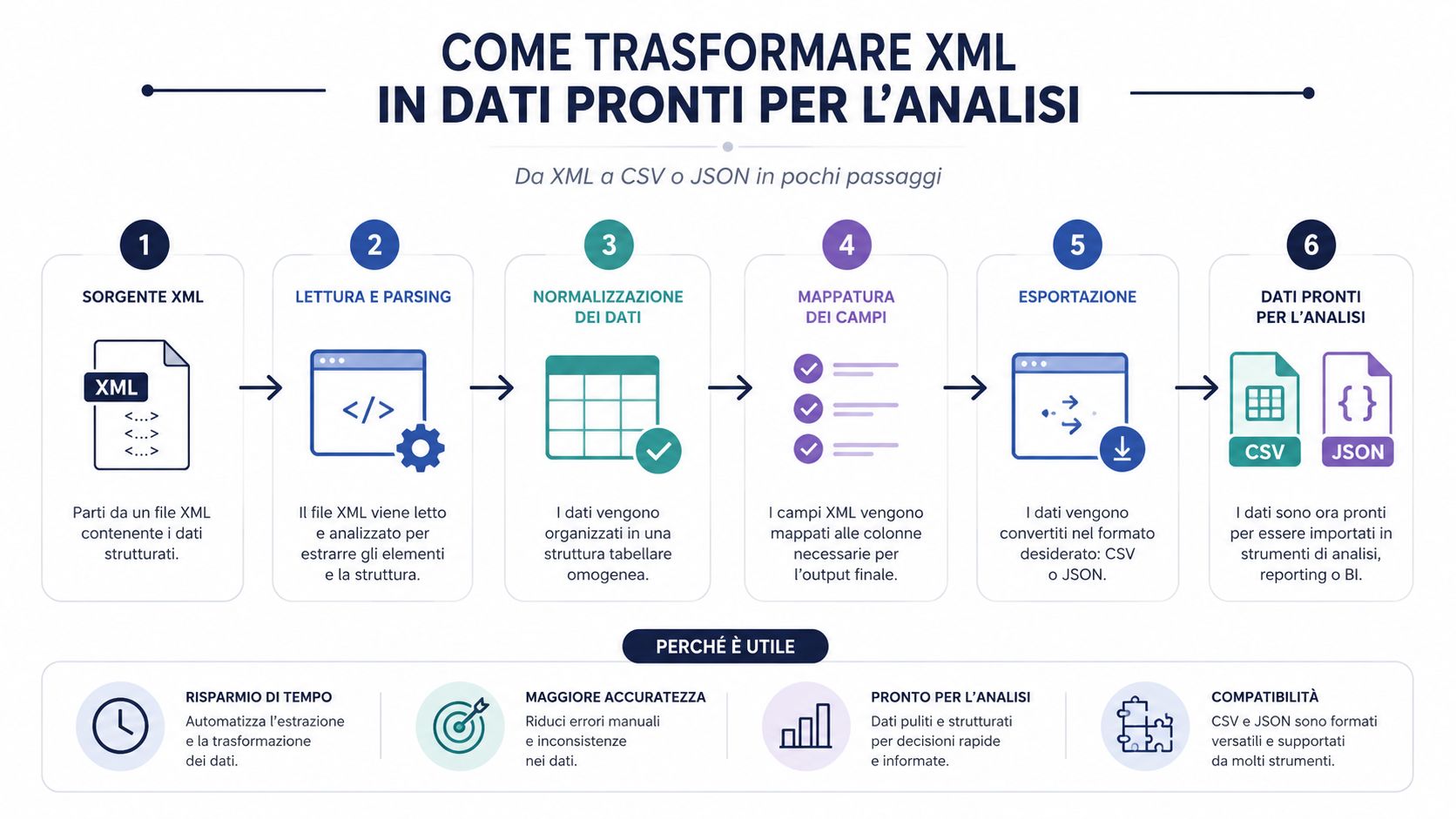
多くのプロセスでこの点が過小評価されています。ボトルネックとなるのは、純粋なパーシングであることはめったにありません。まともなライブラリであれば、XMLの読み込みは瞬時に行われます。時間がかかってしまうのは、構造の解釈、必要なフィールドの抽出、クリーニング、正規化、そして分析ツールへの読み込みといった工程です。
だからこそ、CSVやJSONへの変換は単なる「便利さ」のためだけのものではありません。これは業務上の重要な工程なのです。この段階を飛ばして生データを直接処理すると、ほとんどの場合、手作業でのチェックやその場しのぎの列作成、再現が難しいロジックに頼ることになってしまいます。
XMLとスプレッドシートを頻繁に扱う人にとって、XMLからExcelへより整理された形で移行する方法について解説したこのガイドは、役立つ参考資料となるでしょう。
適切な形式は、そのデータをその後どのように活用するかによって異なります。
CSVは、文書ごとに1行、あるいは請求書の明細ごとに1行といった形式でデータを整理し、その後Excel、Power Query、またはBIを活用したい場合に適しています。
Pythonの例:
import xml.etree.ElementTree as ETimport csvtree = ET.parse("fattura.xml")root = tree.getroot()with open("fatture.csv", "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(["numero", "data"])numero = root.findtext(".//Numero")data = root.findtext(".//Data")writer.writerow([numero, data])メリットはシンプルさです。デメリットは、階層をどのように平坦化するかを慎重に決定する必要がある点です。請求書に複数の明細行がある場合、粒度と結合キーについて明確な判断が必要です。
JSONは、階層構造の一部を維持したい場合に適しています。
JavaScriptの例:
const record = {numero: "123",data: "2024-01-15",righe: [{ descrizione: "Servizio", importo: "100.00" }]};console.log(JSON.stringify(record, null, 2));次のステップがAPI、データレイク、またはネストされたオブジェクトをうまく扱うアプリケーションである場合に、これを使用してください。
参考になる実用的なルールをご紹介します:
XMLファイルはコンテナです。CSVやJSONは、その内容を実際に処理可能にするフォーマットです。
インサイトを得るまでの時間を短縮したいのであれば、ここに力を注ぐべきです。より使いやすい可視化ツールを見つけることではなく、安定的で再現性のある変換方法を確立することに注力すべきなのです。
ファイルの読み取り、検証、変換が完了すると、業務の性質が変わってきます。もはやタグとの格闘に追われることはありません。ようやく、コスト、異常値、サプライヤー、支出項目、業務の傾向について検討できるようになるのです。
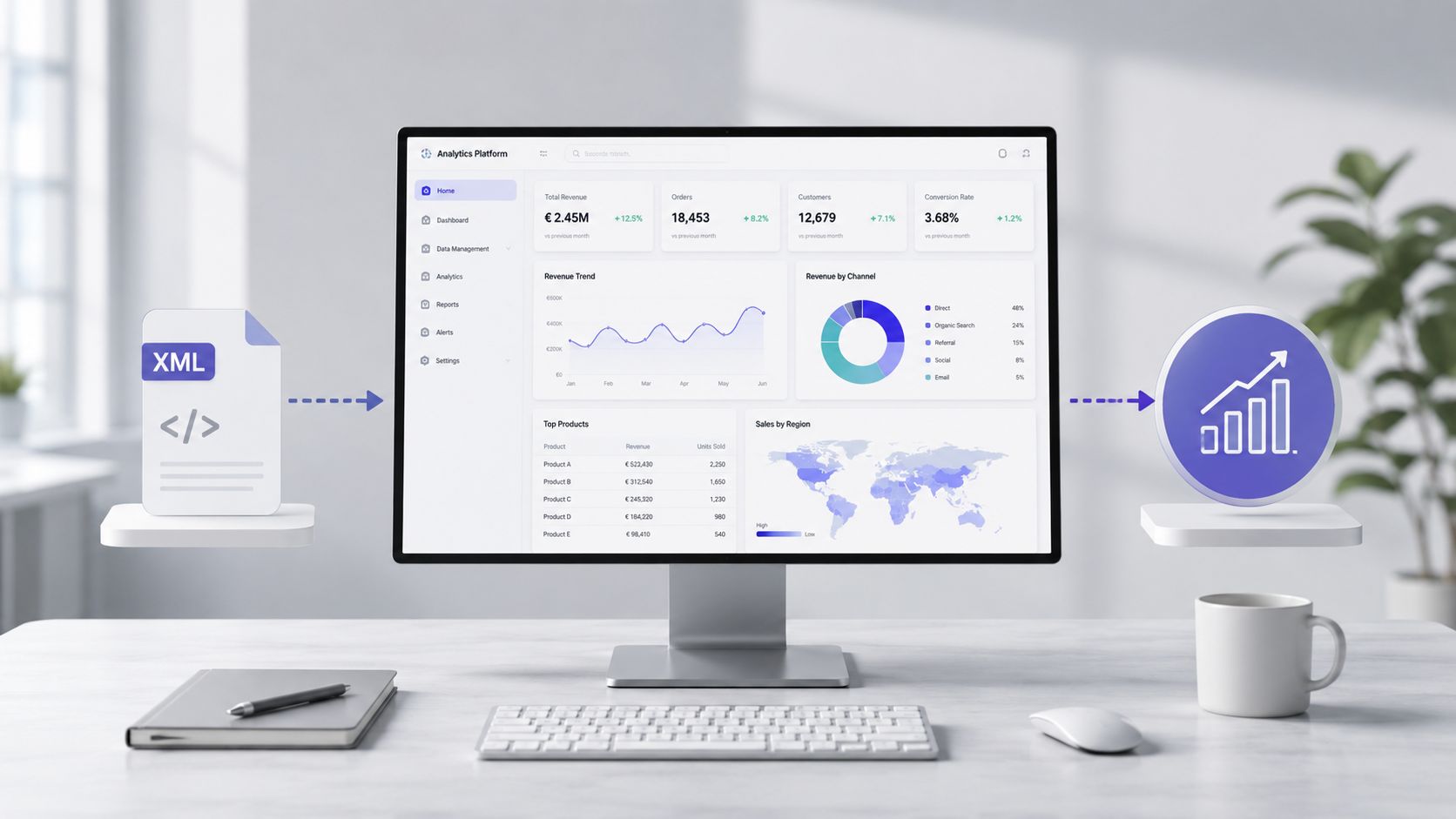
実際の業務において、価値はパーシングにかかる時間にあるわけではありません。その価値は、生のファイルから、意思決定の根拠となる情報に至るまでの時間にあるのです。手動のワークフローでは、担当者がドキュメントを開き、構造を把握し、フィールドを抽出し、値をクリーンアップし、テキストを正規化してから、レポートを作成しなければなりません。これは脆弱なプロセスです。
FatturaPAにおける典型的な例として、「DatiBeniServizi」の自由記述欄が挙げられます。同じサービスであっても、供給業者によってその記述方法は多岐にわたります。一貫性のあるマッピングを行わずにそのデータをインポートすると、コストカテゴリ別の分析において不要な集計結果が生じることになります。
そのため、アナリティクス・プラットフォームを導入する前に、以下のデータ前処理の層が必要となります:
この段階を適切に行えば、どの分析プラットフォームもより効果的に機能します。このステップにおける意思決定や視覚化の側面についてさらに詳しく知りたい場合は、「データを用いたストーリーの構築方法」に関する資料が役立ちます。この資料では、整理されたデータセットが、意思決定者にとって有益なストーリーへとどのように変貌するかが示されています。
この時点で、XMLファイルは単なる技術的な問題ではなく、インサイトを生み出すための素材となります。適切に整備されたデータセットは、経費分析、トレンドのモニタリング、乖離の特定、例外の把握に活用できます。
この「ラストワンマイル」に適したプラットフォームを選ぶには、最新のビジネスアナリティクスソフトウェアが提供する機能と、スプレッドシートやピボットテーブルに依存した純粋に手作業によるワークフローとを比較検討すると参考になるでしょう。
ここで重要な基準は、「XMLを開くことができるか?」ということではありません。それは最低限の条件に過ぎません。重要な質問は別のものです:
| 質問 | なぜ重要なのか |
|---|---|
| データはすでに整理された状態で入力される | 誤ったデータに基づく正確な洞察を避ける |
| カテゴリは一貫している | 本当に業者や期間を比較していますか |
| 異常はすぐに明らかになる | 手作業によるチェックにかかる時間を削減する |
| このレポートは、ビジネス部門および財務部門の担当者でも理解しやすい内容となっています。 | 意思決定を迅速化する |
未熟なプロセスと成熟したプロセスの違いは、XMLファイルを読み取る能力にあるわけではありません。その違いは、それらを信頼性の高いデータベースに変換し、チームが毎回同じ作業を繰り返す必要がないようにする能力にあるのです。
ビジネスに役立つ形でXMLファイルを読み込む必要がある場合は、このチェックリストを参考にしてください。これはどんな技術的な定義よりも具体的であり、時間を無駄にすることなく適切な方法を選ぶのに役立ちます。
常に同じアプローチを取り続けるのは避けましょう。ブラウザ、エディタ、ビューアは、ざっと確認するには適しています。パーサーやスクリプトは、ファイルを反復処理に活用する場合に役立ちます。表示とデータ処理を混同してしまうと、脆弱な基盤の上にレポートを構築してしまうリスクがあります。
ファイル .xml.p7m これには、署名処理に関する特定のステップが必要となります。内容がPECから送信されたものである場合、この確認は単なる付随的な作業ではありません。これは、文書を正しく読み取るための重要な手順の一部です。
スキーマに準拠しているからといって、データセットの品質が保証されるわけではありません。合計値の不一致や税務分類の曖昧さといった論理的な不整合こそが、分析を台無しにする最も多い要因です。意味的なチェックこそが、「許容範囲内」のファイルと信頼できるデータを分ける鍵となります。
CSVやJSONは単なる表面的な変更ではありません。これらは、XMLを分析ツール、スプレッドシート、パイプライン、レポートで処理可能な形式に変換する重要な段階です。この変換を早期に定義すればするほど、手作業やその場しのぎの対応を減らすことができます。
あなたの目的は、XMLファイルを読み込むことではありません。不純なデータでシステムを汚染することなく、有用な洞察を得ることなのです。もしデータフローから一貫性のあるデータセットが生成されない場合、問題は最終的なダッシュボードにあるのではありません。そのはるか上流にあるのです。
実際には、新しいプロジェクトを始める前に、このミニチェックリストを活用することができます:
すでに準備されたデータを明確で実用的なインサイトに変えたい場合、ELECTEは中小企業が「整理されたデータセット」から「インテリジェントなレポート」へと移行できるよう支援します。そのアプローチは、技術的な知識のないチームでも容易に活用できます。これは、業務データと意思決定の間のギャップを埋める最も迅速な方法です。

.svg)
.svg)
.svg)
.webp)





