

こんな経験はありませんか。業務管理システム、ECフィード、銀行システム、あるいは社内APIからXMLファイルを受け取ります。その中には注文、商品明細、取引履歴、マスターデータ、あるいは有用なイベント情報が含まれていることは分かっています。しかし、ファイルを開いてみると、目に入るのはタグ、ノード、属性ばかり。この場合、問題はデータそのものではありません。問題はフォーマットなのです。
多くの企業にとって、XMLからExcelへの変換は、技術的なデータ交換と実務的な分析を分ける重要なステップです。 イタリアでは、この問題は極めて現実的な課題となっています。イタリアのIT企業の68%がデータ交換にXMLを使用していますが、分析のためにExcelに変換しているのはわずか42%にとどまり、26%の効率のギャップが生じています(conversiontools.io)。このギャップは、レポート作成の遅延、手作業の増加、そして重要な数値を分析する時間の減少につながっています。
Excelは、多くのチームにとって依然として自然な選択肢です。財務部門は管理に、小売部門はカタログと注文の照合に、アナリストはデータのクリーニング、フィルタリング、および迅速なレポート作成にExcelを活用しています。重要なのは、単にデータを変換することだけではありません。重要なのは、データフローの構造、量、頻度に応じて適切な方法を選択することです。もし選択を誤れば、ファイルは取り込めますが、プロセスは拡張性がありません。
アナリストが受注システムからXMLデータをエクスポートする。財務担当者が明細や取引履歴を構造化された形式でダウンロードする。運用チームがERPやAPIからデータをエクスポートする。皆、同じ状況からスタートする。データは存在しているが、ビジネスに必要な形式でまだ読み取れる状態ではないのだ。
XMLは、システム間の連携には最適です。しかし、値の比較、ピボットテーブルの作成、異常の検出、あるいは予測の作成を行う際には、最適な形式とは言えません。そこでExcelの出番となります。使い慣れたツールであり、操作も迅速で、何よりも多くの意思決定プロセスがそこで形作られる場なのです。
難しいのは、XMLをExcelに変換する「唯一の正しい方法」が存在しないという点です。単純なファイルであれば、Power Queryで問題なく変換できます。階層構造を持つXMLの場合は、XSLTが必要になることがよくあります。大量のデータや複数のファイルを扱う場合は、Pythonの利用が適しています。短期間のタスクについては、オンライン変換ツールを検討するチームもありますが、その場合は制御性やセキュリティ面で明らかな妥協を強いられることになります。
最適な選択は、構造の複雑さ、ファイル数、そして求められる自動化のレベルという3つの実用的な要素によって決まります。インポート前にこれらを考慮しておけば、すぐに時間を節約できるだけでなく、データがレポートや意思決定の基盤となる段階になってからのミスを減らすことができます。
多くの企業チームにとって、Power Queryは最も確実な出発点となります。Excelに標準搭載されており、コーディングは不要で、普段使っている作業環境から離れることなく、XMLをテーブルに変換することができます。
基本的な手順は以下の通りです:
標準的なITデータセットでは、このアプローチの成功率は92%ですが、エラーの75%は複数のネームスペースに起因しており、この問題は多くの場合、Power Queryの詳細設定(Beyond Japan)で解決できます。
他の表形式のファイルも頻繁に扱う場合は、ExcelでのCSVファイルの管理に関するこの基本ガイドが役立つでしょう。データのクリーニング、型指定、そして最終的な読み込みの手順は、非常に似ているからです。
Power Queryは、次のような場合にうまく機能します:
実用的なヒント:ノードを展開したら、すぐに列の名前を変更しましょう。最後まで待っていると、同じ名前のフィールドを混同してしまうリスクが大幅に高まります。
Power Queryは魔法ではありません。XMLのネストが深い場合、段階的な展開を行うと、テーブルの重複、行の重複、あるいは親と子のエンティティ間の関係が不明確になることがあります。また、特に日付、ブール値、金額などのフィールドが、誤った型でインポートされてしまうこともよくあります。
次の2つの確認を行うことで、多くのトラブルを未然に防ぐことができます:
月次レポート、業務上の照合、および随時行う分析においては、Power Queryが最適な選択肢となることがよくあります。技術的なファイルから読みやすい表へと、素早く変換してくれます。ビジネスにおけるメリットは明白です。準備に費やす時間を削減し、結果の分析に充てる時間を増やすことができるのです。
意思決定者に迅速にレポートを提出することが目的であれば、まずこの方法を試してみるのがほぼ常に最善の策です。
Power Queryがファイルをインポートする際、そのロジックを正しく解釈できない場合は、より詳細な制御が必要になります。XSLTはまさにこのニーズに応えるものです。XSLTは、最終的なテーブルがどのような形になるべきかを推測しようとはしません。それを定義するのはあなた自身です。
XSLTは、階層構造を持つXMLや、標準的な形式ではない構造のフィード、そして固定されたルールに従う必要がある出力レイアウトにおいて特に有用です。最終的なExcelシートが企業の厳格な書式要件を満たす必要がある場合、この方法はドラッグ&ドロップよりもはるかに信頼性が高いと言えます。
このアプローチでは、例えば次のようなテンプレートを使用してスタイルシートを作成します。 <xsl:template match='*'>、Excel XMLワークシートを生成するために。 検証済みのXMLファイルにおける成功率は88%です. 最もよくある問題は明らかです: 失敗の60%は文字列が長すぎることに起因し、30%はブール値のデータ損失によるものである. 性能面では、 XSLTは、100MBのデータセットに対して、ドラッグ&ドロップよりも3倍効率的です (TechRepublic).
XSLT を使えば、事前に次のように指定できます:
| 要件 | Power Query | XSLT |
|---|---|---|
| コードなしで素早くインポート | 非常に適している | あまり適していない |
| カラムとレイアウトの正確な制御 | 限定 | すごく強い |
| カスタムルールの管理 | おいしいけど、見た目が…… | すごく強い |
| 非標準XMLにおける再現性 | 変数 | 適切に設計されていれば高い |
ここで重要なのは、初期の利便性ではありません。重要なのは再現性です。毎月同じXMLを受け取り、常に同じ出力を得たい場合、優れたスタイルシートがあれば予期せぬ結果を最小限に抑えることができます。
複雑な変換から始める必要はありません。実際には、次のように進めるのが良いでしょう:
実用的なヒント:XMLファイルに任意のフィールドが含まれている場合は、値が欠落している場合にも対応できるテンプレートを用意しましょう。そうすることで、データの不整合やファイル間の結果のばらつきを防ぐことができます。
XSLTは、データをExcelに取り込む前に標準化する必要がある場合に最適な選択肢です。これは、コンプライアンス対応、規制に基づくレポーティング、ERPからのエクスポート、あるいはスキーマは判明しているものの構造が複雑すぎて視覚的なインポートではきれいに処理できないようなデータフローにおいて、よく見られるケースです。
トレードオフは明白です。初期段階ではより多くの時間を費やすことになりますが、その代わりに運用の安定性が得られます。分析プロセスがデータセットの特定の形式に依存している場合、この方法が最も専門的なアプローチとなることがよくあります。
XMLをExcelに変換する作業が日常業務となると、手作業による手順はもはや現実的ではなくなります。これは単なる利便性の問題ではなく、業務遂行能力の問題です。そこでPythonの出番となります。
最大の利点は、単にXMLを読み込むことだけではありません。取り込み、検証、クリーニング、正規化、そして最終的にExcelやその後の分析工程で活用できる形式への書き出しまで、一連の処理フローを構築できる点にあります。
実務上、これは次のような意味になります:
FatturaPAのような大量のXMLバッチ処理の場合、この問題は既知のものです。 ある調査によると、無料ツールの72%は電子請求書の構造を適切に処理できていない。同表は、 Pythonで pandas.read_xml カスタム機能を活用することで、こうした制限を克服し、そうでなければ手作業のままになってしまうワークフローを自動化することができます IT分野の中小企業の55% (マイクロソフトのサポート).
アプリケーション統合に携わる方々にとって、検証済みのPostmanELECTE APIは、こうしたワークフローの自然な流れを如実に示しています。ファイルは手動で開く必要がある添付ファイルとして留まるのではなく、より広範なパイプライン内での自動化されたプロセスへと変化するのです。
複雑なアーキテクチャから始める必要はありません。多くの場合、シンプルなパイプラインで十分です:
pandas.read_xml.xlsx あるいは中間形式で重要なのは、読み取りそのものではなく、読み取りに関するロジックです。企業のXMLファイルが完璧なことはめったにありません。ネームスペースやオプションのノード、重複するフィールド、不適切な値などが含まれているものです。Pythonを使えば、どの段階でも自由に手を加えることができます。
Pythonは、以下の3つのシナリオにおいて、手動による方法の限界を克服します:
毎日数十から数百ものファイルが届く場合、一つひとつを手作業でチェックする余裕はありません。スクリプトを使えば、ワークフロー全体を効率化できます。
類似したファイルにわずかな構造上の違いがある場合、Power Queryでは頻繁に手動での対応が必要になりがちです。Pythonでは、例外処理、フォールバック、条件付きマッピングを導入することができます。
出力を生成する前に、重複、空欄、不適切な日付、または欠落したコードをチェックすることができます。ビジネスシーンにおいては、これ自体がデータ変換そのものよりも重要な場合が少なくありません。
実用的なアドバイス:処理したファイルや検出されたエラーのログは、必ず保存しておきましょう。財務部門や運用部門から「レポートにレコードが欠落しているのはなぜか」と尋ねられた際、ログがあれば、時間のかかる手作業による確認を省くことができます。
Pythonはより高度な技術的スキルが求められます。たまに分析を行う程度であれば、過剰な仕様かもしれません。しかし、処理量が多く、繰り返し行われるプロセスにおいては、制御性、拡張性、信頼性のバランスが最も優れた手法です。
ビジネス上のポイントは明確です。XMLからExcelへの変換を繰り返し可能なパイプライン化すれば、毎週発生するデータ準備の隠れたコストを支払う必要がなくなります。
オンライン変換ツールが普及しているのには明確な理由があります。それは、そのスピードの良さです。ファイルをアップロードし、出力形式を選択し、結果をダウンロードするだけです。簡単なテストや機密性の低いファイルには便利かもしれません。しかし、その手軽さの裏には、多くの場合、深刻な機能上の制限が隠されているのです。
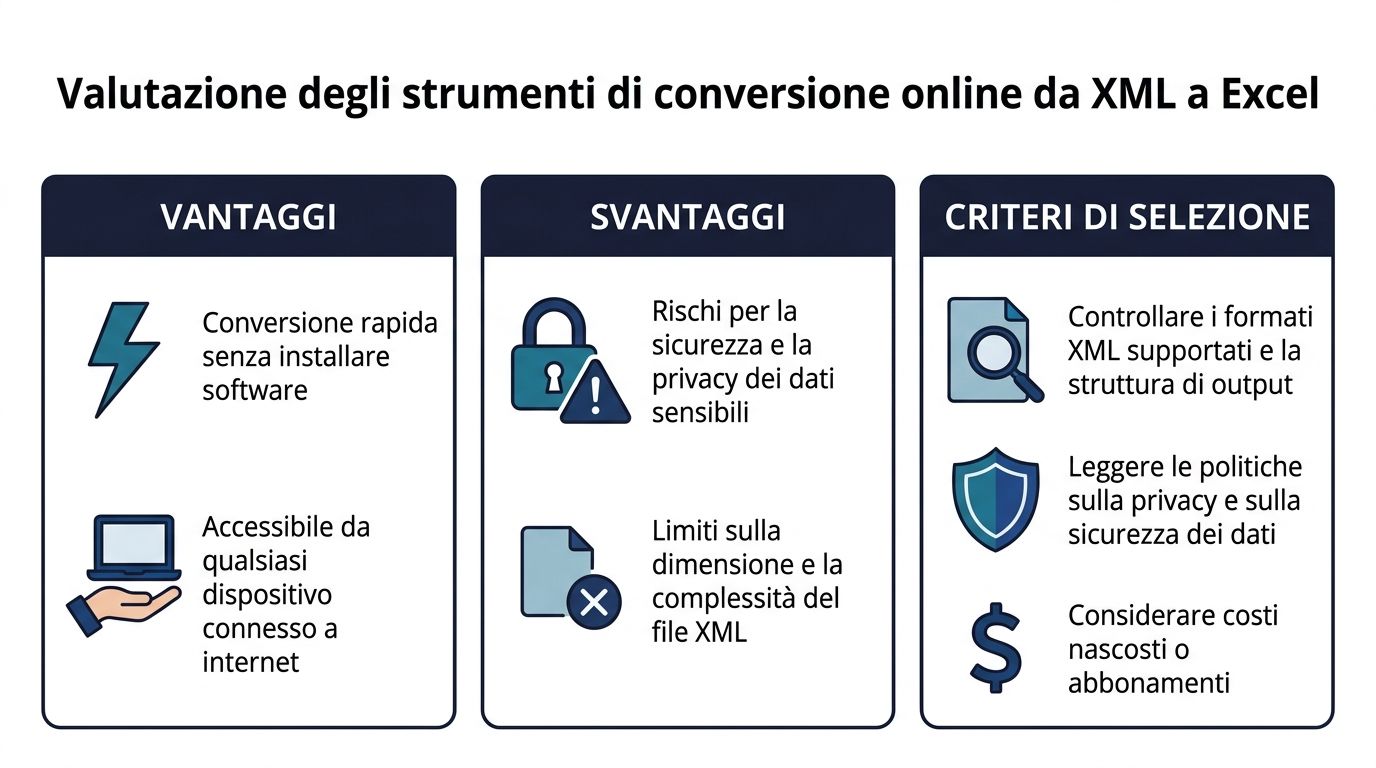
最大のメリットは明らかです。インストールも設定も不要で、すぐに利用できます。そのため、単純なファイルの処理や、その場での構造確認などに便利です。
しかし、ファイルが大きかったり機密性が高かったりすると、状況は一変します。Excelには1,048,576行という制限があり、大規模なXMLファイルの場合、62%の確率でクラッシュが発生します。そのため、多くのユーザーは最大100GBのファイルを処理できるオンラインコンバーターを利用するようになっています。 一方、Excel 2010のPower Queryは、手動での方法と比較してインポート時間を70%短縮しており、ファイルサイズが管理可能な範囲で、かつセキュリティが重視される場合には、このネイティブ機能がはるかに競争力のある選択肢となっています(Sonra)。
オンライン変換ツールを利用する前に、次の3つの点を確認しておくことをお勧めします:
データの機密性
ファイルに顧客情報、財務データ、取引履歴、または規制対象文書が含まれている場合、外部サービスへのアップロードには細心の注意が必要です。
構造的な忠実度
一部のツールは、単純なXMLをうまく変換できるものの、複雑な階層構造を、使いにくい表形式に変換してしまう。
プロセスの再現性
オンラインツールは、一度きりの利用なら問題ありません。しかし、その作業が繰り返し行われるようになると、保存されたルールや自動チェック機能がないことがすぐに負担となります。
合理的な使用が認められるケースもあります:
| シナリオ | 賢明な選択 |
|---|---|
| テスト用ファイルまたは重要でないファイル | はい、それで十分です |
| 単発分析 | はい、構造が単純であれば |
| 規制対象データまたは機密データ | 避けたほうがよい |
| 複数行を含む定期的なデータフロー | あまり適していない |
専門家の見解は単純明快です。たまに速さを重視したいだけなら、オンライン変換ツールで事足りるでしょう。しかし、信頼性の高い処理を求めるのであれば、それが最良の選択となることはほとんどありません。
XMLファイルは正しくインポートされたように見えても、実際には分析に利用できない場合があります。これは、ERPからのエクスポート、APIフィード、電子請求書、製品カタログ、レガシーシステムなどでよく発生します。インポートは明らかなエラーなく完了しますが、Excelを開くと、重複行や空のフィールド、テキストとして読み込まれた日付、見出しと詳細の関連付けが失われているといった問題が発生することがあります。
重要な点はここです。誤りは単にインポートの段階で生じるわけではありません。ビジネスに必要な文脈を損なうことなく、階層構造をテーブル形式に変換する方法の選択において生じるのです。
繰り返し発生する問題は、主に4つある。管理されていないネームスペース、深いネスト構造、一貫性のないデータ型、そして最終ファイルのサイズを肥大化させるフラット化だ。これらはそれぞれ、具体的な影響を及ぼす。数値が合わないレポート、役に立たないピボットテーブル、検証時間の長期化、そして意思決定者に提出する前に手動での修正を必要とする分析などが挙げられる。
信頼性の高いプロセスを目指すのであれば、こうしたケースを例外としてではなく、設計上のルールとして扱うべきである。
多くの企業向けXMLでは、ドキュメントの各セクションに異なるプレフィックスが使用されています。Power Query、スクリプト、またはXSLTトランスフォーマーがこれらを明示的に読み込まない場合、ファイル自体は有効であっても、一部のノードが存在しないものとみなされてしまいます。
実用的な解決策:
この確認作業により、よくある問題を未然に防ぐことができます。インポートは成功したように見えますが、注文行、住所、商品属性などのセクション全体が欠落していることがあります。
親子構造や1対多の構造は、最も注意が必要な点です。すべてを1つのシートに展開すると、Excelは上位レベルのデータを各子ノードごとに複製してしまいます。その結果、ファイルサイズが大きくなり、処理速度が低下し、可読性も低下してしまいます。
実用的な解決策:
実際には、注文、注文行、およびマスターデータは、単一のフラットなシートとして扱うよりも、関連付けられたテーブルとして扱う方が効率的です。
技術的に有効なXMLであっても、日付形式が混在していたり、数値の区切り記号が異なっていたり、ブール値が文字列として扱われていたり、空の値が含まれていたりすることがあり、これらはExcelで正しく解釈されません。その影響は後になって現れます。フィルタリングの誤り、計算結果の誤り、ソート順の不整合などです。
実用的な解決策:
これは、手作業による繰り返しの修正を減らし、レポートの信頼性を高めるため、真っ先に自動化すべきチェック項目のひとつです。
問題は必ずしも元のXMLファイルのサイズにあるわけではありません。多くの場合、Excelファイルのサイズが大きくなるのは、フラット化の過程で関係性が正しく反映されていないためです。各明細行に重複したマスター列が含まれてしまうため、パフォーマンスやファイルの読み込み時間、分析の精度に影響を及ぼします。
実用的な解決策:
単純なXMLであれば、1つのテーブルで十分です。しかし、複雑なXMLの場合、ほとんどの場合そうはいきません。
最も効果的な方法は、Excel内でシンプルな関係構造を維持することです。具体的には、主要なエンティティ用のテーブル、詳細用のテーブル、参照用のテーブルをそれぞれ用意します。こうすることで、データの意味合いを保ち、重複を削減し、ピボットテーブルやチェック機能、より安定した分析モデルに対応できる状態を整えることができます。
ここで、単発の変換と業務の自動化との違いが浮き彫りになります。ワークフローが毎週、あるいは毎日繰り返される場合、構造上のミスはすべて、時間の浪費、手作業によるチェック、レポート作成の遅延につながります。そのため、問うべき正しい問いは、「このXMLをExcelでどう開くか」だけではなく、「処理量の増加、例外、新しいファイル形式の登場があっても、信頼性を維持できる変換をどのように構築するか」なのです。
これは、エンドツーエンドの統合に向けた準備段階でもあります。Excelや中間テーブルで適切に正規化されたXMLデータは、自動パイプラインやダッシュボード、ELECTE分析プラットフォームへの取り込みが容易になります。こうした環境では、初期データの構造の質が、最終的な意思決定の質に直接影響を及ぼします。
適切な手法を選ぶことは、厳密な意味での技術的な問題ではありません。それはプロセス上の判断です。適切な手法を採用することで、手作業やミスを減らし、レポート作成にかかる時間を短縮できます。
Power Query
シンプルなファイルや中規模のファイル、定期的なインポート、そしてExcel上で直接作業したいビジネスユーザーに最適な選択肢です。
XSLT
出力に厳密なルールが求められ、XML構造をきめ細かく制御する必要がある場合に最適な選択肢です。
Python
バッチ処理、頻繁な処理、またはより大規模なパイプラインの一部として処理を行う場合に採用すべき手法。
オンラインツール
機密情報を含まない、重要度の低いデータの簡易変換にのみ適しています。
XMLからExcelへのデータ変換を評価する際、私は以下の4つの点を考慮します:
| 質問 | もし答えが「はい」なら | 推奨される方法 |
|---|---|---|
| ファイルの受信は不定期ですか? | スピードが重要だ | Power Query |
| 出力は標準化される必要がありますか? | 管理が重要 | XSLT |
| ファイルの数が多く、繰り返し発生する問題ですか? | スケーラビリティが重要だ | Python |
| ただの簡単なテストですか? | 即効性が重要だ | オンライン |
効率化はあくまで第一段階に過ぎません。真のメリットは、選択した手法が業務上のプレッシャーがかかった状況下でも信頼性を維持できるときに初めて発揮されます。
適切に変換されたXMLファイルは、業務の効率化につながります。そして、データが分析、管理、レポート作成という信頼性の高いプロセスに組み込まれることで、ビジネス成果がもたらされます。
多くの企業において、Excelは依然としてデータを検証し、コメントを付け、財務、業務、営業部門と共有するための中心的なツールとなっています。この段階では、特に変換されたファイルが定期的なレポート作成に活用される場合、レイアウト、数式、チェック項目を標準化することが重要です。この段階のために整然とした基盤が必要な場合、これらのExcelテンプレートを活用することで、不要なばらつきを減らし、分析結果の可読性を高めることができます。
しかし、その限界はすぐに明らかになる。ファイル数が増えたり、異なるソースからファイルが送られてきたり、レポートの更新頻度が高くなったりすると、Excelのみに依存したプロセスは、手作業の工程や土壇場での修正、管理が難しいバージョン管理といった問題に再び直面することになる。
エンドツーエンドの自動化を実現するには、次のステップとして専用のプラットフォームが必要です。
単純なXMLからExcelへの変換から、より拡張性の高いプロセスへと移行したい場合は、 ELECTE は、データ準備、分析、レポート作成を単一の環境で統合します。単にXMLをExcelで開くだけでなく、そのデータフローを予測、リスク監視、意思決定に役立つ自動レポートへと変換することを目的とする場合、これは理にかなった選択です。

.svg)
.svg)
.svg)






