

Je komt deze situatie vast wel eens tegen: je hebt een bedrijfssoftwarepakket, misschien een CRM-systeem, een paar Excel-bestanden die via e-mail worden rondgestuurd, en dan zegt iemand tegen je dat je, om ‘serieuze analyses’ te kunnen uitvoeren, moet kiezen tussen een data lake en een data warehouse. Op dat moment gaat het gesprek meteen over technologie, maar het echte probleem ligt elders. Heb je echt een nieuwe data-architectuur nodig, of moet je gewoon de gegevens die je al hebt leesbaar en bruikbaar maken?
Voor een mkb-bedrijf gaat het om meer dan alleen terminologie. Een verkeerde keuze leidt niet alleen tot technische complexiteit. Het zorgt ook voor langdurige projecten, afhankelijkheid van consultants, rapporten die te laat binnenkomen en investeringen die maar moeilijk tot betere beslissingen leiden. Maar als er niets wordt ondernomen, blijft het bedrijf op goed geluk varen.
Het gaat er niet om het jargon van de leveranciers te leren. Het gaat erom te begrijpen welke oplossing het beste aansluit bij je bedrijf, je budget en de expertise die je daadwerkelijk in huis hebt. Hier vind je een praktische gids om het debat tussen data lake en data warehouse te bekijken vanuit het perspectief van iemand die kosten, toegankelijkheid en operationeel rendement op elkaar moet afstemmen.
De druk om ‘iets met de gegevens te doen’ is tegenwoordig reëel. De cijfers nemen toe, de bronnen vermenigvuldigen zich, en managers vragen om snellere prognoses, dashboards en waarschuwingen. Ondertussen duiken er termen op die je lijken te dwingen tot een onmiddellijke architecturale beslissing.
Voor veel kleine en middelgrote ondernemingen zit hier echter precies de valkuil. Ze doen je geloven dat de eerste stap bestaat uit het kiezen tussen twee infrastructuurmodellen, terwijl het echte probleem vaak veel concreter is: versnipperde gegevens, inconsistente formaten, handmatig opgestelde rapporten en niemand die de tijd heeft om orde op zaken te stellen.
Er zijn andere vragen die van belang zijn. Heb je echt een probleem met de architectuur? Of heb je een probleem met de toegankelijkheid van de gegevens? Als je de verkeerde oplossing kiest, loop je het risico geld te steken in een technisch project in plaats van de controle over het bedrijf te verbeteren. Als je geen keuze maakt, blijf je beslissingen nemen op basis van onvolledige informatie.
Wie een mkb-bedrijf leidt, heeft geen college nodig. Hij heeft een eenvoudig criterium nodig om te begrijpen wat wel en wat niet nodig is, en waar de werkelijke kosten schuilgaan.
Het belangrijkste verschil wordt duidelijk aan de hand van twee zeer praktische voorbeelden.
Een datawarehouse lijkt op een goed georganiseerde bibliotheek. Elk boek wordt al gecatalogiseerd, ingedeeld en op de juiste plank geplaatst. Als je informatie zoekt, vind je die snel omdat de indeling al van tevoren is vastgesteld. Een datameer daarentegen lijkt op een groot magazijn waar allerlei soorten dozen binnenkomen. Je stopt er geordende bestanden, logbestanden, PDF's, afbeeldingen, exporten uit het beheersysteem en webgegevens in. De ordening pas je er later op toe, wanneer je ze moet analyseren.
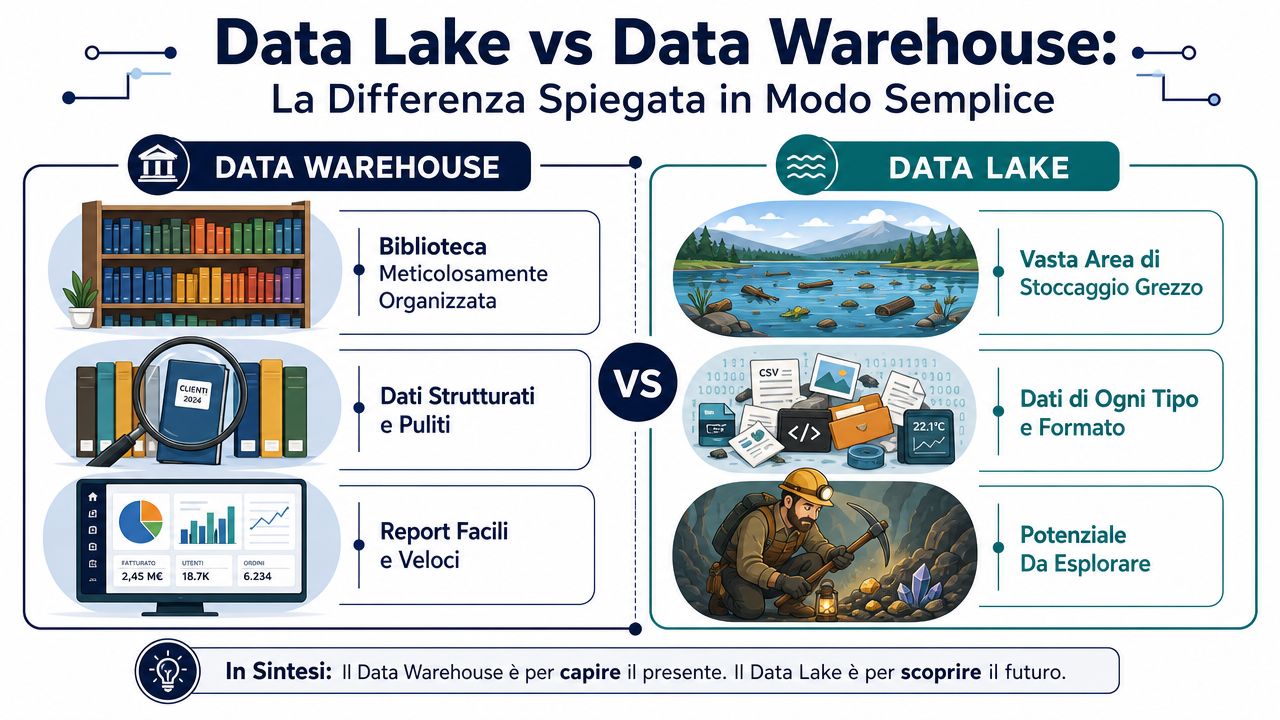
Dit is het enige technische detail dat echt de moeite waard is om te onthouden.
Dit onderscheid weerspiegelt ook hun historische oorsprong. Het datawarehouse is ontstaan voor bedrijfsanalyses op basis van reeds opgeschoonde en gestructureerde gegevens, terwijl het datameer later is ontstaan om ruwe gegevens in uiteenlopende formaten op te slaan. Daarom is het datawarehouse geschikter voor rapportages en KPI’s, terwijl het datameer flexibeler is voor verkenning en machine learning, zoals blijkt uit deze analyse van de verschillen tussen datawarehouse en datameer.
Een datawarehouse is geschikt voor vragen waarvan je het antwoord al kent. Een data lake is nuttig wanneer je weet dat de gegevens waardevol kunnen zijn, maar nog niet weet in welke vorm.
Als je inzicht wilt krijgen in omzet, winstmarges, bestellingen, voorraad, vertragingen, commerciële prestaties en maandelijkse vergelijkingen, sluit het warehouse conceptueel het beste aan bij je behoeften. Het biedt je een betrouwbare basis voor standaardrapportages, consistente SQL-query’s en reproduceerbare cijfers.
Als je daarentegen met zeer uiteenlopende gegevens werkt, zoals applicatielogbestanden, pdf’s, e-mails, teksten, afbeeldingen of machinestreams, biedt het data lake meer vrijheid. IT-teams kunnen heterogene bronnen centraliseren, terwijl rapportageafdelingen de voorkeur blijven geven aan gestructureerde omgevingen voor snelle en consistente zoekopdrachten. In deze context past ook het bredere thema van datagestuurde beslissingen voor bedrijven, waarvoor toegankelijke gegevens nog belangrijker zijn dan geavanceerde technologieën.
In de discussie over data lakes versus datawarehouses verwarren veel mensen flexibiliteit met direct nut.
Een datameer kan bijna alles bevatten. Maar het feit dat iets erin staat, betekent nog niet dat het meteen analyseerbaar is. Een datawarehouse is minder flexibel wat betreft de invoer, maar wel nuttiger als je snelle en gestandaardiseerde antwoorden wilt. Voor een mkb-bedrijf is dit verschil belangrijker dan de theorie. Want het gaat er niet om meer te opslaan. Het gaat erom betere beslissingen te nemen.
Twee bedrijven kunnen met dezelfde uitgangsgegevens uitkomen op heel verschillende resultaten. Het verschil zit vaak niet in de hoeveelheid verzamelde gegevens, maar in de manier waarop ze deze ordenen, verwerken en toegankelijk maken voor degenen die de beslissingen moeten nemen.
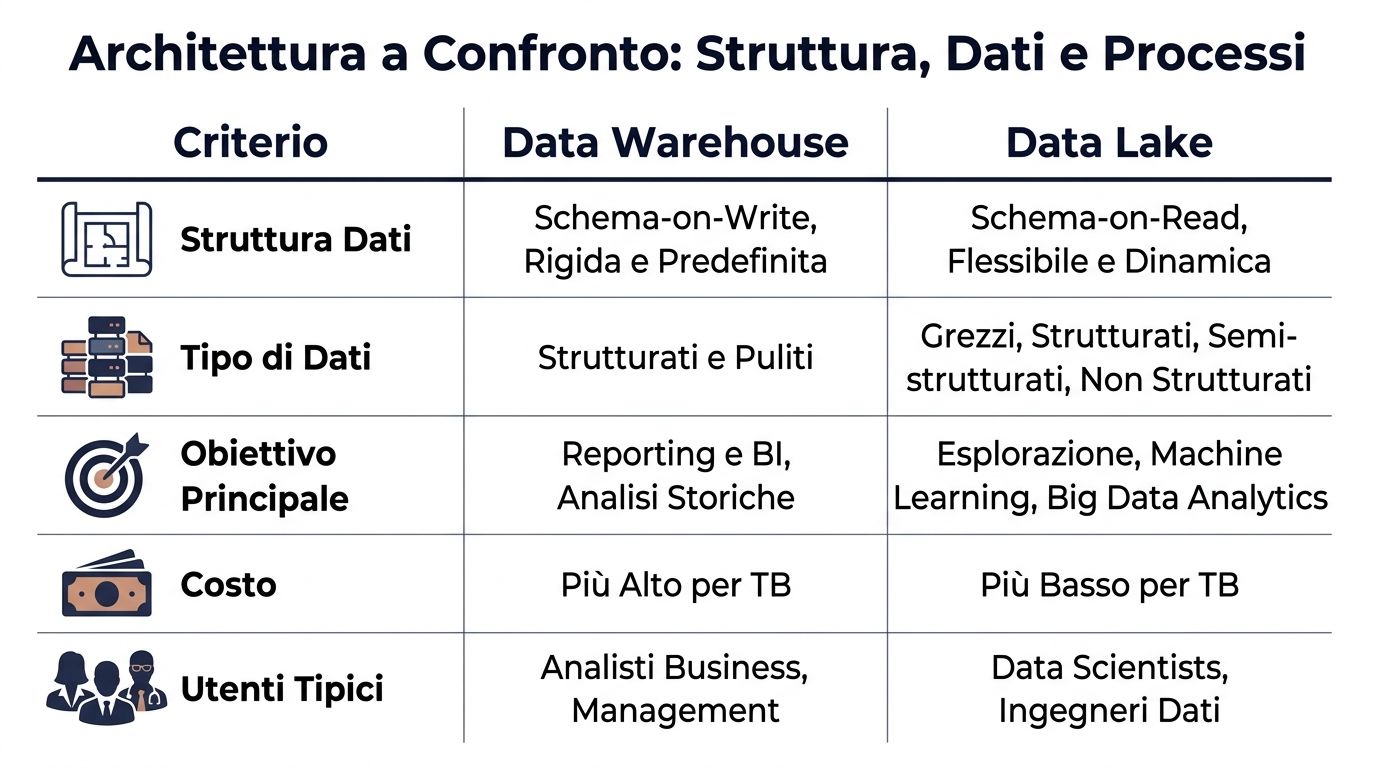
| Criterium | Datawarehouse | Data Lake |
|---|---|---|
| Gegevensstructuur | Schema-on-write, gedefinieerd vóór het laden | Schema-on-read, gedefinieerd op het moment van analyse |
| Gegevenstype | Vooral overzichtelijk en netjes | Gestructureerd, semi-gestructureerd en ongestructureerd |
| Standaardproces | ETL: eerst converteren, daarna uploaden | ELT: eerst laden, dan omzetten |
| Typische gebruikers | Bedrijfsanalist, financiën, management | Data-engineer, datawetenschapper, technische teams |
| Verwachte prestaties | Meer voorspelbaarheid voor BI en rapportage | Meer variabelen, afhankelijk van de query en de voorbereiding |
In het datawarehouse is de klassieke werkwijze ETL: je haalt de gegevens op, verwerkt ze en laadt ze vervolgens in. Dit vergt in het begin wat meer werk, maar zorgt daarna voor minder wrijving. Wie naar een dashboard kijkt, ziet consistente velden, vaste definities en KPI’s waarvan de betekenis niet verschilt van afdeling tot afdeling.
In het data lake verloopt de workflow vaak volgens het ELT-principe: eerst extraheren, vervolgens laden en pas daarna, indien nodig, transformeren. Deze aanpak biedt meer technische vrijheid, maar stelt een deel van het werk uit. Voor een klein of middelgroot bedrijf betekent uitstel vaak dat er taken opstapelen die vervolgens op het slechtst mogelijke moment op het team neerkomen, namelijk wanneer er snel een reactie nodig is.
Praktische tip: als meerdere mensen hetzelfde document moeten lezen en operationele beslissingen moeten nemen, zorgt een vooraf vastgestelde structuur ervoor dat fouten, onnodige discussies en tijdverlies worden voorkomen.
Op operationeel vlak is een datawarehouse ontworpen voor terugkerende zoekopdrachten, regelmatige rapportages en dagelijks gebruikte dashboards. Een datameer kan grote volumes en verschillende formaten goed aan, maar de responstijden en gebruiksvriendelijkheid hangen sterk af van de manier waarop de gegevens zijn gecatalogiseerd, voorbereid en beheerd. Een technische vergelijking die door CloudOptimo is gepubliceerd, vat dit punt goed samen: het warehouse is gericht op voorspelbaarheid, het meer op flexibiliteit.
Voor een mkb-bedrijf is dit geen theoretische kwestie. Als de verkoopmanager ’s ochtends het rapport opent, wil hij consistente cijfers en snelle resultaten. Als het technische team daarentegen bestanden, logbestanden of diverse documenten moet analyseren, kan het meer vertraging accepteren in ruil voor een uitgebreidere gegevensverzameling.
Het praktische verschil is niet alleen van technische aard. Het gaat erom wie de gegevens kan gebruiken zonder telkens om hulp te moeten vragen.
Een goed opgezet datawarehouse brengt de gegevens dichter bij het bedrijf. Een data lake alleen brengt ze vaker dichter bij het technische team. Daarom komen veel kleine en middelgrote ondernemingen pas laat tot een ongemakkelijke conclusie: de echte keuze ligt niet tussen twee technologieën, maar tussen een systeem dat gegevens toegankelijk maakt en een systeem dat ze opslaat zonder ze om te zetten in betere beslissingen.
Wie deze opties in het kader van een IT-moderniseringsproject overweegt, moet niet alleen naar de opslagplaats kijken, maar ook naar het bedrijfsmodel. Cloudoplossingen voor het MKB helpen juist deze overgang te begrijpen: waar de infrastructuur ophoudt en waar de kosten, de vereiste vaardigheden en de dagelijkse verantwoordelijkheden beginnen.
Het datameer wordt vaak voorgesteld als de voordeligste optie omdat het ruwe gegevens opslaat en de initiële werklast vermindert. Dat klopt maar gedeeltelijk. Als er geen catalogus, toegangsregels, consistente naamgeving en minimale kwaliteitscontroles zijn, veranderen de aanvankelijke besparingen in tijdverlies door het zoeken naar bestanden, het reconstrueren van definities en het controleren welke gegevens betrouwbaar zijn.
Daarom is de juiste afweging in veel kleine en middelgrote ondernemingen niet de abstracte vergelijking tussen ‘data lake’ en ‘data warehouse’. De relevante vraag is een andere: is het echt nodig om een van deze complete architecturen op te zetten, of is het beter om te beginnen met een lichtere oplossing die snel inzicht biedt, zonder meteen alle complexiteit op je te nemen?
Voor een mkb-bedrijf komt de duurste fout vaak voort uit een verkeerd geformuleerde vraag: „Wat is goedkoper: een data lake of een data warehouse?”. Binnen het bedrijf komt de echte rekening pas later. Die komt wanneer de gegevens niet met elkaar communiceren, de rapportages bij elke wijziging van het bedrijfssoftwarepakket in de war raken en elk verzoek via consultants of ontwikkelaars loopt in plaats van via het team dat de beslissing moet nemen.

Opslag weegt minder zwaar dan het lijkt. Wat meer weegt, zijn de activiteiten die ervoor zorgen dat de gegevens betrouwbaar en bruikbaar zijn: modellering, integraties, machtigingen, kwaliteit, monitoring, foutcorrectie en gebruikersondersteuning.
Een datawarehouse vergt in het begin wat werk. Je moet statistieken vaststellen, pijplijnen opzetten, bronnen op elkaar afstemmen en alles op orde houden wanneer ERP- of CRM-systemen of bedrijfsregels veranderen. In ruil daarvoor krijgt het management stabielere cijfers te zien en wordt de rapportage doorgaans voorspelbaarder.
Een data lake begint vaak met een bescheiden belofte. Je laadt er allerlei soorten gegevens in en stelt een deel van de structurele beslissingen uit. Het probleem is dat dit uitstel het werk niet wegneemt. Het verschuift het alleen maar naar later, waar het zich manifesteert in de vorm van catalogisering, beveiliging, rekenkosten, dubbele gegevens, inconsistente versies en voortdurende controles om te bepalen welke gegevens echt betrouwbaar zijn.
Het risico voor een kmo is dat ze twee keer moet betalen. Eerst om de gegevens te verzamelen. Daarna om ze eindelijk leesbaar te maken.
De echte complexiteit is niet van technische aard. Ze is operationeel.
Als elk nieuw rapport handmatig werk vereist, als de controller en de verkoper verschillende definities van dezelfde maatstaf hanteren, als de ondernemer dagenlang moet wachten op betrouwbare cijfers, dan slokt het dataproject nu al winstmarge op. Ook al lijkt de infrastructuur op papier modern.
Daarom is het raadzaam om niet alleen naar de architectuur te kijken, maar ook naar het beheermodel. Cloudoplossingen voor het MKB helpen je juist om dit verschil te doorgronden: wat koop je nu eigenlijk, hoeveel onderhoud blijft er intern en in hoeverre ben je elke maand afhankelijk van specialistische kennis?
Op de Italiaanse markt zijn investeerders in analytics op zoek naar tastbare resultaten. Minder handmatig werk. Snellere afhandeling. Betere controle over omzet, marges, voorraden en cashflow. Geen geavanceerd platform dat voorbehouden blijft aan een selecte groep.
Dit verandert de keuze. Een mkb-bedrijf zou zich niet moeten afvragen welke architectuur in theorie het meest aantrekkelijk of flexibel is. Het zou zich moeten afvragen hoeveel tijd er nodig is om tot betrouwbare dashboards te komen, hoeveel mensen er nodig zijn om deze te onderhouden en hoe snel het project rendement oplevert.
In de detailhandel komen verborgen kosten al snel aan het licht. Als verkopen, retouren, promoties en voorraden uit verschillende systemen komen, is één verkeerde definitie van ‘marge’ of ‘netto-omzet’ al genoeg om het vertrouwen in de rapportages te ondermijnen. Op dat moment ligt het probleem niet bij de gekozen database. Het probleem is dat de eigenaar weer zijn beslissingen in Excel gaat nemen.
In de financiële sector zijn de gevolgen van fouten nog duidelijker zichtbaar. Rapportage, afstemming, managementcontrole en afwijkingsanalyse vereisen consistente en traceerbare gegevens. Als elke controle discussies oproept over de herkomst van de cijfers, verliest het project zijn ROI nog voordat het is afgerond.
Daarom hoeven veel kleine en middelgrote ondernemingen in de praktijk geen volledig data lake of data warehouse vanaf nul op te bouwen. Ze hebben behoefte aan een lichter, beter beheersbaar en besluitgericht systeem.
Als je de kwaliteit van de gegevens, de toegangsregels en de gedeelde definities op de lange termijn niet kunt handhaven, ligt het probleem niet in de keuze tussen een data lake en een data warehouse. Het probleem is dat je complexiteit hebt aangeschaft voordat je een use case had die dat rechtvaardigde.
De juiste vraag is niet welke architectuur absoluut de „beste“ is. De vraag is welk probleem je morgenochtend moet oplossen.

In de detailhandel functioneert het magazijn goed wanneer je steeds dezelfde operationele vragen moet beantwoorden:
Hetzelfde geldt voor de financiële sector. Als je gestructureerde gegevens moet consolideren, periodieke rapportages moet opstellen, portefeuilles moet analyseren of economische trends moet interpreteren aan de hand van vaste criteria, blijft een datawarehouse een logische keuze.
Het lake-model is zinvol wanneer je bedrijf zeer uiteenlopende gegevens verzamelt en je niet alles van tevoren wilt of kunt definiëren.
Een realistisch voorbeeld is dat van een energiebedrijf dat:
In een dergelijke context dwingt een traditioneel datawarehouse je om eerst de relaties tussen bronnen te ontwerpen die je misschien nog niet goed kent. Met een data lake kun je alles centraliseren en pas structuur aanbrengen wanneer dat nodig is voor een specifieke analyse. Dit is precies het soort scenario waarin de flexibiliteit van het data lake echt waarde toevoegt.
Een data lake is geen 'modernere' keuze. Het is alleen een verstandige keuze als de verscheidenheid aan gegevens de complexiteit rechtvaardigt die je daarmee in huis haalt.
De meeste kleine en middelgrote ondernemingen bevinden zich niet in die situatie. Ze beschikken vooral over gegevens uit ERP-systemen, CRM-systemen, e-commerce, boekhouding, CSV-exporten en Excel. In deze gevallen is het probleem niet het op grote schaal beheren van videobestanden, applicatielogbestanden of vrije tekst. Het probleem is het beschikken over schone, consistente cijfers die ook voor niet-technische mensen begrijpelijk zijn.
Laten we hier duidelijk over zijn: vaak is er geen behoefte aan een data lake of een traditioneel datawarehouse.
Wat je nodig hebt, is:
Het lakehouse probeert deze twee werelden te verenigen. Het belooft de flexibiliteit van het lake en bepaalde voordelen van het warehouse in één omgeving te combineren. Dit is een interessante ontwikkeling, vooral voor bedrijven met een gemengde werklast op het gebied van BI, AI en datawetenschap.
Voor een mkb-bedrijf blijft de vraag echter dezelfde: heb je echt een probleem dat dit alles vereist? Als je behoefte erin bestaat om een beter inzicht te krijgen in de omzet, winstmarges, cashflow of prognoses, kan een geavanceerde hybride oplossing nog steeds niet in verhouding staan tot de verwachte waarde.
Het data lakehouse is in het leven geroepen om de strikte scheiding tussen data lake en data warehouse te doorbreken. Het idee is eenvoudig: de flexibiliteit van een ruime en open opslag behouden, maar daar orde, prestaties en analytische mogelijkheden aan toevoegen die dichter bij die van een data warehouse liggen. Technologieën als Databricks en Delta Lake zijn goede voorbeelden van deze ontwikkeling.
In theorie klinkt het erg aantrekkelijk. Je gebruikt dezelfde database voor BI, geavanceerde analyse en machine learning, waardoor je voorkomt dat er te veel informatie tussen verschillende systemen wordt gedupliceerd. Voor grote organisaties of voor ervaren datateams is het een logisch antwoord op een ecosysteem dat in de loop der tijd steeds complexer is geworden.
In academische benchmarks wordt de data lakehouse-architectuur beoordeeld aan de hand van maatstaven zoals doorvoersnelheid, latentie en metadata-overhead. Hieruit blijkt dat de vergelijking met het datawarehouse niet alleen functioneel is, maar ook betrekking heeft op de prestaties, in scenario’s waarin kleine verschillen in prestaties een aanzienlijke impact hebben, zoals blijkt uit deze academische presentatie over lakehouse-benchmarks.
Vertaald naar zakelijk Italiaans: het Lakehouse biedt oplossingen voor organisaties die al een zekere mate van schaalgrootte, complexiteit en specialisatie hebben bereikt.
Als je eigenlijk geen behoefte had aan een datameer of een datawarehouse, heb je waarschijnlijk ook geen systeem nodig dat beide combineert.
Voor de meeste kleine en middelgrote ondernemingen is de meest relevante vraag niet „welke architectuur moet ik kiezen?“, maar „hoe krijg ik betrouwbare analyses zonder dat het dataproject een eeuwigdurende bouwput wordt?“.
Dit is het derde aspect dat in veel vergelijkingen tussen data lakes en datawarehouses over het hoofd wordt gezien. Bouw geen nieuwe, propriëtaire infrastructuur. Voeg in plaats daarvan een analyselaag toe bovenop de systemen die je al gebruikt, zodat de technische complexiteit buiten de operationele grenzen van het bedrijf blijft.

In de praktijk is dit de beste aanpak:
Ik heb meer dan eens gezien dat een mkb-bedrijf maandenlang in een traditioneel magazijnsysteem investeerde en het vervolgens nauwelijks gebruikte. Niet omdat het slecht was gebouwd, maar omdat niemand in het bedrijf wist hoe hij er zelfstandig gegevens uit kon halen. De bottleneck lag niet bij de database, maar bij de toegankelijkheid.
Dit is een punt dat vaak over het hoofd wordt gezien. Een elegante architectuur die altijd een technische tussenpersoon vereist, vermindert de praktische waarde van de gegevens. Een eenvoudigere oplossing, die ook voor het management begrijpelijk is, leidt vaak sneller tot betere beslissingen.
Daarom halen veel bedrijven meer waarde uit goed ontworpen business intelligence-software voor het MKB dan uit een te omvangrijk infrastructuurprogramma. Het doel dat ze nastreven is niet het bezit van een datawarehouse, maar het bedrijf beter en sneller begrijpen.
De juiste infrastructuur is degene die je team daadwerkelijk kan gebruiken, onderhouden en omzetten in beslissingen. Niet degene die indruk maakt op een technische dia.
De discussie over data lakes versus datawarehouses is nuttig, maar voor een mkb-bedrijf gaat die vaak uit van de verkeerde vraag. Voordat je een architectuur kiest, moet je eerst nagaan of je daadwerkelijk te maken hebt met een probleem op het gebied van schaal en gegevensdiversiteit, of met een veel vaker voorkomend probleem: versnipperde gegevens, handmatige rapportages en slechte toegankelijkheid.
Het datawarehouse blijft de beste keuze wanneer betrouwbare rapportages, consistente KPI's en voorspelbare prestaties vereist zijn. Het datameer is zinvol wanneer de verscheidenheid aan bronnen meer flexibiliteit en complexiteit rechtvaardigt. Het lakehouse is een interessante ontwikkeling, maar is zelden de juiste eerste stap voor een organisatie die vooral op zoek is naar operationele controle en ROI.
De slimste keuze is niet de meest geavanceerde technologie. Het is de keuze die past bij het daadwerkelijke probleem, de beschikbare vaardigheden en de snelheid waarmee je gegevens in beslissingen wilt omzetten.
Als je bedrijfsgegevens wilt omzetten in rapporten, prognoses en operationele inzichten zonder een complexe infrastructuur op te zetten, ontdek dan ELECTE, een door AI aangestuurd data-analyseplatform voor het MKB. Je kunt aan de slag met de gegevens die je al hebt, handmatig werk verminderen en je team op een veel eenvoudigere manier toegang geven tot analyses.

.svg)
.svg)
.svg)






