

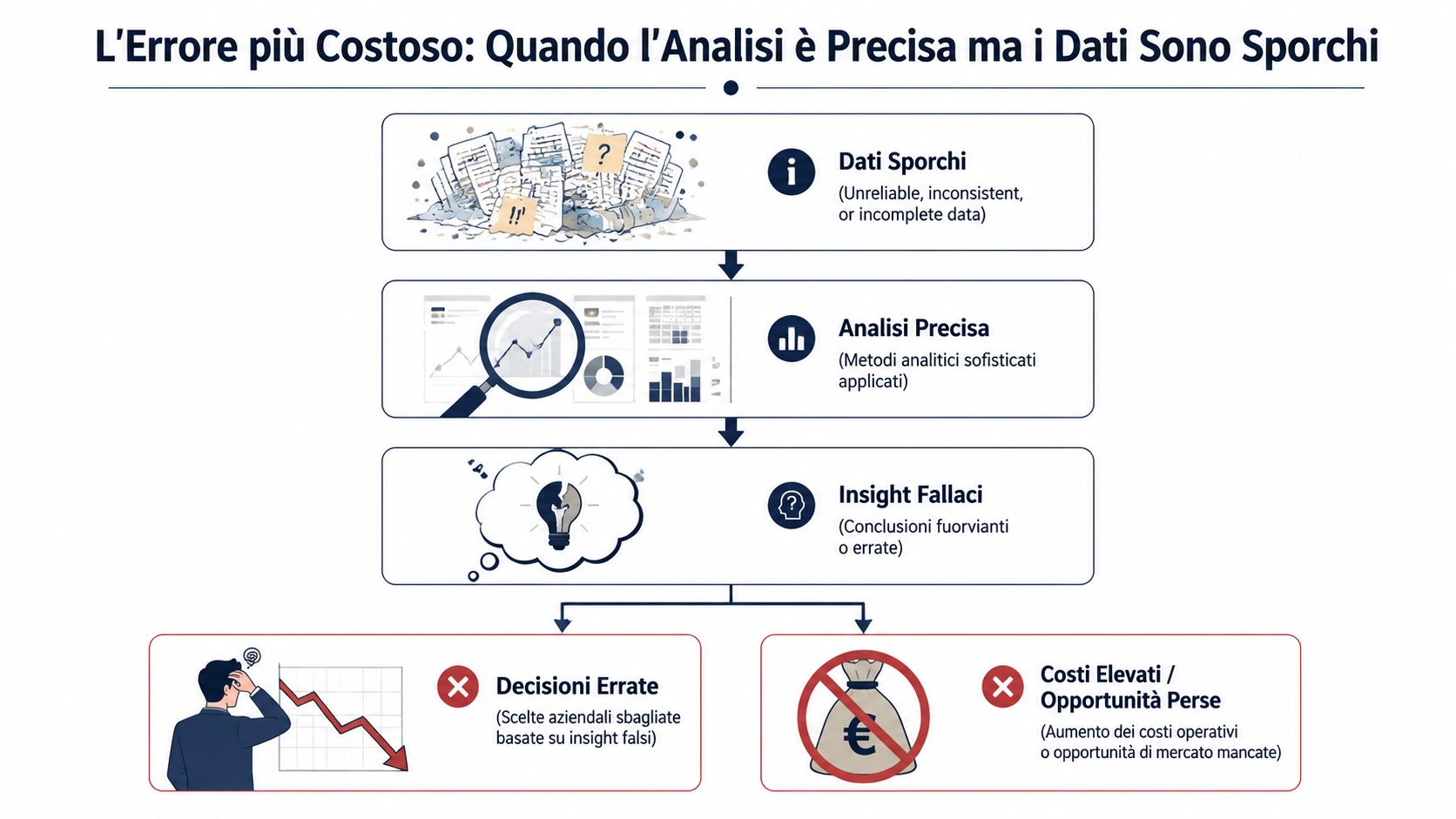
Bekijk het verkooprapport van deze maand eens. De omzet lijkt te zijn gestegen, de marge lijkt te zijn verbeterd, en toch heb je dat vervelende gevoel dat er iets niet klopt. Dat is geen paranoia. Dat is praktijkervaring. Wie bij een Italiaans MKB-bedrijf werkt, weet dat de gegevens – tussen het bedrijfsbeheersysteem, Excel-exporten en handmatige aanpassingen – meerdere keren van vorm veranderen voordat ze op een dashboard terechtkomen.
Het komt simpelweg hierop neer: een onberispelijke analyse op basis van verkeerde gegevens helpt je niet. Het misleidt je. Het geeft je een nauwkeurig, elegant en geruststellend antwoord, maar dat is gebouwd op wankele grond. En dat is veel gevaarlijker dan een onvolledig rapport, omdat het je ertoe aanzet om met zekerheid beslissingen te nemen terwijl die zekerheid er niet is.
Datavalidatietechnieken dienen precies hiervoor: fouten aan het licht brengen. Ze maken de gegevens niet ‘perfect’. Ze brengen de problemen aan het licht die nu onopgemerkt blijven. Of je nu verantwoordelijk bent voor administratie, managementcontrole, verkoop of bedrijfsvoering: dit is het werk dat het verschil maakt tussen een bruikbaar cijfer en een louter decoratief cijfer. En in het MKB is dit waardevoller dan veel ‘geavanceerde’ analytics-initiatieven, omdat de voordelen direct merkbaar zijn, vaak al vanaf de eerste import.
Bij kleine en middelgrote ondernemingen worden cijfers zelden op dezelfde plek gegenereerd als waar ze worden gelezen. Ze gaan van een bedrijfssoftware naar een geëxporteerd bestand, vervolgens naar Excel, en daarna naar een ‘aangepaste’ versie door iemand die eigenlijk maar twee kolommen hoefde te corrigeren, maar uiteindelijk de helft van het blad opnieuw heeft geschreven. Als het eindrapport niet overtuigt, ligt het probleem vaak niet bij de grafiek. Het ligt aan alles wat er daarvoor is gebeurd.
Gegevensvalidatie is het minst aantrekkelijke en tegelijkertijd belangrijkste onderdeel van de gehele analysecyclus. Geen enkele ondernemer wil het hebben over formaatcontroles of ontbrekende verplichte velden. Toch is bijna elke verkeerde beslissing die op ogenschijnlijk foutloze dashboards wordt genomen, hieraan te wijten. Aan een gewijzigd decimaalteken, een verkeerd geïnterpreteerde datum, een dubbel ingevoerde waarde in het stamgegevensbestand, of een totaal dat niet klopt maar door niemand is gecontroleerd.
Wie goed met gegevens werkt, ontwikkelt een bepaalde gewoonte: voordat hij zich afvraagt wat de cijfers zeggen, vraagt hij zich af of die cijfers wel betrouwbaar zijn. De beste technieken voor gegevensvalidatie zijn niet de meest geavanceerde. Het zijn juist die technieken die de meest voorkomende fouten in een vroeg stadium opsporen, zonder het dagelijkse werk te vertragen.
Als je de gegevens niet voldoende vertrouwt om een belangrijke beslissing te nemen, ligt het probleem niet bij de beslissing zelf. Het ligt bij de validatie.
De typische fout is niet een rapport dat overduidelijk niet klopt. Het is een overzichtelijk rapport, dat op het eerste gezicht samenhangend lijkt, maar is gebaseerd op gegevens die hun betrouwbaarheid al hebben verloren. Als dat gebeurt, zit de schade niet alleen in het verkeerde cijfer. De schade zit hem in het feit dat niemand het in twijfel trekt.
De discipline heeft een grote ontwikkeling doorgemaakt. De validatie van gegevens is geëvolueerd van een overwegend handmatige controle naar geautomatiseerde en statistische controles. In de best practices worden ten minste vijf basiscontroles onderscheiden, namelijk datatypecontrole, codecontrole, bereikcontrole, formaatcontrole en consistentiecontrole, zoals samengevat door Teradata in het overzicht over gegevensvalidatie. In Italië speelt deze ontwikkeling een nog grotere rol in gereguleerde contexten, waar zelfs één enkel foutief veld rapporten, prognosemodellen of nalevingsverplichtingen kan beïnvloeden.
De eerste fout is dat men zich beperkt tot de oppervlakte. Veel bedrijven voeren alleen de eenvoudigste controle uit, namelijk de syntactische controle.
Een correct opgegeven belastingnummer kan de eerste hindernis nemen, maar bij de tweede falen. Het totaalbedrag op een factuur kan weliswaar een getal zijn en in het juiste formaat staan, maar als het niet overeenkomt met de som van de regels, heb je een veel ernstiger probleem dan alleen de opmaak.
Praktische regel: een controle die slechts één kolom doorzoekt, spoort triviale fouten op. Een controle die meerdere velden met elkaar in verband brengt, spoort fouten op die van invloed zijn op beslissingen.
Zinnige validatie vindt niet pas aan het einde van het werk plaats. Het gebeurt eerder. Als je wacht op het eindrapport, is de fout al verwerkt, samengevat, naar andere bestanden gekopieerd en tijdens vergaderingen besproken. Op dat moment kost het corrigeren ervan aandacht, tijd en geloofwaardigheid.
Dit geldt des te meer wanneer je meer geavanceerde methoden gaat gebruiken, zoals het opsporen van afwijkingen of het omgaan met statistische uitschieters. Het zijn nuttige hulpmiddelen, maar ze zijn geen vervanging voor basiscontroles. Als een kolom die als tekst is geïmporteerd prijzen bevat, heb je geen complex model nodig. Je hebt een eenvoudig filter nodig dat de fout al bij de invoer tegenhoudt.
Een goede analyse begint niet met mooiere dashboards. Ze begint met gegevens die, zodra ze in de workflow terechtkomen, een reeks zinvolle tests hebben doorstaan.
In de dagelijkse praktijk van kleine en middelgrote ondernemingen komt de meeste waarde voort uit eenvoudige controles. Niet uit de meest verfijnde academische technieken. Niet uit ingewikkelde processen die niemand zal onderhouden. Maar uit duidelijke, herhaalbare regels, dicht bij het punt waar de gegevens daadwerkelijk het bedrijf binnenkomen.

In de Italiaanse context sluit deze aanpak aan bij de benadering van het ISTAT, dat de kwaliteit van gegevens definieert aan de hand van aspecten als nauwkeurigheid, consistentie en volledigheid, en gebruikmaakt van de VIMO-controle (Valid, Invalid, Missing, Outlier) om geldige, ontbrekende en afwijkende waarden te meten. De aanpak voorziet in validatie bij invoer, tijdens de verwerking en vóór het uiteindelijke gebruik van de gegevens, zoals uitgelegd in het ISTAT-materiaal over gegevenskwaliteit en -validatie.
Het verloop is altijd hetzelfde. De gegevens worden in het bedrijfsbeheersysteem aangemaakt. Ze worden geëxporteerd. Ze komen in Excel terecht. Iemand corrigeert een koptekst, sleept een formule, kopieert een kolom, past de datumnotatie aan ‘om het in orde te brengen’. Vanaf dat moment beginnen de verborgen fouten.
Dit zijn de controles die je het beste meteen kunt uitvoeren:
Als je met handmatige exports werkt, kun je beginnen met een heel concreet schema:
| Controle | Een veelvoorkomende fout bij kleine en middelgrote ondernemingen | Een vraag die je jezelf moet stellen |
|---|---|---|
| Type | Prijs van het bed als tekst | Kan deze kolom worden berekend? |
| Formaat | Gemengde datums in verschillende formaten | Interpreteert het systeem het altijd op dezelfde manier? |
| Bereik | Bedragen buiten de schaal | Is deze waarde aannemelijk per klant of per product? |
| Uniekheid | Klant meerdere keren ingevoerd | Tel ik verschillende personen of namen die op verschillende manieren zijn geschreven? |
| Volledigheid | Lege sleutelvelden | Kan ik dit record gebruiken in rapporten en beslissingen? |
| Consistentie | Totalen die niet kloppen | Bevestigen de kolommen elkaar? |
Voor wie werkzaam is in sectoren waar de kwaliteit van documenten en procedures al een grote operationele rol speelt, is het de moeite waard om ook meer gestructureerde kwalificatie- en controleprocedures te bekijken. Een nuttig naslagwerk is de Gids voor kwalificatie in gereguleerde sectoren, omdat hieruit duidelijk blijkt dat validatie niet alleen een kwestie van ‘opschonen’ is, maar ook van procescontrole.
Duplicaten verdienen een aparte vermelding. Ze vormen een chronisch probleem in de klantendatabases van veel kleine en middelgrote ondernemingen en geven een vertekend beeld van vrijwel alles: actieve klanten, aankoopfrequentie, commerciële zichtbaarheid en de geschiedenis van de klantrelaties. Als je met een concreet voorbeeld aan de slag wilt gaan, vind je een praktische aanpak in ELECTE: de complete gids voor duplicaten in Excel.
Geavanceerde controles hebben pas zin als de basis op orde is. Anders is het alsof je een radar op een auto zonder remmen monteert.
Maandagochtend, verkoopvergadering. De eigenaar bekijkt het verkooprapport, de administratief medewerker bekijkt een ander bestand en de controller heeft er nog een derde. De cijfers zouden met elkaar moeten overeenkomen. Dat is echter niet het geval.
Dit is een veelvoorkomend scenario bij Italiaanse kleine en middelgrote ondernemingen. Een verouderd bedrijfsbeheersysteem exporteert CSV-bestanden met vaste velden. Het CRM-systeem hanteert andere labels. De e-commerce heeft zijn eigen logica. Dan komt Excel in beeld, waar iemand de kopteksten aanpast, kolommen kopieert, datums corrigeert en probeert alles op orde te krijgen vóór de vergadering.
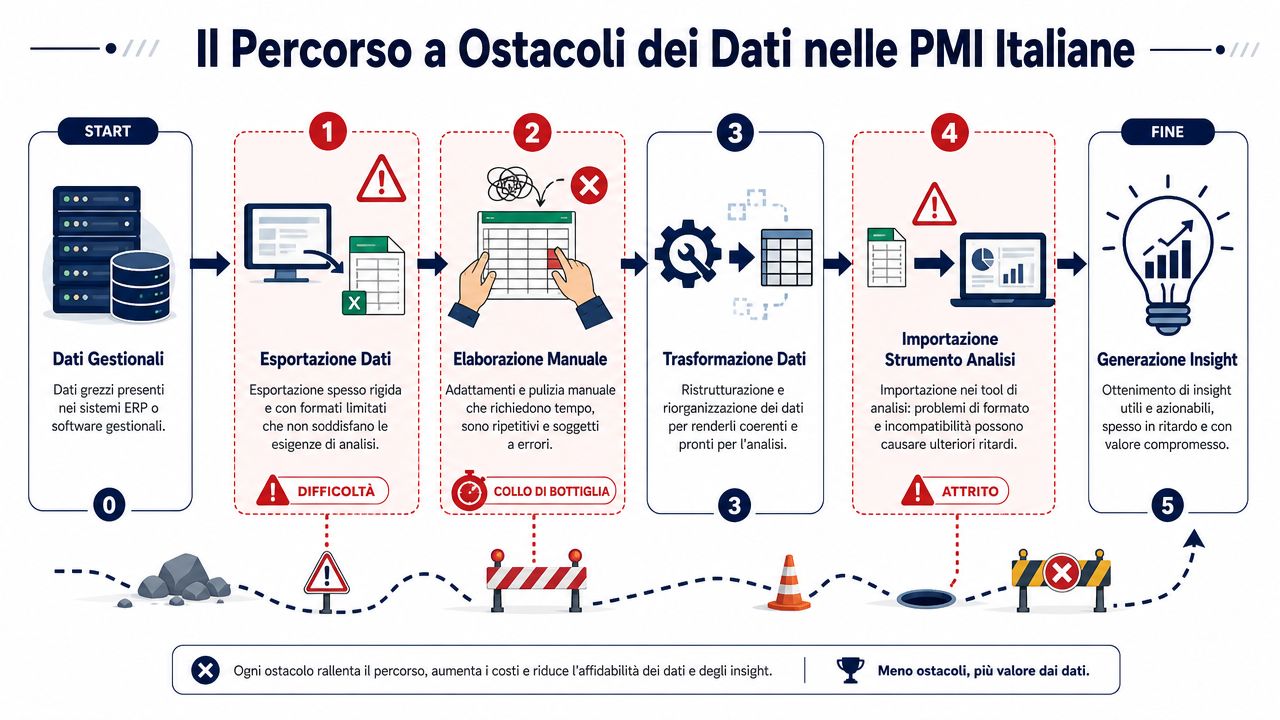
Het probleem ligt niet bij de technologie op zich. Het probleem is de opeenstapeling van kleine handmatige handelingen op gegevens die afkomstig zijn uit systemen die op verschillende momenten zijn ontstaan, vaak zonder gemeenschappelijke regels. Wie met het koppelen van verschillende gegevensbronnen werkt, merkt het meteen: elke bron brengt zijn eigen conventies, terugkerende fouten en willekeurig ingevulde velden met zich mee.
Zelfs de duurste fouten houden het proces niet tegen. Ze worden in het bestand opgenomen en blijven daar staan.
Het gebeurt elke dag in heel concrete situaties:
Veel bedrijven maken hier dezelfde fout. Ze zoeken naar geavanceerde oplossingen voordat ze de voor de hand liggende maar winstgevende maatregelen hebben genomen: de juiste typen, consistente sleutels, bewaarde codes en datums die door alle systemen op dezelfde manier worden gelezen.
Bij kleine en middelgrote ondernemingen is het gegevensbestand zelden vanaf het begin schoon en stabiel. Het gaat heen en weer tussen de administratie, de verkoopafdeling, de logistiek, externe adviseurs en lokale bestanden met namen als "report_finale_def_vero.xlsx". Iedereen past het bestand aan op basis van wat hij of zij nodig heeft om te kunnen werken. Bijna niemand documenteert de wijzigingen.
Daarom komen academische controles of al te ambitieuze projecten voor het opsporen van afwijkingen vaak te laat. Eerst is discipline op het gebied van de basisprincipes nodig. Een automatische controle die ongeldige CAP’s, afgekorte klantcodes, dubbele regels of data buiten de periode signaleert, voorkomt meer fouten dan veel „geavanceerde” initiatieven die te vroeg worden opgezet.
Ik zeg het maar recht voor zijn raap, want dit is het punt dat ik het vaakst tegenkom: een MKB-bedrijf verliest het vertrouwen in de gegevens niet omdat er geen kunstmatige intelligentie wordt gebruikt. Het verliest dat vertrouwen omdat de omzetcijfers van het ene Excel-bestand naar het andere verschillen, en niemand kan zeggen welke versie de juiste is.
Het bestand dat „altijd heeft gewerkt” is vaak het bestand dat niemand meer controleert.
Wanneer gegevens door meerdere handen en systemen gaan, hoeft validatie niet elegant te zijn. Het moet herhaalbaar, saai en zo dicht mogelijk bij de invoer van de gegevens plaatsvinden. Daar wordt het grootste deel van de waarde gerealiseerd, nog voordat we het hebben over voorspellende modellen of mooiere dashboards.
Maandagochtend begint vaak zo. De administratief medewerker opent twee exportbestanden van dezelfde maand, één uit het boekhoudsysteem en één uit het verkoopbestand, en de totalen kloppen niet. Niemand heeft de tijd om de controles handmatig over te doen. Op dat moment is het rapport niet het probleem. Het probleem is dat het vertrouwen in de cijfers al is geschonden.
ELECTE grijpt in voordat de onzuivere gegevens in de analyses terechtkomen. Voor een Italiaanse kmo is dat het punt dat er echt toe doet. Een ingewikkelde machine die geavanceerde controles belooft, heeft geen zin als deze vervolgens banale fouten bij het importeren, verkeerd gelezen kolommen of codes waarvan het formaat tussen de verschillende systemen verschilt, doorlaat.
In de praktijk controleert het platform de gegevens op het moment dat ze binnenkomen. Niet pas na het rapport. Niet pas na de vergadering waarin iemand vraagt waarom de marge tussen de ene versie van het bestand en de andere is veranderd.
De automatische controles richten zich op de problemen die bij kleine en middelgrote ondernemingen meer schade aanrichten dan verwacht: inconsistente gegevenstypen, ontbrekende velden, datums buiten de periode, duplicaten, waarden buiten het bereik en sleutels die niet aan de juiste tabellen zijn gekoppeld. Het zijn weinig glamoureuze controles, maar juist deze voorkomen de meeste operationele fouten in omgevingen vol met Excel-exports, verouderde ERP-systemen en bestanden die via e-mail worden verstuurd.
Dan is er nog het contextuele niveau. Bij onboarding worden regels vastgesteld die aansluiten bij het daadwerkelijke bedrijfsproces, niet bij een theoretisch model. Een distributiebedrijf heeft andere behoeften dan een bureau dat toeristenbezoeken beheert of een fabrikant met gelaagde prijslijsten en kortingsstructuren. Hetzelfde geldt voor specifieke documentgerelateerde gevallen, zoals het uitlezen van gestructureerde gegevens uit documenten en check-ins, een relevant onderwerp ook voor wie met MRZ werkt voor accommodaties.
Het praktische voordeel is simpel: het team hoeft niet telkens opnieuw te bedenken welke controles het moet uitvoeren. Die zijn al op een consistente en herhaalbare manier geïmplementeerd.
Een typisch voorbeeld. Een update van het bedrijfsbeheersysteem verandert het formaat van bepaalde prijsvelden, maar alleen in een deel van de export. Op het eerste gezicht lijkt het bestand correct. Bij nadere analyse blijken die waarden echter de omzet, de winstmarge en de vergelijkingen met voorgaande maanden te beïnvloeden. ELECTE signaleert de afwijking onmiddellijk, isoleert de betreffende rijen en maakt het mogelijk deze te corrigeren voordat ze in dashboards en managementrapportages terechtkomen.
Een van de nuttigste aspecten voor mensen die beslissingen moeten nemen en zich niet bezighouden met data science, is het omgaan met uitzonderingen. Problematische records verdwijnen niet. Ze blijven zichtbaar, worden apart gehouden en er wordt een reden voor aangegeven.
Wie de gegevens bekijkt, begrijpt het meteen:
Deze transparantie voorkomt een van de slechtste gewoontes die ik bij kleine en middelgrote ondernemingen zie: de dataset opschonen zonder sporen achter te laten en pas weken later ontdekken dat de cijfers niet meer kloppen.
Juist daarom is het koppelen van verschillende gegevensbronnen zo waardevol. Het volstaat niet om CRM, ERP, e-commerce en handmatige bestanden aan elkaar te koppelen. Als de gegevens zonder duidelijke controles samenkomen, blijft de chaos bestaan, alleen dan op een overzichtelijker scherm.
ELECTE belooft geen perfecte gegevens. Het vermindert de meest voorkomende fouten, maakt ze zichtbaar en voorkomt dat ze als correcte gegevens in de rapporten terechtkomen. Voor een MKB-bedrijf is dit vaak het verschil tussen praten over cijfers en discussiëren over cijfers.
Validatie mag niet worden beschouwd als een technisch project dat losstaat van de bedrijfsvoering. Het moet worden gezien als een operationeel vakgebied. Wie een begroting opstelt, een prijslijst goedkeurt, de marges herziet of inkoopplannen opstelt, maakt al gebruik van gegevens die goed of slecht zijn gevalideerd. Er is geen derde optie.
Er zijn maar weinig nuttige regels, maar ze moeten wel consequent worden toegepast:
Geldig bij invoer, niet daarna
Als de controle het einde bereikt, heeft de fout de formules, aggregaties en rapporten al aangetast.
Beperk je niet tot het formaat
. Gegevens kunnen goed zijn opgeschreven, maar toch onjuist zijn. Je moet de plausibiliteit en consistentie tussen de velden controleren, niet alleen of ze aan een schema voldoen.
Automatiseer repetitieve controles
Geen enkel administratief of commercieel team heeft de tijd om elke export handmatig te controleren. Basiscontroles moeten systematisch worden uitgevoerd.
Vermijd te strenge regels
Er bestaat een reëel evenwicht tussen strengheid en productiviteit. Te strenge regels kunnen ervoor zorgen dat niet-technische teams minder gebruikmaken van analytische tools, zoals Acceldata benadrukt in zijn beschouwing over de afweging bij datavalidatie. De juiste drempel is die waarbij fouten tot een minimum worden beperkt zonder de bedrijfsvoering te vertragen.
Beschouw uitzonderingen als signalen, niet als hinder
Een afwijkend record zegt bijna altijd iets over het proces dat eraan ten grondslag ligt. Als je het negeert, laat je de kans liggen om het proces zelf te verbeteren.
Een nuttig voorbeeld komt uit sectoren waar het formaat geen detail is, maar een voorwaarde voor de werking. In de horeca bijvoorbeeld laat het thema van het automatisch lezen van documenten goed zien dat de gegevens niet alleen aanwezig moeten zijn, maar ook moeten voldoen aan een interpreteerbare standaard. Wie op zoek is naar een concreet voorbeeld, kan dit diepgaande artikel over MRZ voor de horeca lezen.
De juiste instelling is deze: vertrouw pas op gegevens nadat je ze hebt getoetst. Als je vandaag de dag vertrouwt op bestanden die niemand op een gestructureerde manier controleert, ben je niet bezig met analyse. Je bent aan het hopen.
De meeste problemen in rapporten ontstaan niet in de laatste grafiek. Ze ontstaan al veel eerder, wanneer onvolledige, inconsistente of uit hun context gehaalde gegevens zonder een degelijke filter in de systemen terechtkomen. Daarom zijn technieken voor gegevensvalidatie belangrijker dan ze op het eerste gezicht lijken. Ze vormen het punt waarop je niet langer aan de gegevens onderworpen bent, maar ze zelf gaat beheersen.
Voor een MKB-bedrijf ligt de meerwaarde niet in het streven naar perfectie. Het gaat erom voldoende vertrouwen op te bouwen om weloverwogen beslissingen te kunnen nemen. Controles op type, formaat, bereik, uniekheid, volledigheid en onderlinge consistentie lossen een groot deel van de daadwerkelijke problemen op. Automatisering maakt deze controles haalbaar.
Als je geen gestructureerd validatieproces hebt, vertrouw je niet op de gegevens. Je vertrouwt op geluk.
Als je onoverzichtelijke exportbestanden, kwetsbare Excel-bestanden en heterogene gegevensbronnen wilt omzetten in betrouwbare analyses, ontdek dan hoe ELECTE, een door AI aangedreven data-analyseplatform voor het MKB, controles, afwijkingen en inzichten automatiseert zonder dat dit extra complexiteit voor je team met zich meebrengt.

.svg)
.svg)
.svg)






