

De financiële teams van kleine en middelgrote ondernemingen weten het maar al te goed: telkens wanneer je een PDF in Excel probeert te importeren, begint er een strijd tegen de opmaak. Het klassieke kopiëren en plakken loopt bijna altijd uit op een ramp: verspreide gegevens, willekeurig samengevoegde cellen en overzichtelijke tabellen die veranderen in een onleesbare chaos. De frustratie is reëel, maar het is niet jouw schuld. Het probleem ligt in de aard van het PDF-formaat zelf, dat is ontworpen om te worden afgedrukt en gedeeld, niet om als bron van te analyseren gegevens te dienen.
Deze handmatige workflow, bestaande uit bankafschriften, facturen van leveranciers en documenten van overheidsinstanties, is een ware productiviteitskiller. Het is niet alleen vervelend, maar ook een vrijwel gegarandeerde bron van fouten bij het invoeren van gegevens. Gelukkig zijn er in 2026 veel slimmere methoden beschikbaar om deze uitdaging het hoofd te bieden. In deze gids laten we je stap voor stap de meest effectieve strategieën zien, van de in Excel geïntegreerde functies tot AI-aangedreven oplossingen die handmatig werk volledig elimineren, waardoor je binnen enkele minuten van extractie naar analyse kunt gaan.
Het probleem komt voort uit een fundamenteel verschil: PDF-bestanden zijn gemaakt om de weergave van een document op elk apparaat te behouden, niet om de logische structuur van de gegevens erin te behouden. Inzicht in het verschil tussen de verschillende soorten PDF-bestanden is de eerste stap om de juiste tool te kiezen en uren aan nutteloos werk te voorkomen.
Deze afbeelding geeft perfect de frustratie weer van iedereen die moet zien uit te komen met een ingewikkelde pdf en een rommelig spreadsheet.

Dit is precies het moment waarop een handmatig proces een belemmering voor de productiviteit wordt, wat aantoont dat er behoefte is aan een efficiëntere methode om een PDF in Excel te importeren.
Misschien wist je het nog niet, maar de handigste manier om een PDF in Excel te importeren, zit al ingebouwd in de software die je dagelijks gebruikt. Het heet Power Query en is een krachtige functie voor het "ophalen en transformeren van gegevens" die Microsoft in Excel heeft ingebouwd.

Dit is de ideale oplossing voor het af en toe importeren van eenvoudige, overzichtelijke pdf-bestanden, zoals een prijslijst of een lijst met contactgegevens. Het grootste voordeel? Het is gratis en er is geen extra installatie nodig.
De gegevens worden in een nieuw werkblad geplaatst, al opgemaakt als Excel-tabel en klaar voor gebruik.
Power Query is geweldig, maar heeft wel zijn beperkingen. Het werkt het beste met eenvoudige tabellen die op één pagina staan. Bij complexere scenario’s neemt de prestatie ervan sterk af:
Als je vaak met gegevensanalyse werkt, is het misschien interessant om eens te kijken naar de integraties met Power BI, dat dezelfde technologie gebruikt. Ook is het essentieel om met andere bestandsformaten te kunnen werken; onze handleiding over het bewerken van CSV-bestanden in Excel kan je daarbij nuttige tips geven.
Als je bedrijf al een licentie voor Adobe Acrobat Pro heeft, is de exportfunctie daarvan een van de meest betrouwbare oplossingen. Deze functie presteert vaak beter dan Power Query wat betreft het behoud van de opmaak van complexe tabellen en tabellen met een ongebruikelijke lay-out.
Het gaat heel eenvoudig: open de PDF, ga naar 'Alle tools', kies 'PDF exporteren', stel het formaat in op 'Spreadsheet' en sla je nieuwe Excel-bestand op.
Het resultaat is bijna altijd strak en netjes. Er zijn echter twee belangrijke nadelen:
Tools zoals iLovePDF, Smallpdf of het open-sourceprogramma Tabula zijn ontzettend handig: je sleept het bestand ernaartoe, klikt op een knop en downloadt het resultaat. Ze zijn een goede keuze voor incidentele conversies van niet-gevoelige gegevens.
Achter dit gebruiksgemak schuilt echter een enorm risico: de gegevensbeveiliging.
Als je een document naar een server van een derde partij uploadt, verlies je in feite de controle erover. Als die pdf rekeningafschriften, klantgegevens, vertrouwelijke prijslijsten of andere strategische informatie bevat, stel je je bedrijf bloot aan mogelijke inbreuken op de privacy en ernstige risico’s op het gebied van de naleving van de AVG.
Voor kleine en middelgrote ondernemingen die in Europa actief zijn, is dit geen onbelangrijke kwestie. Het is acceptabel om een online omzetter te gebruiken om een openbaar Istat-rapport te analyseren. Dit doen met de financiële gegevens van je eigen bedrijf is echter een riskante zet die je zorgvuldig moet afwegen.
Als je team elke maand tientallen bankafschriften, facturen of rapporten in hetzelfde formaat moet verwerken, is het handmatig invoeren daarvan meer dan alleen maar vervelend: het is een operationele bottleneck.
Voor kleine en middelgrote ondernemingen die grote hoeveelheden gestandaardiseerde documenten verwerken, is automatisering via Python-scripts geen luxe, maar een gerichte investering in efficiëntie. Natuurlijk vereist dit technische vaardigheden, maar het rendement op de investering is enorm in termen van tijdwinst en het voorkomen van fouten.

Python is op dit gebied toonaangevend dankzij gratis en uiterst krachtige bibliotheken zoals pdfplumber en Camelot, die speciaal zijn ontworpen om de structuur van tabellen in PDF-bestanden te herkennen en te reconstrueren.
pdfplumber: Het is uiterst veelzijdig en uitstekend geschikt voor het extraheren van tabellen, tekst en metagegevens, waarbij de positie van elk afzonderlijk teken wordt geanalyseerd.Camelot: Gespecialiseerd in het extraheren van tabellen, biedt het geavanceerde algoritmen voor het bewerken van tabellen met en zonder zichtbare scheidingslijnen.Praktijkscenario: Stel je voor dat je aan het einde van de maand 50 facturen van een leverancier ontvangt. In plaats van urenlang een medewerker hiermee bezig te houden, kan een Python-script deze facturen scannen, de totalen en datums eruit halen en een Excel-bestand genereren dat klaar is voor analyse. Dit alles in minder dan een minuut en zonder enig risico op menselijke fouten.
Zodra deze gegevens zijn geëxtraheerd en gestructureerd, kunnen ze naar analyseplatforms worden verzonden. Als je meer wilt weten over hoe je deze gegevens in bredere datastromen kunt integreren, ontdek dan hoe de API’s van ELECTE werken om het verzenden van gegevens naar ons platform te automatiseren.
Wanneer traditionele methoden tekortschieten, komt kunstmatige intelligentie in beeld. AI-aangedreven platforms zoals ELECTE een ware revolutie, vooral bij gescande documenten of documenten met een complexe opmaak.
We hebben het hier niet over de oude OCR, die zich beperkte tot het 'lezen' van de tekst. Moderne oplossingen combineren OCR met geavanceerde taalmodellen (LLM) om de structuur, de context en de verbanden tussen de gegevens te begrijpen.
Stel je een financieel rapport voor met tabellen die over meerdere pagina’s lopen. Een AI-platform kan:
Dit verandert alles. In plaats van ruwe gegevens te extraheren, ‘verwerkt’ het AI-platform de PDF en levert deze terug als een opgeschoonde dataset die klaar is voor analyse. Als je hier meer over wilt weten, kun je ons artikel lezen over de beste AI-oplossingen voor bedrijven.
De echte waarde van AI zit niet in het verzamelen van gegevens, maar in het genereren van kant-en-klare informatie. Je krijgt niet zomaar een Excel-bestand, maar gegevens die je team direct kan gebruiken om strategische beslissingen te nemen, zonder tijd te verspillen aan het opschonen ervan.
Het is interessant om te weten dat Milaan de grootste importerende stad van Italië is. Maar door automatisch een volledig rapport over de importerende provincies te kunnen genereren, kan je team veel meer doen: trends vergelijken, de voorraad optimaliseren en de kosten verlagen.
Met zoveel opties, hoe kies je dan de juiste voor jou? Het antwoord hangt af van vier belangrijke factoren die bepalend zijn voor de efficiëntie, de veiligheid en de kosten van je operatie.
Dit beslissingsschema helpt je om het logische verloop van je keuze in kaart te brengen.
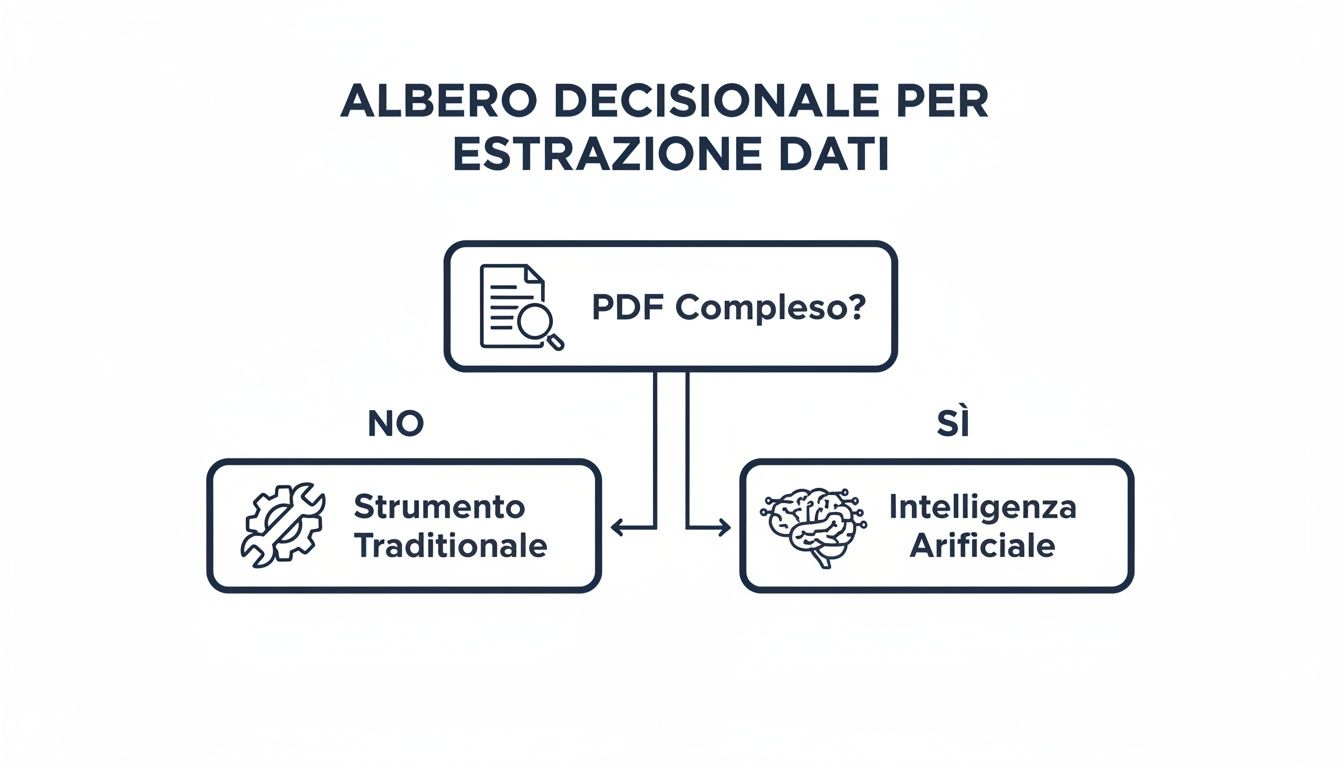
Het principe is simpel: voor eenvoudige PDF-bestanden en incidentele taken zijn traditionele tools zoals Power Query ideaal. Voor grote volumes, complexe documenten en terugkerende workflows ELECTE een AI-aangedreven platform zoals ELECTE een vervelende klus in een geautomatiseerd proces dat waarde oplevert.
Het importeren van een PDF in Excel hoeft niet langer een handmatig en frustrerend proces te zijn. Tegenwoordig heb je een hele reeks hulpmiddelen tot je beschikking, van gratis en ingebouwde tools zoals Power Query tot geavanceerde automatiseringsoplossingen en AI-aangedreven platforms.
De keuze hangt af van uw specifieke behoeften: voor incidentele bewerkingen op eenvoudige bestanden is Power Query onverslaanbaar. Voor het beheer van terugkerende hoeveelheden complexe en gevoelige documenten zijn automatisering en kunstmatige intelligentie niet langer een luxe, maar een strategische noodzaak. Door handmatige extractie te elimineren, bespaart u niet alleen tijd en vermindert u fouten, maar maakt u ook uw meest waardevolle middelen vrij om zich te concentreren op wat er echt toe doet: gegevens analyseren om slimmere en snellere zakelijke beslissingen te nemen. Zo verandert u een eenvoudig document in een bron van concurrentievoordeel.
Klaar om voorgoed afscheid te nemen van kopiëren en plakken? Ontdek hoe ELECTE uw besluitvorming ELECTE versnellen door je meest complexe PDF's om te zetten in bruikbare inzichten.

.svg)
.svg)
.svg)






