

Je ontvangt een XML-bestand via PEC. Je opent het in je browser, ziet een wirwar van tags en denkt dat het probleem ligt in het ‘lezen’ ervan. In werkelijkheid is dat slechts de eerste hindernis. Het echte probleem binnen het bedrijf is een ander: nagaan of die gegevens correct en consistent zijn en klaar om in je rapporten te worden verwerkt.
Voor veel Italiaanse KMO’s is dit onderwerp niet langer strikt technisch van aard. Sinds elektronische facturering verplicht is geworden, is XML een vast onderdeel geworden van de dagelijkse werkzaamheden op het gebied van administratie, managementcontrole en analyse. Het volstaat niet om het document alleen maar te bekijken. Je moet het verschil kunnen zien tussen een leesbaar bestand en een betrouwbaar bestand. Je moet weten wanneer een snelle controle volstaat en wanneer je de gegevens moet parseren, valideren en normaliseren voordat je ze in Excel, een BI-systeem of een analyseplatform laadt.
Als je op zoek bent naar een praktische handleiding voor het lezen van XML-bestanden, dan is dit de juiste aanpak: begin met eenvoudige methoden, zoek uit waar het misgaat en bouw vervolgens een workflow op die ruwe XML omzet in bruikbare bedrijfsgegevens. Zo worden fouten beperkt en wordt de tijd tussen ‘ik heb het bestand’ en ‘ik heb bruikbare inzichten’ verkort.
Een XML-bestand organiseert gegevens in een hiërarchische structuur. Er is een hoofdelement, er zijn geneste secties en elk blok beschrijft een stukje informatie met een precieze betekenis. Voor wie administratieve processen beheert, maakt dit detail het verschil tussen leesbare gegevens en gegevens die daadwerkelijk bruikbaar zijn.
Het gaat er niet om het bestand te ‘openen’. Het gaat erom te achterhalen of dat bestand zonder fouten kan worden verwerkt in de controle-, boekhoud- en analysestromen.
Laten we eens kijken naar een elektronische factuur. In één en hetzelfde bestand staan gegevens van de leverancier, gegevens van de klant, belastbare bedragen, btw, artikelregels, betalingsvoorwaarden, orderreferenties en vaak ook uitzonderingen die het lezen bemoeilijken. In XML staat deze informatie niet onder elkaar, zoals in een gewoon document. Ze staat op specifieke posities, en die positie geeft aan wat ze betekenen.
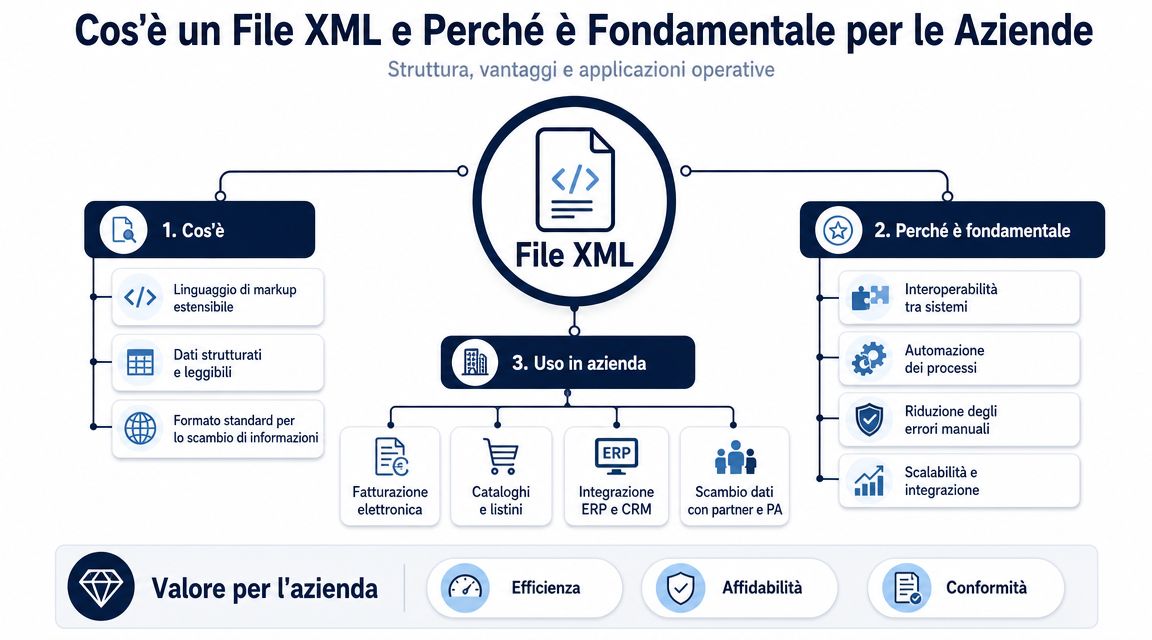
Voor een manager is het nuttige onderscheid niet dat tussen ‘tags’ en ‘attributen’ in theoretische zin. Het is het onderscheid tussen een op zichzelf staand gegeven en een betrouwbaar gegeven. Het heeft weinig zin om ‘1000,00’ buiten de context te lezen. Als je het op de juiste plaats in het bestand leest, kun je begrijpen of het gaat om het totaalbedrag van het document, het belastbaar bedrag, de belasting of de waarde van een enkele regel.
Hier ligt het eerste operationele voordeel. XML behoudt de context van de gegevens.
Praktische regel: een XML-bestand goed lezen betekent dat je de betekenis van de waarde controleert, niet alleen de waarde zelf.
In Italië is dit onderwerp concreet geworden door de opkomst van elektronische facturering. In het FatturaPA-formaat is XML de standaard geworden voor fiscale documentatie. Daardoor is het lezen ervan niet langer alleen een zaak van de IT-afdeling. Het betreft ook de administratie, de managementcontrole, de inkoopafdeling en iedereen die deze gegevens moet gebruiken om beslissingen te nemen.
In de praktijk zie ik steeds hetzelfde probleem. Het bestand bestaat, de gegevens zijn aanwezig, maar het duurt veel te lang om ze om te zetten in bruikbare informatie. Iemand opent het XML-bestand, controleert het visueel, kopieert waarden naar Excel, corrigeert inconsistente velden, hernoemt leveranciers die op verschillende manieren zijn geschreven en probeert uitgavencategorieën te reconstrueren die het bestand niet in een voor analyse geschikte vorm weergeeft. De kosten zijn niet alleen operationeel. Het is verloren ‘time-to-insight’.
Met FatturaPA is het risico nog duidelijker. Twee formeel correcte bestanden kunnen dezelfde analyseproblemen veroorzaken als in de regelbeschrijvingen veel onduidelijkheden staan, als de orderreferenties onvolledig zijn of als de leveranciersgegevens met verschillende varianten worden ingevoerd. Op dat moment is het probleem niet het lezen van XML. Het probleem is te voorkomen dat geldige fiscale gegevens onbetrouwbare bedrijfsgegevens worden.
Een veelgemaakte fout is om XML te behandelen als een bijlage die moet worden weergegeven. Binnen een bedrijf werkt het beter om het te beschouwen als een gestructureerde gegevensbron die moet worden gecontroleerd voordat deze wordt gebruikt voor rapporten, dashboards en uitgavenmodellen. Als deze fase slecht wordt afgehandeld, komt het financiële team terecht in discussies over cijfers die ogenschijnlijk nauwkeurig zijn, maar gebaseerd zijn op inconsistente classificaties.
De juiste vragen zijn in het begin de volgende:
Dit zijn zeer concrete controles. Ze zijn bedoeld om te voorkomen dat leveranciers dubbel in de rapporten voorkomen, dat de btw verkeerd wordt geïnterpreteerd, dat kostenplaatsen onvolledig worden ingevuld en dat de afstemming aan het einde van de maand traag verloopt.
Hier wordt de kloof tussen technische interpretatie en zakelijke waarde duidelijk zichtbaar. Een parser leest het bestand. Een goed ontworpen proces levert schone, vergelijkbare en analyseklare gegevens op. Platformen zoals ELECTE zijn juist in het leven geroepen om deze kloof te dichten, door het handmatige werk te verminderen dat de ontvangen XML scheidt van de inzichten die nodig zijn om betere beslissingen te nemen.
Voor snelle controles van één enkel bestand heb je geen parsers of bibliotheken nodig. Het is belangrijk om te weten of je een visuele controle uitvoert van slechts enkele velden, of dat je al te maken hebt met gegevens die uiteindelijk in de boekhouding, rapportage of managementcontrole terechtkomen. Dat verschil is van belang, vooral bij FatturePA. Een controle die vandaag haastig wordt uitgevoerd, kan morgen een foutieve regel in de leveranciersdataset opleveren.

Browsers, teksteditors en speciale viewers bieden een oplossing voor een specifiek probleem: de inhoud snel lezen zonder een technisch proces op te zetten. Voor een op zichzelf staand bestand is dat vaak voldoende. Je kunt een XML-bestand openen in Chrome, Edge of Firefox om de structuur te bekijken, of Kladblok, WordPad of TextEdit gebruiken als je de tags direct wilt inspecteren. Bij elektronische facturen maakt een speciale viewer de koptekst, documentregels, het belastbaar bedrag en de btw beter leesbaar.
Het komt erop neer dat:
| Instrument | Handig voor | Belangrijkste beperking |
|---|---|---|
| Browser | Snelle visuele controle van de constructie | Er wordt niet gecontroleerd of de velden en secties onderling consistent zijn |
| Teksteditor | Directe inspectie van de tags | Bij lange of geneste bestanden wordt het lastig |
| Excel | Voorlopige controle in tabelvorm | Gaat slecht om met hiërarchieën en herhalingen |
| Speciale viewer | Facturen en belastingdocumenten duidelijker lezen | Het bereidt de gegevens niet voor op analyse of automatisering |
Als je de datum van het document, het btw-nummer, het factuurtotaal of de aanwezigheid van bijlagen moet controleren, zijn deze hulpmiddelen geschikt.
Als het daarentegen de bedoeling is om leveranciers te vergelijken, uitgaven te categoriseren of een dashboard bij te werken, vertraagt het louter bekijken van een bestand het werk en ontstaat er te veel ruimte voor handmatige fouten. Dit is de klassieke kloof tussen het bekijken van een bestand en het tijdig verkrijgen van betrouwbare gegevens.
Het openen van een XML-bestand betekent niet dat de gegevens die je in de rapporten gaat gebruiken, ook gevalideerd zijn.
Een ander praktisch punt betreft het volume. Tien bestanden kun je nog wel met de hand controleren. Honderden FatturePA-facturen daarentegen niet. In dat geval loont het de moeite om al na te denken over een herhaalbare werkstroom of over tools die de inhoud op een gestructureerde manier lezen, bijvoorbeeld via een API om fiscale documenten op een geïntegreerde manier te verwerken en te beheren.
In Italië is het terugkerende probleem niet het openen van een .xml, maar begrijpen wat je moet doen als er een .xml.p7m via PEC. Er moet onderscheid worden gemaakt tussen eenvoudige XML-bestanden en digitaal ondertekende bestanden. In het tweede geval zijn hulpmiddelen nodig die de handtekening kunnen lezen, de inhoud kunnen extraheren en de juiste XML kunnen weergeven, zoals wordt uitgelegd in deze handleiding over XML en XML P7M in de PEC.
Hier kosten fouten tijd:
Voor een administratief medewerker is de handigste volgorde heel eenvoudig:
Deze methoden doen hun werk goed bij controles op het eerste niveau. Ze bieden echter geen oplossing voor het probleem dat het bedrijf echt parten speelt: het omzetten van fiscale XML-bestanden, die vaak onregelmatig of weinig uniform zijn, in schone en vergelijkbare gegevens, zonder dat de tijd tussen het ontvangen van het document en het verkrijgen van bruikbare informatie langer wordt.
Wanneer de bestanden zich beginnen op te stapelen, is handmatig werk niet langer haalbaar. Op dat moment is het lezen van XML-bestanden met code geen elegante oplossing. Het is de eerste stap om repetitieve taken, kopieerfouten en inconsistente datasets te voorkomen.

Een degelijke aanpak voor het lezen van XML volgt altijd dezelfde logica: parseren, normaliseren, gericht extraheren. In de Java- en Android-tutorials verloopt de juiste werkstroom via parse(), door de as te normaliseren met doc.getDocumentElement().normalize() en vervolgens door het herstel van de velden met getElementsByTagName, een stabielere methode dan het simpelweg bekijken in een teksteditor, zoals blijkt uit deze technische handleiding over het uitlezen van XML-gegevens.
Deze volgorde is belangrijker dan de taal die je kiest. Als je de normalisatie overslaat, als je op een te simplistische manier naar knooppunten zoekt, of als je ervan uitgaat dat een tag altijd maar één keer voorkomt, zal je script weliswaar op sommige bestanden werken, maar juist falen bij de bestanden die er echt toe doen.
Voor projecten die vervolgens moeten samenwerken met externe systemen, kan het nuttig zijn om een reproduceerbare en gedocumenteerde extractiestroom op te zetten. Als je aan applicatie-integraties werkt, is de documentatie over de API’s van ELECTE met een geverifieerd Postman-profiel een nuttig uitgangspunt, vooral om te begrijpen hoe je een reeds opgeschoonde dataset kunt koppelen aan vervolgprocessen.
Hieronder vind je enkele eenvoudige voorbeelden. Het is niet de bedoeling om elk geval te behandelen, maar om je de basislogica te laten zien: het bestand openen, een knooppunt zoeken, een waarde afdrukken.
import xml.etree.ElementTree as ETtree = ET.parse("fattura.xml")root = tree.getroot()nummer = root.find(".//Numero")if nummer is not None:print(nummer.text)Python is vaak de snelste keuze voor prototypes, transformaties en lichte pijplijnen. Het is ideaal wanneer je veel XML-bestanden moet inlezen, een paar velden eruit moet halen en deze in CSV of JSON moet opslaan.
const xmlString = `<fattura><Numero>123</Numero></fattura>`;const parser = new DOMParser();const xmlDoc = parser.parseFromString(xmlString, "application/xml");const numero = xmlDoc.getElementsByTagName("Numero")[0];console.log(numero.textContent);Deze aanpak is handig voor snelle tests op de pagina zelf of voor kleine interne tools. Het is geschikt voor eenvoudige interfaces, maar minder voor gestructureerde backoffice-processen.
const fs = require("fs");const xml2js = require("xml2js");const xml = fs.readFileSync("fattura.xml", "utf8");xml2js.parseString(xml, (err, result) => {if (err) throw err;console.log(result.fattura.Numero[0]);});Als je aan de serverkant werkt en automatiseringen wilt bouwen, blijft Node.js een praktische keuze. Het voordeel is dat je het lezen van XML eenvoudig kunt integreren met het bestandssysteem, verwerkingswachtrijen en interne diensten.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse("fattura.xml");doc.getDocumentElement().normalize();NodeList lista = doc.getElementsByTagName("Numero");if (lista.getLength() > 0) {System.out.println(lista.item(0).getTextContent());}Java wordt vaak gebruikt in bedrijfsomgevingen, bedrijfssoftware en middleware. Het belangrijkste is hier niet alleen dat de gegevens worden gelezen, maar dat dit op een voorspelbare en onderhoudbare manier gebeurt.
library(XML)doc <- xmlParse("fattura.xml")numero <- xpathSApply(doc, "//Numero", xmlValue)print(numero)R is zinvol wanneer het parseren deel uitmaakt van een analytische taak. Als je volgende stap een statistische analyse of gegevensvoorbereiding is, kun je alles in dezelfde omgeving houden.
Als je team elke week dezelfde bestanden opent en dezelfde controles uitvoert, ben je al op het terrein van automatisering.
De echte meerwaarde zit niet in het ‘lezen van XML met code’. Het gaat erom mensen te ontlasten van repetitief werk en een workflow op te zetten die consistente datasets oplevert.
De echte problemen beginnen wanneer het niet langer om één enkel bestand gaat. Een enkele FatturaPA is bijna altijd goed te beheren. De moeilijkheden ontstaan wanneer je documenten van meerdere maanden, verschillende leveranciers, ongelijk ingevulde velden en ingesloten bijlagen moet samenvoegen.
Bij Italiaanse KMO’s is het meest voorkomende geval niet het geïsoleerde ‘megabestand’, maar de batch. Een jaarlijkse export van inkomende facturen kan een structuur opleveren met meer dan 380.000 knooppunten verdeeld over 4.200 facturen, bestaande uit kopteksten, detailregels, betalingsgegevens en base64-bijlagen. In dergelijke scenario's is het probleem niet het openen van het document, maar het omzetten van heterogene XML-bestanden in een samenhangende dataset.
Hier komt een technische keuze om de hoek kijken die gevolgen heeft voor de bedrijfsvoering. In de .NET-omgeving geeft Microsoft aan dat XmlDocument het document in het geheugen laadt en handig is voor het lezen en bewerken ervan, terwijl het bij grote bestanden of alleen-lezen-bewerkingen raadzaam is om te kiezen voor efficiëntere benaderingen, zoals streaming-parsers of XPathDocument, om overmatig RAM-gebruik te voorkomen, zoals aangegeven in de Microsoft-documentatie over het lezen van XML met XmlDocument en XPathDocument.
In de praktijk:
De afweging is simpel. Met het model in het geheugen kun je sneller ontwikkelen. Het streamingmodel presteert beter in de productieomgeving wanneer er veel of grote bestanden zijn.
Veel teams beperken zich tot XSD-validatie. Dat is nuttig, maar niet voldoende. Een bestand kan aan het schema voldoen en toch verderop in het proces onjuiste gegevens opleveren.
Typische voorbeelden uit de dagelijkse praktijk:
| Soort controle | Wat wordt gecontroleerd | Waarom is het nodig? |
|---|---|---|
| Structureel | Tags, indeling, hiërarchie | Voorkom parsefouten |
| Semantisch | Logische consistentie van de gegevens | Voorkom verkeerde analyses |
| In gebruik | Aanwezigheid van velden die nuttig zijn voor de rapportage | Vermijd onbruikbare datasets |
Het meest verraderlijke geval is het volgende: het „ImportoTotaleDocumento” is formeel geldig, maar komt niet overeen met de som van de regels, wellicht vanwege afrondingsregels in het boekhoudsysteem van de leverancier. Of btw-codes die formeel zijn toegestaan, maar niet in overeenstemming zijn met de aard van de transactie.
Een formeel correct bestand kan je rapportage toch verstoren.
Er is nog een andere bekende valkuil in de FatturaPA-facturen. De tag ‘DatiBeniServizi’ bevat vrije beschrijvingen. Dezelfde kosten kunnen op veel verschillende manieren worden weergegeven, met duidelijke, afgekorte of cryptische teksten. Als je geen normalisatiestap invoert, wordt elke analyse per uitgavencategorie onbetrouwbaar.
Daarom is het in serieuze gegevensstromen het lezen van het bestand slechts het eerste niveau. Het tweede niveau bestaat altijd uit een reeks regels voor consistentie en opschoning. Daar wordt de kwaliteit van de gegevens gewaarborgd, niet in de parser.
Een correct ingelezen XML-bestand is nog geen bruikbare dataset. Het is een gestructureerd document. Om analyses, vergelijkingen, groeperingen en dashboards te kunnen maken, moet je het bijna altijd omzetten naar een formaat dat gemakkelijker te verwerken is.
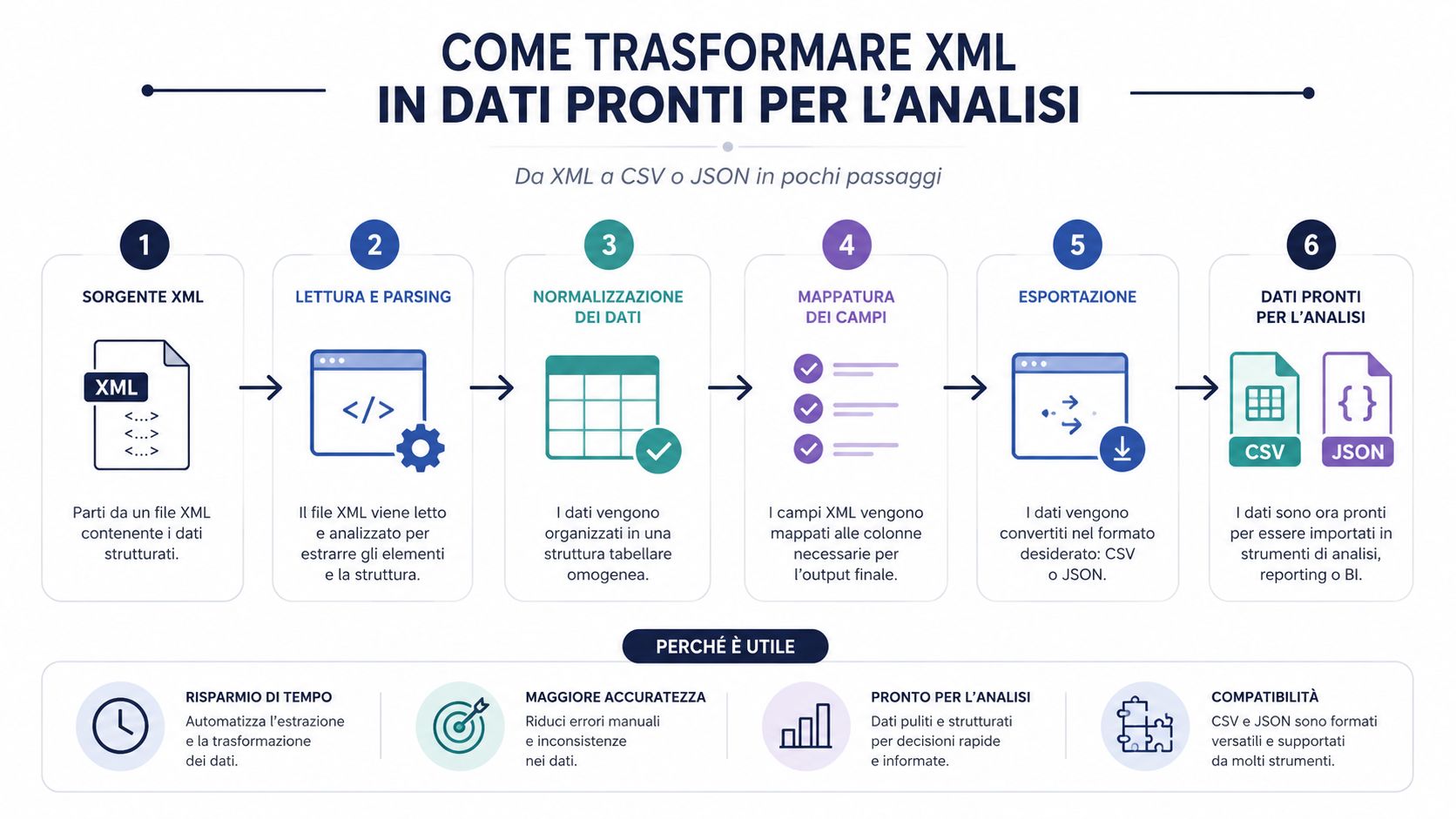
Dit is het punt dat in veel processen over het hoofd wordt gezien. De bottleneck zit zelden in het parseren zelf. Een degelijke bibliotheek leest XML razendsnel in. De tijd gaat verloren bij het interpreteren van de structuur, het extraheren van de relevante velden, het opschonen, het normaliseren en het laden in een analysetool.
Daarom is het converteren naar CSV of JSON geen luxe. Het is een cruciale stap in het proces. Als je deze stap overslaat en rechtstreeks in het ruwe bestand werkt, krijg je bijna altijd te maken met handmatige controles, geïmproviseerde kolommen en logica die moeilijk te repliceren is.
Een handig naslagwerk voor wie vaak met XML en spreadsheets werkt, is deze handleiding over hoe je op een overzichtelijkere manier van XML naar Excel kunt overschakelen.
Het juiste formaat hangt af van hoe je de gegevens later gaat gebruiken.
CSV werkt goed als je één regel per document of één regel per factuurregel wilt, en vervolgens Excel, Power Query of BI wilt gebruiken.
Python-voorbeeld:
import xml.etree.ElementTree as ETimport csvtree = ET.parse("fattura.xml")root = tree.getroot()with open("fatture.csv", "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(["nummer", "datum"])nummer = root.findtext(".//Numero")data = root.findtext(".//Data")writer.writerow([numero, data])Het voordeel is de eenvoud. Het nadeel is dat je goed moet bedenken hoe je de hiërarchie wilt afvlakken. Als een factuur meerdere detailregels bevat, moet je een duidelijke keuze maken wat betreft de gedetailleerdheid en de koppelingssleutel.
JSON is het meest geschikt wanneer je een deel van de hiërarchische structuur wilt behouden.
JavaScript-voorbeeld:
const record = {numero: "123",data: "2024-01-15",righe: [{ descrizione: "Servizio", importo: "100.00" }]};console.log(JSON.stringify(record, null, 2));Gebruik dit wanneer je volgende stap een API, een data lake of een applicatie is die goed overweg kan met geneste objecten.
Hier is een handige vuistregel:
Het XML-bestand is de container. CSV en JSON zijn de formaten die de inhoud daadwerkelijk bruikbaar maken.
Als je de time-to-insight wilt verkorten, is dit het punt waarop je methodisch moet investeren. Niet in het zoeken naar een handigere visualisatietool, maar in het definiëren van een stabiele en herhaalbare transformatie.
Zodra het bestand is ingelezen, gevalideerd en verwerkt, krijgt het werk een heel ander karakter. Je bent niet langer bezig met het uitpluizen van tags. Je houdt je eindelijk bezig met kosten, afwijkingen, leveranciers, uitgavencategorieën en operationele trends.
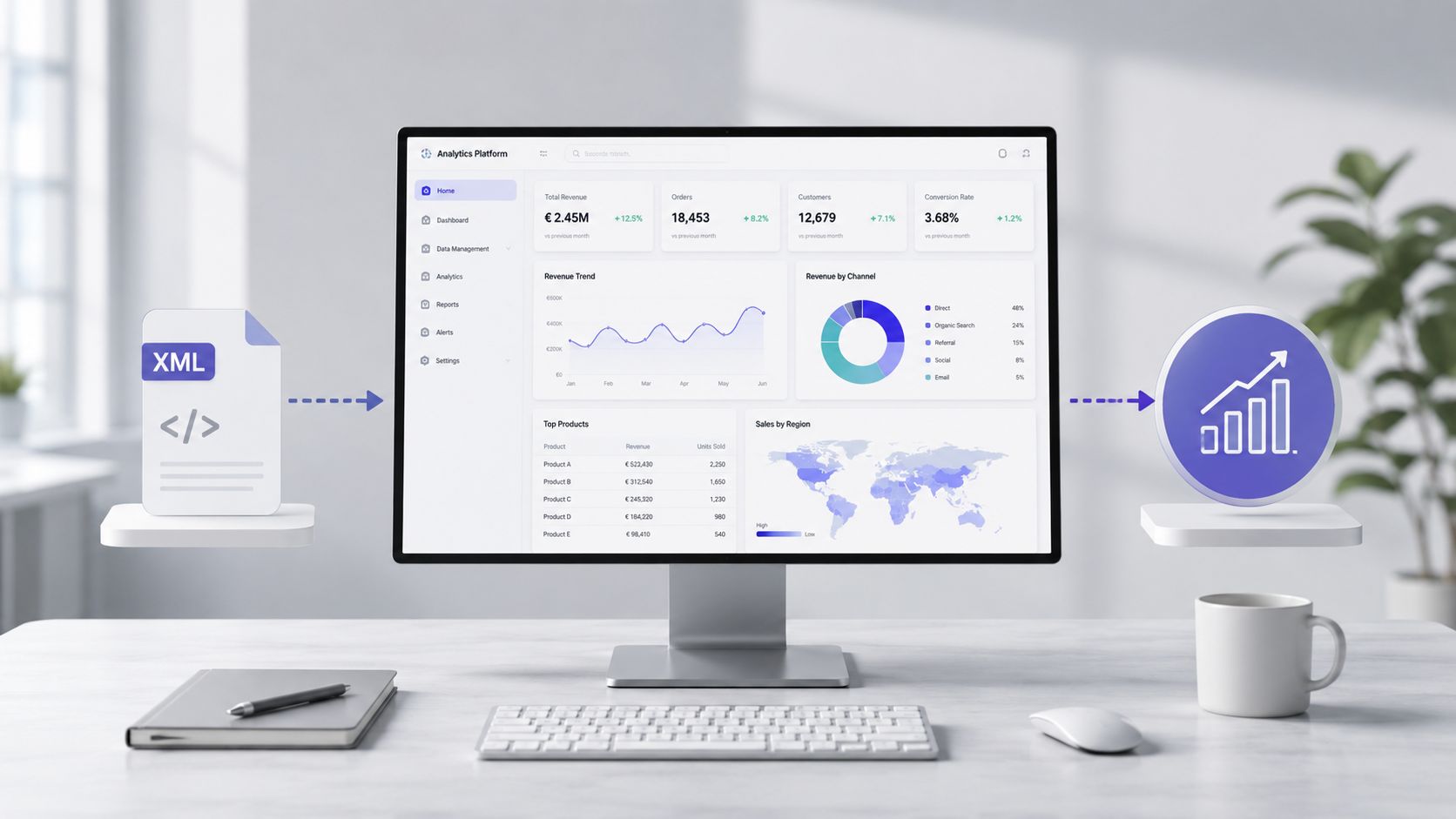
In de praktijk zit de waarde niet in de tijd die het parseren kost. Die zit in de tijd die verstrijkt tussen het ruwe bestand en het moment waarop je een beslissing kunt nemen op basis van die informatie. Bij een handmatige werkstroom moet iemand het document openen, de structuur doorgronden, de velden eruit halen, de waarden opschonen, de tekst normaliseren en vervolgens rapporten opstellen. Het is een kwetsbaar proces.
Een klassiek voorbeeld in FatturaPA is de vrije tekst in DatiBeniServizi. Dezelfde dienst kan door verschillende leveranciers op veel verschillende manieren worden beschreven. Als je die gegevens importeert zonder een consistente toewijzing, leidt de analyse per kostencategorie tot onnodige aggregaties.
Daarom is er, voordat het analyseplatform wordt ingezet, een voorbereidende fase nodig, aangezien:
Als deze fase goed wordt uitgevoerd, werkt elk analyseplatform beter. Als je je wilt verdiepen in het besluitvormings- en visuele aspect van deze stap, is de bron over het opbouwen van verhalen met gegevens nuttig, omdat daarin wordt getoond hoe een opgeschoonde dataset een nuttig verhaal wordt voor besluitvormers.
Op dit punt is het XML-bestand niet langer een technisch probleem, maar wordt het grondstof voor inzichten. Een goed voorbereide dataset kan worden gebruikt voor uitgavenanalyses, het volgen van trends, het signaleren van afwijkingen en het opsporen van uitzonderingen.
Om een platform te kiezen dat geschikt is voor deze laatste stap, kan het nuttig zijn om te vergelijken wat moderne bedrijfsanalysesoftware te bieden heeft ten opzichte van puur handmatige werkprocessen op basis van spreadsheets en draaitabellen.
Het juiste criterium is hier niet: “Kan hij XML openen?”. Dat is het minimum. De relevante vraag is een andere:
| Vraag | Waarom het belangrijk is |
|---|---|
| De gegevens komen al opgeschoond binnen | Vermijd concrete inzichten op basis van onjuiste gegevens |
| De categorieën zijn consistent | Vergelijk je leveranciers en periodes echt? |
| De afwijkingen vallen meteen op | Verminder tijdverlies door handmatige controles |
| Het rapport is begrijpelijk voor mensen uit de bedrijfs- en financiële wereld | Besluitvorming versnellen |
Het verschil tussen een onvolwassen en een volwassen proces zit niet in het vermogen om XML-bestanden te lezen. Het zit in het vermogen om deze om te zetten in een betrouwbare database, waardoor het team niet telkens opnieuw hetzelfde werk hoeft te doen.
Als je XML-bestanden op een voor je bedrijf nuttige manier moet lezen, houd dan deze checklist in gedachten. Deze is concreter dan welke technische definitie dan ook en helpt je de juiste methode te kiezen zonder tijd te verspillen.
Gebruik niet altijd dezelfde aanpak. Browsers, editors en visualisatietools zijn geschikt voor snelle controles. Parsers en scripts zijn nodig wanneer het bestand als input moet dienen voor herhaalde processen. Als je visualisatie en gegevensverwerking door elkaar haalt, loop je het risico rapporten op te stellen op een wankele basis.
De bestanden .xml.p7m vereisen een specifieke stap in het beheer van de handtekening. Als de inhoud afkomstig is van een PEC-adres, is deze controle niet bijkomstig. Het maakt deel uit van het correct lezen van het document.
Het naleven van een schema is geen garantie voor een degelijke dataset. Logische inconsistenties, zoals niet-overeenstemmende totalen of dubbelzinnige fiscale classificaties, zijn de factoren die de analyse het vaakst in de weg staan. Semantische controle is wat het verschil maakt tussen een ‘aanvaardbaar’ bestand en betrouwbare gegevens.
CSV en JSON zijn geen louter cosmetische aanpassing. Ze vormen het punt waarop XML bruikbaar wordt voor analysetools, spreadsheets, pijplijnen en rapporten. Hoe eerder je deze transformatie definieert, hoe eerder je handmatig werk en improvisatie kunt verminderen.
Het is niet de bedoeling dat je XML-bestanden leest. Het gaat erom nuttige inzichten te verkrijgen zonder het systeem te vervuilen met onzuivere gegevens. Als de gegevensstroom geen samenhangende dataset oplevert, ligt het probleem niet bij het uiteindelijke dashboard. Het ligt veel verder stroomopwaarts.
In de praktijk kun je deze mini-checklist voor elk nieuw project gebruiken:
Als je reeds verwerkte gegevens wilt omzetten in duidelijke en bruikbare inzichten, helpt ELECTE het MKB om de stap te zetten van een opgeschoonde dataset naar slimme rapportages, met een aanpak die ook voor niet-technische teams toegankelijk is. Dit is de snelste manier om de kloof tussen operationele gegevens en besluitvorming te overbruggen.

.svg)
.svg)
.svg)
.webp)




