

Je gegevens vertellen al een verhaal. Het probleem is dat ze vaak te zacht spreken.
Elke dag verzamelt een mkb-bedrijf feedback van klanten, bestellingen, supporttickets, financiële transacties, zakelijke e-mails en CRM-notities. Al dit materiaal bevat nuttige signalen. Sommige wijzen erop dat een klant op het punt staat weg te lopen. Andere duiden op een operationeel risico. Weer andere laten zien welke producten aan een opmars bezig zijn of juist aan populariteit inboeten. Zonder een duidelijke methode blijven die signalen echter slechts ruis.
Van alle algoritmen die helpen om orde te scheppen in deze chaos, nemen de naïeve Bayesiaanse classifiers een bijzondere plaats in. Ze zijn logisch eenvoudig te begrijpen, snel te trainen en vaak effectiever dan de naam ‘naïef’ doet vermoeden. Ze zijn niet voor elk scenario de juiste keuze, maar bij veel praktische bedrijfsproblemen bieden ze een zeldzame balans tussen snelheid, interpreteerbaarheid en bruikbare resultaten.
Als je in het bedrijfsleven werkt, hoef je geen onderzoeker te worden om ze te begrijpen. Je moet weten wat ze doen, waarom ze goed werken ook al vereenvoudigen ze de werkelijkheid sterk, en in welke gevallen ze je kunnen helpen betere beslissingen te nemen. Juist hier is het de moeite waard even stil te staan.
Veel bedrijven gaan op zoek naar geavanceerde modellen, terwijl het probleem in de eerste plaats vraagt om een betrouwbaar en gebruiksvriendelijk model. Om dezelfde reden wint in de financiële sector, de detailhandel of de klantenservice vaak het meest overzichtelijke proces, en niet het theoretisch meest verfijnde.
Naïeve Bayesiaanse classifiers gaan uit van een heel concreet idee. Als je over bepaalde aanwijzingen beschikt met betrekking tot een nieuw geval, kun je met een redelijke mate van zekerheid inschatten tot welke categorie het behoort. Als een e-mail bepaalde woorden bevat, kan het om spam gaan. Als een transactie bepaalde patronen vertoont, kan het nodig zijn deze te controleren. Als een recensie bepaalde termen gebruikt, kan dit duiden op tevredenheid of ontevredenheid.
Het woord ‘Bayesiaans’ roept beelden op van ingewikkelde formules. In werkelijkheid is de kern van de methode intuïtief. Je neemt wat je al weet, voegt daar nieuw bewijs aan toe en past je oordeel aan. Het is een gestructureerde manier van redeneren in onzekere situaties, precies wat managers elke dag doen, maar dan systematisch gemaakt door een algoritme.
Het verrassende is dat deze aanpak ook in moderne omgevingen, met grote hoeveelheden gegevens en snelle beslissingen, nog steeds goed werkt. Niet omdat hij de wereld perfect weergeeft, maar omdat hij het nuttige signaal van de ruis scheidt tegen zeer lage rekenkosten.
Bij zakelijke vraagstukken is de juiste vraag niet: „Welk model is het meest verfijnd?“. De vraag is: „Welk model levert betrouwbare beslissingen op binnen een tijdsbestek dat haalbaar is in de praktijk?“.
Daarom blijven naïeve Bayesiaanse classifiers belangrijk. Ze helpen je bij het classificeren, filteren, segmenteren en prioriteren. Bovendien kun je hiermee waarschijnlijkheid in het besluitvormingsproces integreren zonder dat elk project een technisch project wordt.
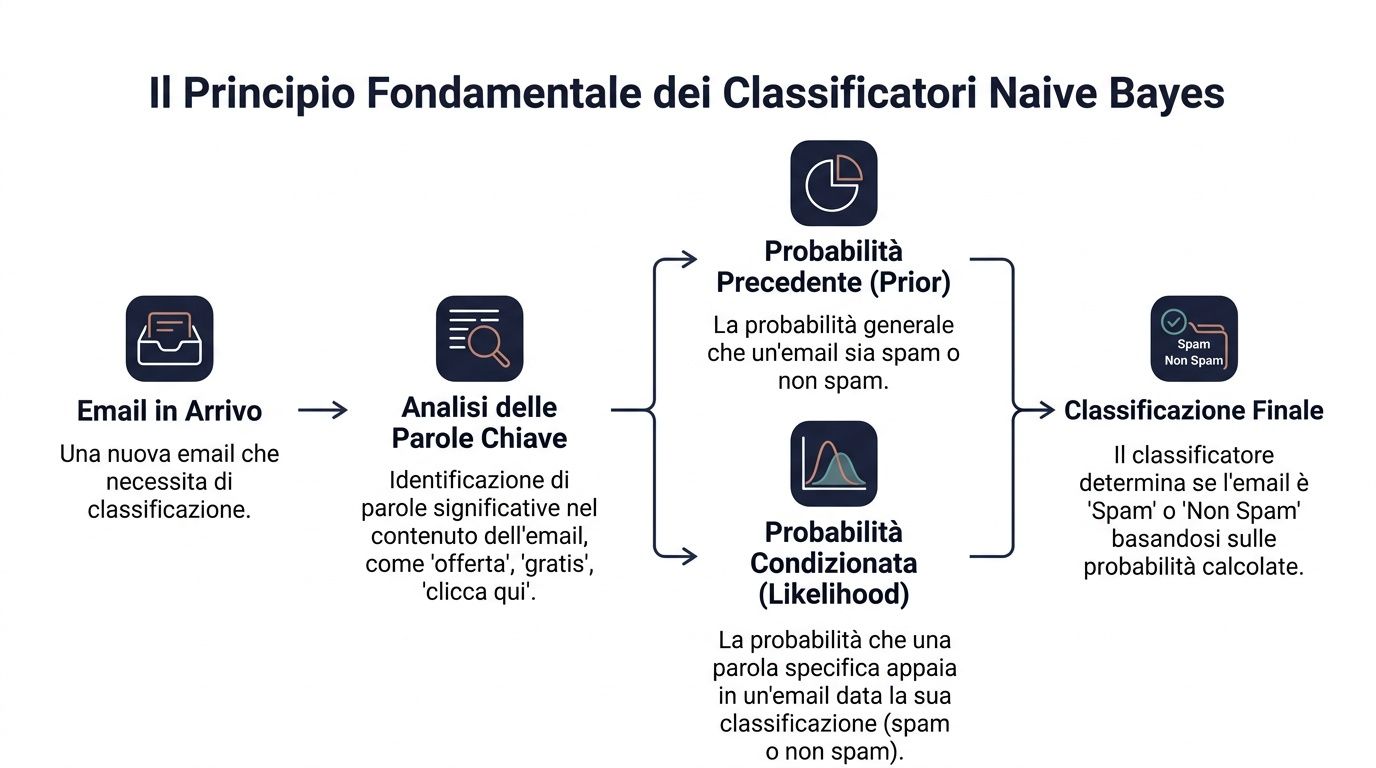
Het uitgangspunt is de stelling van Bayes. In eenvoudige bewoordingen komt het hierop neer: je begint met een uitgangskans en past die aan wanneer er nieuwe informatie binnenkomt.
In de taal van de data luidt de formule als volgt: P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y). Dit betekent dat de waarschijnlijkheid van een klasse, gegeven een reeks signalen, afhankelijk is van twee factoren. De eerste is de initiële waarschijnlijkheid van de klasse. De tweede is de mate waarin elk signaal met die klasse overeenkomt.
Vertaald naar een zakelijk voorbeeld. Je moet bepalen of een e-mail spam is of niet. Je hebt een algemene kans dat een binnenkomende e-mail spam is. Vervolgens let je op bepaalde woorden zoals ‘aanbieding’, ‘gratis’ en ‘klik hier’. Elk van deze woorden beïnvloedt de uiteindelijke beoordeling.
Een manager doet elke dag iets soortgelijks. Hij neemt nooit zomaar een beslissing. Hij gaat uit van een basissituatie en voegt daar aanwijzingen aan toe. Een klant die altijd regelmatig heeft gekocht, heeft een bepaald uitgangspunt. Als hij vervolgens geen e-mails meer opent, de waarde van zijn bestellingen verlaagt en een kritieke supportaanvraag indient, verandert je beoordeling.
De term 'naïef' verwijst naar een specifieke aanname. Het model behandelt de kenmerken alsof ze onderling onafhankelijk zijn, aangezien de klasse bekend is.
In de praktijk moet je, als je een e-mail classificeert, elk woord als een afzonderlijke aanwijzing beschouwen. Probeer niet alle complexe relaties tussen de termen in kaart te brengen. Dit is een sterke vereenvoudiging. In werkelijkheid komen veel woorden samen voor en hangen veel zakelijke gedragingen met elkaar samen.
Toch zorgt juist deze keuze ervoor dat het model erg licht is. Het hoeft geen ingewikkeld netwerk van afhankelijkheden te leren. Het moet eenvoudigere waarschijnlijkheden schatten en deze op een efficiënte manier combineren.
Praktische regel: Naïeve Bayes probeert niet de hele wereld te reconstrueren. Het probeert nuttige beslissingen te nemen op basis van weinig aannames en met een hoge snelheid.
Hier ontstaat vaak een misverstand. Velen lezen ‘naïeve aanname’ en concluderen dat het om een ‘zwak model’ gaat. Dat is niet het geval. Een model kan sterk vereenvoudigen en toch bruikbaar blijven, mits de vereenvoudiging precies datgene weergeeft wat voor de besluitvorming van belang is.
In 2004 heeft een theoretische analyse solide argumenten aangedragen voor de doeltreffendheid van Naive Bayes-classificatoren, ondanks de aanname van onafhankelijkheid, en ook verklaard waarom deze sneller de asymptotische foutgrens kunnen bereiken dan logistische regressie. Binnen dezelfde toepassingsgebieden behalen ze bij spamfiltering een nauwkeurigheid van meer dan 99% en schalen ze op naar miljoenen documenten, zoals beschreven in het artikel over Naive Bayes-classificatoren.
Dit punt is belangrijk voor een zakelijk publiek. De waarde van een algoritme zit niet alleen in de eindscore. Het zit ook in het vermogen om snel te worden getraind, zich aan te passen aan grote datasets en interpreteerbaar te blijven.
Wanneer je te maken hebt met verspreide teksten, categorieën, labels of signalen, werken naïeve Bayesiaanse classifiers goed omdat:
Er zijn echter twee punten waarmee je rekening moet houden.
Daarom moet Naïef Bayes worden gezien als een zeer effectief hulpmiddel bij snelle classificatieproblemen, en niet als een universele toverstaf. In veel praktische situaties is het echter een van de slimste manieren om te beginnen.
Een veelgemaakte fout is om over Naïeve Bayes te spreken alsof het in elke situatie om één en hetzelfde model gaat. In werkelijkheid bestaan er verschillende varianten, die zijn ontworpen voor verschillende soorten gegevens.
De juiste keuze hangt af van de vorm van de gegevens die je hebt. Als je de verkeerde variant kiest, kan het model weliswaar een voorspelling doen, maar redeneert het niet op de manier die het meest geschikt is voor jouw probleem.
Gaussian Naive Bayes is de meest geschikte variant wanneer de kenmerken continu zijn. Denk bijvoorbeeld aan het gemiddelde transactiebedrag, de leeftijd van de klant, de gemiddelde tijd tussen twee aankopen, de marge per eenheid of de waarde van de kassabon.
Het model gaat er hier vanuit dat de waarden binnen elke klasse een Gauss-verdeling volgen. Je hoeft dit niet als een theoretische beperking te zien. Onthoud gewoon het praktische idee: voor elke klasse schat het model een typisch middelpunt en een spreiding.
Deze aanpak is handig wanneer je gevallen wilt indelen zoals:
In een scikit-learn-benchmark met een dataset die vergelijkbaar is met Italiaanse e-commercegegevens, behaalde een Naive Bayes-model een nauwkeurigheid van 95% met 1000 voorbeelden, waarbij de trainingstijd 15% korter was dan bij logistische regressie . De aangegeven vergelijking is 0,01 s versus 0,1 s op een standaard-CPU, dankzij closed-loop training, zoals weergegeven in het hoofdstuk van Jake VanderPlas over In Depth Naive Bayes Classification.
Voor een bedrijf gaat het niet om de komma. Het punt is dat deze variant goede resultaten kan opleveren zonder lange trainingstijden en zonder een zware infrastructuur.
Als je met teksten, tickets, recensies of reacties werkt, is Multinomial Naive Bayes vaak de logische keuze. Hier zijn de kenmerken tellingen of frequenties. In de praktijk kijkt het model naar hoe vaak woorden of termen voorkomen.
Het is het klassieke scenario van:
De reden waarom dit goed werkt, is heel concreet. In zakelijke teksten kan de woordenschat weliswaar uitgebreid zijn, maar elk document bevat slechts een klein deel van de mogelijke woorden. De gegevens zijn verspreid. Multinomial Naive Bayes kan juist goed overweg met dit soort structuren.
In een onderzoek onder 100.000 Italiaanse tweets die op sentiment waren gelabeld, behaalde Multinomial Naive Bayes een F1-score van 0,88 en was het 10 keer sneller dan SVM, zoals vermeld in de handleiding van GeeksforGeeks over Naive Bayes-classifiers.
Om dit gemakkelijk te onthouden, kun je het zo bekijken: als je gegevens lijken op een document vol getelde woorden, is de multinomiale verdeling bijna altijd de eerste optie die je moet testen.
Als je bedrijf grote hoeveelheden tekst moet verwerken, is de vraag niet alleen: "Hoe nauwkeurig is het model?". Maar ook: "Hoeveel verzoeken kan het verwerken zonder het team te vertragen?".
Bernoulli Naive Bayes werkt met binaire kenmerken. Het telt niet mee hoe vaak een signaal voorkomt. Het telt alleen of het aanwezig is of niet.
Deze variant is handig wanneer de aanwezigheid van een kenmerk belangrijker is dan de frequentie ervan. Enkele voorbeelden uit het bedrijfsleven:
Dit is een zeer nuttige benadering wanneer je complexe verschijnselen wilt omzetten in eenvoudig te volgen ja/nee-indicatoren. Bij sentimentanalyse kan het bijvoorbeeld belangrijker zijn dat een negatief woord voorkomt, dan hoe vaak het wordt herhaald.
Bernoulli is niet ‘minder geavanceerd’ dan de multinomiale verdeling. Het is gewoon geschikter wanneer de gegevens de aanwezigheid of afwezigheid beschrijven. Het verschil is in woorden klein, maar in de resultaten groot.
| Variant | Ideaal gegevenstype | Voorbeeld van een zakelijke use case |
|---|---|---|
| Gaussiaanse Naïeve Bayes | Doorlopende gegevens | Transacties op basis van risico indelen aan de hand van bedragen, frequentie en gemiddelde waarden |
| Multinomiale Naïeve Bayes | Teksten, berekeningen, frequenties | Klantenrecensies en tickets analyseren op basis van sentiment of categorie |
| Bernoulli Naïef-Bayesiaans | Binaire gegevens, aanwezig/afwezig | Ja/nee-signalen beoordelen op het gebied van compliance, ondersteuning of productgebruik |
Om een goede keuze te maken, kun je een eenvoudige regel hanteren:
Veel teams lopen vast omdat ze op zoek zijn naar het allerbeste model. De juiste keuze is bijna altijd het model dat het beste aansluit bij het soort gegevens.
Het goede nieuws is dat je voor de praktische toepassing van Naïef Bayes geen gigantisch project nodig hebt. Zelfs een eenvoudig prototype geeft al inzicht in hoe het model redeneert en welke gegevens het nodig heeft.

Een classificatiesysteem ontstaat bijna altijd in vier stappen.
-gegevensvoorbereiding Je moet reeds gelabelde historische voorbeelden verzamelen. Als je recensies classificeert, heb je teksten nodig die al als positief of negatief zijn gemarkeerd. Als je operationele risico’s analyseert, heb je eerdere gevallen nodig waarvan de uitkomst bekend is.
-model trainen Het model analyseert de gegevens en schat de relevante waarschijnlijkheden. Bij naive bayesian classifiers verloopt dit snel, omdat de training geen bijzonder intensieve optimalisaties vereist.
Voorspelling van nieuwe gevallen
Voer nieuwe records in en het model wijst een categorie toe. Bijvoorbeeld „spam“, „geen spam“, „risicoklant“, „stabiele klant“.
-evaluatie: vergelijk de voorspellingen met de werkelijkheid op een aparte testdataset. Hier kijk je niet alleen of het model werkt. Je kijkt ook hoe het fouten maakt.
Als je meer wilt weten over het algemene beeld van voorspellende benaderingen, helpt dit overzicht van machine learning-algoritmen je om Naive Bayes binnen een bredere reeks methoden te plaatsen.
Om het proces concreet te maken, volgt hier een eenvoudig voorbeeld met scikit-learn. Je hoeft dit niet te lezen als ontwikkelaar. Het volstaat om de werkwijze te begrijpen.
# We importeren de belangrijkste toolsfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# We laden een voorbeelddatasetX, y = load_iris(return_X_y=True)# We splitsen de gegevens op in een trainings- en een testdeelX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# We maken het modelmodel = GaussianNB()# We trainen het model op de historische gegevensmodel.fit(X_train, y_train)# We doen voorspellingen op gegevens die we nog niet hebben gezieny_pred = model.predict(X_test)# We meten de nauwkeurigheidprint(accuracy_score(y_test, y_pred))Dit fragment zegt veel meer dan het op het eerste gezicht lijkt.
GaussianNB() kies de variant voor continue gegevens.fit() dat is het moment waarop het model leert.predict() past toe wat hij heeft geleerd.accuracy_score() controleer hoeveel classificaties er in totaal correct zijn.Bij tekstgegevens verloopt het proces ongeveer hetzelfde, maar voordat je het model toepast, moet je de tekst eerst in getallen omzetten. In de praktijk zet je de woorden om in kenmerken die door een classificator kunnen worden gebruikt.
Na een eerste blik op de code kan het nuttig zijn om een visuele uitleg van het mechanisme te bekijken.
Het eerste model is niet bedoeld om perfectie aan te tonen. Het dient om drie praktische vragen te beantwoorden.
Hier komt de kracht van Naive Bayes naar voren. Je kunt snel tot een solide uitgangspunt komen. Van daaruit kun je bepalen of het zin heeft om het project ingewikkelder te maken, of dat een eenvoudige oplossing al waarde oplevert.
Een classificatiemodel wordt niet alleen beoordeeld op basis van het feit dat het ‘lijkt te werken’. Het wordt beoordeeld op basis van de manier waarop het fouten maakt en op basis van de impact die die fouten hebben op het bedrijf.

De nauwkeurigheid is de meest intuïtieve maatstaf. Deze geeft aan hoeveel voorspellingen van het totaal correct zijn. Het is nuttig, maar op zichzelf kan het misleidend zijn.
Als van de honderd transacties slechts enkele echt verdacht zijn, kan een model dat bijna alles als normaal classificeert, op het gebied van nauwkeurigheid goed lijken, maar juist tekortschieten waar het er echt toe doet.
Om dat te begrijpen, moet je aan een visnet denken.
In het bedrijfsleven is dit onderscheid van groot belang.
Een goed model is niet het model dat over het algemeen weinig fouten maakt. Het is het model dat fouten maakt op de manier die het minst kostbaar is voor je proces.
Om beter te begrijpen hoe een algoritme leert van historische gegevens en waarom de kwaliteit van de training het eindresultaat beïnvloedt, kun je dit artikel lezen over wat het trainen van een algoritme precies inhoudt.
Naïeve Bayes is eenvoudig, maar laat bepaalde praktische fouten niet door de vingers.
Eerste fout: het probleem van de nulfrequentie negeren.
Als een woord of een waarde nooit voorkomt in de trainingsgegevens voor een bepaalde klasse, kan de waarschijnlijkheid tot nul dalen en de berekening in gevaar brengen. Daarom wordt vaak gebruikgemaakt van Laplace-smoothing, waarbij een kleine correctie aan de tellingen wordt toegevoegd.
Tweede fout: sterk gecorreleerde kenmerken gebruiken.
Als twee kolommen vrijwel dezelfde informatie bevatten, bestaat het risico dat het model het signaal overschat. Het ‘begrijpt’ niet dat de twee aanwijzingen vrijwel identiek zijn.
Derde fout: te veel vertrouwen op ruwe waarschijnlijkheden.
Naive Bayes levert vaak goede rangschikkingen op, maar de waarschijnlijkheden kunnen te zeker zijn. Voor het bedrijfsleven betekent dit dat de rangschikking weliswaar nuttig kan zijn, maar dat de precieze waarde van de waarschijnlijkheid met de nodige voorzichtigheid moet worden geïnterpreteerd.
Om deze risico's te beperken, is het raadzaam om:
De werkelijke waarde van naïeve Bayesiaanse classifiers komt pas echt tot uiting wanneer je ze niet langer als een wiskundige oefening beschouwt, maar ze gaat gebruiken als een instrument om prioriteiten te stellen. In een bedrijf betekent goed classificeren bijna altijd beter beslissen.

Stel je een financieel team voor dat transactiestromen, operationele beschrijvingen en historische signalen analyseert. Elke regel is niet zomaar een record. Het is een potentiële beslissing: doorlaten, nader onderzoeken, blokkeren of doorsturen naar een analist.
Met Naïve Bayes kun je verschillende indicatoren combineren in één classificatie. Sommige zijn numeriek, andere binair en weer andere tekstueel. Het model helpt te bepalen welke gevallen het meest lijken op reeds waargenomen patronen die als normaal of afwijkend worden beschouwd.
Het praktische voordeel is tweeledig:
Het vervangt het menselijk oordeel niet in gereguleerde contexten. Het structureert het. En bij operationele processen met grote volumes maakt dat echt een verschil.
In de marketing betekent segmenteren vaak dat elke klant aan een bepaalde doelgroep wordt toegewezen. Trouwe klanten. Prijsgevoelige klanten. Klanten met een hoog risico op wegtreden. Klanten die reageren op aanbiedingen. Slapende klanten.
Hier is Naive Bayes nuttig omdat het verschillende signalen snel kan combineren:
Een CRM-team heeft geen perfecte theorie over menselijk gedrag nodig. Het heeft een segmentatie nodig die goed genoeg is om zinvolle acties te ondernemen. Bijvoorbeeld het aanpassen van de boodschap, de contactfrequentie of het soort aanbieding.
Wanneer een model helpt bij het kiezen van de volgende boodschap voor de juiste klant, levert het al operationele waarde op.
In de detailhandel en de e-commerce ondersteunt classificatie activiteiten die op het eerste gezicht verschillend lijken, maar dezelfde logica hebben: orde scheppen in de chaos.
Je kunt producten indelen op basis van hun verkoopcijfers. Je kunt recensies en supporttickets doornemen om te achterhalen welke categorieën voor problemen zorgen. Je kunt vraagpatronen herkennen die het team helpen om promoties en voorraden beter te plannen.
In dit soort omgevingen zijn de gegevens vaak talrijk, divers en niet altijd perfect. Daarom is een snel, schaalbaar en begrijpelijk model van grote waarde. Niet omdat het het meest indrukwekkend is, maar omdat het naadloos in de workflow past zonder deze te vertragen.
Als je wilt zien hoe analytische benaderingen in de bedrijfswereld vorm krijgen in concrete projecten, kun je deze casestudy’s eens bekijken.
Inzicht in Naïve Bayes is nuttig. Het goed implementeren in een bedrijfsomgeving is een heel ander verhaal.
Het probleem ligt bijna nooit alleen bij het algoritme. Het echte werk zit hem in het model. Je moet verschillende gegevensbronnen aan elkaar koppelen, ontbrekende velden verwerken, teksten voorbereiden, labels bijwerken, de kwaliteit van de output controleren en de resultaten op een voor besluitvormers begrijpelijke manier presenteren.
Voor een mkb-bedrijf is deze stap vaak het knelpunt. Niet omdat er geen interesse is in AI, maar omdat het team maar beperkt de tijd heeft en de operationele prioriteiten niet kunnen wachten.
Hier is het zinvol om een platform te gebruiken dat de technische complexiteit uit handen neemt. Met een AI-aangedreven oplossing kun je ruwe data omzetten in bruikbare inzichten, zonder dat de business code hoeft te schrijven, bibliotheken hoeft te kiezen of handmatige pijplijnen hoeft te onderhouden.
Een platform als ELECTE, een door AI aangestuurd data-analyseplatform voor het MKB, maakt methoden zoals naïeve Bayesiaanse classifiers toegankelijk zonder dat daarvoor specialistische kennis op het gebied van machine learning vereist is. Het voordeel is niet alleen de snelheid. Het is de vermindering van de weerstand tussen data en besluitvorming.
Als de automatisering goed werkt, denkt het team niet meer in termen van formules. Het denkt in termen van nuttige vragen:
Dat is ook de reden waarom steeds meer bedrijven op zoek zijn naar tools die helpen bij het beoordelen van de betrouwbaarheid van door AI gegenereerde inhoud en van tekstuele signalen die in interne processen circuleren. In dit verband kan het nuttig zijn om ook een handleiding over een Italiaanse AI-detector te raadplegen, vooral als je team werkt met documenten, inhoud en taalkundige controles.
Het verschil is in de praktijk heel eenvoudig. In plaats van je bezig te houden met losse technische stappen, richt je je op het bedrijfsresultaat. En dat is precies het punt waarop AI echt bruikbaar wordt, en niet alleen maar interessant.
Naïeve Bayesiaanse classifiers leren ons een belangrijke les. In de data-analyse kan goed toegepaste eenvoud het winnen van slecht beheerde complexiteit.
Met een intuïtieve probabilistische basis, een goede schaalbaarheid en zeer concrete toepassingsvoorbeelden blijft deze aanpak een betrouwbaar hulpmiddel voor bedrijven die informatie willen classificeren, verborgen signalen willen ontcijferen en met meer zekerheid willen handelen. Je hoeft geen specialist in machine learning te zijn om de waarde ervan te begrijpen. Het gaat erom wiskunde te koppelen aan operationele besluitvorming.
Zodra dit verband duidelijk is, is AI niet langer een technisch onderwerp, maar wordt het een organisatorisch voordeel. Op dat moment begint de voorspelling echt effect te sorteren.
Als je losse gegevens wilt omzetten in duidelijke inzichten, probeer dan ELECTE. Het platform helpt kleine en middelgrote ondernemingen om gegevensbronnen te koppelen, analyses te automatiseren en rapporten en prognoses te genereren die nuttig zijn voor snellere en beter onderbouwde beslissingen.

.svg)
.svg)
.svg)






