

Je stelt een nieuw productblad op, opent het Excel-bestand van de productmanager, vervolgens de export uit het bedrijfsbeheersysteem en daarna het CRM. De gewichtsgegevens komen niet overeen. De technische beschrijving is bijgewerkt in een gedeelde map, maar de logistieke gegevens zijn nog gebaseerd op een eerdere versie. Ondertussen vragen de afdelingen Verkoop, Kwaliteit en Operations je allemaal hetzelfde: „Wat is nu de juiste waarde?”.
Voor veel bedrijven ontstaat het probleem met productgegevensbladen niet op het moment dat het document wordt opgesteld. Het ontstaat al veel eerder, wanneer nog niemand echt zeker weet welke gegevens betrouwbaar zijn. Juist daar stapelen zich fouten, vertragingen, eindeloze herzieningen en dubbele versies op.
In de Italiaanse richtlijnen wordt het technische gegevensblad beschouwd als een serieus document, niet als een brochure. Het moet het product gedurende zijn hele levenscyclus duidelijk, gestandaardiseerd en vergelijkbaar maken, met meetbare gegevens, constructiekenmerken, certificeringen, gebruiksinstructies en onderhoudsinformatie, zoals wordt benadrukt in de Italiaanse richtlijn voor technische productgegevensbladen.
Het goede nieuws is dat dit probleem op een praktische manier kan worden aangepakt. Niet door uit te gaan van het sjabloon, maar van de kwaliteit van de gegevens die in het sjabloon worden ingevoerd.
Het typische voorbeeld is eenvoudig. De technische afdeling werkt een maatvoering bij in het bedrijfsbeheersysteem. De marketingafdeling blijft een oud Excel-blad gebruiken. De verkoper kopieert de gegevens uit een PDF-presentatie. Uiteindelijk komt het productblad eruit, maar niemand zou elk afzonderlijk veld kunnen toelichten tegenover een klant, een distributeur of een interne auditor.

Dit komt doordat veel bedrijven het technische gegevensblad beschouwen als een formulier dat moet worden ingevuld, en niet als het eindresultaat van een proces van gegevensbeheer. Als de gegevens al bij de bron onjuist zijn, worden ze nog slechter verspreid. En als ze slechter worden verspreid, wordt het gegevensblad slechts de plek waar de fout zichtbaar wordt.
Hetzelfde patroon zien we ook buiten de productiesector. In alle contexten waar authenticiteit, traceerbaarheid en detail het verschil maken, ligt de waarde in de kwaliteit van de informatie en het vermogen om die correct te interpreteren. Een nuttig voorbeeld, zij het in een andere context, is deze deskundige gids over vervalste Rolex-horloges, die laat zien hoe belangrijk technische details werkelijk zijn wanneer je onderscheid moet maken tussen betrouwbare informatie en een overtuigende schijn.
Praktische regel: als je, om een formulier in te vullen, meerdere bestanden, afdelingen en versies met elkaar moet vergelijken, ligt het probleem niet bij het document. Het ligt aan de gegevensarchitectuur.
Productgegevensbladen kunnen pas snel worden ingevuld als er vooraf een duidelijke bron van waarheid is. Zolang die basis ontbreekt, is elk nieuw gegevensblad een klein project van handmatige afstemming.
Een technisch gegevensblad is pas echt bruikbaar als het een eenvoudig vraag kan beantwoorden: waar komt dit gegeven vandaan, wie heeft het gevalideerd en wanneer is het bijgewerkt?
Hier leggen veel bedrijven de prioriteiten verkeerd. Er wordt gediscussieerd over het sjabloon, de volgorde van de velden en de uiteindelijke PDF. Maar bij de eerste serieuze controle komen dan inconsistente codes aan het licht, gewichten die uit oude versies zijn overgenomen, certificaten die worden genoemd zonder verwijzing naar het juiste document en beschrijvingen die van afdeling tot afdeling verschillen. De kwaliteit van het gegevensblad hangt in de eerste plaats af van de structuur van de gegevens, en pas daarna van de manier waarop je ze presenteert.
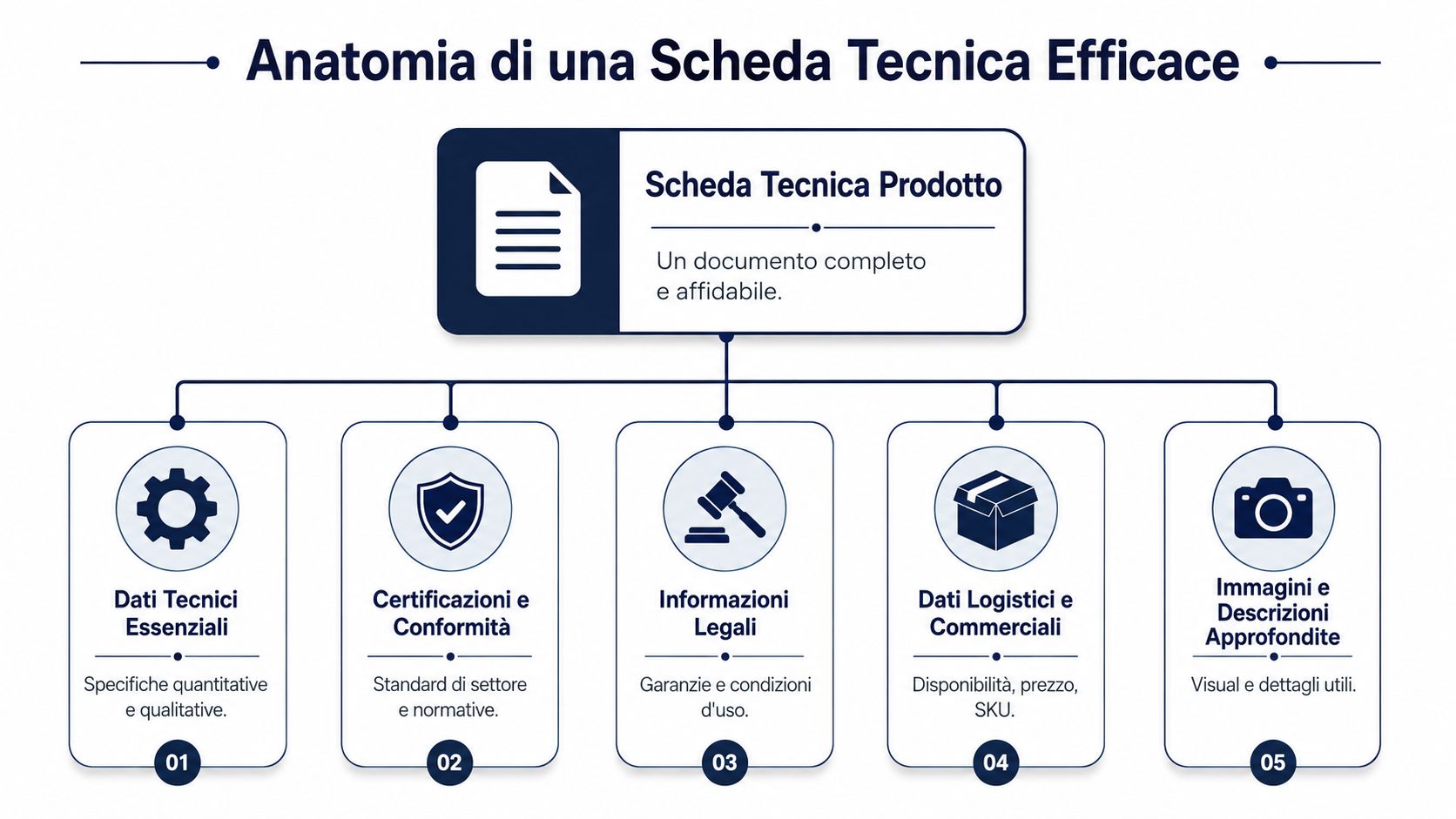
Een bruikbare structuur begint met velden die een duidelijke eigenaar en een eenduidige definitie hebben. In de praktijk zijn dit de velden die bijna altijd nodig zijn:
De meest voorkomende fout is niet dat je een veld vergeet. Het is dat je in hetzelfde veld vaste gegevens en gegevens die vaak veranderen door elkaar haalt, of dat je algemene labels gebruikt voor informatie die binnen het bedrijf verschillende betekenissen heeft. ‘Gewicht’ alleen is niet voldoende. Je moet weten of het om het netto-, bruto- of verzendgewicht gaat. Hetzelfde geldt voor ‘afmetingen’, ‘capaciteit’, ‘compatibiliteit’ en voor elke certificering die zonder context wordt vermeld.
Daarom is het raadzaam om vooraf de velddefinities en de toegestane bronnen vast te leggen, vooral als de gegevens afkomstig zijn uit ERP-, CRM- of PLM-systemen of uit gedistribueerde archieven. Een goed beheerde database, gevoed door gekoppelde en verifieerbare productbronnen, vermindert het aantal fouten al vóór de invoerfase.
Een overzichtelijk dossier kan toch nog steeds gebrekkig zijn. Dit komt vaak voor in situaties waarin het document handmatig wordt bijgewerkt en niemand de consistentie tussen de systemen controleert.
| Signaal | Waarom dit problemen veroorzaakt |
|---|---|
| Veld zonder bijwerkingsdatum | Het team weet niet of het cijfer nog steeds klopt |
| Technische gegevens in vrije vorm | Het vergelijken van producten verloopt traag en onduidelijk |
| Genoemde certificeringen die niet aan de documenten zijn gekoppeld | Kwaliteit en compliance moeten handmatige controles uitvoeren |
| Algemene beschrijvingen | Verkopers, kopers en distributeurs interpreteren de inhoud op verschillende manieren |
| Er wordt geen onderscheid gemaakt tussen statische en variabele gegevens | De kaart veroudert snel en niemand weet wat er moet worden herzien |
Sector voor sector verandert de opzet. In de mode spelen varianten, maten, materialen, afwerkingen en productie-opmerkingen een rol. In de voedingssector zijn ingrediënten, allergenen, houdbaarheid en wettelijke voorschriften van belang. In de technische detailhandel zijn compatibiliteit, afmetingen, logistieke gegevens en presentatiebeperkingen doorslaggevend. Het principe blijft hetzelfde. Als de onderliggende gegevens niet duidelijk zijn gedefinieerd en gecontroleerd, leidt het informatieblad alleen maar tot verwarring.
Een betrouwbaar technisch gegevensblad bevat informatie die verifieerbaar en traceerbaar is en die tussen de afdelingen onderling consistent is.
Wie echt bruikbare formulieren opstelt, volgt een vaste volgorde: hij definieert de velden, wijst de verantwoordelijkheid voor de gegevens toe, stelt de validatieregels vast en bepaalt pas daarna de lay-out. Op deze manier is het formulier niet langer een bestand dat op het laatste moment wordt ingevuld, maar wordt het het stabiele eindresultaat van een betrouwbaar proces.
Als een team zegt dat „het opstellen van de fiches te veel tijd kost”, heeft het bijna nooit het over de opmaak. Het gaat dan om het zoeken naar de juiste gegevens. Dat is een enorm verschil, want het verandert de soort oplossing die moet worden gekozen volledig.
In een concreet geval dat door het ELECTE-team werd beschreven, deed een klant met een catalogus van 340 artikelen er gemiddeld 45 minuten per artikel over om alleen al actuele gegevens uit verschillende bronnen te verzamelen. Met reeds gestandaardiseerde en geanalyseerde gegevens werd diezelfde stap teruggebracht tot minder dan 10 minuten. Het gaat er niet om dat het document zichzelf schrijft. Het gaat erom dat je geen tijd meer verspilt aan het controleren of ERP-, CRM- en lokale bestanden elkaar tegenspreken.
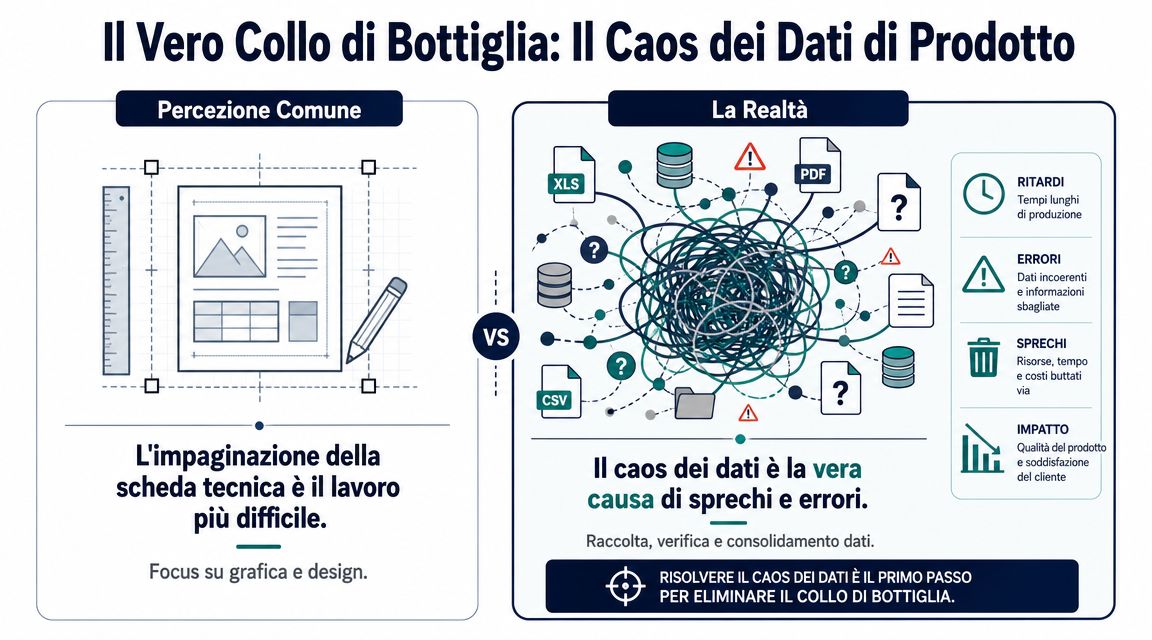
De meest voorkomende breuken zijn heel concreet:
Als je teams momenteel informatie uit meerdere bronnen verzamelen voordat ze een formulier invullen, is het niet de prioriteit om het sjabloon te herzien. De prioriteit ligt bij het verduidelijken van de herkomst van de gegevens en het samenvoegen daarvan. Een goed uitgangspunt is het creëren van één overzicht van de bronnen, zoals bij een aanpak die gericht is op geïntegreerde gegevensbronnen voor het bedrijf.
Als het vertrouwen ontbreekt, wordt het werk dubbel zo zwaar. De productmanager controleert alles nog eens. De marketingafdeling vraagt om bevestiging. De verkoopafdeling wacht af. De kwaliteitsafdeling houdt de publicatie tegen. Niemand zegt openlijk: „We vertrouwen het systeem niet”, maar het proces laat dat bij elke stap zien.
Als drie afdelingen op verschillende momenten hetzelfde veld valideren, ligt het probleem niet bij de kwaliteitscontrole. Het probleem is dat de gegevens niet goed worden beheerd.
De gevolgen blijven niet beperkt tot de productgegevensbladen. Diezelfde wanorde vertraagt ook prijslijsten, catalogi, distributeursgegevensbladen, e-commercedocumentatie en prestatieanalyses. Daarom is het gegevensblad een uitstekende indicator. Als het opstellen ervan moeizaam verloopt, is je productdatabestand vrijwel altijd al in slechte staat.
Een inkoper opent de productfiche en ziet dat het gewicht, de afmetingen en het materiaal kloppen. Vervolgens gaat hij naar het bedrijfsbeheersysteem en ziet hij een levertijd die afwijkt van wat met het verkoopnetwerk is afgesproken. Op dat moment is de fiche niet langer een operationeel hulpmiddel, maar wordt het een document dat moet worden gecontroleerd.

In de detailhandel is het productblad alleen nuttig als het helpt bij het nemen van beslissingen. Het volstaat niet om het product te beschrijven. Het moet ook de werkelijke omstandigheden weergeven waarin dat product wordt verkocht, geretourneerd, aangevuld en vergeleken met de alternatieven in de catalogus.
Daarom zijn de nuttigste velden niet altijd de meest ‘technische’ in strikte zin. Vaak maken gegevens als de volgende het verschil:
Hier zie ik vaak dezelfde fout terugkomen. Het team vult het sjabloon aan, maar blijft gegevens uit verschillende bronnen halen, met verschillende regels. Het resultaat is een overzicht dat alleen op het eerste gezicht uitgebreider lijkt. Als omloopsnelheid, voorraad en winstmarge niet op elkaar zijn afgestemd, leidt het document tot discussies in plaats van dat het deze vermindert.
Wie zich bezighoudt met assortiment, distributie en sell-through, moet productgegevens en prestatiegegevens binnen dezelfde operationele context kunnen interpreteren. Dit is precies de behoefte die duidelijk naar voren komt in de use cases voor de detailhandel en de distributie.
Ook de opbouw van de productpagina verschilt sterk per branche. In de modewereld spelen varianten, maten, materialen, productieopmerkingen en visuele verwijzingen een rol. In de voedingssector zijn ingrediënten, allergenen, voedingswaarden en wettelijke voorschriften van belang. De kern blijft echter hetzelfde: hoe gespecialiseerder de inhoud wordt, hoe duurder het wordt om deze te beheren zonder een overzichtelijke en goed beheerde database.
In de financiële sector raak je het product niet aan, maar het probleem blijft hetzelfde. Een informatieblad, een interne KIID of ondersteunend materiaal voor het verkoopnetwerk heeft alleen waarde als de gegevens daarin consistent zijn met de analyse, de compliance en de documentatie die voor de klant bestemd is.
De meest voorkomende fout is niet een verkeerd opgestelde meting. Het is een risicoversie die in het systeem is bijgewerkt, maar in het document dat door de verkoper of de klantenservice wordt gebruikt, nog steeds verouderd is.
De gevolgen zijn anders dan in de detailhandel. In de detailhandel zorgt een inconsistent gegeven ervoor dat bestellingen, herbevoorrading of onderhandelingen vertraging oplopen. In de financiële sector leidt dit tot een probleem op het gebied van governance, controle en het achterhalen van verantwoordelijkheden.
Daarom hangt de kwaliteit van het gegevensblad in gereguleerde contexten in de eerste plaats af van de regelgeving rond de gegevens en pas in de tweede plaats van de vorm van het document. Als de bron betrouwbaar is, kan het gegevensblad met minder moeite worden bijgewerkt. Als de bron onzeker is, blijft zelfs de best verzorgde PDF kwetsbaar.
De beperking van de PDF ligt niet in het formaat zelf. De beperking zit hem in het gebruik ervan als definitieve opslagplaats voor gegevens die niemand echt goed heeft gestructureerd. Wanneer een technisch gegevensblad afhankelijk is van kopiëren en plakken, bijlagen en handmatige aanpassingen, leidt elke update tot een nieuw breekpunt.
Een zeer concrete vraag die in de Italiaanse technische documentatie naar voren is gekomen, luidt als volgt: hoe kan een technische fiche worden omgezet van een statische PDF naar een automatische en actuele conformiteitscontrole? Dit is een cruciaal onderwerp, omdat bedrijven meerdere versies van documenten beheren en het gebruik ervan nog steeds overwegend statisch is, zonder dat er gebruik wordt gemaakt van gestructureerde gegevens, met gevolgen voor de kwaliteit, de veiligheid en de wettelijke aansprakelijkheid, zoals wordt benadrukt in dit artikel over de relatie tussen technische documentatie en operationele conformiteit.
Hier is er sprake van een duidelijke verandering van perspectief. ELECTE genereert niet automatisch het technische gegevensblad en vervangt ook niet de documentatietool van het marketingteam of de technische afdeling. De rol ervan is anders en, voor veel bedrijven, nuttiger: het stelt gegevens ter beschikking die al gestandaardiseerd, geanalyseerd en gecontroleerd zijn voordat iemand begint met het invullen van het document.
De gebruikelijke werkwijze is als volgt:
Wanneer de brongegevens afkomstig zijn uit ongestructureerde documenten, is een van de eerste stappen het omzetten van de inhoud naar een analyseerbaar formaat. Voor wie vaak werkt met technische bijlagen en vergrendelde tabellen in ongestructureerde documenten, is het nuttig om meer inzicht te krijgen in het proces van het omzetten van PDF’s naar Excel.
Het grootste verschil is niet van esthetische aard. Het is functioneel.
Tot nu toe werkt het team als volgt:
| Fase | Handmatige modus |
|---|---|
| Gegevensverzameling | Zoeken in meerdere systemen en bestanden |
| Consistentiecontrole | Handmatige controle tussen afdelingen |
| Update | Losgekoppelde versies |
| Formulier invullen | Kopiëren en plakken en herhaalde bevestigingen |
Zodra je een goede database hebt, verandert het werk:
De echte kwaliteitssprong vindt plaats wanneer de vraag niet langer luidt: „Wie heeft de nieuwste versie?”, maar: „Is de data al gevalideerd?”.
Voor wie veel productgegevensbladen beheert, is deze stap belangrijker dan welke automatisering van de opmaak dan ook. Als de gegevens betrouwbaar zijn, verloopt het opstellen van het document vlot. Als de gegevens twijfelachtig zijn, levert zelfs de beste sjabloon slechts een mooi opgemaakte maar kwetsbare PDF op.
Bedrijven die hun productgegevensbladen daadwerkelijk verbeteren, beginnen niet met het lettertype, de lay-out of de software waarmee ze de PDF exporteren. Ze beginnen met een veel lastigere vraag: welke productgegevens zijn betrouwbaar, wie werkt ze bij en hoe valideren we ze voordat ze in het document terechtkomen?
Als je proces momenteel voortdurende controles, afstemming tussen afdelingen en handmatige herberekeningen vereist, heb je geen nieuwe sjabloon nodig. Je hebt een duidelijkere gegevensstructuur nodig. Het technische gegevensblad werkt alleen als het een solide systeem in de achtergrond weerspiegelt.
| Actie | Belangrijkste voordeel |
|---|---|
| Geef een overzicht van alle bronnen die de fiche voeden | Ontdek waar inconsistenties en doublures ontstaan |
| Stel voor elk kritisch veld een eigenaar in | Verminder conflicten en ongecontroleerde updates |
| Maak een onderscheid tussen statische gegevens en variabele gegevens | Behandel informatie die vaak verandert niet als vaststaand |
| Standaardiseer namen, meeteenheden en versies | Zorg ervoor dat de gegevens vergelijkbaar en herbruikbaar zijn |
| Maak een validatiestroom aan vóór de sjabloon | Versnel het opstellen van documenten en verhoog de betrouwbaarheid |
Een perfect technisch gegevensblad is niet het blad met de meeste velden. Het is het blad dat je zonder aarzelen kunt verdedigen, omdat elke informatie een duidelijke bron, een gedeelde logica en een herkenbare update heeft.
Als je de tijd wilt verminderen die je kwijt bent aan het zoeken, controleren en samenvoegen van de gegevens die in je tabellen terechtkomen, helpt ELECTE – een door AI aangedreven data-analyseplatform voor het MKB – je om verschillende bronnen te centraliseren, de informatie te standaardiseren en deze om te zetten in betrouwbare inzichten die klaar zijn voor verdere verwerking. Het maakt het document niet voor je aan. Het stelt je in staat om het in te vullen met schone, consistente en actuele gegevens. Als je wilt zien hoe het werkt, kun je het platform verkennen en ontdekken hoe je meer orde kunt brengen in de beslissingen die voortvloeien uit je productgegevens.

.svg)
.svg)
.svg)






