

Dubbele gegevens in Excel zijn niet zomaar een ergernis. Ze vormen een verborgen kostenpost die, regel na regel, de betrouwbaarheid van je analyses ondermijnt en daarmee ook de degelijkheid van je zakelijke beslissingen. Of je nu een klantenbestand, een productvoorraad of een financieel rapport beheert, je weet maar al te goed dat zelfs één foutief gegeven kan leiden tot verspilling van budget en onbetrouwbare prognoses.
Het wegwerken van deze dubbele gegevens is geen optie, maar een cruciale taak voor elke kmo die op basis van concrete gegevens wil groeien. Toch is de handmatige aanpak – waarbij je je geduld moet bewaren en duizenden regels moet doorlopen – traag, frustrerend en zeer foutgevoelig.
In deze handleiding laten we je zien hoe je een rommelig werkblad kunt omzetten in een betrouwbare gegevensbron. We bespreken de meest effectieve methoden om dubbele gegevens in Excel op te sporen, van de ingebouwde tools tot geautomatiseerde oplossingen die je nauwkeurigheid garanderen en je kostbare tijd besparen. Je leert hoe je voor elke situatie de juiste tool kiest, zodat je beslissingen altijd op een solide basis rusten.
Denk eens even na over scenario’s die maar al te vaak voorkomen. Een e-mailmarketingcampagne die dezelfde klant met meerdere berichten bestookt vanwege onjuiste klantgegevens. Of een verkooprapport met opgeblazen cijfers omdat sommige bestellingen twee of drie keer zijn ingevoerd. Dit zijn geen abstracte scenario’s; het zijn de directe gevolgen van dubbele records die zich in je spreadsheets hebben genesteld.
Voor kleine en middelgrote ondernemingen die Excel als basis voor hun gegevensanalyse gebruiken, betekent het negeren van dit probleem dat ze hun strategieën op een kaartenhuis bouwen. Elk niet-opgemerkt dubbel exemplaar kan leiden tot:

Velen proberen het probleem van dubbele records in Excel met handmatige methoden aan te pakken, maar deze aanpak brengt meer nadelen dan voordelen met zich mee. Het probleem komt ongelooflijk vaak voor: uit onderzoek op de Italiaanse IT-markt blijkt dat ongeveer 72% van de kleine en middelgrote ondernemingen met databases van meer dan 100.000 records melding maakt van een aanzienlijk aantal dubbele records.
Het gebruik van technieken zoals voorwaardelijke opmaak, gevolgd door handmatige verwijdering, biedt geen garantie op succes. Integendeel. Deze methode kan leiden tot een geschat foutenpercentage van 15% tot 22% bij het opschonen van gegevens. Je kunt een beter beeld krijgen van waarom dit zo is door meer te lezen over het weergeven van dubbele waarden in Excel.
Een schone dataset is geen einddoel, maar het uitgangspunt voor elke waardevolle analyse. Het omvormen van datareiniging van een reactieve en kostbare activiteit tot een gestructureerd proces levert een doorslaggevend concurrentievoordeel op.
Voordat je je op ingewikkelde formules of scripts stort, is het essentieel om de tools die Excel je vanaf het begin biedt onder de knie te krijgen. Dit zijn ingebouwde functies die perfect zijn voor snelle bewerkingen en voor het beheren van kleine datasets. Ze vormen je eerste verdedigingslinie wanneer je duplicaten in Excel moet opsporen en snel moet handelen.
Stel je een veelvoorkomend scenario voor: je hebt zojuist een klantenbestand geïmporteerd en je wilt meteen de duidelijk identieke vermeldingen verwijderen. Of je moet een productlijst uploaden naar een webwinkel, waar dubbele artikelcodes de voorraadadministratie in de war kunnen sturen. In zulke gevallen heeft het geen zin om het jezelf onnodig moeilijk te maken. De ingebouwde functies van Excel zijn ontworpen om je direct een oplossing te bieden.
De functie 'Duplicaten verwijderen' is de meest eenvoudige manier om hele rijen met identieke waarden te verwijderen. Je vindt deze functie op het tabblad 'Gegevens' en hoewel hij ongelooflijk krachtig is, moet je er wel voorzichtig mee omgaan. De echte kracht van deze functie ligt in de mogelijkheid om zelf te bepalen wat een 'duplicaat' is, op basis van een of meer kolommen naar keuze.
Laten we een praktisch voorbeeld nemen. Stel je een lijst met contactpersonen voor met de kolommen "Voornaam", "Achternaam" en "E-mail".
In het dialoogvenster kunt u precies aangeven op welke kolommen de controle moet worden gebaseerd, zoals u hier kunt zien.
Zoals op de afbeelding te zien is, is het ontzettend eenvoudig: zodra je het gegevensbereik hebt geselecteerd, hoef je alleen maar de kolommen aan te vinken die moeten overeenkomen om een rij als een duplicaat te beschouwen.
En wat als je juist niets wilt verwijderen, althans niet meteen? Wat als je eerst handmatig alles wilt controleren voordat je een beslissing neemt? Hier komt voorwaardelijke opmaak om de hoek kijken. Deze methode verwijdert geen gegevens, maar markeert alleen de cellen die dubbele waarden bevatten.
Dit is de ideale aanpak voor verkennende data-analyse. Stel je voor dat je moet controleren of er in een boekhoudregister facturen met hetzelfde nummer staan. Met een paar muisklikken kun je alle cellen met dubbele factuurnummers markeren, zodat je elk afzonderlijk geval kunt onderzoeken zonder het risico te lopen per ongeluk belangrijke gegevens te verwijderen.
Voorwaardelijke opmaak verandert het opsporen van dubbele gegevens van een "blind" proces in een visuele en gecontroleerde analyse. Het stelt je in staat het probleem te zien voordat je het oplost.
Deze aanpak is een waardevolle hulp bij de kwaliteitscontrole van gegevens. Als je vaak met gegevens uit externe bronnen werkt, zoals een pdf-bestand, raden we je aan om je ook te verdiepen in hoe je gegevens correct van pdf naar Excel kunt converteren, zodat je fouten al bij de start kunt voorkomen.
Beide tools zijn uitstekende uitgangspunten, maar hebben hun beperkingen. "Duplicaten verwijderen" is een onomkeerbare, bijna brutale handeling. "Voorwaardelijke opmaak" kan daarentegen grote bestanden verzwaren en vertragen. Wanneer het er serieuzer op wordt en de gegevens complexer worden, is het tijd om over te stappen op geavanceerdere technieken.
Als de standaardfuncties van Excel niet meer volstaan, is het tijd om het zware geschut in te zetten. Of je nu dubbele gegevens met complexe logica moet verwerken, of het opschonen van wekelijkse rapporten wilt automatiseren: formules en Power Query zijn niet zomaar opties, maar dé oplossing.
Dit is de overgang van een handmatige, foutgevoelige aanpak naar een gestructureerd, betrouwbaar en herbruikbaar systeem. Door verder te gaan dan alleen het markeren of verwijderen, krijg je chirurgische precisie, wat van cruciaal belang is wanneer je met grote hoeveelheden gegevens of met voortdurend bijgewerkte gegevensstromen werkt.
Met deze formules kun je zelf met absolute nauwkeurigheid bepalen wat een duplicaat is. De meest beproefde en betrouwbare methode is om een extra kolom aan te maken en de functie CONTA.SE te gebruiken (of COUNTIF, als je de Engelstalige versie van Excel gebruikt). Deze techniek spoort niet alleen duplicaten op, maar geeft ook aan hoe vaak ze voorkomen.
Stel je voor dat je een lijst met bestellingen hebt en op zoek bent naar eventuele dubbele transactie-ID's. Je zou een kolom 'Aantal' kunnen toevoegen en daar een heel eenvoudige formule in kunnen invoeren: =CONTA.SE(A$2:A$100; A2).
Deze formule telt hoe vaak de waarde in cel A2 in de hele lijst voorkomt. Als je de formule naar beneden sleept, krijg je voor elke afzonderlijke rij een duidelijk resultaat:
Vervolgens hoef je alleen maar een filter op deze kolom toe te passen om alleen de waarden groter dan 1 weer te geven. Dat is alles: je hebt zojuist alle duplicaten geïsoleerd, klaar om te worden geanalyseerd of verwijderd.
Als je met de nieuwste versies van Excel werkt (vanaf Microsoft 365), maken dynamische matrixfuncties zoals UNICI (UNIQUE) en FILTRO (FILTER) het proces nog sneller. Met slechts één formule kun je een overzichtelijke lijst met unieke waarden in een nieuw deel van het werkblad genereren, zonder dat je daarvoor zelfs maar hulpkolommen nodig hebt.
Met formules verandert het zoeken naar dubbele waarden van een statische handeling in een dynamische analyse. Zo krijg je weer de volledige controle om dubbele waarden te definiëren, te tellen en te filteren volgens jouw eigen regels, en niet die van Excel.
Maar de echte doorbraak voor iedereen die regelmatig met gegevens werkt, is Power Query. Deze tool, die in Excel is geïntegreerd onder het kopje 'Gegevens ophalen en transformeren', is veel meer dan alleen een hulpmiddel om dubbele gegevens op te sporen. Het is een volwaardige automatiseringsengine die elke opschoningsstap vastlegt en deze met één muisklik herhaalbaar maakt.
Het proces is verrassend intuïtief. Eerst laad je je gegevens in de Power Query-editor. Eenmaal daar selecteer je de kolommen die samen een dubbel record vormen en gebruik je de functie "Rijen verwijderen" > "Duplicaten verwijderen".
Deze infographic geeft een goed overzicht van het besluitvormingsproces om de methode te kiezen die het beste bij jouw doel past.
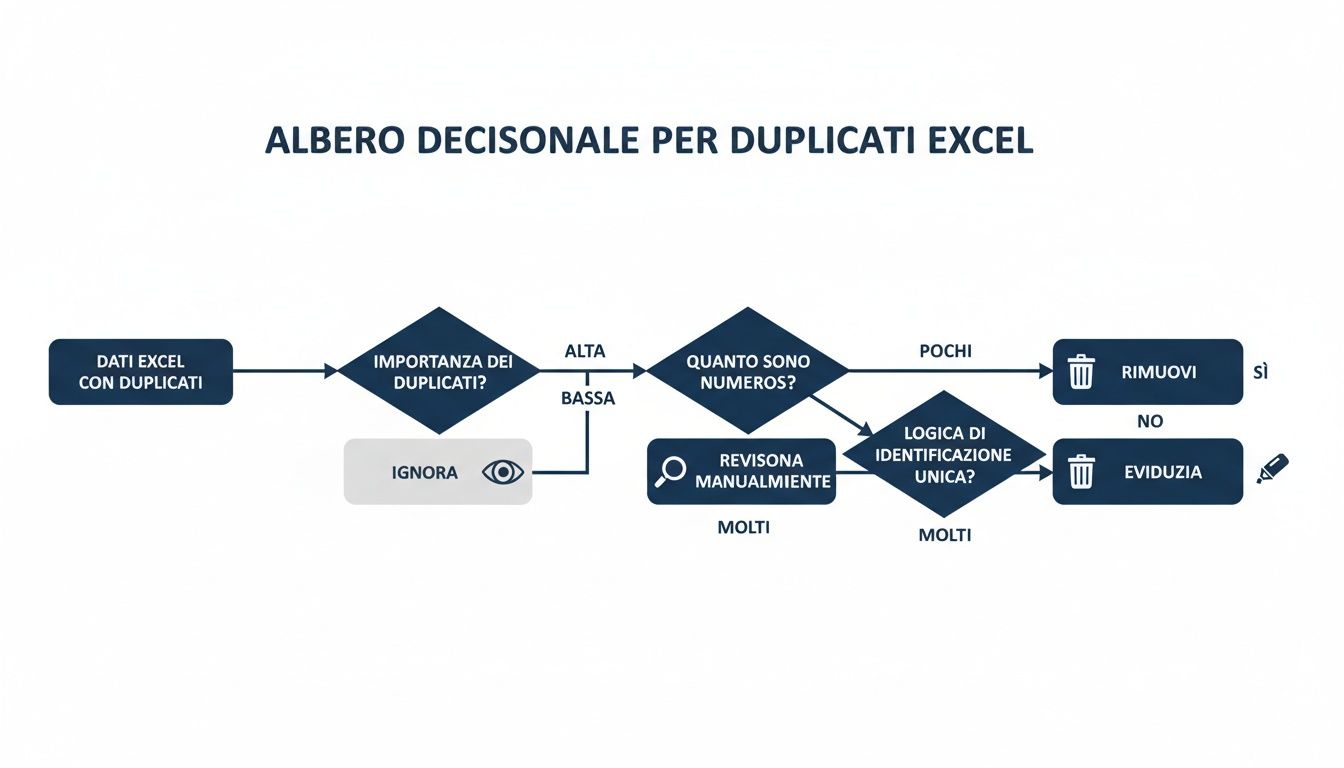
Zoals je ziet, hangt de aanpak ervan af of je de duplicaten alleen wilt identificeren of definitief wilt verwijderen. En voor terugkerende taken blijkt Power Query bijna altijd de beste keuze te zijn.
De echte kracht van Power Query komt pas na verloop van tijd tot uiting. Zodra je de query hebt ingesteld, hoef je alleen maar de gegevensbron bij te werken (bijvoorbeeld door het bestand van vorige maand te vervangen door het nieuwe) en op 'Bijwerken' te klikken. Excel voert dan automatisch alle stappen uit die je hebt gedefinieerd, inclusief het verwijderen van dubbele waarden, en levert je binnen enkele seconden een schone dataset op.
Dit is een essentiële werkwijze als je regelmatig met CSV-bestanden of andere soorten periodieke rapporten werkt. Als je meer wilt weten over hoe je deze workflows kunt optimaliseren, is onze essentiële gids voor het beheren van CSV-bestanden in Excel een uitstekend startpunt.
Als de standaardtools niet meer volstaan, is het tijd om een stap verder te gaan. Voor wie dagelijks te maken heeft met enorme hoeveelheden gegevens en op zoek is naar volledige flexibiliteit, vormen macro’s op basis van Visual Basic for Applications (VBA) de nieuwste grens op het gebied van automatisering in Excel.
Het is niet voor iedereen weggelegd, dat is duidelijk. Maar als het je doel is om complexe en repetitieve taken om te zetten in een proces dat met één klik wordt gestart, kan VBA je werkdag echt veranderen.
Het idee is om de beperkingen van 'Duplicaten verwijderen' of Power Query te omzeilen door een logica te implementeren die precies op jouw specifieke behoeften is afgestemd. Stel je voor dat je niet alleen duplicaten moet vinden, maar ze ook moet analyseren op basis van meerdere criteria, ze naar een archiefblad moet verplaatsen, een e-mailmelding moet versturen of ze moet markeren volgens regels die van keer tot keer veranderen. Dit is het soort automatisering dat VBA mogelijk maakt.
Om te beginnen moet je eerst het tabblad Ontwikkeling in de werkbalk van Excel activeren, dat standaard verborgen is. Dit hoef je maar één keer te doen: ga naar Bestand > Opties > Werkbalk aanpassen en vink het vakje "Ontwikkeling" aan. Klaar. Nu heb je toegang tot de Visual Basic-editor, waar je je code kunt schrijven of plakken.
Zie een macro als een recept dat je aan Excel geeft. In plaats van handmatig op knoppen en menu’s te klikken, schrijf je instructies die die handelingen — en nog veel meer — automatisch en direct uitvoeren.
Laten we eens een concreet voorbeeld bekijken. Stel dat we dubbele rijen willen vinden op basis van niet één, maar twee kolommen: "Voornaam" (kolom A) en "Achternaam" (kolom B). Het doel is om alle vermeldingen geel te markeren, niet alleen die welke na de eerste komen.
Hier is een VBA-script, compleet met opmerkingen, dat precies dit doet.
Sub MarkeerDuplicatenMeerdereKolommen()Dim dict As ObjectDim lastRow As LongDim i As LongDim sleutel As String' Zoek de laatste rij met gegevens in het actieve werkbladlastRow = ActiveSheet.Cells(Rows.Count, 1).End(xlUp).Row' Maak een "woordenboek"-object aan om de unieke combinaties op te slaanSet dict = CreateObject("Scripting.Dictionary")' Verwijdert eventuele eerdere achtergrondkleurenActiveSheet.Range("A2:B" & lastRow).Interior.ColorIndex = xlNone' Doorloop elke rij, beginnend bij de tweedeFor i = 2 To lastRow' Maak een unieke "sleutel" door Voornaam en Achternaam samen te voegensleutel = Trim(ActiveSheet.Cells(i, 1).Value) & "|" & Trim(ActiveSheet.Cells(i, 2).Value)If dict.exists(sleutel) Then' Als de sleutel al bestaat, is dit een dubbele rij. Ik kleur deze...ActiveSheet.Rows(i).Interior.Color = vbYellow' ...en kleur ook de eerste vermelding die ik in het woordenboek had opgeslagen.ActiveSheet.Rows(dict(sleutel)).Interior.Color = vbYellowElse' Als de sleutel nieuw is, voeg ik deze samen met het bijbehorende rijnummer toe aan het woordenboekdict.Add sleutel, iEnd IfNext i' Ik geef het geheugen vrij dat door het woordenboek wordt gebruiktSet dict = NothingEnd SubMet VBA heb je volledige controle. Je bent niet langer beperkt tot de standaardfuncties, maar kunt je eigen logica bouwen om dubbele waarden in Excel op te sporen en deze precies zo te verwerken als jouw workflow vereist.
Om deze code te gebruiken, hoef je alleen maar de VBA-editor te openen (met de sneltoets ALT + F11), via het menu Invoegen een nieuwe module toe te voegen en het script te plakken. Vervolgens kun je de macro rechtstreeks vanuit het tabblad Ontwikkeling starten.
Met een paar kleine aanpassingen zou ditzelfde script de dubbele waarden naar een ander werkblad kunnen verplaatsen in plaats van ze te markeren, of ze misschien zelfs verwijderen en alleen de eerste vermelding behouden. De flexibiliteit is ongeëvenaard, maar er is een leercurve voor nodig en het onderhoud van de code, iets wat modernere, geïntegreerde oplossingen niet hebben.
Laten we eerlijk zijn: voor veel kleine en middelgrote ondernemingen was Excel hun eerste liefde in de wereld van data. Het is veelzijdig, vertrouwd, een echt Zwitsers zakmes. Maar er komt een moment dat dat Zwitserse zakmes niet meer volstaat om een kathedraal te bouwen. Vasthouden aan het gebruik ervan wanneer de complexiteit van de data explosief toeneemt, is geen oplossing meer, maar juist de oorzaak van het probleem.
De signalen dat het tijd is voor verandering zijn frustrerend en onmiskenbaar. Bestanden die een eeuwigheid nodig hebben om te openen, om vervolgens vast te lopen of, erger nog, beschadigd te raken. De enorme inspanning die het kost om gegevens uit verschillende bronnen – het CRM-systeem, de bedrijfssoftware, de API’s – bij elkaar te brengen. En dan is er nog de chaos rondom de versies, met tientallen ‘definitieve’ en ‘definitieve’ kopieën waardoor het onmogelijk is om te achterhalen wat de officiële gegevens zijn.

ELECTE, een door AI aangestuurd platform voor data-analyse, doet meer dan alleen duplicaten in Excel opsporen. Het pakt de datakwaliteit bij de bron aan, met een diepgang die Excel niet kan evenaren. Uit een analyse is gebleken dat 64% van de kleine en middelgrote ondernemingen negatieve gevolgen heeft ondervonden van dubbele gegevens. Maar er is goed nieuws: bedrijven die deze processen hebben geautomatiseerd, zagen de betrouwbaarheid van hun gegevens stijgentot 89% en hebben de tijd die ze verspilden aan handmatige taken met 73% teruggebracht.
Als je verder gaat dan Excel, krijg je toegang tot slimmere functies:
Investeren in een speciaal platform is geen kostenpost, maar een strategische stap voorwaarts. Het betekent dat je niet langer gaten hoeft te dichten, maar kunt beginnen met het opbouwen van een solide, schaalbaar en toekomstbestendig analysesysteem.
Automatisering op basis van kunstmatige intelligentie, zoals die achter ELECTE, zorgt voor een drastische vermindering van menselijke fouten en maakt kostbare tijd vrij. Plotseling hoeft uw team niet langer te worstelen met onbeheersbare spreadsheets en kan het zich eindelijk richten op wat er echt toe doet: strategische analyse, het interpreteren van inzichten en het nemen van beslissingen die de groei stimuleren.
Wanneer het opschonen van gegevens een dagelijkse hindernis wordt, is dat het definitieve teken dat Excel zijn potentieel als instrument voor grootschalige analyse heeft uitgeput. De overstap naar business intelligence-software is niet alleen een kwestie van efficiëntie: het is een noodzaak om de analytische capaciteiten van je bedrijf op te schalen en concurrerend te blijven. Je kunt meer te weten komen over de voordelen door ons artikel over de beste business intelligence-software voor het MKB te lezen.
Het beheren van dubbele gegevens in Excel is essentieel om de betrouwbaarheid van je analyses te waarborgen. Dit zijn de belangrijkste punten om in gedachten te houden:
Je hebt gezien hoe je het probleem van dubbele gegevens in Excel kunt aanpakken, van snelle oplossingen tot geavanceerde automatiseringstechnieken. Elke methode heeft zo zijn voordelen, maar het uiteindelijke doel is altijd hetzelfde: je ruwe gegevens omzetten in een betrouwbare bron die als basis dient voor slimme zakelijke beslissingen. Laat onzuivere gegevens je groei niet in de weg staan.
Ben je klaar om afscheid te nemen van handmatig opschonen en het ware potentieel van je analyses te benutten? Met ELECTE kun je het beheer van dubbele gegevens automatiseren, al je gegevensbronnen integreren en met slechts een paar muisklikken betrouwbare inzichten verkrijgen.
Ontdek hoe ELECTE uw gegevens ELECTE transformeren, start uw gratis proefperiode →

.svg)
.svg)
.svg)






