

Najbardziej niedocenianym aspektem dyrektywy CSRD nie jest samo sporządzenie raportu. Jest nim mechanizm operacyjny niezbędny do jego przygotowania. Dyrektywa wymaga raportowania ponad 1000 punktów danych, a dla firmy produkcyjnej z 500 dostawcami może to oznaczać analizę 1500–2000 dokumentów na cykl (analiza rynku dotycząca automatyzacji raportowania ESG za pomocą sztucznej inteligencji). Dla dyrektora finansowego oznacza to jedno: problem nie jest tylko regulacyjny, ale także przemysłowy.
Dobrą wiadomością jest to, że sztuczna inteligencja staje się realnym narzędziem pozwalającym opanować tę złożoność. Metodologia oparta na sztucznej inteligencji w zakresie sprawozdawczości CSRD może skrócić czas ręcznego gromadzenia danych nawet o 70% i zwiększyć dokładność przetwarzania danych do 95% w porównaniu z 78% w przypadku procesów ręcznych, o ile dane wyjściowe są odpowiednie (praktyczny przewodnik po wykorzystaniu sztucznej inteligencji w audytach CSRD). Zła wiadomość jest taka, że wiele włoskich firm nie docenia pułapek: rozproszonych danych, słabych kontroli, modeli trudnych do wyjaśnienia i niewystarczającego zarządzania.
Jeśli rozważasz wdrożenie automatyzacji opartej na sztucznej inteligencji w zakresie sprawozdawczości CSRD, nie chodzi tu o sam zakup platformy. Chodzi o stworzenie procesu, który wytrzyma audyt, dotrzyma terminów i zapewni wysoką jakość danych. Znajdziesz tu realistyczny przewodnik, napisany z myślą o dyrektorze finansowym: jasne procesy, wyraźnie przedstawione kompromisy, konkretne korzyści oraz zagrożenia, którymi należy się zająć, zanim staną się problemem.
Dla wielu włoskich małych i średnich przedsiębiorstw problemem nie jest zrozumienie, że dyrektywa CSRD wymaga dostarczenia większej ilości danych. Problemem jest natomiast przygotowanie danych, które wytrzymają kontrolę audytową, przy terminach zamknięcia zgodnych z harmonogramem pracy działu finansowego i bez mnożenia plików, uzgodnień oraz niekontrolowanych wersji.
Trudność wzrasta, ponieważ sprawozdawczość CSRD łączy bardzo zróżnicowane źródła. Systemy ERP, dane dotyczące zakupów, kadr, rachunków, środowiska, ankiety dostawców, dokumenty PDF oraz uwagi metodologiczne muszą zostać połączone w jeden proces, który będzie weryfikowalny i powtarzalny. Jeśli etap ten pozostaje ręczny, dyrektor finansowy traci wgląd właśnie tam, gdzie ryzyko jest największe: w zakresie jakości danych, odpowiedzialności operacyjnej oraz identyfikowalności korekt.
W średnich przedsiębiorstwach często dostrzegam ten sam schemat. Dział finansowy koordynuje sprawozdawczość, ale znaczna część informacji pozostaje rozproszona między różnymi działami, zewnętrznymi konsultantami i dostawcami. Skutkiem tego jest nie tylko opóźnienie. Jest to również słaby łańcuch kontroli.
Typowe objawy to:
Większość problemów związanych z CSRD nie pojawia się w raporcie końcowym. Powstaje ona już kilka miesięcy wcześniej, na etapie gromadzenia i oczyszczania danych.
Dla włoskiego MŚP kwestia ta ma większe znaczenie niż w przypadku dużych koncernów. Struktury są bardziej uproszczone, systemy mniej zintegrowane, a nadzór metodologiczny często spoczywa na barkach zaledwie kilku osób. Jeśli jedna z tych osób zmieni stanowisko lub odejdzie z firmy, proces ten natychmiast traci na skuteczności.
Sztuczna inteligencja sprawdza się przede wszystkim w zadaniach o dużej skali i niskim stopniu standaryzacji. Potrafi klasyfikować dokumenty, odczytywać pola z różnorodnych źródeł, proponować powiązania między punktami danych a wymaganiami ESRS, sygnalizować nieprawidłowości, wykrywać brakujące wartości oraz przygotowywać projekty opisów spójnych z dostępnymi danymi.
Działa to jednak dobrze tylko wtedy, gdy opiera się na ustalonych zasadach. Bez jasnego zarysu źródeł i zakresów odpowiedzialności nawet najlepszy silnik AI sprzyja powstawaniu błędów, niejasności i niespójności. Dlatego priorytetem nie jest samo narzędzie, ale struktura przepływu informacji i źródeł danych związanych ze sprawozdawczością CSRD.
W praktyce automatyzacja ma sens, gdy ogranicza powtarzalne czynności i zwiększa kontrolę człowieka nad kluczowymi etapami.
| Obszar | Ryzyko związane z procesem ręcznym | Przydatne zastosowania sztucznej inteligencji |
|---|---|---|
| Zbiór | niekompletne dane wejściowe i ciągłe opóźnienia | pozyskiwanie i klasyfikacja dokumentów |
| Normalizacja | różne formaty i nieprawidłowe konwersje | standaryzacja pól, jednostek i struktur |
| Kontrola | spóźnione i niekompletne kontrole | powiadomienia o nieprawidłowościach, lukach i niespójnościach |
| Ścieżka audytu | niekompletne dowody | powiązanie między danymi, źródłem i etapami weryfikacji |
Potrzebny jest tu realizm. System sztucznej inteligencji, który generuje wiarygodną liczbę, ale nie wyjaśnia dokładnie, z jakiego dokumentu ją zaczerpnął, na jakiej logice opierała się jej transformacja i kto ją zweryfikował, stwarza nowy problem zamiast rozwiązać stary.
W audycie nie chodzi o to, czy wynik „wygląda na poprawny”. Chodzi o to, czy można odtworzyć proces, który do niego doprowadził. To jest sedno kwestii „czarnej skrzynki”. Jeśli zespół nie jest w stanie wykazać źródła danych, zastosowanych zasad, wystąpionych wyjątków oraz ostatecznego zatwierdzenia, wiarygodność sprawozdania ulega osłabieniu.
Dlatego zawsze zalecam traktowanie sztucznej inteligencji jako narzędzia do wstępnej obróbki danych i kontroli, a nie jako substytutu profesjonalnej oceny. Odpowiedzialność spoczywa na nas samych. Dotyczy to w szczególności zakresu Scope 3, podwójnej istotności oraz opisu związanego z szacunkami lub założeniami metodologicznymi.
Rzeczywistą korzyścią nie jest „szybsze sporządzenie raportu” w sensie ogólnym. Chodzi o ograniczenie trzech konkretnych zagrożeń:
Jeśli te trzy efekty nie są widoczne, oznacza to, że firma nie usprawnia sprawozdawczości w zakresie CSRD. Po prostu wprowadza nowe technologie do procesu, który wciąż jest niestabilny.
Z mojego doświadczenia wynika, że projekty automatyzacji CSRD we włoskich małych i średnich przedsiębiorstwach kończą się niepowodzeniem częściej z powodu nieuporządkowanych danych niż z powodu ograniczeń wybranej platformy. Nie chodzi o to, by po prostu dodać sztuczną inteligencję do istniejącego procesu. Chodzi o stworzenie przepływu pracy, który wytrzyma kontrolę, z weryfikowalnymi etapami i jasno określonymi obowiązkami.
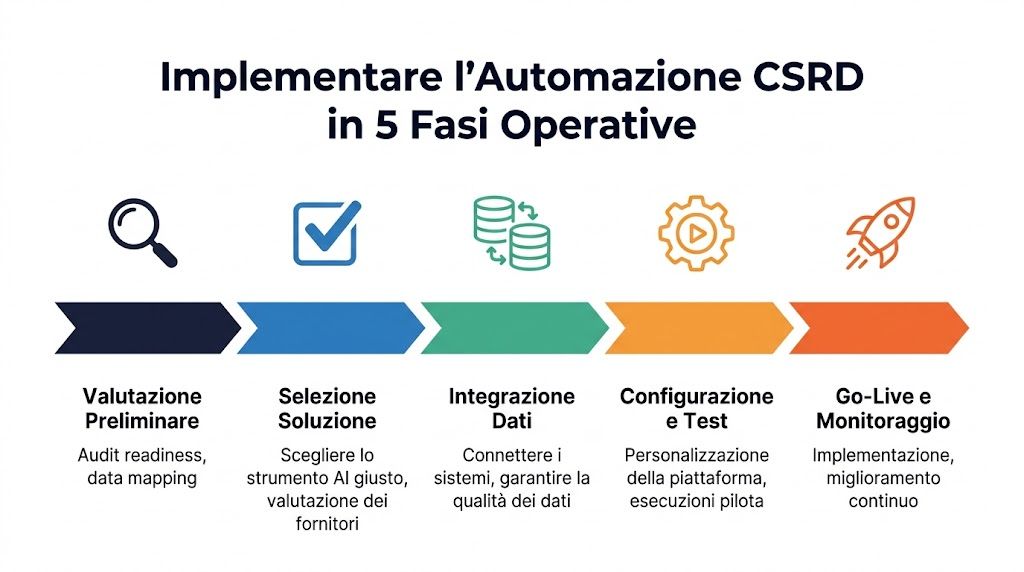
Pierwsza decyzja dotyczy zakresu danych. Należy określić, które punkty danych ESRS są istotne dla firmy, w jakich systemach się obecnie znajdują, jakich danych brakuje i kto ma je zweryfikować. Bez takiego przeglądu automatyzacja może przyspieszyć również powstawanie błędów.
W przypadku włoskich małych i średnich przedsiębiorstw trudności nie mają wyłącznie charakteru technicznego. Dane dotyczące środowiska, kadr i łańcucha dostaw są często rozproszone między systemami ERP, arkuszami Excel, portalami dostawców i plikami PDF. Sztuczna inteligencja może pomóc w klasyfikacji źródeł i zaproponować wstępne powiązanie między wymogami prawnymi a dostępnymi danymi, jednak odpowiedzialność za potwierdzenie tego powiązania spoczywa na samej firmie.
Wynikiem tej fazy jest macierz operacyjna zawierająca sześć pól:
Jeśli ta matryca jest niekompletna, ryzyko nie jest tylko teoretyczne. Podczas audytu trudno jest wyjaśnić, dlaczego dany wskaźnik znalazł się w raporcie właśnie w takim zakresie i z takiego źródła.
Wybór platformy powinien opierać się na zasadach kontroli wewnętrznej, a nie wyłącznie na wydajności. Dobrze przygotowana wersja demonstracyjna to za mało. Trzeba sprawdzić, czy system rejestruje przebieg przetwarzania, przechowuje wersje, zarządza uprawnieniami oraz czy umożliwia prześledzenie ścieżki od surowych danych do końcowego wyniku.
Dyrektor finansowy powinien zadać dostawcy cztery konkretne pytania:
Warto również od razu sprawdzić kwestię integracji aplikacji. Platforma źle zintegrowana z systemami firmowymi powoduje konieczność ręcznego uzgadniania danych, częste wyjątki i wydłużenie czasu zamknięcia. Dlatego warto z wyprzedzeniem sprawdzić jakość integracji z głównymi źródłami danych w firmie.
Już w tym miejscu pojawia się kwestia „czarnej skrzynki”. Jeśli dostawca nie potrafi pokazać, w jaki sposób model klasyfikuje dokument, sygnalizuje nieprawidłowość lub proponuje szkic opisu, problem ujawni się później, zazwyczaj w najgorszym możliwym momencie.
To właśnie na tym etapie wiele projektów traci na wiarygodności. Sztuczna inteligencja przetwarza ogromne ilości danych w krótkim czasie, ale nie jest w stanie samodzielnie skorygować niespójnych kodów, różnych jednostek miary, niezgodnych zakresów ani plików przesyłanych według zasad różniących się w poszczególnych działach.
Należy zająć się trzema zadaniami:
W tym miejscu pojawia się prawdziwy kompromis. Im bardziej zautomatyzujesz wprowadzanie danych, tym więcej musisz zainwestować w reguły jakości na wcześniejszym etapie. Jeśli tego nie zrobisz, zespół finansowy będzie musiał weryfikować wyjątki generowane przez system zamiast ograniczać nakład pracy ręcznej.
Praktyczna zasada pomaga uniknąć błędów w konfiguracji. Każdy automatyczny przepływ danych musi zawierać mechanizm weryfikacji, który jest zrozumiały dla osoby nieposiadającej wiedzy technicznej. Jeśli mechanizm ten jest jasny tylko dla osoby, która skonfigurowała platformę, proces pozostaje podatny na awarie.
Po oczyszczeniu strumieni danych sztuczna inteligencja może generować wymierną wartość. Może sygnalizować nieprawidłowości, przygotowywać szkice tekstów oraz wspierać wypełnianie powtarzających się sekcji. Nie należy jednak powierzać modelowi najbardziej wrażliwych elementów, takich jak założenia metodologiczne, zakres konsolidacji czy wyjaśnienia dotyczące szacunków i luk informacyjnych.
Najbardziej sprawdzone metody to:
W małych i średnich przedsiębiorstwach ukrytym zagrożeniem jest zbytnia wiara w dobrze sformułowany tekst. Zgrabny tekst może kryć w sobie słabe podstawy merytoryczne. Dlatego zawsze proszę o sprawdzenie dwóch rzeczy przed zatwierdzeniem: skąd pochodzi każde stwierdzenie i na podstawie jakiej reguły system je sformułował.
Uruchomienie systemu nie oznacza zakończenia projektu. Rozpoczyna się etap, w którym automatyzacja musi wykazać swoją niezawodność miesiąc po miesiącu, w obliczu nowych danych, rzeczywistych wyjątków oraz zmian w modelach lub szablonach.
W ramach minimalnego systemu zarządzania należy wyjaśnić następujące kwestie:
| Zakres | Wniosek do zamknięcia |
|---|---|
| Własność | kto zatwierdza dane przed ich opublikowaniem |
| Wyjątki | kto decyduje, kiedy pewna nieprawidłowość jest dopuszczalna |
| Wersje | która wersja danych trafia do raportu |
| Ścieżka audytu | gdzie przechowywane są dowody |
| Model AI | kiedy następuje aktualizacja i kto zatwierdza zmiany |
W mniejszych firmach ryzyko operacyjne często spoczywa na barkach zaledwie kilku osób. Jeśli tylko jedna osoba zna zasady, wyjątki i logikę wprowadzania danych, automatyzacja pozostaje uzależniona od jej pamięci. Nie jest to zmiana o charakterze strukturalnym.
Dobrze wdrożone rozwiązanie przynosi trzy wymierne korzyści: mniej ręcznych poprawek, mniej sporów podczas audytów oraz większą przewidywalność terminów zamknięcia. Jeśli brakuje choćby jednego z tych trzech elementów, warto zrewidować projekt procesu przed rozszerzeniem zakresu stosowania sztucznej inteligencji.
Zanim zainwestujesz w automatyzację, warto przeprowadzić wewnętrzną ocenę gotowości. Nie potrzebujesz struktury na skalę korporacyjną. Potrzebujesz jasności co do tego, co już masz, czego brakuje i czego nie należy powierzać platformie.

Właściwe pytanie nie brzmi: „Czy mamy dużo danych?”. Brzmi ono: „Czy mamy dane, które są łatwe do odnalezienia, spójne i dobrze zarządzane?”. Jeśli odpowiedź nie jest jednoznaczna, należy lepiej przygotować się do automatyzacji.
Sprawdź następujące kwestie:
Dobry stan wyjściowy nie oznacza doskonałości. Oznacza to, że każda istotna informacja ma co najmniej jednego właściciela, rozpoznawalne źródło oraz kryteria weryfikacji.
Wiele projektów utknęło w martwym punkcie z przyczyn, które nie mają charakteru technicznego. Platforma istnieje, ale nikt nie określa jej granic, nie zatwierdza zatrudnienia ani nie rozwiązuje konfliktów między działami.
Przygotowania organizacyjne wymagają co najmniej czterech jasnych decyzji:
Projekt CSRD sprawdza się wtedy, gdy firma określa, kto ponosi odpowiedzialność za dane. Nie wtedy, gdy wdraża nową warstwę technologiczną.
W przypadku małych i średnich przedsiębiorstw najskuteczniejszym modelem jest często model hybrydowy. Zaawansowana automatyzacja w zakresie gromadzenia danych, klasyfikacji i kontroli spójności. Nadzór ludzki nad wyborami dotyczącymi zakresu, istotności, opisu oraz ostatecznego zatwierdzenia.
Automatyzacja ma sens, gdy zmienia codzienną pracę. Handel detaliczny i finanse to dwie dziedziny, w których widać to od razu, choć z różnych powodów.

W włoskim sektorze detalicznym wąskim gardłem jest często łańcuch dostaw. Ocena podwójnej istotności napotyka trudności, gdy dane dotyczące wpływu są dostarczane w formatach trudnych do odczytania lub nieporównywalnych. Raport cytowany przez Deloitte wskazuje, że 52% włoskich MŚP z branży detalicznej nie posiada szczegółowych danych dotyczących wpływu, i właśnie w tym obszarze sztuczna inteligencja może przyspieszyć proces benchmarkingu, jednak z uwzględnieniem błędów wynikających ze słabej jakości danych dotyczących łańcucha dostaw (analiza podwójnej istotności i sztuczna inteligencja).
W praktyce dobrze zaprojektowany proces w handlu detalicznym przebiega zgodnie z następującą logiką:
Wartościowy wynik to nie tylko końcowa liczba. To także lista wyjątków, jakość źródeł i ślad założeń. To właśnie naprawdę pomaga podczas weryfikacji.
Jeśli chodzi o stronę narracyjną, wiele firm zbyt późno zdaje sobie sprawę, że sama umiejętność analizy to za mało. Trzeba również przedstawić wyniki w zrozumiały sposób. W tej kwestii przydatny jest przewodnik Data Storytelling Academy dotyczący pisania skutecznych raportów, ponieważ pomaga on przekształcić zbiór danych technicznych w komunikat zrozumiały dla kierownictwa, audytorów i interesariuszy.
W sektorze finansowym proces wygląda inaczej. Problem nie polega na samym śledzeniu danych fizycznych czy dotyczących dostaw, ale na spójnym powiązaniu ryzyka, ekspozycji, wewnętrznych zasad i ujawnień. W tym przypadku sztuczna inteligencja jest szczególnie przydatna w klasyfikowaniu istotnych kwestii, analizowaniu danych jakościowych oraz przygotowywaniu projektów dokumentów, które zespół ds. zgodności może następnie dopracować.
Typowy przebieg pracy obejmuje:
| Faza | Konkretne wyniki |
|---|---|
| zebranie opinii wewnętrznych | wykaz istotnych ryzyk ESG |
| analiza dokumentów | podsumowanie polityk, kontroli i luk |
| klasyfikacja | mapa tematów do ujawnienia |
| kontrola przez człowieka | zatwierdzenie zakresu i języka |
| sprawozdawczość | sekcje narracyjne i pulpity kontrolne |
W branży finansowej korzyścią nie jest „szybsze pisanie”. Chodzi o zmniejszenie rozbieżności między działami, które generują te same dane, stosując różne definicje.
Dla małego lub średniego przedsiębiorstwa problemem nie jest znalezienie kolejnej platformy, którą można by dodać do stosu technologicznego. Problemem jest połączenie danych, procesów kontrolnych i wyników w jeden przepływ, z którego zespół będzie mógł faktycznie korzystać.
ELECTE, platforma do analizy danych oparta na sztucznej inteligencji przeznaczona dla małych i średnich przedsiębiorstw, sprawdza się w tej sytuacji, ponieważ obejmuje cały łańcuch procesów. Łączy różnorodne źródła danych, przetwarza je wstępnie, ułatwia wykrywanie anomalii oraz przekształca złożone zbiory danych w wnioski zrozumiałe nawet dla użytkowników bez wiedzy technicznej.
W kontekście CSRD podejście to przynosi korzyści przede wszystkim w trzech aspektach:
W końcowej fazie ujawniania informacji szczególnie istotna jest możliwość tworzenia przejrzystych i nadających się do ponownego wykorzystania wyników. Logika narzędzia do tworzenia raportów, zaprojektowanego z myślą o generowaniu automatycznych i dostosowywalnych raportów, jest właśnie tym, czego brakuje w wielu procesach CSRD, które nadal opierają się na niepowiązanych dokumentach, równoległych wersjach i opóźnionych konsolidacjach.
Odpowiednia platforma nie zastępuje osądu kierownictwa. Eliminuje ona powtarzalne zadania, które uniemożliwiają kierownictwu właściwe wykonywanie tej funkcji.
Właśnie w tym momencie podejście oparte na analityce robi różnicę. Nie traktuje ono raportowania jako gotowego dokumentu do sformatowania, ale jako naturalny wynik procesu przetwarzania danych, który jest bardziej uporządkowany, przejrzysty i łatwiejszy do kontrolowania.
Wdrożenie sztucznej inteligencji w sprawozdawczości dotyczącej zrównoważonego rozwoju nie kończy się niepowodzeniem z powodu niedojrzałości technologii. Niepowodzenie następuje wtedy, gdy firma powierza jej zadania wymagające osądu, uwzględnienia kontekstu lub wyjaśnień, których model nie jest w stanie samodzielnie zapewnić.
We Włoszech brak przejrzystości sztucznej inteligencji stanowi przeszkodę dla 62% małych i średnich przedsiębiorstw, które muszą dostosować się do dyrektywy CSRD, a w podobnych sytuacjach 28% odrzuconych wyników audytów wynika z modeli, których nie da się wyjaśnić (badanie dotyczące sztucznej inteligencji i sprawozdawczości w zakresie zrównoważonego rozwoju dla małych i średnich przedsiębiorstw). Dane te należy dokładnie przeanalizować. Ryzyko nie polega na tym, że „sztuczna inteligencja popełnia błędy”. Ryzyko polega na tym, że „firma nie potrafi wyjaśnić, w jaki sposób doszła do danego wyniku”.
Praktyczne środki zaradcze są bardzo konkretne:
Dla wielu dyrektorów finansowych kwestia ta wiąże się również z szerszym kontekstem regulacyjnym. Warto mieć na uwadze ramy zgodności z przepisami oraz wymogi europejskiej ustawy o sztucznej inteligencji, ponieważ kierunek zmian regulacyjnych w Europie wyraźnie zmierza w stronę większej przejrzystości, ściślejszej kontroli i mniejszego ślepego zaufania do modeli, których wyników nie da się zinterpretować.
Kolejna pułapka jest bardziej banalna, ale często bardziej szkodliwa. Jeśli dane są nieprawidłowe, automatyzacja tylko przyspiesza już istniejący błąd. Dzieje się tak zwłaszcza w przypadku mało ustandaryzowanych dokumentów dostawców, niezgodnych zakresów oraz rozbieżnych definicji między działami.
Najskuteczniejsze środki obrony to te praktyczne, a nie teoretyczne:
| Ryzyko | Praktyczne działania łagodzące |
|---|---|
| niekompletne dane | zasady dotyczące pól obowiązkowych i ograniczenia dotyczące wyjątków |
| jednostki niespójne | centralna normalizacja |
| wiele wersji | jedyne wiarygodne źródło informacji dla każdego ujawnienia |
| niepotwierdzone relacje | obowiązek przedstawienia dokumentacji potwierdzającej |
Najskuteczniejszym modelem pozostaje model z udziałem człowieka. Sztuczna inteligencja gromadzi dane, klasyfikuje je, sygnalizuje i przygotowuje. Zespół weryfikuje, interpretuje i zatwierdza.
Tak, ale w ściśle określonych granicach. Sztuczna inteligencja sprawdza się przy odczytywaniu plików PDF, kwestionariuszy otwartych, załączników i dokumentacji o niejednolitym formacie. Działa dobrze, gdy musi wyodrębniać pola, rozpoznawać powtarzające się kategorie i sygnalizować brakujące informacje. Nie wystarczy jednak, by samodzielnie zagwarantować poprawność danych w zakresie CSRD. Zawsze należy przewidzieć reguły walidacji oraz ręczną weryfikację wyjątków.
Rola ta pozostaje kluczowa. Sztuczna inteligencja nie podejmuje w imieniu firmy decyzji dotyczących istotności, zakresu, metodologii ani ostatecznych założeń. Zespół ds. finansów i zgodności z przepisami określa zasady, zatwierdza wyjątki, kontroluje spójność ujawnień oraz weryfikuje, czy raport odzwierciedla rzeczywisty model operacyjny. Z kolei audytor potrzebuje śladów, dowodów i możliwych do odtworzenia etapów.
Kiedy sztuczna inteligencja wkracza do świata sprawozdawczości, kontrola ze strony człowieka nie znika. Staje się ona ważniejsza i bardziej ukierunkowana.
Więcej, niż wiele małych i średnich przedsiębiorstw sobie wyobraża. Nie potrzeba tu całkowitej sztywności, ale konieczne są pewne minimalne standardy. Spójne nazwy plików, pola obowiązkowe, odpowiedzialność za dane, zasady zatwierdzania oraz uporządkowane archiwum dokumentów. Bez tej dyscypliny automatyzacja pozostaje niepełna.
Tak. Gdy proces jest dobrze zorganizowany, dane zebrane na potrzeby CSRD stają się przydatne również w obszarach zaopatrzenia, zarządzania ryzykiem, kontroli zarządczej oraz w kontaktach z inwestorami lub klientami. Prawdziwą korzyścią nie jest tylko „sporządzenie raportu”. Chodzi o to, by dysponować lepszą bazą danych, która pozwala podejmować lepsze decyzje.
Nie. Zazwyczaj najlepiej zacząć od najbardziej krytycznych i powtarzalnych procesów. Na przykład od gromadzenia danych od dostawców, uzgadniania danych między działami lub przygotowywania szkiców opisów do ujawnień wymagających częstych aktualizacji. Błędem jest próba zautomatyzowania wszystkiego naraz, bez uprzedniego ustalenia zasad zarządzania.
Zamiast skupiać się na prezentacji, zwróć większą uwagę na sam proces. Zapytaj, czy platforma rejestruje przebieg przetwarzania, czy obsługuje wyjątki, czy łączy dane wyjściowe ze źródłowymi, czy mogą z niej korzystać również osoby bez wiedzy technicznej oraz czy integruje się z systemami, które już posiadasz. Wiarygodne rozwiązanie do raportowania CSRD powinno pomóc Ci pracować lepiej, a nie tylko szybciej generować dokumenty.
Jeśli chcesz przekształcić proces zapewnienia zgodności z CSRD w bardziej uporządkowany, identyfikowalny i przydatny dla firmy proces, dowiedz się, jak to zrobić ELECTE może pomóc Ci połączyć źródła danych, zautomatyzować raportowanie i uzyskać jasne wnioski bez złożoności typowej dla dużych przedsiębiorstw.

.svg)
.svg)
.svg)






