

Z pewnością znasz tę sytuację: masz system do zarządzania, może CRM, kilka plików Excel krążących w mailach, a w międzyczasie ktoś mówi ci, że aby „prowadzić poważną analitykę”, musisz wybrać między jeziorem danych a hurtownią danych. W tym momencie rozmowa natychmiast schodzi na grunt technologii, ale prawdziwy problem leży gdzie indziej. Czy naprawdę potrzebujesz nowej architektury danych, czy po prostu chcesz, by dane, które już posiadasz, stały się czytelne i użyteczne?
Dla małego lub średniego przedsiębiorstwa to rozróżnienie ma większe znaczenie niż sama terminologia. Niewłaściwy wybór nie tylko powoduje komplikacje techniczne. Prowadzi on do przedłużających się projektów, uzależnienia od konsultantów, opóźnień w dostarczaniu raportów oraz inwestycji, które z trudem przekładają się na lepsze decyzje. Decyzja o niepodejmowaniu żadnych działań sprawia jednak, że firma działa na ślepo.
Nie chodzi o to, by nauczyć się żargonu dostawców. Chodzi o to, by zrozumieć, które rozwiązanie jest odpowiednie dla Twojej firmy, Twojego budżetu i kompetencji, którymi faktycznie dysponujesz. Znajdziesz tu praktyczny przewodnik, który pomoże Ci spojrzeć na debatę dotyczącą jezior danych (data lake) i hurtowni danych (data warehouse) z perspektywy osoby, która musi pogodzić koszty, dostępność i zwrot z inwestycji.
Obecnie naprawdę odczuwa się presję, by „coś zrobić z danymi”. Liczby rosną, źródła się mnożą, a menedżerowie domagają się szybszych prognoz, pulpitów nawigacyjnych i powiadomień. Tymczasem pojawiają się terminy, które wydają się zmuszać do podjęcia natychmiastowej decyzji dotyczącej architektury.
Dla wielu małych i średnich przedsiębiorstw pułapka polega jednak właśnie na tym. Przekonują je, że pierwszym krokiem jest wybór między dwoma modelami infrastruktury, podczas gdy często prawdziwy problem jest znacznie bardziej konkretny: rozproszone dane, niespójne formaty, ręczne raporty i brak osób, które miałyby czas na uporządkowanie tego wszystkiego.
Warto zadać sobie inne pytania. Czy naprawdę masz problem z architekturą? A może chodzi o dostęp do danych? Jeśli wybierzesz niewłaściwe rozwiązanie, ryzykujesz sfinansowanie projektu technicznego zamiast poprawy kontroli nad działalnością biznesową. Jeśli nie podejmiesz żadnej decyzji, nadal będziesz podejmować decyzje w oparciu o niepełne informacje.
Kto prowadzi małą lub średnią firmę, nie potrzebuje wykładu akademickiego. Potrzebuje prostych wskazówek, aby zrozumieć, co jest potrzebne, a co nie, oraz gdzie kryją się rzeczywiste koszty.
Najlepiej zrozumieć tę różnicę na podstawie dwóch bardzo praktycznych przykładów.
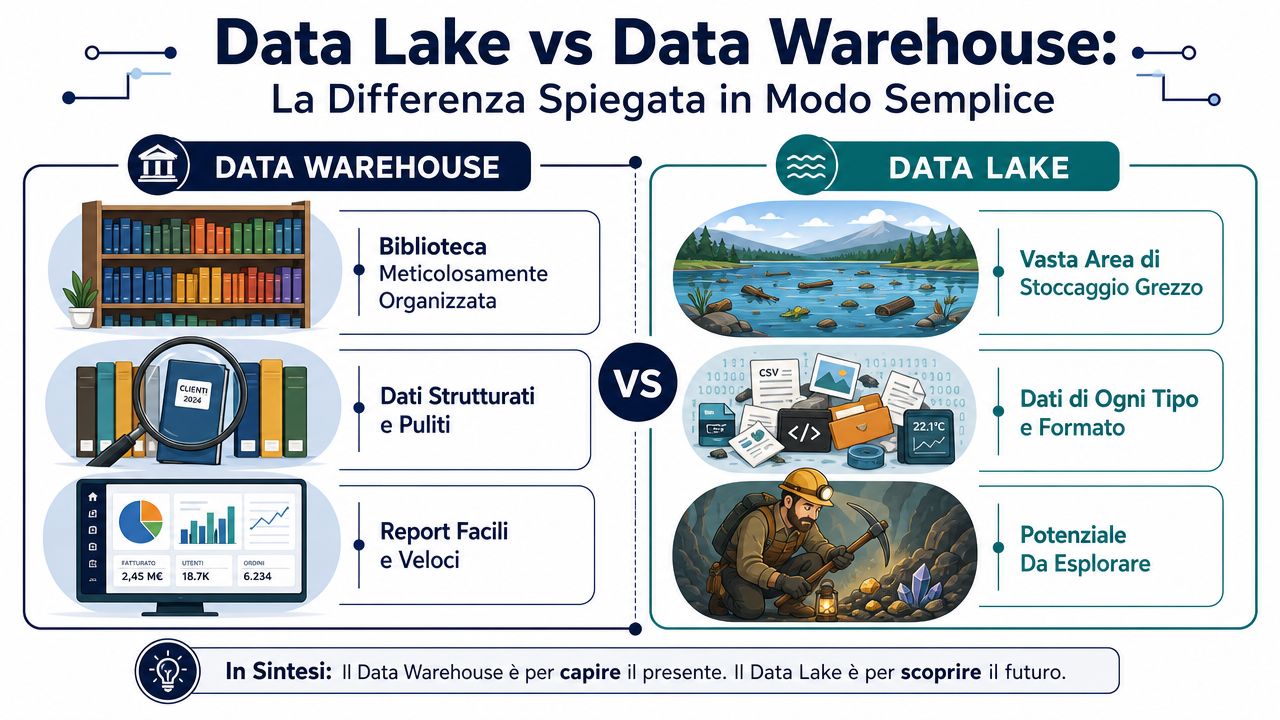
Magazyn danych przypomina dobrze zorganizowaną bibliotekę. Każda książka trafia tam już skatalogowana, sklasyfikowana i umieszczona na odpowiedniej półce. Kiedy szukasz informacji, szybko ją znajdujesz, ponieważ porządek został ustalony wcześniej. Jezioro danych przypomina natomiast wielki magazyn, do którego trafiają różnego rodzaju pudła. Umieszczasz w nim uporządkowane pliki, logi, pliki PDF, obrazy, eksporty z systemu zarządzania, dane z internetu. Porządek wprowadzasz później, kiedy musisz je przeanalizować.
W tym miejscu pojawia się jedyna kwestia techniczna, o której naprawdę warto wspomnieć.
To rozróżnienie odzwierciedla również ich historyczne pochodzenie. Magazyn danych powstał z myślą o analizie biznesowej opartej na już oczyszczonych i ustrukturyzowanych danych, natomiast jezioro danych pojawiło się później, aby przechowywać surowe dane w różnorodnych formatach. Dlatego magazyn danych lepiej nadaje się do raportowania i wskaźników KPI, podczas gdy jezioro danych jest bardziej elastyczne pod względem eksploracji danych i uczenia maszynowego, jak wyjaśnia ta analiza różnic między magazynem danych a jeziorem danych.
Magazyn danych dobrze sprawdza się w przypadku znanych zapytań. Jezioro danych przydaje się, gdy wiadomo, że dane mogą zawierać wartościowe informacje, ale nie wiadomo jeszcze, w jakiej formie.
Jeśli chcesz śledzić sprzedaż, marże, zamówienia, stany magazynowe, opóźnienia, wyniki handlowe i porównania miesięczne, system magazynowy najlepiej odpowiada Twoim potrzebom. Zapewnia on solidną podstawę do tworzenia standardowych raportów, spójnych zapytań SQL i powtarzalnych wyników.
Jeśli natomiast pracujesz z bardzo zróżnicowanymi danymi, takimi jak logi aplikacji, pliki PDF, wiadomości e-mail, teksty, obrazy czy strumienie danych maszynowych, jezioro danych zapewnia większą swobodę. Zespoły IT mogą scentralizować różnorodne źródła danych, podczas gdy specjaliści ds. raportowania nadal preferują środowiska ustrukturyzowane, umożliwiające szybkie i spójne wyszukiwanie. W tym kontekście pojawia się również szerszy temat decyzji biznesowych opartych na danych, które wymagają przede wszystkim dostępności danych, a dopiero potem zaawansowanych technologii.
W dyskusji na temat „data lake kontra data warehouse” wiele osób myli elastyczność z natychmiastową użytecznością.
Data lake może pomieścić niemal wszystko. Jednak samo przechowywanie danych nie oznacza, że można je od razu analizować. Magazyn danych jest mniej elastyczny pod względem wprowadzania danych, ale bardziej przydatny, gdy potrzebne są szybkie i standardowe odpowiedzi. Dla małych i średnich przedsiębiorstw ta różnica ma większe znaczenie niż sama teoria. Problemem nie jest bowiem gromadzenie większej ilości danych, lecz podejmowanie lepszych decyzji.
Dwie firmy mogą dysponować tymi samymi danymi wyjściowymi, a mimo to osiągać zupełnie różne wyniki. Różnica często nie polega na ilości zebranych danych, ale na tym, jak je organizują, przygotowują i udostępniają osobom podejmującym decyzje.
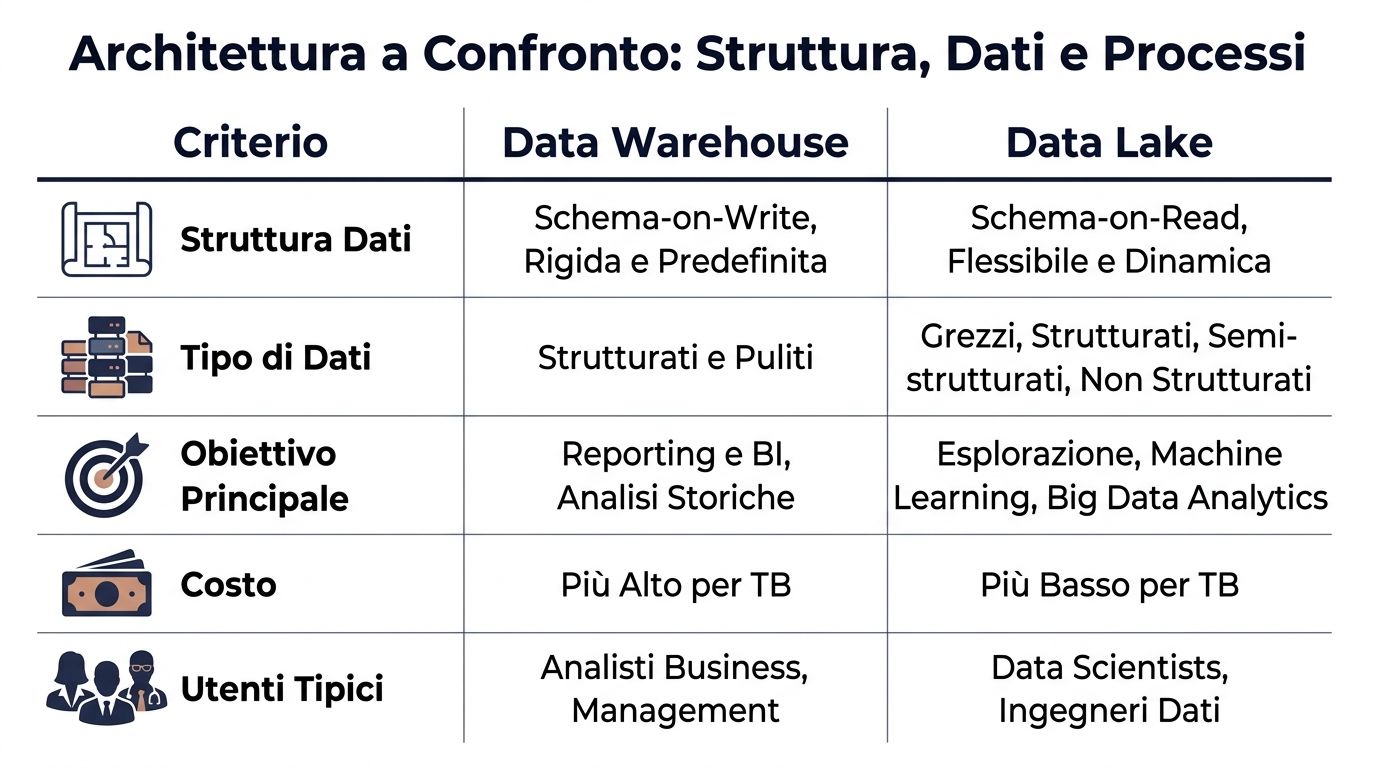
| Kryterium | Magazyn danych | Zbiornik danych |
|---|---|---|
| Struktura danych | Schemat przy zapisie, zdefiniowany przed załadowaniem | Schemat odczytu, definiowany w momencie analizy |
| Typ danych | Przede wszystkim uporządkowane i schludne | Strukturalne, częściowo strukturalne i nieustrukturyzowane |
| Typowy proces | ETL: najpierw przetwarzaj, potem ładuj | ELT: najpierw obciążenia, potem transformatory |
| Typowi użytkownicy | Analityk biznesowy, finanse, zarządzanie | Inżynier danych, analityk danych, zespoły techniczne |
| Oczekiwane wyniki | Większa przewidywalność w zakresie analizy biznesowej i raportowania | Są bardziej zmienne, zależą od zapytania i przygotowania |
W hurtowni danych klasyczny proces przebiega według schematu ETL: dane są pobierane, przetwarzane, a następnie ładowane. Wymaga to wprawdzie więcej pracy na początku, ale później ogranicza potencjalne problemy. Osoba przeglądająca pulpit nawigacyjny ma do dyspozycji spójne pola, stałe definicje oraz wskaźniki KPI, których znaczenie nie zmienia się w zależności od działu.
W jeziorze danych proces często przebiega według modelu ELT: dane są najpierw pobierane, a dopiero potem, w razie potrzeby, ładowane i przetwarzane. Takie podejście zapewnia większą swobodę techniczną, ale powoduje odłożenie części pracy na później. W przypadku małych i średnich przedsiębiorstw odkładanie zadań na później często oznacza gromadzenie się pracy, która następnie spada na zespół w najgorszym możliwym momencie, czyli wtedy, gdy potrzebna jest szybka reakcja.
Zasada praktyczna: jeśli kilka osób ma zapoznać się z tym samym dokumentem i podjąć decyzje operacyjne, ustalona przed jego udostępnieniem struktura pozwala ograniczyć liczbę błędów, niepotrzebnych dyskusji i straconego czasu.
Z operacyjnego punktu widzenia hurtownia danych jest zaprojektowana z myślą o powtarzających się zapytaniach, częstych raportach i codziennym korzystaniu z pulpitów nawigacyjnych. Jezioro danych dobrze radzi sobie z dużymi ilościami danych i różnymi formatami, ale czas odpowiedzi i łatwość obsługi w dużym stopniu zależą od tego, w jaki sposób dane zostały skatalogowane, przygotowane i zarządzane. Porównanie techniczne opublikowane przez CloudOptimo dobrze podsumowuje tę kwestię: hurtownia danych stawia na przewidywalność, a jezioro danych na elastyczność.
Dla małego lub średniego przedsiębiorstwa nie jest to kwestia czysto teoretyczna. Gdy kierownik ds. sprzedaży otwiera poranny raport, oczekuje spójnych danych i szybkich wyników. Z kolei jeśli zespół techniczny musi analizować pliki, logi lub różnorodne dokumenty, może zaakceptować większe opóźnienia w zamian za szerszy zakres danych.
Różnica w praktyce nie jest tylko techniczna. Zmienia się to, kto potrafi korzystać z danych bez konieczności proszenia za każdym razem o pomoc.
Dobrze zorganizowana hurtownia danych przybliża dane do biznesu. Samo jezioro danych częściej przybliża je do zespołu technicznego. Dlatego wiele małych i średnich przedsiębiorstw zbyt późno odkrywa pewną niewygodną prawdę: prawdziwy wybór nie polega na wyborze między dwiema technologiami, ale między systemem, który udostępnia dane, a takim, który je przechowuje, nie przekładając ich na lepsze decyzje.
Kto rozważa te opcje w ramach projektu modernizacji IT, powinien wziąć pod uwagę nie tylko repozytorium, ale także model operacyjny. Rozwiązania chmurowe dla małych i średnich przedsiębiorstw pomagają zrozumieć właśnie ten aspekt: gdzie kończy się infrastruktura, a gdzie zaczynają się koszty, wymagane kompetencje i codzienne obowiązki.
Data lake jest często przedstawiane jako najbardziej ekonomiczne rozwiązanie, ponieważ pozwala przechowywać surowe dane i ogranicza nakład pracy na początku. Jest to prawda tylko częściowo. Jeśli brakuje katalogu, zasad dostępu, spójnej nomenklatury i minimalnych kontroli jakości, początkowe oszczędności zamieniają się w stracony czas poświęcony na wyszukiwanie plików, odtwarzanie definicji i sprawdzanie, które dane są wiarygodne.
Dlatego w wielu małych i średnich przedsiębiorstwach właściwe porównanie nie polega na abstrakcyjnym zestawieniu „lake kontra warehouse”. Istotniejsze jest inne pytanie: czy naprawdę konieczne jest wdrażanie jednej z tych kompleksowych architektur, czy też lepiej zacząć od lżejszego rozwiązania, które zapewni szybki wgląd w dane, nie obciążając od razu całego systemu złożonymi mechanizmami?
W przypadku małych i średnich przedsiębiorstw najdroższy błąd wynika często z nieodpowiednio sformułowanego pytania: „czy tańsze jest jezioro danych, czy hurtownia danych?”. W firmie prawdziwy rachunek przychodzi później. Przychodzi wtedy, gdy dane nie są ze sobą kompatybilne, raporty przestają działać przy każdej zmianie systemu zarządzania, a każde zapytanie trafia do konsultantów lub programistów zamiast do zespołu, który ma podjąć decyzję.

Przechowywanie danych to mniejszy problem, niż mogłoby się wydawać. Znacznie większe znaczenie mają działania, które sprawiają, że dane są wiarygodne i użyteczne: modelowanie, integracja, uprawnienia, jakość, monitorowanie, korygowanie błędów oraz wsparcie dla użytkowników.
Tworzenie hurtowni danych wymaga początkowego nakładu pracy. Trzeba zdefiniować wskaźniki, zbudować potoki danych, zsynchronizować źródła oraz zadbać o porządek w systemie w przypadku zmian w systemach ERP, CRM lub zasadach biznesowych. W zamian za to kierownictwo otrzymuje bardziej stabilne dane, a raportowanie staje się bardziej przewidywalne.
Data lake często wiąże się z mniejszą obietnicą. Wgrywa się do niego dane różnego rodzaju i odkłada część decyzji dotyczących struktury na później. Problem polega na tym, że odłożenie tych decyzji nie eliminuje pracy. Przenosi ją jedynie na późniejszy etap, gdzie pojawia się ona w postaci katalogowania, zapewnienia bezpieczeństwa, kosztów obliczeniowych, powielania danych, niespójnych wersji oraz ciągłego sprawdzania, które dane są rzeczywiście wiarygodne.
Ryzyko dla małego lub średniego przedsiębiorstwa polega na tym, że może zapłacić podwójnie. Najpierw za zebranie danych, a potem za to, by w końcu stały się one czytelne.
Prawdziwa złożoność nie ma charakteru technicznego. Ma charakter operacyjny.
Jeśli każde nowe sprawozdanie wymaga ręcznej ingerencji, jeśli kontroler i handlowiec stosują różne definicje tego samego wskaźnika, jeśli przedsiębiorca musi czekać kilka dni na wiarygodne dane, to projekt związany z danymi już teraz pochłania zyski. Nawet jeśli infrastruktura na papierze wydaje się nowoczesna.
Dlatego warto przeanalizować nie tylko architekturę, ale także model zarządzania. Rozwiązania chmurowe dla małych i średnich przedsiębiorstw pomagają właśnie dostrzec tę różnicę: co tak naprawdę kupujesz, jaka część konserwacji pozostaje w gestii firmy, a w jakim stopniu co miesiąc polegasz na specjalistycznej wiedzy.
Na rynku włoskim inwestorzy zainteresowani analityką oczekują widocznych rezultatów. Ograniczenia pracy ręcznej. Szybsze finalizowanie transakcji. Lepsza kontrola nad sprzedażą, marżami, zapasami i przepływami pieniężnymi. Nie chodzi o wyrafinowaną platformę, z której korzysta tylko garstka osób.
To zmienia kryteria wyboru. Małe i średnie przedsiębiorstwo nie powinno zastanawiać się, która architektura jest bardziej atrakcyjna lub elastyczna w teorii. Powinno raczej zadać sobie pytanie, ile czasu zajmie stworzenie niezawodnych pulpitów nawigacyjnych, ile osób będzie potrzebnych do ich utrzymania oraz jak szybko projekt zacznie przynosić korzyści.
W handlu detalicznym ukryte koszty szybko wychodzą na jaw. Jeśli dane dotyczące sprzedaży, zwrotów, promocji i zapasów pochodzą z różnych systemów, wystarczy jedno błędne zdefiniowanie pojęcia „marża” lub „sprzedaż netto”, by podważyć wiarygodność raportów. W takiej sytuacji problemem nie jest wybrana baza danych. Chodzi o to, że właściciel znów zaczyna podejmować decyzje w programie Excel.
W branży finansowej cena błędu jest jeszcze bardziej odczuwalna. Sprawozdawczość, bilansowanie, kontrola zarządcza i analiza odchyleń wymagają spójnych i identyfikowalnych danych. Jeśli każda weryfikacja wywołuje dyskusje na temat pochodzenia danych, projekt traci na opłacalności, zanim jeszcze zostanie ukończony.
Dlatego w praktyce wiele małych i średnich przedsiębiorstw nie musi budować od podstaw kompletnego jeziora danych ani hurtowni danych. Potrzebują one lżejszego, łatwiejszego w zarządzaniu i zorientowanego na podejmowanie decyzji systemu.
Jeśli nie jesteś w stanie utrzymać jakości danych, zasad dostępu i wspólnych definicji w dłuższej perspektywie, problemem nie jest wybór między jeziorem danych a hurtownią danych. Problemem jest to, że wprowadziłeś złożoność, zanim pojawił się przypadek użycia, który by ją uzasadniał.
Nie chodzi o to, która architektura jest „najlepsza” w sensie ogólnym. Chodzi o to, jakie wyzwanie musisz rozwiązać jutro rano.

W handlu detalicznym magazyn działa sprawnie, gdy trzeba zawsze odpowiadać na te same pytania operacyjne:
To samo dotyczy sektora finansowego. Jeśli musisz konsolidować dane ustrukturyzowane, sporządzać okresowe raporty, analizować portfele lub interpretować trendy gospodarcze w oparciu o stałe kryteria, hurtownia danych pozostaje naturalnym wyborem.
Model ten ma sens, gdy Twoja firma gromadzi bardzo zróżnicowane dane i nie chcesz lub nie możesz z góry określić wszystkich szczegółów.
Realistycznym przykładem jest przedsiębiorstwo energetyczne, które łączy:
W takiej sytuacji klasyczny magazyn danych zmusza do wcześniejszego zaprojektowania relacji między źródłami, których być może jeszcze dobrze nie znasz. Jezioro danych pozwala scentralizować wszystkie dane i nadać im strukturę dopiero wtedy, gdy jest to potrzebne do konkretnej analizy. Właśnie w takich sytuacjach elastyczność jeziora danych naprawdę tworzy wartość.
Data lake nie jest po prostu „nowocześniejszym” rozwiązaniem. Jest to rozsądny wybór tylko wtedy, gdy różnorodność danych uzasadnia złożoność, jaką się w ten sposób wprowadza do firmy.
Większość małych i średnich przedsiębiorstw nie ma do czynienia z taką sytuacją. Dysponują one przede wszystkim danymi z systemów ERP, CRM, sklepów internetowych, księgowości oraz plików CSV i Excel. W takich przypadkach problemem nie jest zarządzanie plikami wideo, logami aplikacji czy tekstami dowolnymi na dużą skalę. Problemem jest posiadanie danych czystych, spójnych i zrozumiałych dla osób bez wiedzy technicznej.
W tym miejscu należy jasno powiedzieć: często nie potrzeba ani jeziora danych, ani tradycyjnej hurtowni danych.
Potrzebne jest raczej:
Model „lakehouse” próbuje połączyć te dwa światy. Oferuje elastyczność modelu „lake” oraz niektóre zalety modelu „warehouse” w jednym środowisku. To interesujący kierunek, zwłaszcza dla firm, których obciążenia obejmują zarówno BI, AI, jak i naukę o danych.
Dla małego lub średniego przedsiębiorstwa pytanie pozostaje jednak takie samo: czy naprawdę masz problem, który wymaga aż tego wszystkiego? Jeśli chcesz po prostu lepiej analizować wyniki sprzedaży, marże, przepływy pieniężne lub prognozy, zaawansowane rozwiązanie hybrydowe może nadal być nieproporcjonalne w stosunku do oczekiwanej wartości.
Koncepcja data lakehouse powstała, aby przełamać sztywny podział między jeziorem danych a hurtownią danych. Idea jest prosta: zachować elastyczność rozległej i otwartej pamięci masowej, dodając jednocześnie porządek, wydajność i możliwości analityczne zbliżone do tych, jakie oferuje hurtownia danych. Technologie takie jak Databricks i Delta Lake dobrze odzwierciedlają ten kierunek rozwoju.
W teorii brzmi to bardzo atrakcyjnie. Wykorzystuje się tę samą bazę danych do celów BI, zaawansowanej analizy i uczenia maszynowego, unikając w ten sposób nadmiernego powielania informacji między różnymi systemami. Dla dużych organizacji lub dojrzałych zespołów ds. danych jest to logiczna odpowiedź na ekosystem, który z biegiem czasu stał się coraz bardziej skomplikowany.
W testach porównawczych przeprowadzanych w środowisku akademickim architektura typu data lakehouse jest oceniana na podstawie takich wskaźników, jak przepustowość, opóźnienie i obciążenie związane z metadanymi. Pokazuje to, że porównanie z hurtownią danych dotyczy nie tylko funkcjonalności, ale także wydajności – zwłaszcza w scenariuszach, w których nawet niewielkie różnice w wydajności mają znaczący wpływ, co podkreśla ta akademicka prezentacja poświęcona testom porównawczym architektury typu data lakehouse.
W języku biznesowym: Lakehouse rozwiązuje problemy organizacji, które osiągnęły już pewien poziom skali, złożoności i specjalizacji.
Jeśli tak naprawdę nie potrzebowałeś ani jeziora danych, ani hurtowni danych, to raczej nie potrzebujesz systemu, który łączy w sobie obie te funkcje.
Dla większości małych i średnich przedsiębiorstw najważniejsze pytanie nie brzmi: „Jaką architekturę wybrać?”, ale: „Jak uzyskać wiarygodne analizy, nie zamieniając projektu związanego z danymi w niekończącą się budowę?”.
To właśnie ten trzeci aspekt jest pomijany w wielu porównaniach typu „data lake kontra data warehouse”. Nie należy budować nowej, zastrzeżonej infrastruktury. Zamiast tego warto wprowadzić warstwę analityczną nad systemami, z których już korzystasz, przenosząc techniczną złożoność poza obszar operacyjny firmy.

W praktyce najrozsądniejsze podejście wygląda następująco:
Widziałem już niejedną małą lub średnią firmę, która poświęcała miesiące na wdrożenie tradycyjnego systemu magazynowego, a potem prawie z niego nie korzystała. Nie dlatego, że był źle zbudowany. Po prostu nikt w firmie nie umiał samodzielnie wyszukiwać w nim informacji. Wąskim gardłem nie była baza danych. Była to dostępność.
To właśnie ten aspekt jest często niedoceniany. Elegancka architektura, która zawsze wymaga pośrednika technicznego, zmniejsza praktyczną wartość danych. Prostsze rozwiązanie, zrozumiałe dla kierownictwa, często pozwala szybciej podejmować lepsze decyzje.
Dlatego wiele firm czerpie większe korzyści z dobrze zaprojektowanego oprogramowania do analizy biznesowej dla małych i średnich przedsiębiorstw niż z rozbudowanego systemu infrastrukturalnego. Nie chodzi im o to, by posiadać hurtownię danych. Chodzi o to, by lepiej i szybciej zrozumieć swoją działalność.
Właściwa infrastruktura to taka, z której Twój zespół potrafi korzystać, którą potrafi utrzymywać i która pomaga mu podejmować decyzje. Nie ta, która robi wrażenie na technicznej prezentacji.
Dyskusja na temat tego, czy lepiej wybrać jezioro danych, czy hurtownię danych, jest przydatna, ale w przypadku małych i średnich przedsiębiorstw często wychodzi się przy tym od niewłaściwego pytania. Zanim wybierzesz architekturę, musisz zrozumieć, czy naprawdę masz problem ze skalą i różnorodnością danych, czy też borykasz się z dużo częściej spotykanym problemem: rozproszonymi danymi, ręcznym tworzeniem raportów i ograniczoną dostępnością.
Hurtownia danych sprawdza się tam, gdzie potrzebne są wiarygodne raporty, spójne wskaźniki KPI i przewidywalna wydajność. Jezioro danych ma sens, gdy różnorodność źródeł uzasadnia większą elastyczność i złożoność. Model lakehouse stanowi interesującą ewolucję, ale rzadko jest właściwym pierwszym krokiem dla organizacji, której zależy przede wszystkim na kontroli operacyjnej i zwrocie z inwestycji.
Najmądrzejszym wyborem nie jest najnowocześniejsza technologia. Najmądrzejszym wyborem jest rozwiązanie dostosowane do rzeczywistego problemu, dostępnych kompetencji oraz tempa, w jakim chcesz przekształcać dane w decyzje.
Jeśli chcesz przekształcić dane firmowe w raporty, prognozy i wnioski operacyjne bez konieczności budowania skomplikowanej infrastruktury, poznaj ELECTE – platformę do analizy danych opartą na sztucznej inteligencji, przeznaczoną dla małych i średnich przedsiębiorstw. Możesz zacząć od danych, które już posiadasz, ograniczyć nakład pracy ręcznej i zapewnić swojemu zespołowi dostęp do analiz dzięki znacznie bardziej sprawnemu podejściu.

.svg)
.svg)
.svg)






