

Zespoły finansowe w małych i średnich przedsiębiorstwach dobrze o tym wiedzą: za każdym razem, gdy próbuje się zaimportować plik PDF do Excela, zaczyna się walka z formatowaniem. Klasyczne kopiowanie i wklejanie prawie zawsze kończy się katastrofą: rozrzucone dane, przypadkowo połączone komórki i uporządkowane tabele zamieniają się w nieczytelny chaos. Frustracja jest realna, ale to nie twoja wina. Problem leży w samej naturze formatu PDF, zaprojektowanego do drukowania i udostępniania, a nie jako źródło danych do analizy.
Ten ręczny proces, obejmujący raporty bankowe, faktury od dostawców i dokumenty urzędowe, stanowi prawdziwą czarną dziurę dla wydajności. Oprócz tego, że jest uciążliwy, stanowi niemal pewne źródło błędów przy wprowadzaniu danych. Na szczęście w 2026 roku masz do dyspozycji znacznie inteligentniejsze metody, aby sprostać temu wyzwaniu. W tym przewodniku pokażemy Ci krok po kroku najskuteczniejsze strategie, od tych zintegrowanych z programem Excel po rozwiązania oparte na sztucznej inteligencji, które całkowicie eliminują pracę ręczną, umożliwiając przejście od ekstrakcji danych do analizy w ciągu kilku minut.
Problem wynika z zasadniczej różnicy: pliki PDF zostały stworzone w celu zachowania wyglądu dokumentu na każdym urządzeniu, a nie w celu zachowania logicznej struktury zawartych w nim danych. Zrozumienie różnicy między rodzajami plików PDF to pierwszy krok do wyboru odpowiedniego narzędzia i uniknięcia wielu godzin niepotrzebnej pracy.
To zdjęcie doskonale oddaje frustrację każdego, kto musi pogodzić zawartość skomplikowanego pliku PDF z nieuporządkowanym arkuszem kalkulacyjnym.

To właśnie w tym momencie ręczny proces staje się przeszkodą dla wydajności, co wskazuje na potrzebę zastosowania bardziej efektywnej metody importowania plików PDF do programu Excel.
Być może nie wiesz, ale najprostszym narzędziem do importowania plików PDF do programu Excel jest funkcja wbudowana w oprogramowanie, z którego korzystasz na co dzień. Nazywa się ona Power Query i jest to potężna funkcja „Pobierania i przekształcania danych”, którą firma Microsoft włączyła do programu Excel.

To idealne rozwiązanie do sporadycznego importowania prostych i przejrzystych plików PDF, takich jak cennik czy lista kontaktów. Jego największa zaleta? Jest bezpłatne i nie wymaga instalacji dodatkowego oprogramowania.
Dane zostaną umieszczone w nowym arkuszu, sformatowanym już jako tabela programu Excel i gotowym do użycia.
Power Query jest świetne, ale ma swoje ograniczenia. Najlepiej sprawdza się w przypadku prostych tabel zawartych na jednej stronie. Jego wydajność znacznie spada w bardziej złożonych sytuacjach:
Jeśli często zajmujesz się analizą danych, warto zapoznać się z integracjami z Power BI, które wykorzystują tę samą technologię. Podobnie, umiejętność obsługi innych formatów ma kluczowe znaczenie; nasz przewodnik dotyczący obsługi plików CSV w programie Excel może dostarczyć Ci przydatnych wskazówek.
Jeśli Twoja firma posiada już licencję na program Adobe Acrobat Pro, jego funkcja eksportu jest jednym z najbardziej niezawodnych rozwiązań. Często przewyższa ona możliwości Power Query pod względem zachowania formatowania złożonych tabel o nietypowym układzie.
Procedura jest prosta: otwórz plik PDF, przejdź do sekcji „Wszystkie narzędzia”, wybierz opcję „Eksportuj do PDF”, ustaw format na „Arkusz kalkulacyjny” i zapisz nowy plik Excel.
Efekt jest prawie zawsze schludny i uporządkowany. Istnieją jednak dwie główne wady:
Narzędzia takie jak iLovePDF, Smallpdf czy oprogramowanie open source Tabula są niezwykle wygodne: wystarczy przeciągnąć plik, kliknąć przycisk i pobrać wynik. Stanowią one dobre rozwiązanie do sporadycznej konwersji danych, które nie zawierają informacji wrażliwych.
Jednak za tą wygodą kryje się ogromne ryzyko: bezpieczeństwo danych.
Przesłanie dokumentu na serwer podmiotu zewnętrznego oznacza w praktyce utratę nad nim kontroli. Jeśli ten plik PDF zawiera wyciągi z kont, dane klientów, poufne cenniki lub jakiekolwiek informacje strategiczne, narażasz swoją firmę na potencjalne naruszenia prywatności i poważne ryzyko związane z niezgodnością z RODO.
Dla małych i średnich przedsiębiorstw działających w Europie nie jest to kwestia bez znaczenia. Korzystanie z internetowego konwertera w celu analizy publicznego raportu Istat jest dopuszczalne. Jednak stosowanie go w odniesieniu do danych finansowych własnej firmy to ryzykowne posunięcie, które należy dokładnie rozważyć.
Jeśli Twój zespół musi zajmować się dziesiątkami wyciągów bankowych, faktur lub raportów, które co miesiąc przychodzą w tym samym formacie, ręczne ich wyodrębnianie to coś więcej niż tylko uciążliwość: to prawdziwe wąskie gardło w pracy.
Dla małych i średnich przedsiębiorstw, które przetwarzają duże ilości standardowych dokumentów, automatyzacja za pomocą skryptów w języku Python nie jest luksusem, lecz inwestycją mającą na celu zwiększenie wydajności. Oczywiście wymaga to umiejętności technicznych, ale zwrot z inwestycji jest ogromny pod względem zaoszczędzonego czasu i wyeliminowanych błędów.

Python dominuje w tej dziedzinie dzięki bezpłatnym i niezwykle potężnym bibliotekom, takim jak pdfplumber i Camelot, zaprojektowane specjalnie do rozpoznawania i odtwarzania struktury tabel zawartych w plikach PDF.
pdfplumber: Jest niezwykle wszechstronny i doskonale nadaje się do wyodrębniania tabel, tekstu i metadanych poprzez analizę położenia każdego pojedynczego znaku.Camelot: Specjalizuje się w wyciąganiu danych z tabel i oferuje zaawansowane algorytmy do obsługi tabel zarówno z widocznymi liniami podziału, jak i bez nich.Praktyczny przykład: Wyobraź sobie, że pod koniec miesiąca otrzymujesz od dostawcy 50 faktur. Zamiast angażować zasoby na wiele godzin, skrypt w języku Python może je przeanalizować, wyodrębnić sumy i daty oraz wygenerować plik Excel gotowy do analizy. Wszystko to w mniej niż minutę i przy całkowitym wyeliminowaniu ryzyka błędów ludzkich.
Po wyodrębnieniu i uporządkowaniu dane te można przesłać do platform analitycznych. Aby dowiedzieć się więcej o tym, jak włączyć te dane do szerszych procesów, zapoznaj się z działaniem interfejsów API ELECTE, które umożliwiają automatyczne przesyłanie danych do naszej platformy.
Kiedy tradycyjne metody zawodzą, do akcji wkracza sztuczna inteligencja. Platformy oparte na sztucznej inteligencji, takie jak ELECTE zasady gry, zwłaszcza w przypadku dokumentów zeskanowanych lub o złożonym układzie.
Nie mówimy tu o starym OCR, który ograniczał się jedynie do „odczytywania” tekstu. Nowoczesne rozwiązania łączą OCR z zaawansowanymi modelami językowymi (LLM), aby zrozumieć strukturę, kontekst i powiązania między danymi.
Wyobraź sobie raport finansowy zawierający tabele rozciągające się na kilka stron. Platforma oparta na sztucznej inteligencji jest w stanie:
To wszystko zmienia. Zamiast wyodrębniać surowe dane, platforma AI „przetwarza” plik PDF i zwraca go w postaci uporządkowanego zbioru danych gotowego do analizy. Jeśli chcesz dowiedzieć się więcej, omówiliśmy to w naszym artykule poświęconym najlepszym rozwiązaniom sztucznej inteligencji dla firm.
Prawdziwą wartością sztucznej inteligencji nie jest pozyskiwanie danych, ale uzyskiwanie gotowych do wykorzystania informacji. Nie otrzymujesz zwykłego pliku Excel, ale dane, które Twój zespół może od razu wykorzystać do podejmowania strategicznych decyzji, bez tracenia czasu na ich porządkowanie.
Ciekawym faktem jest to, że Mediolan dominuje wśród włoskich importerów. Jednak możliwość automatycznego wygenerowania pełnego raportu dotyczącego prowincji importujących pozwala Twojemu zespołowi osiągnąć znacznie więcej: porównać trendy, zoptymalizować zapasy i obniżyć koszty.
Skoro jest tak wiele opcji, jak wybrać tę odpowiednią dla siebie? Odpowiedź zależy od czterech kluczowych czynników, które decydują o wydajności, bezpieczeństwie i kosztach Twojej operacji.
To drzewo decyzyjne pomoże Ci prześledzić logiczny tok rozumowania prowadzący do podjęcia decyzji.
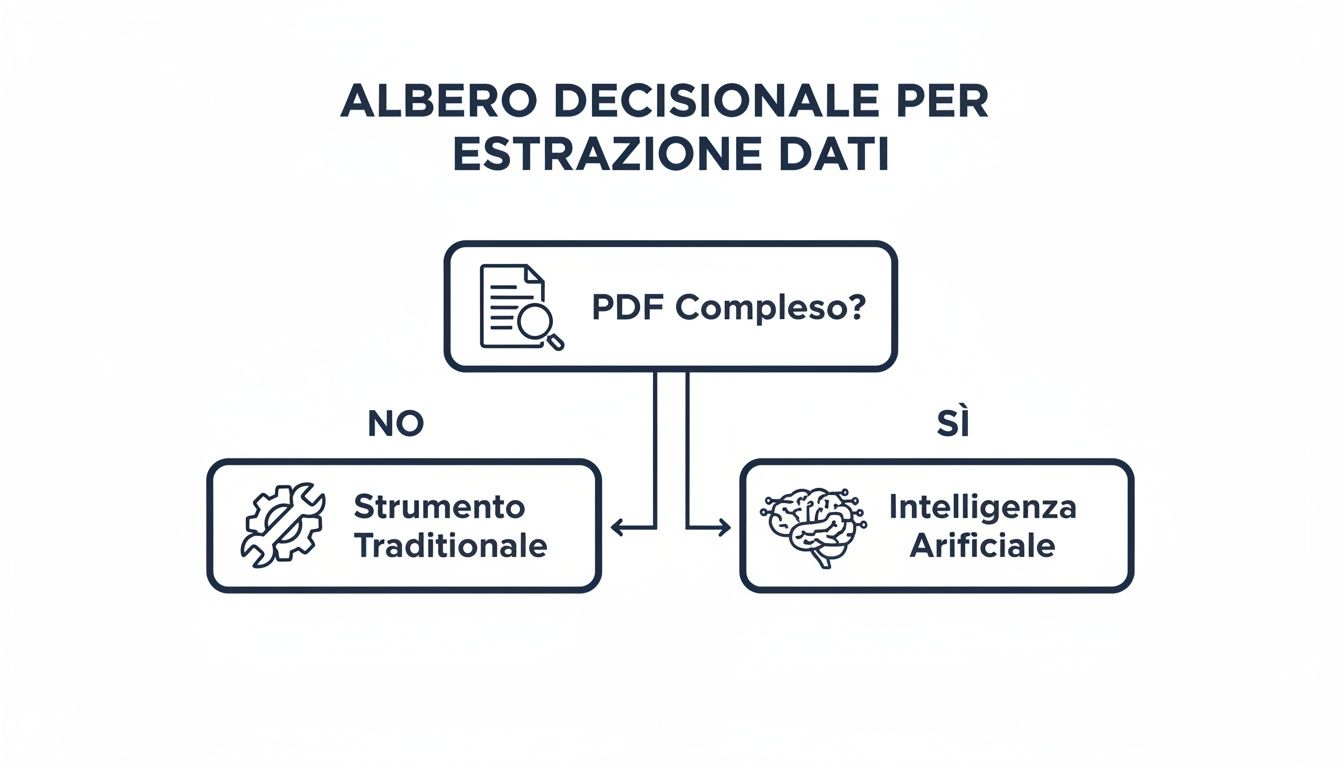
Schemat jest prosty: w przypadku prostych plików PDF i sporadycznych zadań idealnie sprawdzają się tradycyjne narzędzia, takie jak Power Query. Natomiast w przypadku dużych ilości danych, złożonych dokumentów i powtarzających się procesów platforma oparta na sztucznej inteligencji, taka jak ELECTE żmudne zadanie w zautomatyzowany proces, który generuje wartość.
Importowanie plików PDF do programu Excel nie musi już być żmudnym i frustrującym procesem. Obecnie masz do dyspozycji szeroki wachlarz narzędzi – od bezpłatnych i wbudowanych, takich jak Power Query, po zaawansowane rozwiązania automatyzacyjne i platformy oparte na sztucznej inteligencji.
Wybór zależy od konkretnych potrzeb: w przypadku sporadycznych operacji na prostych plikach Power Query nie ma sobie równych. Jeśli chodzi o obsługę powtarzających się dużych ilości złożonych i wrażliwych dokumentów, automatyzacja i sztuczna inteligencja nie są już luksusem, lecz strategiczną koniecznością. Eliminując ręczne pozyskiwanie danych, nie tylko oszczędzasz czas i ograniczasz błędy, ale także uwalniasz swoje najcenniejsze zasoby, aby mogły skupić się na tym, co naprawdę ma znaczenie: analizowaniu danych w celu podejmowania mądrzejszych i szybszych decyzji biznesowych. W ten sposób przekształcasz zwykły dokument w źródło przewagi konkurencyjnej.
Gotowy, by na zawsze pożegnać się z kopiowaniem i wklejaniem? Dowiedz się, jak ELECTE przyspieszyć Twoje decyzje przekształcając Twoje najbardziej skomplikowane pliki PDF w praktyczne wnioski.

.svg)
.svg)
.svg)






