

Właśnie dlatego Mistral Science jest ważniejszy niż wiele innych projektów AI, które wzbudziły większy rozgłos. Jeśli pracujesz w dziedzinie badań, przemysłu lub strategii danych, prawdziwą nowością nie jest kolejny asystent potrafiący płynnie rozmawiać o nauce. Jest nią pojawienie się europejskiej próby stworzenia sztucznej inteligencji dla badań naukowych, zdolnej do modelowania, symulowania i przyspieszania odkryć w dziedzinach, w których fizyka, materiałoznawstwo, biologia i systemy finansowe nie wybaczają przybliżeń. Dla Europy to coś znacznie więcej niż tylko jedna firma. Dotyka to strukturalnej słabości, z którą kontynent boryka się od lat: polegania na dostawcach modeli spoza Europy w zakresie podstawowej infrastruktury cyfrowej.
Zainteresowanie firmy Mistral modelami typu open-weight oraz jej wejście na rynek specjalistycznej sztucznej inteligencji poprzez Emmi AI wskazują na inną ścieżkę rozwoju. Ścieżkę, na której europejskie organizacje mogą analizować, dostosowywać i wdrażać modele, zachowując większą kontrolę nad danymi, metodami oraz zależnościami od podmiotów działających na dalszych etapach łańcucha.
Poniższe pytanie stanowi sedno nagłówków prasowych: dlaczego ta zmiana może stać się punktem zwrotnym dla europejskiej suwerenności technologicznej i co oznacza to w praktyce dla naukowców, małych i średnich przedsiębiorstw oraz liderów branży technologicznej, którzy właśnie teraz wybierają swój stos rozwiązań AI.
Mistral jest interesujący nie tylko dlatego, że jest europejskim projektem. Jest interesujący, ponieważ podejmuje się czegoś, co Europa dotychczas rzadko realizowała na skalę globalną: przekształcenia sztucznej inteligencji z ogólnego oprogramowania w strategiczną infrastrukturę dla nauki i przemysłu.
Różnica ma znaczenie. Model konsumencki może poprawić indywidualną wydajność, ułatwić pisanie i zwiększyć dostęp do wiedzy. Natomiast platforma sztucznej inteligencji przeznaczona do badań naukowych może skrócić cykle odkryć, wspierać symulacje, przyspieszyć wybór hipotez oraz zmienić relacje między laboratorium, obliczeniami a decyzjami przemysłowymi.
Kwestia ta nie jest abstrakcyjna nawet we Włoszech. Istat sformalizował wykorzystanie sztucznej inteligencji w celu unowocześnienia procesów statystycznych, realizując działania obejmujące dane syntetyczne, klasyfikatory, chatboty oraz program LAbInn służący do automatyzacji kodowania, ulepszania baz danych administracyjnych oraz analizy terytorium i obrazów geoprzestrzennych, sygnalizując przejście od wykorzystania eksperymentalnego do bardziej ustrukturyzowanego wdrożenia instytucjonalnego (podejście Istat do sztucznej inteligencji).
Temat: Model LLM o charakterze ogólnym; Mistral Science i modele naukowe; Główny cel: Język, synteza, wsparcie konwersacyjne; Symulacja, modelowanie, przyspieszone odkrywanie; Podstawa uczenia się: Wzorce statystyczne w dużych korpusach; Dane specjalistyczne, ograniczenia dziedzinowe, prawa fizyczne Typowy wynik Prawdopodobna i dobrze sformułowana odpowiedź Przydatna prognoza w technicznym lub naukowym przepływie pracy Wartość strategiczna Wszechstronna produktywność Uzasadniona przewaga przemysłowa i naukowa Implikacje europejskie Uzależnienie od globalnych dostawców w przypadku rozwiązania zamkniętego Większa kontrola w przypadku rozwiązania otwartego i adaptowalnego
Mistral Science należy postrzegać jako strategiczny atut Europy, a nie jako zwykłą funkcję.
Przede wszystkim należy wyjaśnić, że Mistral for Science nie powinien być postrzegany jako akademicka wersja chatbota. Takie rozumienie jest zbyt wąskie i prowadzi do błędnych wniosków.
Kiedy model ogólny „mówi o nauce”, zazwyczaj posługuje się językiem technicznym zaczerpniętym z podręczników, artykułów, dokumentacji i kodu. Może to być przydatne do podsumowywania, wyjaśniania lub formułowania hipotez. Nie oznacza to jednak, że model ten dobrze odwzorowuje układ fizyczny, procesy inżynieryjne czy symulację o wysokiej wierności.
W badaniach naukowych problem nie polega tylko na tym, by sformułować spójną tezę. Problem polega na uwzględnieniu rzeczywistych ograniczeń.
Model ogólny może wyjaśnić zasady aerodynamiki. Model inżynierski powinien pomóc w symulacji zachowania przepływu w określonych warunkach. Model LLM może streszczać artykuły naukowe dotyczące materiałów. Model specjalistyczny powinien pomóc w zawężeniu zakresu możliwości do przetestowania.
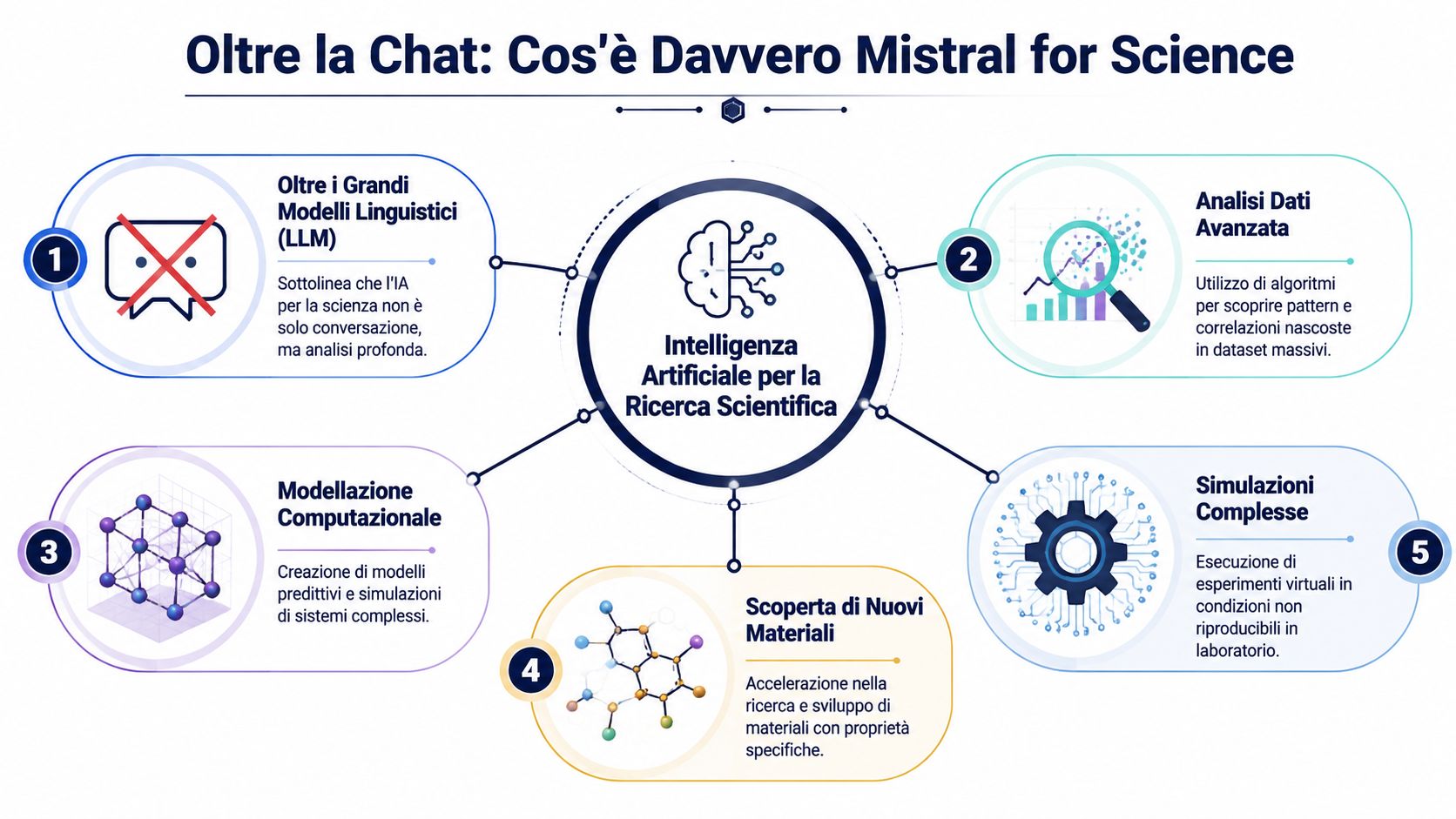
Właśnie dlatego przejęcie firmy Emmi AI ma tak duże znaczenie. Sygnał strategiczny jest jasny: Mistral nie chce ograniczać się do poziomu aplikacji językowych. Wkracza w kategorię, w której model uwzględnia strukturę problemu.
Tak zwane „Large Engineering Models” wyznaczają konkretny kierunek. Nie są to jedynie modele wyszkolone na dokumentacji technicznej, ale systemy zaprojektowane do działania w kontekstach, w których rzeczywistość podlega równaniom, ograniczeniom i symulacjom.
Dla europejskiego czytelnika zmienia to samo znaczenie pojęcia „sztuczna inteligencja w nauce”. Nie chodzi tu o stworzenie lepszego asystenta dla naukowca. Chodzi o zbudowanie silnika obliczeniowego, który przyspieszy badania nad rzeczywistymi problemami.
Trzy praktyczne konsekwencje:
Istnieje również drugi poziom, który często jest pomijany. We Włoszech instytucjonalne wdrożenie sztucznej inteligencji przez Istat tworzy bardziej sprzyjające warunki kulturowe i operacyjne dla tego przełomu. Jeśli krajowa instytucja statystyczna wykorzystuje sztuczną inteligencję do tworzenia danych zbiorczych, automatyzacji kodowania i analizy danych geoprzestrzennych, oznacza to, że sztuczna inteligencja naukowa nie jest już ograniczona do elitarnych laboratoriów, ale wkracza w formalne procesy tworzenia wiedzy publicznej.
Ogólny model językowy (LLM) świetnie radzi sobie z wyjaśnianiem świata. Przydatny model naukowy powinien natomiast pomagać w jego obliczaniu.
Właśnie tego wielu nie dostrzega. Mistral Science nie jest ważny dlatego, że „wkracza w sferę nauki”. Jest ważny, ponieważ próbuje przenieść Mistral do bardziej uzasadnionej kategorii, w której wartość wynika z integracji modelu, dziedziny i procesu przemysłowego.
Najbardziej niedocenianym aspektem firmy Mistral nie jest tempo, w jakim działa. Jest nim jej decyzja o postawieniu na modele w kategorii open-weight. Z punktu widzenia badań naukowych oraz wielu europejskich firm jest to decyzja o znaczeniu bardziej strategicznym niż jakakolwiek prezentacja.
Model zamknięty, dostępny wyłącznie za pośrednictwem API, zapewnia wygodę. Model typu open-weight daje większą swobodę kontroli. A w Europie kontrola nie jest kwestią filozoficzną. Jest to warunek konieczny przy pracy z danymi wrażliwymi, własnością intelektualną, procesami podlegającymi regulacjom lub krytycznymi łańcuchami dostaw.
Gdy dane dotyczące modelu są dostępne, organizacja może realizować zadania, które w przypadku usługi opartej wyłącznie na modelu typu „czarna skrzynka” pozostają trudne lub niemożliwe do wykonania.
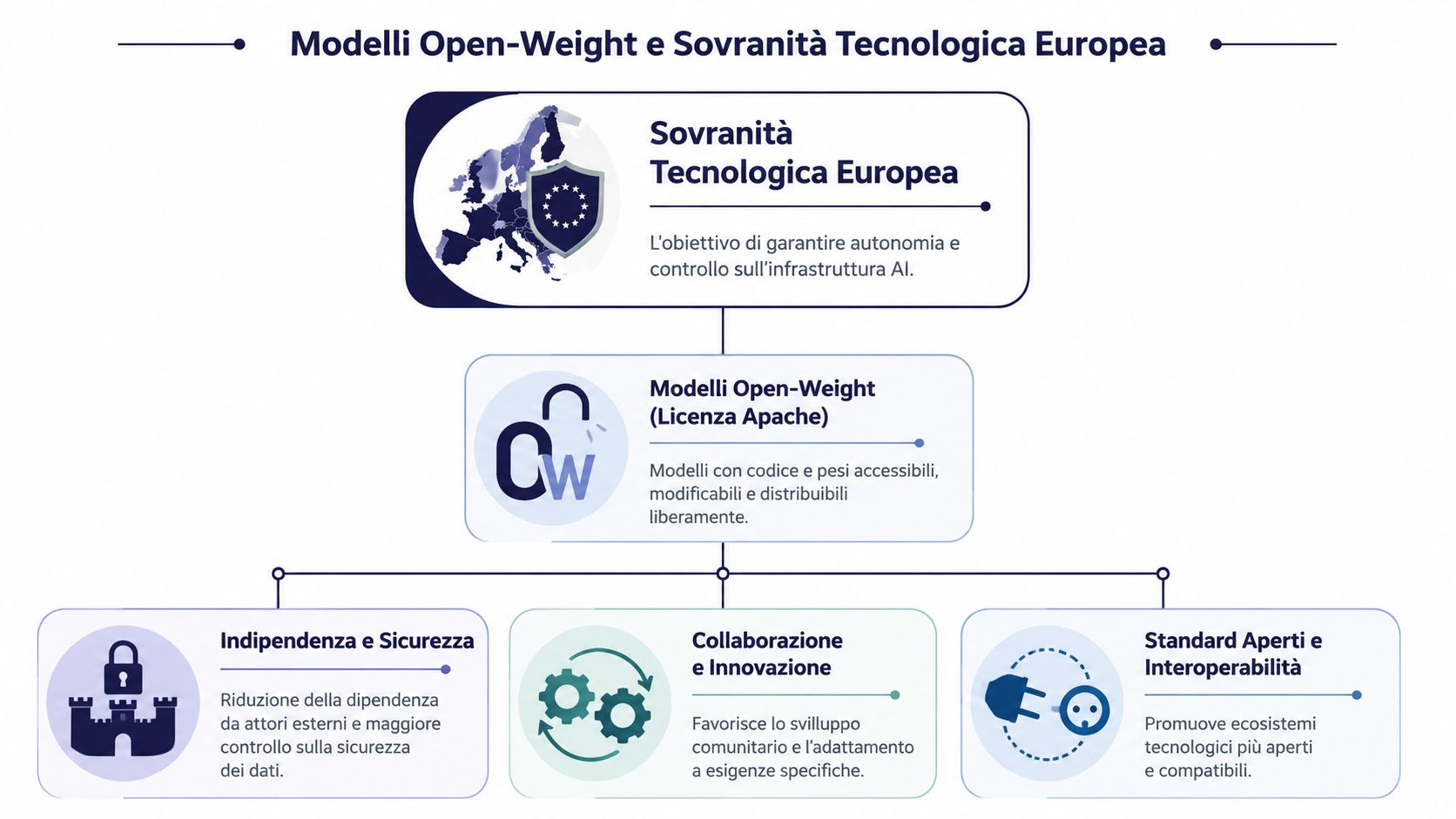
Dlatego też suwerenność technologiczna nie powinna sprowadzać się jedynie do hasła w dokumentach strategicznych. Dla przedsiębiorstwa oznacza to świadomość tego, kto kontroluje model, gdzie przepływają dane, w jakim stopniu rozwiązanie można dostosować do własnych potrzeb oraz ile będzie kosztowała zmiana kierunku w przyszłości.
Jeśli zarządzasz danymi badawczymi, własnością intelektualną lub procesami wymagającymi ścisłej zgodności z przepisami, to tak naprawdę nie pytasz: „Który model jest najpopularniejszy?”. Pytasz raczej: „Który model mogę kontrolować, nie uzależniając się strategicznie od jednego podmiotu zewnętrznego?”.
Dotyczy to również aspektów prawnych i organizacyjnych. Każdy, kto ma do czynienia z obowiązkami związanymi ze sztuczną inteligencją w przedsiębiorstwach, wie, że nie chodzi tu wyłącznie o wydajność modelu. Istotna jest również identyfikowalność decyzji, zrozumienie ograniczeń oraz możliwość udokumentowania sposobu wykorzystania.
Istnieje też mniej poruszany aspekt ekonomiczny. W środowisku akademickim i wśród małych i średnich przedsiębiorstw wartość modelu otwartego nie polega wyłącznie na kosztach. Polega ona na możliwości budowania lokalnego potencjału. Dostępny model sprzyja uczeniu się, dostosowywaniu i tworzeniu wewnętrznych narzędzi. Natomiast zamknięty interfejs API zazwyczaj skupia potencjał intelektualny i operacyjny w rękach dostawcy.
Suwerenność technologiczna zaczyna się wtedy, gdy można zdecydować, jak wykorzystać dany model, a nie tylko wtedy, gdy można wykupić do niego dostęp.
Z tego punktu widzenia posunięcie firmy Mistral ma jednoznaczny wydźwięk. Jeśli Europa chce zająć wiarygodną pozycję w dziedzinie sztucznej inteligencji, nie wystarczy mieć start-upy, które odsprzedają rozwiązania innych podmiotów. Potrzebni są gracze, którzy tworzą modele, ekosystemy i standardy wdrażania zgodne z realiami europejskiego przemysłu.
Aby zrozumieć, dokąd może prowadzić ta tendencja, warto przyjrzeć się przykładowi z praktyki, który już można zaobserwować na rynku. Microsoft informuje, że Microsoft Quantum i PNNL, korzystając z Azure Quantum Elements, przeanalizowały cyfrowo ponad 32 miliony materiałów, identyfikując nowy materiał do produkcji baterii, który wymaga o 70% mniej litu, a proces selekcji i testów zakończył się w ciągu zaledwie kilku tygodni (sztuczna inteligencja i obliczenia o wysokiej wydajności w służbie odkryć naukowych).
Ten przykład nie dotyczy bezpośrednio firmy Mistral. Pokazuje jednak kierunek, w którym zmierza ta branża: połączenie sztucznej inteligencji, obliczeń o wysokiej wydajności i szybkiej walidacji w celu radykalnego zawężenia zakresu badań.

Nie chodzi o to, że „sztuczna inteligencja wyczarowuje rozwiązania”. Wniosek jest bardziej konkretny: odpowiednie połączenie masowych badań przesiewowych, automatycznego ustalania priorytetów i ukierunkowanych testów może skrócić czas trwania badań i zmniejszyć nakład pracy związany z ich przeprowadzeniem.
Kiedy zespół przestaje działać na ślepo i zaczyna skuteczniej weryfikować hipotezy, poprawia się jakość podejmowanych wcześniej decyzji. W tym sensie prawdziwy potencjałsztucznej inteligencji w badaniach naukowych ma charakter selektywny, a nie spektakularny.
W praktyce inicjatywa taka jak Mistral Science ma sens w dziedzinach, w których sam język nie wystarcza.
Jest jeszcze jedna kwestia, która nie jest tak oczywista. Badanie podsumowane przez Il Bo Live wskazuje, że osoby korzystające z narzędzi AI w badaniach publikują około trzy razy więcej artykułów, otrzymują prawie pięć razy więcej cytowań i szybciej osiągają stanowiska kierownicze. Jednak to samo badanie wykazuje również spadek o 4,63% w zakresie zbiorowego zgłębiania tematów oraz spadek o 22% w cytowaniach między artykułami odnoszącymi się do tej samej pracy (włoska analiza badania opublikowanego w Nature).
Dane te sugerują wniosek, który może być niewygodny, ale przydatny. Sztuczna inteligencja może zwiększyć wydajność badań naukowych, a jednocześnie ograniczyć różnorodność kierunków badań. Twórcy platform i procesów badawczych będą zatem musieli dążyć do optymalizacji nie tylko pod kątem wydajności, ale także różnorodności hipotez.
Dyskusja na temat Mistrala traci sens, gdy popada w dwie skrajności. Z jednej strony mamy automatyczny entuzjazm wobec każdego europejskiego gracza. Z drugiej zaś – odruchowe uznawanie za nieistotnego każdego, kto nie osiąga najlepszych wyników we wszystkich ogólnych testach porównawczych.
Rzeczywistość jest bardziej interesująca. Jeśli chodzi o najtrudniejsze zadania wymagające myślenia przekrojowego, cała branża wciąż jest daleka od osiągnięć, które naprawdę budziłyby zaufanie.
Włoski przewodnik po testach porównawczych wskazuje, że model Deep Research firmy NinjaTech osiągnął 17,47% trafności w teście Humanity's Last Exam, uznawanym za jeden z najtrudniejszych testów sprawdzających rozumowanie wielodomenowe. W tym samym przewodniku zauważono, że testy porównawcze przydatne w badaniach naukowych powinny uwzględniać również opóźnienia, jakość rozumowania oraz wydajność sieci podczas korzystania z interfejsu API (testy porównawcze AI w kontekście badań naukowych).

Warto dokładnie zapoznać się z tym wydaniem. Nie dowodzi ono, że którykolwiek z graczy jest słaby. Pokazuje natomiast, że nawet zaawansowane modele wciąż napotykają problemy wymagające solidnej uogólnienia. Byłoby więc naiwnością opisywanie obecnie modelu Mistral jako równoważnego, w sensie ogólnym, z najlepszymi amerykańskimi modelami typu frontier w przypadku bardziej złożonych zadań.
Jednak właściwe pytanie nie brzmi: „kto wygrywa wszędzie”. Brzmi ono: „która architektura i która strategia są najlepsze do realizacji konkretnego zadania”.
Mistral może być nieco słabszy w niektórych obszarach ogólnych, ale o wiele bardziej interesujący tam, gdzie ma to znaczenie:
Jeśli postrzega się rynek wyłącznie jako wyścig o osiągnięcie absolutnego benchmarku, projekt Mistral może sprawiać wrażenie, jakby pozostawał w tyle. Jeśli jednak spojrzeć na niego jako na budowę europejskiej infrastruktury przeznaczonej do specjalistycznych zastosowań, obraz sytuacji zmienia się diametralnie. W tym kontekście celem nie jest pokonanie każdego konkurenta na najbardziej zatłoczonym polu. Chodzi o zajęcie segmentu o wysokiej wartości, w którym połączenie otwartości, wydajności i specjalizacji ma większe znaczenie niż sama skala.
Aby właściwie zrozumieć ten fragment, warto zapoznać się z rynkiem dużych modeli językowych, nie ograniczając się jednak do rankingu modeli ogólnych.
Strategiczna przewaga Mistrala nie wynika z dążenia do tego, by zadowolić wszystkich. Wynika ona z tego, że może on być bardzo przydatny tam, gdzie dominacja ma większe znaczenie niż skala.
Istnieje też pewien aspekt, który rynek często pomija. Włoskie analizy dotyczące wykorzystania generatywnej sztucznej inteligencji w badaniach naukowych wykazały problemy z weryfikowalnością źródeł, potencjalne zagrożenia związane z prawami autorskimi oraz pogorszenie jakości naukowej w przypadku niewłaściwego stosowania tych systemów. To prosta wskazówka: im większa pozorna autonomia modelu, tym większa musi być dyscyplina metodologiczna ze strony człowieka.
W przypadku europejskiej firmy wniosek nie brzmi: „zawsze wybieraj Mistral” ani „zawsze wybieraj najmocniejszy model”. Byłoby to błędne uproszczenie. Właściwy wybór zależy od rodzaju problemu, który chcesz rozwiązać.
Jeśli Twoja kwestia dotyczy wielu dziedzin, dokumentacji, języka lub ogólnej wydajności, warto rozważyć zastosowanie modelu LLM o szerokim zakresie zastosowań.
Jeśli natomiast korzystasz z:
W takim razie pytanie wygląda inaczej. W takich przypadkach trzeba rozważyć, czy wyspecjalizowany model – a przynajmniej taki, który można dostosować i kontrolować – przyniesie większą wartość strategiczną niż zamknięta usługa, która w wersji demonstracyjnej prezentuje się bardziej efektownie.
Praktyczny model można opierać na pięciu kryteriach:
Część rynku będzie nadal traktować sztuczną inteligencję jako narzędzie użytkowe. W wielu przypadkach jest to uzasadniony wybór. Jednak podmioty działające w wysoce wyspecjalizowanych sektorach europejskich powinny zacząć postrzegać sztuczną inteligencję jako infrastrukturę strategiczną. Właśnie w tym kontekście działania takie jak Mistral Science nabierają znaczenia.
Najważniejsza lekcja jest prosta. Nie należy mylić uroku sztucznej inteligencji ogólnej z wartością sztucznej inteligencji specjalistycznej.

Oto kwestie, które należy poruszyć na spotkaniu:
Mistral Science nie jest jeszcze punktem kulminacyjnym europejskiej sztucznej inteligencji. Jest to jednak jeden z najsilniejszych sygnałów, że Europa zaczęła grać mądrzej. Nie chodzi tylko o naśladowanie światowych liderów, ale o wybór obszarów, w których może zbudować własną przewagę.
Jeśli zastanawiasz się, jak wdrożyć sztuczną inteligencję w rzeczywiste procesy decyzyjne bez niepotrzebnego komplikowania ich, zapoznaj się z ELECTE. Jest to oparta na sztucznej inteligencji platforma do analizy danych, stworzona z myślą o przekształcaniu surowych danych w praktyczne wnioski, a jej obsługa jest przystępna nawet dla zespołów bez wiedzy technicznej. Możesz sprawdzić, jak działa, i dowiedzieć się, która architektura sztucznej inteligencji najlepiej pasuje do Twoich potrzeb.

.svg)
.svg)
.svg)






