

Otrzymujesz plik XML za pośrednictwem certyfikowanej poczty elektronicznej (PEC). Otwierasz go w przeglądarce, widzisz morze tagów i wydaje ci się, że problemem jest „odczytanie” tego pliku. W rzeczywistości to tylko pierwsza przeszkoda. Prawdziwym problemem w firmie jest coś innego: ustalenie, czy te dane są poprawne, spójne i gotowe do wykorzystania w raportach.
Dla wielu włoskich małych i średnich przedsiębiorstw kwestia ta nie ma już charakteru czysto technicznego. Odkąd faktury elektroniczne stały się obowiązkowe, format XML stał się częścią codziennej pracy w obszarach administracji, kontroli zarządczej i analizy. Nie wystarczy po prostu wyświetlić dokument. Trzeba umieć odróżnić plik czytelny od pliku wiarygodnego. Trzeba zrozumieć, kiedy wystarczy szybka kontrola, a kiedy konieczne jest parsowanie, walidacja i normalizacja przed załadowaniem danych do Excela, systemu BI lub platformy analitycznej.
Jeśli szukasz praktycznego przewodnika po odczytywaniu plików XML, oto właściwa droga: zacznij od prostych metod, zrozum, gdzie pojawiają się problemy, a następnie stwórz proces, który przekształci surowy XML w dane przydatne dla biznesu. W ten sposób zmniejszysz liczbę błędów i skrócisz czas między momentem „mam plik” a „mam przydatną informację”.
Plik XML porządkuje dane w strukturze hierarchicznej. Zawiera element główny, sekcje zagnieżdżone, a każdy blok opisuje informację o konkretnym znaczeniu. Dla osób zajmujących się procesami administracyjnymi ten szczegół stanowi różnicę między danymi czytelnymi a danymi, które naprawdę można wykorzystać.
Nie chodzi o „otwarcie” pliku. Chodzi o to, by ustalić, czy plik ten może bezbłędnie zostać włączony do procesów kontroli, księgowości i analizy.
Weźmy na przykład fakturę elektroniczną. W tym samym pliku znajdują się jednocześnie dane dostawcy, dane klienta, kwoty podlegające opodatkowaniu, podatek VAT, pozycje towarowe, warunki płatności, numery zamówień, a często także wyjątki, które utrudniają odczytanie dokumentu. W formacie XML informacje te nie są umieszczone jedna pod drugą, jak w zwykłym arkuszu. Znajdują się one w ściśle określonych miejscach, a to właśnie położenie wyjaśnia, co one oznaczają.
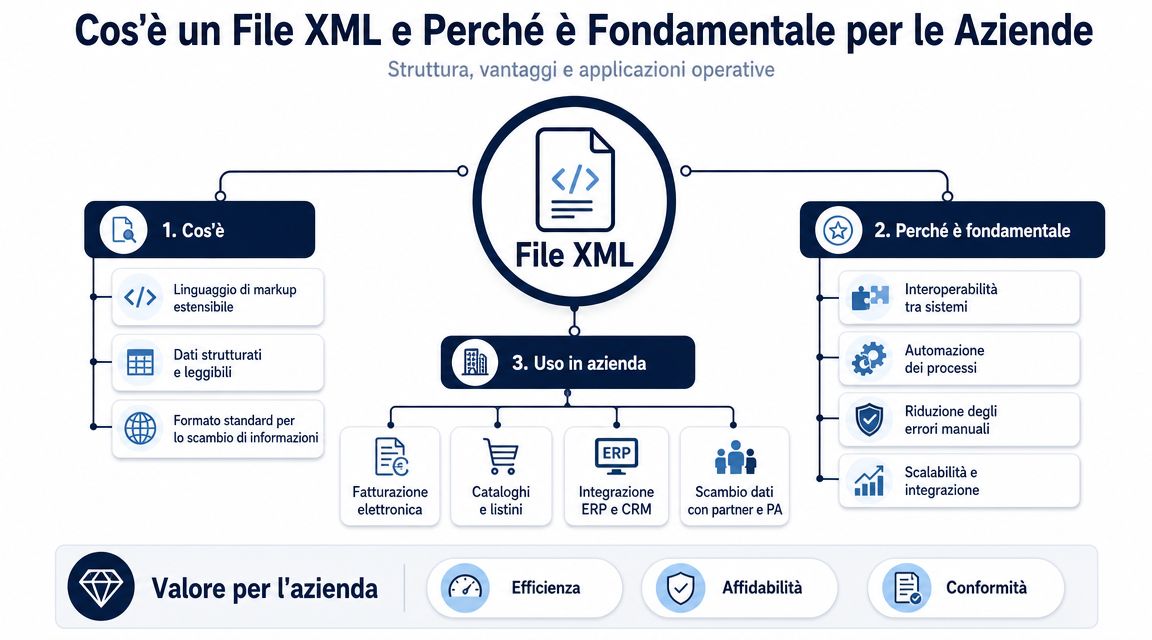
Dla menedżera istotne rozróżnienie nie dotyczy tagów i atrybutów w sensie teoretycznym. Chodzi o rozróżnienie między danymi wyizolowanymi a danymi wiarygodnymi. Odczytanie wartości „1000,00” poza kontekstem niewiele daje. Odczytanie jej we właściwym miejscu pliku pozwala zrozumieć, czy jest to suma dokumentu, podstawa opodatkowania, podatek, czy też wartość pojedynczego wiersza.
I tu pojawia się pierwsza zaleta operacyjna. XML zachowuje kontekst danych.
Zasada praktyczna: dokładne przeczytanie pliku XML oznacza sprawdzenie znaczenia wartości, a nie tylko samej wartości.
We Włoszech kwestia ta nabrała konkretnego wymiaru wraz z upowszechnieniem się faktur elektronicznych. W formacie FatturaPA język XML stał się standardem dla dokumentacji podatkowej. W związku z tym jego odczytywanie nie dotyczy już wyłącznie działu IT. Angażuje ono administrację, kontrolę zarządczą, dział zakupów oraz wszystkich, którzy muszą korzystać z tych danych w celu podejmowania decyzji.
W praktyce zawsze spotykam się z tym samym problemem. Plik istnieje, dane są dostępne, ale czas potrzebny na przekształcenie ich w użyteczną informację zbytnio się wydłuża. Pracownik otwiera plik XML, sprawdza go na oko, kopiuje wartości do Excela, koryguje niejednolite pola, zmienia nazwy dostawców zapisanych w różny sposób i próbuje odtworzyć kategorie wydatków, których plik nie przedstawia w formie gotowej do analizy. Koszt ten nie jest wyłącznie operacyjny. To stracony czas potrzebny na uzyskanie wniosków.
W przypadku FatturaPA ryzyko to jest jeszcze bardziej widoczne. Dwa pliki, które formalnie są poprawne, mogą powodować te same problemy analityczne, jeśli w jednym z nich zastosowano bardzo nieprecyzyjne opisy pozycji, jeśli numery zamówień są niekompletne lub jeśli dane katalogowe dostawcy zawierają różne warianty. W takiej sytuacji problemem nie jest odczytanie pliku XML. Problemem jest zapobieżenie sytuacji, w której prawidłowe dane podatkowe stają się mało wiarygodnymi danymi zarządczymi.
Częstym błędem jest traktowanie pliku XML jako załącznika przeznaczonego do wyświetlenia. W firmie lepiej jest traktować go jako ustrukturyzowane źródło danych, które należy sprawdzić przed wykorzystaniem w raportach, pulpitach analitycznych i modelach wydatków. Jeśli ten etap zostanie źle przeprowadzony, zespół finansowy będzie musiał zajmować się liczbami, które na pierwszy rzut oka wydają się dokładne, ale opierają się na niespójnych klasyfikacjach.
Na początku należy zadać sobie następujące pytania:
Są to bardzo konkretne kontrole. Służą one uniknięciu powielania dostawców w raportach, błędnej interpretacji podatku VAT, niekompletnego wypełniania centrów kosztów oraz powolnego uzgadniania danych pod koniec miesiąca.
Właśnie tutaj widać różnicę między analizą techniczną a wartością biznesową. Parser odczytuje plik. Dobrze zaprojektowany proces generuje czyste, porównywalne i gotowe do analizy dane. Platformy takie jak ELECTE powstały właśnie po to, by zniwelować tę lukę, ograniczając nakład pracy ręcznej niezbędny do przekształcenia otrzymanego pliku XML w przydatne informacje pozwalające na podejmowanie lepszych decyzji.
Do szybkiej weryfikacji pojedynczego pliku nie są potrzebne żadne parsery ani biblioteki. Trzeba jednak rozróżnić, czy przeprowadzasz wizualną weryfikację kilku pól, czy też masz już do czynienia z danymi, które trafią do księgowości, sprawozdawczości lub kontroli zarządczej. Ta różnica ma znaczenie, zwłaszcza w przypadku faktur FatturePA. Weryfikacja przeprowadzona dziś w pośpiechu może jutro przełożyć się na błędny wiersz w zbiorze danych dostawców.

Przeglądarki, edytory tekstu i dedykowane programy do przeglądania plików rozwiązują konkretny problem: umożliwiają szybkie zapoznanie się z treścią bez konieczności konfigurowania procesu technicznego. W przypadku pojedynczego pliku to często wystarcza. Możesz otworzyć plik XML w przeglądarce Chrome, Edge lub Firefox, aby zapoznać się z jego strukturą, albo skorzystać z Notatnika, WordPada lub TextEdit, jeśli chcesz bezpośrednio sprawdzić tagi. W przypadku faktur elektronicznych dedykowana przeglądarka ułatwia odczytanie nagłówków, pozycji dokumentu, kwoty podlegającej opodatkowaniu oraz podatku VAT.
Istota sprawy jest następująca:
| Narzędzie | Przydatne do | Główne ograniczenie |
|---|---|---|
| Przeglądarka | Szybka kontrola wzrokowa konstrukcji | Nie sprawdza spójności między polami a sekcjami |
| Edytor tekstu | Bezpośrednia kontrola znaczników | W przypadku długich lub zagnieżdżonych plików staje się to uciążliwe |
| Excel | Wstępna kontrola w formie tabelarycznej | Nie radzi sobie dobrze z hierarchiami i powtórzeniami |
| Specjalna przeglądarka | Lepsza czytelność faktur i dokumentów podatkowych | Nie przygotowuje danych do analizy ani automatyzacji |
Jeśli chcesz sprawdzić datę dokumentu, numer NIP, sumę faktury lub obecność załączników, te narzędzia są odpowiednie.
Jeśli natomiast celem jest porównanie dostawców, klasyfikacja wydatków lub zasilanie pulpitu nawigacyjnego, sama wizualizacja spowalnia pracę i stwarza zbyt duże pole do ręcznych błędów. Jest to klasyczna rozbieżność między przeglądaniem pliku a uzyskaniem wiarygodnych danych w odpowiednim czasie.
Otwarcie pliku XML nie oznacza sprawdzenia poprawności danych, które zostaną wykorzystane w raportach.
Kolejna kwestia praktyczna dotyczy ilości. Dziesięć plików da się sprawdzić nawet ręcznie. Setki faktur FatturePA – już nie. W takim przypadku warto już rozważyć wprowadzenie powtarzalnego procesu lub narzędzi, które odczytują treść w sposób ustrukturyzowany, na przykład za pośrednictwem API, umożliwiającego zintegrowane pozyskiwanie i zarządzanie dokumentami podatkowymi.
We Włoszech powracającym problemem nie jest otwarcie .xml, ale zrozumieć, co zrobić, gdy pojawi się .xml.p7m za pośrednictwem PEC. Należy rozróżnić proste pliki XML od plików podpisanych cyfrowo. W tym drugim przypadku potrzebne są narzędzia zdolne do odczytania podpisu, wyodrębnienia treści i wyświetlenia prawidłowego kodu XML, jak wyjaśnia niniejszy przewodnik poświęcony formatom XML i XML P7M w systemie PEC.
Tutaj błędy kosztują czas:
Dla pracownika administracyjnego najbardziej przydatna sekwencja jest prosta:
Metody te sprawdzają się dobrze na pierwszym etapie kontroli. Nie rozwiązują jednak problemu, który naprawdę stanowi obciążenie dla firmy: przekształcania dokumentów podatkowych w formacie XML, często nieprawidłowych lub niejednolitych, w czyste i porównywalne dane, bez wydłużania czasu, jaki upływa od otrzymania dokumentu do uzyskania użytecznej informacji.
Kiedy pliki zaczynają się gromadzić, ręczna praca przestaje być wykonalna. W takiej sytuacji odczytywanie plików XML za pomocą kodu nie jest eleganckim rozwiązaniem. To pierwszy krok w kierunku uniknięcia powtarzalnych czynności, błędów podczas kopiowania i niespójnych zbiorów danych.

Solidne podejście do odczytu plików XML zawsze opiera się na tej samej logice: parsowanie, normalizacja, ukierunkowane wyodrębnianie danych. W samouczakach dotyczących języka Java i platformy Android prawidłowy przebieg procesu wygląda następująco: parse(), poprzez normalizację drzewa za pomocą doc.getDocumentElement().normalize() a następnie z rekultywacji pól za pomocą getElementsByTagName, metoda bardziej stabilna niż zwykłe wyświetlanie w edytorze tekstowym, jak pokazuje ten poradnik techniczny dotyczący odczytu danych XML.
Ta sekwencja ma większe znaczenie niż wybrany język. Jeśli pominiesz normalizację, będziesz szukać węzłów w zbyt prosty sposób lub założysz, że tag pojawia się zawsze tylko raz, twój skrypt będzie działał na niektórych plikach, a zawiedzie właśnie na tych, które mają największe znaczenie.
W przypadku projektów, które muszą następnie współpracować z systemami zewnętrznymi, przydatne może być stworzenie powtarzalnego i udokumentowanego procesu pobierania danych. Jeśli zajmujesz się integracją aplikacji, pomocną podstawą jest dokumentacja dotycząca interfejsów API ELECTE wraz ze zweryfikowanym profilem Postman, zwłaszcza aby zrozumieć, w jaki sposób połączyć już oczyszczony zbiór danych z kolejnymi procesami.
Poniżej znajdziesz proste przykłady. Celem nie jest omówienie wszystkich przypadków, ale pokazanie podstawowej logiki: otwarcie pliku, znalezienie węzła, wyświetlenie wartości.
import xml.etree.ElementTree as ETtree = ET.parse("fattura.xml")root = tree.getroot()numero = root.find(".//Numero")if numero is not None:print(numero.text)Python jest często najszybszym rozwiązaniem w przypadku prototypów, przetwarzania danych i lekkich potoków przetwarzania. Doskonale sprawdza się, gdy trzeba odczytać wiele plików XML, wyodrębnić z nich kilka pól i zapisać je w formacie CSV lub JSON.
const xmlString = `<fattura><Numero>123</Numero></fattura>`;const parser = new DOMParser();const xmlDoc = parser.parseFromString(xmlString, "application/xml");const numero = xmlDoc.getElementsByTagName("Numero")[0];console.log(numero.textContent);Takie podejście sprawdza się w przypadku szybkich testów na stronie lub niewielkich narzędzi wewnętrznych. Nadaje się do prostych interfejsów, ale w mniejszym stopniu do ustrukturyzowanych procesów back-office.
const fs = require("fs");const xml2js = require("xml2js");const xml = fs.readFileSync("fattura.xml", "utf8");xml2js.parseString(xml, (err, result) => {if (err) throw err;console.log(result.fattura.Numero[0]);});Jeśli zajmujesz się programowaniem po stronie serwera i chcesz tworzyć automatyzacje, Node.js pozostaje praktycznym wyborem. Zaletą jest łatwa integracja odczytu plików XML z systemem plików, kolejkami przetwarzania i usługami wewnętrznymi.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse("fattura.xml");doc.getDocumentElement().normalize();NodeList lista = doc.getElementsByTagName("Numero");if (lista.getLength() > 0) {System.out.println(lista.item(0).getTextContent());}Java jest często wykorzystywana w środowiskach korporacyjnych, systemach zarządzania i oprogramowaniu pośredniczącym. W tym przypadku kluczową kwestią jest nie tylko odczytanie danych, ale także zrobienie tego w sposób przewidywalny i umożliwiający łatwą konserwację.
library(XML)doc <- xmlParse("fattura.xml")numero <- xpathSApply(doc, "//Numero", xmlValue)print(numero)R ma sens, gdy parsowanie stanowi część pracy analitycznej. Jeśli kolejnym krokiem jest analiza statystyczna lub przygotowanie danych, można wszystko przeprowadzić w tym samym środowisku.
Jeśli Twój zespół co tydzień otwiera te same pliki i powtarza te same czynności kontrolne, to znaczy, że już wkroczyłeś w obszar automatyzacji.
Prawdziwą korzyścią nie jest „odczytywanie plików XML za pomocą kodu”. Chodzi o to, by uwolnić ludzi od rutynowej pracy i stworzyć proces, który generuje spójne zbiory danych.
Poważne problemy zaczynają się, gdy plik nie jest już pojedynczym plikiem. Pojedyncza faktura FatturaPA jest prawie zawsze łatwa do opanowania. Trudności pojawiają się, gdy trzeba skonsolidować dokumenty z kilku miesięcy, od różnych dostawców, z niejednolicie wypełnionymi polami i załącznikami.
W włoskich MŚP najczęstszym przypadkiem nie jest pojedynczy „mega plik”, lecz partia plików. Roczny eksport faktur przychodzących może generować strukturę zawierającą ponad 380 000 węzłów w 4 200 fakturach, obejmującą nagłówki, wiersze szczegółowe, dane płatnicze i załączniki w formacie base64. W takich sytuacjach problemem nie jest otwarcie dokumentu, lecz przekształcenie heterogenicznych plików XML w spójny zbiór danych.
W tym miejscu pojawia się wybór techniczny, który ma wpływ na działalność biznesową. W środowisku .NET firma Microsoft wskazuje, że klasa XmlDocument ładuje dokument do pamięci i jest przydatna do odczytu oraz modyfikacji, natomiast w przypadku dużych plików lub operacji wyłącznie odczytowych warto skorzystać z bardziej wydajnych rozwiązań, takich jak parser strumieniowy lub klasa XPathDocument, aby uniknąć nadmiernego zużycia pamięci RAM, jak określono w dokumentacji firmy Microsoft dotyczącej odczytu XML za pomocą klas XmlDocument i XPathDocument.
W praktyce:
Kompromis jest prosty. Model przechowywany w pamięci pozwala na szybsze tworzenie aplikacji. Model strumieniowy lepiej sprawdza się w środowisku produkcyjnym, gdy plików jest dużo lub są one duże.
Wiele zespołów poprzestaje na walidacji XSD. Jest to przydatne, ale to za mało. Plik może być zgodny ze schematem, a mimo to generować błędne dane na dalszych etapach przetwarzania.
Typowe przykłady z pracy operacyjnej:
| Rodzaj kontroli | Co sprawdza | Po co to jest potrzebne |
|---|---|---|
| Konstrukcyjne | Tagi, format, hierarchia | Unikaj błędów analizy składniowej |
| Semantyczny | Spójność logiczna danych | Unikaj błędnych analiz |
| W trakcie realizacji | Obecność pól przydatnych do sporządzania raportów | Unikaj zbędnych zbiorów danych |
Najbardziej podstępny przypadek wygląda następująco: kwota całkowita dokumentu (ImportoTotaleDocumento) jest formalnie prawidłowa, ale nie zgadza się z sumą pozycji, na przykład z powodu zasad zaokrąglania stosowanych w systemie księgowym dostawcy. Albo kody VAT są formalnie dopuszczalne, ale nie odpowiadają charakterowi transakcji.
Nawet plik zgodny z wymogami formalnymi może jednak zafałszować Twoje raporty.
W systemie FatturaPA istnieje jeszcze jedna znana pułapka. Tag „DatiBeniServizi” zawiera opisy swobodne. Ten sam koszt może pojawiać się na wiele różnych sposobów – w postaci tekstów pełnych, skróconych lub niejasnych. Jeśli nie wprowadzisz etapu normalizacji, każda analiza według kategorii wydatków stanie się zawodna.
Dlatego w poważnych procesach odczyt pliku stanowi jedynie pierwszy poziom. Drugi poziom to zawsze zestaw reguł dotyczących spójności i czystości danych. To właśnie na tym poziomie zabezpiecza się jakość danych, a nie w parserze.
Prawidłowo odczytany plik XML nie jest jeszcze użytecznym zbiorem danych. Jest to dokument o ustalonej strukturze. Aby przeprowadzać analizy, porównania, grupowanie danych i tworzyć pulpity nawigacyjne, prawie zawsze trzeba przekształcić go do formatu, który łatwiej przetwarzać.
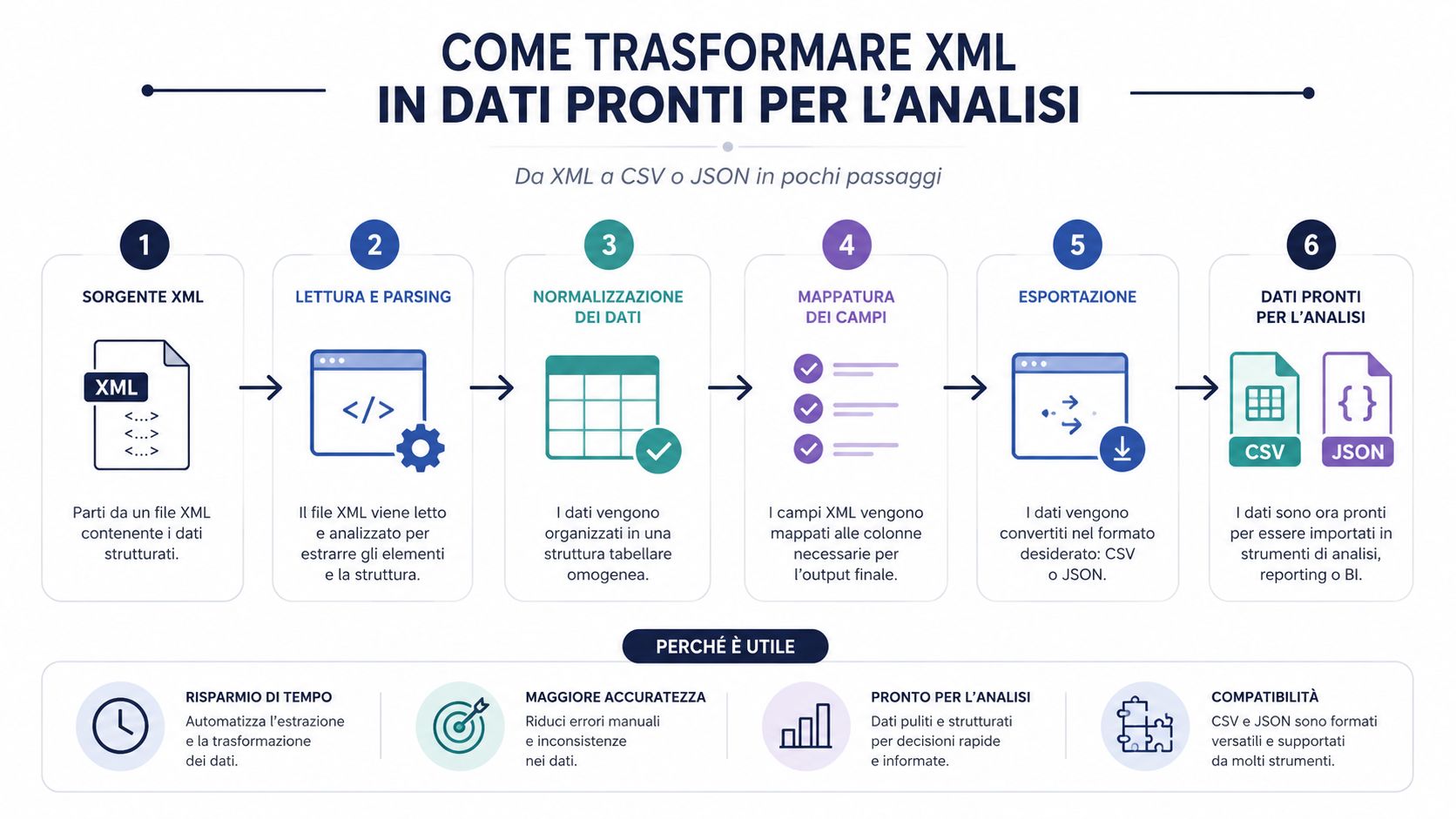
To właśnie ten aspekt jest często niedoceniany w wielu procesach. Wąskim gardłem rzadko jest samo parsowanie. Dobra biblioteka szybko odczytuje plik XML. Czas traci się na interpretację struktury, wyodrębnianie przydatnych pól, czyszczenie danych, normalizację oraz wgrywanie do narzędzia analitycznego.
Dlatego konwersja do formatu CSV lub JSON nie jest tylko udogodnieniem. To kluczowy etap pracy. Jeśli pominiesz ten etap i będziesz pracować bezpośrednio na surowym pliku, prawie zawsze skończysz na ręcznych sprawdzaniach, improwizowanych kolumnach i logice trudnej do odtworzenia.
Przydatnym źródłem informacji dla osób, które często pracują zarówno z plikami XML, jak i arkuszami kalkulacyjnymi, jest ten przewodnik dotyczący tego, jak w bardziej uporządkowany sposób przenosić dane z XML do programu Excel.
Wybór odpowiedniego formatu zależy od tego, w jaki sposób będziesz później wykorzystywać te dane.
CSV sprawdza się dobrze, gdy potrzebujesz jednego wiersza na dokument lub jednego wiersza na pozycję faktury, a następnie chcesz korzystać z programu Excel, Power Query lub narzędzi BI.
Przykład w języku Python:
import xml.etree.ElementTree as ETimport csvtree = ET.parse("fattura.xml")root = tree.getroot()with open("fatture.csv", "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(["numero", "data"])numero = root.findtext(".//Numero")data = root.findtext(".//Data")writer.writerow([numero, data])Zaletą jest prostota. Ograniczeniem jest to, że trzeba dobrze przemyśleć, w jaki sposób spłaszczyć hierarchię. Jeśli faktura zawiera wiele pozycji szczegółowych, konieczne jest jasne określenie poziomu szczegółowości i klucza powiązania.
JSON najlepiej sprawdza się, gdy chcesz zachować część struktury hierarchicznej.
Przykład kodu JavaScript:
const record = {numero: "123",data: "2024-01-15",righe: [{ descrizione: "Servizio", importo: "100.00" }]};console.log(JSON.stringify(record, null, 2));Użyj tego, gdy następnym krokiem jest API, jezioro danych lub aplikacja, która dobrze radzi sobie z obiektami zagnieżdżonymi.
Oto pomocna zasada praktyczna:
Plik XML pełni rolę kontenera. Formaty CSV i JSON sprawiają, że zawartość jest rzeczywiście przydatna do dalszej obróbki.
Jeśli chcesz skrócić czas potrzebny do uzyskania wniosków, właśnie w tym warto zainwestować. Nie w znalezienie wygodniejszego narzędzia do wizualizacji, ale w zdefiniowanie stabilnej i powtarzalnej transformacji.
Gdy plik zostanie odczytany, zweryfikowany i przetworzony, charakter pracy ulega zmianie. Nie zmagasz się już z tagami. W końcu zaczynasz analizować koszty, nieprawidłowości, dostawców, kategorie wydatków i trendy operacyjne.
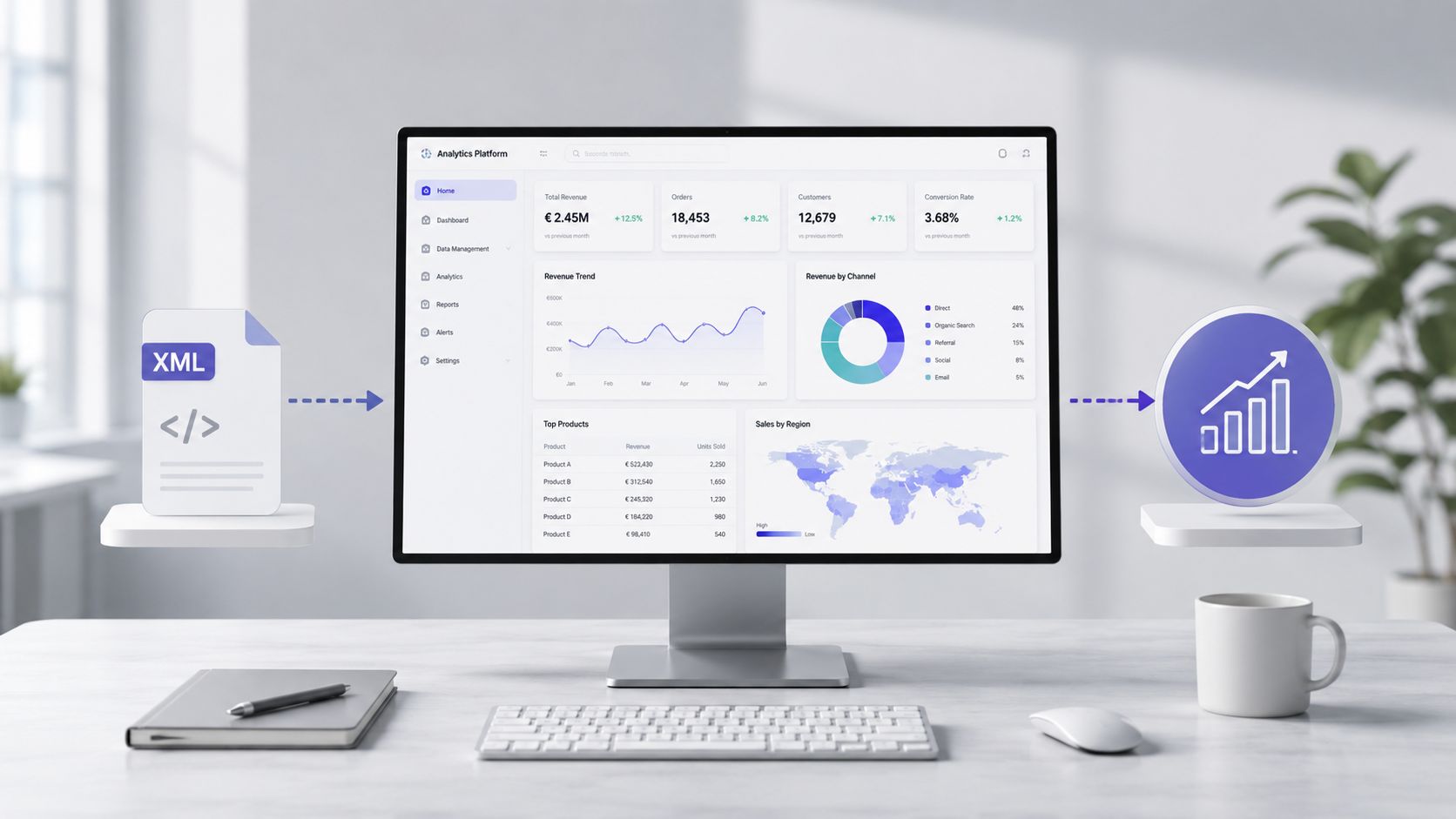
W praktyce wartość nie leży w czasie potrzebnym na parsowanie. Leży ona w czasie, jaki upływa od momentu otrzymania surowego pliku do uzyskania informacji, na podstawie której można podjąć decyzję. W przypadku ręcznego przetwarzania dana osoba musi otworzyć dokument, zrozumieć jego strukturę, wyodrębnić pola, oczyścić wartości, znormalizować teksty, a następnie sporządzić raporty. Jest to proces podatny na błędy.
Klasycznym przykładem w systemie FatturaPA jest pole tekstowe w sekcji „DatiBeniServizi”. Ta sama usługa może być opisana na wiele różnych sposobów przez różnych dostawców. Jeśli zaimportujesz te dane bez spójnego mapowania, analiza według kategorii kosztów doprowadzi do powstania zbędnych agregacji.
Z tego powodu przed wdrożeniem platformy analitycznej konieczne jest przygotowanie danych:
Gdy ten etap zostanie przeprowadzony prawidłowo, każda platforma analityczna działa lepiej. Jeśli chcesz zgłębić aspekt decyzyjny i wizualny tego etapu, przydatnym źródłem informacji jest materia ł poświęcony tworzeniu historii na podstawie danych, ponieważ pokazuje on, w jaki sposób uporządkowany zbiór danych staje się narracją przydatną dla decydentów.
W tym momencie plik XML przestaje być problemem technicznym i staje się surowcem do uzyskania wniosków. Dobrze przygotowany zbiór danych może służyć do analizy wydatków, monitorowania trendów, wykrywania odchyleń i identyfikacji wyjątków.
Aby wybrać platformę odpowiednią do obsługi tego ostatniego etapu, warto porównać możliwości nowoczesnego oprogramowania do analizy biznesowej z czysto ręcznymi procesami opartymi na arkuszach kalkulacyjnych i tabelach przestawnych.
W tym przypadku właściwym kryterium nie jest pytanie: „Czy potrafi otworzyć plik XML?”. To tylko minimum. Istotne pytanie brzmi inaczej:
| Pytanie | Dlaczego to ma znaczenie |
|---|---|
| Dane są już w czystej postaci | Unikaj wyciągania konkretnych wniosków na podstawie błędnych danych |
| Kategorie są spójne | Czy naprawdę porównujesz dostawców i okresy? |
| Anomalie ujawniają się od razu | Ogranicz czas poświęcany na ręczne kontrole |
| Raport jest zrozumiały dla działów biznesowych i finansowych | Przyspiesz proces podejmowania decyzji |
Różnica między procesem niedojrzałym a dojrzałym nie polega na umiejętności odczytywania plików XML. Polega ona na zdolności do przekształcania ich w niezawodną bazę danych, która nie zmusza zespołu do powtarzania za każdym razem tej samej pracy.
Jeśli chcesz odczytywać pliki XML w sposób przydatny dla firmy, pamiętaj o tej liście kontrolnej. Jest ona bardziej konkretna niż jakakolwiek definicja techniczna i pomoże Ci wybrać właściwą metodę bez straty czasu.
Nie stosuj zawsze tego samego podejścia. Przeglądarki, edytory i narzędzia do wyświetlania nadają się do szybkiej kontroli. Parsery i skrypty są potrzebne, gdy plik ma zasilać powtarzające się procesy. Jeśli pomylisz wyświetlanie z przetwarzaniem danych, ryzykujesz tworzenie raportów opartych na kruchych podstawach.
Pliki .xml.p7m wymagają specjalnego etapu obsługi podpisu. Jeśli treść pochodzi z adresu PEC, kontrola ta nie ma charakteru dodatkowego. Stanowi ona część prawidłowego odczytu dokumentu.
Przestrzeganie schematu nie gwarantuje poprawności zbioru danych. To właśnie niespójności logiczne, takie jak niezgodne sumy lub niejednoznaczne klasyfikacje podatkowe, najczęściej psują analizę. Kontrola semantyczna stanowi o różnicy między plikiem „akceptowalnym” a danymi wiarygodnymi.
CSV i JSON to nie tylko kosmetyczna zmiana. To właśnie dzięki nim XML staje się formatem, z którym mogą pracować narzędzia analityczne, arkusze kalkulacyjne, potoki danych i raporty. Im wcześniej zdefiniujesz tę transformację, tym szybciej ograniczysz ręczną pracę i improwizację.
Twoim celem nie jest odczytywanie plików XML. Chodzi o uzyskanie przydatnych wniosków bez zanieczyszczania systemu nieprawidłowymi danymi. Jeśli strumień danych nie generuje spójnego zbioru danych, problem nie leży w końcowym panelu kontrolnym. Leży on znacznie wcześniej w procesie.
W praktyce możesz skorzystać z tej mini-listy kontrolnej przed rozpoczęciem każdego nowego projektu:
Jeśli chcesz przekształcić już przygotowane dane w jasne i przydatne wnioski, ELECTE pomaga małym i średnim przedsiębiorstwom przejść od uporządkowanego zbioru danych do inteligentnego raportowania, stosując podejście przystępne nawet dla zespołów nietechnicznych. To najszybszy sposób na skrócenie dystansu między danymi operacyjnymi a procesem podejmowania decyzji.

.svg)
.svg)
.svg)
.webp)





