

Twoje dane już opowiadają pewną historię. Problem polega na tym, że często mówią zbyt cicho.
Każdego dnia małe i średnie przedsiębiorstwo gromadzi opinie klientów, zamówienia, zgłoszenia serwisowe, transakcje finansowe, e-maile handlowe oraz notatki w systemie CRM. Wszystkie te dane zawierają przydatne sygnały. Niektóre wskazują na klienta, który może wkrótce odejść. Inne sygnalizują ryzyko operacyjne. Jeszcze inne pokazują, które produkty zyskują na popularności, a które tracą. Bez jasnej metody te sygnały pozostają jednak jedynie szumem.
Wśród algorytmów, które pomagają zaprowadzić porządek w tym chaosie, szczególne miejsce zajmują klasyfikatory bayesowskie typu naive. Są one łatwe do zrozumienia pod względem logicznym, szybkie w uczeniu i często skuteczniejsze, niż sugeruje nazwa „naive”. Nie są one idealnym rozwiązaniem w każdym przypadku, ale w wielu rzeczywistych problemach biznesowych zapewniają rzadką równowagę między szybkością, interpretowalnością a użytecznymi wynikami.
Jeśli pracujesz w biznesie, nie musisz zostawać naukowcem, żeby je zrozumieć. Musisz wiedzieć, jak działają, dlaczego sprawdzają się nawet wtedy, gdy znacznie upraszczają rzeczywistość, oraz w jakich sytuacjach mogą pomóc ci podejmować lepsze decyzje. Właśnie na tym warto się zatrzymać.
Wiele firm poszukuje skomplikowanych modeli, podczas gdy problem wymaga przede wszystkim modelu niezawodnego i łatwego w użyciu. Z tego samego powodu w finansach, handlu detalicznym czy obsłudze klienta często wygrywa proces bardziej przejrzysty, a nie ten najbardziej elegancki z teoretycznego punktu widzenia.
Klasyfikatory bayesowskie typu naive opierają się na bardzo konkretnej zasadzie. Jeśli znasz pewne wskazówki dotyczące nowego przypadku, możesz z dużym prawdopodobieństwem oszacować, do której kategorii on należy. Jeśli wiadomość e-mail zawiera określone słowa, może to być spam. Jeśli transakcja wykazuje określone wzorce, może wymagać sprawdzenia. Jeśli recenzja zawiera określone sformułowania, może to wskazywać na zadowolenie lub niezadowolenie.
Słowo „bayesowski” kojarzy się ze skomplikowanymi wzorami. W rzeczywistości sedno tej metody jest intuicyjne. Bierzesz to, co już wiesz, dodajesz nowe dowody i aktualizujesz swoją ocenę. To uporządkowany sposób rozumowania w warunkach niepewności – dokładnie to, co menedżerowie robią na co dzień, tyle że usystematyzowane przez algorytm.
Zaskakujące jest to, że podejście to nadal sprawdza się dobrze nawet w nowoczesnych środowiskach, charakteryzujących się ogromną ilością danych i koniecznością podejmowania szybkich decyzji. Nie dlatego, że idealnie opisuje świat, ale dlatego, że pozwala oddzielić użyteczny sygnał od szumu przy bardzo niskich kosztach obliczeniowych.
W przypadku problemów biznesowych właściwe pytanie nie brzmi: „Który model jest najbardziej dopracowany?”. Brzmi ono raczej: „Który model pozwala mi podejmować wiarygodne decyzje w czasie, który jest zgodny z realiami pracy?”.
Dlatego klasyfikatory bayesowskie typu naive nadal odgrywają ważną rolę. Pomagają one w klasyfikowaniu, filtrowaniu, segmentacji i ustalaniu priorytetów. Pozwalają też uwzględnić prawdopodobieństwo w procesie podejmowania decyzji, nie zamieniając przy tym każdego projektu w techniczną budowle.
Podstawą jest twierdzenie Bayesa. W uproszczeniu mówi ono, że zaczyna się od początkowego prawdopodobieństwa, a następnie aktualizuje się je w miarę napływania nowych informacji.
W języku statystyki wzór ten wygląda następująco: P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y). Oznacza to, że prawdopodobieństwo przynależności do danej klasy, biorąc pod uwagę zbiór sygnałów, zależy od dwóch czynników. Pierwszym z nich jest początkowe prawdopodobieństwo przynależności do tej klasy. Drugim jest stopień, w jakim każdy sygnał jest zgodny z tą klasą.
Przełożone na przykład biznesowy. Musisz ustalić, czy dana wiadomość e-mail jest spamem, czy nie. Masz ogólne prawdopodobieństwo, że przychodząca wiadomość to spam. Następnie zwracasz uwagę na takie słowa jak „oferta”, „za darmo”, „kliknij tutaj”. Każde z tych słów wpływa na ostateczną ocenę.
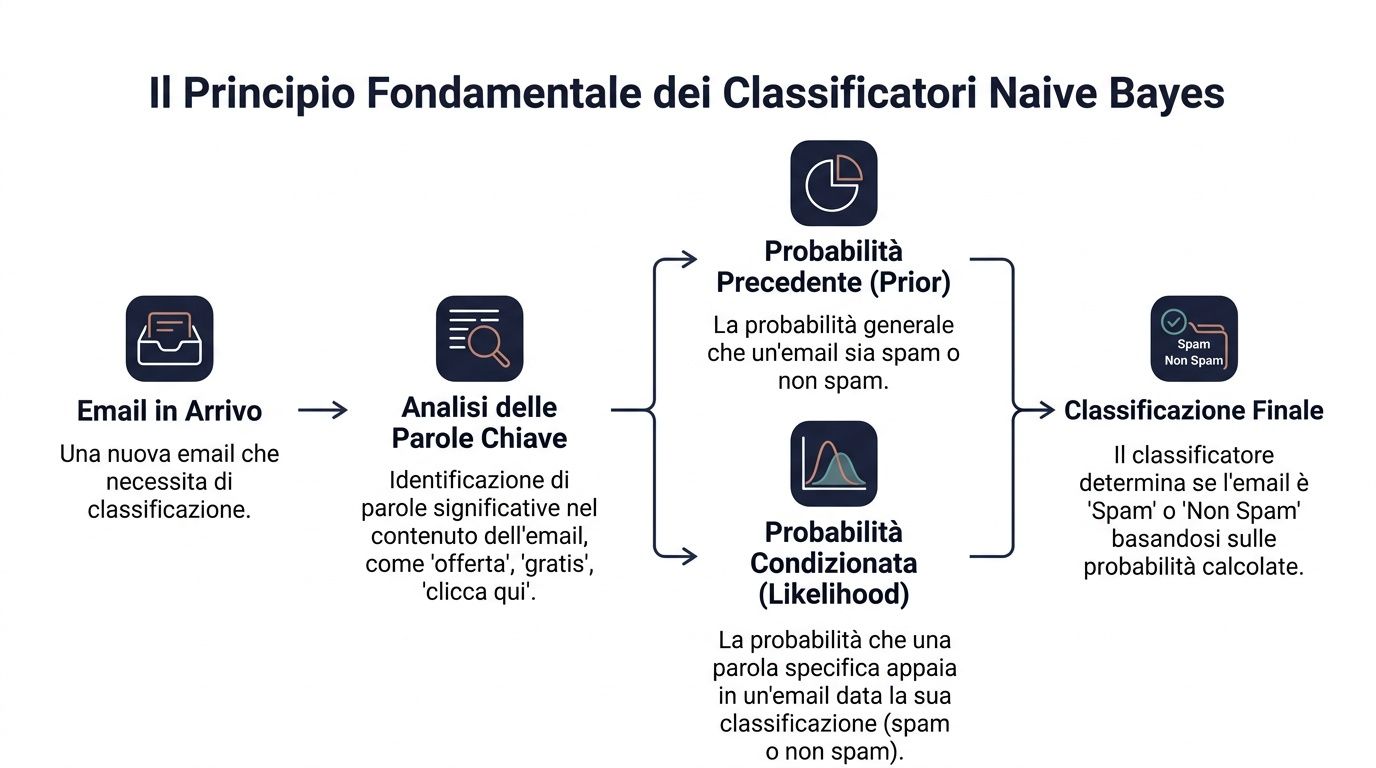
Menedżer robi coś podobnego każdego dnia. Nigdy nie podejmuje decyzji w próżni. Wychodzi od podstawowego kontekstu i dodaje do niego kolejne wskazówki. Klient, który zawsze regularnie dokonywał zakupów, ma pewien wstępny profil. Jeśli jednak przestaje otwierać e-maile, zmniejsza wartość zamówień i zgłasza poważny problem, twoja ocena ulega zmianie.
Termin „naiwny” odnosi się do konkretnego założenia. Model traktuje cechy tak, jakby były od siebie niezależne, ponieważ klasa jest znana.
W praktyce, klasyfikując wiadomość e-mail, traktuj każde słowo jako osobną wskazówkę. Nie próbuj odzwierciedlać wszystkich złożonych powiązań między terminami. To znaczne uproszczenie. W rzeczywistości wiele słów pojawia się razem, a wiele zachowań biznesowych jest ze sobą powiązanych.
Jednak właśnie ten wybór sprawia, że model jest bardzo lekki. Nie musi on uczyć się skomplikowanej sieci zależności. Musi jedynie szacować prostsze prawdopodobieństwa i efektywnie je łączyć.
Zasada praktyczna: Naive Bayes non cerca di ricostruire l’intero mondo. Cerca di prendere decisioni utili con poche assunzioni e molta velocità.
Właśnie tu często pojawia się nieporozumienie. Wielu, czytając „naiwne założenie”, wyciąga wniosek, że mamy do czynienia z „słabym modelem”. Tak jednak nie jest. Model może znacznie upraszczać rzeczywistość i pozostawać konkurencyjny, o ile to uproszczenie oddaje to, co ma znaczenie dla procesu decyzyjnego.
W 2004 roku analiza teoretyczna wykazała solidne podstawy skuteczności klasyfikatorów Naive Bayes pomimo założenia o niezależności, wyjaśniając również, dlaczego mogą one osiągnąć błąd asymptotyczny szybciej niż regresja logistyczna. W tym samym obszarze zastosowań, w filtrowaniu spamu osiągają one dokładność przekraczającą 99% i skalują się na miliony dokumentów, jak opisano w artykule poświęconym klasyfikatorom Naive Bayes.
Ta kwestia jest istotna dla odbiorców z sektora biznesowego. Wartość algorytmu nie polega wyłącznie na końcowym wyniku. Polega ona również na zdolności do szybkiego uczenia się, dostosowywania się do obszernych zbiorów danych oraz zachowania interpretowalności.
Gdy mamy do czynienia z rozproszonymi tekstami, kategoriami, tagami lub sygnałami, klasyfikatory bayesowskie typu naive sprawdzają się dobrze, ponieważ:
Należy jednak pamiętać o dwóch kwestiach.
Z tego powodu algorytm Naive Bayes należy traktować jako bardzo skuteczne narzędzie do szybkiej klasyfikacji, a nie jako uniwersalną magiczną różdżkę. W wielu praktycznych sytuacjach jest to jednak jeden z najrozsądniejszych sposobów na rozpoczęcie pracy.
Częstym błędem jest mówienie o modelu Naive Bayes tak, jakby był to jeden i ten sam model w każdej sytuacji. W rzeczywistości istnieją różne jego odmiany, przeznaczone do różnych typów danych.
Właściwy wybór zależy od postaci danych, którymi dysponujesz. Jeśli wybierzesz niewłaściwą wersję, model nadal może wygenerować prognozę, ale nie będzie działał w sposób najlepiej dostosowany do twojego problemu.
Model Gaussian Naive Bayes najlepiej sprawdza się w przypadku cech ciągłych. Weźmy na przykład średnią kwotę transakcji, wiek klienta, średni czas między dwoma zakupami, marżę jednostkową lub wartość paragonu.
W tym modelu zakłada się, że w obrębie każdej klasy wartości mają rozkład Gaussa. Nie należy tego traktować jako akademickiego ograniczenia. Wystarczy pamiętać o praktycznej zasadzie: dla każdej klasy model szacuje typową wartość środkową i rozrzut.
Takie podejście sprawdza się, gdy chcesz sklasyfikować takie przypadki, jak:
W teście porównawczym scikit-learn z wykorzystaniem zbioru danych podobnego do włoskich danych e-commerce model Naive Bayes osiągnął 95% dokładności na 1000 próbkach, a czas szkolenia był o 15% krótszy niż w przypadku regresji logistycznej . Wskazane porównanie to 0,01 s vs 0,1 s na standardowym procesorze, dzięki uczeniu w trybie zamkniętym, jak pokazano w rozdziale Jake'a VanderPlasa pt. „In Depth Naive Bayes Classification”.
Dla firmy nie chodzi o przecinek. Chodzi o to, że ta wersja może zapewnić dobre wyniki bez długiego okresu szkolenia i bez rozbudowanej infrastruktury.
Jeśli pracujesz z tekstami, zgłoszeniami, recenzjami lub komentarzami, model Multinomial Naive Bayes jest często naturalnym wyborem. W tym przypadku cechami są liczby lub częstotliwości. W praktyce model sprawdza, ile razy pojawiają się poszczególne słowa lub terminy.
To klasyczny scenariusz:
Powód, dla którego ta metoda działa dobrze, jest bardzo konkretny. W tekstach biznesowych słownictwo może być bogate, ale każdy dokument zawiera tylko niewielką część możliwych słów. Dane są rozproszone. Model Multinomial Naive Bayes dobrze radzi sobie właśnie z tego typu strukturą.
W badaniu obejmującym 100 000 włoskich tweetów oznaczonych pod kątem nastroju model Multinomial Naive Bayes osiągnął wynik F1 wynoszący 0,88, wykazując 10-krotne przyspieszenie w porównaniu z SVM, jak podano w przewodniku GeeksforGeeks dotyczącym klasyfikatorów Naive Bayes.
Aby łatwiej to zapamiętać, pomyśl o tym w ten sposób: jeśli twoje dane przypominają dokument pełen policzonych słów, wielomian jest prawie zawsze pierwszym rozwiązaniem, które warto wypróbować.
Jeśli Twoja firma musi analizować duże ilości tekstu, pytanie nie brzmi tylko: „Jak dokładny jest ten model?”. Chodzi również o to, „ile zapytań jest w stanie sklasyfikować bez spowalniania pracy zespołu?”.
Algorytm Bernoulli Naive Bayes wykorzystuje cechy binarne. Nie bierze pod uwagę, ile razy pojawia się dany sygnał. Liczy się tylko to, czy występuje, czy nie.
Ta opcja jest przydatna, gdy znaczenie danego atrybutu jest ważniejsze niż jego częstotliwość. Oto kilka przykładów z życia firmy:
Jest to bardzo przydatna zasada, gdy chcesz przekształcić złożone zjawiska w łatwe do monitorowania wskaźniki typu „tak/nie”. Na przykład w analizie nastrojów ważniejsze może być samo pojawienie się negatywnego słowa, a nie to, ile razy się powtarza.
Rozkład Bernoulliego nie jest „mniej zaawansowany” niż rozkład wielomianowy. Po prostu lepiej sprawdza się w sytuacjach, gdy dane dotyczą obecności lub braku. Różnica ta jest niewielka w teorii, ale ma ogromny wpływ na wyniki.
| Wariant | Idealny typ danych | Przykład zastosowania w biznesie |
|---|---|---|
| Gaussowski algorytm Naiwnego Bayesa | Dane ciągłe | Klasyfikowanie transakcji pod względem ryzyka na podstawie kwot, częstotliwości i wartości średnich |
| Wielomianowy algorytm Naive Bayes | Teksty, obliczenia, częstotliwości | Analizować recenzje i zgłoszenia klientów pod kątem nastroju lub kategorii |
| Bernoulliego, Naive Bayes | Dane binarne, obecność/nieobecność | Ocena sygnałów „tak/nie” w zakresie zgodności, wsparcia lub wykorzystania produktu |
Aby dokonać dobrego wyboru, kieruj się prostą zasadą:
Wiele zespołów utknęło w martwym punkcie, ponieważ poszukują absolutnie „najlepszego” modelu. Prawidłowym wyborem jest prawie zawsze model najlepiej dostosowany do rodzaju danych.
Dobrą wiadomością jest to, że wdrożenie algorytmu Naive Bayes w praktyce nie wymaga realizacji wielkiego projektu. Nawet prosty prototyp pozwala już zrozumieć, w jaki sposób działa ten model i jakich danych potrzebuje.

Klasyfikator powstaje prawie zawsze w czterech etapach.
Przygotowanie danych
Musisz zebrać historyczne przykłady, które zostały już opatrzone etykietami. Jeśli klasyfikujesz recenzje, potrzebujesz tekstów oznaczonych jako pozytywne lub negatywne. Jeśli analizujesz ryzyko operacyjne, potrzebujesz przypadków z przeszłości o znanym wyniku.
Trening modelu typu „
” Model analizuje dane i szacuje odpowiednie prawdopodobieństwa. W przypadku klasyfikatorów typu „naive bayesian” ten etap przebiega szybko, ponieważ trening nie wymaga szczególnie skomplikowanych optymalizacji.
Prognoza dotycząca nowych przypadków
Wprowadź nowe rekordy, a model przypisze im kategorię. Na przykład „spam”, „nie spam”, „klient z grupy ryzyka”, „klient stabilny”.
Ocena modelu „
” – porównaj prognozy z rzeczywistymi wynikami na oddzielnym zbiorze testowym. Nie chodzi tu tylko o to, czy model działa. Chodzi o to, w jaki sposób popełnia błędy.
Jeśli chcesz lepiej poznać ogólny zarys metod predykcyjnych, ten przegląd algorytmów uczenia maszynowego pomoże Ci umieścić algorytm Naive Bayes w szerszym kontekście różnych metod.
Aby lepiej zrozumieć ten proces, oto prosty przykład z wykorzystaniem biblioteki scikit-learn. Nie musisz go analizować jak programista. Wystarczy, że zrozumiesz przebieg procesu.
# Importujemy główne narzędziafrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# Ładujemy przykładowy zbiór danychX, y = load_iris(return_X_y=True)# Podzielmy dane na część do szkolenia i część do testowania X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Tworzymy modelmodel = GaussianNB()# Trenujemy model na danych historycznymodel.fit(X_train, y_train)# Tworzymy prognozy dla danych, których wcześniej nie widzieliy_pred = model.predict(X_test)# Mierzymy dokładnośćprint(accuracy_score(y_test, y_pred))Ten fragment mówi o wiele więcej, niż się wydaje.
GaussianNB() wybierz opcję dla danych ciągłych.fit() to moment, w którym model się uczy.predict() wykorzystuje zdobytą wiedzę.accuracy_score() sprawdź, ile klasyfikacji jest ogólnie poprawnych.W przypadku danych tekstowych proces przebiega podobnie, ale przed zastosowaniem modelu należy przekształcić tekst na liczby. W praktyce oznacza to przekształcenie słów na cechy, które mogą być wykorzystane przez klasyfikator.
Po pierwszym zapoznaniu się z kodem warto zapoznać się z wizualnym wyjaśnieniem tego mechanizmu.
Pierwszy model nie ma na celu wykazania doskonałości. Służy on udzielenie odpowiedzi na trzy pytania praktyczne.
W tym miejscu widać siłę algorytmu Naive Bayes. Można szybko uzyskać solidną podstawę. Na tej podstawie można ocenić, czy warto komplikować projekt, czy też proste rozwiązanie już przynosi korzyści.
Model klasyfikacji nie ocenia się wyłącznie na podstawie tego, że „wydaje się działać”. Ocenia się go na podstawie tego, jak popełnia błędy i jak bardzo te błędy wpływają na działalność firmy.

Dokładność to najbardziej intuicyjny wskaźnik. Pokazuje, ile prognoz jest trafnych w stosunku do całości. Jest przydatna, ale sama w sobie może wprowadzać w błąd.
Jeśli spośród stu transakcji tylko kilka jest rzeczywiście podejrzanych, model, który klasyfikuje prawie wszystko jako normalne, może wydawać się dobry pod względem dokładności, ale jednocześnie pozostawać niewystarczający tam, gdzie jest to naprawdę potrzebne.
Aby to zrozumieć, wyobraź sobie sieć rybacką.
W biznesie to rozróżnienie ma ogromne znaczenie.
Dobry model to nie taki, który generalnie rzadko popełnia błędy. To taki, który popełnia błędy w sposób najmniej kosztowny dla Twojego procesu.
Aby lepiej zrozumieć, w jaki sposób algorytm uczy się na podstawie danych historycznych oraz dlaczego jakość szkolenia wpływa na wynik końcowy, zapoznaj się z tym artykułem wyjaśniającym, na czym polega szkolenie algorytmu.
Algorytm Naive Bayes jest prosty, ale nie wybacza niektórych błędów praktycznych.
Pierwszy błąd: pomijanie problemu częstotliwości zerowej.
Jeśli dane słowo lub wartość nigdy nie pojawia się w danych szkoleniowych dla danej klasy, prawdopodobieństwo może spaść do zera i zakłócić obliczenia. Z tego powodu często stosuje się wygładzanie Laplace’a, które dodaje niewielką korektę do wyników.
Błąd nr 2: stosowanie silnie skorelowanych zmiennych.
Jeśli dwie kolumny zawierają niemal identyczne informacje, model może przeszacować sygnał. Nie „rozumie” on, że te dwie wskazówki są niemal identyczne.
Trzeci błąd: zbytnie poleganie na surowych prawdopodobieństwach.
Algorytm Naive Bayes często zapewnia dobre wyniki klasyfikacji, ale jego prawdopodobieństwa mogą być zbyt pewne. Z biznesowego punktu widzenia oznacza to, że ranking może być przydatny, natomiast dokładną wartość prawdopodobieństwa należy interpretować z ostrożnością.
Aby ograniczyć te zagrożenia, warto:
Prawdziwa wartość klasyfikatorów bayesowskich typu naive ujawnia się, gdy przestaje się traktować je jako ćwiczenie matematyczne, a zaczyna wykorzystywać jako narzędzie do ustalania priorytetów. W biznesie trafna klasyfikacja prawie zawsze oznacza lepsze podejmowanie decyzji.

Wyobraź sobie zespół finansowy, który analizuje przepływy transakcji, opisy operacyjne i dane historyczne. Każdy wiersz to nie tylko wpis. To potencjalna decyzja: przepuścić, zbadać dokładniej, zablokować lub przekazać analitykowi.
Dzięki algorytmowi Naive Bayes można łączyć różne wskaźniki w ramach jednej klasyfikacji. Niektóre z nich mają charakter liczbowy, inne binarny, a jeszcze inne tekstowy. Model pomaga ustalić, które przypadki najbardziej przypominają już zaobserwowane wzorce uznane za normalne lub nietypowe.
Korzyść praktyczna jest dwojaka:
Nie zastępuje ludzkiej oceny w sytuacjach podlegających regulacjom. Pomaga ją uporządkować. A w procesach operacyjnych o dużej skali ma to realne znaczenie.
W marketingu klasyfikacja często oznacza przypisanie każdego klienta do określonej grupy. Lojalni. Wrażliwi na cenę. Zagrożeni odejściem. Reagujący na promocje. Uśpieni.
W tym przypadku metoda Naive Bayes jest przydatna, ponieważ pozwala szybko połączyć różnorodne sygnały:
Zespół CRM nie potrzebuje doskonałej teorii ludzkich zachowań. Potrzebuje segmentacji na tyle dobrej, by umożliwić podjęcie sensownych działań. Na przykład zmianę treści wiadomości, częstotliwości kontaktów lub rodzaju oferty.
Kiedy model pomaga wybrać kolejną wiadomość dla odpowiedniego klienta, już wtedy tworzy wartość operacyjną.
W handlu detalicznym i handlu elektronicznym klasyfikacja wspiera działania, które na pierwszy rzut oka wydają się różne, ale opierają się na tej samej logice: porządkowaniu chaosu.
Możesz klasyfikować produkty na podstawie ich wyników sprzedaży. Możesz przeglądać recenzje i zgłoszenia, aby zorientować się, które kategorie powodują problemy. Możesz dostrzec wzorce popytu, które pomogą zespołowi w bardziej przemyślanym planowaniu promocji i zapasów.
W tego typu środowisku dane są często obszerne, zróżnicowane i nie zawsze idealne. Dlatego też szybki, skalowalny i przejrzysty model ma ogromną wartość. Nie dlatego, że jest najbardziej efektowny, ale dlatego, że wpisuje się w przebieg pracy, nie spowalniając go.
Jeśli chcesz zobaczyć, jak podejścia analityczne stosowane w biznesie przekładają się na konkretne projekty, zapoznaj się z poniższymi studiami przypadków.
Zrozumienie algorytmu Naive Bayes jest przydatne. Jednak jego skuteczne wdrożenie w środowisku biznesowym to już zupełnie inna sprawa.
Problem prawie nigdy nie dotyczy wyłącznie algorytmu. Prawdziwa praca skupia się na modelu. Trzeba połączyć różne źródła danych, poradzić sobie z brakującymi polami, przygotować teksty, zaktualizować etykiety, sprawdzić jakość wyników oraz przedstawić je w sposób zrozumiały dla decydentów.
Dla małych i średnich przedsiębiorstw ten etap jest często punktem krytycznym. Nie dlatego, że brakuje im zainteresowania sztuczną inteligencją, ale dlatego, że czas zespołu jest ograniczony, a priorytety operacyjne nie mogą czekać.
W tym przypadku warto skorzystać z platformy, która przejmuje na siebie techniczne zawiłości. Rozwiązanie oparte na sztucznej inteligencji pozwala przekształcić surowe dane w zrozumiałe wnioski, bez konieczności pisania kodu, wybierania bibliotek czy ręcznego utrzymywania procesów przetwarzania danych.
Platforma taka jak ELECTE – oparta na sztucznej inteligencji platforma do analizy danych dla małych i średnich przedsiębiorstw – udostępnia takie metody jak klasyfikatory bayesowskie typu naive, nie wymagając specjalistycznej wiedzy z zakresu uczenia maszynowego. Zaletą jest nie tylko szybkość działania. Chodzi o zmniejszenie oporu między danymi a podjęciem decyzji.
Kiedy automatyzacja działa prawidłowo, zespół nie myśli już w kategoriach wzorów. Zamiast tego zadaje sobie istotne pytania:
To właśnie dlatego coraz więcej firm poszukuje narzędzi, które pomogą ocenić wiarygodność treści generowanych przez sztuczną inteligencję oraz sygnałów tekstowych pojawiających się w procesach wewnętrznych. W tym kontekście warto zapoznać się również z przewodnikiem po włoskich wykrywaczach sztucznej inteligencji, zwłaszcza jeśli Twój zespół zajmuje się dokumentami, treściami i weryfikacją językową.
W praktyce różnica jest prosta. Zamiast zajmować się pojedynczymi etapami technicznymi, skupiasz się na wynikach firmy. I właśnie w tym momencie sztuczna inteligencja staje się naprawdę przydatna, a nie tylko interesująca.
Klasyfikatory bayesowskie typu naive dostarczają ważnej lekcji. W analityce dobrze zastosowana prostota może okazać się skuteczniejsza niż źle zarządzana złożoność.
Dzięki intuicyjnej podstawie probabilistycznej, dobrej skalowalności i bardzo konkretnym zastosowaniom podejście to pozostaje niezawodnym narzędziem dla firm, które chcą klasyfikować informacje, dostrzegać ukryte sygnały i podejmować działania z większą pewnością. Nie trzeba być specjalistą w dziedzinie uczenia maszynowego, aby zrozumieć jego wartość. Wystarczy połączyć matematykę z decyzjami operacyjnymi.
Kiedy ten związek staje się jasny, sztuczna inteligencja przestaje być kwestią techniczną, a staje się atutem organizacyjnym. Właśnie wtedy prognozowanie zaczyna przynosić wymierne korzyści.
Jeśli chcesz przekształcić rozproszone dane w jasne wnioski, wypróbuj ELECTE. Platforma pomaga małym i średnim przedsiębiorstwom łączyć źródła danych, automatyzować analizy oraz uzyskiwać raporty i prognozy przydatne do podejmowania szybszych i bardziej świadomych decyzji.

.svg)
.svg)
.svg)






