

Ti trovi facilmente in questa situazione: hai un gestionale, magari un CRM, qualche file Excel che girano via email, e intanto qualcuno ti dice che per “fare analytics seri” devi scegliere tra data lake e data warehouse. A quel punto la conversazione si sposta subito sulla tecnologia, ma il problema vero è un altro. Ti serve davvero una nuova architettura dati, oppure ti serve semplicemente rendere leggibili e utili i dati che hai già?
Per una PMI, questa distinzione conta più della terminologia. La scelta sbagliata non crea solo complessità tecnica. Crea progetti lunghi, dipendenza dai consulenti, report che arrivano tardi e investimenti che faticano a trasformarsi in decisioni migliori. La scelta di non fare nulla, però, lascia l'azienda a navigare a vista.
Il punto non è imparare il gergo dei vendor. Il punto è capire quale soluzione è proporzionata al tuo business, al tuo budget e alle competenze che hai davvero in casa. Qui trovi una guida pratica per leggere il dibattito data lake vs data warehouse con gli occhi di chi deve far quadrare costi, accessibilità e ritorno operativo.
La pressione a “fare qualcosa con i dati” oggi è reale. I numeri crescono, le fonti si moltiplicano, i manager chiedono previsioni, dashboard e alert più rapidi. Nel frattempo, sul tavolo arrivano termini che sembrano obbligarti a una decisione architetturale immediata.
Per molte PMI, però, la trappola sta proprio qui. Ti convincono che il primo passo sia scegliere tra due modelli infrastrutturali, quando spesso il vero nodo è molto più concreto: dati dispersi, formati incoerenti, report manuali e nessuno che abbia tempo di rimettere ordine.
Le domande utili sono altre. Hai davvero un problema di architettura? Oppure hai un problema di accessibilità al dato? Se scegli la soluzione sbagliata, rischi di finanziare un progetto tecnico invece di migliorare il controllo sul business. Se non scegli nulla, continui a prendere decisioni con informazioni parziali.
Chi guida una PMI non ha bisogno di una lezione universitaria. Ha bisogno di un criterio semplice per capire cosa serve, cosa no, e dove si nasconde il vero costo.
La differenza più utile si capisce con due immagini molto pratiche.
Un data warehouse assomiglia a una biblioteca ben organizzata. Ogni libro entra già catalogato, classificato e messo nello scaffale corretto. Quando chiedi un'informazione, la trovi in fretta perché l'ordine è stato deciso prima. Un data lake, invece, assomiglia a un grande deposito dove arrivano scatole di ogni tipo. Metti dentro file ordinati, log, PDF, immagini, esportazioni dal gestionale, dati web. L'ordine lo applichi dopo, quando devi analizzarli.
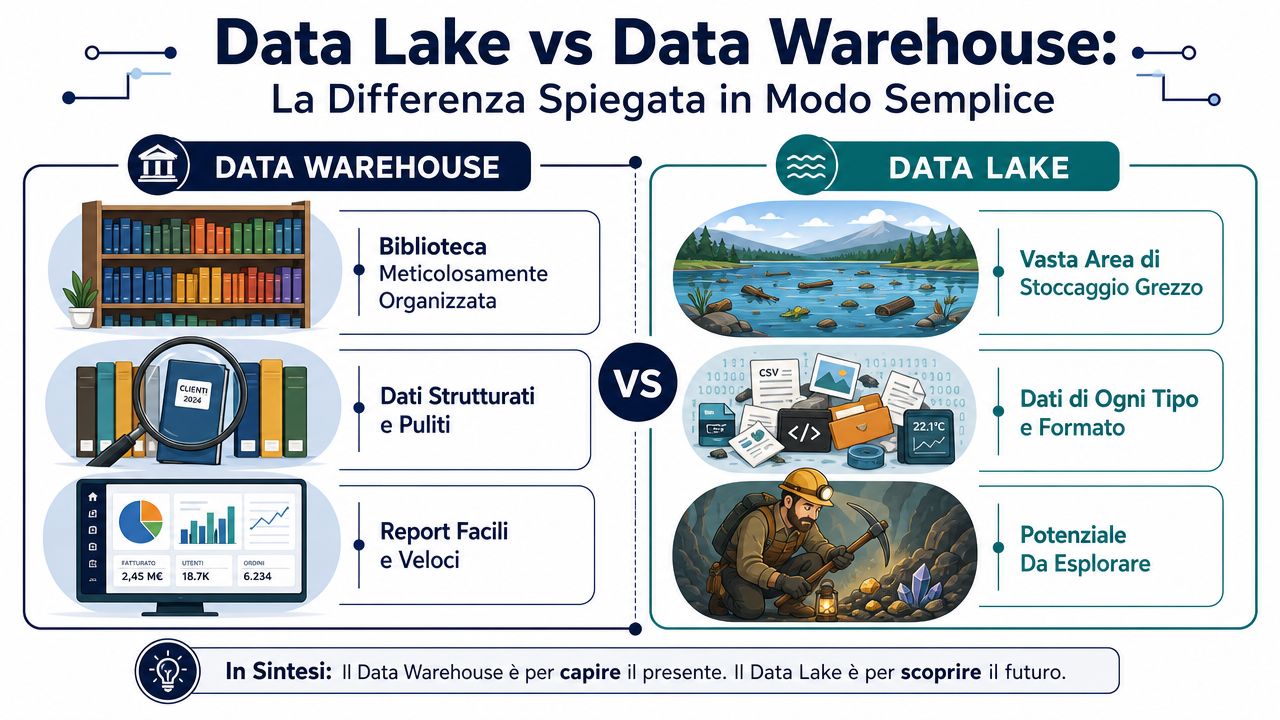
Qui entra il solo tecnicismo che vale davvero la pena ricordare.
Questa distinzione riassume anche la loro origine storica. Il data warehouse nasce per l'analisi aziendale su dati già puliti e strutturati, mentre il data lake arriva dopo per conservare dati grezzi in formati eterogenei. Per questo il warehouse è più adatto a reporting e KPI, mentre il lake è più flessibile per esplorazione e machine learning, come spiega questa analisi sulle differenze tra data warehouse e data lake.
Un warehouse risponde bene a domande già note. Un lake serve quando sai che i dati potrebbero contenere valore, ma non sai ancora in quale forma.
Se il tuo obiettivo è sapere vendite, marginalità, ordini, stock, ritardi, performance commerciali e confronti mensili, il warehouse è concettualmente più vicino al bisogno. Ti dà una base affidabile per report standard, interrogazioni SQL coerenti e numeri ripetibili.
Se invece lavori con dati molto diversi tra loro, come log applicativi, PDF, email, testi, immagini o flussi macchina, il lake offre più libertà. I team IT possono centralizzare fonti eterogenee, mentre chi fa reporting continua a preferire ambienti strutturati per interrogazioni veloci e coerenti. In questa logica si inserisce anche il tema più ampio delle data-driven decisions for businesses, che richiedono dati accessibili prima ancora che tecnologie sofisticate.
Nel dibattito data lake vs data warehouse, molti confondono flessibilità con utilità immediata.
Un data lake può contenere quasi tutto. Ma contenere non significa rendere subito analizzabile. Un data warehouse è meno flessibile all'ingresso, ma più utile quando vuoi risposte rapide e standardizzate. Per una PMI, questa differenza pesa più della teoria. Perché il problema non è archiviare di più. È decidere meglio.
Due aziende possono avere gli stessi dati di partenza e ottenere risultati molto diversi. La differenza, spesso, non sta nella quantità di dati raccolti ma in come li organizzano, li preparano e li rendono accessibili a chi deve decidere.
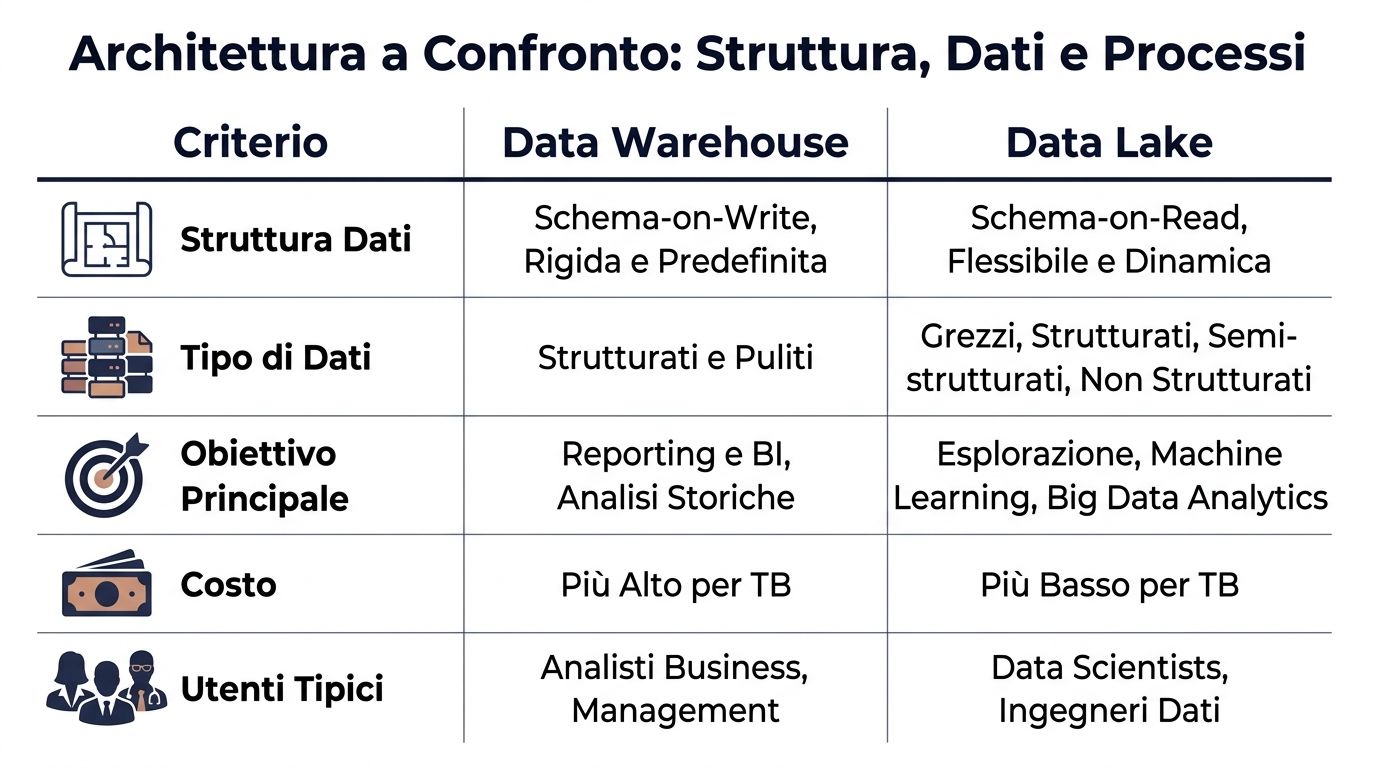
| Criterio | Data Warehouse | Data Lake |
|---|---|---|
| Struttura dati | Schema-on-write, definita prima del caricamento | Schema-on-read, definita al momento dell'analisi |
| Tipo di dati | Soprattutto strutturati e puliti | Strutturati, semi-strutturati e non strutturati |
| Processo tipico | ETL, trasformi prima e carichi dopo | ELT, carichi prima e trasformi dopo |
| Utenti tipici | Business analyst, finance, management | Data engineer, data scientist, team tecnici |
| Prestazioni attese | Più prevedibili per BI e reporting | Più variabili, dipendono da query e preparazione |
Nel data warehouse, il flusso classico è ETL: estrai i dati, li trasformi e poi li carichi. Richiede più lavoro all'inizio, ma riduce attriti dopo. Chi guarda una dashboard trova campi coerenti, definizioni stabili e KPI che non cambiano significato da un reparto all'altro.
Nel data lake, il flusso è spesso ELT: estrai, carichi e trasformi solo dopo, se serve. Questo approccio dà più libertà tecnica, ma rinvia una parte del lavoro. Per un'azienda piccola o media, rinviare spesso significa accumulare attività che poi ricadono sul team nel momento peggiore, cioè quando serve una risposta rapida.
Regola pratica: se più persone devono leggere lo stesso numero e prendere decisioni operative, la struttura definita prima del caricamento riduce errori, discussioni inutili e tempo perso.
Sul piano operativo, un data warehouse è progettato per interrogazioni ripetitive, report frequenti e dashboard usate ogni giorno. Un data lake gestisce bene grandi volumi e formati diversi, ma tempi di risposta e semplicità d'uso dipendono molto da come i dati sono stati catalogati, preparati e governati. Un confronto tecnico pubblicato da CloudOptimo riassume bene questo punto: il warehouse punta alla prevedibilità, il lake alla flessibilità.
Per una PMI il tema non è accademico. Se il responsabile vendite apre il report del mattino, vuole numeri coerenti e tempi rapidi. Se invece il team tecnico deve analizzare file, log o documenti eterogenei, può accettare più latenza in cambio di una raccolta dati più ampia.
La differenza pratica non è solo tecnica. Cambia chi riesce a usare i dati senza chiedere aiuto ogni volta.
Un warehouse ben impostato avvicina i dati al business. Un lake, da solo, li avvicina più spesso al team tecnico. Per questo molte PMI scoprono tardi un punto scomodo: il vero bivio non è tra due tecnologie, ma tra un sistema che rende i dati accessibili e uno che li conserva senza trasformarli in decisioni migliori.
Chi valuta queste opzioni dentro un progetto di modernizzazione IT dovrebbe considerare anche il modello operativo, non solo il repository. Le soluzioni cloud per PMI aiutano a capire proprio questo passaggio: dove finisce l'infrastruttura e dove iniziano costi, competenze richieste e responsabilità quotidiane.
Il data lake viene spesso presentato come la scelta più economica perché conserva dati grezzi e riduce il lavoro iniziale. È vero solo in parte. Se mancano catalogo, regole di accesso, naming coerente e controlli minimi di qualità, il risparmio iniziale si trasforma in tempo perso per cercare file, ricostruire definizioni e verificare quale dato sia affidabile.
Per questo, in molte PMI, il confronto corretto non è “lake contro warehouse” in astratto. La domanda utile è un'altra: serve davvero costruire una di queste architetture complete, oppure conviene partire da un livello più leggero che porti insight rapidi senza caricarsi subito tutta la complessità?
Per una PMI, l'errore più costoso nasce spesso da una domanda impostata male: “costa meno un data lake o un data warehouse?”. In azienda, il conto vero arriva dopo. Arriva quando i dati non si parlano, i report si rompono a ogni cambio del gestionale e ogni richiesta passa da consulenti o sviluppatori invece che dal team che deve decidere.

Lo storage pesa meno di quanto sembri. Pesano di più le attività che rendono il dato affidabile e usabile: modellazione, integrazioni, permessi, qualità, monitoraggio, correzione degli errori, supporto agli utenti.
Un data warehouse richiede lavoro all'inizio. Bisogna definire metriche, costruire pipeline, allineare le fonti e mantenere tutto ordinato quando cambiano ERP, CRM o regole di business. In cambio, il management legge numeri più stabili e il reporting tende a diventare più prevedibile.
Un data lake entra spesso con una promessa più leggera. Carichi dati di tipi diversi e rimandi parte delle decisioni strutturali. Il problema è che il rinvio non elimina il lavoro. Lo sposta più avanti, dove si presenta sotto forma di catalogazione, sicurezza, costi di calcolo, duplicazioni, versioni incoerenti e continue verifiche su quale dato sia davvero affidabile.
Il rischio, per una PMI, è pagare due volte. Prima per raccogliere i dati. Poi per renderli finalmente leggibili.
La vera complessità non è tecnica. È operativa.
Se ogni nuovo report richiede interventi manuali, se il controller e il commerciale usano definizioni diverse della stessa metrica, se l'imprenditore deve aspettare giorni per avere un numero attendibile, il progetto dati sta già consumando margine. Anche se l'infrastruttura, sulla carta, sembra moderna.
Per questo conviene valutare anche il modello di gestione, non solo l'architettura. Le soluzioni cloud per PMI aiutano proprio a leggere questa differenza: cosa stai davvero comprando, quanta manutenzione resta interna e quanto dipendi da competenze specialistiche ogni mese.
Nel mercato italiano, chi investe in analytics cerca risultati visibili. Riduzione del lavoro manuale. Chiusure più rapide. Controllo migliore su vendite, marginalità, scorte, cash flow. Non una piattaforma sofisticata che resta nelle mani di pochi.
Questo cambia il criterio di scelta. Una PMI non dovrebbe chiedersi quale architettura sia più affascinante o più flessibile in astratto. Dovrebbe chiedersi quanto tempo serve per arrivare a dashboard affidabili, quante persone servono per mantenerle e quanto velocemente il progetto restituisce valore.
Nel retail, il costo nascosto emerge presto. Se vendite, resi, promo e giacenze arrivano da sistemi diversi, basta una definizione sbagliata di “margine” o “venduto netto” per bloccare la fiducia nei report. A quel punto il problema non è il database scelto. È che il titolare torna a decidere su Excel.
Nel finance, il prezzo dell'errore è ancora più evidente. Reporting, quadrature, controllo di gestione e analisi degli scostamenti richiedono dati coerenti e tracciabili. Se ogni revisione apre discussioni sull'origine del numero, il progetto perde ROI anche prima di finire.
Per questo, nella pratica, molte PMI non hanno bisogno di costruire da zero un lake o un warehouse completo. Hanno bisogno di un sistema più leggero, gestibile e orientato alle decisioni.
Se non riesci a mantenere qualità del dato, regole di accesso e definizioni condivise nel tempo, il problema non è la scelta tra lake e warehouse. Il problema è aver comprato complessità prima di avere un caso d'uso che la giustifichi.
La domanda giusta non è quale architettura sia “migliore” in assoluto. La domanda è quale problema devi risolvere domani mattina.

Nel retail, il warehouse funziona bene quando devi rispondere sempre alle stesse domande operative:
Lo stesso vale in ambito finance. Se devi consolidare dati strutturati, fare reporting periodico, analizzare portafogli o leggere andamenti economici con criteri stabili, il warehouse resta una scelta naturale.
Il lake ha senso quando la tua azienda raccoglie dati molto diversi e non vuoi o non puoi definire tutto in anticipo.
Un caso realistico è quello di un'azienda energia che incrocia:
In un contesto simile, un warehouse classico ti costringe a progettare prima le relazioni tra fonti che forse non conosci ancora bene. Un lake permette di centralizzare tutto e dare struttura solo quando serve all'analisi specifica. Questo è il tipo di scenario in cui la flessibilità del lake crea davvero valore.
Il data lake non è una scelta “più moderna”. È una scelta sensata solo quando la varietà dei dati giustifica la complessità che ti porti in casa.
La maggior parte delle PMI non vive in quello scenario. Ha soprattutto dati da ERP, CRM, e-commerce, contabilità, export CSV ed Excel. In questi casi, il problema non è gestire file video, log applicativi o testi liberi su larga scala. Il problema è avere numeri puliti, coerenti e leggibili da persone non tecniche.
Qui il punto va detto con chiarezza: spesso non serve né un data lake né un data warehouse tradizionale.
Serve piuttosto:
Il lakehouse prova a unire i due mondi. Promette la flessibilità del lake e alcune qualità del warehouse nello stesso ambiente. È una direzione interessante, soprattutto per aziende con workload misti tra BI, AI e data science.
Per una PMI, però, la domanda resta identica: hai davvero un problema che richiede tutto questo? Se la tua esigenza è leggere meglio vendite, marginalità, cash flow o forecast, una soluzione ibrida sofisticata può essere ancora fuori scala rispetto al valore atteso.
Il data lakehouse nasce per superare la separazione rigida tra lake e warehouse. L'idea è semplice: tenere la flessibilità di uno storage ampio e aperto, ma aggiungere ordine, prestazioni e capacità analitiche più vicine a quelle di un warehouse. Tecnologie come Databricks e Delta Lake rappresentano bene questa direzione.
In teoria è molto attraente. Usi la stessa base dati per BI, analisi avanzata e machine learning, evitando di duplicare troppe informazioni tra sistemi diversi. Per grandi organizzazioni, o per team dati maturi, è una risposta logica a un ecosistema che si è complicato nel tempo.
Nei benchmark accademici, l'architettura data lakehouse viene valutata con metriche come throughput, latenza e overhead dei metadati. Questo mostra che il confronto con il data warehouse non è solo funzionale, ma anche prestazionale, in scenari dove piccole differenze di performance hanno un impatto rilevante, come evidenzia questa presentazione accademica sui benchmark lakehouse.
Tradotto in italiano aziendale: il lakehouse risolve problemi da organizzazioni che hanno già un certo livello di scala, complessità e specializzazione.
Se non ti servivano davvero né un data lake né un data warehouse, difficilmente ti serve un sistema che combina entrambi.
Per la maggior parte delle PMI, la domanda più utile non è “quale architettura scelgo?”, ma “come ottengo analisi affidabili senza trasformare il progetto dati in un cantiere permanente?”.
Questa è la terza via che manca in molti confronti data lake vs data warehouse. Non costruire una nuova infrastruttura proprietaria. Mettere invece un livello di analisi sopra i sistemi che già usi, assorbendo la complessità tecnica fuori dal perimetro operativo dell'azienda.

Nella pratica, l'approccio più sano è questo:
Ho visto più di una PMI investire mesi in un warehouse tradizionale e poi usarlo pochissimo. Non perché fosse costruito male. Perché nessuno in azienda sapeva interrogarlo in autonomia. Il collo di bottiglia non era il database. Era l'accessibilità.
Questo è il punto che spesso viene sottovalutato. Un'architettura elegante che richiede sempre un intermediario tecnico riduce il valore pratico del dato. Una soluzione più semplice, ma leggibile dal management, spesso genera decisioni migliori più in fretta.
Per questo molte aziende ottengono più valore da un software di business intelligence per PMI ben progettato che da un programma infrastrutturale sovradimensionato. Il risultato che cercano non è possedere un data warehouse. È capire il business meglio e prima.
L'infrastruttura giusta è quella che il tuo team riesce a usare, mantenere e trasformare in decisioni. Non quella che impressiona in una slide tecnica.
Il dibattito data lake vs data warehouse è utile, ma per una PMI spesso parte dalla domanda sbagliata. Prima di scegliere un'architettura, devi capire se hai davvero un problema di scala e varietà del dato, oppure un problema molto più comune: dati dispersi, report manuali e scarsa accessibilità.
Il data warehouse resta forte quando servono reporting affidabile, KPI coerenti e prestazioni prevedibili. Il data lake ha senso quando la varietà delle fonti giustifica maggiore flessibilità e maggiore complessità. Il lakehouse è un'evoluzione interessante, ma raramente è il primo passo giusto per una realtà che vuole soprattutto controllo operativo e ROI.
La scelta più intelligente non è la tecnologia più avanzata. È quella proporzionata al problema reale, alle competenze disponibili e alla velocità con cui vuoi trasformare i dati in decisioni.
Se vuoi trasformare i dati aziendali in report, forecast e insight operativi senza costruire un'infrastruttura complessa, scopri ELECTE, un'AI-powered data analytics platform for SMEs. Puoi partire dai dati che hai già, ridurre il lavoro manuale e portare analytics accessibili nel tuo team con un approccio molto più snello.

.svg)
.svg)
.svg)






