

Stai già vivendo il problema che l'High Performance Computing risolve, anche se forse non lo chiami così. Hai un forecast che impiega troppo tempo a girare. Un report arriva quando il contesto è già cambiato. Un modello promettente di domanda, rischio o pricing si ferma non perché manchino i dati, ma perché il tempo di calcolo lo rende poco utile per il business.
Per molte PMI, il limite non è più raccogliere informazioni. Il limite è trasformarle in decisioni in tempo utile. È qui che l’High Performance Computing smette di sembrare un tema da laboratorio e diventa una questione manageriale: quante simulazioni puoi eseguire, quanto velocemente puoi aggiornare una previsione, quante alternative puoi confrontare prima che il mercato ti costringa a scegliere.
In Italia, il tema ha anche un peso strategico nazionale. Il supercalcolatore Leonardo del CINECA, inaugurato a Bologna nel 2022 nell'ambito di EuroHPC, al momento dell'installazione è stato presentato come uno dei sistemi più potenti al mondo, segnalando che l'HPC è ormai una leva per industria e ricerca applicata, non solo per l'accademia (contesto sul mercato HPC e su Leonardo).
Lunedì mattina. Il direttore commerciale chiede un nuovo forecast entro il pomeriggio, la supply chain vuole rivedere i livelli di stock prima di confermare gli ordini, e il finance team pretende uno scenario prudente e uno aggressivo per la riunione del giorno dopo. I dati ci sono. Il problema è il tempo necessario per elaborarli bene.
L’High Performance Computing serve proprio a questo: eseguire molti calcoli complessi nello stesso momento, così da ottenere risposte utili quando servono ancora. Per una PMI, il punto non è possedere un supercomputer. Il punto è evitare che analisi lente rallentino decisioni che hanno un impatto diretto su margini, servizio e inventario.
Un sistema tradizionale esegue il lavoro in modo più lineare. L'HPC distribuisce il carico tra più risorse coordinate, come farebbe un team ben organizzato davanti a una scadenza stretta. Il risultato non è solo velocità. È la possibilità di testare più ipotesi, aggiornare le previsioni più spesso e scegliere con meno approssimazione.
In ELECTE lo vediamo in contesti molto concreti. Un forecast ricalcolato più rapidamente aiuta a ridurre rotture di stock e overstock. Un motore di ottimizzazione più veloce consente di confrontare scenari diversi prima di allocare budget, scorte o capacità operativa. In pratica, il calcolo diventa una leva gestionale, non un tema da reparto IT.
L'HPC conta quando arrivare tardi con un'analisi costa più che eseguirla in parallelo.
Un equivoco frequente tra i manager è associare l'HPC solo a volumi enormi di dati. Nelle decisioni aziendali, spesso il limite arriva prima, quando cresce la complessità della domanda da risolvere.
Succede, per esempio, quando un dataset tutto sommato gestibile deve alimentare calcoli molto più pesanti del semplice reporting. Alcuni casi tipici sono questi:
Qui la domanda giusta non è “quanti dati ho?”. È “quanto costa decidere con un modello semplificato o con risultati che arrivano troppo tardi?”.
Dal punto di vista tecnico, l'HPC combina molte risorse di calcolo per affrontare elaborazioni che una singola macchina gestirebbe con più lentezza o con più vincoli. Dal punto di vista di una PMI, la traduzione è più semplice: previsioni disponibili prima, simulazioni più frequenti, piani di stock meglio calibrati, meno attese tra una domanda di business e una risposta affidabile.
Ed è qui che cambia la prospettiva rispetto ai contenuti più accademici sull'argomento. Per una piccola o media impresa, HPC non significa entrare nel mondo dei centri di ricerca. Significa usare una capacità di calcolo scalabile per risolvere problemi aziendali complessi, senza costruire da zero un team di ingegneri o un'infrastruttura difficile da gestire. È il tipo di approccio che piattaforme come ELECTE rendono praticabile anche fuori dalle grandi enterprise.
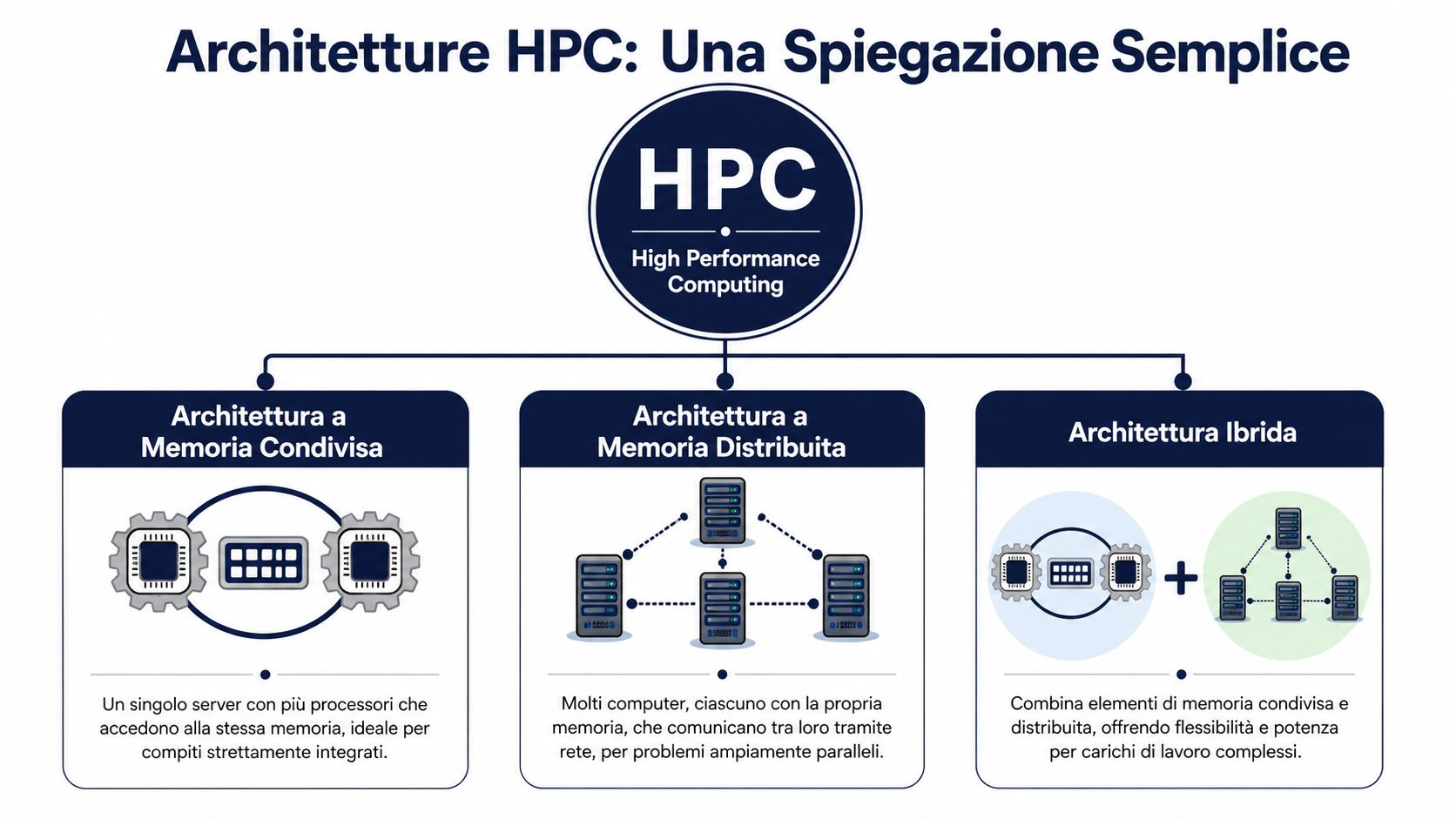
L'HPC funziona grazie a più componenti che collaborano. I tre termini che contano davvero sono cluster, GPU e cloud.
Un cluster mette insieme più macchine, chiamate nodi, per eseguire uno stesso lavoro in parallelo. In pratica, un'attività troppo pesante per un solo server viene suddivisa in parti più piccole e assegnata a più nodi coordinati tra loro. Per un manager, il punto non è tecnico ma operativo: meno tempo di attesa tra la richiesta di un'analisi e una decisione su stock, pricing o forecasting.
In ELECTE questo principio è utile, per esempio, quando un'azienda deve ricalcolare previsioni su molte combinazioni di prodotto, punto vendita e periodo. Se il lavoro resta su una sola macchina, i tempi si allungano e il team tende a lanciare meno simulazioni. Se il carico viene distribuito, diventa realistico confrontare più scenari nello stesso ciclo decisionale.
Le GPU servono per un altro tipo di accelerazione. Sono molto efficaci quando lo stesso tipo di calcolo deve essere ripetuto moltissime volte, come accade nel machine learning, in alcune ottimizzazioni e in parte dell'analisi avanzata. Il risultato di business è concreto: addestrare o testare modelli più rapidamente, aggiornare prima le previsioni e ridurre il tempo che separa un'ipotesi da una verifica.
Il cloud HPC aggiunge elasticità alla capacità di calcolo. Invece di comprare risorse pensate per il picco massimo dell'anno, l'azienda può attivarle nei momenti in cui servono davvero. Per una PMI è spesso la differenza tra rinunciare a un'analisi complessa e farla nel momento giusto, senza costruire in casa un'infrastruttura difficile da mantenere. Se vuoi chiarire come si collocano questi modelli di erogazione, può essere utile questo approfondimento su IaaS, PaaS e SaaS nel cloud.
Nella pratica aziendale, la scelta migliore raramente passa da una sola architettura. Conta di più combinare bene le risorse.
Un ambiente on-premise offre controllo diretto, prevedibilità e, in alcuni casi, una latenza più gestibile. Il cloud aggiunge capacità on demand. Le GPU accelerano i carichi adatti al parallelismo massivo. I cluster distribuiscono il lavoro tra più nodi. Un'architettura ibrida nasce proprio da questo mix, costruito in base al tipo di analisi, alla frequenza dei picchi e ai vincoli di governance.
Per una PMI, il criterio corretto è semplice. Se hai processi stabili, ricorrenti e sensibili ai tempi di risposta, una base on-premise può avere senso. Se invece i carichi salgono in alcuni momenti, come chiusure di periodo, ri-forecast o simulazioni straordinarie, il cloud permette di aumentare la capacità senza immobilizzare budget tutto l'anno.
C'è poi un punto che spesso crea confusione. Scalare non significa solo aggiungere core o server. In un workload reale contano anche rete, memoria e storage, perché i nodi devono scambiarsi dati in modo rapido e ordinato. Le spiegazioni tecniche dei data center HPC mostrano bene questo principio, soprattutto nel rapporto tra nodi, interconnessione e memoria (approfondimento su nodi, interconnessione e memoria nei data centre HPC).
Tradotto in linguaggio manageriale, l'architettura giusta è quella che riduce i colli di bottiglia che rallentano il business. Non serve il supercomputer da laboratorio. Serve una configurazione scalabile che permetta analisi più frequenti, previsioni più tempestive e decisioni operative prese con dati migliori. È qui che piattaforme come ELECTE rendono l'HPC concreto anche per aziende che non hanno un team interno di ingegneria specializzata.
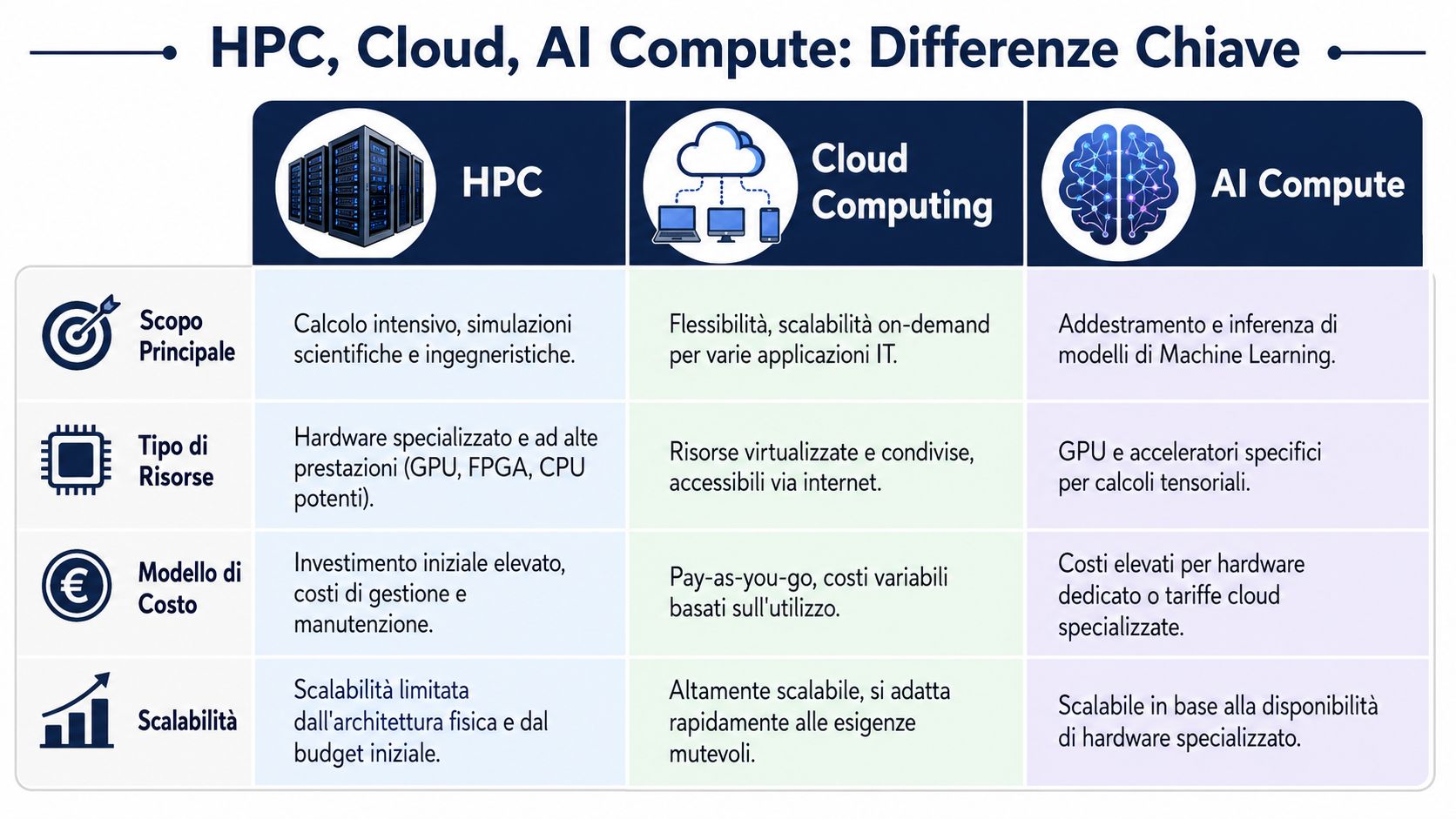
Questi tre termini vengono spesso mescolati, ma indicano livelli diversi della stessa realtà.
Una frase semplice aiuta a distinguerli. L'HPC è il motore. Il cloud è la modalità di accesso. L'AI compute è il tipo di corsa che stai facendo.
| Aspetto | HPC | Cloud Computing | AI Compute |
|---|---|---|---|
| Domanda a cui risponde | Come accelero calcoli intensivi? | Dove ottengo risorse flessibili? | Che tipo di elaborazione sto eseguendo? |
| Uso tipico | Simulazioni, forecasting complesso, ottimizzazione | Ambienti elastici, provisioning rapido, burst capacity | Training e inferenza di modelli ML |
| Vantaggio manageriale | Riduce tempi di esecuzione | Evita investimenti rigidi su picchi non continui | Sblocca casi d'uso di AI |
| Relazione con gli altri | Può girare on-premise o in cloud | Può ospitare workload HPC e AI | Spesso usa infrastrutture HPC |
Se stai valutando servizi digitali più ampi, può aiutarti anche chiarire la differenza tra modelli infrastrutturali e applicativi come IaaS, PaaS e SaaS nelle architetture cloud.
Cloud non significa automaticamente HPC. E AI non significa automaticamente architettura ben progettata.
Un cluster HPC in cloud è quindi possibile. Un carico AI su infrastruttura HPC è normale. Un ambiente cloud generico, invece, non è per forza adatto a un lavoro dove servono parallelizzazione spinta, scheduler, acceleratori e throughput costante.

Uno dei modi più chiari per capire il valore dell'HPC è osservare cosa succede quando i tempi di elaborazione smettono di essere accettabili per il business.
In un progetto retail seguito da ELECTE, un cliente con 42 punti vendita doveva ricalcolare le previsioni di domanda settimanale su 8.600 SKU, tenendo conto di stagionalità, promozioni, effetti calendario e cannibalizzazione tra prodotti. Il processo precedente, basato su script Python sequenziali su un server singolo, richiedeva circa 50 ore per un ciclo completo. Dopo la migrazione su un'architettura distribuita con parallelizzazione per cluster di prodotto, il tempo è sceso a 4 ore.
Il beneficio più importante non era la sola velocità. Era organizzativo. Il team poteva rieseguire il modello molto più spesso, invece di lavorare con previsioni già vecchie quando arrivavano ai category manager.
Questo cambia decisioni molto concrete:
Nel settore energia, ELECTE ha gestito un caso dove il collo di bottiglia non era il “big data” in senso classico. Il dataset comprendeva 14 milioni di record di consumi orari distribuiti su 36 mesi, incrociati con variabili meteo, tariffarie e di capacità produttiva. Il modello di forecasting richiedeva l'ottimizzazione simultanea di oltre 200 combinazioni di iperparametri su cinque algoritmi.
Su una macchina singola con 32 GB di RAM, il processo si bloccava dopo 18 ore senza completare la grid search. Distribuendo il carico su un cluster con 128 vCPU e 512 GB di RAM aggregati, l'intera pipeline si è chiusa in meno di 3 ore.
Qui si vede bene il punto: il valore dell'HPC non nasce solo dal volume dati. Nasce dalla complessità combinatoria del problema.
Per chi guida una PMI, questi esempi valgono più di una definizione tecnica. Mostrano che l'HPC migliora il business quando accorcia il tempo tra domanda e decisione.
C'è anche un tema di maturità del mercato. In Italia, nel 2024 solo il 5,7% delle imprese con almeno 10 addetti dichiarava di usare l'AI, contro una media UE del 13,5% (dato sull'adozione AI nelle imprese italiane). Questo gap è un problema, ma anche un'opportunità per chi porta analytics e AI in produzione con più rapidità.
Per capire perché il volume dati non basta da solo a spiegare questi scenari, è utile distinguere bene i casi in cui serve davvero l'analisi distribuita dai normali workload BI. Una buona base è questo approfondimento su big data analytics e complessità analitica.

Il vero ostacolo all'adozione dell'HPC nelle PMI non è capire che serve. È gestirlo senza trasformare ogni progetto analitico in un progetto infrastrutturale.
Qui entra in gioco l'approccio di ELECTE. La piattaforma separa l'esperienza utente dalla complessità tecnica. Chi usa il sistema vede dati, modelli, report e insight. Non deve decidere dove schedulare un job, come distribuire un dataframe o quale nodo ha abbastanza memoria libera.
Questo cambia la convenienza economica dell'HPC. Non perché il calcolo diventi magicamente gratuito, ma perché il costo operativo della complessità si abbassa. In pratica, il manager ottiene la potenza quando serve senza doversi costruire un reparto di ingegneria dedicato.
Dietro le quinte, ELECTE usa uno stack progettato per scalare senza riscrivere la logica quando aumentano dati o complessità:
Per il forecasting, i modelli proprietari di ELECTE girano su un layer di orchestrazione che decide automaticamente se eseguire in locale o distribuire il carico sul cluster in base alla dimensione dell'input e alla complessità della pipeline.
Osservazione operativa: la scelta migliore non è legarsi a un solo framework. È costruire un'architettura sostituibile, così la piattaforma può evolvere senza riscrivere il valore di business.
Questo approccio ha un effetto molto concreto per una PMI. Il team non compra “potenza” in astratto. Compra continuità analitica. Se il caso d'uso cresce, l'infrastruttura cresce. Se il carico rientra, non resta una macchina sovradimensionata a occupare budget e attenzione.

La domanda giusta non è “quanto costa l'HPC?”. La domanda giusta è “quale configurazione serve davvero ai miei carichi reali?”.
Dall'esperienza di ELECTE emerge una regola molto pratica: non dimensionare per il picco permanente. La maggior parte delle PMI ha carichi intermittenti. Forecast, chiusure trimestrali, ricalcoli ad hoc e simulazioni non richiedono la stessa intensità tutti i giorni.
Per un cliente tipo con dataset tra 5 e 50 milioni di record, il costo infrastrutturale può collocarsi tra 400 e 1.200 euro al mese, con un cluster base che copre la gran parte delle esigenze e capacità aggiuntiva on-demand per i picchi. L'errore più comune è il contrario: comprare capacità “nel dubbio” e ritrovarsi con una larga parte dell'infrastruttura inutilizzata per quasi tutto l'anno.
Una checklist utile per la decisione:
La sicurezza non può essere un'aggiunta successiva. Nel 2024, l'Agenzia per la Cybersicurezza Nazionale ha registrato un aumento del 40% degli eventi cyber e del 45% degli incidenti confermati rispetto al 2023 (dato ACN riportato nel riferimento indicato). Questo basta per chiarire una cosa: una piattaforma di calcolo ad alte prestazioni deve essere sicura fin dal disegno iniziale.
Per ambienti regolati o sensibili, conviene verificare almeno questi aspetti:
| Area | Domanda manageriale |
|---|---|
| Segmentazione | I workload critici sono separati dal resto dell'infrastruttura? |
| Data residency | Sai dove risiedono i dati e dove vengono elaborati? |
| Audit | Puoi ricostruire chi ha eseguito cosa e quando? |
| Scalabilità | L'aumento del carico mantiene gli stessi controlli? |
L'integrazione conta quanto la sicurezza. Se l'HPC resta isolato, finisce per essere usato poco. Se entra nel flusso dei dati aziendali, diventa una leva continua. Per capire come collegare analytics avanzata e sistemi esistenti, può aiutarti valutare le opzioni di integrazione dati e applicativa in ELECTE.
L'High Performance Computing non è più una categoria lontana dalla realtà delle PMI. È una risposta concreta a un problema molto comune: hai dati, hai modelli, hai domande importanti, ma non hai abbastanza tempo per trasformarli in decisioni utili.
Il punto chiave da ricordare è semplice. L'HPC diventa prezioso quando cresce la complessità analitica. Non serve inseguire l'idea del supercomputer. Serve capire dove il calcolo parallelo può accorciare il ciclo tra insight e azione.
Se stai valutando i prossimi passi, parti così:
Quando forecasting, ottimizzazione e AI diventano più rapidi, cambia anche il modo in cui l'azienda lavora. Le decisioni non aspettano più i report. I report iniziano a seguire il ritmo del business.
Se vuoi trasformare dati complessi in insight chiari senza gestire l'infrastruttura sottostante, scopri ELECTE, la piattaforma AI-powered di data analytics per le PMI. Puoi vedere come automatizzare reporting, forecasting e analisi avanzate con un'esperienza pensata per team business, non solo per specialisti tecnici.

.svg)
.svg)
.svg)






