

Ti arriva un file XML via PEC. Lo apri in browser, vedi una parete di tag e pensi che il problema sia “leggerlo”. In realtà, quello è solo il primo ostacolo. Il problema vero in azienda è un altro: capire se quei dati sono corretti, coerenti e pronti per entrare nei tuoi report.
Per molte PMI italiane, questo tema non è più tecnico in senso stretto. Da quando la fatturazione elettronica è diventata obbligatoria, l'XML è entrato nel lavoro quotidiano di amministrazione, controllo di gestione e analisi. Non basta visualizzare il documento. Devi saper distinguere tra un file leggibile e un file affidabile. Devi capire quando basta un controllo rapido e quando serve parsing, validazione e normalizzazione prima di caricare i dati in Excel, nel BI o in una piattaforma analytics.
Se stai cercando una guida pratica su come leggere file XML, la strada giusta è questa: partire dai metodi semplici, capire dove si rompono, poi costruire un flusso che trasformi XML grezzo in dati utili al business. È lì che si riducono gli errori e si accorcia il tempo tra “ho il file” e “ho un insight utilizzabile”.
Un file XML organizza i dati in una struttura gerarchica. C'è un elemento principale, ci sono sezioni annidate e ogni blocco descrive un'informazione con un significato preciso. Per chi gestisce processi amministrativi, questo dettaglio fa la differenza tra un dato leggibile e un dato davvero utilizzabile.
Il punto non è “aprire” il file. Il punto è capire se quel file può entrare senza errori nei flussi di controllo, contabilità e analisi.
Prendiamo una fattura elettronica. Dentro lo stesso file convivono dati del fornitore, dati del cliente, imponibili, IVA, righe articolo, condizioni di pagamento, riferimenti ordine e spesso anche eccezioni che complicano la lettura. In XML queste informazioni non sono messe una sotto l'altra come in un foglio qualsiasi. Sono collocate in posizioni precise, e quella posizione spiega cosa rappresentano.
Per un manager, la distinzione utile non è tra tag e attributi in senso teorico. È tra dato isolato e dato affidabile. Leggere “1000,00” fuori contesto serve a poco. Leggerlo nel punto corretto del file permette di capire se è il totale documento, l'imponibile, l'imposta o il valore di una singola riga.
Qui nasce il primo vantaggio operativo. L'XML conserva il contesto del dato.
Regola pratica: leggere bene un file XML significa verificare il significato del valore, non solo il valore.
In Italia questo tema è diventato concreto con la diffusione della fatturazione elettronica. Nel formato FatturaPA, l'XML è diventato lo standard per la documentazione fiscale. Di conseguenza, la sua lettura non riguarda più solo l'IT. Coinvolge amministrazione, controllo di gestione, acquisti e chiunque debba usare quei dati per prendere decisioni.
Nella pratica vedo sempre lo stesso problema. Il file esiste, il dato c'è, ma il tempo per trasformarlo in informazione utile si allunga troppo. Una persona apre l'XML, controlla a vista, copia valori in Excel, corregge campi non uniformi, rinomina fornitori scritti in modi diversi e prova a ricostruire categorie di spesa che il file non espone in forma pronta per l'analisi. Il costo non è solo operativo. È tempo-to-insight perso.
Con FatturaPA il rischio è ancora più evidente. Due file formalmente corretti possono creare gli stessi problemi di analisi se uno usa descrizioni riga molto sporche, se i riferimenti ordine sono incompleti o se l'anagrafica fornitore entra con varianti diverse. A quel punto il problema non è leggere XML. Il problema è evitare che dati fiscali validi diventino dati gestionali poco affidabili.
Un errore comune è trattare l'XML come un allegato da visualizzare. In azienda funziona meglio considerarlo come una sorgente dati strutturata da controllare prima che alimenti report, dashboard e modelli di spesa. Se questa fase viene gestita male, il team finance si ritrova a discutere numeri apparentemente precisi ma costruiti su classificazioni incoerenti.
Le domande giuste, all'inizio, sono queste:
Sono verifiche molto concrete. Servono a evitare fornitori duplicati nei report, IVA interpretata male, centri di costo popolati in modo incompleto e riconciliazioni lente a fine mese.
È qui che si vede la distanza tra lettura tecnica e valore di business. Un parser legge il file. Un processo ben progettato produce dati puliti, confrontabili e pronti per l'analisi. Piattaforme come ELECTE nascono per chiudere proprio questo scarto, riducendo il lavoro manuale che separa l'XML ricevuto dall'insight utile per decidere meglio.
Per controlli veloci su un singolo file, non servono parser o librerie. Serve capire se stai facendo una verifica visiva di pochi campi o se stai già toccando dati che finiranno in contabilità, reportistica o controllo di gestione. La differenza conta, soprattutto con le FatturePA. Un controllo fatto in modo sbrigativo oggi può diventare una riga sbagliata nel dataset fornitori domani.

Browser, editor di testo e visualizzatori dedicati risolvono un problema preciso: leggere rapidamente il contenuto senza impostare un flusso tecnico. Per un file isolato, spesso basta. Puoi aprire un XML in Chrome, Edge o Firefox per vedere la struttura, oppure usare Blocco note, WordPad o TextEdit se vuoi ispezionare direttamente i tag. Nel caso delle fatture elettroniche, un visualizzatore dedicato rende più leggibili intestazioni, righe documento, imponibile e IVA.
Il punto operativo è questo:
| Strumento | Utile per | Limite principale |
|---|---|---|
| Browser | Controllo visivo rapido della struttura | Non verifica coerenza tra campi e sezioni |
| Editor di testo | Ispezione diretta dei tag | Diventa scomodo su file lunghi o annidati |
| Excel | Controllo preliminare in formato tabellare | Gestisce male gerarchie e ripetizioni |
| Visualizzatore dedicato | Lettura più chiara di fatture e documenti fiscali | Non prepara i dati per analisi o automazioni |
Se devi verificare data documento, partita IVA, totale fattura o presenza di allegati, questi strumenti sono adeguati.
Se invece l'obiettivo è confrontare fornitori, classificare spese o alimentare una dashboard, la sola visualizzazione rallenta il lavoro e lascia troppo spazio a errori manuali. È il classico gap tra vedere un file e arrivare a un dato affidabile in tempi utili.
Aprire un XML non equivale a validare i dati che userai nei report.
Un altro punto pratico riguarda il volume. Dieci file si controllano anche a mano. Centinaia di FatturePA no. In quel caso conviene già ragionare su un flusso ripetibile o su strumenti che leggano il contenuto in modo strutturato, per esempio tramite API per acquisire e gestire documenti fiscali in modo integrato.
In Italia il problema ricorrente non è aprire un .xml, ma capire cosa fare quando arriva un .xml.p7m via PEC. Bisogna distinguere tra file XML semplici e file firmati digitalmente. Il secondo caso richiede strumenti capaci di leggere la firma, estrarre il contenuto e mostrare l'XML corretto, come spiega questa guida dedicata a XML e XML P7M nella PEC.
Qui gli errori costano tempo:
Per un addetto amministrativo, la sequenza più utile è semplice:
Questi metodi fanno bene il loro lavoro nei controlli di primo livello. Non risolvono il problema che pesa davvero in azienda: trasformare XML fiscali, spesso irregolari o poco uniformi, in dati puliti e confrontabili senza allungare il tempo che separa il documento ricevuto dall'informazione utile.
Quando i file iniziano ad accumularsi, il lavoro manuale smette di essere sostenibile. A quel punto leggere file XML con codice non è una scelta elegante. È il primo passo per evitare attività ripetitive, errori di copia e dataset incoerenti.

Un approccio solido alla lettura di XML segue sempre la stessa logica: parsing, normalizzazione, estrazione mirata. Nei tutorial Java e Android, il flusso corretto passa da parse(), dalla normalizzazione dell'albero con doc.getDocumentElement().normalize() e poi dal recupero dei campi con getElementsByTagName, un metodo più stabile della semplice visualizzazione in editor di testo, come mostra questo tutorial tecnico sulla lettura dei dati XML.
Questa sequenza conta più del linguaggio che scegli. Se salti la normalizzazione, se cerchi nodi in modo troppo ingenuo, o se assumi che un tag compaia sempre una sola volta, il tuo script funzionerà su alcuni file e fallirà proprio su quelli che contano.
Per progetti che devono poi dialogare con sistemi esterni, può essere utile costruire un flusso di estrazione replicabile e documentato. Se lavori su integrazioni applicative, una base utile è la documentazione sulle API di ELECTE con profilo Postman verificato, soprattutto per capire come collegare un dataset già pulito a processi successivi.
Di seguito trovi esempi minimi. L'obiettivo non è coprire ogni caso, ma mostrarti la logica di base: aprire il file, trovare un nodo, stampare un valore.
import xml.etree.ElementTree as ETtree = ET.parse("fattura.xml")root = tree.getroot()numero = root.find(".//Numero")if numero is not None:print(numero.text)Python è spesso la scelta più veloce per prototipi, trasformazioni e pipeline leggere. È ottimo quando devi leggere molti file XML, estrarre pochi campi e salvarli in CSV o JSON.
const xmlString = `<fattura><Numero>123</Numero></fattura>`;const parser = new DOMParser();const xmlDoc = parser.parseFromString(xmlString, "application/xml");const numero = xmlDoc.getElementsByTagName("Numero")[0];console.log(numero.textContent);Questo approccio è utile per test rapidi in pagina o piccoli strumenti interni. Va bene per interfacce leggere, meno per flussi strutturati di back-office.
const fs = require("fs");const xml2js = require("xml2js");const xml = fs.readFileSync("fattura.xml", "utf8");xml2js.parseString(xml, (err, result) => {if (err) throw err;console.log(result.fattura.Numero[0]);});Se lavori lato server e vuoi costruire automazioni, Node.js resta una scelta pratica. Il vantaggio è integrare facilmente la lettura dell'XML con file system, code di elaborazione e servizi interni.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse("fattura.xml");doc.getDocumentElement().normalize();NodeList lista = doc.getElementsByTagName("Numero");if (lista.getLength() > 0) {System.out.println(lista.item(0).getTextContent());}Java è spesso presente in contesti enterprise, gestionali e middleware. Qui il punto chiave non è solo leggere il dato, ma farlo in modo prevedibile e mantenibile.
library(XML)doc <- xmlParse("fattura.xml")numero <- xpathSApply(doc, "//Numero", xmlValue)print(numero)R ha senso quando il parsing è parte di un lavoro analitico. Se il tuo passo successivo è un'analisi statistica o una preparazione dati, puoi tenere tutto nello stesso ambiente.
Se il tuo team apre gli stessi file ogni settimana e ripete gli stessi controlli, sei già nel territorio dell'automazione.
Il guadagno reale non è “leggere XML con codice”. È togliere alle persone un lavoro meccanico e costruire un flusso che produce dataset consistenti.
I problemi seri iniziano quando il file non è più uno. Una singola FatturaPA è gestibile quasi sempre. La difficoltà compare quando devi consolidare mesi di documenti, fornitori diversi, campi compilati in modo non uniforme e allegati incorporati.
Nelle PMI italiane il caso più comune non è il “mega file” isolato, ma il lotto. Un export annuale di fatture passive può produrre una struttura con oltre 380.000 nodi su 4.200 fatture, tra intestazioni, righe di dettaglio, dati di pagamento e allegati in base64. In questi scenari il problema non è aprire il documento. È trasformare XML eterogenei in un dataset coerente.
Qui entra in gioco una scelta tecnica che ha effetti di business. In ambiente .NET, Microsoft indica che XmlDocument carica il documento in memoria ed è utile per lettura e modifica, mentre per file di grandi dimensioni o operazioni di sola lettura conviene orientarsi verso approcci più efficienti come parser streaming o XPathDocument, per evitare consumo eccessivo di RAM, come specificato nella documentazione Microsoft sulla lettura XML con XmlDocument e XPathDocument.
In pratica:
Il trade-off è semplice. Il modello in memoria ti fa sviluppare più velocemente. Il modello streaming regge meglio in produzione quando i file diventano tanti o pesanti.
Molti team si fermano alla validazione XSD. È utile, ma non basta. Un file può rispettare lo schema e produrre comunque dati sporchi a valle.
Esempi tipici dal lavoro operativo:
| Tipo di controllo | Cosa verifica | Perché serve |
|---|---|---|
| Strutturale | Tag, formato, gerarchia | Evita errori di parsing |
| Semantico | Coerenza logica dei dati | Evita analisi sbagliate |
| Operativo | Presenza campi utili al reporting | Evita dataset inutilizzabili |
Il caso più subdolo è questo: ImportoTotaleDocumento formalmente valido ma non coerente con la somma delle righe, magari per logiche di arrotondamento del gestionale del fornitore. Oppure codici IVA formalmente ammessi ma incoerenti con la natura dell'operazione.
Un file formalmente corretto può comunque inquinare il tuo reporting.
C'è poi un'altra trappola nota nelle FatturaPA. Il tag DatiBeniServizi contiene descrizioni libere. Lo stesso costo può comparire in molti modi diversi, con testi puliti, abbreviati o criptici. Se non introduci un passaggio di normalizzazione, qualsiasi analisi per categoria di spesa diventa fragile.
Per questo, nei flussi seri, la lettura del file è solo il livello uno. Il livello due è sempre un set di regole di coerenza e pulizia. È lì che si protegge la qualità del dato, non nel parser.
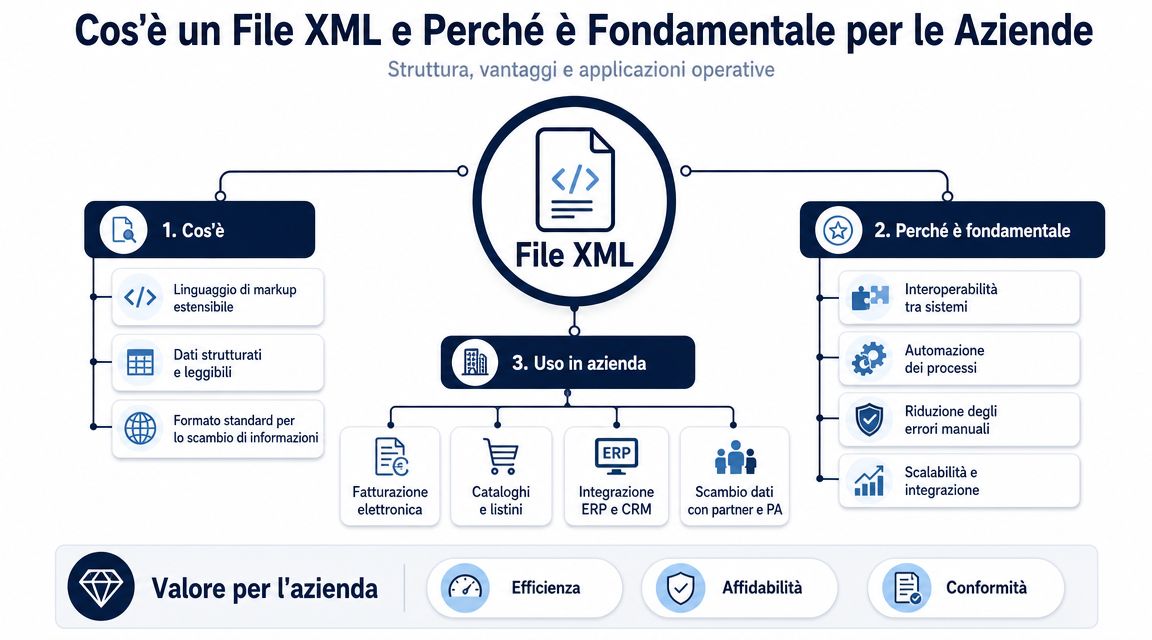
Un file XML ben letto non è ancora un dataset utile. È un documento strutturato. Per fare analisi, confronti, raggruppamenti e dashboard, quasi sempre devi portarlo in un formato più semplice da trattare.
Questo è il punto che molti processi sottovalutano. Il collo di bottiglia raramente è il parsing puro. Una libreria decente legge un XML in tempi rapidi. Il tempo si perde tra interpretazione della struttura, estrazione dei campi utili, pulizia, normalizzazione e caricamento in uno strumento analitico.
Per questo la conversione in CSV o JSON non è una comodità. È un passaggio operativo centrale. Se salti questa fase e lavori direttamente sul file grezzo, finisci quasi sempre con controlli manuali, colonne improvvisate e logiche difficili da replicare.
Un riferimento utile per chi lavora spesso tra XML e fogli di calcolo è questa guida su come passare da XML a Excel in modo più ordinato.
Il formato giusto dipende da come userai i dati dopo.
Il CSV funziona bene quando vuoi una riga per documento, o una riga per dettaglio fattura, e poi usare Excel, Power Query o BI.
Esempio Python:
import xml.etree.ElementTree as ETimport csvtree = ET.parse("fattura.xml")root = tree.getroot()with open("fatture.csv", "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(["numero", "data"])numero = root.findtext(".//Numero")data = root.findtext(".//Data")writer.writerow([numero, data])Il vantaggio è la semplicità. Il limite è che devi decidere bene come appiattire la gerarchia. Se una fattura ha più righe di dettaglio, serve una scelta chiara su granularità e chiave di collegamento.
Il JSON è più adatto quando vuoi mantenere parte della struttura gerarchica.
Esempio JavaScript:
const record = {numero: "123",data: "2024-01-15",righe: [{ descrizione: "Servizio", importo: "100.00" }]};console.log(JSON.stringify(record, null, 2));Usalo quando il tuo passaggio successivo è un'API, un data lake, o un'applicazione che lavora bene con oggetti annidati.
Ecco una regola pratica che aiuta:
Il file XML è il contenitore. CSV e JSON sono i formati che rendono il contenuto davvero lavorabile.
Se vuoi ridurre il time-to-insight, è qui che conviene investire metodo. Non nel trovare un visualizzatore più comodo, ma nel definire una trasformazione stabile e ripetibile.
Una volta che il file è stato letto, validato e trasformato, il lavoro cambia natura. Non stai più combattendo con i tag. Stai finalmente ragionando su costi, anomalie, fornitori, categorie di spesa e trend operativi.
Nel lavoro reale, il valore non sta nel tempo di parsing. Sta nel tempo che separa il file grezzo da un'informazione su cui puoi decidere. Con un flusso manuale, una persona deve aprire il documento, capire la struttura, estrarre i campi, pulire i valori, normalizzare testi e poi costruire report. È un processo fragile.
Un esempio classico nelle FatturaPA è il testo libero in DatiBeniServizi. Lo stesso servizio può essere descritto in molti modi diversi da fornitori diversi. Se importi quei dati senza una mappatura coerente, l'analisi per categoria di costo produce aggregazioni inutili.
Per questo, prima della piattaforma analytics, serve un layer di preparazione dato:
Quando questa fase è fatta bene, qualsiasi piattaforma di analytics lavora meglio. Se vuoi approfondire il lato decisionale e visivo di questo passaggio, la risorsa su come costruire storie con i dati è utile perché mostra come un dataset pulito diventa una narrazione utile per chi decide.
A questo punto il file XML smette di essere un problema tecnico e diventa materia prima per insight. Un dataset ben preparato può alimentare analisi spese, monitoraggio trend, evidenza di scostamenti e lettura delle eccezioni.
Per scegliere una piattaforma adatta a questo ultimo miglio, può aiutarti confrontare cosa offre un moderno software di business analytics rispetto a flussi puramente manuali basati su fogli e pivot.
Qui il criterio giusto non è “sa aprire XML?”. Quello è il minimo. La domanda utile è un'altra:
| Domanda | Perché conta |
|---|---|
| I dati entrano già puliti | Eviti insight precisi su dati sbagliati |
| Le categorie sono coerenti | Confronti davvero fornitori e periodi |
| Le anomalie emergono subito | Riduci tempo perso in controlli manuali |
| Il report è leggibile da business e finance | Acceleri decision-making |
La differenza tra un processo acerbo e uno maturo non sta nella capacità di leggere file XML. Sta nella capacità di trasformarli in una base dati affidabile, che non costringa il team a rifare ogni volta lo stesso lavoro.
Se devi leggere file XML in modo utile al business, tieni a mente questa checklist. È più concreta di qualsiasi definizione tecnica e ti aiuta a scegliere il metodo giusto senza perdere tempo.
Non usare sempre lo stesso approccio. Browser, editor e visualizzatori vanno bene per controlli rapidi. Parser e script servono quando il file deve alimentare processi ripetuti. Se confondi visualizzazione e trattamento dati, il rischio è costruire report su basi fragili.
I file .xml.p7m richiedono un passaggio specifico di gestione firma. Se il contenuto arriva da PEC, questo controllo non è accessorio. Fa parte della corretta lettura del documento.
Uno schema rispettato non garantisce un dataset sano. Le incoerenze logiche, come totali non allineati o classificazioni fiscali ambigue, sono quelle che più spesso rovinano l'analisi. Il controllo semantico è ciò che separa un file “accettabile” da un dato affidabile.
CSV e JSON non sono un passaggio cosmetico. Sono il punto in cui l'XML diventa lavorabile da strumenti analytics, fogli di calcolo, pipeline e report. Prima definisci questa trasformazione, prima riduci lavoro manuale e improvvisazione.
Il tuo obiettivo non è leggere file XML. È ottenere insight utili senza inquinare il sistema con dati sporchi. Se il flusso non produce un dataset coerente, il problema non è nella dashboard finale. È molto più a monte.
In pratica, puoi usare questa mini-checklist prima di ogni nuovo progetto:
Se vuoi trasformare dati già preparati in insight chiari e azionabili, ELECTE aiuta le PMI a passare dal dataset pulito al reporting intelligente, con un approccio accessibile anche ai team non tecnici. È il modo più rapido per accorciare la distanza tra dati operativi e decision-making.

.svg)
.svg)
.svg)
.webp)





