

I tuoi dati stanno già raccontando una storia. Il problema è che spesso parlano troppo piano.
Ogni giorno una PMI accumula feedback clienti, ordini, ticket di assistenza, movimenti finanziari, email commerciali, note CRM. Tutto questo materiale contiene segnali utili. Alcuni indicano un cliente vicino all’abbandono. Altri anticipano un rischio operativo. Altri ancora mostrano quali prodotti stanno per accelerare o rallentare. Senza un metodo chiaro, però, quei segnali restano rumore.
Tra gli algoritmi che aiutano a portare ordine in questo caos, i naive bayesian classifiers occupano un posto particolare. Sono semplici da capire nella logica, rapidi da addestrare e spesso più efficaci di quanto il nome “naive” lasci pensare. Non sono la scelta giusta per ogni scenario, ma in molti problemi aziendali reali offrono un equilibrio raro tra velocità, interpretabilità e risultati utili.
Se lavori in ambito business, non ti serve diventare un ricercatore per capirli. Ti serve sapere cosa fanno, perché funzionano bene anche quando semplificano molto la realtà, e in quali casi possono aiutarti a prendere decisioni migliori. È proprio qui che vale la pena fermarsi.
Molte aziende cercano modelli sofisticati quando il problema richiede, prima di tutto, un modello affidabile e facile da usare. È lo stesso motivo per cui in finanza, nel retail o nel customer care spesso vince il processo più chiaro, non il più teoricamente elegante.
I naive bayesian classifiers partono da un’idea molto concreta. Se conosci alcuni indizi su un caso nuovo, puoi stimare a quale categoria appartiene con buona probabilità. Se un’email contiene certe parole, potrebbe essere spam. Se una transazione ha certi pattern, potrebbe richiedere un controllo. Se una recensione usa certi termini, potrebbe indicare soddisfazione o insoddisfazione.
La parola “bayesiano” fa pensare a formule complesse. In realtà, il cuore del metodo è intuitivo. Prendi ciò che sai già, aggiungi nuove evidenze e aggiorni il giudizio. È un modo ordinato di ragionare sotto incertezza, esattamente ciò che i manager fanno ogni giorno, solo reso sistematico da un algoritmo.
Quello che sorprende è che questo approccio continua a funzionare bene anche in ambienti moderni, con tanti dati e decisioni veloci. Non perché descriva il mondo in modo perfetto, ma perché separa il segnale utile dal rumore con un costo computazionale molto contenuto.
Nei problemi di business, la domanda giusta non è “qual è il modello più raffinato?”. È “quale modello mi dà decisioni affidabili in tempi compatibili con il lavoro reale?”.
Per questo i naive bayesian classifiers restano importanti. Ti aiutano a classificare, filtrare, segmentare e prioritizzare. E ti permettono di portare la probabilità dentro il processo decisionale senza trasformare ogni progetto in un cantiere tecnico.
Il principio di base è il teorema di Bayes. In forma semplice dice questo: parti da una probabilità iniziale, poi la aggiorni quando arrivano nuove informazioni.
Nel linguaggio dei dati, la formula si legge così: P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y). Significa che la probabilità di una classe dato un insieme di segnali dipende da due elementi. Il primo è la probabilità iniziale della classe. Il secondo è quanto ogni segnale è compatibile con quella classe.
Tradotto in un esempio business. Devi capire se un’email è spam oppure no. Hai una probabilità generale che una mail in arrivo sia spam. Poi osservi alcune parole come “offerta”, “gratis”, “clicca qui”. Ognuna di queste parole modifica il giudizio finale.
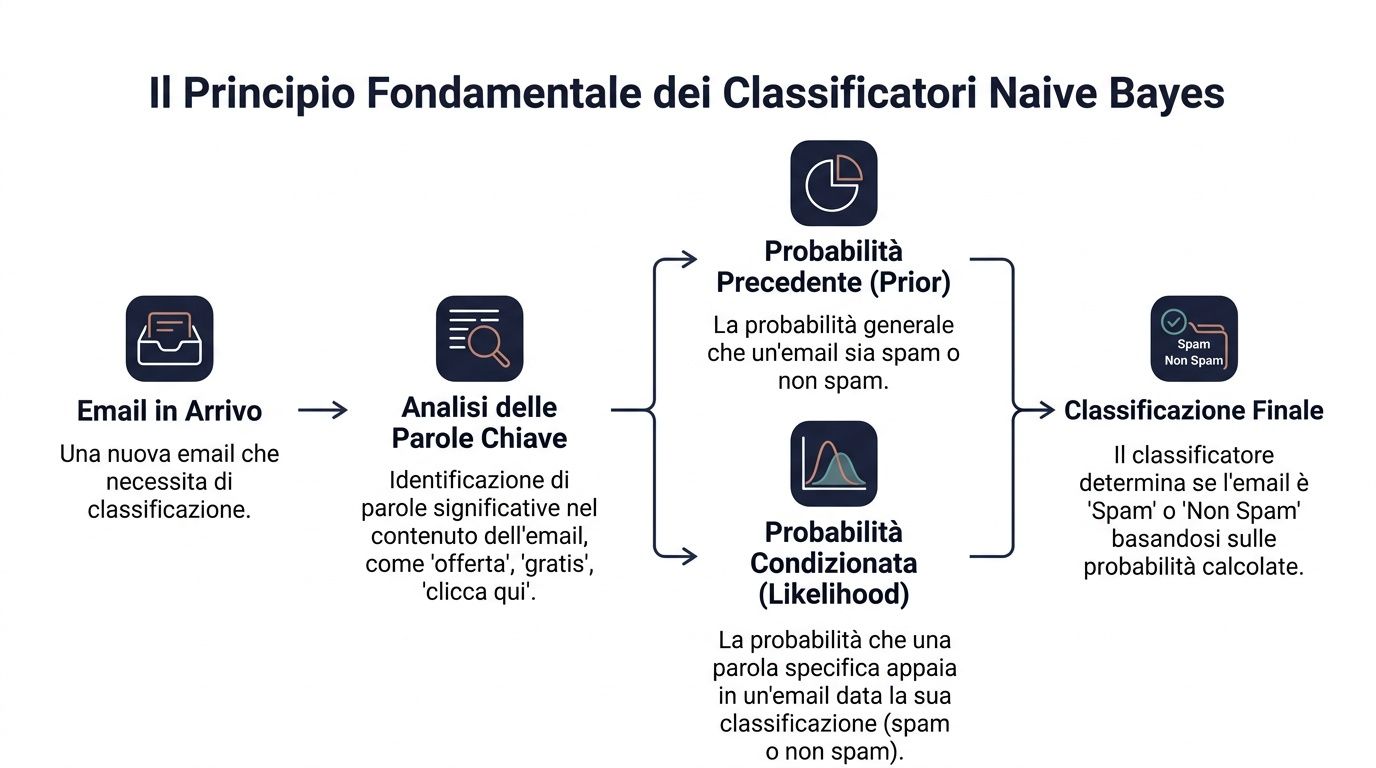
Un manager fa qualcosa di simile ogni giorno. Non decide mai nel vuoto. Parte da un contesto di base e aggiunge indizi. Un cliente che ha sempre acquistato regolarmente ha un certo profilo iniziale. Se poi smette di aprire le email, riduce il valore degli ordini e apre un ticket critico, la tua valutazione cambia.
Il termine naive indica un’assunzione precisa. Il modello tratta le feature come se fossero indipendenti tra loro, dato che la classe è nota.
In pratica, se stai classificando un’email, considera ogni parola come un indizio separato. Non prova a modellare tutte le relazioni complesse tra i termini. Questa è una semplificazione forte. Nella realtà, molte parole compaiono insieme e molti comportamenti aziendali sono correlati.
Eppure proprio questa scelta rende il modello molto leggero. Non deve imparare una rete intricata di dipendenze. Deve stimare probabilità più semplici e combinarle in modo efficiente.
Regola pratica: Naive Bayes non cerca di ricostruire l’intero mondo. Cerca di prendere decisioni utili con poche assunzioni e molta velocità.
Qui spesso nasce il fraintendimento. Molti leggono “assunzione ingenua” e concludono “modello debole”. Non è così. Un modello può semplificare molto e restare competitivo se la semplificazione coglie ciò che conta per il compito decisionale.
Nel 2004, un’analisi teorica ha mostrato ragioni solide per l’efficacia dei classificatori Naive Bayes nonostante l’assunzione di indipendenza, spiegando anche perché possono raggiungere l’errore asintotico più rapidamente della regressione logistica. Nello stesso filone di applicazioni, nel filtraggio spam raggiungono accuracy superiori al 99% e scalano su milioni di documenti, come riportato nella voce dedicata ai Naive Bayes classifier.
Questo punto è importante per un pubblico aziendale. Il valore di un algoritmo non sta solo nel punteggio finale. Sta anche nella capacità di addestrarsi rapidamente, adattarsi a dataset ampi e restare interpretabile.
Quando hai testi, categorie, etichette o segnali sparsi, i naive bayesian classifiers lavorano bene perché:
Ci sono però due punti da tenere a mente.
Per questo motivo Naive Bayes va visto come uno strumento molto efficace in problemi di classificazione veloci, non come una bacchetta magica universale. In molti contesti pratici, però, è uno dei modi più intelligenti per partire.
Un errore comune è parlare di Naive Bayes come se fosse un solo modello identico in ogni situazione. In realtà esistono varianti diverse, pensate per tipi di dati diversi.
La scelta giusta dipende dalla forma dei dati che hai in mano. Se sbagli variante, il modello può comunque produrre una previsione, ma non sta ragionando nel modo più adatto al tuo problema.
Gaussian Naive Bayes è la variante più adatta quando le feature sono continue. Pensa a importo medio di una transazione, età cliente, tempo medio tra due acquisti, margine unitario o valore dello scontrino.
Qui il modello assume che, dentro ogni classe, i valori seguano una distribuzione gaussiana. Non devi pensarlo come un vincolo accademico. Ti basta ricordare l’idea pratica: per ogni classe, il modello stima un centro tipico e una dispersione.
Questo approccio è utile quando vuoi classificare casi come:
Su un benchmark scikit-learn con un dataset simile a dati e-commerce italiani, un modello Naive Bayes ha raggiunto 95% di accuratezza con 1000 campioni, con un tempo di addestramento migliore della regressione logistica del 15%. Il confronto indicato è 0.01s vs 0.1s su CPU standard, grazie all’addestramento in forma chiusa, come mostrato nel capitolo di Jake VanderPlas su In Depth Naive Bayes Classification.
Per un’azienda, il punto non è il decimale. Il punto è che questa variante può dare risultati buoni senza tempi lunghi di training e senza un’infrastruttura pesante.
Se lavori con testi, ticket, recensioni o commenti, Multinomial Naive Bayes è spesso la scelta naturale. Qui le feature sono conteggi o frequenze. In pratica il modello guarda quante volte compaiono parole o termini.
È il classico scenario di:
Il motivo per cui funziona bene è molto concreto. Nei testi aziendali il vocabolario può essere ampio, ma ogni documento contiene solo una piccola parte delle parole possibili. Il dato è sparso. Multinomial Naive Bayes gestisce bene proprio questo tipo di struttura.
In uno studio su 100.000 tweet italiani etichettati per il sentiment, Multinomial Naive Bayes ha ottenuto un F1-score di 0.88 con uno speedup di 10 volte rispetto a SVM, come riportato nella guida di GeeksforGeeks sui Naive Bayes classifiers.
Per ricordarlo facilmente, pensa così: se il tuo dato somiglia a un documento pieno di parole contate, il multinomiale è quasi sempre il primo candidato da testare.
Se la tua azienda deve leggere grandi volumi di testo, la domanda non è solo “quanto è preciso il modello?”. È anche “quante richieste riesce a classificare senza rallentare il team?”.
Bernoulli Naive Bayes lavora con feature binarie. Non conta quante volte compare un segnale. Conta se è presente oppure assente.
Questa variante è utile quando la presenza di un attributo vale più della sua frequenza. Alcuni esempi aziendali:
È una logica molto utile quando vuoi trasformare fenomeni complessi in indicatori sì/no facili da monitorare. In analisi del sentiment, per esempio, può contare di più il fatto che una parola negativa appaia, non quante volte venga ripetuta.
Bernoulli non è “meno evoluto” del multinomiale. È semplicemente più adatto quando il dato descrive presenza o assenza. La differenza è piccola a parole, ma grande nei risultati.
| Variante | Tipo di Dati Ideale | Esempio di Caso d'Uso Aziendale |
|---|---|---|
| Gaussian Naive Bayes | Dati continui | Classificare transazioni per rischio usando importi, frequenza e valori medi |
| Multinomial Naive Bayes | Testi, conteggi, frequenze | Analizzare recensioni e ticket clienti per sentiment o categoria |
| Bernoulli Naive Bayes | Dati binari, presenza/assenza | Valutare segnali sì/no in compliance, supporto o product usage |
Per scegliere bene, usa una regola semplice:
Molti team si bloccano perché cercano il modello “migliore” in assoluto. La scelta corretta, quasi sempre, è il modello più coerente con il tipo di dato.
La buona notizia è che portare Naive Bayes in pratica non richiede un progetto monumentale. Anche un prototipo leggibile permette già di capire come ragiona il modello e quali dati gli servono.

Un classificatore nasce quasi sempre attraverso quattro passaggi.
Preparazione dei dati
Devi raccogliere esempi storici già etichettati. Se stai classificando recensioni, ti servono testi già marcati come positivi o negativi. Se stai analizzando rischio operativo, ti servono casi passati con esito noto.
Addestramento del modello
Il modello osserva i dati e stima le probabilità utili. Nei naive bayesian classifiers questo passaggio è rapido perché il training non richiede ottimizzazioni particolarmente pesanti.
Previsione su nuovi casi
Inserisci nuovi record e il modello assegna una classe. Per esempio “spam”, “non spam”, “cliente a rischio”, “cliente stabile”.
Valutazione
Confronti le previsioni con la realtà su un set di test separato. Qui non guardi solo se il modello funziona. Guardi come sbaglia.
Se vuoi approfondire il quadro generale degli approcci predittivi, questa panoramica sugli algoritmi di machine learning aiuta a collocare Naive Bayes dentro una famiglia più ampia di metodi.
Per rendere il processo concreto, ecco un esempio minimale con scikit-learn. Non serve leggerlo come sviluppatore. Basta capire il flusso.
# Importiamo gli strumenti principalifrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# Carichiamo un dataset di esempioX, y = load_iris(return_X_y=True)# Dividiamo i dati in parte per addestramento e parte per testX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Creiamo il modellomodel = GaussianNB()# Addestriamo il modello sui dati storicimodel.fit(X_train, y_train)# Facciamo previsioni su dati mai vistiy_pred = model.predict(X_test)# Misuriamo l'accuratezzaprint(accuracy_score(y_test, y_pred))Questo frammento dice molto più di quanto sembri.
GaussianNB() sceglie la variante per dati continui.fit() è il momento in cui il modello impara.predict() applica ciò che ha imparato.accuracy_score() verifica quante classificazioni sono corrette nel complesso.Per dati testuali, il flusso resta simile, ma prima del modello devi trasformare il testo in numeri. In pratica converti le parole in feature utilizzabili da un classificatore.
Dopo un primo sguardo al codice, può essere utile vedere una spiegazione visiva del meccanismo.
Il primo modello non serve a dimostrare perfezione. Serve a rispondere a tre domande operative.
Qui si vede la forza di Naive Bayes. Puoi arrivare rapidamente a un baseline solido. Da lì capisci se ha senso complicare il progetto o se una soluzione semplice sta già creando valore.
Un modello di classificazione non si giudica solo dal fatto che “sembra funzionare”. Si giudica da come sbaglia e da quanto quegli errori pesano nel business.

L’accuracy è la metrica più intuitiva. Dice quante previsioni sono corrette sul totale. È utile, ma da sola può ingannare.
Se su cento transazioni solo poche sono davvero sospette, un modello che classifica quasi tutto come normale può sembrare buono in accuracy e restare scarso dove serve davvero.
Per capirlo, pensa a una rete da pesca.
Nel business questa distinzione conta molto.
Un buon modello non è quello che sbaglia poco in generale. È quello che sbaglia nel modo meno costoso per il tuo processo.
Per comprendere meglio come un algoritmo apprende dai dati storici e perché la qualità dell’addestramento cambia il risultato finale, puoi leggere questo approfondimento su in cosa consiste l'addestramento di un algoritmo.
Naive Bayes è semplice, ma non perdona alcuni errori pratici.
Primo errore: ignorare il problema della frequenza zero.
Se una parola o un valore non compare mai nei dati di training per una certa classe, la probabilità può crollare a zero e compromettere il calcolo. Per questo si usa spesso lo smoothing di Laplace, che aggiunge un piccolo correttivo ai conteggi.
Secondo errore: usare feature fortemente correlate.
Se due colonne raccontano quasi la stessa informazione, il modello rischia di sovrastimare il segnale. Non “capisce” che i due indizi sono quasi duplicati.
Terzo errore: fidarsi troppo delle probabilità grezze.
Naive Bayes spesso classifica bene, ma le sue probabilità possono essere troppo sicure. Per il business questo significa che il ranking può essere utile, mentre il valore preciso della probabilità va interpretato con prudenza.
Per ridurre questi rischi, conviene:
Il vero valore dei naive bayesian classifiers emerge quando smetti di considerarli un esercizio matematico e inizi a usarli come motore di priorità. In azienda, classificare bene significa quasi sempre decidere meglio.

Pensa a un team finance che analizza flussi di transazioni, descrizioni operative e segnali storici. Ogni riga non è solo un record. È una decisione potenziale: lasciar passare, approfondire, bloccare, inoltrare a un analista.
Con Naive Bayes puoi combinare indicatori diversi in un’unica classificazione. Alcuni sono numerici, altri binari, altri testuali. Il modello aiuta a capire quali casi assomigliano di più a pattern già osservati come normali o anomali.
Il beneficio pratico è duplice:
Non sostituisce il giudizio umano nei contesti regolati. Lo organizza. E nei processi operativi ad alto volume questo fa una differenza reale.
Nel marketing, classificare significa spesso assegnare ogni cliente a un gruppo operativo. Fedeli. Sensibili al prezzo. A rischio churn. Reattivi alle promozioni. Dormienti.
Qui Naive Bayes è utile perché riesce a combinare segnali eterogenei in modo veloce:
Un team CRM non ha bisogno di una teoria perfetta del comportamento umano. Ha bisogno di una segmentazione abbastanza buona da attivare azioni sensate. Per esempio cambiare il messaggio, la frequenza di contatto o il tipo di offerta.
Quando un modello aiuta a scegliere il messaggio successivo per il cliente giusto, sta già creando valore operativo.
Nel retail e nell’e-commerce, la classificazione supporta attività che sembrano diverse ma condividono la stessa logica: ordinare il caos.
Puoi classificare prodotti in base al loro profilo di vendita. Puoi leggere recensioni e ticket per capire quali categorie generano attrito. Puoi riconoscere pattern di domanda che aiutano il team a pianificare promozioni e stock con più lucidità.
In questo tipo di ambiente i dati sono spesso numerosi, eterogenei e non sempre perfetti. Per questo un modello rapido, scalabile e leggibile ha grande valore. Non perché sia il più glamour, ma perché entra nel flusso di lavoro senza rallentarlo.
Se vuoi vedere come approcci di analytics applicati al business prendono forma in progetti concreti, puoi dare uno sguardo a questi casi di studio.
Capire Naive Bayes è utile. Implementarlo bene in un contesto aziendale è un’altra storia.
Il problema non è quasi mai solo l’algoritmo. Il lavoro vero sta attorno al modello. Devi collegare fonti dati diverse, gestire campi mancanti, preparare testi, aggiornare etichette, controllare la qualità degli output, leggere i risultati in modo comprensibile per chi decide.
Per una PMI, questo passaggio è spesso il punto critico. Non perché manchi l’interesse per l’AI, ma perché il tempo del team è limitato e le priorità operative non aspettano.
Qui ha senso usare una piattaforma che assorbe la complessità tecnica. Una soluzione AI-powered consente di trasformare dati grezzi in insight leggibili senza chiedere al business di scrivere codice, scegliere librerie o mantenere pipeline manuali.
Una piattaforma come Electe, un AI-powered data analytics platform for SMEs, rende accessibili metodi come i naive bayesian classifiers senza richiedere competenze specialistiche in machine learning. Il vantaggio non è solo la velocità. È la riduzione dell’attrito tra dato e decisione.
Quando l’automazione funziona bene, il team non ragiona più in termini di formule. Ragiona in termini di domande utili:
Questo è anche il motivo per cui sempre più aziende cercano strumenti che aiutino a leggere l’affidabilità dei contenuti generati dall’AI e dei segnali testuali che circolano nei processi interni. In questo contesto può essere utile consultare anche una guida su un AI detector italiano, soprattutto se il tuo team lavora con documenti, contenuti e verifiche linguistiche.
La differenza, in pratica, è semplice. Invece di gestire passaggi tecnici frammentati, porti il focus sul risultato aziendale. E questo è il punto in cui l’AI diventa davvero adottabile, non solo interessante.
I naive bayesian classifiers dimostrano una lezione importante. In analytics, la semplicità ben applicata può battere la complessità mal gestita.
Con una base probabilistica intuitiva, una buona scalabilità e casi d’uso molto concreti, questo approccio resta uno strumento affidabile per aziende che vogliono classificare informazioni, leggere segnali nascosti e agire con più sicurezza. Non serve essere specialisti di machine learning per capire il loro valore. Serve collegare la matematica alla decisione operativa.
Quando questo collegamento è chiaro, l’AI smette di essere un tema tecnico e diventa un vantaggio organizzativo. È lì che la previsione inizia a produrre impatto.
Se vuoi trasformare dati sparsi in insight chiari, prova Electe. La piattaforma aiuta le PMI a connettere fonti dati, automatizzare l’analisi e ottenere report e previsioni utili per decisioni più rapide e informate.

.svg)
.svg)
.svg)






