

É fácil encontrares-te nesta situação: tens um sistema de gestão, talvez um CRM, alguns ficheiros Excel que circulam por e-mail, e, entretanto, alguém te diz que, para «fazer análises a sério», tens de escolher entre um data lake e um data warehouse. Nessa altura, a conversa passa imediatamente para a tecnologia, mas o verdadeiro problema é outro. Precisas mesmo de uma nova arquitetura de dados, ou precisas simplesmente de tornar legíveis e úteis os dados que já tens?
Para uma PME, esta distinção é mais importante do que a terminologia. Uma escolha errada não gera apenas complexidade técnica. Gera projetos demorados, dependência de consultores, relatórios que chegam atrasados e investimentos que têm dificuldade em traduzir-se em melhores decisões. A escolha de não fazer nada, no entanto, deixa a empresa a navegar à vista.
A questão não é aprender a gíria dos fornecedores. A questão é perceber qual a solução mais adequada ao seu negócio, ao seu orçamento e às competências de que realmente dispõe internamente. Aqui encontra um guia prático para analisar o debate entre data lake e data warehouse com a perspetiva de quem precisa de equilibrar custos, acessibilidade e retorno operacional.
A pressão para «fazer algo com os dados» é hoje uma realidade. Os números aumentam, as fontes multiplicam-se, os gestores exigem previsões, painéis de controlo e alertas mais rápidos. Entretanto, surgem termos que parecem obrigar-nos a tomar uma decisão arquitetónica imediata.
Para muitas PME, porém, é precisamente aqui que reside o problema. Convencem-nos de que o primeiro passo é escolher entre dois modelos de infraestrutura, quando muitas vezes o verdadeiro problema é muito mais concreto: dados dispersos, formatos inconsistentes, relatórios manuais e ninguém com tempo para pôr ordem nisso tudo.
As perguntas importantes são outras. Tens realmente um problema de arquitetura? Ou tens um problema de acesso aos dados? Se escolheres a solução errada, corres o risco de financiar um projeto técnico em vez de melhorar o controlo sobre o negócio. Se não escolheres nada, continuas a tomar decisões com base em informações parciais.
Quem dirige uma PME não precisa de uma aula universitária. Precisa de um critério simples para perceber o que é necessário, o que não é, e onde se esconde o verdadeiro custo.
A diferença mais útil fica clara com duas imagens muito práticas.
Um data warehouse assemelha-se a uma biblioteca bem organizada. Cada livro chega já catalogado, classificado e colocado na prateleira correta. Quando se procura uma informação, encontra-se rapidamente porque a ordem já foi definida previamente. Um data lake, por outro lado, assemelha-se a um grande armazém onde chegam caixas de todo o tipo. Coloca lá dentro ficheiros ordenados, registos, PDFs, imagens, exportações do sistema de gestão, dados da web. A ordem aplica-se depois, quando precisas de os analisar.
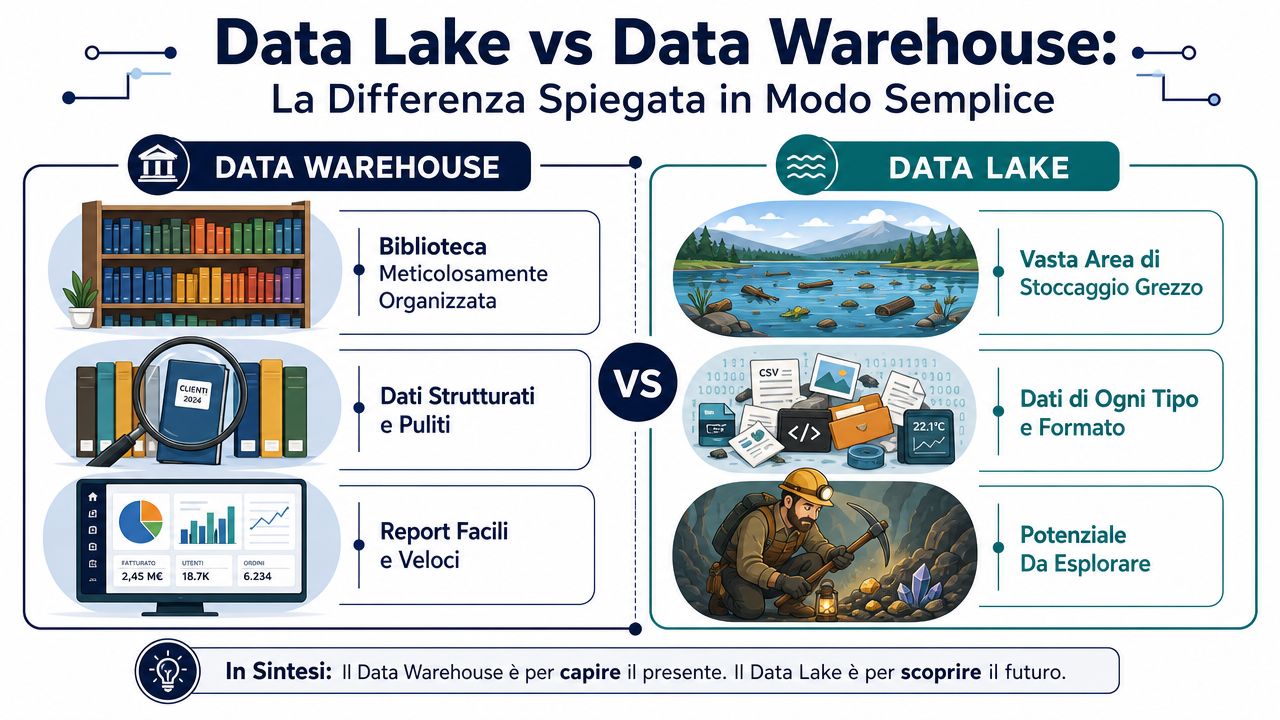
É aqui que entra o único pormenor técnico que vale realmente a pena referir.
Esta distinção resume também a sua origem histórica. O data warehouse surgiu para a análise empresarial de dados já limpos e estruturados, enquanto o data lake surgiu posteriormente para armazenar dados brutos em formatos heterogéneos. Por isso, o warehouse é mais adequado para relatórios e KPIs, enquanto o lake é mais flexível para exploração e aprendizagem automática, como explica esta análise sobre as diferenças entre data warehouse e data lake.
Um warehouse funciona bem para responder a perguntas já conhecidas. Um data lake é útil quando se sabe que os dados podem conter valor, mas ainda não se sabe de que forma.
Se o seu objetivo é conhecer as vendas, as margens, as encomendas, o stock, os atrasos, o desempenho comercial e as comparações mensais, o warehouse é, em termos conceptuais, mais adequado às suas necessidades. Proporciona-lhe uma base fiável para relatórios padrão, consultas SQL consistentes e dados fiáveis.
Se, por outro lado, trabalha com dados muito diferentes entre si, como registos de aplicações, PDFs, e-mails, textos, imagens ou fluxos de dados de máquinas, o data lake oferece maior liberdade. As equipas de TI podem centralizar fontes heterogéneas, enquanto os responsáveis pela elaboração de relatórios continuam a preferir ambientes estruturados para consultas rápidas e coerentes. Nesta lógica insere-se também o tema mais amplo das decisões baseadas em dados para as empresas, que exigem dados acessíveis antes mesmo de tecnologias sofisticadas.
No debate entre data lake e data warehouse, muitos confundem flexibilidade com utilidade imediata.
Um data lake pode conter quase tudo. Mas conter não significa que os dados fiquem imediatamente prontos para análise. Um data warehouse é menos flexível na fase de entrada, mas mais útil quando se quer respostas rápidas e padronizadas. Para uma PME, esta diferença tem mais peso do que a teoria. Porque o problema não é armazenar mais. É decidir melhor.
Duas empresas podem partir dos mesmos dados e obter resultados muito diferentes. A diferença, muitas vezes, não reside na quantidade de dados recolhidos, mas na forma como os organizam, preparam e tornam acessíveis aos responsáveis pela tomada de decisões.
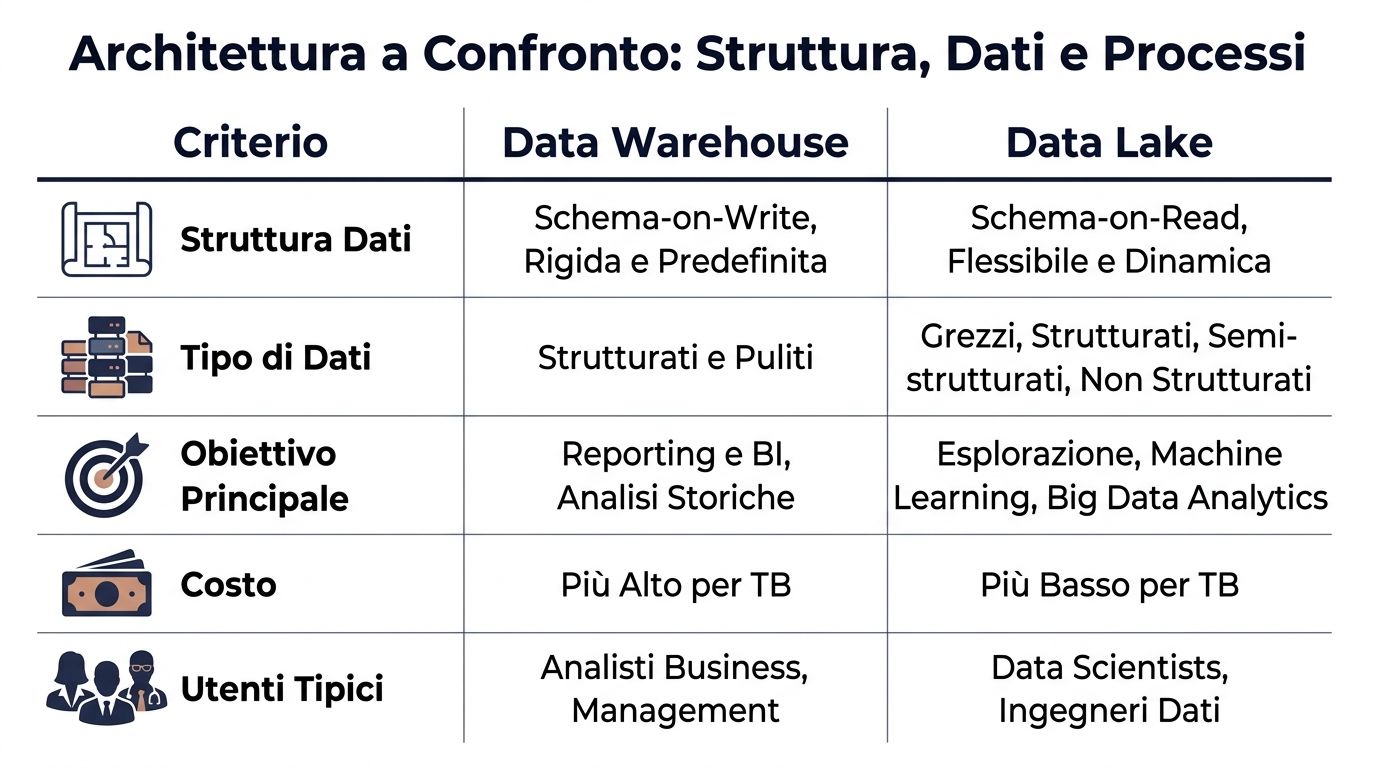
| Critério | Data Warehouse | Data Lake |
|---|---|---|
| Estrutura de dados | Esquema-on-write, definido antes do carregamento | Esquema na leitura, definido no momento da análise |
| Tipo de dados | Acima de tudo, organizados e arrumados | Estruturados, semiestruturados e não estruturados |
| Processo típico | ETL: processe primeiro e carregue depois | ELT: primeiro as cargas, depois as transformações |
| Utilizadores típicos | Analista de negócios, finanças, gestão | Engenheiro de dados, cientista de dados, equipas técnicas |
| Desempenho esperado | Mais previsíveis para a BI e o reporting | São mais variáveis, dependem da consulta e da preparação |
No data warehouse, o fluxo clássico é o ETL: extrai-se os dados, transforma-se e, por fim, carrega-se. Exige mais trabalho no início, mas reduz os atritos posteriormente. Quem consulta um painel encontra campos coerentes, definições estáveis e KPIs cujo significado não varia de um departamento para outro.
No data lake, o fluxo é frequentemente do tipo ELT: extrai, carrega e transforma apenas posteriormente, se necessário. Esta abordagem oferece maior liberdade técnica, mas adia uma parte do trabalho. Para uma pequena ou média empresa, adiar significa muitas vezes acumular tarefas que acabam por recair sobre a equipa no pior momento possível, ou seja, quando é necessária uma resposta rápida.
Regra prática: se várias pessoas tiverem de ler o mesmo documento e tomar decisões operacionais, a estrutura definida antes do carregamento reduz erros, discussões desnecessárias e perda de tempo.
A nível operacional, um data warehouse é concebido para consultas repetitivas, relatórios frequentes e painéis de controlo utilizados diariamente. Um data lake lida bem com grandes volumes e formatos diversos, mas os tempos de resposta e a facilidade de utilização dependem muito da forma como os dados foram catalogados, preparados e geridos. Uma comparação técnica publicada pela CloudOptimo resume bem este ponto: o warehouse aposta na previsibilidade, o lake na flexibilidade.
Para uma PME, esta questão não é meramente teórica. Se o responsável pelas vendas abrir o relatório matinal, quer números consistentes e respostas rápidas. Se, por outro lado, a equipa técnica tiver de analisar ficheiros, registos ou documentos heterogéneos, pode aceitar um maior tempo de resposta em troca de uma recolha de dados mais abrangente.
A diferença prática não é apenas técnica. O que muda é quem consegue utilizar os dados sem precisar de pedir ajuda todas as vezes.
Um armazém de dados bem estruturado aproxima os dados do negócio. Um lago de dados, por si só, aproxima-os mais frequentemente da equipa técnica. É por isso que muitas PME só mais tarde se apercebem de um ponto delicado: a verdadeira encruzilhada não está entre duas tecnologias, mas entre um sistema que torna os dados acessíveis e outro que os armazena sem os transformar em melhores decisões.
Quem analisa estas opções no âmbito de um projeto de modernização de TI deve ter em conta também o modelo operacional, e não apenas o repositório. As soluções em nuvem para PME ajudam a compreender precisamente esta transição: onde termina a infraestrutura e onde começam os custos, as competências necessárias e as responsabilidades diárias.
O data lake é frequentemente apresentado como a opção mais económica, pois armazena dados brutos e reduz o trabalho inicial. Isso é verdade apenas em parte. Se não houver um catálogo, regras de acesso, uma nomenclatura coerente e controlos mínimos de qualidade, a poupança inicial transforma-se em tempo perdido a procurar ficheiros, a reconstruir definições e a verificar quais os dados que são fiáveis.
Por isso, em muitas PME, a comparação correta não é «lake versus warehouse» em termos abstratos. A questão relevante é outra: será realmente necessário construir uma destas arquiteturas completas, ou será mais vantajoso começar por uma solução mais leve que proporcione insights rápidos, sem ter de lidar logo com toda a complexidade?
Para uma PME, o erro mais dispendioso resulta frequentemente de uma pergunta mal formulada: «O que sai mais barato, um data lake ou um data warehouse?». Na empresa, a verdadeira conta chega depois. Chega quando os dados não se comunicam entre si, os relatórios deixam de funcionar a cada mudança de sistema de gestão e todos os pedidos passam por consultores ou programadores, em vez de passarem pela equipa que deve tomar a decisão.

O armazenamento tem menos peso do que parece. O que pesa mais são as atividades que tornam os dados fiáveis e utilizáveis: modelação, integrações, permissões, qualidade, monitorização, correção de erros e apoio aos utilizadores.
Um data warehouse exige algum trabalho inicial. É necessário definir métricas, criar pipelines, alinhar as fontes e manter tudo organizado quando ocorrem mudanças no ERP, no CRM ou nas regras de negócio. Em troca, a gestão dispõe de dados mais estáveis e os relatórios tendem a tornar-se mais previsíveis.
Um data lake surge frequentemente com uma promessa mais simples. Carrega dados de diferentes tipos e adia parte das decisões estruturais. O problema é que esse adiamento não elimina o trabalho. Apenas o adia para mais tarde, onde se manifesta sob a forma de catalogação, segurança, custos de computação, duplicações, versões inconsistentes e verificações contínuas sobre quais dados são realmente fiáveis.
O risco, para uma PME, é ter de pagar duas vezes. Primeiro, para recolher os dados. Depois, para os tornar finalmente legíveis.
A verdadeira complexidade não é técnica. É operacional.
Se cada novo relatório exige intervenções manuais, se o controlador e o comercial utilizam definições diferentes para a mesma métrica, se o empresário tem de esperar dias para obter um número fiável, o projeto de dados já está a consumir margem. Mesmo que a infraestrutura, no papel, pareça moderna.
Por isso, convém avaliar também o modelo de gestão, e não apenas a arquitetura. As soluções em nuvem para PME ajudam precisamente a compreender esta diferença: o que está realmente a adquirir, que parte da manutenção continua a ser feita internamente e em que medida depende de competências especializadas todos os meses.
No mercado italiano, quem investe em análise de dados procura resultados visíveis. Redução do trabalho manual. Fechamento mais rápido de negócios. Melhor controlo sobre vendas, margens, stocks e fluxo de caixa. Não uma plataforma sofisticada que fica nas mãos de poucos.
Isto altera os critérios de escolha. Uma PME não deve questionar-se sobre qual a arquitetura mais atraente ou mais flexível em teoria. Deve questionar-se quanto tempo é necessário para obter painéis de controlo fiáveis, quantas pessoas são necessárias para os manter e com que rapidez o projeto gera valor.
No retalho, os custos ocultos rapidamente se tornam evidentes. Se as vendas, as devoluções, as promoções e os stocks provêm de sistemas diferentes, basta uma definição errada de «margem» ou «valor líquido vendido» para minar a confiança nos relatórios. Nessa altura, o problema não é a base de dados escolhida. O problema é que o proprietário volta a tomar decisões no Excel.
No setor financeiro, o custo do erro é ainda mais evidente. Relatórios, balanços, controlo de gestão e análise de desvios exigem dados coerentes e rastreáveis. Se cada revisão suscitar discussões sobre a origem dos números, o projeto perde o retorno sobre o investimento (ROI) antes mesmo de terminar.
Por isso, na prática, muitas PME não precisam de criar do zero um data lake ou um data warehouse completo. Precisam de um sistema mais leve, fácil de gerir e orientado para a tomada de decisões.
Se não conseguir manter a qualidade dos dados, as regras de acesso e as definições partilhadas ao longo do tempo, o problema não é a escolha entre um data lake e um data warehouse. O problema é ter adquirido complexidade antes de ter um caso de utilização que a justifique.
A questão não é saber qual a arquitetura que é «melhor» em termos absolutos. A questão é saber qual o problema que tens de resolver amanhã de manhã.

No setor do retalho, o armazém funciona bem quando é necessário responder sempre às mesmas questões operacionais:
O mesmo se aplica ao setor financeiro. Se precisar de consolidar dados estruturados, elaborar relatórios periódicos, analisar carteiras ou interpretar tendências económicas com base em critérios fixos, o armazém de dados continua a ser a escolha natural.
O «data lake» faz sentido quando a sua empresa recolhe dados muito diversos e não quer ou não consegue definir tudo antecipadamente.
Um caso realista é o de uma empresa do setor energético que combina:
Num contexto semelhante, um armazém de dados clássico obriga-o a definir antecipadamente as relações entre fontes que talvez ainda não conheça bem. Um data lake permite centralizar tudo e só atribuir uma estrutura quando for necessário para uma análise específica. É neste tipo de cenário que a flexibilidade do data lake cria verdadeiramente valor.
O data lake não é uma opção «mais moderna». Só faz sentido quando a variedade dos dados justifica a complexidade que isso implica.
A maioria das PME não se encontra nessa situação. Dispõe, sobretudo, de dados provenientes de sistemas ERP, CRM, comércio eletrónico, contabilidade, exportações CSV e Excel. Nestes casos, o problema não é gerir ficheiros de vídeo, registos de aplicações ou texto livre em grande escala. O problema é dispor de dados limpos, coerentes e compreensíveis para pessoas sem conhecimentos técnicos.
É preciso deixar isto bem claro: muitas vezes, não é necessário nem um data lake nem um data warehouse tradicional.
O que é necessário, pelo contrário, é:
O lakehouse procura unir os dois mundos. Promete a flexibilidade do lake e algumas das qualidades do warehouse num único ambiente. É uma abordagem interessante, sobretudo para empresas com cargas de trabalho mistas que incluem BI, IA e ciência de dados.
Para uma PME, porém, a questão permanece a mesma: tens realmente um problema que justifique tudo isto? Se o teu objetivo é compreender melhor as vendas, as margens, o fluxo de caixa ou as previsões, uma solução híbrida sofisticada pode ainda ser desproporcionada em relação ao valor esperado.
O data lakehouse surgiu para superar a separação rígida entre o lake e o warehouse. A ideia é simples: manter a flexibilidade de um armazenamento amplo e aberto, mas acrescentar ordem, desempenho e capacidades analíticas mais próximas das de um warehouse. Tecnologias como o Databricks e o Delta Lake representam bem esta tendência.
Em teoria, é muito atraente. Utiliza-se a mesma base de dados para BI, análise avançada e aprendizagem automática, evitando a duplicação excessiva de informações entre sistemas diferentes. Para grandes organizações, ou para equipas de dados experientes, é uma resposta lógica a um ecossistema que se tornou mais complexo ao longo do tempo.
Nos benchmarks académicos, a arquitetura data lakehouse é avaliada com métricas como débito, latência e sobrecarga de metadados. Isto demonstra que a comparação com o data warehouse não é apenas funcional, mas também em termos de desempenho, em cenários em que pequenas diferenças de desempenho têm um impacto significativo, como destaca esta apresentação académica sobre benchmarks de lakehouse.
Traduzido para a linguagem empresarial: o Lakehouse resolve problemas de organizações que já possuem um certo nível de escala, complexidade e especialização.
Se não precisavas realmente nem de um data lake nem de um data warehouse, é improvável que precises de um sistema que combine ambos.
Para a maioria das PME, a pergunta mais útil não é «que arquitetura devo escolher?», mas sim «como posso obter análises fiáveis sem transformar o projeto de dados num canteiro de obras permanente?».
Esta é a terceira abordagem que falta em muitas comparações entre data lake e data warehouse. Não construa uma nova infraestrutura proprietária. Em vez disso, implemente uma camada de análise sobre os sistemas que já utiliza, transferindo a complexidade técnica para fora do âmbito operacional da empresa.

Na prática, a abordagem mais sensata é esta:
Já vi mais do que uma PME investir meses num armazém tradicional e depois utilizá-lo muito pouco. Não porque estivesse mal construído. Mas porque ninguém na empresa sabia consultar os dados de forma autónoma. O estrangulamento não era a base de dados. Era a acessibilidade.
Este é um aspeto que muitas vezes é subestimado. Uma arquitetura sofisticada que exige sempre um intermediário técnico diminui o valor prático dos dados. Uma solução mais simples, mas compreensível para a gestão, muitas vezes leva a melhores decisões mais rapidamente.
É por isso que muitas empresas obtêm mais valor de um software de business intelligence para PME bem concebido do que de um programa de infraestrutura sobredimensionado. O resultado que procuram não é possuir um data warehouse. É compreender o negócio melhor e mais rapidamente.
A infraestrutura certa é aquela que a tua equipa consegue utilizar, manter e transformar em decisões. Não aquela que impressiona numa apresentação técnica.
O debate entre data lake e data warehouse é útil, mas, para uma PME, parte frequentemente da pergunta errada. Antes de escolher uma arquitetura, é preciso perceber se existe realmente um problema de escala e variedade dos dados, ou se se trata de um problema muito mais comum: dados dispersos, relatórios manuais e acessibilidade limitada.
O data warehouse continua a ser a melhor opção quando são necessários relatórios fiáveis, KPIs consistentes e um desempenho previsível. O data lake faz sentido quando a variedade de fontes justifica uma maior flexibilidade e complexidade. O lakehouse é uma evolução interessante, mas raramente é o primeiro passo certo para uma empresa que procura, acima de tudo, controlo operacional e retorno do investimento.
A escolha mais inteligente não é a tecnologia mais avançada. É aquela que se adapta ao problema real, às competências disponíveis e à rapidez com que pretende transformar os dados em decisões.
Se pretende transformar os dados da sua empresa em relatórios, previsões e insights operacionais sem ter de criar uma infraestrutura complexa, descubra a ELECTE, uma plataforma de análise de dados baseada em IA para PME. Pode partir dos dados de que já dispõe, reduzir o trabalho manual e tornar a análise de dados acessível à sua equipa com uma abordagem muito mais ágil.

.svg)
.svg)
.svg)






