

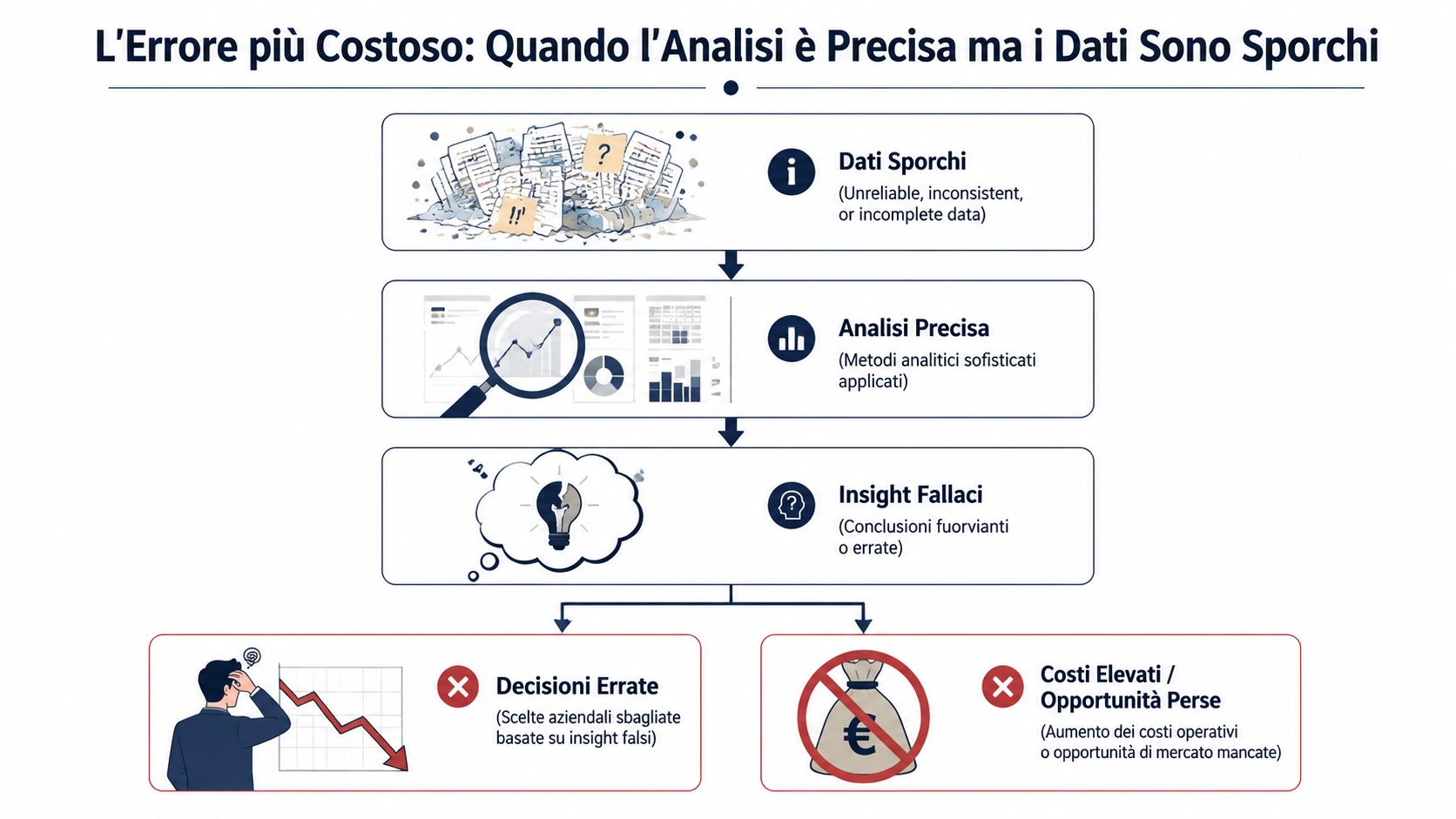
Veja o relatório de vendas do mês. As receitas parecem ter aumentado, a margem parece ter melhorado, mas há aquela sensação incómoda de que algo não bate certo. Não é paranóia. É experiência operacional. Quem trabalha numa PME italiana sabe que, entre o software de gestão, as exportações para o Excel e as alterações manuais, os dados mudam de forma várias vezes antes de chegarem a um painel de controlo.
A questão é simples: uma análise impecável baseada em dados errados não te ajuda. Engana-te. Dá-te uma resposta precisa, elegante e tranquilizadora, mas construída sobre bases frágeis. E é muito mais perigosa do que um relatório incompleto, porque leva-te a tomar decisões com segurança quando essa segurança não existe.
As técnicas de validação de dados servem precisamente para isso: revelar os erros. Não tornam os dados «perfeitos». Tornam visíveis os problemas que, atualmente, passam despercebidos. Se gere a administração, o controlo de gestão, as vendas ou as operações, este é o trabalho que distingue um número utilizável de um número meramente decorativo. E nas PME, vale mais do que muitas iniciativas «avançadas» de análise de dados, porque os benefícios são imediatos, muitas vezes já a partir do primeiro import.
Nas PME, os números raramente surgem no local onde são analisados. Passam de um sistema de gestão para um ficheiro exportado, depois para o Excel e, por fim, para uma versão «ajustada» por alguém que só tinha de corrigir duas colunas e acabou por reescrever metade da folha. Quando o relatório final não convence, o problema muitas vezes não é o gráfico. É tudo o que aconteceu antes.
A validação de dados é o tema menos apelativo e mais importante de todo o ciclo analítico. Nenhum empresário quer discutir sobre controlos de formato ou campos obrigatórios em falta. No entanto, quase todas as decisões erradas tomadas com base em painéis de controlo aparentemente limpos têm origem aí. Num separador decimal alterado, numa data mal interpretada, numa duplicação na base de dados, num total que não bate certo, mas que ninguém verificou.
Quem trabalha bem com dados desenvolve um hábito específico: antes de se perguntar o que os números dizem, questiona-se se esses números são fiáveis. As melhores técnicas de validação de dados não são as mais sofisticadas. São aquelas que detetam rapidamente os erros mais comuns, sem atrasar o trabalho diário.
Se não confias nos dados o suficiente para tomares uma decisão importante, o problema não é a decisão. É a validação.
O erro típico não é um relatório manifestamente incorreto. É um relatório organizado, aparentemente coerente, elaborado com base em dados que já perderam a sua fiabilidade. Quando isso acontece, o problema não reside apenas no número errado. Reside no facto de ninguém o questionar.
Esta área evoluiu bastante. A validação de dados passou de um controlo predominantemente manual para verificações automatizadas e estatísticas. As melhores práticas distinguem, pelo menos, cinco controlos básicos: verificação do tipo de dados, verificação de código, verificação de intervalo, verificação de formato e verificação de consistência, tal como resumido pela Teradata na sua visão geral sobre a validação de dados. Em Itália, esta evolução tem ainda mais peso em contextos regulamentados, onde mesmo um único campo errado pode alterar relatórios, modelos de previsão ou cumprimento de obrigações.
O primeiro erro é limitar-se à superfície. Muitas empresas limitam-se a fazer apenas a verificação mais simples, a sintática.
Um código fiscal bem escrito pode ultrapassar a primeira barreira e falhar na segunda. O total de uma fatura pode ser numérico e estar no formato correto, mas se não corresponder à soma das linhas, tem-se um problema muito mais grave do que o simples formato.
Regra prática: uma verificação que analisa apenas uma coluna deteta erros triviais. Uma verificação que relaciona vários campos deteta os erros que influenciam as decisões.
A validação eficaz não ocorre no final do trabalho. Ocorre antes. Se esperares pelo relatório final, o erro já terá sido transformado, agregado, copiado para outros ficheiros e discutido numa reunião. Nessa altura, corrigi-lo custa atenção, tempo e credibilidade.
Isto é ainda mais verdade quando se começa a utilizar métodos mais sofisticados, como a deteção de anomalias ou a gestão de valores atípicos. São ferramentas úteis, mas não substituem os controlos básicos. Se uma coluna importada como texto contiver preços, não é necessário um modelo complexo. É necessário um filtro básico que bloqueie o erro logo na entrada.
Uma boa análise não começa com painéis mais bonitos. Começa com dados que passaram por uma série de testes rigorosos, logo que entram no fluxo.
Na prática quotidiana das PME, a maior parte do valor provém de controlos simples. Não das técnicas académicas mais refinadas. Não de processos sofisticados que ninguém irá manter. Mas de regras claras, repetíveis, próximas do ponto em que os dados entram efetivamente na empresa.

No contexto italiano, esta abordagem está em consonância com a abordagem do ISTAT, que define a qualidade dos dados através de dimensões como a exatidão, a coerência e a exaustividade e utiliza o controlo VIMO (Valid, Invalid, Missing, Outlier) para medir valores válidos, em falta e anómalos. A abordagem prevê a validação na entrada, durante a transformação e antes da utilização final dos dados, tal como explicado no material do ISTAT sobre a qualidade e a validação dos dados.
O processo típico é sempre o mesmo. Os dados são gerados no sistema de gestão. São exportados. Passam para o Excel. Alguém corrige um cabeçalho, arrasta uma fórmula, copia uma coluna, altera o formato da data «para arranjar tudo». A partir daí, começam os erros silenciosos.
Eis as medidas de controlo que convém implementar imediatamente:
Se trabalhas com exportações manuais, podes começar com um esquema muito concreto:
| Controlo | Erro típico nas PME | Pergunta que deves fazer a ti próprio |
|---|---|---|
| Tipo | Preço da cama como texto | É possível calcular esta coluna? |
| Formato | Datas mistas entre formatos diferentes | O sistema interpreta-a sempre da mesma forma? |
| Gama | Valores fora da escala | Este valor é plausível para o cliente ou para o produto? |
| Exclusividade | Cliente introduzido várias vezes | Estou a contar pessoas diferentes ou nomes escritos de forma diferente? |
| Exaustividade | Campos-chave em branco | Posso utilizar este registo em relatórios e decisões? |
| Coerência | Totais que não batem certo | As colunas confirmam-se mutuamente? |
Para quem trabalha em setores onde a qualidade documental e processual já tem um peso operacional significativo, vale a pena analisar também práticas mais estruturadas de qualificação e controlo. Uma leitura útil é o Guia de qualificação em setores regulamentados, pois ilustra bem que a disciplina da validação não se resume apenas à «limpeza», mas sim ao controlo do processo.
Os registos duplicados merecem uma menção à parte. Constituem um problema crónico nas bases de dados de muitas PME e distorcem praticamente tudo: clientes ativos, frequência de compra, exposição comercial e histórico de relações. Se quiser partir de um caso concreto, encontrará uma abordagem prática no ELECTE: guia completo sobre registos duplicados no Excel.
Os controlos sofisticados só são úteis depois de se terem estabelecido as bases. Caso contrário, é como instalar um radar num carro sem travões.
Segunda-feira de manhã, reunião comercial. O proprietário analisa o relatório de vendas, o responsável administrativo analisa outro ficheiro e o controlador tem um terceiro. Os números deveriam coincidir. Mas não coincidem.
É uma situação comum nas PME italianas. Um sistema de gestão antigo exporta ficheiros CSV com campos rígidos. O CRM utiliza etiquetas diferentes. O comércio eletrónico tem a sua própria lógica. Depois entra em cena o Excel, que se torna o ponto onde alguém ajusta os cabeçalhos, copia colunas, corrige datas e tenta fazer com que tudo encaixe antes da reunião.
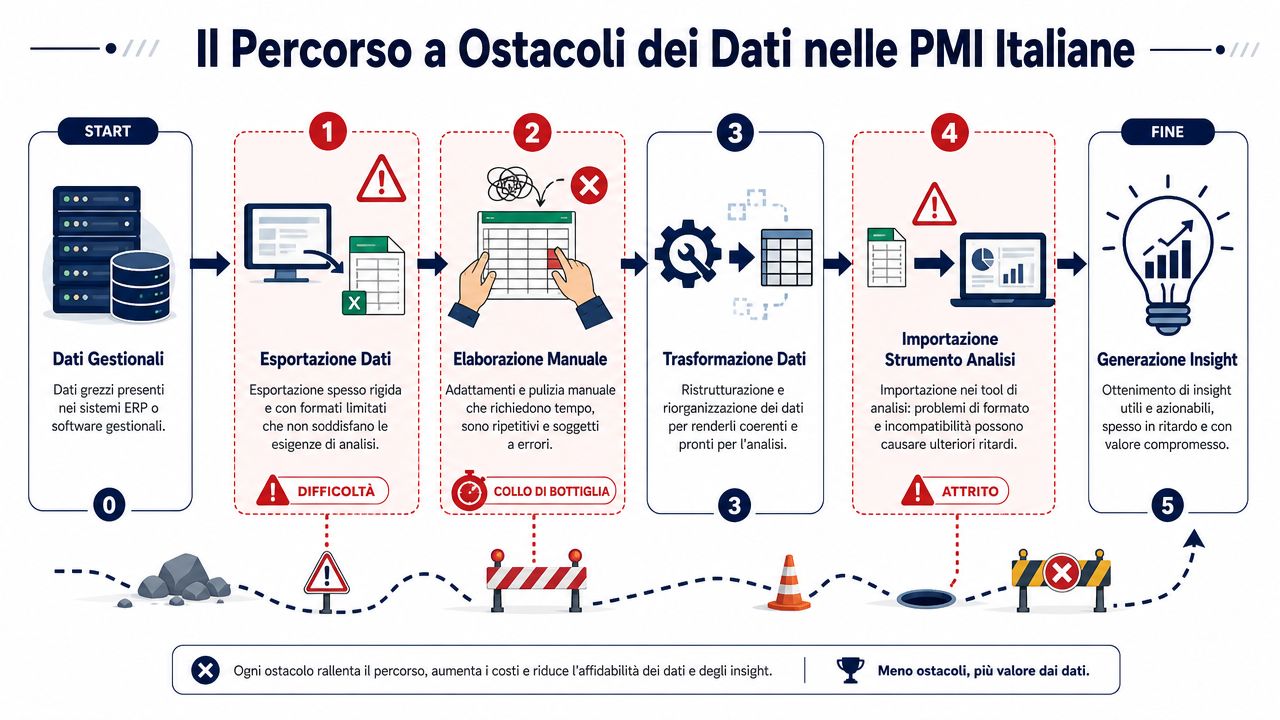
O problema não é a tecnologia em si. O problema é a soma de pequenas etapas manuais aplicadas a dados provenientes de sistemas criados em momentos diferentes, muitas vezes sem uma regra comum. Quem trabalha com a ligação de várias fontes de dados percebe isso imediatamente: cada fonte traz consigo convenções, erros recorrentes e campos preenchidos «como dá na sorte».
Os erros mais dispendiosos não interrompem o processo. São registados no ficheiro e permanecem lá.
Acontece todos os dias em contextos muito concretos:
Nesta área, muitas empresas cometem o mesmo erro. Procuram soluções sofisticadas antes de terem garantido a segurança dos controlos mais simples, mas lucrativos: tipos de dados corretos, chaves coerentes, códigos preservados e datas legíveis de forma idêntica por todos os sistemas.
Nas PME, os dados raramente surgem limpos e estáveis. Passam pela administração, pelas vendas, pela logística, por consultores externos e por ficheiros locais com nomes como «report_finale_def_vero.xlsx». Cada pessoa corrige o que precisa para trabalhar. Quase ninguém documenta a alteração.
É por isso que as verificações académicas ou os projetos de deteção de anomalias demasiado ambiciosos acabam muitas vezes por surgir na altura errada. Primeiro, é preciso ter rigor nos aspetos fundamentais. Uma verificação automática que sinalize CAP inválidos, códigos de cliente incompletos, linhas duplicadas ou datas fora do período evita mais erros do que muitas iniciativas «avançadas» lançadas demasiado cedo.
Digo isto de forma direta porque é o problema que vejo com mais frequência: uma PME não perde a confiança nos dados por falta de inteligência artificial. Perde-a porque o próprio volume de negócios varia de um ficheiro Excel para outro, e ninguém sabe dizer qual é a versão correta.
O ficheiro que «sempre funcionou» é, muitas vezes, aquele que já ninguém verifica.
Quando os dados passam por várias mãos e vários sistemas, a validação não tem de ser elegante. Tem de ser repetível, monótona e realizada logo na fase de introdução dos dados. É aí que se obtém grande parte do valor, antes mesmo de se falar de modelos preditivos ou de painéis de controlo mais apelativos.
As segundas-feiras de manhã começam frequentemente assim. O responsável administrativo abre dois ficheiros de exportação do mesmo mês, um do sistema de gestão e outro do ficheiro comercial, e os totais não batem certo. Ninguém tem tempo para refazer as verificações manualmente. Nessa altura, o problema não é o relatório. É que a confiança nos números já se quebrou.
A ELECTE intervém antes de os dados não validados entrarem na análise. Para uma PME italiana, é esse o ponto que realmente importa. Não serve de nada uma máquina complicada que promete controlos sofisticados se, depois, deixa passar erros banais de importação, colunas mal interpretadas ou códigos que mudam de formato de um sistema para outro.
Na prática, a plataforma verifica os dados à medida que estes vão chegando. Não depois do relatório. Não depois da reunião em que alguém pergunta por que razão a margem mudou de uma versão do ficheiro para outra.
As verificações automáticas abrangem os problemas que, nas PME, causam mais danos do que o previsto: tipos de dados incoerentes, campos em falta, datas fora do período, duplicados, valores fora do intervalo, chaves que não se associam às tabelas corretas. São verificações pouco glamorosas, mas são estas que evitam a maioria dos erros operacionais em contextos repletos de exportações do Excel, sistemas ERP desatualizados e ficheiros enviados por e-mail.
Depois, há o nível contextual. No onboarding, definem-se regras coerentes com o processo empresarial real, e não com um modelo teórico. Uma empresa do setor da distribuição tem necessidades diferentes das de um escritório que gere presenças turísticas ou de um fabricante com tabelas de preços e descontos estratificados. O mesmo se aplica a casos documentais específicos, como a leitura de dados estruturados a partir de documentos e check-ins, um tema relevante também para quem trabalha com MRZ em estruturas de alojamento.
A vantagem prática é simples: a equipa não tem de decidir de cada vez quais os controlos a realizar. Encontra-os já aplicados de forma coerente e repetível.
Um exemplo típico. Uma atualização do sistema de gestão altera o formato de alguns campos de preço apenas numa parte do ficheiro de exportação. À primeira vista, o ficheiro parece estar correto. No entanto, após análise, esses valores alteram o volume de negócios, as margens e as comparações com os meses anteriores. O ELECTE sinaliza imediatamente a anomalia, isola as linhas afetadas e permite corrigi-las antes de estas chegarem aos painéis de controlo e aos relatórios de gestão.
Um dos aspetos mais úteis, para quem tem de tomar decisões e não se dedica à ciência de dados, é a gestão de exceções. Os registos problemáticos não desaparecem. Permanecem visíveis, separados e com a respetiva justificação.
Quem utiliza os dados percebe logo:
Esta transparência evita um dos piores hábitos que vejo nas PME: limpar o conjunto de dados sem deixar rasto e descobrir, semanas depois, que os números já não batem certo.
A função de ligar várias fontes de dados tem valor precisamente por esta razão. Não basta ligar o CRM, o ERP, o comércio eletrónico e os ficheiros manuais. Se os dados forem integrados sem controlos claros, o caos mantém-se, apenas numa tela mais organizada.
A ELECTE não promete dados perfeitos. Reduz os erros mais frequentes, torna-os visíveis e impede que sejam incluídos nos relatórios como se fossem corretos. Para uma PME, muitas vezes é isto que faz a diferença entre discutir números e discutir sobre os números.
A validação não deve ser tratada como um projeto técnico separado da atividade empresarial. Deve ser tratada como uma disciplina operacional. Quem elabora um orçamento, aprova uma tabela de preços, revê as margens ou planeia as compras já está a utilizar dados bem validados ou mal validados. Não existe uma terceira opção.
As regras úteis são poucas, mas devem ser aplicadas com consistência:
Válido na entrada, mas não a jusante
Se a verificação chegar ao fim, o erro já terá afetado fórmulas, agregações e relatórios.
Não te limites ao formato
. Um dado pode estar bem escrito e, mesmo assim, estar errado. Tens de verificar a plausibilidade e a coerência entre os campos, e não apenas o cumprimento de um esquema.
Automatize as verificações repetitivas
Nenhuma equipa administrativa ou comercial tem tempo para rever manualmente cada exportação. As verificações básicas têm de se tornar sistemáticas.
Evite regras demasiado rígidas
Existe um equilíbrio real entre rigor e produtividade. Regras demasiado restritivas podem reduzir a adoção de ferramentas analíticas por parte de equipas não técnicas, tal como a Acceldata salienta na sua reflexão sobre o compromisso na validação de dados. O limiar certo é aquele que minimiza os erros sem atrasar o negócio.
Encarem as exceções como sinais, não como incómodos
Um registo anómalo revela quase sempre algo sobre o processo que o gerou. Ignorá-lo significa abdicar de melhorar a montante.
Um exemplo útil surge em áreas em que o formato não é um pormenor, mas sim uma condição essencial para o funcionamento. Nas estruturas de acolhimento, por exemplo, a questão da leitura automática de documentos ilustra bem até que ponto os dados devem não só estar presentes, mas também ser coerentes com uma norma interpretável. Quem desejar uma referência concreta pode ler este artigo aprofundado sobre MRZ para estruturas de acolhimento.
A mentalidade correta é esta: só confie nos dados depois de os ter testado. Se hoje se baseia em ficheiros que ninguém verifica de forma estruturada, não está a fazer uma análise. Está apenas a esperar.
A maioria dos problemas nos relatórios não surge no último gráfico. Surge muito antes, quando dados incompletos, incoerentes ou fora de contexto entram nos sistemas sem um filtro rigoroso. É por isso que as técnicas de validação de dados são mais importantes do que parece. São o ponto em que se deixa de ser dominado pelos dados e se começa a controlá-los.
Para uma PME, o benefício não está em perseguir a perfeição. Está em construir um nível de confiança suficiente para tomar decisões com lucidez. Controlos de tipo, formato, intervalo, unicidade, integridade e coerência cruzada resolvem grande parte dos problemas reais. A automatização torna estes controlos sustentáveis.
Se não tiveres um processo de validação estruturado, não estás a confiar nos dados. Estás a confiar na sorte.
Se pretende transformar exportações confusas, ficheiros Excel instáveis e fontes de dados heterogéneas em análises fiáveis, descubra como a ELECTE, uma plataforma de análise de dados baseada em IA para PME, automatiza verificações, deteta anomalias e fornece insights sem aumentar a complexidade para a sua equipa.

.svg)
.svg)
.svg)






