

Já estás a enfrentar o problema que a Computação de Alto Desempenho resolve, mesmo que talvez não lhe chames assim. Tens uma previsão que demora demasiado tempo a ser processada. Um relatório chega quando o contexto já mudou. Um modelo promissor de procura, risco ou preços fica paralisado, não por falta de dados, mas porque o tempo de cálculo o torna pouco útil para o negócio.
Para muitas PME, o desafio já não é recolher informação. O desafio é transformá-la em decisões atempadas. É aqui quea Computação de Alto Desempenho deixa de parecer um tema de laboratório e passa a ser uma questão de gestão: quantas simulações se consegue realizar, com que rapidez se consegue atualizar uma previsão, quantas alternativas se conseguem comparar antes de o mercado obrigar a escolher.
Em Itália, o tema tem também um peso estratégico a nível nacional. O supercomputador Leonardo do CINECA, inaugurado em Bolonha em 2022 no âmbito do EuroHPC, foi apresentado, aquando da sua instalação, como um dos sistemas mais potentes do mundo, o que demonstra que a HPC é, atualmente, um fator determinante para a indústria e a investigação aplicada, e não apenas para o meio académico (contexto do mercado da HPC e do Leonardo).
Segunda-feira de manhã. O diretor comercial pede uma nova previsão até ao final da tarde, a cadeia de abastecimento quer rever os níveis de stock antes de confirmar as encomendas e a equipa financeira exige um cenário prudente e outro agressivo para a reunião do dia seguinte. Os dados estão disponíveis. O problema é o tempo necessário para os analisar devidamente.
A Computação de Alto Desempenho serve precisamente para isso: executar muitos cálculos complexos ao mesmo tempo, de modo a obter respostas úteis quando estas ainda são necessárias. Para uma PME, o que importa não é possuir um supercomputador. O que importa é evitar que análises lentas atrasem decisões que têm um impacto direto nas margens, no serviço e no inventário.
Um sistema tradicional executa o trabalho de forma mais linear. O HPC distribui a carga de trabalho por várias recursos coordenados, tal como faria uma equipa bem organizada perante um prazo apertado. O resultado não é apenas a velocidade. É a possibilidade de testar mais hipóteses, atualizar as previsões com maior frequência e tomar decisões com menos margem de erro.
Na ELECTE, vemos isso em contextos muito concretos. Uma previsão recalculada mais rapidamente ajuda a reduzir a falta de stock e o excesso de stock. Um motor de otimização mais rápido permite comparar diferentes cenários antes de alocar orçamentos, stocks ou capacidade operacional. Na prática, o cálculo torna-se uma alavanca de gestão, e não uma questão da área de TI.
O HPC é importante quando o atraso numa análise custa mais do que a sua execução em paralelo.
Um equívoco frequente entre os gestores é associar a HPC apenas a enormes volumes de dados. Nas decisões empresariais, muitas vezes o limite surge antes, quando a complexidade do problema a resolver aumenta.
Isso acontece, por exemplo, quando um conjunto de dados, que, no geral, é fácil de gerir, tem de alimentar cálculos muito mais complexos do que a simples elaboração de relatórios. Alguns casos típicos são os seguintes:
Neste caso, a pergunta certa não é «quantos dados tenho?». É «quanto custa tomar uma decisão com base num modelo simplificado ou com resultados que chegam demasiado tarde?».
Do ponto de vista técnico, a HPC combina muitos recursos de computação para lidar com processamentos que uma única máquina demoraria mais tempo a realizar ou que apresentariam mais limitações. Do ponto de vista de uma PME, a tradução é mais simples: previsões disponíveis mais cedo, simulações mais frequentes, planos de stock melhor ajustados e menos tempo de espera entre um pedido de informação e uma resposta fiável.
E é aqui que a perspetiva muda em relação aos conteúdos mais académicos sobre o tema. Para uma pequena ou média empresa, a HPC não significa entrar no mundo dos centros de investigação. Significa utilizar uma capacidade de computação escalável para resolver problemas empresariais complexos, sem ter de criar do zero uma equipa de engenheiros ou uma infraestrutura difícil de gerir. É o tipo de abordagem que plataformas como a ELECTE tornam viável mesmo fora das grandes empresas.
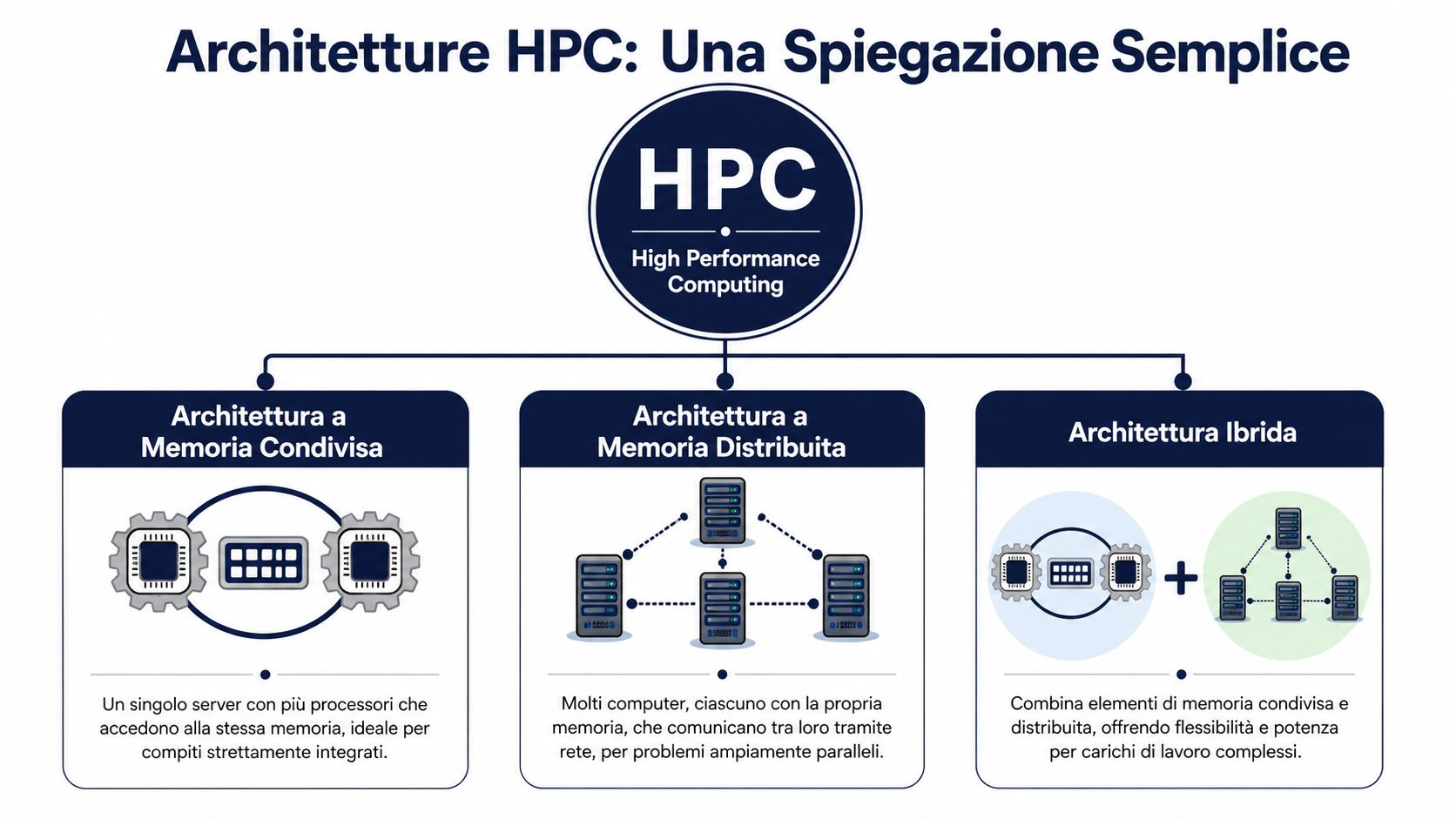
O HPC funciona graças à colaboração de vários componentes. Os três termos que realmente importam são «cluster», «GPU» e «cloud».
Um cluster reúne várias máquinas, denominadas nós, para executar a mesma tarefa em paralelo. Na prática, uma tarefa demasiado pesada para um único servidor é dividida em partes mais pequenas e atribuída a vários nós coordenados entre si. Para um gestor, a questão não é técnica, mas sim operacional: menos tempo de espera entre o pedido de uma análise e uma decisão sobre stocks, preços ou previsões.
No ELECTE, este princípio é útil, por exemplo, quando uma empresa precisa de recalcular previsões para várias combinações de produto, ponto de venda e período. Se o trabalho ficar concentrado numa única máquina, os tempos aumentam e a equipa tende a realizar menos simulações. Se a carga de trabalho for distribuída, torna-se viável comparar vários cenários no mesmo ciclo de decisão.
As GPUs servem para outro tipo de aceleração. São muito eficazes quando o mesmo tipo de cálculo tem de ser repetido inúmeras vezes, como acontece na aprendizagem automática, em algumas otimizações e em parte da análise avançada. O resultado para o negócio é concreto: treinar ou testar modelos mais rapidamente, atualizar as previsões mais cedo e reduzir o tempo que separa uma hipótese de uma verificação.
A nuvem HPC confere elasticidade à capacidade de computação. Em vez de adquirir recursos concebidos para o pico máximo do ano, a empresa pode ativá-los nos momentos em que são realmente necessários. Para uma PME, isso representa frequentemente a diferença entre ter de renunciar a uma análise complexa e realizá-la no momento certo, sem ter de construir internamente uma infraestrutura difícil de manter. Se quiser compreender melhor como se enquadram estes modelos de prestação de serviços, esta análise aprofundada sobre IaaS, PaaS e SaaS na nuvem pode ser útil.
Na prática empresarial, a melhor opção raramente passa por uma única arquitetura. O mais importante é combinar bem os recursos.
Um ambiente on-premise oferece controlo direto, previsibilidade e, em alguns casos, uma latência mais fácil de gerir. A nuvem acrescenta capacidade sob demanda. As GPUs aceleram as cargas de trabalho adequadas ao paralelismo massivo. Os clusters distribuem o trabalho por vários nós. Uma arquitetura híbrida surge precisamente desta combinação, construída com base no tipo de análise, na frequência dos picos e nas restrições de governação.
Para uma PME, o critério correto é simples. Se tiver processos estáveis, recorrentes e sensíveis aos tempos de resposta, uma infraestrutura local pode fazer sentido. Se, por outro lado, as cargas aumentarem em determinados momentos, como encerramentos de período, revisões de previsões ou simulações extraordinárias, a nuvem permite aumentar a capacidade sem imobilizar o orçamento durante todo o ano.
Há ainda um aspeto que muitas vezes gera confusão. Escalar não significa apenas adicionar núcleos ou servidores. Numa carga de trabalho real, a rede, a memória e o armazenamento também são importantes, porque os nós têm de trocar dados de forma rápida e ordenada. As explicações técnicas sobre os centros de dados HPC ilustram bem este princípio, sobretudo no que diz respeito à relação entre nós, interligação e memória (análise aprofundada sobre nós, interligação e memória nos centros de dados HPC).
Traduzido para a linguagem empresarial, a arquitetura certa é aquela que reduz os estrangulamentos que atrasam o negócio. Não é necessário um supercomputador de laboratório. É necessária uma configuração escalável que permita análises mais frequentes, previsões mais atempadas e decisões operacionais tomadas com base em dados de melhor qualidade. É aqui que plataformas como a ELECTE tornam a HPC acessível também para empresas que não dispõem de uma equipa interna de engenharia especializada.
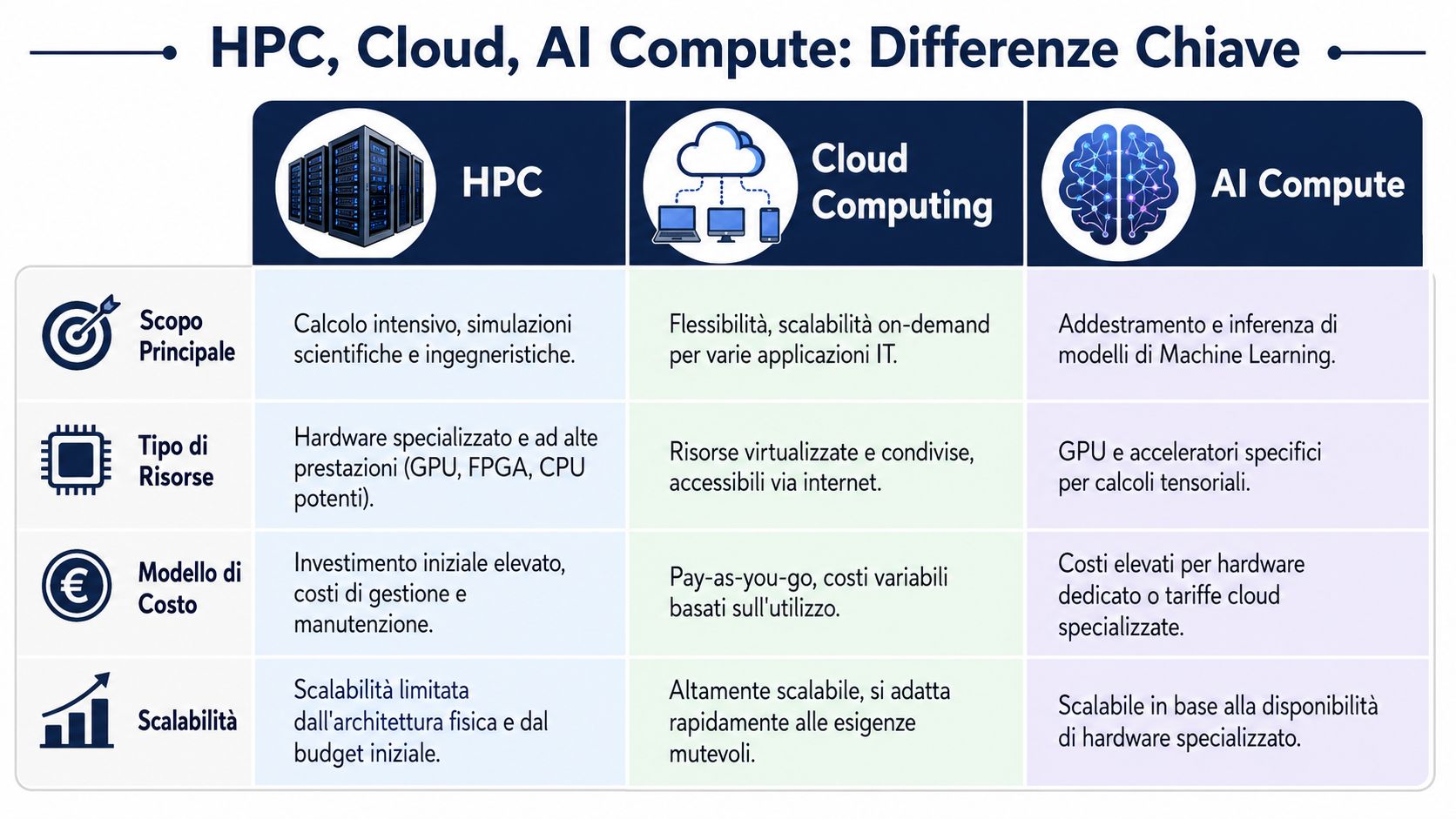
Estes três termos são frequentemente confundidos, mas referem-se a diferentes níveis da mesma realidade.
Uma frase simples ajuda a distingui-los. O HPC é o motor. A nuvem é a forma de acesso. O processamento de IA é o tipo de viagem que estás a fazer.
| Aspecto | HPC | Computação em nuvem | Computação de IA |
|---|---|---|---|
| Pergunta à qual responde | Como posso acelerar cálculos intensivos? | Onde posso obter recursos flexíveis? | Que tipo de processamento estou a realizar? |
| Utilização típica | Simulações, previsões complexas, otimização | Ambientes elásticos, aprovisionamento rápido, capacidade de pico | Treino e inferência de modelos de ML |
| Vantagem de gestão | Reduz os tempos de execução | Evite investimentos rígidos em picos não contínuos | Desbloqueie casos de utilização da IA |
| Relação com os outros | Pode ser executado no local ou na nuvem | Pode alojar cargas de trabalho de HPC e IA | Recorre frequentemente a infraestruturas de HPC |
Se estiver a considerar serviços digitais mais abrangentes, também pode ser útil esclarecer a diferença entre modelos de infraestrutura e de aplicações, como IaaS, PaaS e SaaS, nas arquiteturas na nuvem.
A nuvem não significa automaticamente HPC. E a IA não significa automaticamente uma arquitetura bem concebida.
Um cluster HPC na nuvem é, portanto, possível. Uma carga de trabalho de IA numa infraestrutura HPC é comum. Um ambiente de nuvem genérico, por outro lado, não é necessariamente adequado para um trabalho que exija paralelização intensiva, agendadores, aceleradores e débito constante.

Uma das formas mais claras de compreender o valor da HPC é observar o que acontece quando os tempos de processamento deixam de ser aceitáveis para a empresa.
Num projeto de retalho acompanhado pela ELECTE, um cliente com 42 pontos de venda precisava de recalcular as previsões de procura semanal para 8 600 SKU, tendo em conta a sazonalidade, as promoções, os efeitos do calendário e a canibalização entre produtos. O processo anterior, baseado em scripts Python sequenciais num único servidor, demorava cerca de 50 horas para um ciclo completo. Após a migração para uma arquitetura distribuída com paralelização por cluster de produto, o tempo reduziu-se para 4 horas.
A vantagem mais importante não era apenas a rapidez. Era de natureza organizacional. A equipa podia reexecutar o modelo com muito mais frequência, em vez de trabalhar com previsões já desatualizadas quando estas chegavam aos gestores de categoria.
Isto influencia decisões muito concretas:
No setor da energia, a ELECTE geriu um caso em que o estrangulamento não era o «big data» no sentido clássico. O conjunto de dados incluía 14 milhões de registos de consumo horário distribuídos ao longo de 36 meses, cruzados com variáveis meteorológicas, tarifárias e de capacidade de produção. O modelo de previsão exigia a otimização simultânea de mais de 200 combinações de hiperparâmetros em cinco algoritmos.
Numa única máquina com 32 GB de RAM, o processo bloqueava após 18 horas sem concluir a pesquisa em grelha. Ao distribuir a carga num cluster com 128 vCPU e 512 GB de RAM agregados, todo o pipeline foi concluído em menos de 3 horas.
Aqui fica bem claro o ponto: o valor da HPC não decorre apenas do volume de dados. Decorre da complexidade combinatória do problema.
Para quem dirige uma PME, estes exemplos valem mais do que uma definição técnica. Mostram que a HPC melhora o negócio ao reduzir o tempo entre o pedido e a decisão.
Há também uma questão relacionada com a maturidade do mercado. Em Itália, em 2024, apenas 5,7% das empresas com pelo menos 10 colaboradores declaravam utilizar IA, contra uma média da UE de 13,5% (dados sobre a adoção da IA nas empresas italianas). Esta diferença constitui um problema, mas também uma oportunidade para quem implementa a análise de dados e a IA em produção com maior rapidez.
Para compreender por que razão o volume de dados, por si só, não basta para explicar estes cenários, é útil distinguir claramente os casos em que a análise distribuída é realmente necessária das cargas de trabalho normais de BI. Um bom ponto de partida é esta análise aprofundada sobre a análise de big data e a complexidade analítica.

O verdadeiro obstáculo à adoção da HPC nas PME não é compreender que ela é necessária. É geri-la sem transformar cada projeto analítico num projeto de infraestrutura.
É aqui que entra em jogo a abordagem da ELECTE. A plataforma separa a experiência do utilizador da complexidade técnica. Quem utiliza o sistema vê dados, modelos, relatórios e informações. Não tem de decidir onde agendar uma tarefa, como distribuir um dataframe ou qual o nó que tem memória livre suficiente.
Isto altera a viabilidade económica do HPC. Não porque o cálculo se torne magicamente gratuito, mas porque o custo operacional da complexidade diminui. Na prática, o gestor obtém a potência necessária quando precisa, sem ter de criar um departamento de engenharia dedicado.
Nos bastidores, a ELECTE utiliza uma pilha concebida para escalar sem ter de reescrever a lógica quando os dados ou a complexidade aumentam:
No que diz respeito à previsão, os modelos proprietários da ELECTE funcionam numa camada de orquestração que decide automaticamente se a execução deve ser feita localmente ou se a carga deve ser distribuída pelo cluster, com base no tamanho dos dados de entrada e na complexidade do pipeline.
Observação prática: a melhor opção não é ficar preso a um único framework. Trata-se de construir uma arquitetura substituível, para que a plataforma possa evoluir sem ter de reescrever o valor de negócio.
Esta abordagem tem um efeito muito concreto para uma PME. A equipa não adquire «potência» de forma abstrata. Adquire continuidade analítica. Se o caso de utilização crescer, a infraestrutura cresce. Se a carga diminuir, não fica uma máquina sobredimensionada a ocupar orçamento e atenção.

A pergunta certa não é «quanto custa o HPC?». A pergunta certa é «que configuração é que as minhas cargas reais realmente necessitam?».
Da experiência da ELECTE depreende-se uma regra muito prática: não dimensionar com base no pico permanente. A maioria das PME tem cargas intermitentes. Previsões, encerramentos trimestrais, recálculos pontuais e simulações não exigem a mesma intensidade todos os dias.
Para um cliente típico com um conjunto de dados entre 5 e 50 milhões de registos, o custo da infraestrutura pode situar-se entre 400 e 1 200 euros por mês, com um cluster básico que cobre a maior parte das necessidades e capacidade adicional sob demanda para os picos de tráfego. O erro mais comum é precisamente o contrário: adquirir capacidade «por precaução» e acabar por ficar com uma grande parte da infraestrutura sem utilização durante quase todo o ano.
Uma lista de verificação útil para a decisão:
A segurança não pode ser uma adição posterior. Em 2024, a Agência Nacional de Cibersegurança registou um aumento de 40 % nos eventos cibernéticos e de 45 % nos incidentes confirmados, em comparação com 2023 (dados da ACN referidos na fonte indicada). Isto basta para deixar uma coisa clara: uma plataforma de computação de alto desempenho tem de ser segura desde a sua conceção inicial.
No caso de ambientes controlados ou sensíveis, é aconselhável verificar, pelo menos, os seguintes aspetos:
| Área | Questão de gestão |
|---|---|
| Segmentação | As cargas de trabalho críticas estão separadas do resto da infraestrutura? |
| Residência de dados | Sabes onde se encontram os dados e onde são processados? |
| Auditoria | Consegues determinar quem fez o quê e quando? |
| Escalabilidade | Com o aumento da carga, os controlos mantêm-se os mesmos? |
A integração é tão importante quanto a segurança. Se o HPC permanecer isolado, acaba por ser pouco utilizado. Se for integrado no fluxo de dados da empresa, torna-se uma mais-valia contínua. Para compreender como ligar a análise avançada aos sistemas existentes, pode ser útil avaliar as opções de integração de dados e de aplicações na ELECTE.
A Computação de Alto Desempenho já não é uma categoria distante da realidade das PME. É uma resposta concreta a um problema muito comum: tens dados, tens modelos, tens questões importantes, mas não tens tempo suficiente para os transformar em decisões úteis.
O ponto-chave a reter é simples. A HPC torna-se valiosa à medida que a complexidade analítica aumenta. Não vale a pena perseguir a ideia do supercomputador. É preciso compreender onde é que o cálculo paralelo pode encurtar o ciclo entre o insight e a ação.
Se estás a ponderar os próximos passos, começa assim:
À medida que a previsão, a otimização e a IA se tornam mais rápidas, a forma como a empresa funciona também muda. As decisões já não esperam pelos relatórios. Os relatórios começam a acompanhar o ritmo do negócio.
Se pretende transformar dados complexos em informações claras sem ter de gerir a infraestrutura subjacente, descubra a ELECTE, a plataforma de análise de dados baseada em IA para as PME. Pode ver como automatizar a elaboração de relatórios, as previsões e as análises avançadas com uma experiência concebida para equipas empresariais, e não apenas para especialistas técnicos.

.svg)
.svg)
.svg)






