

Recebes um ficheiro XML por PEC. Abres-o no navegador, vês uma profusão de tags e pensas que o problema é «lê-lo». Na realidade, esse é apenas o primeiro obstáculo. O verdadeiro problema na empresa é outro: perceber se esses dados estão corretos, coerentes e prontos para serem incluídos nos teus relatórios.
Para muitas PME italianas, esta questão já não é estritamente técnica. Desde que a faturação eletrónica se tornou obrigatória, o XML passou a fazer parte do trabalho quotidiano de administração, controlo de gestão e análise. Não basta visualizar o documento. É preciso saber distinguir entre um ficheiro legível e um ficheiro fiável. É preciso compreender quando basta uma verificação rápida e quando é necessário efetuar a análise sintática, a validação e a normalização antes de carregar os dados no Excel, no BI ou numa plataforma de análise.
Se estás à procura de um guia prático sobre como ler ficheiros XML, este é o caminho certo: começar pelos métodos simples, perceber onde surgem os problemas e, depois, criar um fluxo que transforme o XML bruto em dados úteis para o negócio. É assim que se reduzem os erros e se encurta o tempo entre «tenho o ficheiro» e «tenho uma informação útil».
Um ficheiro XML organiza os dados numa estrutura hierárquica. Existe um elemento principal, há secções aninhadas e cada bloco descreve uma informação com um significado preciso. Para quem gere processos administrativos, este pormenor faz a diferença entre um dado legível e um dado verdadeiramente utilizável.
A questão não é «abrir» o ficheiro. A questão é perceber se esse ficheiro pode ser integrado, sem erros, nos fluxos de controlo, contabilidade e análise.
Tomemos como exemplo uma fatura eletrónica. No mesmo ficheiro coexistem dados do fornecedor, dados do cliente, valores tributáveis, IVA, linhas de artigos, condições de pagamento, referências de encomenda e, muitas vezes, também exceções que complicam a leitura. Em XML, estas informações não estão dispostas uma abaixo da outra, como numa folha qualquer. Estão localizadas em posições precisas, e essa posição explica o que representam.
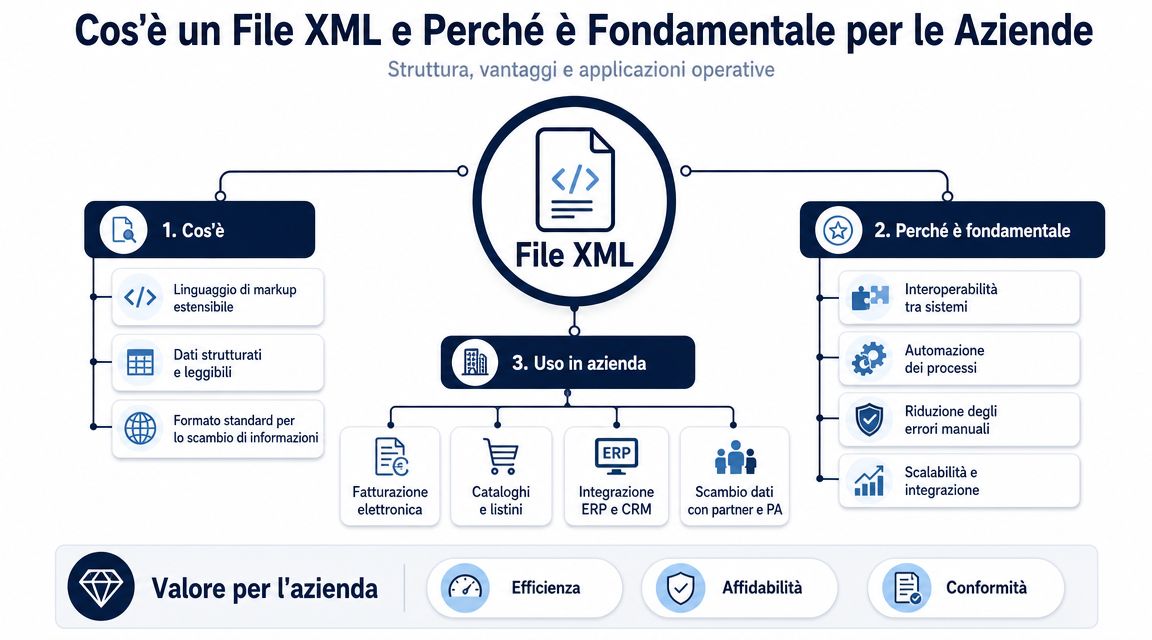
Para um gestor, a distinção útil não é entre etiquetas e atributos num sentido teórico. É entre um dado isolado e um dado fiável. Ler «1000,00» fora do contexto serve de pouco. Ler esse valor no local correto do ficheiro permite perceber se se trata do total do documento, da base tributável, do imposto ou do valor de uma única linha.
É aqui que surge a primeira vantagem operacional. O XML preserva o contexto dos dados.
Regra prática: ler bem um ficheiro XML significa verificar o significado do valor, e não apenas o valor em si.
Em Itália, esta questão tornou-se uma realidade com a generalização da faturação eletrónica. No formato FatturaPA, o XML tornou-se o padrão para a documentação fiscal. Consequentemente, a sua interpretação já não diz respeito apenas às TI. Envolve a administração, o controlo de gestão, as compras e todos aqueles que precisam de utilizar esses dados para tomar decisões.
Na prática, vejo sempre o mesmo problema. O ficheiro existe, os dados estão lá, mas o tempo necessário para os transformar em informação útil é demasiado longo. Uma pessoa abre o ficheiro XML, verifica visualmente, copia valores para o Excel, corrige campos inconsistentes, renomeia fornecedores cujos nomes estão escritos de formas diferentes e tenta reconstruir categorias de despesas que o ficheiro não apresenta de forma pronta para análise. O custo não é apenas operacional. É tempo perdido até à obtenção de insights.
Com o FatturaPA, o risco é ainda mais evidente. Dois ficheiros formalmente corretos podem criar os mesmos problemas de análise se um deles utilizar descrições de linha muito imprecisas, se as referências da encomenda estiverem incompletas ou se os dados de base do fornecedor forem introduzidos com variações diferentes. Nessa altura, o problema não é ler o XML. O problema é evitar que dados fiscais válidos se tornem dados de gestão pouco fiáveis.
Um erro comum é tratar o XML como um anexo a ser visualizado. Nas empresas, é mais eficaz considerá-lo como uma fonte de dados estruturada que deve ser verificada antes de alimentar relatórios, painéis de controlo e modelos de despesas. Se esta fase for mal gerida, a equipa financeira acaba por debater números aparentemente precisos, mas baseados em classificações incoerentes.
As perguntas certas, no início, são estas:
São verificações muito concretas. Servem para evitar a duplicação de fornecedores nos relatórios, erros na interpretação do IVA, centros de custo preenchidos de forma incompleta e reconciliações demoradas no final do mês.
É aqui que se percebe a diferença entre a leitura técnica e o valor empresarial. Um analisador lê o ficheiro. Um processo bem concebido produz dados limpos, comparáveis e prontos para análise. Plataformas como a ELECTE surgem precisamente para colmatar esta lacuna, reduzindo o trabalho manual que separa o XML recebido das informações úteis para uma melhor tomada de decisão.
Para verificações rápidas num único ficheiro, não são necessários analisadores nem bibliotecas. É preciso perceber se está a fazer uma verificação visual de alguns campos ou se já está a lidar com dados que irão para a contabilidade, relatórios ou controlo de gestão. A diferença é importante, sobretudo no caso das FaturasPA. Uma verificação feita de forma apressada hoje pode tornar-se amanhã uma linha errada no conjunto de dados dos fornecedores.

Os navegadores, editores de texto e visualizadores dedicados resolvem um problema específico: ler rapidamente o conteúdo sem ter de configurar um fluxo técnico. Para um ficheiro isolado, muitas vezes isso é suficiente. Pode abrir um ficheiro XML no Chrome, Edge ou Firefox para ver a estrutura, ou utilizar o Bloco de Notas, o WordPad ou o TextEdit se quiser inspecionar diretamente as etiquetas. No caso das faturas eletrónicas, um visualizador específico torna mais legíveis os cabeçalhos, as linhas do documento, a base tributável e o IVA.
A questão prática é esta:
| Instrumento | Útil para | Principal limitação |
|---|---|---|
| Navegador | Inspeção visual rápida da estrutura | Não verifica a coerência entre campos e secções |
| Editor de texto | Inspeção direta das etiquetas | Torna-se complicado em ficheiros longos ou aninhados |
| Excel | Verificação preliminar em formato tabular | Lida mal com hierarquias e repetições |
| Visualizador dedicado | Leitura mais clara de faturas e documentos fiscais | Não prepara os dados para análise ou automatização |
Se precisar de verificar a data do documento, o número de identificação fiscal, o total da fatura ou a existência de anexos, estas ferramentas são adequadas.
Se, por outro lado, o objetivo for comparar fornecedores, classificar despesas ou alimentar um painel de controlo, a simples visualização atrasa o trabalho e deixa margem a erros manuais. É a clássica diferença entre ver um ficheiro e chegar a um dado fiável em tempo útil.
Abrir um ficheiro XML não significa validar os dados que irá utilizar nos relatórios.
Outro aspeto prático diz respeito ao volume. Dez registos ainda se conseguem verificar manualmente. Centenas de FatturePA, já não. Nesse caso, já vale a pena pensar num fluxo repetível ou em ferramentas que leiam o conteúdo de forma estruturada, por exemplo, através de uma API para adquirir e gerir documentos fiscais de forma integrada.
Em Itália, o problema recorrente não é abrir um .xml, mas perceber o que fazer quando chega um .xml.p7m por PEC. É necessário distinguir entre ficheiros XML simples e ficheiros assinados digitalmente. No segundo caso, são necessárias ferramentas capazes de ler a assinatura, extrair o conteúdo e apresentar o XML correto, tal como explica este guia dedicado ao XML e ao XML P7M no PEC.
Aqui, os erros custam tempo:
Para um funcionário administrativo, a sequência mais útil é simples:
Estes métodos cumprem bem a sua função nas verificações de primeiro nível. No entanto, não resolvem o problema que realmente pesa na empresa: transformar ficheiros XML fiscais, muitas vezes irregulares ou pouco uniformes, em dados limpos e comparáveis, sem prolongar o tempo que decorre entre a receção do documento e a obtenção da informação útil.
Quando os ficheiros começam a acumular-se, o trabalho manual deixa de ser viável. Nessa altura, ler ficheiros XML através de código não é uma opção elegante. É o primeiro passo para evitar tarefas repetitivas, erros de cópia e conjuntos de dados incoerentes.

Uma abordagem sólida à leitura de XML segue sempre a mesma lógica: análise, normalização e extração seletiva. Nos tutoriais de Java e Android, o fluxo correto passa por parse(), a partir da normalização do árvore com doc.getDocumentElement().normalize() e, em seguida, pela recuperação dos campos com getElementsByTagName, um método mais estável do que a simples visualização num editor de texto, como se pode ver este tutorial técnico sobre a leitura de dados XML.
Esta sequência é mais importante do que a linguagem que escolheres. Se ignorares a normalização, se procurares nós de forma demasiado simplista ou se assumires que uma etiqueta aparece sempre apenas uma vez, o teu script funcionará em alguns ficheiros e falhará precisamente naqueles que mais importam.
Para projetos que tenham de interagir com sistemas externos, pode ser útil criar um fluxo de extração replicável e documentado. Se estiver a trabalhar em integrações de aplicações, uma base útil é a documentação sobre as API da ELECTE com perfil Postman verificado, sobretudo para compreender como ligar um conjunto de dados já limpo a processos subsequentes.
A seguir, encontras alguns exemplos básicos. O objetivo não é abranger todos os casos, mas mostrar-te a lógica básica: abrir o ficheiro, encontrar um nó, imprimir um valor.
import xml.etree.ElementTree as ETtree = ET.parse("fattura.xml")root = tree.getroot()numero = root.find(".//Numero")if numero is not None:print(numero.text)O Python é frequentemente a opção mais rápida para protótipos, transformações e pipelines leves. É excelente quando é necessário ler muitos ficheiros XML, extrair alguns campos e guardá-los em CSV ou JSON.
const xmlString = `<fattura><Numero>123</Numero></fattura>`;const parser = new DOMParser();const xmlDoc = parser.parseFromString(xmlString, "application/xml");const numero = xmlDoc.getElementsByTagName("Numero")[0];console.log(numero.textContent);Esta abordagem é útil para testes rápidos na página ou para pequenas ferramentas internas. É adequada para interfaces simples, mas menos adequada para fluxos estruturados de back-office.
const fs = require("fs");const xml2js = require("xml2js");const xml = fs.readFileSync("fattura.xml", "utf8");xml2js.parseString(xml, (err, result) => {if (err) throw err;console.log(result.fattura.Numero[0]);});Se trabalhas no lado do servidor e pretendes criar automatizações, o Node.js continua a ser uma opção prática. A vantagem é poder integrar facilmente a leitura de XML com o sistema de ficheiros, filas de processamento e serviços internos.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse("fattura.xml");doc.getDocumentElement().normalize();NodeList lista = doc.getElementsByTagName("Numero");if (lista.getLength() > 0) {System.out.println(lista.item(0).getTextContent());}O Java está frequentemente presente em contextos empresariais, de gestão e de middleware. Neste contexto, o ponto-chave não é apenas ler os dados, mas fazê-lo de forma previsível e sustentável.
library(XML)doc <- xmlParse("fattura.xml")numero <- xpathSApply(doc, "//Numero", xmlValue)print(numero)O R faz sentido quando a análise sintática faz parte de um trabalho analítico. Se o teu próximo passo for uma análise estatística ou a preparação de dados, podes manter tudo no mesmo ambiente.
Se a tua equipa abre os mesmos ficheiros todas as semanas e repete as mesmas verificações, já estás no domínio da automatização.
O verdadeiro ganho não é «ler XML com código». É libertar as pessoas de um trabalho mecânico e criar um fluxo que produza conjuntos de dados consistentes.
Os problemas sérios começam quando já não se trata de um único ficheiro. Uma única FatturaPA é quase sempre fácil de gerir. A dificuldade surge quando é necessário consolidar meses de documentos, fornecedores diferentes, campos preenchidos de forma não uniforme e anexos incorporados.
Nas PME italianas, o caso mais comum não é o «mega ficheiro» isolado, mas sim o lote. Uma exportação anual de faturas recebidas pode gerar uma estrutura com mais de 380 000 nós em 4 200 faturas, incluindo cabeçalhos, linhas de detalhe, dados de pagamento e anexos em base64. Nestes cenários, o problema não é abrir o documento. É transformar XMLs heterogéneos num conjunto de dados coerente.
Aqui entra em jogo uma escolha técnica com implicações comerciais. No ambiente .NET, a Microsoft indica que o XmlDocument carrega o documento na memória e é útil para leitura e modificação, enquanto que, para ficheiros de grande dimensão ou operações de apenas leitura, é aconselhável optar por abordagens mais eficientes, como o analisador de fluxo (parser streaming) ou o XPathDocument, para evitar um consumo excessivo de RAM, tal como especificado na documentação da Microsoft sobre a leitura de XML com o XmlDocument e o XPathDocument.
Na prática:
A escolha é simples. O modelo em memória permite-te desenvolver mais rapidamente. O modelo de streaming tem melhor desempenho em produção quando os ficheiros são muitos ou pesados.
Muitas equipas limitam-se à validação XSD. É útil, mas não é suficiente. Um ficheiro pode estar em conformidade com o esquema e, mesmo assim, produzir dados incorretos nas etapas seguintes.
Exemplos típicos do trabalho operacional:
| Tipo de controlo | O que verifica | Para que serve |
|---|---|---|
| Estrutural | Etiquetas, formato, hierarquia | Evite erros de análise sintática |
| Semântico | Coerência lógica dos dados | Evite análises erradas |
| Operacional | Existência de campos úteis para a elaboração de relatórios | Evite conjuntos de dados inutilizáveis |
O caso mais insidioso é este: o «ImportoTotalDoDocumento» é formalmente válido, mas não é coerente com a soma das linhas, talvez devido a regras de arredondamento do sistema de gestão do fornecedor. Ou ainda, códigos de IVA formalmente admissíveis, mas incoerentes com a natureza da operação.
Um ficheiro formalmente correto pode, mesmo assim, comprometer os teus relatórios.
Existe ainda outra armadilha conhecida nas FatturaPA. A etiqueta «DatiBeniServizi» contém descrições livres. O mesmo custo pode aparecer de muitas formas diferentes, com textos claros, abreviados ou enigmáticos. Se não se introduzir uma etapa de normalização, qualquer análise por categoria de despesa torna-se pouco fiável.
Por isso, em fluxos sérios, a leitura do ficheiro é apenas o nível um. O nível dois é sempre um conjunto de regras de coerência e limpeza. É aí que se protege a qualidade dos dados, não no analisador.
Um ficheiro XML bem lido ainda não é um conjunto de dados útil. É um documento estruturado. Para realizar análises, comparações, agrupamentos e painéis de controlo, quase sempre é necessário convertê-lo para um formato mais fácil de tratar.
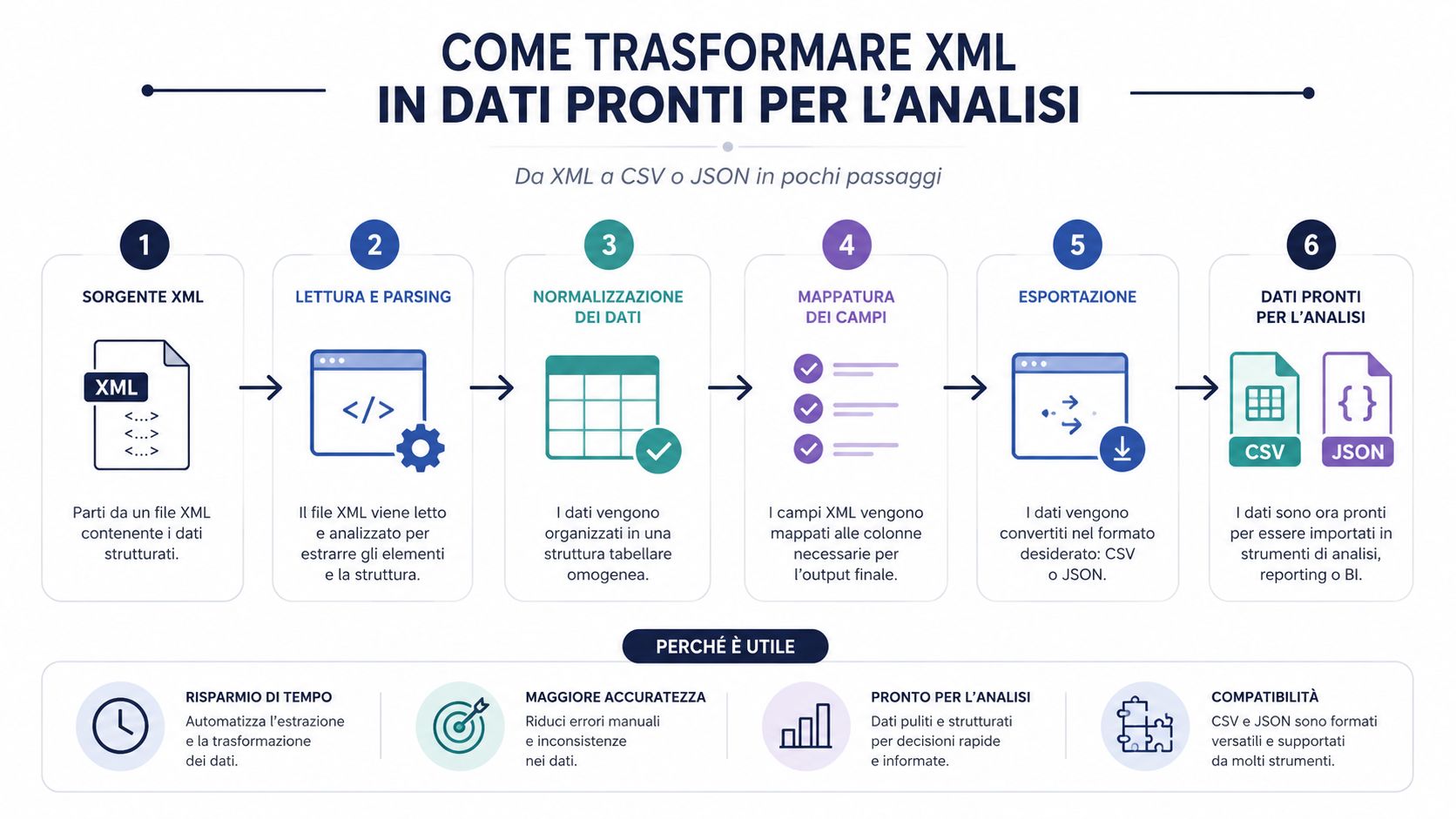
Este é o ponto que muitos processos subestimam. O gargalo raramente é a análise sintática em si. Uma biblioteca decente lê um ficheiro XML rapidamente. O tempo perde-se na interpretação da estrutura, na extração dos campos úteis, na limpeza, na normalização e no carregamento numa ferramenta analítica.
É por isso que a conversão para CSV ou JSON não é apenas uma questão de comodidade. Trata-se de uma etapa operacional fundamental. Se ignorares esta etapa e trabalhares diretamente no ficheiro bruto, acabas quase sempre por ter de recorrer a verificações manuais, colunas improvisadas e lógicas difíceis de replicar.
Uma referência útil para quem trabalha frequentemente com XML e folhas de cálculo é este guia sobre como passar do XML para o Excel de forma mais organizada.
O formato adequado depende da forma como irás utilizar os dados posteriormente.
O CSV funciona bem quando se pretende uma linha por documento ou uma linha por detalhe de fatura, para depois utilizar o Excel, o Power Query ou o BI.
Exemplo em Python:
import xml.etree.ElementTree as ETimport csvtree = ET.parse("fattura.xml")root = tree.getroot()with open("fatture.csv", "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(["número", "data"])número = root.findtext(".//Numero")data = root.findtext(".//Data")writer.writerow([numero, data])A vantagem é a simplicidade. A limitação é que é preciso decidir bem como simplificar a hierarquia. Se uma fatura tiver várias linhas de detalhe, é necessário definir claramente a granularidade e a chave de ligação.
O JSON é mais adequado quando se pretende manter parte da estrutura hierárquica.
Exemplo em JavaScript:
const record = {numero: "123",data: "2024-01-15",righe: [{ descrizione: "Servizio", importo: "100.00" }]};console.log(JSON.stringify(record, null, 2));Utiliza-o quando o teu próximo passo for uma API, um data lake ou uma aplicação que funcione bem com objetos aninhados.
Eis uma regra prática que ajuda:
O ficheiro XML é o contêiner. CSV e JSON são os formatos que tornam o conteúdo realmente utilizável.
Se quiser reduzir o tempo até à obtenção de insights, é aqui que vale a pena investir de forma metódica. Não em encontrar um visualizador mais prático, mas em definir uma transformação estável e repetível.
Assim que o ficheiro for lido, validado e transformado, o trabalho assume uma nova dimensão. Já não estás a debater-te com as etiquetas. Estás, finalmente, a analisar custos, anomalias, fornecedores, categorias de despesas e tendências operacionais.
Na prática, o valor não reside no tempo de análise. Reside no tempo que separa o ficheiro bruto de uma informação com base na qual se possa tomar uma decisão. Num fluxo manual, uma pessoa tem de abrir o documento, compreender a estrutura, extrair os campos, limpar os valores, normalizar os textos e, só depois, elaborar relatórios. É um processo frágil.
Um exemplo clássico nas FatturaPA é o texto livre na secção «DatiBeniServizi». O mesmo serviço pode ser descrito de muitas formas diferentes por fornecedores distintos. Se importar esses dados sem um mapeamento coerente, a análise por categoria de custo produz agregados inúteis.
Por isso, antes da plataforma de análise, é necessária uma fase de preparação, uma vez que:
Quando esta fase é bem executada, qualquer plataforma de análise funciona melhor. Se quiseres aprofundar a vertente decisória e visual desta etapa, o recurso sobre como construir histórias com os dados é útil, pois mostra como um conjunto de dados limpo se transforma numa narrativa útil para os decisores.
Nesta altura, o ficheiro XML deixa de ser um problema técnico e passa a ser matéria-prima para a obtenção de insights. Um conjunto de dados bem preparado pode servir de base para análises de despesas, acompanhamento de tendências, identificação de desvios e análise de exceções.
Para escolher uma plataforma adequada para esta «última milha», pode ser útil comparar o que um software moderno de análise de negócios oferece em comparação com fluxos puramente manuais baseados em folhas de cálculo e tabelas dinâmicas.
Aqui, o critério certo não é «sabe abrir ficheiros XML?». Isso é o mínimo. A pergunta relevante é outra:
| Pergunta | Porque é que isso importa |
|---|---|
| Os dados já chegam limpos | Evite conclusões precisas com base em dados errados |
| As categorias são coerentes | Comparas mesmo os fornecedores e os períodos? |
| As anomalias tornam-se evidentes de imediato | Reduza o tempo perdido com verificações manuais |
| O relatório é compreensível para os setores empresarial e financeiro | Acelerar a tomada de decisões |
A diferença entre um processo imaturo e um maduro não reside na capacidade de ler ficheiros XML. Reside na capacidade de os transformar numa base de dados fiável, que não obrigue a equipa a repetir sempre o mesmo trabalho.
Se precisares de ler ficheiros XML de forma útil para o negócio, tem em conta esta lista de verificação. É mais prática do que qualquer definição técnica e ajuda-te a escolher o método certo sem perder tempo.
Não utilize sempre a mesma abordagem. Navegadores, editores e visualizadores são adequados para verificações rápidas. Os analisadores e os scripts são úteis quando o ficheiro tem de alimentar processos repetitivos. Se confundir visualização com tratamento de dados, corre-se o risco de criar relatórios com bases frágeis.
Os ficheiros .xml.p7m exigem um passo específico na gestão da assinatura. Se o conteúdo for proveniente de um endereço PEC, esta verificação não é secundária. Faz parte da leitura correta do documento.
Um esquema respeitado não garante um conjunto de dados válido. As incoerências lógicas, como totais não alinhados ou classificações fiscais ambíguas, são as que mais frequentemente comprometem a análise. A verificação semântica é o que distingue um ficheiro «aceitável» de um conjunto de dados fiável.
O CSV e o JSON não são uma mera alteração superficial. São o ponto em que o XML se torna processável por ferramentas de análise, folhas de cálculo, pipelines e relatórios. Quanto mais cedo definir esta transformação, mais cedo reduzirá o trabalho manual e a improvisação.
O teu objetivo não é ler ficheiros XML. É obter informações úteis sem sobrecarregar o sistema com dados de má qualidade. Se o fluxo não produzir um conjunto de dados coerente, o problema não está no painel final. Está muito mais a montante.
Na prática, podes utilizar esta mini-lista de verificação antes de cada novo projeto:
Se pretende transformar dados já preparados em informações claras e úteis para a tomada de decisões, a ELECTE ajuda as PME a passar de um conjunto de dados limpo para relatórios inteligentes, com uma abordagem acessível mesmo para equipas sem conhecimentos técnicos. É a forma mais rápida de reduzir a distância entre os dados operacionais e a tomada de decisões.

.svg)
.svg)
.svg)
.webp)





