

Os teus dados já estão a contar uma história. O problema é que, muitas vezes, falam demasiado baixo.
Todos os dias, uma PME acumula feedback dos clientes, encomendas, tickets de assistência, transações financeiras, e-mails comerciais e notas do CRM. Todo este material contém sinais úteis. Alguns indicam que um cliente está prestes a abandonar a empresa. Outros antecipam um risco operacional. Outros ainda mostram quais os produtos que estão prestes a crescer ou a abrandar. Sem um método claro, porém, esses sinais não passam de ruído.
Entre os algoritmos que ajudam a trazer ordem a este caos, os classificadores bayesianos ingênuos ocupam um lugar especial. São fáceis de compreender em termos lógicos, rápidos de treinar e, muitas vezes, mais eficazes do que o nome «ingênuo» sugere. Não são a escolha certa para todos os cenários, mas, em muitos problemas empresariais reais, oferecem um equilíbrio raro entre velocidade, interpretabilidade e resultados úteis.
Se trabalhas no mundo dos negócios, não precisas de te tornar um investigador para os compreender. Precisas de saber o que fazem, por que razão funcionam bem mesmo quando simplificam bastante a realidade e em que casos te podem ajudar a tomar melhores decisões. É precisamente aqui que vale a pena parar para refletir.
Muitas empresas procuram modelos sofisticados quando o problema exige, acima de tudo, um modelo fiável e fácil de utilizar. É pela mesma razão que, nas finanças, no retalho ou no atendimento ao cliente, muitas vezes prevalece o processo mais claro, e não o mais elegante do ponto de vista teórico.
Os classificadores bayesianos ingênuos partem de uma ideia muito concreta. Se tivermos algumas pistas sobre um caso novo, podemos estimar a que categoria ele pertence com boa probabilidade. Se um e-mail contiver determinadas palavras, pode ser spam. Se uma transação apresentar determinados padrões, pode ser necessário verificá-la. Se uma avaliação utilizar determinados termos, pode indicar satisfação ou insatisfação.
A palavra «bayesiano» faz pensar em fórmulas complexas. Na realidade, o cerne do método é intuitivo. Pegue no que já sabe, acrescente novas evidências e atualize o seu julgamento. É uma forma ordenada de raciocinar em situações de incerteza, exatamente o que os gestores fazem todos os dias, só que sistematizada por um algoritmo.
O que surpreende é que esta abordagem continua a funcionar bem mesmo em ambientes modernos, com grandes quantidades de dados e decisões rápidas. Não porque descreva o mundo de forma perfeita, mas porque separa o sinal útil do ruído com um custo computacional muito reduzido.
Nos problemas empresariais, a pergunta certa não é «qual é o modelo mais sofisticado?». É «qual é o modelo que me permite tomar decisões fiáveis num prazo compatível com o trabalho prático?».
É por isso que os classificadores bayesianos ingênuos continuam a ser importantes. Ajudam-te a classificar, filtrar, segmentar e estabelecer prioridades. E permitem-te integrar a probabilidade no processo de tomada de decisão sem transformar cada projeto num campo de batalha técnico.
O princípio básico é o teorema de Bayes. Em termos simples, diz o seguinte: parte-se de uma probabilidade inicial e, depois, atualiza-se essa probabilidade à medida que surgem novas informações.
Na linguagem dos dados, a fórmula é a seguinte: P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y). Isto significa que a probabilidade de uma classe, dado um conjunto de sinais, depende de dois elementos. O primeiro é a probabilidade inicial da classe. O segundo é o grau de compatibilidade de cada sinal com essa classe.
Traduzindo para um exemplo empresarial. Tens de determinar se um e-mail é spam ou não. Tens uma probabilidade geral de que um e-mail recebido seja spam. Depois, observas algumas palavras como «oferta», «grátis», «clica aqui». Cada uma destas palavras altera a avaliação final.
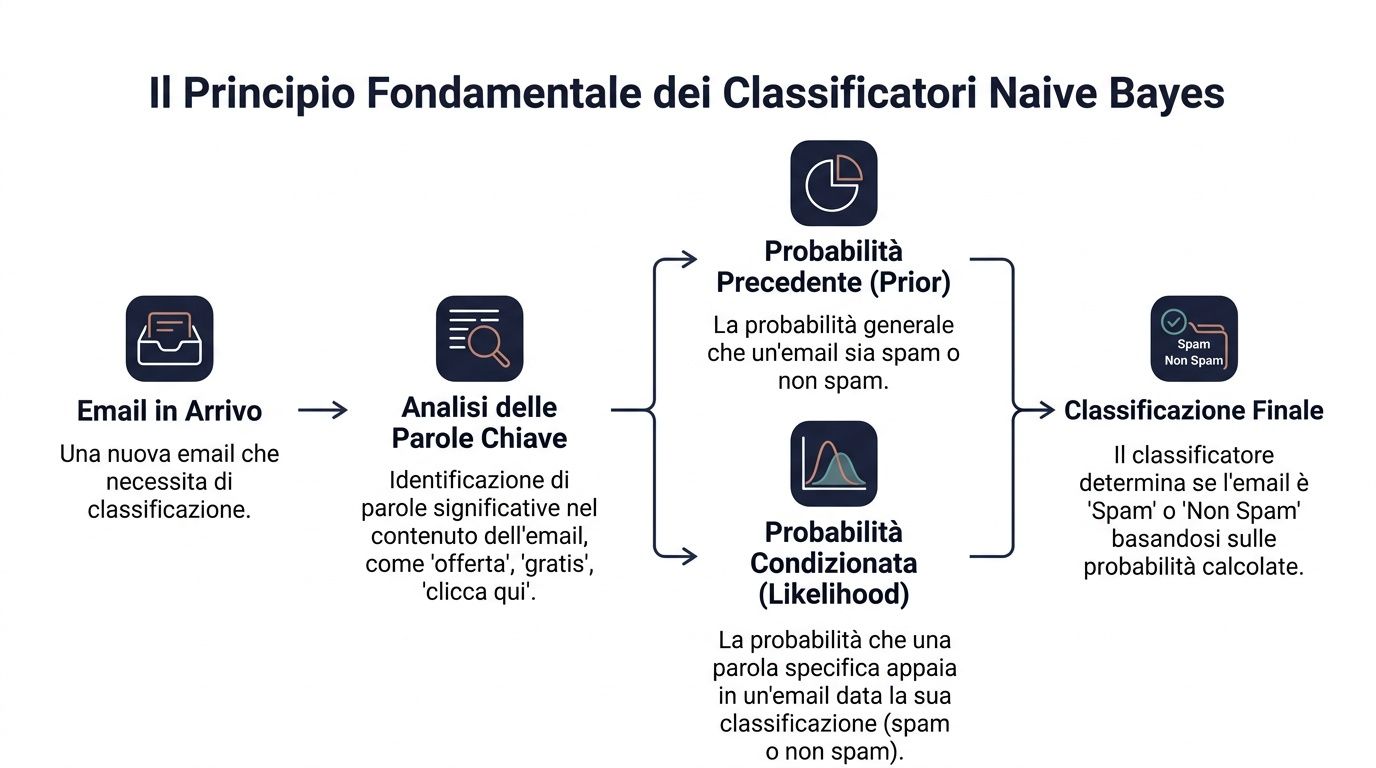
Um gestor faz algo semelhante todos os dias. Nunca toma decisões no vácuo. Parte de um contexto de base e vai acrescentando pistas. Um cliente que sempre comprou regularmente tem um certo perfil inicial. Se depois deixar de abrir os e-mails, reduzir o valor das encomendas e abrir um ticket crítico, a tua avaliação muda.
O termo «naive» indica um pressuposto específico. O modelo trata as características como se fossem independentes umas das outras, uma vez que a classe é conhecida.
Na prática, se estiveres a classificar um e-mail, considera cada palavra como uma pista separada. Não tentes modelar todas as relações complexas entre os termos. Trata-se de uma simplificação significativa. Na realidade, muitas palavras aparecem juntas e muitos comportamentos empresariais estão interligados.
No entanto, é precisamente essa escolha que torna o modelo muito leve. Não precisa de aprender uma rede complexa de dependências. Tem de estimar probabilidades mais simples e combiná-las de forma eficiente.
Regra prática: o Naive Bayes não tenta reconstruir o mundo inteiro. Procura tomar decisões úteis com poucas suposições e muita rapidez.
É aqui que muitas vezes surge o mal-entendido. Muitos interpretam «pressuposto ingênuo» e concluem que se trata de um «modelo fraco». Não é assim. Um modelo pode simplificar bastante e continuar a ser competitivo se a simplificação captar o que é relevante para a tomada de decisão.
Em 2004, uma análise teórica apresentou argumentos sólidos para a eficácia dos classificadores Naive Bayes, apesar do pressuposto de independência, explicando também por que razão estes conseguem atingir o erro assintótico mais rapidamente do que a regressão logística. Na mesma linha de aplicações, na filtragem de spam, atingem precisões superiores a 99% e escalam para milhões de documentos, conforme descrito na secção dedicada aos classificadores Naive Bayes.
Este ponto é importante para um público empresarial. O valor de um algoritmo não reside apenas na pontuação final. Reside também na capacidade de ser treinado rapidamente, de se adaptar a conjuntos de dados extensos e de permanecer interpretável.
Quando se tem textos, categorias, etiquetas ou sinais dispersos, os classificadores bayesianos ingênuos funcionam bem porque:
Há, no entanto, dois pontos a ter em conta.
Por esse motivo, o Naive Bayes deve ser visto como uma ferramenta muito eficaz em problemas de classificação rápidos, e não como uma varinha mágica universal. Em muitos contextos práticos, porém, é uma das formas mais inteligentes de começar.
Um erro comum é referir-se ao Naive Bayes como se fosse um único modelo idêntico em todas as situações. Na realidade, existem várias variantes, concebidas para diferentes tipos de dados.
A escolha certa depende do formato dos dados de que dispõe. Se escolher a variante errada, o modelo pode, mesmo assim, produzir uma previsão, mas não estará a raciocinar da forma mais adequada ao seu problema.
O Gaussian Naive Bayes é a variante mais adequada quando as características são contínuas. Pense, por exemplo, no valor médio de uma transação, na idade do cliente, no tempo médio entre duas compras, na margem unitária ou no valor do recibo.
Aqui, o modelo parte do princípio de que, dentro de cada classe, os valores seguem uma distribuição gaussiana. Não deves encarar isto como uma restrição académica. Basta teres em mente a ideia prática: para cada classe, o modelo estima um centro típico e uma dispersão.
Esta abordagem é útil quando se pretende classificar casos como:
Num benchmark do scikit-learn com um conjunto de dados semelhante aos dados de comércio eletrónico italianos, um modelo Naive Bayes atingiu 95% de precisão com 1000 amostras, com um tempo de treino 15% mais rápido do que o da regressão logística . A comparação indicada é de 0,01 s contra 0,1 s numa CPU padrão, graças ao treino em forma fechada, conforme demonstrado no capítulo de Jake VanderPlas sobre «In Depth Naive Bayes Classification».
Para uma empresa, o ponto não é a casa decimal. O ponto é que esta variante pode produzir bons resultados sem longos períodos de formação e sem uma infraestrutura pesada.
Se trabalha com textos, tickets, avaliações ou comentários, o Multinomial Naive Bayes é frequentemente a escolha natural. Neste caso, as características são contagens ou frequências. Na prática, o modelo analisa quantas vezes as palavras ou termos aparecem.
É o cenário clássico de:
A razão pela qual funciona bem é muito concreta. Nos textos empresariais, o vocabulário pode ser vasto, mas cada documento contém apenas uma pequena parte das palavras possíveis. Os dados estão dispersos. O Multinomial Naive Bayes lida bem precisamente com este tipo de estrutura.
Num estudo realizado com 100 000 tweets italianos classificados por sentimento, o Multinomial Naive Bayes obteve um F1-score de 0,88, com um aumento de velocidade de 10 vezes em relação ao SVM, conforme relatado no guia da GeeksforGeeks sobre classificadores Naive Bayes.
Para te lembrares facilmente, pensa assim: se os teus dados se assemelham a um documento repleto de palavras contadas, a análise multinomial é quase sempre a primeira opção a testar.
Se a sua empresa precisa de analisar grandes volumes de texto, a questão não é apenas «quão preciso é o modelo?». É também «quantas solicitações consegue classificar sem atrasar o trabalho da equipa?».
O Bernoulli Naive Bayes trabalha com características binárias. Não conta quantas vezes um sinal aparece. Conta apenas se está presente ou ausente.
Esta variante é útil quando a presença de um atributo é mais importante do que a sua frequência. Alguns exemplos empresariais:
É uma lógica muito útil quando se pretende transformar fenómenos complexos em indicadores de «sim» ou «não» fáceis de monitorizar. Na análise de sentimentos, por exemplo, pode ser mais importante o facto de uma palavra negativa aparecer do que o número de vezes que é repetida.
A distribuição de Bernoulli não é «menos evoluída» do que a multinomial. É simplesmente mais adequada quando os dados descrevem presença ou ausência. A diferença é pequena em termos teóricos, mas grande nos resultados.
| Variante | Tipo de dados ideal | Exemplo de caso de uso empresarial |
|---|---|---|
| Gaussiano Naive Bayes | Dados contínuos | Classificar transações por risco utilizando montantes, frequência e valores médios |
| Naive Bayes multinomial | Textos, cálculos, frequências | Analisar comentários e tickets de clientes por tom ou categoria |
| Bernoulli e Naive Bayes | Dados binários, presença/ausência | Avaliar sinais de «sim» ou «não» em matéria de conformidade, assistência ou utilização do produto |
Para fazer uma boa escolha, segue esta regra simples:
Muitas equipas ficam paralisadas porque procuram o «melhor» modelo de todos. A escolha certa, na maioria das vezes, é o modelo mais adequado ao tipo de dados.
A boa notícia é que a aplicação prática do Naive Bayes não requer um projeto de grande envergadura. Mesmo um protótipo compreensível já permite perceber como o modelo funciona e de que dados necessita.

Um classificador é quase sempre criado através de quatro etapas.
Preparação dos dados
É necessário recolher exemplos históricos já rotulados. Se estiver a classificar avaliações, precisa de textos já marcados como positivos ou negativos. Se estiver a analisar o risco operacional, precisa de casos passados com um resultado conhecido.
Treino do modelo bayesiano simples (
) O modelo analisa os dados e estima as probabilidades relevantes. Nos classificadores bayesianos simples, esta etapa é rápida, pois o treino não requer otimizações particularmente complexas.
Previsão de novos casos
Introduza novos registos e o modelo atribui uma classe. Por exemplo, «spam», «não spam», «cliente de risco», «cliente estável».
Avaliação do
: Compare as previsões com a realidade num conjunto de dados de teste separado. Aqui, não se trata apenas de verificar se o modelo funciona. Trata-se de ver como é que ele erra.
Se quiser aprofundar o panorama geral das abordagens preditivas, esta visão geral sobre os algoritmos de aprendizagem automática ajuda a situar o Naive Bayes no contexto de uma família mais ampla de métodos.
Para tornar o processo mais concreto, eis um exemplo simples com o scikit-learn. Não é preciso interpretá-lo como um programador. Basta compreender o fluxo.
# Importamos as principais ferramentasfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# Carregamos um conjunto de dados de exemploX, y = load_iris(return_X_y=True)# Dividimos os dados em uma parte para treino e outra para testeX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Criemos o modelo model = GaussianNB()# Treinemos o modelo com os dados históricos model.fit(X_train, y_train)# Façamos previsões sobre dados nunca vistos y_pred = model.predict(X_test)# Medamos a precisão print(accuracy_score(y_test, y_pred))Este trecho diz muito mais do que parece.
GaussianNB() escolha a opção para dados contínuos.fit() é o momento em que o modelo aprende.predict() aplica o que aprendeu.accuracy_score() verifica quantas classificações estão corretas no total.No caso de dados textuais, o fluxo permanece semelhante, mas antes de aplicar o modelo é necessário converter o texto em números. Na prática, converte-se as palavras em características que possam ser utilizadas por um classificador.
Depois de uma primeira análise do código, pode ser útil ver uma explicação visual do mecanismo.
O primeiro modelo não serve para demonstrar perfeição. Serve para responder a três questões práticas.
É aqui que se vê a força do Naive Bayes. É possível chegar rapidamente a uma base sólida. A partir daí, percebe-se se faz sentido complicar o projeto ou se uma solução simples já está a gerar valor.
Um modelo de classificação não se avalia apenas pelo facto de «parecer funcionar». Avalia-se pela forma como comete erros e pelo impacto que esses erros têm no negócio.

A precisão é a métrica mais intuitiva. Indica quantas previsões estão corretas em relação ao total. É útil, mas, por si só, pode induzir em erro.
Se, de cada cem transações, apenas algumas são realmente suspeitas, um modelo que classifica quase tudo como normal pode parecer bom em termos de precisão, mas acabar por ter um desempenho fraco onde realmente importa.
Para compreender isso, pensa numa rede de pesca.
No mundo dos negócios, esta distinção é muito importante.
Um bom modelo não é aquele que comete poucos erros em geral. É aquele que comete erros da forma menos onerosa para o seu processo.
Para compreender melhor como um algoritmo aprende com os dados históricos e por que razão a qualidade do treino influencia o resultado final, pode ler este artigo detalhado sobre o que consiste o treino de um algoritmo.
O Naive Bayes é simples, mas não perdoa certos erros práticos.
Primeiro erro: ignorar o problema da frequência zero.
Se uma palavra ou um valor nunca aparecer nos dados de treino para uma determinada classe, a probabilidade pode cair para zero e comprometer o cálculo. Por isso, utiliza-se frequentemente o suavização de Laplace, que adiciona uma pequena correção às contagens.
Segundo erro: utilizar características fortemente correlacionadas.
Se duas colunas fornecem praticamente a mesma informação, o modelo corre o risco de sobrestimar o sinal. Ele não «percebe» que as duas características são praticamente duplicadas.
Terceiro erro: confiar demasiado nas probabilidades brutas.
O Naive Bayes costuma classificar bem, mas as suas probabilidades podem ser demasiado categóricas. Para as empresas, isto significa que a classificação pode ser útil, mas o valor exato da probabilidade deve ser interpretado com cautela.
Para reduzir esses riscos, é aconselhável:
O verdadeiro valor dos classificadores bayesianos ingênuos revela-se quando deixamos de os considerar um exercício matemático e começamos a utilizá-los como um mecanismo de definição de prioridades. Nas empresas, classificar bem significa, quase sempre, tomar melhores decisões.

Imagine uma equipa financeira que analisa fluxos de transações, descrições operacionais e dados históricos. Cada linha não é apenas um registo. É uma decisão potencial: deixar passar, aprofundar, bloquear ou encaminhar para um analista.
Com o Naive Bayes, é possível combinar diferentes indicadores numa única classificação. Alguns são numéricos, outros binários e outros ainda textuais. O modelo ajuda a compreender quais os casos que mais se assemelham a padrões já observados como normais ou anómalos.
A vantagem prática é dupla:
Não substitui o julgamento humano em contextos regulamentados. Organiza-o. E, em processos operacionais de grande volume, isso faz uma diferença real.
No marketing, classificar significa, muitas vezes, atribuir cada cliente a um grupo operacional. Clientes fiéis. Sensíveis ao preço. Em risco de abandono. Receptivos às promoções. Inativos.
Neste caso, o Naive Bayes é útil porque consegue combinar sinais heterogéneos de forma rápida:
Uma equipa de CRM não precisa de uma teoria perfeita sobre o comportamento humano. Precisa de uma segmentação suficientemente boa para dar origem a ações sensatas. Por exemplo, alterar a mensagem, a frequência de contacto ou o tipo de oferta.
Quando um modelo ajuda a escolher a próxima mensagem para o cliente certo, já está a criar valor operacional.
No retalho e no comércio eletrónico, a classificação apoia atividades que parecem diferentes, mas que partilham a mesma lógica: pôr ordem no caos.
Podes classificar os produtos com base no seu perfil de vendas. Podes ler comentários e tickets para perceber quais as categorias que geram atrito. Podes identificar padrões de procura que ajudam a equipa a planear promoções e stocks com maior clareza.
Neste tipo de ambiente, os dados são frequentemente numerosos, heterogéneos e nem sempre perfeitos. Por isso, um modelo rápido, escalável e legível tem um grande valor. Não porque seja o mais apelativo, mas porque se integra no fluxo de trabalho sem o atrasar.
Se quiseres ver como as abordagens de análise aplicadas aos negócios se concretizam em projetos reais, podes dar uma vista de olhos nestes estudos de caso.
Compreender o Naive Bayes é útil. Implementá-lo corretamente num contexto empresarial é outra história.
O problema quase nunca se resume apenas ao algoritmo. O verdadeiro trabalho reside no modelo. É preciso ligar diferentes fontes de dados, gerir campos em falta, preparar textos, atualizar rótulos, verificar a qualidade dos resultados e interpretar os resultados de forma compreensível para os decisores.
Para uma PME, esta etapa é frequentemente o ponto crítico. Não por falta de interesse na IA, mas porque o tempo da equipa é limitado e as prioridades operacionais não podem esperar.
Neste caso, faz sentido utilizar uma plataforma que absorva a complexidade técnica. Uma solução baseada em IA permite transformar dados brutos em informações úteis, sem que a empresa tenha de escrever código, escolher bibliotecas ou gerir pipelines manualmente.
Uma plataforma como ELECTE, uma plataforma de análise de dados baseada em IA para PME, torna acessíveis métodos como os classificadores bayesianos ingênuos, sem exigir conhecimentos especializados em aprendizagem automática. A vantagem não é apenas a rapidez. É a redução do atrito entre os dados e a tomada de decisão.
Quando a automação funciona bem, a equipa deixa de pensar em termos de fórmulas. Pensa em termos de perguntas úteis:
É também por isso que cada vez mais empresas procuram ferramentas que ajudem a avaliar a fiabilidade dos conteúdos gerados pela IA e dos sinais textuais que circulam nos processos internos. Neste contexto, pode ser útil consultar também um guia sobre um detetor de IA em português, especialmente se a sua equipa trabalha com documentos, conteúdos e revisões linguísticas.
Na prática, a diferença é simples. Em vez de gerir etapas técnicas fragmentadas, concentra-se no resultado da empresa. E é aqui que a IA se torna realmente viável, e não apenas interessante.
Os classificadores bayesianos ingênuos ensinam-nos uma lição importante. Na análise de dados, a simplicidade bem aplicada pode superar a complexidade mal gerida.
Com uma base probabilística intuitiva, boa escalabilidade e casos de utilização muito concretos, esta abordagem continua a ser uma ferramenta fiável para as empresas que pretendem classificar informações, identificar sinais ocultos e agir com maior segurança. Não é necessário ser especialista em aprendizagem automática para compreender o seu valor. O que é preciso é ligar a matemática à tomada de decisões operacionais.
Quando esta ligação fica clara, a IA deixa de ser uma questão técnica e passa a ser uma vantagem organizacional. É aí que a previsão começa a ter impacto.
Se quiser transformar dados dispersos em informações claras, experimente ELECTE. A plataforma ajuda as PME a ligar fontes de dados, automatizar a análise e obter relatórios e previsões úteis para decisões mais rápidas e informadas.

.svg)
.svg)
.svg)






