

Primești un fișier XML prin PEC. Îl deschizi în browser, vezi o mulțime de etichete și crezi că problema este „citirea” lui. De fapt, acesta este doar primul obstacol. Adevărata problemă în cadrul companiei este alta: să înțelegi dacă acele date sunt corecte, coerente și gata să fie incluse în rapoartele tale.
Pentru multe IMM-uri italiene, această temă nu mai este una strict tehnică. De când facturarea electronică a devenit obligatorie, formatul XML a intrat în activitatea zilnică de administrare, control de gestiune și analiză. Nu este suficient să vizualizezi documentul. Trebuie să știi să faci diferența între un fișier lizibil și unul fiabil. Trebuie să înțelegi când este suficientă o verificare rapidă și când este necesară parsarea, validarea și normalizarea înainte de a încărca datele în Excel, în BI sau într-o platformă de analiză.
Dacă ești în căutarea unui ghid practic despre cum să citești fișiere XML, aceasta este calea corectă: începe cu metodele simple, înțelege unde apar problemele, apoi construiește un flux care să transforme XML-ul brut în date utile pentru afaceri. Așa se reduc erorile și se scurtează timpul dintre „am fișierul” și „am o informație utilă”.
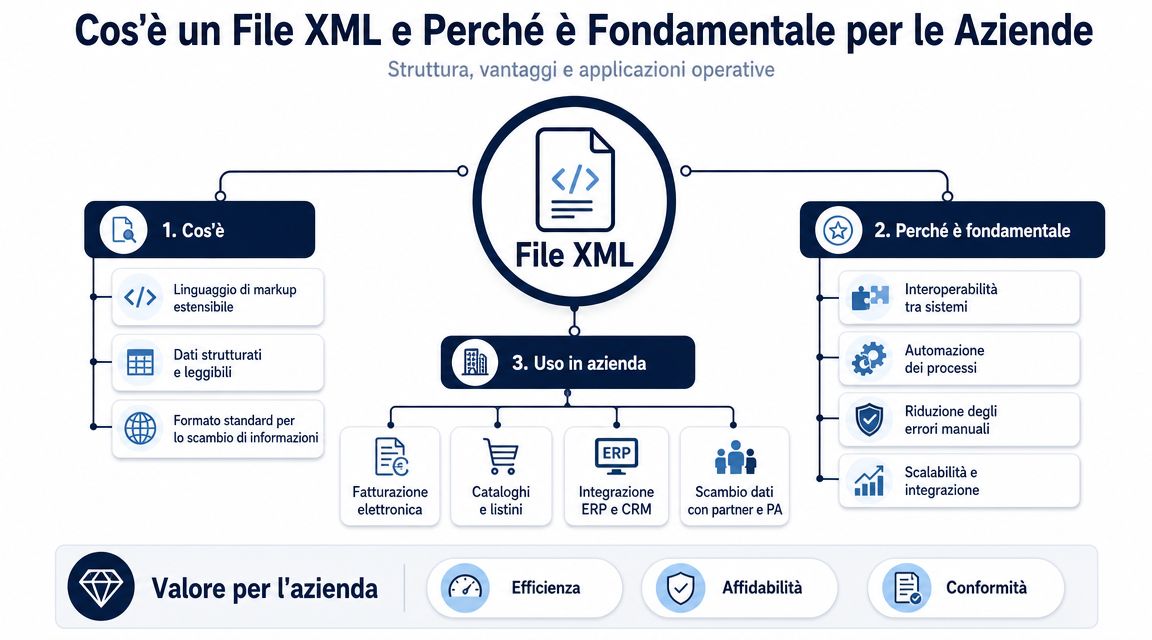
Un fișier XML organizează datele într-o structură ierarhică. Există un element principal, există secțiuni imbricate, iar fiecare bloc descrie o informație cu o semnificație precisă. Pentru cei care gestionează procesele administrative, acest detaliu face diferența între o informație lizibilă și una cu adevărat utilă.
Nu este vorba despre „deschiderea” fișierului. Este vorba despre a înțelege dacă acel fișier poate fi integrat fără erori în fluxurile de control, contabilitate și analiză.
Să luăm ca exemplu o factură electronică. În același fișier se regăsesc simultan datele furnizorului, datele clientului, sumele impozabile, TVA-ul, rândurile cu articole, condițiile de plată, referințele comenzii și, adesea, chiar și excepții care complică citirea. În formatul XML, aceste informații nu sunt așezate una sub alta, ca într-un document obișnuit. Ele sunt plasate în poziții precise, iar acea poziție explică ce reprezintă.
Pentru un manager, distincția utilă nu este cea dintre etichete și atribute în sens teoretic. Ci cea dintre o informație izolată și o informație fiabilă. A citi „1000,00” fără context nu are prea mare utilitate. Citirea acestei valori în locul potrivit din fișier permite să se înțeleagă dacă este vorba despre totalul documentului, baza de impozitare, impozitul sau valoarea unei singure linii.
Aici apare primul avantaj operațional. XML păstrează contextul datelor.
Regulă practică: a citi corect un fișier XML înseamnă a verifica semnificația valorii, nu doar valoarea în sine.
În Italia, această temă a căpătat o dimensiune concretă odată cu răspândirea facturării electronice. În formatul FatturaPA, XML a devenit standardul pentru documentația fiscală. În consecință, interpretarea acestuia nu mai ține doar de domeniul IT. Ea implică administrația, controlul de gestiune, departamentul de achiziții și pe oricine trebuie să utilizeze aceste date pentru a lua decizii.
În practică, observ mereu aceeași problemă. Fișierul există, datele sunt acolo, dar timpul necesar pentru a le transforma în informații utile se prelungește prea mult. O persoană deschide fișierul XML, îl verifică vizual, copiază valorile în Excel, corectează câmpurile neuniforme, redenumește furnizorii scriși în moduri diferite și încearcă să reconstituie categoriile de cheltuieli pe care fișierul nu le prezintă într-o formă gata de analiză. Costul nu este doar operațional. Este timp pierdut până la obținerea de informații utile.
Cu FatturaPA, riscul este și mai evident. Două fișiere corecte din punct de vedere formal pot genera aceleași probleme de analiză dacă unul dintre ele conține descrieri de rând foarte neclare, dacă referințele comenzii sunt incomplete sau dacă datele de bază ale furnizorului sunt introduse cu variante diferite. În acest moment, problema nu constă în citirea XML-ului. Problema este aceea de a evita ca datele fiscale valide să devină date de gestiune puțin fiabile.
O greșeală frecventă este aceea de a trata XML-ul ca pe un atașament care trebuie vizualizat. În cadrul companiei, este mai eficient să-l considerăm o sursă de date structurată, care trebuie verificată înainte de a alimenta rapoartele, tablourile de bord și modelele de cheltuieli. Dacă această etapă este gestionată necorespunzător, echipa financiară se trezește discutând cifre aparent precise, dar bazate pe clasificări incoerente.
La început, întrebările potrivite sunt următoarele:
Sunt verificări foarte concrete. Acestea servesc la evitarea apariției furnizorilor în dublu exemplar în rapoarte, a interpretării eronate a TVA-ului, a completării incomplete a centrelor de cost și a reconcilierilor lente la sfârșitul lunii.
Aici se observă diferența dintre interpretarea tehnică și valoarea pentru afaceri. Un parser citește fișierul. Un proces bine conceput generează date curate, comparabile și gata de analiză. Platforme precum ELECTE au fost create tocmai pentru a elimina această discrepanță, reducând efortul manual necesar pentru a transforma XML-ul primit în informații utile pentru luarea unor decizii mai bune.
Pentru verificări rapide ale unui singur fișier, nu sunt necesare parsere sau biblioteci. Trebuie să înțelegi dacă efectuezi o verificare vizuală a câtorva câmpuri sau dacă lucrezi deja cu date care vor ajunge în contabilitate, raportare sau controlul de gestiune. Diferența contează, mai ales în cazul facturilor FatturePA. O verificare efectuată în grabă astăzi poate deveni mâine o linie eronată în setul de date al furnizorilor.

Browserele, editorii de text și vizualizatoarele dedicate rezolvă o problemă specifică: citirea rapidă a conținutului fără a configura un flux tehnic. Pentru un fișier izolat, de multe ori este suficient. Poți deschide un fișier XML în Chrome, Edge sau Firefox pentru a vedea structura acestuia, sau poți folosi Notepad, WordPad sau TextEdit dacă dorești să inspectezi direct etichetele. În cazul facturilor electronice, un vizualizator dedicat face ca antetul, liniile documentului, baza de impozitare și TVA-ul să fie mai ușor de citit.
Ideea de bază este următoarea:
| Instrument | Util pentru | Limită principală |
|---|---|---|
| Browser | Verificare vizuală rapidă a structurii | Nu verifică coerența dintre câmpuri și secțiuni |
| Editor de text | Inspecția directă a etichetelor | Devine incomod în cazul fișierelor lungi sau imbricate |
| Excel | Verificare preliminară sub formă de tabel | Nu gestionează bine ierarhiile și repetițiile |
| Vizualizator dedicat | O citire mai clară a facturilor și a documentelor fiscale | Nu pregătește datele pentru analize sau automatizări |
Dacă trebuie să verifici data documentului, numărul de înregistrare fiscală, valoarea totală a facturii sau prezența anexelor, aceste instrumente sunt potrivite.
Dacă, în schimb, obiectivul este să se compare furnizorii, să se clasifice cheltuielile sau să se alimenteze un tablou de bord, simpla vizualizare încetinește munca și lasă prea mult loc pentru erori manuale. Este clasica discrepanță dintre a vedea un fișier și a obține o informație fiabilă în timp util.
Deschiderea unui fișier XML nu înseamnă validarea datelor pe care le vei folosi în rapoarte.
Un alt aspect practic se referă la volum. Zece fișiere pot fi verificate și manual. Sute de facturi FatturePA, însă, nu. În acest caz, este deja recomandabil să se ia în considerare un flux repetabil sau instrumente care să citească conținutul într-un mod structurat, de exemplu prin intermediul unei API pentru preluarea și gestionarea documentelor fiscale într-un mod integrat.
În Italia, problema care apare frecvent nu este deschiderea unui .xml, dar să înțelegi ce trebuie să faci când apare un .xml.p7m prin PEC. Trebuie să se facă distincția între fișierele XML simple și fișierele semnate digital. În cel de-al doilea caz sunt necesare instrumente capabile să citească semnătura, să extragă conținutul și să afișeze fișierul XML corect, așa cum explică acest ghid dedicat XML și XML P7M în PEC.
Aici, greșelile costă timp:
Pentru un angajat administrativ, secvența cea mai utilă este simplă:
Aceste metode își îndeplinesc bine rolul în cadrul controalelor de prim nivel. Ele nu rezolvă însă problema cu adevărat importantă pentru companie: transformarea fișierelor XML fiscale, adesea neregulate sau puțin uniforme, în date curate și comparabile, fără a prelungi intervalul de timp dintre primirea documentului și obținerea informațiilor utile.
Când fișierele încep să se acumuleze, munca manuală nu mai este viabilă. În acel moment, citirea fișierelor XML cu ajutorul codului nu mai este o soluție elegantă. Este primul pas pentru a evita activitățile repetitive, erorile de copiere și seturile de date incoerente.

O abordare solidă a citirii fișierelor XML urmează întotdeauna aceeași logică: analiză sintactică, normalizare, extragere selectivă. În tutorialele Java și Android, fluxul corect trece prin parse(), prin normalizarea arborelui cu doc.getDocumentElement().normalize() și apoi prin refacerea terenurilor cu getElementsByTagName, o metodă mai stabilă decât simpla vizualizare într-un editor de text, așa cum se vede acest tutorial tehnic privind citirea datelor XML.
Această secvență contează mai mult decât limbajul pe care îl alegi. Dacă omiti normalizarea, dacă cauți noduri într-un mod prea simplist sau dacă presupui că o etichetă apare întotdeauna o singură dată, scriptul tău va funcționa pe unele fișiere, dar va eșua tocmai pe cele care contează.
Pentru proiectele care trebuie să interacționeze ulterior cu sisteme externe, poate fi util să se creeze un flux de extragere replicabil și documentat. Dacă lucrezi la integrări de aplicații, o bază utilă o constituie documentația privind API-urile ELECTE cu profil Postman verificat, mai ales pentru a înțelege cum se poate conecta un set de date deja curățat la procesele ulterioare.
Mai jos găsești câteva exemple simple. Scopul nu este acela de a acoperi toate cazurile, ci de a-ți arăta logica de bază: deschiderea fișierului, găsirea unui nod, afișarea unei valori.
import xml.etree.ElementTree as ETtree = ET.parse("fattura.xml")root = tree.getroot()numero = root.find(".//Numero")if numero is not None:print(numero.text)Python este adesea cea mai rapidă opțiune pentru prototipuri, transformări și fluxuri de lucru ușoare. Este excelent atunci când trebuie să citești multe fișiere XML, să extragi câteva câmpuri și să le salvezi în format CSV sau JSON.
const xmlString = `<fattura><Numero>123</Numero></fattura>`;const parser = new DOMParser();const xmlDoc = parser.parseFromString(xmlString, "application/xml");const numero = xmlDoc.getElementsByTagName("Numero")[0];console.log(numero.textContent);Această abordare este utilă pentru testele rapide efectuate direct pe pagină sau pentru mici instrumente interne. Este potrivită pentru interfețe ușoare, dar mai puțin pentru fluxurile structurate din back-office.
const fs = require("fs");const xml2js = require("xml2js");const xml = fs.readFileSync("fattura.xml", "utf8");xml2js.parseString(xml, (err, result) => {if (err) throw err;console.log(result.fattura.Numero[0]);});Dacă lucrezi pe partea de server și vrei să creezi automatizări, Node.js rămâne o alegere practică. Avantajul constă în integrarea ușoară a citirii fișierelor XML cu sistemul de fișiere, cozile de procesare și serviciile interne.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse("fattura.xml");doc.getDocumentElement().normalize();NodeList lista = doc.getElementsByTagName("Numero");if (lista.getLength() > 0) {System.out.println(lista.item(0).getTextContent());}Java este adesea utilizată în contexte enterprise, de gestionare și middleware. În acest context, aspectul esențial nu este doar citirea datelor, ci realizarea acestui proces într-un mod previzibil și ușor de întreținut.
library(XML)doc <- xmlParse("fattura.xml")numero <- xpathSApply(doc, "//Numero", xmlValue)print(numero)R are sens atunci când parsarea face parte dintr-un proces analitic. Dacă următorul tău pas este o analiză statistică sau o pregătire a datelor, poți păstra totul în același mediu.
Dacă echipa ta deschide aceleași fișiere în fiecare săptămână și repetă aceleași verificări, te afli deja în domeniul automatizării.
Adevăratul beneficiu nu constă în „citirea fișierelor XML cu ajutorul codului”. Ci în a scuti oamenii de o muncă mecanică și în a crea un flux care generează seturi de date consistente.
Problemele serioase apar atunci când nu mai este vorba de un singur fișier. O singură factură FatturaPA este aproape întotdeauna ușor de gestionat. Dificultățile apar atunci când trebuie să consolidezi documente din mai multe luni, furnizori diferiți, câmpuri completate în mod neuniform și anexe încorporate.
În cazul IMM-urilor italiene, cel mai frecvent scenariu nu este „fișierul uriaș” izolat, ci lotul. O exportare anuală a facturilor primite poate genera o structură cu peste 380.000 de noduri pe 4.200 de facturi, incluzând anteturi, rânduri de detalii, date de plată și atașamente în format base64. În aceste scenarii, problema nu constă în deschiderea documentului, ci în transformarea fișierelor XML eterogene într-un set de date coerent.
Aici intervine o alegere tehnică care are implicații asupra activității. În mediul .NET, Microsoft precizează că XmlDocument încarcă documentul în memorie și este util pentru citire și modificare, în timp ce pentru fișiere de dimensiuni mari sau operațiuni de tip „doar citire” este recomandabil să se opteze pentru abordări mai eficiente, precum parserul de tip streaming sau XPathDocument, pentru a evita consumul excesiv de memorie RAM, așa cum se specifică în documentația Microsoft privind citirea XML cu XmlDocument și XPathDocument.
Practic:
Compromisul este simplu. Modelul stocat în memorie îți permite să dezvolți mai repede. Modelul de streaming se comportă mai bine în producție atunci când fișierele sunt numeroase sau de dimensiuni mari.
Multe echipe se limitează la validarea XSD. Este utilă, dar nu este suficientă. Un fișier poate respecta schema și totuși să genereze date eronate în etapele ulterioare.
Exemple tipice din activitatea operațională:
| Tipul de control | Ce verifică | De ce este necesar |
|---|---|---|
| Structural | Etichete, format, ierarhie | Evită erorile de analiză sintactică |
| Semantic | Coerența logică a datelor | Evită analizele eronate |
| Funcțional | Prezența câmpurilor utile pentru raportare | Evită seturile de date inutilizabile |
Cel mai insidios caz este acesta: „ImportoTotaleDocumento” este valid din punct de vedere formal, dar nu corespunde cu suma liniilor, poate din cauza logicii de rotunjire a sistemului de gestionare al furnizorului. Sau coduri TVA admise din punct de vedere formal, dar care nu corespund naturii operațiunii.
Un fișier corect din punct de vedere formal poate totuși să afecteze negativ raportarea ta.
Există, de asemenea, o altă capcană cunoscută în FatturaPA. Eticheta „DatiBeniServizi” conține descrieri libere. Același cost poate apărea în multe moduri diferite, cu texte clare, prescurtate sau criptice. Dacă nu introduci o etapă de normalizare, orice analiză pe categorii de cheltuieli devine nesigură.
De aceea, în fluxurile serioase, citirea fișierului reprezintă doar nivelul unu. Nivelul doi constă întotdeauna într-un set de reguli de coerență și curățare. Acolo se asigură calitatea datelor, nu în parser.
Un fișier XML citit corect nu este încă un set de date util. Este un document structurat. Pentru a efectua analize, comparații, grupări și a crea tablouri de bord, aproape întotdeauna trebuie să îl convertești într-un format mai ușor de prelucrat.
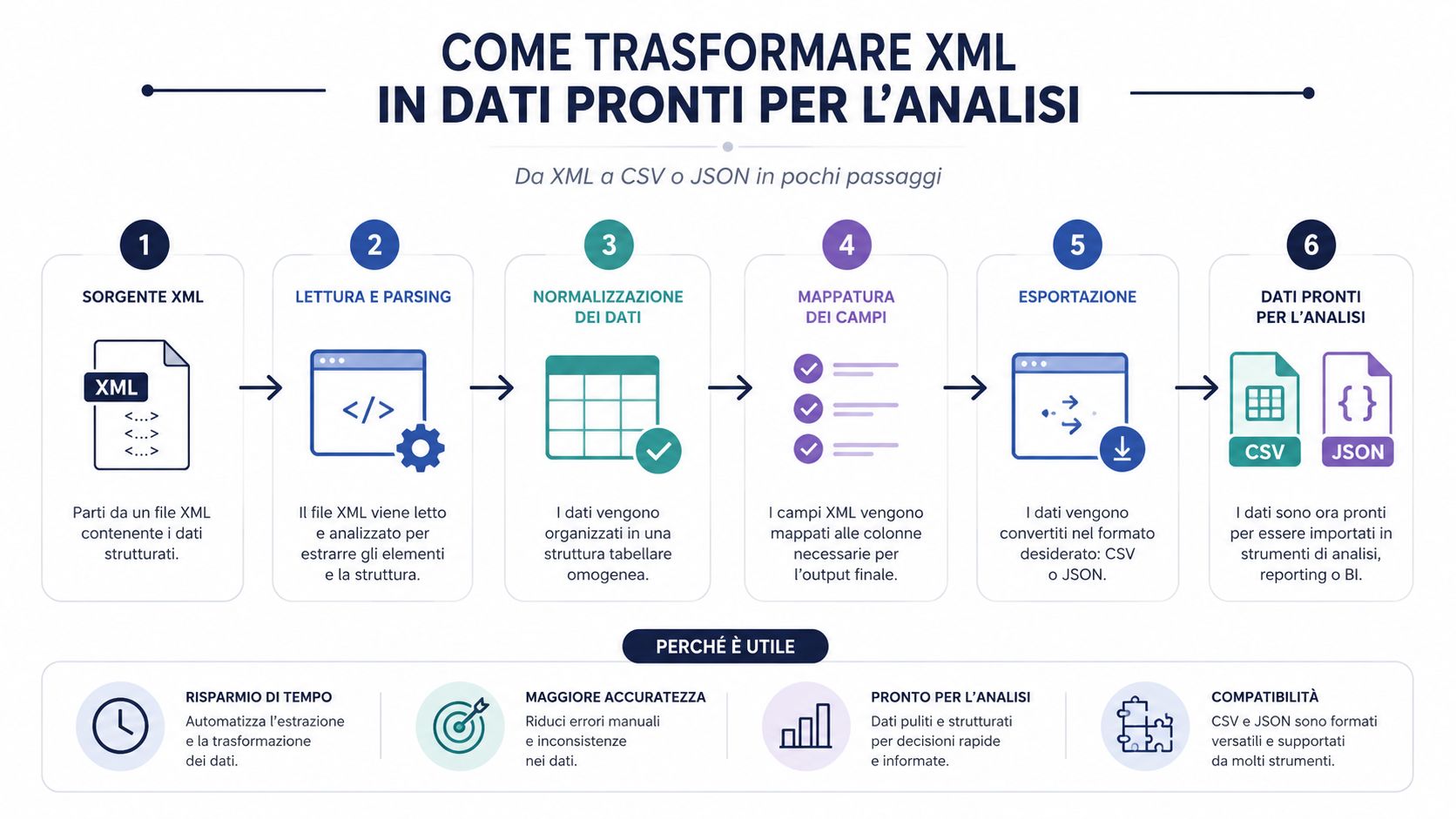
Acesta este aspectul pe care multe procese îl subestimează. Gâtul de sticlă rareori constă în simpla analiză sintactică. O bibliotecă decentă citește un fișier XML rapid. Timpul se pierde în interpretarea structurii, extragerea câmpurilor utile, curățarea, normalizarea și încărcarea într-un instrument de analiză.
De aceea, conversia în format CSV sau JSON nu este doar o chestiune de comoditate. Este o etapă operațională esențială. Dacă sari peste această etapă și lucrezi direct pe fișierul brut, ajungi aproape întotdeauna să faci verificări manuale, să creezi coloane improvizate și să folosești logici greu de reprodus.
Un ghid util pentru cei care lucrează frecvent cu fișiere XML și foi de calcul este acest ghid despre cum să treci de la XML la Excel într-un mod mai organizat.
Formatul potrivit depinde de modul în care vei folosi datele ulterior.
CSV funcționează bine atunci când doriți o linie pentru fiecare document sau o linie pentru fiecare detaliu al facturii, pentru a utiliza apoi Excel, Power Query sau BI.
Exemplu în Python:
import xml.etree.ElementTree as ETimport csvtree = ET.parse("fattura.xml")root = tree.getroot()with open("fatture.csv", "w", newline="", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(["numero", "data"])numero = root.findtext(".//Numero")data = root.findtext(".//Data")writer.writerow([numero, data])Avantajul este simplitatea. Dezavantajul este că trebuie să decizi cu atenție cum să aplatizezi ierarhia. Dacă o factură are mai multe rânduri de detalii, este necesară o alegere clară în ceea ce privește granularitatea și cheia de legătură.
JSON este mai potrivit atunci când dorești să păstrezi o parte din structura ierarhică.
Exemplu de JavaScript:
const record = {numero: "123",data: "2024-01-15",righe: [{ descrizione: "Servizio", importo: "100.00" }]};console.log(JSON.stringify(record, null, 2));Folosește-l atunci când următorul tău pas este o API, un data lake sau o aplicație care funcționează bine cu obiecte imbricate.
Iată o regulă practică care te ajută:
Fișierul XML este containerul. CSV și JSON sunt formatele care fac conținutul cu adevărat utilizabil.
Dacă vrei să reduci timpul necesar pentru obținerea de informații utile, aici merită să investești efort. Nu în găsirea unui vizualizator mai ușor de folosit, ci în definirea unei transformări stabile și repetabile.
Odată ce fișierul a fost citit, validat și transformat, natura muncii se schimbă. Nu te mai lupți cu etichetele. În sfârșit, te concentrezi asupra costurilor, anomaliilor, furnizorilor, categoriilor de cheltuieli și tendințelor operaționale.
În practică, valoarea nu constă în timpul necesar pentru parsare. Ea constă în timpul care separă fișierul brut de informația pe baza căreia poți lua o decizie. Într-un flux manual, o persoană trebuie să deschidă documentul, să înțeleagă structura acestuia, să extragă câmpurile, să curețe valorile, să normalizeze textele și apoi să creeze rapoarte. Este un proces fragil.
Un exemplu clasic în FatturaPA este câmpul de text liber din secțiunea „DatiBeniServizi”. Același serviciu poate fi descris în multe moduri diferite de către furnizori diferiți. Dacă importați aceste date fără o mapare coerentă, analiza pe categorii de costuri generează agregări inutile.
Din acest motiv, înainte de platforma de analiză, este necesar un nivel de pregătire, având în vedere că:
Atunci când această etapă este realizată corect, orice platformă de analiză funcționează mai bine. Dacă dorești să aprofundezi aspectul decizional și vizual al acestei etape, resursa despre cum să construiești povești cu ajutorul datelor este utilă, deoarece arată cum un set de date curățat se transformă într-o narațiune utilă pentru factorii de decizie.
În acest moment, fișierul XML încetează să mai fie o problemă tehnică și devine materie primă pentru obținerea de informații utile. Un set de date bine pregătit poate sta la baza analizelor cheltuielilor, monitorizării tendințelor, identificării abaterilor și interpretării excepțiilor.
Pentru a alege o platformă potrivită pentru această „ultimă etapă”, ar putea fi util să compari ce oferă un software modern de analiză de afaceri în comparație cu fluxurile pur manuale, bazate pe foi de calcul și tabele pivot.
Aici criteriul corect nu este „știe să deschidă fișiere XML?”. Asta e minimul. Întrebarea relevantă este alta:
| Întrebare | De ce contează |
|---|---|
| Datele sunt deja curățate | Evitați concluziile precise bazate pe date eronate |
| Categoriile sunt coerente | Compari cu adevărat furnizorii și perioadele |
| Anomaliile se observă imediat | Reduceți timpul pierdut cu verificările manuale |
| Raportul este accesibil pentru departamentele de afaceri și finanțe | Accelerează procesul decizional |
Diferența dintre un proces în stadiu incipient și unul matur nu constă în capacitatea de a citi fișiere XML. Ea constă în capacitatea de a le transforma într-o bază de date fiabilă, care să nu oblige echipa să refacă de fiecare dată aceeași muncă.
Dacă trebuie să citești fișiere XML într-un mod util pentru afaceri, ține cont de această listă de verificare. Este mai concretă decât orice definiție tehnică și te ajută să alegi metoda potrivită fără să pierzi timp.
Nu folosiți mereu aceeași abordare. Browserele, editorii și vizualizatoarele sunt potrivite pentru verificări rapide. Analizatoarele și scripturile sunt necesare atunci când fișierul trebuie să alimenteze procese repetitive. Dacă confundați vizualizarea cu prelucrarea datelor, riscați să creați rapoarte pe baze fragile.
Fișierele .xml.p7m necesită o etapă specifică de gestionare a semnăturii. Dacă conținutul provine dintr-o adresă PEC, această verificare nu este una secundară. Face parte din procesul de citire corectă a documentului.
Respectarea unui format nu garantează un set de date corect. Incoerențele logice, precum totalurile care nu se potrivesc sau clasificările fiscale ambigue, sunt cele care afectează cel mai adesea analiza. Verificarea semantică este ceea ce face diferența între un fișier „acceptabil” și un set de date fiabil.
CSV și JSON nu sunt doar o schimbare de formă. Ele reprezintă punctul în care XML devine utilizabil de către instrumentele de analiză, foile de calcul, fluxurile de date și rapoartele. Cu cât definiți mai repede această transformare, cu atât reduceți mai repede munca manuală și improvizația.
Obiectivul tău nu este să citești fișiere XML. Este să obții informații utile fără a polua sistemul cu date eronate. Dacă fluxul nu generează un set de date coerent, problema nu se află în tabloul de bord final. Se află mult mai sus în lanțul de procesare.
Practic, poți folosi această mini-listă de verificare înainte de fiecare proiect nou:
Dacă doriți să transformați datele deja pregătite în informații clare și utile, ELECTE ajută IMM-urile să treacă de la un set de date curățat la raportare inteligentă, printr-o abordare accesibilă chiar și echipelor fără cunoștințe tehnice. Este cea mai rapidă modalitate de a reduce distanța dintre datele operaționale și procesul decizional.

.svg)
.svg)
.svg)
.webp)





