

Datele tale spun deja o poveste. Problema este că, de multe ori, vorbesc prea încet.
În fiecare zi, o întreprindere mică sau mijlocie acumulează feedback de la clienți, comenzi, tichete de asistență, tranzacții financiare, e-mailuri comerciale și note din CRM. Toate aceste informații conțin indicii utile. Unele indică faptul că un client este pe punctul de a renunța. Altele prevăd un risc operațional. Altele arată care produse sunt pe cale să înregistreze o creștere sau o scădere. Fără o metodă clară, însă, aceste indicii rămân doar zgomot de fond.
Printre algoritmii care ajută la aducerea ordinii în acest haos, clasificatorii bayesieni naivi ocupă un loc special. Sunt ușor de înțeles din punct de vedere logic, rapizi de antrenat și adesea mai eficienți decât ar sugera denumirea de „naivi”. Nu reprezintă alegerea potrivită pentru orice scenariu, dar în multe probleme reale din mediul de afaceri oferă un echilibru rar între viteză, interpretabilitate și rezultate utile.
Dacă lucrezi în domeniul afacerilor, nu e nevoie să devii cercetător pentru a le înțelege. Trebuie să știi ce fac, de ce funcționează bine chiar și atunci când simplifică foarte mult realitatea și în ce situații te pot ajuta să iei decizii mai bune. Tocmai aici merită să ne oprim.
Multe companii caută modele sofisticate, deși problema necesită, în primul rând, un model fiabil și ușor de utilizat. Acesta este și motivul pentru care, în domeniul finanțelor, al comerțului cu amănuntul sau al serviciilor de relații cu clienții, de multe ori câștigă procesul cel mai clar, nu cel mai elegant din punct de vedere teoretic.
Clasificatoarele bayesiene naive pornesc de la o idee foarte concretă. Dacă ai câteva indicii despre un caz nou, poți estima cu o probabilitate ridicată la ce categorie aparține. Dacă un e-mail conține anumite cuvinte, ar putea fi spam. Dacă o tranzacție prezintă anumite tipare, ar putea necesita o verificare. Dacă o recenzie folosește anumite termeni, ar putea indica satisfacție sau nemulțumire.
Cuvântul „bayesian” sugerează formule complexe. De fapt, esența metodei este intuitivă. Pornești de la ceea ce știi deja, adaugi noi dovezi și îți actualizezi părerea. Este o modalitate ordonată de a raționa în condiții de incertitudine, exact ceea ce fac managerii în fiecare zi, doar că este sistematizată printr-un algoritm.
Ceea ce surprinde este faptul că această abordare continuă să funcționeze bine chiar și în mediile moderne, caracterizate de volume mari de date și decizii rapide. Nu pentru că ar descrie lumea în mod perfect, ci pentru că separă informația utilă de zgomotul de fond cu un cost computacional foarte redus.
În ceea ce privește problemele de afaceri, întrebarea potrivită nu este „care este cel mai sofisticat model?”. Ci „care model îmi oferă decizii fiabile într-un timp compatibil cu activitatea reală?”.
De aceea, clasificatorii bayesieni naivi rămân importanți. Aceștia te ajută să clasifici, să filtrezi, să segmentezi și să stabilești priorități. În plus, îți permit să integrezi probabilitatea în procesul decizional fără a transforma fiecare proiect într-un șantier tehnic.
Principiul de bază este teorema lui Bayes. În termeni simpli, aceasta spune următoarele: pornești de la o probabilitate inițială, pe care o actualizezi pe măsură ce apar informații noi.
În limbajul datelor, formula se citește astfel: P(y|x) ∝ P(y) ⋅ ∏ P(x_i|y). Aceasta înseamnă că probabilitatea unei clase, având în vedere un set de semnale, depinde de doi factori. Primul este probabilitatea inițială a clasei. Al doilea este măsura în care fiecare semnal este compatibil cu acea clasă.
Transpus într-un exemplu din domeniul afacerilor. Trebuie să-ți dai seama dacă un e-mail este spam sau nu. Ai o probabilitate generală ca un e-mail primit să fie spam. Apoi observi anumite cuvinte precum „ofertă”, „gratuit”, „dă clic aici”. Fiecare dintre aceste cuvinte influențează decizia finală.
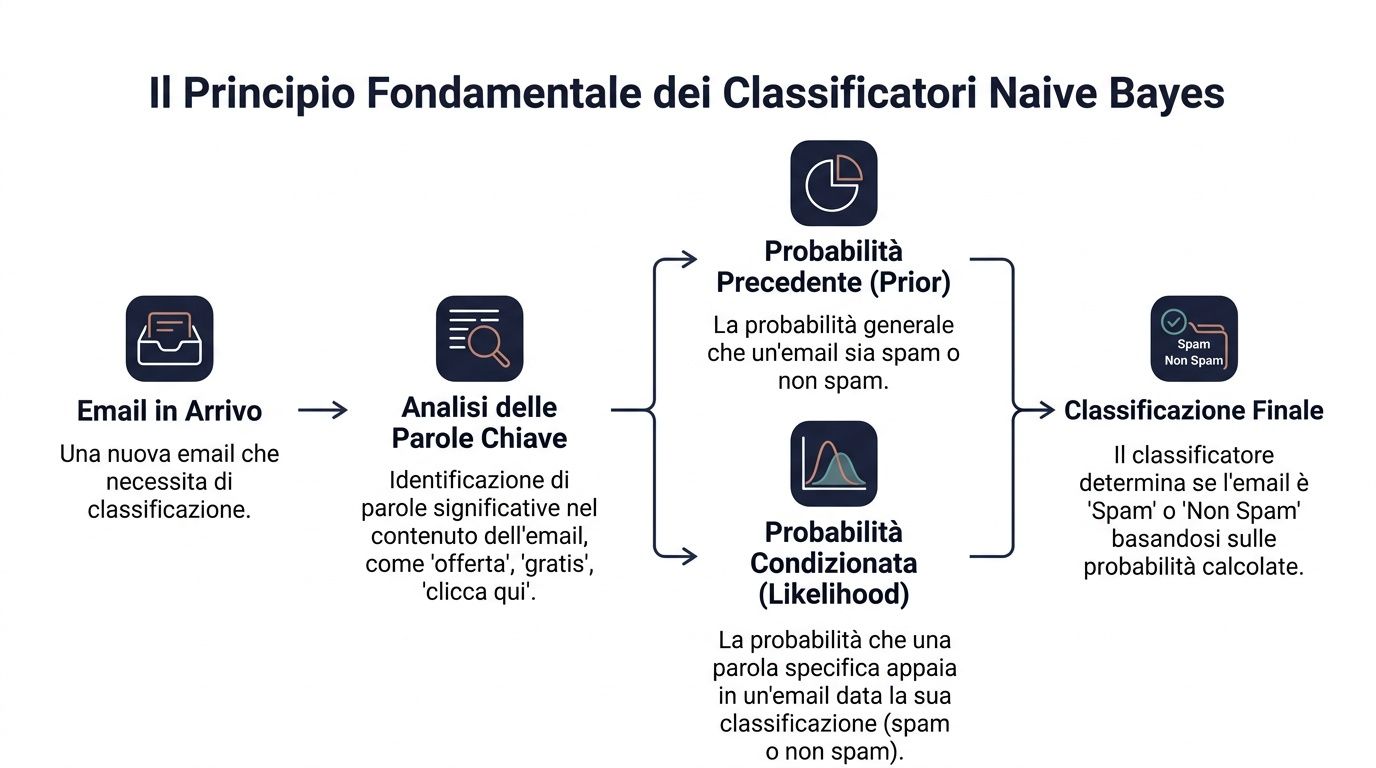
Un manager face ceva similar în fiecare zi. Nu ia niciodată decizii în vid. Pornește de la un context de bază și adaugă indicii. Un client care a cumpărat întotdeauna în mod regulat are un anumit profil inițial. Dacă apoi încetează să mai deschidă e-mailurile, reduce valoarea comenzilor și deschide un tichet de asistență critic, evaluarea ta se schimbă.
Termenul „naiv” se referă la o presupunere precisă. Modelul tratează caracteristicile ca și cum ar fi independente unele de altele, având în vedere că clasa este cunoscută.
Practic, atunci când clasifici un e-mail, tratează fiecare cuvânt ca pe un indiciu separat. Nu încerca să reproduci toate relațiile complexe dintre termeni. Aceasta este o simplificare extremă. În realitate, multe cuvinte apar împreună, iar multe comportamente organizaționale sunt interconectate.
Totuși, tocmai această alegere face ca modelul să fie foarte ușor. Nu trebuie să învețe o rețea complexă de dependențe. Trebuie să estimeze probabilități mai simple și să le combine în mod eficient.
Regulă practică: Naive Bayes nu încearcă să reconstituie întreaga lume. Încearcă să ia decizii utile pe baza unui număr redus de ipoteze și cu mare rapiditate.
Aici apare adesea o neînțelegere. Mulți interpretează expresia „presupunere simplistă” și ajung la concluzia că este vorba de un „model slab”. Nu este așa. Un model poate simplifica foarte mult și poate rămâne competitiv dacă simplificarea surprinde ceea ce contează pentru procesul decizional.
În 2004, o analiză teoretică a evidențiat argumente solide în favoarea eficienței clasificatorilor Naive Bayes, în ciuda ipotezei de independență, explicând totodată de ce aceștia pot atinge eroarea asimptotică mai rapid decât regresia logistică. În același domeniu de aplicații, în filtrarea spamului, aceștia ating o precizie de peste 99% și pot fi scalate la milioane de documente, așa cum se menționează în articolul dedicat clasificatorilor Naive Bayes.
Acest aspect este important pentru un public din mediul de afaceri. Valoarea unui algoritm nu rezidă doar în scorul final. Ea constă și în capacitatea acestuia de a se antrena rapid, de a se adapta la seturi de date de mari dimensiuni și de a rămâne interpretabil.
Când ai texte, categorii, etichete sau semnale dispersate, clasificatorii bayesieni naivi funcționează bine deoarece:
Există însă două aspecte de care trebuie să țineți cont.
Din acest motiv, algoritmul Naive Bayes trebuie privit ca un instrument foarte eficient în cazul problemelor de clasificare rapide, și nu ca o baghetă magică universală. În multe contexte practice, însă, este una dintre cele mai inteligente modalități de a începe.
O greșeală frecventă este aceea de a vorbi despre Naive Bayes ca și cum ar fi un singur model identic în orice situație. În realitate, există diverse variante, concepute pentru diferite tipuri de date.
Alegerea potrivită depinde de forma datelor pe care le ai la dispoziție. Dacă alegi varianta greșită, modelul poate genera totuși o previziune, dar nu raționează în modul cel mai adecvat pentru problema ta.
Modelul Gaussian Naive Bayes este cea mai potrivită variantă atunci când caracteristicile sunt continue. Gândește-te la valoarea medie a unei tranzacții, vârsta clientului, intervalul mediu dintre două achiziții, marja unitară sau valoarea bonului de casă.
Aici, modelul pornește de la premisa că, în cadrul fiecărei clase, valorile urmează o distribuție gaussiană. Nu trebuie să o consideri o constrângere teoretică. Este suficient să reții ideea practică: pentru fiecare clasă, modelul estimează un centru tipic și o dispersie.
Această abordare este utilă atunci când doriți să clasificați cazuri precum:
Într-un test de performanță scikit-learn cu un set de date similar cu datele din comerțul electronic italian, un model Naive Bayes a atins o precizie de 95% cu 1000 de eșantioane, cu un timp de antrenare cu 15% mai scurt decât cel al regresiei logistice . Comparația indicată este de 0,01 s față de 0,1 s pe un procesor standard, datorită antrenării în formă închisă, așa cum se arată în capitolul lui Jake VanderPlas despre Clasificarea Naive Bayes în profunzime.
Pentru o companie, problema nu ține de zecimale. Problema este că această variantă poate oferi rezultate bune fără a fi nevoie de perioade lungi de instruire și fără o infrastructură complexă.
Dacă lucrezi cu texte, tichete, recenzii sau comentarii, modelul Multinomial Naive Bayes este adesea alegerea firească. În acest caz, caracteristicile sunt reprezentate de numere sau frecvențe. Practic, modelul analizează de câte ori apar anumite cuvinte sau termeni.
Este scenariul clasic al:
Motivul pentru care funcționează bine este unul foarte concret. În textele de afaceri, vocabularul poate fi vast, dar fiecare document conține doar o mică parte din cuvintele posibile. Datele sunt dispersate. Modelul Multinomial Naive Bayes gestionează foarte bine tocmai acest tip de structură.
Într-un studiu realizat pe 100.000 de tweet-uri italiene etichetate în funcție de sentiment, modelul Multinomial Naive Bayes a obținut un scor F1 de 0,88, cu o viteză de 10 ori mai mare decât SVM, așa cum se menționează în ghidul GeeksforGeeks privind clasificatorii Naive Bayes.
Pentru a-ți aminti mai ușor, gândește-te astfel: dacă datele tale seamănă cu un document plin de cuvinte numărate, distribuția multinomială este aproape întotdeauna prima opțiune pe care trebuie să o testezi.
Dacă compania ta trebuie să analizeze volume mari de text, întrebarea nu este doar „cât de precis este modelul?”. Ci și „câte solicitări reușește să clasifice fără a încetini ritmul de lucru al echipei?”.
Algoritmul Bernoulli Naive Bayes funcționează cu caracteristici binare. Nu ține cont de câte ori apare un semnal. Contează doar dacă acesta este prezent sau absent.
Această variantă este utilă atunci când prezența unui atribut are o importanță mai mare decât frecvența acestuia. Iată câteva exemple din mediul de afaceri:
Este o abordare foarte utilă atunci când dorești să transformi fenomene complexe în indicatori de tip „da/nu” ușor de monitorizat. În analiza sentimentului, de exemplu, poate conta mai mult faptul că apare un cuvânt negativ, decât de câte ori este repetat.
Distribuția Bernoulli nu este „mai puțin evoluată” decât distribuția multinomială. Este pur și simplu mai potrivită atunci când datele descriu prezența sau absența. Diferența este mică la nivel teoretic, dar mare în ceea ce privește rezultatele.
| Variantă | Tipul ideal de date | Exemplu de caz de utilizare în mediul corporativ |
|---|---|---|
| Gaussian Naive Bayes | Date continue | Clasificarea tranzacțiilor în funcție de risc pe baza sumelor, frecvenței și valorilor medii |
| Naive Bayes multinomial | Texte, calcule, frecvențe | Analizați recenziile și tichetele clienților în funcție de sentiment sau categorie |
| Bernoulli Naive Bayes | Date binare, prezență/absență | Evaluarea semnalelor de tip „da/nu” în ceea ce privește conformitatea, asistența sau utilizarea produsului |
Pentru a face o alegere bună, folosește o regulă simplă:
Multe echipe se blochează pentru că caută modelul „cel mai bun” în absolut. Alegerea corectă este, aproape întotdeauna, modelul care se potrivește cel mai bine tipului de date.
Vestea bună este că punerea în practică a modelului Naive Bayes nu necesită un proiect de anvergură. Chiar și un prototip ușor de înțeles permite deja să înțelegem cum funcționează modelul și de ce date are nevoie.

Un clasificator se creează aproape întotdeauna în patru etape.
Pregătirea datelor
Trebuie să colectezi exemple istorice deja etichetate. Dacă clasifici recenzii, ai nevoie de texte deja marcate ca fiind pozitive sau negative. Dacă analizezi riscul operațional, ai nevoie de cazuri anterioare cu rezultat cunoscut.
Antrenarea modelului
Modelul analizează datele și estimează probabilitățile relevante. În cazul clasificatorilor bayesieni naivi, această etapă este rapidă, deoarece antrenarea nu necesită optimizări deosebit de complexe.
Previziuni privind cazurile noi
Introduceți înregistrări noi, iar modelul le va atribui o categorie. De exemplu: „spam”, „nu este spam”, „client cu risc”, „client stabil”.
Evaluarea
: comparați previziunile cu realitatea pe un set de date de testare separat. Aici nu verificați doar dacă modelul funcționează, ci și modul în care greșește.
Dacă dorești să aprofundezi imaginea de ansamblu a abordărilor predictive, această prezentare generală a algoritmilor de învățare automată te ajută să încadrezi algoritmul Naive Bayes într-o familie mai largă de metode.
Pentru a ilustra concret acest proces, iată un exemplu simplu cu scikit-learn. Nu este necesar să-l citești ca dezvoltator. Este suficient să înțelegi fluxul.
# Importăm instrumentele principalefrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# Încărcăm un set de date de exempluX, y = load_iris(return_X_y=True)# Împărțim datele într-o parte pentru antrenare și o parte pentru testare X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Creăm modelulmodel = GaussianNB()# Antrenăm modelul pe datele istoricemodel.fit(X_train, y_train)# Facem previziuni pe date nevăzutey_pred = model.predict(X_test)# Măsurăm acuratețaprint(accuracy_score(y_test, y_pred))Acest fragment spune mult mai mult decât pare la prima vedere.
GaussianNB() alege varianta pentru date continue.fit() este momentul în care modelul învață.predict() pune în practică ceea ce a învățat.accuracy_score() verifică câte clasificări sunt corecte în ansamblu.În cazul datelor textuale, procesul rămâne similar, dar înainte de a aplica modelul trebuie să transformi textul în numere. Practic, convertești cuvintele în caracteristici care pot fi utilizate de un clasificator.
După o primă privire asupra codului, ar putea fi util să vedem o explicație vizuală a mecanismului.
Primul model nu are rolul de a demonstra perfecțiunea. El servește la a răspunde la trei întrebări practice.
Aici se vede puterea modelului Naive Bayes. Poți ajunge rapid la un punct de referință solid. De acolo îți dai seama dacă are sens să complici proiectul sau dacă o soluție simplă generează deja valoare.
Un model de clasificare nu se evaluează doar pe baza faptului că „pare să funcționeze”. Se evaluează în funcție de modul în care greșește și de cât de mult afectează aceste erori activitatea companiei.

Precizia este cel mai intuitiv indicator. Aceasta indică numărul de previziuni corecte din total. Este utilă, dar, luată separat, poate induce în eroare.
Dacă, din o sută de tranzacții, doar câteva sunt cu adevărat suspecte, un model care clasifică aproape totul ca fiind normal poate părea precis, dar să se dovedească ineficient acolo unde este cu adevărat necesar.
Pentru a înțelege acest lucru, imaginează-ți o plasă de pescuit.
În lumea afacerilor, această distincție contează foarte mult.
Un model bun nu este cel care greșește puțin în general. Este cel care greșește în modul cel mai puțin costisitor pentru procesul tău.
Pentru a înțelege mai bine cum învață un algoritm din datele istorice și de ce calitatea antrenamentului influențează rezultatul final, poți citi acest articol detaliat despre ce presupune antrenarea unui algoritm.
Algoritmul Naive Bayes este simplu, dar nu iartă anumite greșeli practice.
Prima greșeală: ignorarea problemei frecvenței zero.
Dacă un cuvânt sau o valoare nu apare niciodată în datele de antrenament pentru o anumită clasă, probabilitatea poate scădea la zero și poate compromite calculul. Din acest motiv, se utilizează adesea netezirea Laplace, care adaugă o mică corecție la numărări.
A doua greșeală: utilizarea unor caracteristici puternic corelate.
Dacă două coloane conțin aproape aceeași informație, modelul riscă să supraestimeze semnalul. Acesta nu „înțelege” că cele două indicii sunt aproape identice.
A treia greșeală: a te baza prea mult pe probabilitățile brute.
Modelul Naive Bayes clasifică adesea corect, dar probabilitățile sale pot fi prea categorice. Din punct de vedere comercial, acest lucru înseamnă că clasamentul poate fi util, în timp ce valoarea exactă a probabilității trebuie interpretată cu prudență.
Pentru a reduce aceste riscuri, este recomandat:
Adevărata valoare a clasificatorilor bayesieni naivi iese la iveală atunci când încetezi să îi mai privești ca pe un exercițiu matematic și începi să îi folosești ca motor de stabilire a priorităților. În cadrul unei companii, o clasificare corectă înseamnă aproape întotdeauna o luare mai bună a deciziilor.

Imaginează-ți o echipă financiară care analizează fluxurile de tranzacții, descrierile operaționale și datele istorice. Fiecare rând nu este doar o înregistrare. Este o decizie potențială: a lăsa să treacă, a aprofunda, a bloca, a transmite unui analist.
Cu Naive Bayes poți combina diferiți indicatori într-o singură clasificare. Unii sunt numerici, alții binari, iar alții textuali. Modelul te ajută să înțelegi care cazuri seamănă cel mai mult cu tiparele deja observate ca fiind normale sau anomale.
Avantajul practic este dublu:
Nu înlocuiește judecata umană în contextele reglementate. Ci o organizează. Iar în procesele operaționale de mare volum, acest lucru face o diferență reală.
În marketing, clasificarea înseamnă adesea încadrarea fiecărui client într-un grup operațional. Clienți fideli. Clienți sensibili la preț. Clienți cu risc de pierdere. Clienți receptivi la promoții. Clienți inactivi.
În acest caz, Naive Bayes este util deoarece reușește să combine rapid semnale eterogene:
O echipă de CRM nu are nevoie de o teorie perfectă a comportamentului uman. Are nevoie de o segmentare suficient de bună pentru a genera acțiuni pertinente. De exemplu, modificarea mesajului, a frecvenței contactului sau a tipului de ofertă.
Atunci când un model ajută la alegerea mesajului următor pentru clientul potrivit, acesta creează deja valoare operațională.
În comerțul cu amănuntul și în comerțul electronic, clasificarea stă la baza unor activități care par diferite, dar care au aceeași logică: a pune ordine în haos.
Poți clasifica produsele în funcție de profilul lor de vânzări. Poți citi recenziile și tichetele de asistență pentru a identifica categoriile care generează probleme. Poți identifica tiparele de cerere care ajută echipa să planifice promoțiile și stocurile cu mai multă claritate.
În acest tip de mediu, datele sunt adesea numeroase, eterogene și nu întotdeauna perfecte. De aceea, un model rapid, scalabil și ușor de înțeles are o mare valoare. Nu pentru că ar fi cel mai spectaculos, ci pentru că se integrează în fluxul de lucru fără a-l încetini.
Dacă vrei să vezi cum abordările analitice aplicate în domeniul afacerilor prind contur în proiecte concrete, poți arunca o privire la aceste studii de caz.
Este util să înțelegi modelul Naive Bayes. Însă implementarea lui corectă într-un context de afaceri este cu totul altă poveste.
Problema nu ține aproape niciodată doar de algoritm. Adevărata muncă se concentrează pe model. Trebuie să conectezi diverse surse de date, să gestionezi câmpurile lipsă, să pregătești textele, să actualizezi etichetele, să verifici calitatea rezultatelor și să interpretezi rezultatele într-un mod ușor de înțeles pentru factorii de decizie.
Pentru o întreprindere mică sau mijlocie, această etapă reprezintă adesea punctul critic. Nu pentru că nu ar exista interes pentru IA, ci pentru că timpul echipei este limitat, iar prioritățile operaționale nu pot aștepta.
În acest context, este indicat să se utilizeze o platformă care preia complexitatea tehnică. O soluție bazată pe inteligență artificială permite transformarea datelor brute în informații ușor de interpretat, fără a fi necesar ca departamentul de afaceri să scrie cod, să aleagă biblioteci sau să gestioneze manual fluxurile de date.
O platformă precum ELECTE, o platformă de analiză a datelor bazată pe inteligență artificială destinată IMM-urilor, face accesibile metode precum clasificatorii bayesieni naivi, fără a necesita cunoștințe de specialitate în domeniul învățării automate. Avantajul nu constă doar în viteză. Este vorba despre reducerea fricțiunii dintre date și decizie.
Când automatizarea funcționează bine, echipa nu mai gândește în termeni de formule. Gândește în termeni de întrebări utile:
Acesta este și motivul pentru care tot mai multe companii caută instrumente care să le ajute să evalueze fiabilitatea conținutului generat de IA și a semnalelor textuale care circulă în cadrul proceselor interne. În acest context, poate fi util să consulți și un ghid privind un detector de IA italian, mai ales dacă echipa ta lucrează cu documente, conținut și verificări lingvistice.
În practică, diferența este simplă. În loc să te ocupi de etape tehnice fragmentate, îți concentrezi atenția asupra rezultatului companiei. Și acesta este momentul în care IA devine cu adevărat utilă, nu doar interesantă.
Clasificatoarele bayesiene naive ne oferă o lecție importantă. În domeniul analizei de date, simplitatea bine aplicată poate depăși complexitatea prost gestionată.
Datorită unei baze probabilistice intuitive, unei scalabilități bune și unor cazuri de utilizare foarte concrete, această abordare rămâne un instrument de încredere pentru companiile care doresc să clasifice informațiile, să identifice semnale ascunse și să acționeze cu mai multă siguranță. Nu este nevoie să fii specialist în învățarea automată pentru a-i înțelege valoarea. Este nevoie să corelezi matematica cu deciziile operaționale.
Când această legătură devine clară, IA încetează să mai fie o chestiune tehnică și devine un avantaj organizațional. Abia atunci previziunile încep să aibă un impact.
Dacă vrei să transformi datele disparate în informații clare, încearcă ELECTE. Platforma ajută IMM-urile să conecteze surse de date, să automatizeze analiza și să obțină rapoarte și previziuni utile pentru decizii mai rapide și mai informate.

.svg)
.svg)
.svg)




.webp)

